Problem Admin- oder Influx-Adapter ?
-
@djmarc75 sagte in Problem Admin- oder Influx-Adapter ?:
@segway sagte in Problem Admin- oder Influx-Adapter ?:
Wo liegt das Problem ?
Zeig mal die Benutzerdefinierten Einstellungen vom DP bitte.
Meinst du die ?
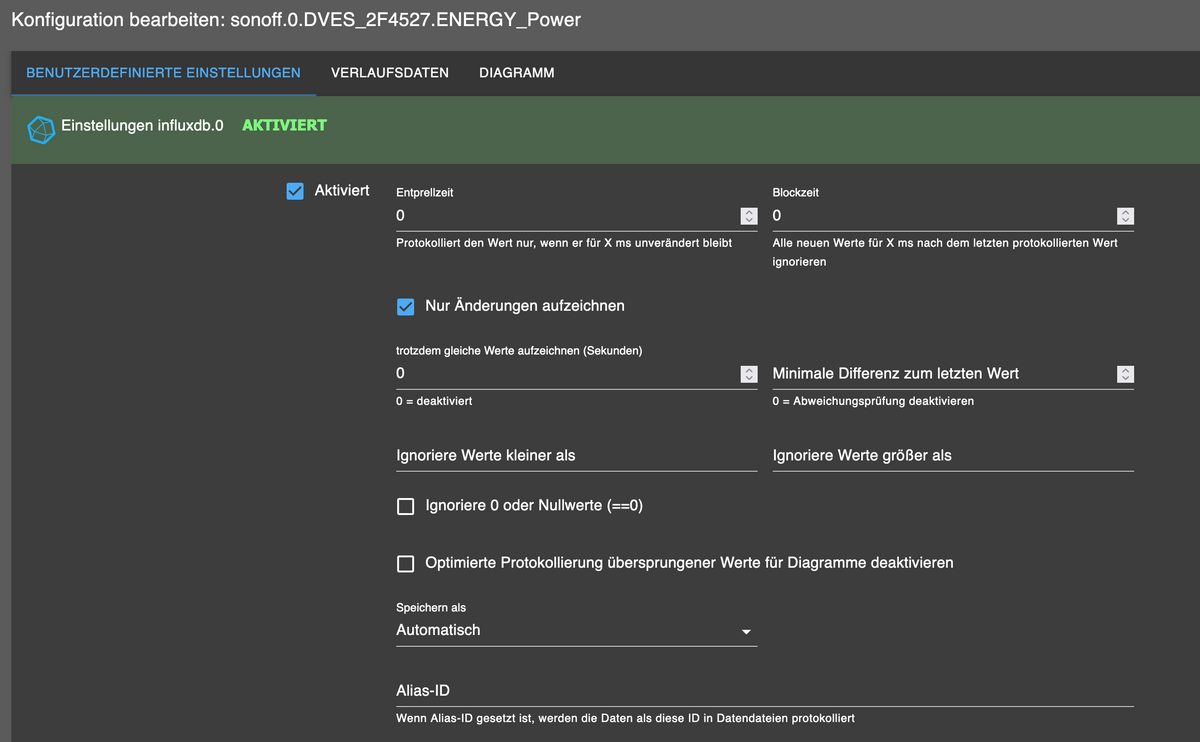
{ "_id": "sonoff.0.DVES_2F4527.ENERGY_Power", "common": { "type": "number", "role": "value.power.consumption", "read": true, "write": false, "unit": "W", "name": "DVES_2F4527 ENERGY Power", "custom": { "influxdb.0": { "enabled": true, "changesOnly": true, "debounce": "", "retention": "63072000", "changesRelogInterval": 0, "changesMinDelta": "", "storageType": "", "aliasId": "", "maxLength": 10, "debounceTime": 0, "blockTime": 0, "ignoreBelowNumber": "", "disableSkippedValueLogging": false, "enableDebugLogs": false }, "sourceanalytix.0": { "enabled": true, "selectedUnit": "Detect automatically", "deviceResetLogicEnabled": true, "threshold": 1, "start_day": 0, "start_week": 0, "start_month": 0, "start_quarter": 0, "start_year": 0, "costs": true, "consumption": true, "selectedPrice": "ElectricityDay" } } }, "native": {}, "type": "state", "acl": { "object": 1636, "state": 1636, "owner": "system.user.admin", "ownerGroup": "system.group.administrator" }, "from": "system.adapter.admin.0", "user": "system.user.admin", "ts": 1704104138604 } -
-
-
Error: connect ECONNREFUSED 192.168.40.99:8086
das heisst auf jeden Fall, dass der Adapter die Influxdb nicht erreicht, da zu diesem Zeitpunkt niemand auf dem Influx-Port antwortet. Schau‘ am besten mal im Log der Influxdb - ich tippe auf Speichermangel…
-
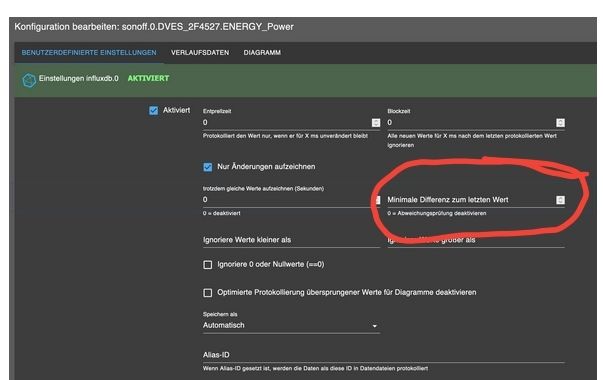
nutze influxdb nicht, aber so sollte das nicht aussehen.
Wenn deaktiviert soll da eine 0 stehen, und die Überschrift höher -
@homoran sagte in Problem Admin- oder Influx-Adapter ?:
nutze influxdb nicht, aber so sollte das nicht aussehen.
Wenn deaktiviert soll da eine 0 stehen, und die Überschrift höherAlso das sieht bei jedem Datenpunkt so aus bei mir.
Habe das mal auf 0 geändert für den Datenpunkt und gespeichert aber der Effekt ist derselbe. VM Lief voll und nichts geht mehr. Da kann ich auch so viel Speicher geben wie ich will ist immer desgleichen und das ist nur für eine halbe Stunde !!!!
Irgendwas stimmt da nicht. -
@segway ich hab das so
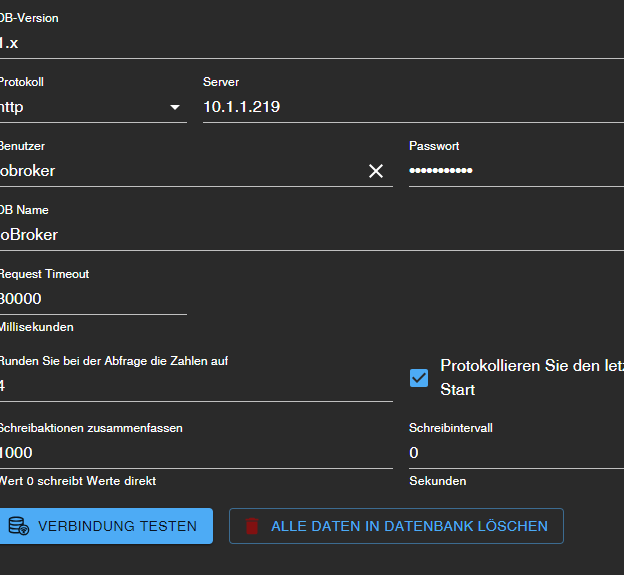
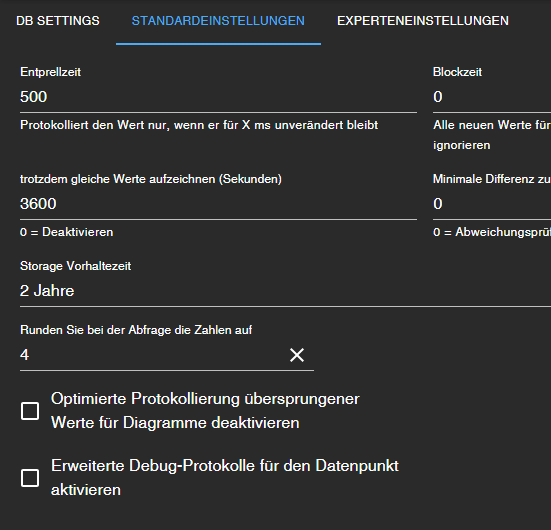
bei mir ist allerdings in der Basiseinstellung history hinterlegt
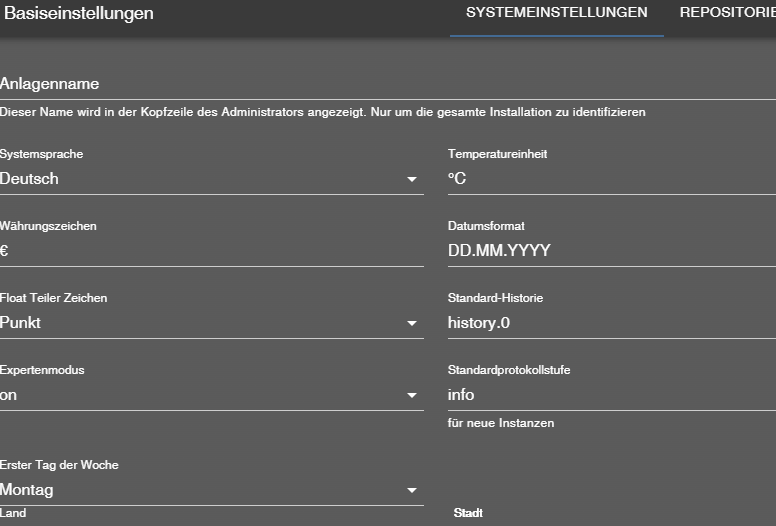
-
@crunchip sagte in Problem Admin- oder Influx-Adapter ?:
@segway ich hab das so
Sieht bei mir ähnlich aus:
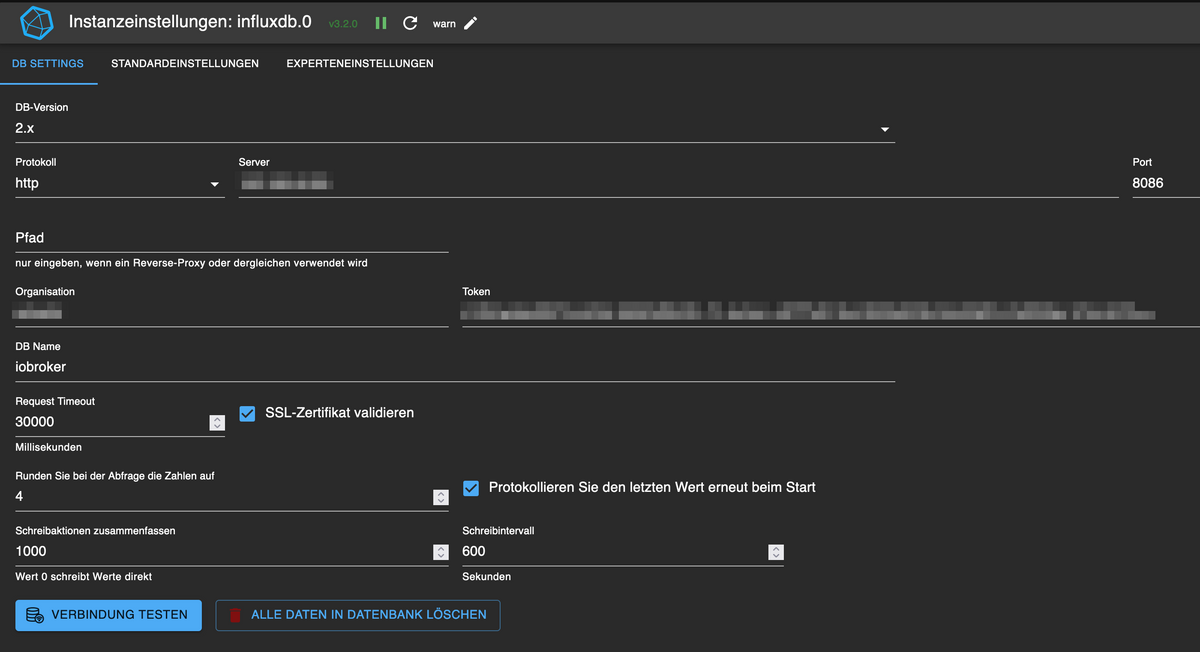
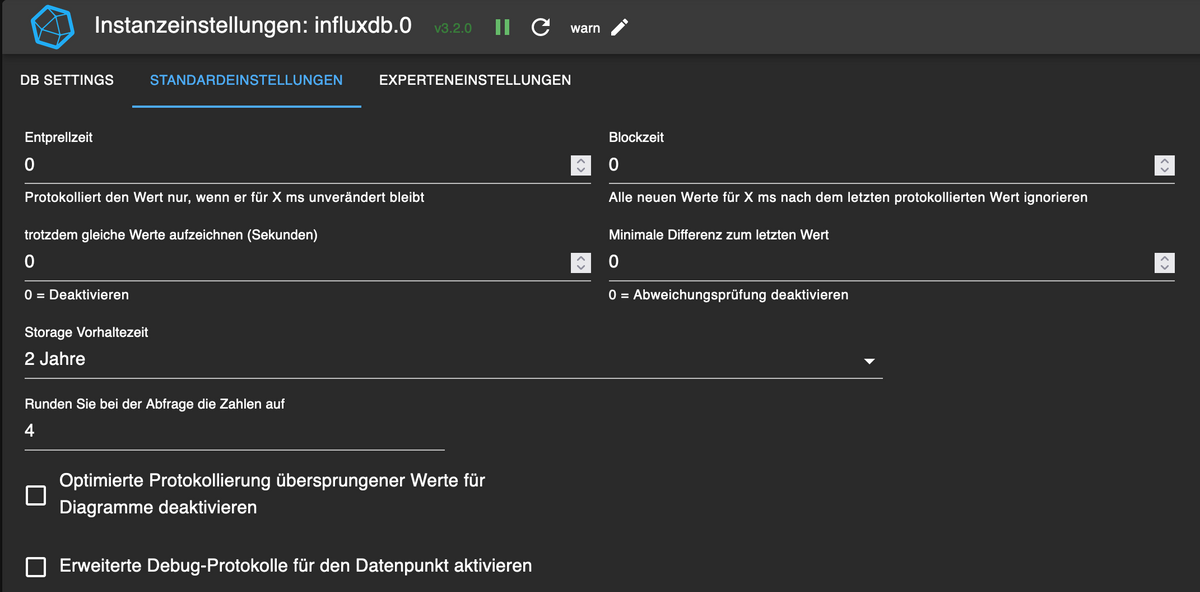
bei mir ist allerdings in der Basiseinstellung history hinterlegt
bei natürlich influxdb.0 da ich kein Historie Adapter habe
-
@segway sagte in Problem Admin- oder Influx-Adapter ?:
und das ist nur für eine halbe Stunde !!!!
So ist es leider nicht. Der Adapter macht im Hintergrund Abfragen über den gesamten Datenbestand (für das selektierte Measurement). Ich vermute, dass du dort so viel Daten drin hast, dass die InfluxDB die Segel streicht.
Hier kannst du mal schauen, wie viele Datensätze jeweils drin sind, ist natürlich dann fraglich, ob die DB das schafft:
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"}) -
@marc-berg sagte in Problem Admin- oder Influx-Adapter ?:
@segway sagte in Problem Admin- oder Influx-Adapter ?:
und das ist nur für eine halbe Stunde !!!!
So ist es leider nicht. Der Adapter macht im Hintergrund Abfragen über den gesamten Datenbestand (für das selektierte Measurement). Ich vermute, dass du dort so viel Daten drin hast, dass die InfluxDB die Segel streicht.
Hier kannst du mal schauen, wie viele Datensätze jeweils drin sind, ist natürlich dann fraglich, ob die DB das schafft:
Mhhh, natürlich habe ich sehr viele Daten drin, dafür soll die DB ja auch sein.
Warum fragt er den gesamten Datenbestand ab wenn ich nur einen Datenpunkt ausgewählt habe ? Das macht eher keine Sinn oder ? -
@marc-berg sagte in Problem Admin- oder Influx-Adapter ?:
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})Der Vollständigkeit halber hier das Ergebnis - aber bitte jetzt keine Diskussion darüber. Auf der Arbeit haben wir deutlich mehr an Daten:
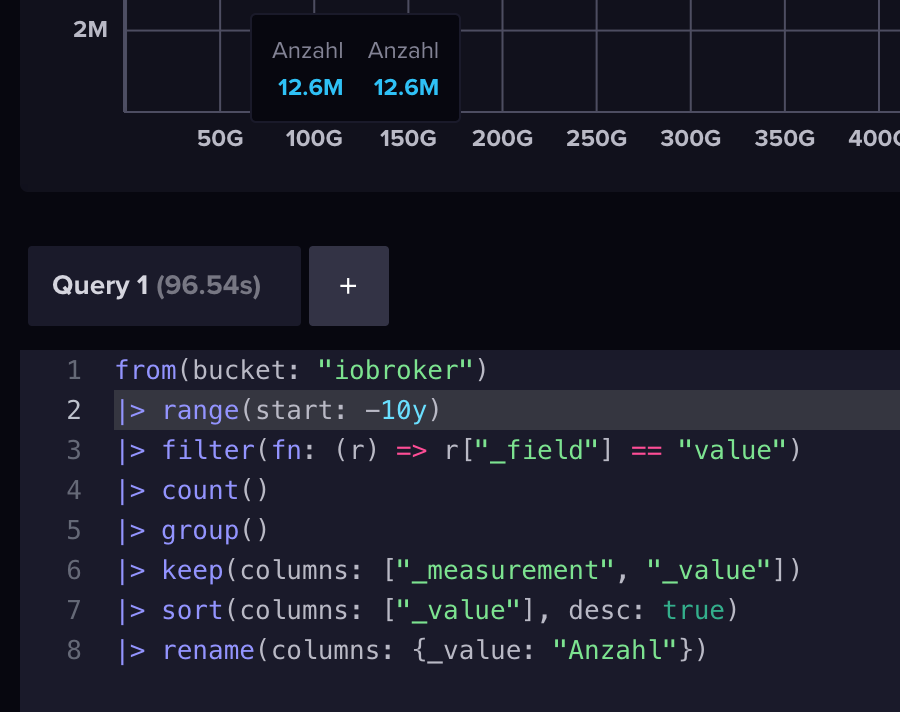
Der Befehl wurde anstandslos in 96s abgearbeitet
-
siehe oben ergänzende Infos
-
@segway sagte in Problem Admin- oder Influx-Adapter ?:
Warum fragt er den gesamten Datenbestand ab wenn ich nur einen Datenpunkt ausgewählt habe ? Das macht eher keine Sinn oder ?
Nein, ich hatte ja geschrieben, dass "nur das selektierte Measurement" / Datenpunkt abgefragt wird, dieses aber ab 1999. Das reicht aber offensichtlich bei deinen Datenmengen schon aus.
Unbhängig davon sind die Abfragen im Hintergrund wohl optimierungsbedürftig. Habe das gerade mal getestet. Wenn man auf Verlaufsdaten klickt, werden im Hintergrund acht Abfragen mit unterschiedlichen Zeiträumen abgefeuert.
-
@segway sagte in Problem Admin- oder Influx-Adapter ?:
Der Vollständigkeit halber hier das Ergebnis - aber bitte jetzt keine Diskussion darüber.
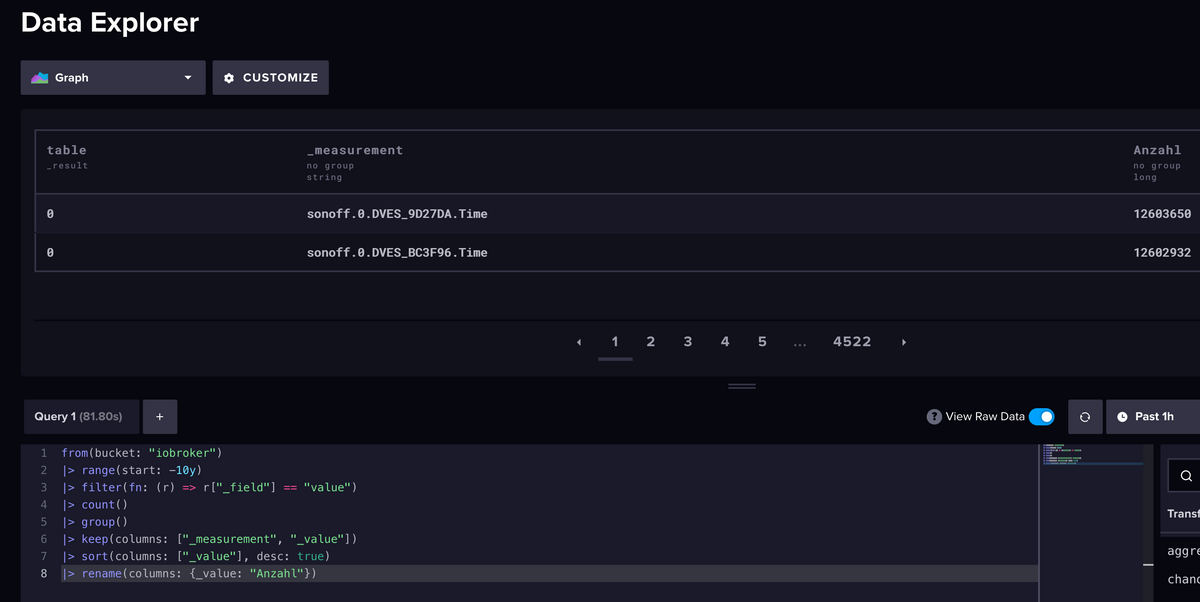
Kannst du mal auf

schalten? Gibt es da noch mehr als 12 Mio Datensätze?
-
@marc-berg sagte in Problem Admin- oder Influx-Adapter ?:
Unbhängig davon sind die Abfragen im Hintergrund wohl optimierungsbedürftig. Habe das gerade mal getestet. Wenn man auf Verlaufsdaten klickt, werden im Hintergrund acht Abfragen mit unterschiedlichen Zeiträumen abgefeuert.
Das ist ja schonmal was. Aber erklärt das mein beschriebenes verhalten ?
@marc-berg sagte in Problem Admin- oder Influx-Adapter ?:
Kannst du mal auf
schalten? Gibt es da noch mehr als 12 Mio Datensätze?Sind wohl ähnlich:
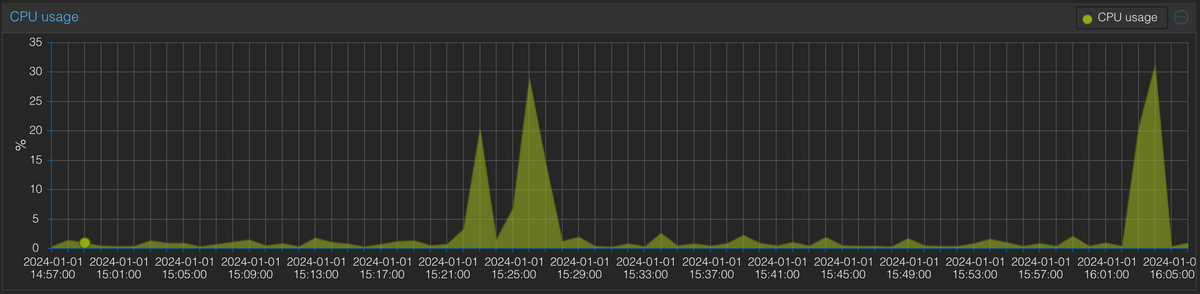
Hier sieht man noch die Influx VM, wie sie ihre Arbeit verrichtet für die 3 Abfragen von mir:
-
@segway sagte in Problem Admin- oder Influx-Adapter ?:
Das ist ja schonmal was. Aber erklärt das mein beschriebenes verhalten ?
Ich finde das schon ziemlich plausibel. Die acht Queries werden ja praktisch zeitgleich abgesetzt. D.h. acht mal wird da parallel über (teilweise) 12 Mio Datensätze gerauscht. Da darf CPU und RAM aus meiner Sicht schon mal an Grenzen geraten.
-
@marc-berg sagte in Problem Admin- oder Influx-Adapter ?:
@segway sagte in Problem Admin- oder Influx-Adapter ?:
Das ist ja schonmal was. Aber erklärt das mein beschriebenes verhalten ?
Ich finde das schon ziemlich plausibel. Die acht Queries werden ja praktisch zeitgleich abgesetzt. D.h. acht mal wird da parallel über (teilweise) 12 Mio Datensätze gerauscht. Da darf CPU und RAM aus meiner Sicht schon mal an Grenzen geraten.
Also ein Bug ? Soll ich ein Issue aufmachen ?
-
@segway sagte in Problem Admin- oder Influx-Adapter ?:
Also ein Bug ? Soll ich ein Issue aufmachen ?
Als Bug würde ich es nicht unbedingt bezeichnen. Hier treffen nicht optimierte Abfragen auf, ähm..., nicht optimierte Daten.
Aber da ich die Queries sowieso gerade parat habe, kann ich das auch machen.
-
@marc-berg sagte in Problem Admin- oder Influx-Adapter ?:
Als Bug würde ich es nicht unbedingt bezeichnen. Hier treffen nicht optimierte Abfragen auf, ähm..., nicht optimierte Daten.
sehr schön ausgedrückt

Aber da ich die Queries sowieso gerade parat habe, kann ich das auch machen.
Alles klar danke. Poste mir bitte den Issue dann subscribe ich den
-
@segway sagte in Problem Admin- oder Influx-Adapter ?:
Hier sieht man noch die Influx VM, wie sie ihre Arbeit verrichtet für die 3 Abfragen von mir:
Das selbe Bild hatte ich vor kurzem und der influx adapter hatte keine Verbindung. Als ich mich über SSH in der influx VM einloggen wollte stand ganz oben OOM Kill. Obwohl der RAM verbrauch bei mir immer 880-890MB von 1GB hatte. Ich hab den RAM jetzt auf 1,5GB erhöht jetzt nutzt die VM ca. 970MB.
Icht würde testweise den RAM mal erhöhen, falls es das nicht war kann man es ja wieder rückgängig machen...