ioBroker sehr hohe Diskwrites in Proxmox
-
@meister-mopper
Die Log-Dateien sind auch nicht zu groß.
Wie sieht es mit History aus ? -
@homoran sagte in ioBroker sehr hohe Diskwrites in Proxmox:
oder!
Warum erst nach 60-90 Minuten?Trägheit der Aufzeichnung die geht sowieso nur 4 Stunden Takt... aber was weiß ich schon davon, das ist nur stochern im Trüben Wasser.
Und wenn Redis erst sammelt und dann schreibt kommt doch die gleichmäßige Schreibkurve zusammen oder verstehe ich das falsch?
")
-
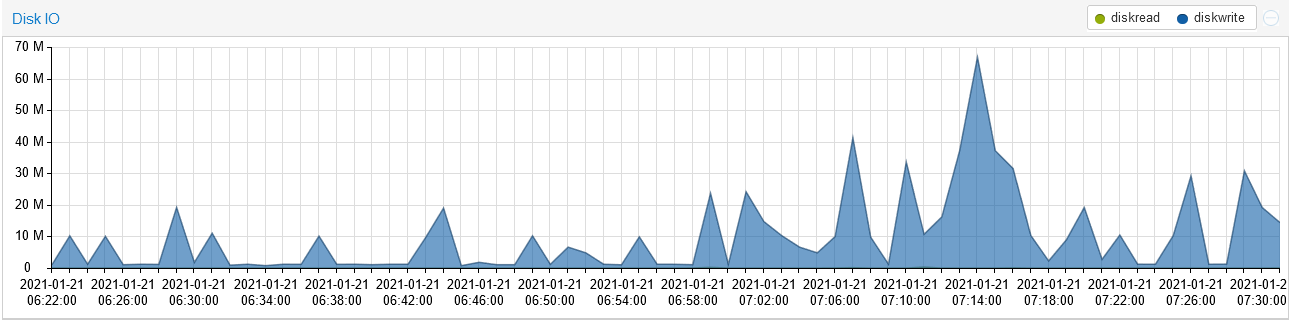
Wenn ich in die Grafik der letzten Stunde schaue, gibt es regelmäßige Spitzen. Diese stammen von zwei Adaptern. Nämlich
netatmo(gelb) unddaswetter(grün).
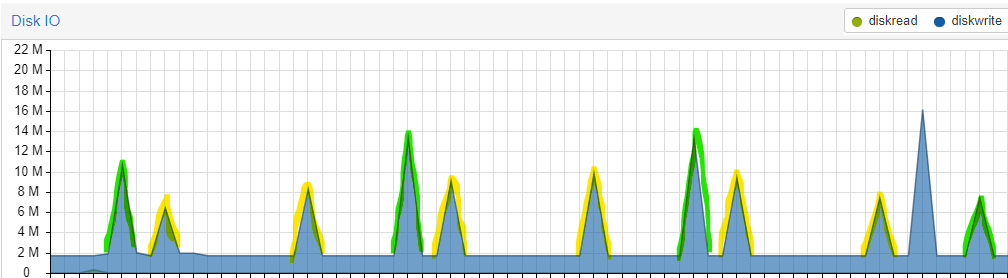
Bei Netatmo habe ich das Abfrageintervall von 5 auf 10 Minuten erhöht. Das hat eine Reduktion von knapp 20% gebracht. Die Frage ist ob man diese Schreibwerte senken kann (ohne die Intervalle weiter zu erhöhen), bzw. ob Redis hier etwas signifikant verbessern würde?
-
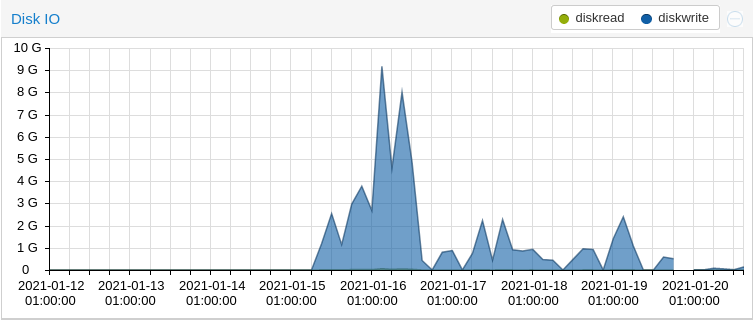
Jetzt hab ich mir meins auch mal angesehen, seltsamerweise auch die Änderung ab dem 15.01. Jedoch eher negativ.
Was war die große Veränderung ab diesem Tag? Updates der Adapter und Js-Controller 3.2.x und folgende.
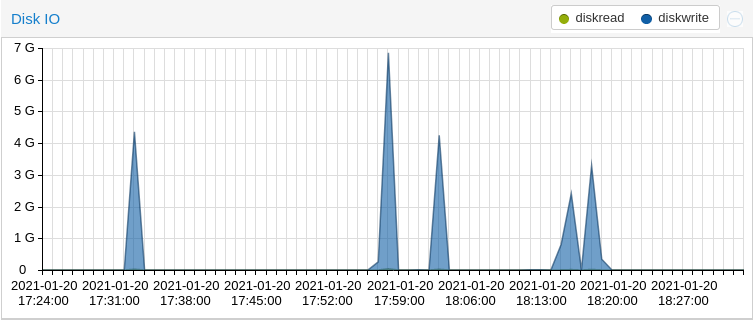
Das ist ein Screen von einer Woche, wenn ich da meine Werte anschau, fall ich ja total aus dem Rahmen, bin bei knapp über 9G Spitze,
vor dem Anstieg lag ich im Schnitt bei knapp 3M
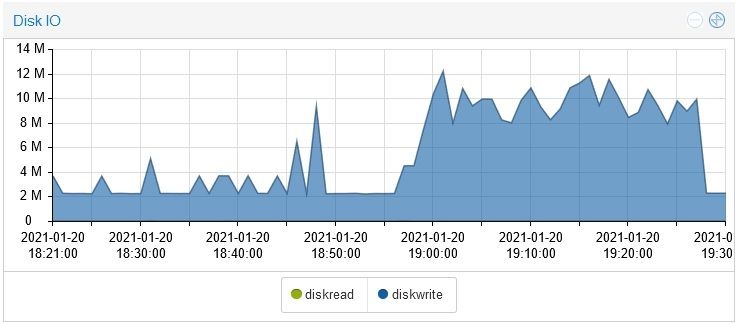
diese von der letzten Stunde, auch da sieht man die spitzen im Detail
das deckt sich auch mit solchen Meldungeninfluxdb.0 2021-01-20 18:15:33.302 warn / "{\"error\":\"timeout\"}\n" influxdb.0 2021-01-20 18:15:33.302 warn (925) Error on writePoint("{"value":22,"time":"2021-01-20T17:05:00.988Z","from":"system.adapter.sonoff.0","q":0,"ack":true}): Error: {"error":"timeout"} influxdb.0 2021-01-20 18:15:21.085 warn / "{\"error\":\"timeout\"}\n" influxdb.0 2021-01-20 18:15:21.085 warn (925) Error on writePoint("{"value":4,"time":"2021-01-20T17:04:50.516Z","from":"system.adapter.sonoff.0","q":0,"ack":true}): Error: {"error":"timeout"} broadlink2.0 2021-01-20 18:15:18.409 info -
@crunchip Ich bin gerade dabei, geduldig Adapter zu starten, wenn der Vorgänger ruhig wird. Bin mal gespannt welcher es ist ...
-
Weiss es noch nicht, aber hier die Reaktion, wenn der synology startet.
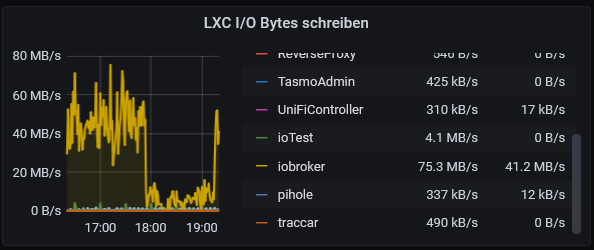
Wenn sich das bestätigt, mach ich ein issue auf. -
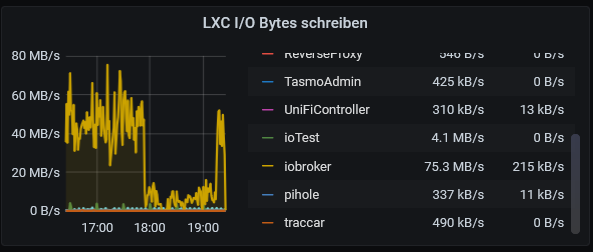
Jetzt ist es klar. Bei mir ist es der Synology-Adapter. Hier wurde er gerade
ausgeschaltet:
-
-
@saeft_2003 Na ja, da wissen wir ja Bescheid

-
ja aaaaaber davor war der Monate aus. Ich habe diesen heute nur zufällig ( @Glasfaser ) aktiviert.
-
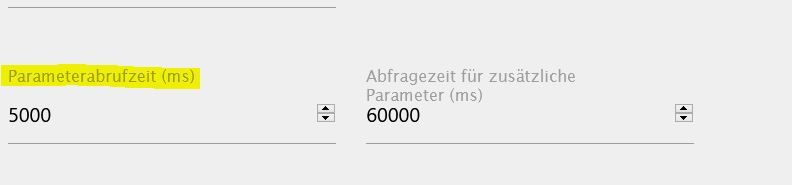
In der Standarteinstellung ist 100 ms
Stellt ihn mal hoch , was ist dann !?
-
100ms ist Standard?

Bei mir stand es auf 5000ms ich habe es jetzt einfach mal extrem erhöht auf 50000ms und schaue was der diskwrite sagt.
-
@saeft_2003 sagte in ioBroker sehr hohe Diskwrites in Proxmox:
habe es jetzt einfach mal extrem erhöht auf 50000ms
Mit diesem Wert herrscht auch bei mir wieder Ruhe
-
Also ich habe einen diskwrite von ca 3-4 MB pro Sek im Durchschnitt das macht in der Stunde 10 GB. Ich verstehe immer noch nicht wo diese Datenmengen herkommen...
Ist dazu einer von euch schon schlauer?
-
@saeft_2003 also ich habe auf jeden Fall bei mir festgestellt, dass der javascript adapter sowie influxdb hohe Datenmengen verursachen.
Aktuell glaube ich aber, es liegt dennoch an der Kombination aus Consumer SSD mit Proxmox. Da kann man einiges drüber nachlesen auch ohne ioBroker.https://forum.proxmox.com/threads/schlechte-windows-performance-hoher-i-o-delay.52064/
Falls einer grade mal Zeit hat das zu studieren
") oder zu testen
oder zu testenliegt der Verschleiß der SSD vor allem an der Verwendung von ZFS als Dateisystem?`` nein. Das liegt an Proxmox, da es ziemlich viel in die Logs schreibt. Man kann das deaktivieren, wenn man nur ein single-node betreibt. Mehr siehe hier: https://wiki.chotaire.net/proxmox-various-commands Meine beiden 250 GB EVO 850 hatten nach 3 Jahren ca. 25 % wearout (bei 24/7). Mein neuer Server hat nach nun 2 Monaten 1 % Wearout auf zwei 500 GB EVO 860.L
-
@robbsen sagte in ioBroker sehr hohe Diskwrites in Proxmox:
Interessant, hast Du dazu diese Befehle in Folge eingegeben?
systemctl stop pve-ha-lrm systemctl stop pve-ha-crm systemctl disable pve-ha-lrm systemctl disable pve-ha-crm -
liegt der Verschleiß der SSD vor allem an der Verwendung von ZFS als Dateisystem?`` nein. Das liegt an Proxmox, da es ziemlich viel in die Logs schreibt. Man kann das deaktivieren, wenn man nur ein single-node betreibt. Mehr siehe hier: https://wiki.chotaire.net/proxmox-various-commands Meine beiden 250 GB EVO 850 hatten nach 3 Jahren ca. 25 % wearout (bei 24/7). Mein neuer Server hat nach nun 2 Monaten 1 % Wearout auf zwei 500 GB EVO 860.L
Das verstehe ich nicht nach 3 Jahren 25% macht 0,6% pro Monat. Dann ist nach 2 Monaten 1% auch nicht wirklich viel besser (um genau zu sein 0,2%).
Wie genau kann man eigentlich den wearout ermitteln?
-
@saeft_2003
Über Linux Konsole, aber auch über Proxmox zeigt er die Smart Werte (siehe Bilder)
aber Wearout konnte ich da auch nicht finden.
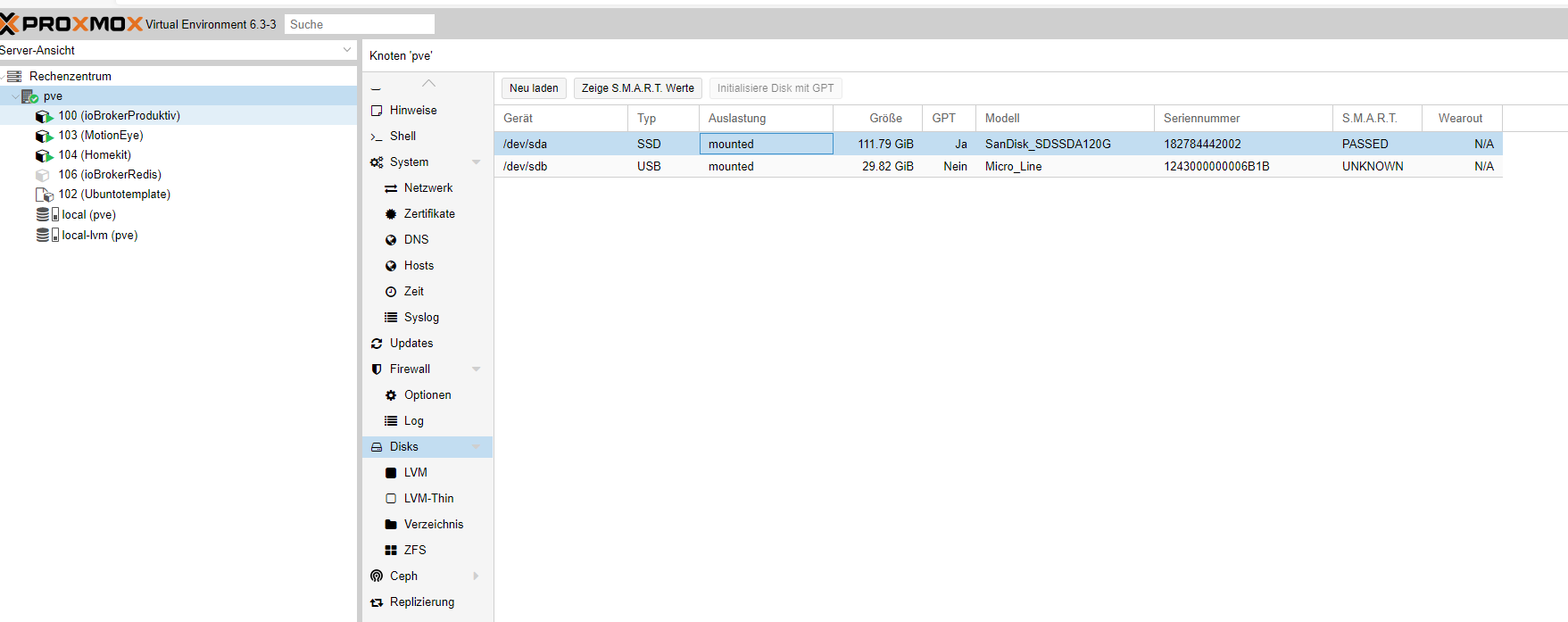
226 Timed Workload, Media Wear (Abnutzung) https://www.thomas-krenn.com/de/wiki/SMART_Attribute_von_Intel_SSDs
Bei mir ist dort nur der Life Circle der wohl bei 100 sagt "Festplatte i.O."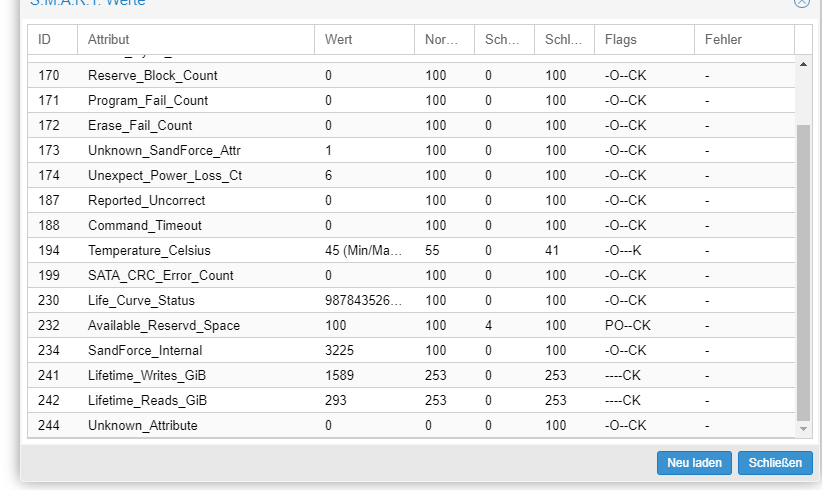
@meister-mopper lieber nicht bin grade im Stress ^^. Wenn ich wieder mein SmartHome zerlege und Nachtschichten einlege brauche ich kein Corona mehr zum sterben
-
Ich habe auch mal versucht den Zustand meiner SSD raus zu bekommen.
In proxmox unter PVE --> Disks siehe ich meine SSD dort steht ein wearout von 0% (was schon mal gut sein sollte).
Dann kann man sich noch die SMART Werte anzeigen lassen. Hier gibt es den Atribut "Media_Wearout_Indicator". Dieser steht bei mir auf 100. Wenn ich es richtig verstanden habe sinkt dieser bis auf 1.
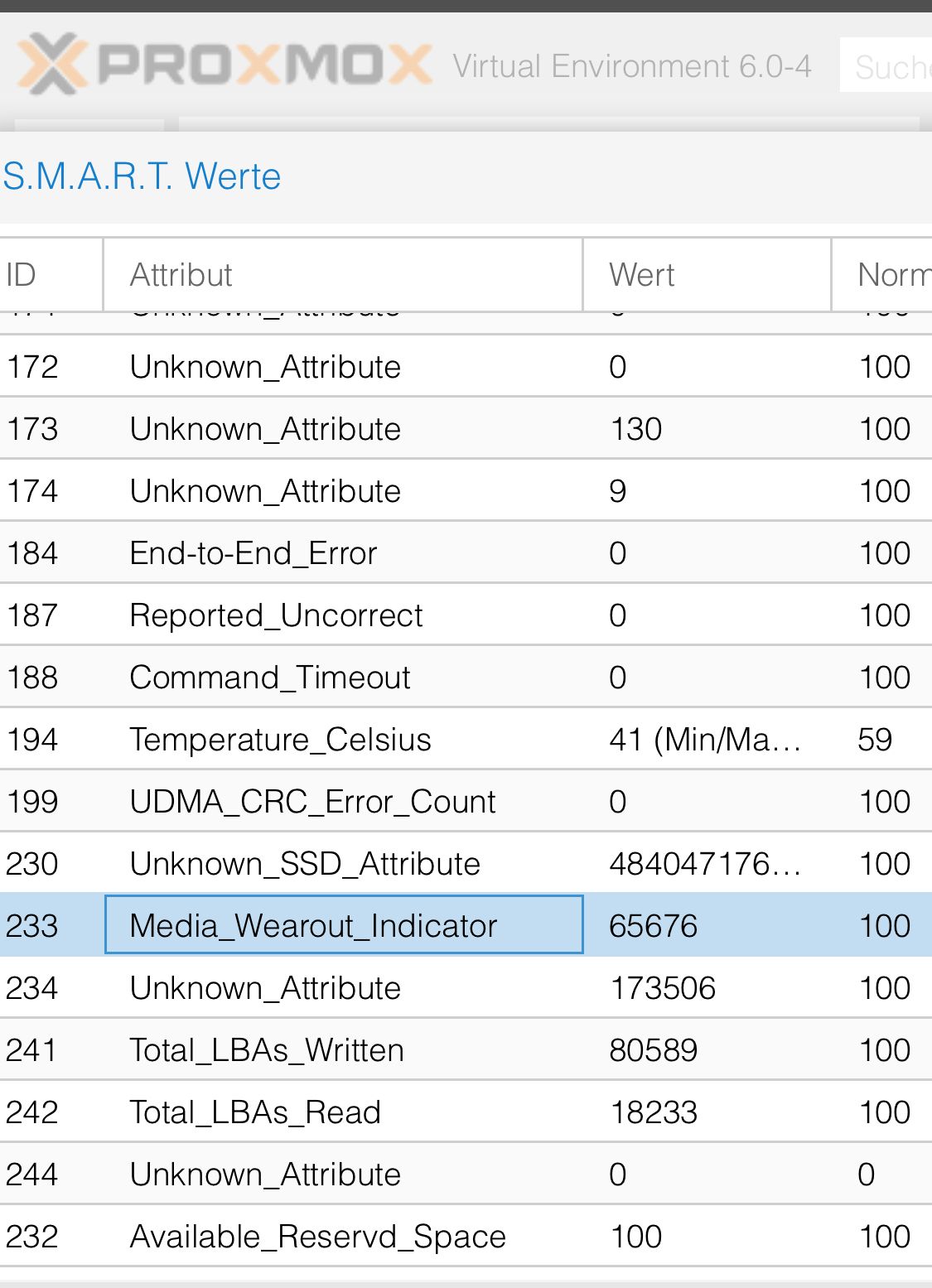
Ich muss dazu sagen das die SSD noch relativ neu ist (ca. 1 Jahr). Was habt den ihr für welche Werte?
-
@saeft_2003 sagte in ioBroker sehr hohe Diskwrites in Proxmox:
In proxmox unter PVE --> Disks siehe ich meine SSD dort steht ein wearout von 0% (was schon mal gut sein sollte)
Ist das nicht eher das Gegenteil?
Je kleiner der Wert desto schlechter der Zustand