

iobroker hochverfügbar
-
Ich habe mit ewas HM angeht entschieden ncht selbst zu basteln (also Debmatic und wie es alles heisst) sondern echt die CCU Hardware zu nutzen. Updates macht man das wenn nötig über die Firmware und so. Die CCU als "Hardwarekomponente" ist aktuell noch nie ausgefallen und ich kann es nicht kaputtspielen :-)
-
was hab ich Tage damit verbracht.. aber wenns einmal läuft musst du du dich mit dem Ausfall beschäftigen falls das cluster mal nicht will... und so lernt man immer was dazu..
ich habs so wie apollon.. nur mit 5 nucs.. das ganze auch im Haus verteilt an einzelnen USV's.. um beruhig in den Urlaub zu fahren.
der Spass beginnt wenn du eine Update Orgie startest.. mal eben so ist es nicht getan. da können Admins ein Lied von singen..
-
@darkiop sagte: HM Komponenten sind an das Funkmodul gebunden.
Das ist der Vorteil von HomeMatic (zumindest classic), dass sie nicht an das Funkmodul, sondern an die CCU gebunden sind, also nicht wissen, wenn eine andere CCU (mit gleicher ID) übernimmt. Es kann natürlich immer nur eine CCU "funken".
@paul53 sagte in iobroker hochverfügbar:
@darkiop sagte: HM Komponenten sind an das Funkmodul gebunden.
Das ist der Vorteil von HomeMatic (zumindest classic), dass sie nicht an das Funkmodul, sondern an die CCU gebunden sind, also nicht wissen, wenn eine andere CCU (mit gleicher ID) übernimmt. Es kann natürlich immer nur eine CCU "funken".
Ok, dann hatte ich das in meinem Kopf irgendwann mal falsch abgespeichert - dann bleibt nur die Frage ob das auch so bei HM IP ist. @Homoran kannst du dazu etwas sagen?
Proxmox-ioBroker-Redis-HA Doku: https://forum.iobroker.net/topic/47478/dokumentation-einer-proxmox-iobroker-redis-ha-umgebung
-
@oliverio sagte in iobroker hochverfügbar:
Was ist mit der 2. Stromschiene eines 2. Stromanbieters? :)
PV aufm Dach + Irgendwann ein Auto im Hof das als Puffer dient :D
-
@darkiop sagte in iobroker hochverfügbar:
Du hast aber auch das ganze HA Zegs über die eine LAN-Schnittstelle des NUC laufen? Idealerweise sollte man das ja trennen ...
Ja habe alles über die eine LAN Schnittstelle, aber alles dann mit der Zeit auf 10G in der Verteilung hochgezogen. Also Faktisch kann damit jetzt wirklich jeder Nuc seine 1G ziehen und weder der Switch noch die Hauptverteilung limitiert das dann. Sonst müsste man ja ganz andere Hardware nutzen, weil auch mit Nuc und dann per USB ne zweite NIC bereitstellen hat wieder andere Probleme.
@apollon77 sagte in iobroker hochverfügbar:
@darkiop sagte in iobroker hochverfügbar:
Du hast aber auch das ganze HA Zegs über die eine LAN-Schnittstelle des NUC laufen? Idealerweise sollte man das ja trennen ...
Ja habe alles über die eine LAN Schnittstelle, aber alles dann mit der Zeit auf 10G in der Verteilung hochgezogen. Also Faktisch kann damit jetzt wirklich jeder Nuc seine 1G ziehen und weder der Switch noch die Hauptverteilung limitiert das dann. Sonst müsste man ja ganz andere Hardware nutzen, weil auch mit Nuc und dann per USB ne zweite NIC bereitstellen hat wieder andere Probleme.
Ok, 10G hab ich auch aufm Schirm - allerdings, da ich im Unifi Universum bleiben möchte bisher noch nicht realisiert, Kosten für den Switch kommen auf 500-600€ - da muss dann auch der Usecase passen. Ggf. dann irgendwann mal, wenn HA ausgeprägter bei mir ist.
Wie hast du denn den NUCs 10Gb verpasst? Die können doch nur 1Gb. Per USB-C/Thunderbolt Adapter?
@apollon77 sagte in iobroker hochverfügbar:
Ich habe mit ewas HM angeht entschieden ncht selbst zu basteln (also Debmatic und wie es alles heisst) sondern echt die CCU Hardware zu nutzen. Updates macht man das wenn nötig über die Firmware und so. Die CCU als "Hardwarekomponente" ist aktuell noch nie ausgefallen und ich kann es nicht kaputtspielen :-)
Verstehe, ich hab die CCU bei mir in eine VM gezogen um den Raspi einzusparen und die "Sicherheit" (Backups, Snapshots) von Proxmox zu haben. Angebunden sind die aktuell über HB-RF-USB-2 mit HM-MOD-RPI-PCB und lauft komplett unauffällig.
Proxmox-ioBroker-Redis-HA Doku: https://forum.iobroker.net/topic/47478/dokumentation-einer-proxmox-iobroker-redis-ha-umgebung
-
was hab ich Tage damit verbracht.. aber wenns einmal läuft musst du du dich mit dem Ausfall beschäftigen falls das cluster mal nicht will... und so lernt man immer was dazu..
ich habs so wie apollon.. nur mit 5 nucs.. das ganze auch im Haus verteilt an einzelnen USV's.. um beruhig in den Urlaub zu fahren.
der Spass beginnt wenn du eine Update Orgie startest.. mal eben so ist es nicht getan. da können Admins ein Lied von singen..
@arteck sagte in iobroker hochverfügbar:
was hab ich Tage damit verbracht.. aber wenns einmal läuft musst du du dich mit dem Ausfall beschäftigen falls das cluster mal nicht will... und so lernt man immer was dazu..
ich habs so wie apollon.. nur mit 5 nucs.. das ganze auch im Haus verteilt an einzelnen USV's.. um beruhig in den Urlaub zu fahren.
Ich muss mir mal Gedanken und einen Plan machen was die nächsten Schritte sind. Und so Sinnvoll ein Schritt nach dem andern gehen :D Das Thema USV schiebe ich auch schon ewig im Kopf rum und vergesse es immer wieder :D Was habt ihr denn für Welche im Einsatz?
der Spass beginnt wenn du eine Update Orgie startest.. mal eben so ist es nicht getan. da können Admins ein Lied von singen..
Das ist es ja jetzt schon, bei >10 LXCs/VMs + diversen anderen Geräten. Aus diesem Grund hab ich letzte Woche in einigen LXCs/VMs unattended-upgrades aktiviert. Ich hatte eigentlich noch nicht Probleme nach einem Update - solange man vorher nicht komplett sein System verwurschtelt hatte :) Mal schauen wann ich die ersten negativen Erfahrungen damit mache :D
Proxmox-ioBroker-Redis-HA Doku: https://forum.iobroker.net/topic/47478/dokumentation-einer-proxmox-iobroker-redis-ha-umgebung
-
@paul53 sagte in iobroker hochverfügbar:
@darkiop sagte: HM Komponenten sind an das Funkmodul gebunden.
Das ist der Vorteil von HomeMatic (zumindest classic), dass sie nicht an das Funkmodul, sondern an die CCU gebunden sind, also nicht wissen, wenn eine andere CCU (mit gleicher ID) übernimmt. Es kann natürlich immer nur eine CCU "funken".
Ok, dann hatte ich das in meinem Kopf irgendwann mal falsch abgespeichert - dann bleibt nur die Frage ob das auch so bei HM IP ist. @Homoran kannst du dazu etwas sagen?
@darkiop sagte in iobroker hochverfügbar:
dann bleibt nur die Frage ob das auch so bei HM IP ist. @Homoran kannst du dazu etwas sagen?
müsste, da IMHO funkmodultechnisch diesbezüglich kein Unterschied besteht.
@darkiop sagte in iobroker hochverfügbar:
Irgendwann ein Auto im Hof das als Puffer dient
V2Home ist in D leider noch nicht zulässig.
du könntest ja kostenlos bei ikea laden und dann einspeisen.Batterie mi USV-Funktion wäre ja auch schon was
kein Support per PN! - Fragen im Forum stellen - Benutzt das Voting rechts unten im Beitrag wenn er euch geholfen hat.
Das Forum freut sich über eine Spende. Benutzt dazu den Spendenbutton oben rechts. Danke!
der Installationsfixer: curl -fsL https://iobroker.net/fix.sh | bash - -
@darkiop sagte in iobroker hochverfügbar:
dann bleibt nur die Frage ob das auch so bei HM IP ist. @Homoran kannst du dazu etwas sagen?
müsste, da IMHO funkmodultechnisch diesbezüglich kein Unterschied besteht.
@darkiop sagte in iobroker hochverfügbar:
Irgendwann ein Auto im Hof das als Puffer dient
V2Home ist in D leider noch nicht zulässig.
du könntest ja kostenlos bei ikea laden und dann einspeisen.Batterie mi USV-Funktion wäre ja auch schon was
@homoran sagte in iobroker hochverfügbar:
@darkiop sagte in iobroker hochverfügbar:
dann bleibt nur die Frage ob das auch so bei HM IP ist. @Homoran kannst du dazu etwas sagen?
müsste, da IMHO funkmodultechnisch diesbezüglich kein Unterschied besteht.
Ok, gehe Ich auch davon aus ...
@darkiop sagte in iobroker hochverfügbar:
Irgendwann ein Auto im Hof das als Puffer dient
V2Home ist in D leider noch nicht zulässig.
du könntest ja kostenlos bei ikea laden und dann einspeisen.Ja, Zukunftsmusik - aber spannend :)
Solange halte ich es im Ikea nicht aus das sich das lohnen könnte :D
Batterie mi USV-Funktion wäre ja auch schon was
Ja, aber die müssen auch erstmal bezahlbar/rentabel werden - das ist aktuell noch nicht wirklich interessant.
-
@apollon77 sagte in iobroker hochverfügbar:
@darkiop sagte in iobroker hochverfügbar:
Du hast aber auch das ganze HA Zegs über die eine LAN-Schnittstelle des NUC laufen? Idealerweise sollte man das ja trennen ...
Ja habe alles über die eine LAN Schnittstelle, aber alles dann mit der Zeit auf 10G in der Verteilung hochgezogen. Also Faktisch kann damit jetzt wirklich jeder Nuc seine 1G ziehen und weder der Switch noch die Hauptverteilung limitiert das dann. Sonst müsste man ja ganz andere Hardware nutzen, weil auch mit Nuc und dann per USB ne zweite NIC bereitstellen hat wieder andere Probleme.
Ok, 10G hab ich auch aufm Schirm - allerdings, da ich im Unifi Universum bleiben möchte bisher noch nicht realisiert, Kosten für den Switch kommen auf 500-600€ - da muss dann auch der Usecase passen. Ggf. dann irgendwann mal, wenn HA ausgeprägter bei mir ist.
Wie hast du denn den NUCs 10Gb verpasst? Die können doch nur 1Gb. Per USB-C/Thunderbolt Adapter?
@apollon77 sagte in iobroker hochverfügbar:
Ich habe mit ewas HM angeht entschieden ncht selbst zu basteln (also Debmatic und wie es alles heisst) sondern echt die CCU Hardware zu nutzen. Updates macht man das wenn nötig über die Firmware und so. Die CCU als "Hardwarekomponente" ist aktuell noch nie ausgefallen und ich kann es nicht kaputtspielen :-)
Verstehe, ich hab die CCU bei mir in eine VM gezogen um den Raspi einzusparen und die "Sicherheit" (Backups, Snapshots) von Proxmox zu haben. Angebunden sind die aktuell über HB-RF-USB-2 mit HM-MOD-RPI-PCB und lauft komplett unauffällig.
@darkiop sagte in iobroker hochverfügbar:
Wie hast du denn den NUCs 10Gb verpasst? Die können doch nur 1Gb. Per USB-C/Thunderbolt Adapter?
Nee gar nicht. Die haben weiter je 1gb. Wenn aber der semwitxh dann in Richtung Hausverteilung auch nur 1gb kann dann kann es eng werden wenn mehrere 1gb Geräte an dem Switch in Summe mehr als 1gb „reden“ wollen zu hosts woanders im Haus. Daher können meine lokalen switche hin zur hausverteilung und dort der hauptswitch 10g auf einigen Ports. Damit istvder bottleneck „Verteilung raus“ und jeder nuc kann ggf seine 1gb voll ausnutzen.
Am Ende wenn du pro Host einen glusterfs brick hast ist das alles noch easy. Meine bricks sind anders verteilt und daher mehr und da wird es ggf eng wenn die mal alle Daten syncen wollen ;-)
-
@darkiop sagte in iobroker hochverfügbar:
Wie hast du denn den NUCs 10Gb verpasst? Die können doch nur 1Gb. Per USB-C/Thunderbolt Adapter?
Nee gar nicht. Die haben weiter je 1gb. Wenn aber der semwitxh dann in Richtung Hausverteilung auch nur 1gb kann dann kann es eng werden wenn mehrere 1gb Geräte an dem Switch in Summe mehr als 1gb „reden“ wollen zu hosts woanders im Haus. Daher können meine lokalen switche hin zur hausverteilung und dort der hauptswitch 10g auf einigen Ports. Damit istvder bottleneck „Verteilung raus“ und jeder nuc kann ggf seine 1gb voll ausnutzen.
Am Ende wenn du pro Host einen glusterfs brick hast ist das alles noch easy. Meine bricks sind anders verteilt und daher mehr und da wird es ggf eng wenn die mal alle Daten syncen wollen ;-)
@apollon77 sagte in iobroker hochverfügbar:
jeder nuc kann ggf seine 1gb voll ausnutze
Ok. Müsste mal schauen was meine Unifi Switchtes auf der Backplane liefern - sollte aber mehr als 1Gb sein. Die Dream Machine Pro ist allerdings beschnitten auf 1Gb.
@apollon77 sagte in iobroker hochverfügbar:
Am Ende wenn du pro Host einen glusterfs brick hast ist das alles noch easy. Meine bricks sind anders verteilt und daher mehr und da wird es ggf eng wenn die mal alle Daten syncen wollen
Ich versuche mich mal dran, komme sicher mit der ein oder anderen Frage auf dich zurück :)
Proxmox-ioBroker-Redis-HA Doku: https://forum.iobroker.net/topic/47478/dokumentation-einer-proxmox-iobroker-redis-ha-umgebung
-
@darkiop sagte in iobroker hochverfügbar:
dann bleibt nur die Frage ob das auch so bei HM IP ist. @Homoran kannst du dazu etwas sagen?
müsste, da IMHO funkmodultechnisch diesbezüglich kein Unterschied besteht.
@darkiop sagte in iobroker hochverfügbar:
Irgendwann ein Auto im Hof das als Puffer dient
V2Home ist in D leider noch nicht zulässig.
du könntest ja kostenlos bei ikea laden und dann einspeisen.Batterie mi USV-Funktion wäre ja auch schon was
-
@paul53 sagte in iobroker hochverfügbar:
@homoran sagte: da IMHO funkmodultechnisch diesbezüglich kein Unterschied besteht.
Bis auf das Rekeying über das Internet, was mich stören würde
stimmt! das dauert etwas.
hatte ich nicht auf dem Schirmkein Support per PN! - Fragen im Forum stellen - Benutzt das Voting rechts unten im Beitrag wenn er euch geholfen hat.
Das Forum freut sich über eine Spende. Benutzt dazu den Spendenbutton oben rechts. Danke!
der Installationsfixer: curl -fsL https://iobroker.net/fix.sh | bash - -
@paul53 sagte in iobroker hochverfügbar:
@homoran sagte: da IMHO funkmodultechnisch diesbezüglich kein Unterschied besteht.
Bis auf das Rekeying über das Internet, was mich stören würde
stimmt! das dauert etwas.
hatte ich nicht auf dem Schirm -
@apollon77 sagte in iobroker hochverfügbar:
jeder nuc kann ggf seine 1gb voll ausnutze
Ok. Müsste mal schauen was meine Unifi Switchtes auf der Backplane liefern - sollte aber mehr als 1Gb sein. Die Dream Machine Pro ist allerdings beschnitten auf 1Gb.
@apollon77 sagte in iobroker hochverfügbar:
Am Ende wenn du pro Host einen glusterfs brick hast ist das alles noch easy. Meine bricks sind anders verteilt und daher mehr und da wird es ggf eng wenn die mal alle Daten syncen wollen
Ich versuche mich mal dran, komme sicher mit der ein oder anderen Frage auf dich zurück :)
-
@apollon77 sagte: Das sind aber die Limitierungen mit denen man leben muss denke ich
Was nutzt die Hochverfügbarkeit von ioBroker, wenn wichtige Geräte nicht mehr gesteuert werden können?
@paul53 sagte in iobroker hochverfügbar:
Was nutzt die Hochverfügbarkeit von ioBroker, wenn wichtige Geräte nicht mehr gesteuert werden können?
Das ist Salamitaktik, wie beim Testen. Wenn vollständig nicht geht, dann macht man das was geht. Besser als nicht starten.
Leider gibt es tatsächlich Quertreiber wie Zigbee, wo der Koordinator seine Schäfchen an sich bindet und ein Ersatz nicht vorgesehen ist.
Aber mit einem redundanten ioBroker hätte man zumindest Funktion während der Updates. Seit bei mir das gesamte Wohnungslicht über Zigbee und ioBroker läuft, bin ich da (noch) sensibler geworden.Aber zumindest habe ich bisher die Abhängigkeiten von USB für die Interfaces eliminiert. Smartmeter, RFLink und Zigbee laufen über TCP und können daher von verschiedenen Rechnern aus parallel angesprochen werden.
-
@darkiop wenn alles am gleichen Switch hängt ist ja erstmal easy mit Netzwerk. Die backplane hat meistens ne viel höhere Leistung. Dann user nur dein Switch halt auch ein SPOF :-)
@apollon77 sagte in iobroker hochverfügbar:
@darkiop wenn alles am gleichen Switch hängt ist ja erstmal easy mit Netzwerk. Die backplane hat meistens ne viel höhere Leistung. Dann user nur dein Switch halt auch ein SPOF :-)
Ja - das ist klar - aber das Risiko gehe ich erstmal ein.
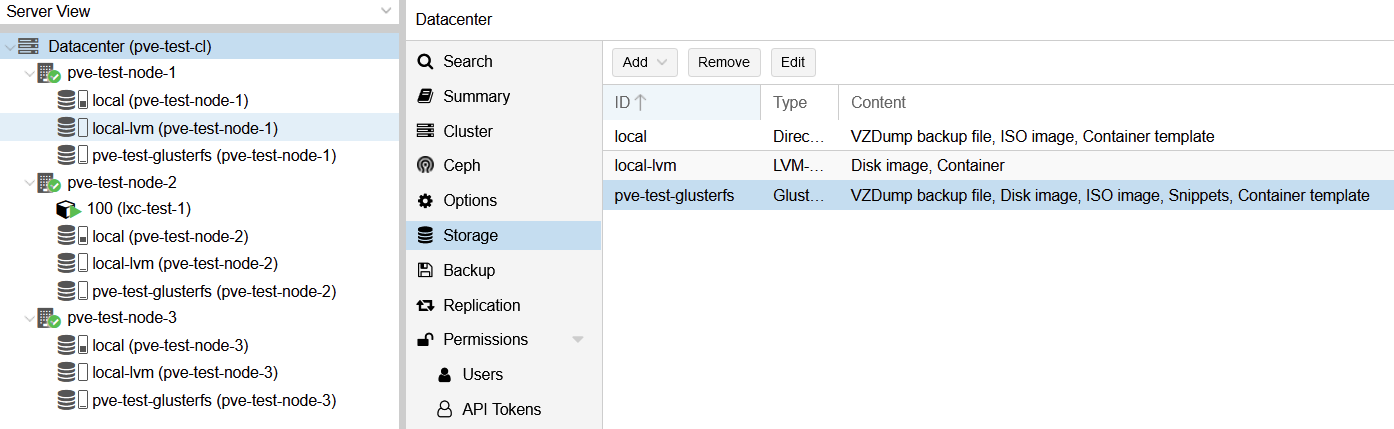
Hab heut Morgen mit meinen 3 VMs mal mit GlusterFS gespielt, installation + config liefen ohne größere hürden. Doku im Anhang.
Aber eine Frage: GlusterFS kann nicht mit LXCs umgehen? Hast du das bei dir gelöst? Wenn ja, wie? :D
https://forum.proxmox.com/threads/container-on-gluster-volume-not-possible.40889/
Proxmox-ioBroker-Redis-HA Doku: https://forum.iobroker.net/topic/47478/dokumentation-einer-proxmox-iobroker-redis-ha-umgebung
-
@apollon77 sagte in iobroker hochverfügbar:
@darkiop wenn alles am gleichen Switch hängt ist ja erstmal easy mit Netzwerk. Die backplane hat meistens ne viel höhere Leistung. Dann user nur dein Switch halt auch ein SPOF :-)
Ja - das ist klar - aber das Risiko gehe ich erstmal ein.
Hab heut Morgen mit meinen 3 VMs mal mit GlusterFS gespielt, installation + config liefen ohne größere hürden. Doku im Anhang.
Aber eine Frage: GlusterFS kann nicht mit LXCs umgehen? Hast du das bei dir gelöst? Wenn ja, wie? :D
https://forum.proxmox.com/threads/container-on-gluster-volume-not-possible.40889/
@darkiop antworte ich dir heute Abend. Da muss ich an en Laptop. Da muss man bissl Tricksen. Und ja mir lxc soll es Performance technisch nicht ideal sein. Ich hatte bisher keine issues damit.
Die drei vms sind jetzt bei dir nicht HA sondern eine vm pro node fest. Gell? Mit Autostart on Boot? Dann könnte das vllt gehen.
Heißt du startest die vms mit dem proxmox node ind definierest das dann als glusterfs Host? Coole Idee. -
@apollon77 sagte in iobroker hochverfügbar:
@darkiop wenn alles am gleichen Switch hängt ist ja erstmal easy mit Netzwerk. Die backplane hat meistens ne viel höhere Leistung. Dann user nur dein Switch halt auch ein SPOF :-)
Ja - das ist klar - aber das Risiko gehe ich erstmal ein.
Hab heut Morgen mit meinen 3 VMs mal mit GlusterFS gespielt, installation + config liefen ohne größere hürden. Doku im Anhang.
Aber eine Frage: GlusterFS kann nicht mit LXCs umgehen? Hast du das bei dir gelöst? Wenn ja, wie? :D
https://forum.proxmox.com/threads/container-on-gluster-volume-not-possible.40889/
@darkiop zur Anleitung ein Feedback: du kann’s es gleich mit replica 3 anlegen. Also muss kein „erst zwei dann Rest“ machen
Aber mach mal noch keine Daten rein!!!! Du brauchst für vm Hosting ein paar spezielle Einstellungen!! Die kannst du mit Daten drin nicht gescheit setzen.
-
@darkiop antworte ich dir heute Abend. Da muss ich an en Laptop. Da muss man bissl Tricksen. Und ja mir lxc soll es Performance technisch nicht ideal sein. Ich hatte bisher keine issues damit.
Die drei vms sind jetzt bei dir nicht HA sondern eine vm pro node fest. Gell? Mit Autostart on Boot? Dann könnte das vllt gehen.
Heißt du startest die vms mit dem proxmox node ind definierest das dann als glusterfs Host? Coole Idee.@apollon77 sagte in iobroker hochverfügbar:
@darkiop antworte ich dir heute Abend. Da muss ich an en Laptop. Da muss man bissl Tricksen. Und ja mir lxc soll es Performance technisch nicht ideal sein. Ich hatte bisher keine issues damit.
Ok, eilt nicht - auch frühestens heut spät Abend wieder schauen. Performance sollte für zuhause vermutlich trotzdem passen.
Die drei vms sind jetzt bei dir nicht HA sondern eine vm pro node fest. Gell? Mit Autostart on Boot? Dann könnte das vllt gehen.
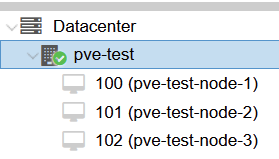
Heißt du startest die vms mit dem proxmox node ind definierest das dann als glusterfs Host? Coole Idee.Die 3 Nodes auf dem Screen sind die 3 VMs mit Proxmox. Innerhalb dieser teste ich dann GlusterFS und Co. Auf pve-test ist Proxmox direkt aufm Blech installiert :)
@apollon77 sagte in iobroker hochverfügbar:
@darkiop zur Anleitung ein Feedback: du kann’s es gleich mit replica 3 anlegen. Also muss kein „erst zwei dann Rest“ machen
Musste grad eh alles zurücksetzen, teste ich dann beim nächsten mal :)
Aber mach mal noch keine Daten rein!!!! Du brauchst für vm Hosting ein paar spezielle Einstellungen!! Die kannst du mit Daten drin nicht gescheit setzen.
Ok :)
-
Ahhh ok hast also IN den VMs auch proxmox und testet da nen proxmox cluser ... auch ne Idee :-)
Also dann ... (kam doch kurz dazu)
- nach aufsetzen des glusterfs volumes noch ein
gluster volume set <VOLNAME> group virtmachen. Das setzt einige Settings sodass sie besser für vms und grössere mages geeignet sind. - prüfen dann mit
gluster volume infoMindestens "features.shard=on" sollte dabei sein ... dann hats geklappt. Sharding heisst das er die echten Files in Chunks von zB nur 64MB aufteilt ... geht dann beim "healing" schneller. Was die anderen Settings alle bedeuten -> https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.1/html/administration_guide/chap-managing_red_hat_storage_volumes#Configuring_Volume_Options - Erst dann Daten reinkopieren
Dann empfehle ich "gstatus" als "Monitoring Tool"
- Install: https://github.com/gluster/gstatus#install
- Aufruf überblick nur
gstatus... detailliert `gstatus -a -b´ - Sobald du irgendwas gemacht hast wie updates oder so danach da rein schauen. Vor allem schauen ob Files ein healing machen oder brauchen!
- GlusterFS low level befehl für details
gluster volume status <VOLNAME> detail... so zum merken Da sieht man bei heals noch mehr.
Welche Glusterfs Version hast Du jetzt drauf? Bei proxmox dabei ist ne recht alte. Aktuell ist 9.x ... ich bin auf 8.x ...
-
Vorher Changelog checken! (https://docs.gluster.org/en/latest/release-notes/8.4/)
-
Upgrade Log checken (https://docs.gluster.org/en/latest/Upgrade-Guide/upgrade_to_8/)
-
Proxmox update instructions:
wget -O - https://download.gluster.org/pub/gluster/glusterfs/8/rsa.pub | apt-key add - vi /etc/apt/sources.list.d/gluster.list --> 8 einstellen bzw falls es fehlt halt nochanlegen gluster volume info apt-get update systemctl stop glusterd && systemctl stop glustereventsd && killall glusterfs glusterfsd glusterd glustereventsd apt-get dist-upgrade gluster --version rebootImmer den Proxmx Host nach Update rebooten!
LXC über Proxmox:
- Du hast im proxmox den storage angelegt. Damit mounted proxmox das beim start. mit
mountsiehst Du alles was gerade gemounted ist. Da müsste etwas sein wie "<IP>:<VOLNAME> on /mnt/pve/glusterfs type fuse.glusterfs" - Das jetzt equivalent im /etc/fstab reinschreiben als "<IP>:<VOLNAME> /mnt/pve/glusterfs glusterfs defaults,_netdev 0 0". Wichtig ist das /mnt/pve/glusterfs (oder wie auch immer es bei dir heisst). Merken!!
- achja: Wenn glusterfs lokal ist und auf allen nodes dann am besten in der proxmox konfig einfach "localhost" bei der IP angeben, dann regelt glusterfs das ganze mit connection ... und wenn localhost nicht da ist ist was anderes kaputt.
- In Proxmox dann einen "Directory Storage" anlegen und den lässt Du auf das Glusterfx Mount directory zeigen. in storage.cfg sieht das dann so aus (Mount Dir halt anpassen)
dir: glusterfs-container path /mnt/pve/glusterfs content rootdir is_mountpoint yes shared 1Auf dem Kannst Du dann die Container Images ablegen :-)
Ganz wichtig noch ab glusterfs 8:
systemctl status glusterfssharedstorage.service... wenn es das gibt ... deaktivieren!systemctl disable glusterfssharedstorage.servicesystemctl stop glusterfssharedstorage.servicereboot
Das Funkt sonst beim Reboot dazwischen und unmounted die Directory zu früh wo die LXC noch laufen und dann wird es blöd.
Wenn Du jetzt VMs oder Container auf dem glusterfs hast dann mal starten und mal geflaggt als "HA" oder ohne testen das sie beim Booten sauber automatisch hochkommen und beim reboot sauber beendet werden bevor das glusterfs weg ist. Da hab ich einiges rumgemacht mit.
Am besten /var/log/syslog checken nach bem Reboot das da keine Filesystem fehler angezeigt werden. Beim Boot kann es sein das Proxmox mal sagt "ohh mount noch nicht fertig ... muss noch kurz warten" bevor es die LXC startet. Das ist ok und sollte sich dann paar Sekunden später von selbst geben.Offtopic: Proxmox Cluster: Wenn Du NUCs hast dann nutze den Hardware Watchdog!
In /etc/default/pve-ha-manager WATCHDOG_MODULE=iTCO_wdtDann Reboot und im /var/log/syslog suchen nach wdt um zu schauen obs geklappt hat
Dann viel Spass beim experimentieren und wäre cool am Ende eine Anleitung zu haben :-))
- nach aufsetzen des glusterfs volumes noch ein
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
427
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge