

Website mit Parser auslesen
-
@dr-bakterius Vielen Dank für die rasende Antwort, bekomme aber nach wie vor einen 403 Fehler. Heißt das, dass es von der Seite geschützt ist?
@legerm wie sieht denn der Seitenquelltext aus?
kein Support per PN! - Fragen im Forum stellen -
Benutzt das Voting rechts unten im Beitrag wenn er euch geholfen hat.
Das Forum freut sich über eine Spende. Benutzt dazu den Spendenbutton oben rechts. Danke!
der Installationsfixer: curl -fsL https://iobroker.net/fix.sh | bash - -
@homoran sagte in Website mit Parser auslesen:
@legerm wie sieht denn der Seitenquelltext aus?
bei 403 kommt ja nix mit. da kommt nur der http header
Meine Adapter und Widgets
TVProgram, SqueezeboxRPC, OpenLiga, RSSFeed, MyTime,, pi-hole2, vis-json-template, skiinfo, vis-mapwidgets, vis-2-widgets-rssfeed
Links im Profil -
@homoran sagte in Website mit Parser auslesen:
@legerm wie sieht denn der Seitenquelltext aus?
bei 403 kommt ja nix mit. da kommt nur der http header
-
@homoran sagte in Website mit Parser auslesen:
@legerm wie sieht denn der Seitenquelltext aus?
bei 403 kommt ja nix mit. da kommt nur der http header
@oliverio sagte in Website mit Parser auslesen:
@homoran sagte in Website mit Parser auslesen:
@legerm wie sieht denn der Seitenquelltext aus?
bei 403 kommt ja nix mit. da kommt nur der http header
klar, aber ich kann mobil nur mitspielen wenn hier jemand den am PC gewonnenen Seitenquelltext postet.
kein Support per PN! - Fragen im Forum stellen -
Benutzt das Voting rechts unten im Beitrag wenn er euch geholfen hat.
Das Forum freut sich über eine Spende. Benutzt dazu den Spendenbutton oben rechts. Danke!
der Installationsfixer: curl -fsL https://iobroker.net/fix.sh | bash - -
@oliverio sagte in Website mit Parser auslesen:
@homoran sagte in Website mit Parser auslesen:
@legerm wie sieht denn der Seitenquelltext aus?
bei 403 kommt ja nix mit. da kommt nur der http header
klar, aber ich kann mobil nur mitspielen wenn hier jemand den am PC gewonnenen Seitenquelltext postet.
kein problem
aber am quelltext liegt es nicht.
der seitenbetreiber kann sehr gut zwischen browser und anderem abruf unterscheiden.
als antwort kommt immer 403, was forbidden entspricht. selbst wenn ich den original fetch aus dem browser ausführe.
vergleich des fetchs zwischen 2 funktionierende browser abfragen haben kein unterschied feststellen können.andere scheinen kein problem zu haben
da mehr wie 10000 zeichen hier als datei
europapark.txtMeine Adapter und Widgets
TVProgram, SqueezeboxRPC, OpenLiga, RSSFeed, MyTime,, pi-hole2, vis-json-template, skiinfo, vis-mapwidgets, vis-2-widgets-rssfeed
Links im Profil -
kein problem
aber am quelltext liegt es nicht.
der seitenbetreiber kann sehr gut zwischen browser und anderem abruf unterscheiden.
als antwort kommt immer 403, was forbidden entspricht. selbst wenn ich den original fetch aus dem browser ausführe.
vergleich des fetchs zwischen 2 funktionierende browser abfragen haben kein unterschied feststellen können.andere scheinen kein problem zu haben
da mehr wie 10000 zeichen hier als datei
europapark.txt@oliverio sagte in Website mit Parser auslesen:
aber am quelltext liegt es nicht.
der seitenbetreiber kann sehr gut zwischen browser und anderem abruf unterscheiden.
als antwort kommt immer 403, was forbidden entspricht. selbst wenn ich den original fetch aus dem browser ausführe.Hmm, ich kann mir das eigentlich nicht vorstellen.
Den Parser-Adapter habe ich quasi mit den Standard-Einstellungen laufen lassen, und kriege Antworten ...
Vielleicht macht die Seite "Dicht", wenn es zu viele Anfragen von einem Client gibt ...
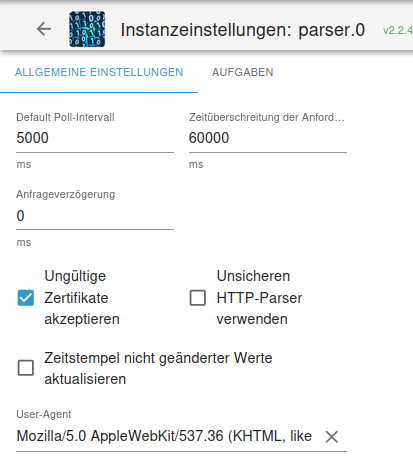
Für diesen Anwendungsfall sind sicher auch deutlich mehr als 5 Sekunden Abfrageintervall völlig ausreichend...
Vielleicht eine "faule" Parser-Instanz einrichten, die nur alle 10 Minuten schaut ...Hier der Beginn des Outputs, wenn man sie ohne weiteren Parameter mit curl saugt:
martin@martin-D2836-S1:~$ curl https://www.wartezeiten.app/europapark/ <!DOCTYPE html><html lang="en-US"><head><title>Just a moment...</title><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=Edge"><meta name="robots" content="noindex,nofollow"><meta name="viewport" content="width=device-width,initial-scale=1"><style>*{box-sizing:border-box;margin:0;padding:0}html{line-height:1.15;-webkit-text-size-adjust:100%;color:#313131;font-family:system-ui,-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,"Helvetica Neue",Arial,"Noto Sans",sans-serif .... -
kein problem
aber am quelltext liegt es nicht.
der seitenbetreiber kann sehr gut zwischen browser und anderem abruf unterscheiden.
als antwort kommt immer 403, was forbidden entspricht. selbst wenn ich den original fetch aus dem browser ausführe.
vergleich des fetchs zwischen 2 funktionierende browser abfragen haben kein unterschied feststellen können.andere scheinen kein problem zu haben
da mehr wie 10000 zeichen hier als datei
europapark.txt@oliverio sagte in Website mit Parser auslesen:
aber am quelltext liegt es nicht.
Natürlich nicht!
aber ohne quelltext komm ich nicht an einen (eigenen) Regex zum testen
Danke dafür, mein noch ungetester RegEx wäre
owd-Lev[^\d]+([\d,]+)Das Problem von number wird das Komma sein.
EDIT: hab auch die 403
kein Support per PN! - Fragen im Forum stellen -
Benutzt das Voting rechts unten im Beitrag wenn er euch geholfen hat.
Das Forum freut sich über eine Spende. Benutzt dazu den Spendenbutton oben rechts. Danke!
der Installationsfixer: curl -fsL https://iobroker.net/fix.sh | bash - -
@oliverio sagte in Website mit Parser auslesen:
aber am quelltext liegt es nicht.
Natürlich nicht!
aber ohne quelltext komm ich nicht an einen (eigenen) Regex zum testen
Danke dafür, mein noch ungetester RegEx wäre
owd-Lev[^\d]+([\d,]+)Das Problem von number wird das Komma sein.
EDIT: hab auch die 403
@homoran sagte in Website mit Parser auslesen:
Das Problem von number wird das Komma sein.
Korrekt. Wenn der Datenpunkt als number angelegt ist, kommt statt 15,7 als Ergebnis 157. Aber grundsätzlich hat es mit beidem funktioniert. Aber keine Ahnung warum es bei mir auf Anhieb geklappt hat, und beim TE nicht.
Der entscheidende Teil im Quelltext sieht bei mir so aus:
<span class="icon is-small" style="margin-right: 10px;"> <i class="fa fa-hourglass-half"></i> </span> Crowd-Level: 15,7 % - sehr gering <br /> -
@homoran sagte in Website mit Parser auslesen:
Das Problem von number wird das Komma sein.
Korrekt. Wenn der Datenpunkt als number angelegt ist, kommt statt 15,7 als Ergebnis 157. Aber grundsätzlich hat es mit beidem funktioniert. Aber keine Ahnung warum es bei mir auf Anhieb geklappt hat, und beim TE nicht.
Der entscheidende Teil im Quelltext sieht bei mir so aus:
<span class="icon is-small" style="margin-right: 10px;"> <i class="fa fa-hourglass-half"></i> </span> Crowd-Level: 15,7 % - sehr gering <br />@dr-bakterius
bei http error code 403 = forbidden, kommen erst gar keine daten
da kommt nur der http header zurück -
@dr-bakterius
bei http error code 403 = forbidden, kommen erst gar keine daten
da kommt nur der http header zurück -
@dr-bakterius
nein, wie oben geschrieben
im parser adapter und per skript adapter mit fetch -
@dr-bakterius
nein, wie oben geschrieben
im parser adapter und per skript adapter mit fetch@oliverio Tja, bei mir klappt es.
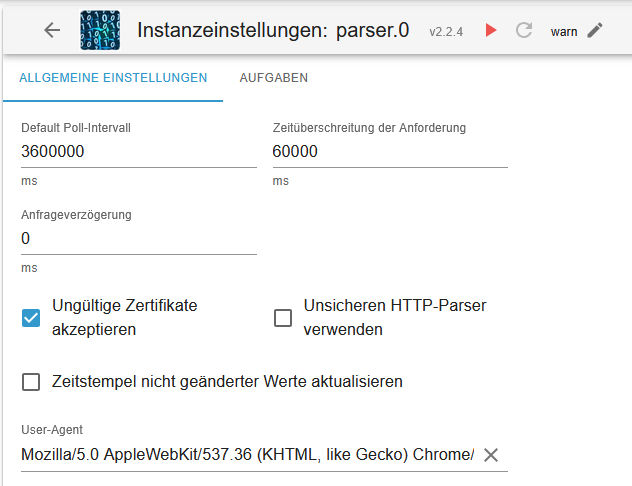
-
ich hab mal die Website im Browser aufgerufen
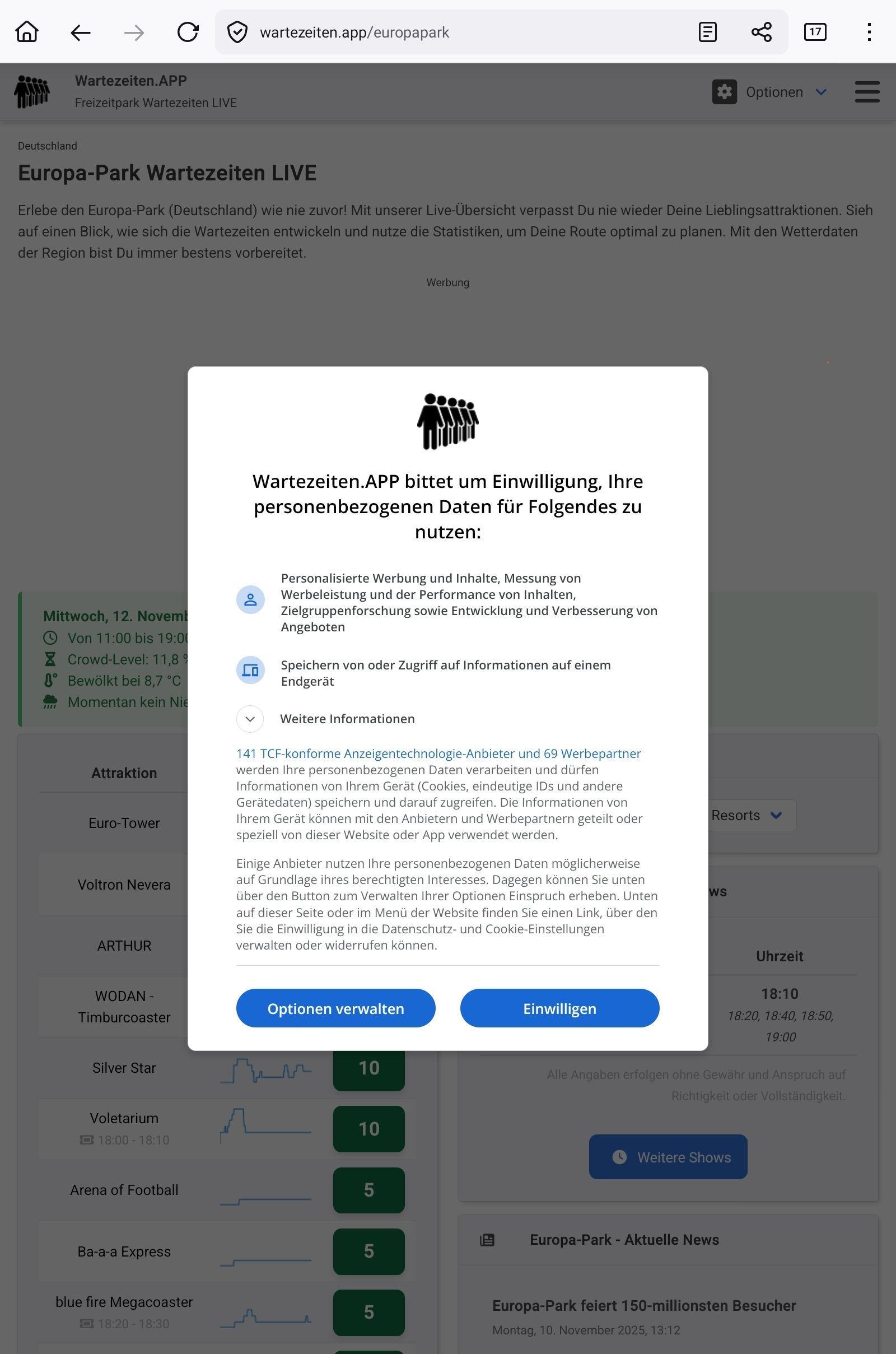
ohne Bestätigung kommst du ja gar nicht auf die Seite!
@homoran said in Website mit Parser auslesen:
ich hab mal die Website im Browser aufgerufen
ohne Bestätigung kommst du ja gar nicht auf die Seite!
Liegt es vielleicht daran?
-
@homoran said in Website mit Parser auslesen:
ich hab mal die Website im Browser aufgerufen
ohne Bestätigung kommst du ja gar nicht auf die Seite!
Liegt es vielleicht daran?
@legerm Durchaus möglich.
Wiederholt sich die Einwilligung-Abfrage wenn man sie einmal erteilt hat, wenn man die Seite erneut mit dem frisch neu gestarteten Browser aufruft?Vielleicht kann man den Cookie irgendwie in eine Curl-Anfrage mit einpacken, und den Parser dann auf die heruntergeladene Seite arbeiten lassen.
Ich habe die Cookie Einwilligung nicht, wenn ich die Seite im Browser aufrufe. Womöglich ist die gar nicht von der Seite selber, sondern von der eingeblendeten Werbung.
Vor der schützt mich PiHole... (Blaues Feld)BTW: Im roten Feld gibt es keine Stau-Infos, da außerhalb der Öffnungszeit ...
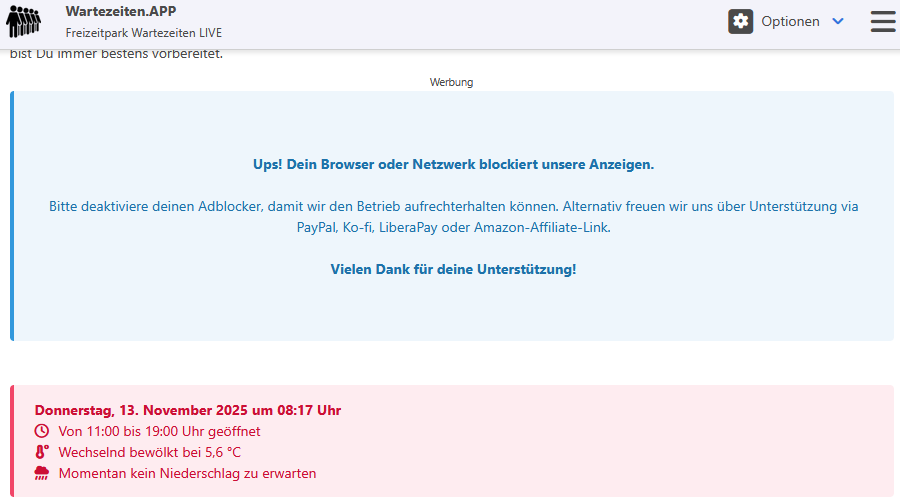
NACHTRAG: Mit Chrome kriege ich die Cookie-Abfrage beim ersten Aufruf - danach nicht mehr. Werbung wird eingeblendet.
-
@homoran said in Website mit Parser auslesen:
ich hab mal die Website im Browser aufgerufen
ohne Bestätigung kommst du ja gar nicht auf die Seite!
Liegt es vielleicht daran?
@legerm sagte in Website mit Parser auslesen:
Liegt es vielleicht daran?
Das glaube ich nicht. Im Hintergrund wird es ja angezeigt. Also steht es auch im Quellcode. Einzige Ausnahme: es handelt sich um ein Bild. Doch das ist eher unwahrscheinlich weil ja auch das aktuelle Datum angezeigt wird.
Was ich aber habe ist ein Pi Hole. Vielleicht liegt es daran.
-
@legerm sagte in Website mit Parser auslesen:
Liegt es vielleicht daran?
Das glaube ich nicht. Im Hintergrund wird es ja angezeigt. Also steht es auch im Quellcode. Einzige Ausnahme: es handelt sich um ein Bild. Doch das ist eher unwahrscheinlich weil ja auch das aktuelle Datum angezeigt wird.
Was ich aber habe ist ein Pi Hole. Vielleicht liegt es daran.
Habe mir Deinen - dankbarerweise formatierten - Seitenquelltext angeschaut... Was macht man denn hier für Schweinereien...?
(function() { 'use strict'; const configCheck1 = 'ukhZqPRxsYdCRaOVOSqx'; const configCheck2 = 'ZaPFFyEoIxocFaIgkRFv'; const configCheck3 = 'soBleRBitSfRPwnMlwkg'; function revealElements() { window.requestAnimationFrame(() => { [configCheck1, configCheck2, configCheck3].forEach(id => { const el = document.getElementById(id); if (el) { el.style.display = 'block'; } }); }); }Intel(R) Celeron(R) CPU N3000 @1.04GHz 8G RAM 480G SSD * Virtualization : unprivileged lxc container on Proxmox * 6 GByte RAM für den iobroker Container * Remote-Access über Wireguard meiner Fritzbox
-
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
-
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
@legerm Könnte an Anschluss-Typen liegen (DSLite, DualStack, IOv4 only), an zu vielen Anfragen, die Du gestellt hast (5000 ms sind vielleicht schon Bot-Verdächtig) oder an durch Bots "verbrannten" eigenen öffentlichen IP-Adressen ...
Kriegst Du denn mit curl die Seite heruntergeladen?
Wenn ja könntest Du sie ja per CRON-Job herunterladen (vielleicht nur alle 5...10 Minuten, damit es unverdächtig bleibt)
Der iobroker - Parser Adapter könnte dann auf die heruntergeladene Datei statt auf die URL schauen...
Wenn Curl per IPv4 nicht herunterladen kann, vielleicht auf IPv6 ausweichen, wenn an Deinem Anschluss verfügbar.
teste mal ...curl -6 https://www.wartezeiten.app/europapark/Nachtrag: Eigentlich verbietet es die "Netiquette", die Seite durch den Parser-Adapter durchsuchen zu lassen, wenn der Betreiber das durch die Header als "unerwünscht" tituliert hat... Aber vielleicht bin ich nur im "früher war alles besser verfangen"
-
Habe mir Deinen - dankbarerweise formatierten - Seitenquelltext angeschaut... Was macht man denn hier für Schweinereien...?
(function() { 'use strict'; const configCheck1 = 'ukhZqPRxsYdCRaOVOSqx'; const configCheck2 = 'ZaPFFyEoIxocFaIgkRFv'; const configCheck3 = 'soBleRBitSfRPwnMlwkg'; function revealElements() { window.requestAnimationFrame(() => { [configCheck1, configCheck2, configCheck3].forEach(id => { const el = document.getElementById(id); if (el) { el.style.display = 'block'; } }); }); }Nix schlimmes.
requestAnimationFrame Gibt einem Script die Möglichkeit hochperformante Animationen durchzuführen.
https://developer.mozilla.org/de/docs/Web/API/Window/requestAnimationFrameHier wird also sehr oft für 3 Elemente die Display Einstellung wieder auf Block gestellt.
Irgendwo müsste es ein html Element mit dem id soBleRBitSfRPwnMlwkg geben. Ich gehe davon aus, das das dynamisch generiert wird und jedes Mal anders heiß.Warum, müsste man mal im code schauen. Ohne das das überprüft wird macht das kein Sinn.

Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden294
Online33.0k
Benutzer83.3k
Themen1.3m
Beiträge