

Website mit Parser auslesen
-
@dr-bakterius
bei http error code 403 = forbidden, kommen erst gar keine daten
da kommt nur der http header zurück -
@dr-bakterius
nein, wie oben geschrieben
im parser adapter und per skript adapter mit fetch -
@dr-bakterius
nein, wie oben geschrieben
im parser adapter und per skript adapter mit fetch@oliverio Tja, bei mir klappt es.
-
ich hab mal die Website im Browser aufgerufen
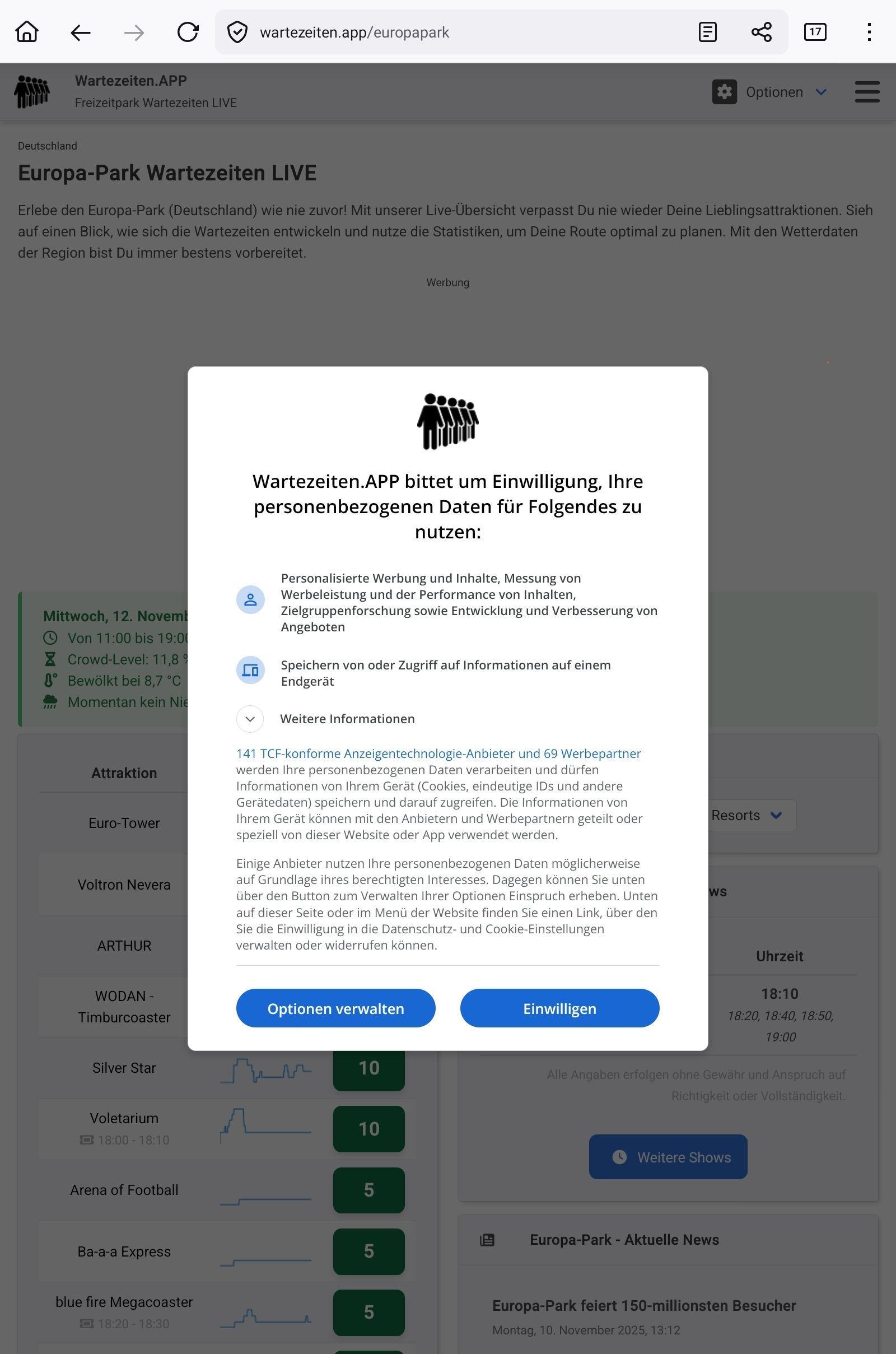
ohne Bestätigung kommst du ja gar nicht auf die Seite!
@homoran said in Website mit Parser auslesen:
ich hab mal die Website im Browser aufgerufen
ohne Bestätigung kommst du ja gar nicht auf die Seite!
Liegt es vielleicht daran?
-
@homoran said in Website mit Parser auslesen:
ich hab mal die Website im Browser aufgerufen
ohne Bestätigung kommst du ja gar nicht auf die Seite!
Liegt es vielleicht daran?
@legerm Durchaus möglich.
Wiederholt sich die Einwilligung-Abfrage wenn man sie einmal erteilt hat, wenn man die Seite erneut mit dem frisch neu gestarteten Browser aufruft?Vielleicht kann man den Cookie irgendwie in eine Curl-Anfrage mit einpacken, und den Parser dann auf die heruntergeladene Seite arbeiten lassen.
Ich habe die Cookie Einwilligung nicht, wenn ich die Seite im Browser aufrufe. Womöglich ist die gar nicht von der Seite selber, sondern von der eingeblendeten Werbung.
Vor der schützt mich PiHole... (Blaues Feld)BTW: Im roten Feld gibt es keine Stau-Infos, da außerhalb der Öffnungszeit ...
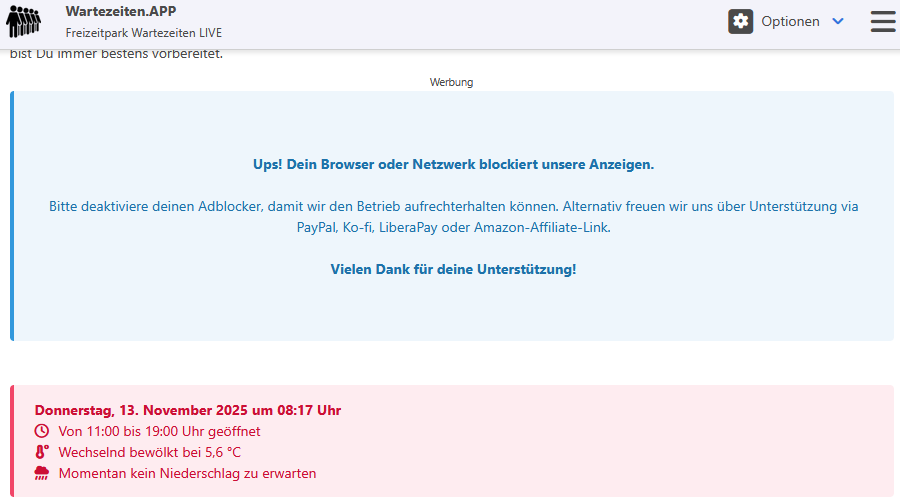
NACHTRAG: Mit Chrome kriege ich die Cookie-Abfrage beim ersten Aufruf - danach nicht mehr. Werbung wird eingeblendet.
-
@homoran said in Website mit Parser auslesen:
ich hab mal die Website im Browser aufgerufen
ohne Bestätigung kommst du ja gar nicht auf die Seite!
Liegt es vielleicht daran?
@legerm sagte in Website mit Parser auslesen:
Liegt es vielleicht daran?
Das glaube ich nicht. Im Hintergrund wird es ja angezeigt. Also steht es auch im Quellcode. Einzige Ausnahme: es handelt sich um ein Bild. Doch das ist eher unwahrscheinlich weil ja auch das aktuelle Datum angezeigt wird.
Was ich aber habe ist ein Pi Hole. Vielleicht liegt es daran.
-
@legerm sagte in Website mit Parser auslesen:
Liegt es vielleicht daran?
Das glaube ich nicht. Im Hintergrund wird es ja angezeigt. Also steht es auch im Quellcode. Einzige Ausnahme: es handelt sich um ein Bild. Doch das ist eher unwahrscheinlich weil ja auch das aktuelle Datum angezeigt wird.
Was ich aber habe ist ein Pi Hole. Vielleicht liegt es daran.
Habe mir Deinen - dankbarerweise formatierten - Seitenquelltext angeschaut... Was macht man denn hier für Schweinereien...?
(function() { 'use strict'; const configCheck1 = 'ukhZqPRxsYdCRaOVOSqx'; const configCheck2 = 'ZaPFFyEoIxocFaIgkRFv'; const configCheck3 = 'soBleRBitSfRPwnMlwkg'; function revealElements() { window.requestAnimationFrame(() => { [configCheck1, configCheck2, configCheck3].forEach(id => { const el = document.getElementById(id); if (el) { el.style.display = 'block'; } }); }); }Intel(R) Celeron(R) CPU N3000 @1.04GHz 8G RAM 480G SSD * Virtualization : unprivileged lxc container on Proxmox * 6 GByte RAM für den iobroker Container * Remote-Access über Wireguard meiner Fritzbox
-
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
-
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
@legerm Könnte an Anschluss-Typen liegen (DSLite, DualStack, IOv4 only), an zu vielen Anfragen, die Du gestellt hast (5000 ms sind vielleicht schon Bot-Verdächtig) oder an durch Bots "verbrannten" eigenen öffentlichen IP-Adressen ...
Kriegst Du denn mit curl die Seite heruntergeladen?
Wenn ja könntest Du sie ja per CRON-Job herunterladen (vielleicht nur alle 5...10 Minuten, damit es unverdächtig bleibt)
Der iobroker - Parser Adapter könnte dann auf die heruntergeladene Datei statt auf die URL schauen...
Wenn Curl per IPv4 nicht herunterladen kann, vielleicht auf IPv6 ausweichen, wenn an Deinem Anschluss verfügbar.
teste mal ...curl -6 https://www.wartezeiten.app/europapark/Nachtrag: Eigentlich verbietet es die "Netiquette", die Seite durch den Parser-Adapter durchsuchen zu lassen, wenn der Betreiber das durch die Header als "unerwünscht" tituliert hat... Aber vielleicht bin ich nur im "früher war alles besser verfangen"
-
Habe mir Deinen - dankbarerweise formatierten - Seitenquelltext angeschaut... Was macht man denn hier für Schweinereien...?
(function() { 'use strict'; const configCheck1 = 'ukhZqPRxsYdCRaOVOSqx'; const configCheck2 = 'ZaPFFyEoIxocFaIgkRFv'; const configCheck3 = 'soBleRBitSfRPwnMlwkg'; function revealElements() { window.requestAnimationFrame(() => { [configCheck1, configCheck2, configCheck3].forEach(id => { const el = document.getElementById(id); if (el) { el.style.display = 'block'; } }); }); }Nix schlimmes.
requestAnimationFrame Gibt einem Script die Möglichkeit hochperformante Animationen durchzuführen.
https://developer.mozilla.org/de/docs/Web/API/Window/requestAnimationFrameHier wird also sehr oft für 3 Elemente die Display Einstellung wieder auf Block gestellt.
Irgendwo müsste es ein html Element mit dem id soBleRBitSfRPwnMlwkg geben. Ich gehe davon aus, das das dynamisch generiert wird und jedes Mal anders heiß.Warum, müsste man mal im code schauen. Ohne das das überprüft wird macht das kein Sinn.
-
Nix schlimmes.
requestAnimationFrame Gibt einem Script die Möglichkeit hochperformante Animationen durchzuführen.
https://developer.mozilla.org/de/docs/Web/API/Window/requestAnimationFrameHier wird also sehr oft für 3 Elemente die Display Einstellung wieder auf Block gestellt.
Irgendwo müsste es ein html Element mit dem id soBleRBitSfRPwnMlwkg geben. Ich gehe davon aus, das das dynamisch generiert wird und jedes Mal anders heiß.Warum, müsste man mal im code schauen. Ohne das das überprüft wird macht das kein Sinn.
-
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
@legerm sagte in Website mit Parser auslesen:
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
Am besten den Wert in die api integrieren.
https://api.wartezeiten.app/Meine Adapter und Widgets
TVProgram, SqueezeboxRPC, OpenLiga, RSSFeed, MyTime,, pi-hole2, vis-json-template, skiinfo, vis-mapwidgets, vis-2-widgets-rssfeed
Links im Profil -
@legerm sagte in Website mit Parser auslesen:
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
Am besten den Wert in die api integrieren.
https://api.wartezeiten.app/ -
@legerm sagte in Website mit Parser auslesen:
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
Am besten den Wert in die api integrieren.
https://api.wartezeiten.app/ -
@oliverio Das ist eine gute Fundstelle ... Vom Betreiber wahrscheinlich für Bots gedacht, und spart viel Traffic ... nur das Nötige wird übertragen ... und dann noch die Spielmöglichkeiten mit der API
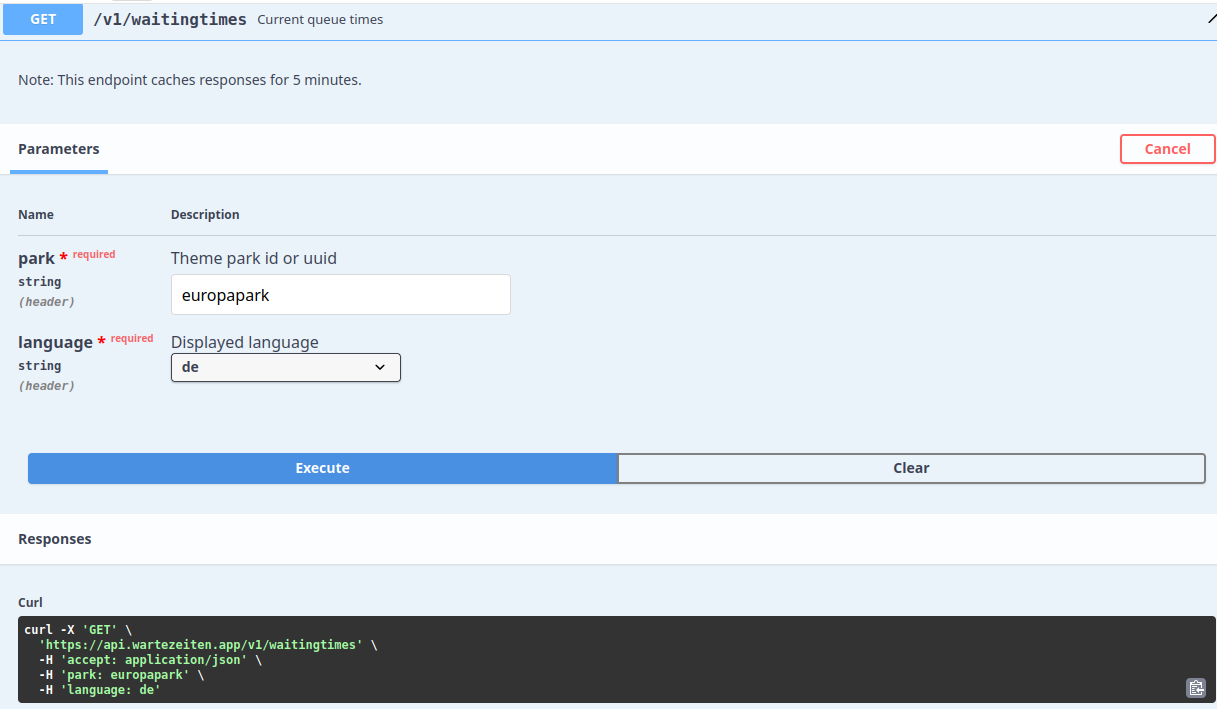
@martinp said in Website mit Parser auslesen:
@oliverio Das ist eine gute Fundstelle ... Vom Betreiber wahrscheinlich für Bots gedacht, und spart viel Traffic ... nur das Nötige wird übertragen ... und dann noch die Spielmöglichkeiten mit der API
Ja, leider ohne CrowdLevel....
-
@legerm Könnte an Anschluss-Typen liegen (DSLite, DualStack, IOv4 only), an zu vielen Anfragen, die Du gestellt hast (5000 ms sind vielleicht schon Bot-Verdächtig) oder an durch Bots "verbrannten" eigenen öffentlichen IP-Adressen ...
Kriegst Du denn mit curl die Seite heruntergeladen?
Wenn ja könntest Du sie ja per CRON-Job herunterladen (vielleicht nur alle 5...10 Minuten, damit es unverdächtig bleibt)
Der iobroker - Parser Adapter könnte dann auf die heruntergeladene Datei statt auf die URL schauen...
Wenn Curl per IPv4 nicht herunterladen kann, vielleicht auf IPv6 ausweichen, wenn an Deinem Anschluss verfügbar.
teste mal ...curl -6 https://www.wartezeiten.app/europapark/Nachtrag: Eigentlich verbietet es die "Netiquette", die Seite durch den Parser-Adapter durchsuchen zu lassen, wenn der Betreiber das durch die Header als "unerwünscht" tituliert hat... Aber vielleicht bin ich nur im "früher war alles besser verfangen"
-
@martinp said in Website mit Parser auslesen:
@oliverio Das ist eine gute Fundstelle ... Vom Betreiber wahrscheinlich für Bots gedacht, und spart viel Traffic ... nur das Nötige wird übertragen ... und dann noch die Spielmöglichkeiten mit der API
Ja, leider ohne CrowdLevel....
@legerm Das ist anscheinend wirklich so - alles selber aus den Einzelwerten ausrechnen wäre noch möglich ...
Alle Fahrgeschäfte summieren, und dann durch die Anzahl der Fahrgeschäfte dividieren wäre ein Ansatz um die durchschnittliche Wartezeit zu erfassen ...
das funtkioniert... das heisst, ich hol mir dir Seite einmal die Stunde (reicht völlig aus), speichere sie und lese sie dann via Parser aus? Einfach per 127.0.0.1 ?
Ich habe den Quelltext der Seite angeschaut, die ist nicht vollständig, auch in der steht das Crowd-Level nicht drin, wahrscheinlich weil Curl Javascript nicht ausgeführt hat ... keine statische Seite
-
Habe Kontakt zum Seitenbetreiber aufgenommen. Die Seite ist durch Cloudfare gegen Bots abgesichert. Scheint wohl gut zu funktionieren....
Aber warum funktioniert es bei Dr. Bakterius? Kann eigentlich nicht am Pihole liegen, oder?
Beste Grüße
Martin
@legerm sagte in Website mit Parser auslesen:
Die Seite ist durch Cloudfare gegen Bots abgesichert.
das hatte ich vermutet
@legerm sagte in Website mit Parser auslesen:
Aber warum funktioniert es bei Dr. Bakterius?
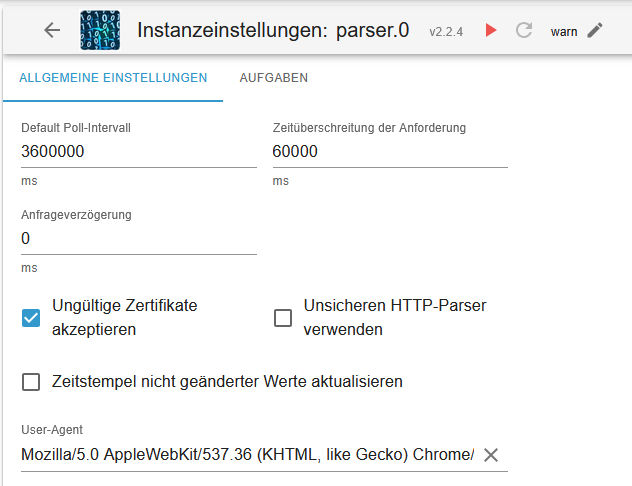
weil sein default poll Intervall seeeehr lang ist.
meines hatte sich wohl durch ein update wieder suf 10 Sekunden gestellt.
-
Es gibt auch noch weitere Seiten mit ähnlichen Informationen:
https://www.thrill-data.com/waits/park/eup/eup/
https://queue-times.com/de/parks/51
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden582
Online33.0k
Benutzer83.3k
Themen1.3m
Beiträge