

ioBroker Prozess- & Gesundheitsmonitor + Grafana + HTML
-
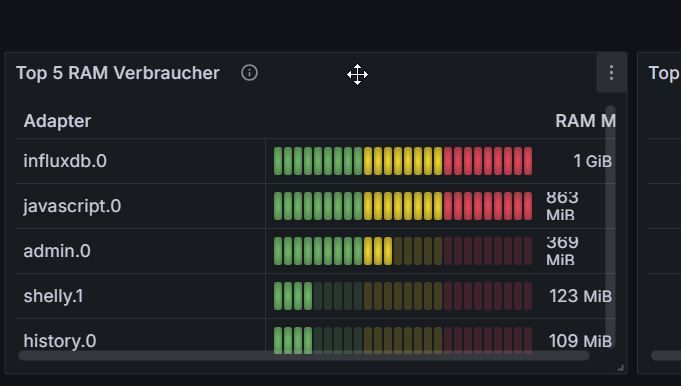
ok funktioniert jetzt super. Allerdings geht mein Synology NAS jetzt in die Knie. Mein iobroker belegt mehr als 44% RAM und es werden jede menge Warnings und errors in die influxdb geschrieben. schaukelt sich also hoch. da muss ich noch was optimieren
-
ok funktioniert jetzt super. Allerdings geht mein Synology NAS jetzt in die Knie. Mein iobroker belegt mehr als 44% RAM und es werden jede menge Warnings und errors in die influxdb geschrieben. schaukelt sich also hoch. da muss ich noch was optimieren
-
-
habe jetzt 350 warnings /h in der influxdb.0 und ich sehe das die instanz neugestartet wird. Mein Host Ram ist auch zeitweise kritisch nur 13% und mein iobroker Ram belegt mehr als 54% zeitweise
hab eine synology Nas DS918+ mit 12 GB ram -
habe jetzt 350 warnings /h in der influxdb.0 und ich sehe das die instanz neugestartet wird. Mein Host Ram ist auch zeitweise kritisch nur 13% und mein iobroker Ram belegt mehr als 54% zeitweise
hab eine synology Nas DS918+ mit 12 GB ram@rallef das der RAM oder die CPU mal schwankt ist normal, meine Frage lag eher darin:
Hattest du diese Probleme schon vorher oder wolltest du mir mitteilen, erst seit Scriptinstallation -
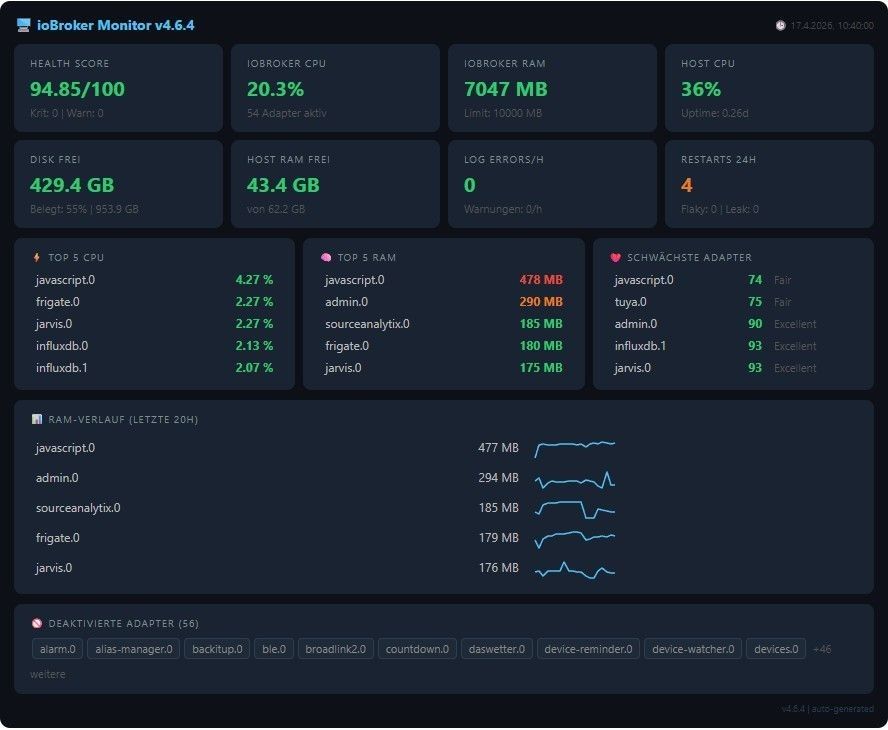
ioBroker Prozess-Monitor — Langzeit-Gesundheitsmonitoring
Ich stelle hier mein Script für ein erweitertes Prozess- und Gesundheitsmonitoring von ioBroker vor, inklusive passendem Grafana-Dashboard für InfluxDB v1. (InfluxQL )
InfluxDB v2 ist grundsätzlich vorgesehen, aktuell aber noch nicht als separates Dashboard-Paket enthalten.
Habe das Grafana json (flux) im Beitrag unten ergänzt, jedoch ungetestetDas Script nutzt Standard-States wie
system.adapter.*undsystem.host.*und benötigt keinen zusätzlichen eigenen Adapter.
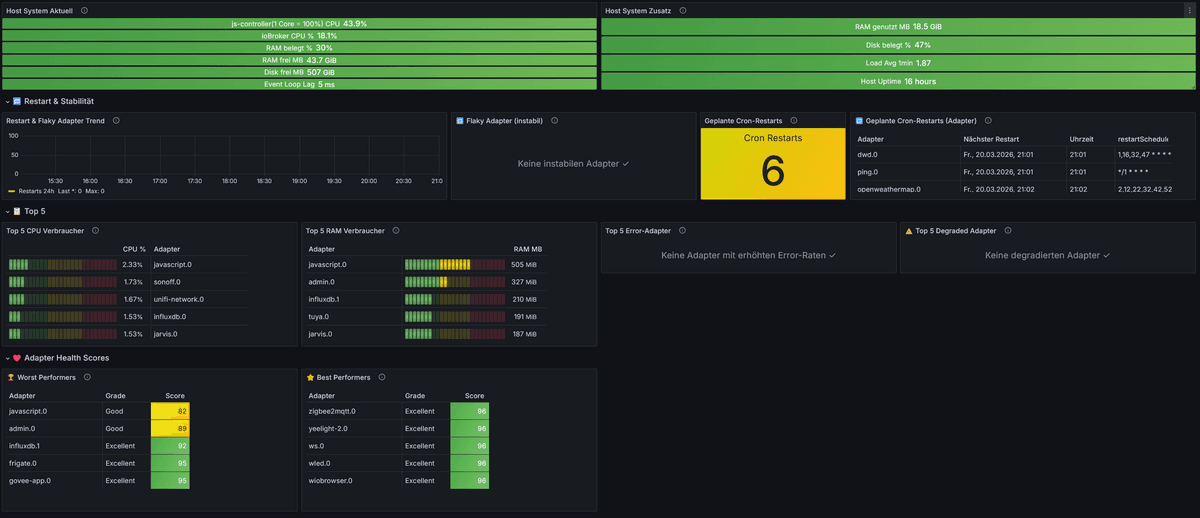
Für Log-Tracking und die Erkennung degradierter Adapter wirdonLogdes JavaScript-Adapters benötigt.Enthalten sind unter anderem:
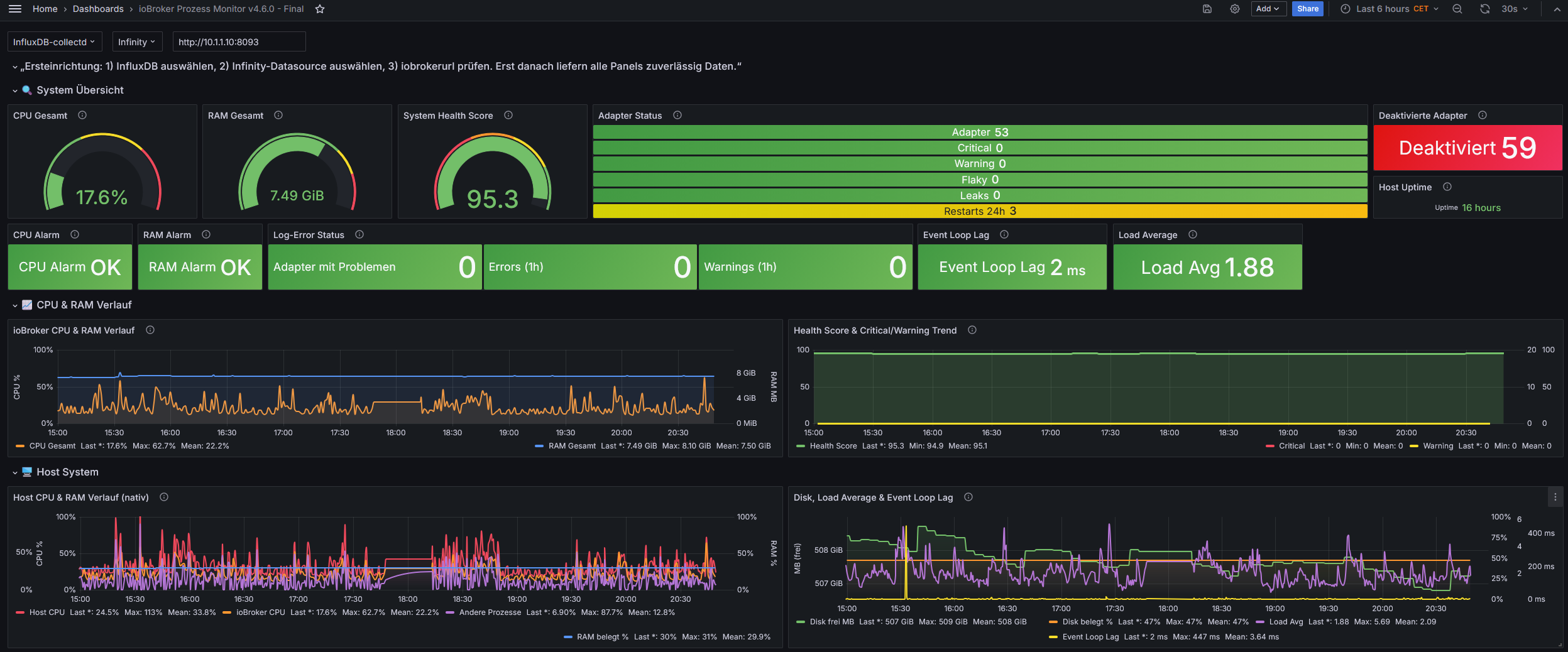
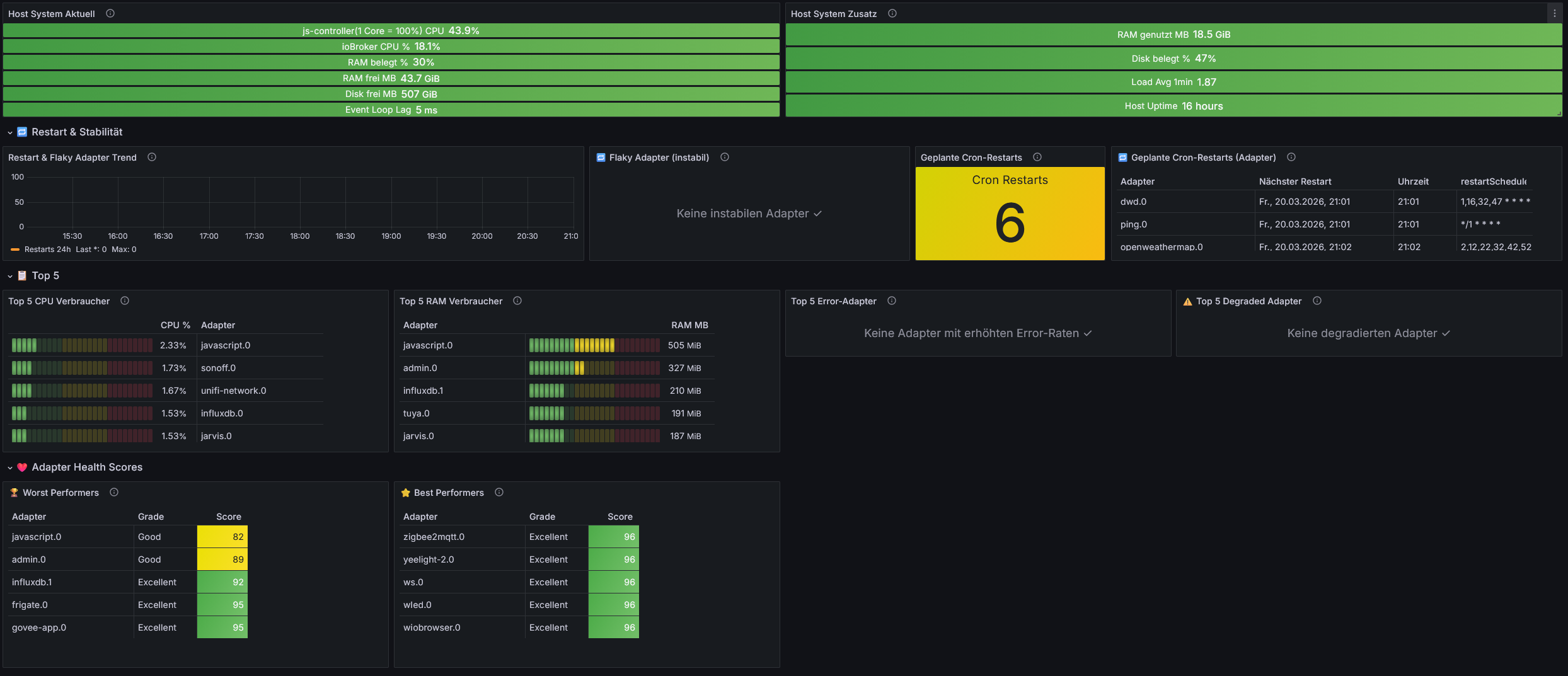
- CPU-/RAM-Monitoring aller laufenden Adapter
- Restart-Tracking für Flaky-Adapter und Cron-Restarts
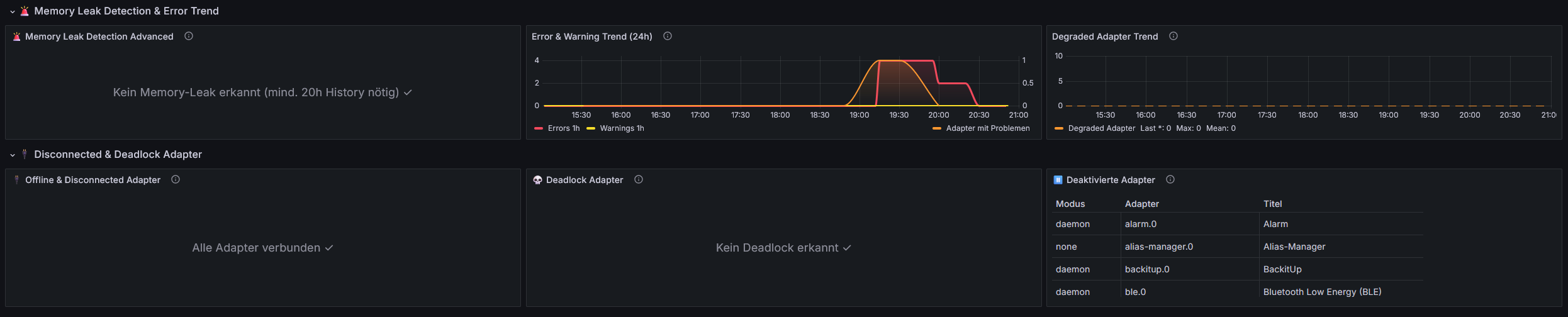
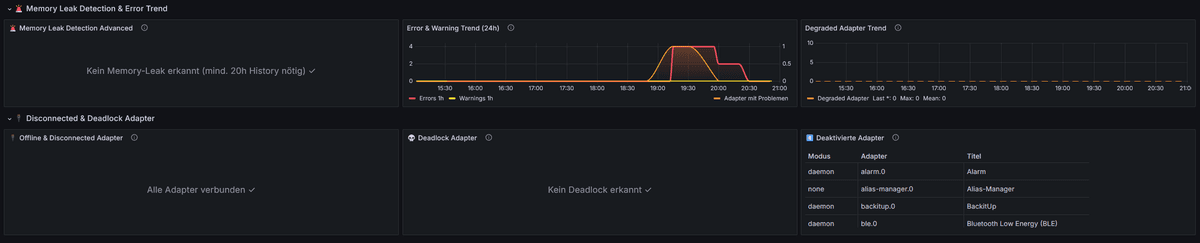
- Memory-Leak- und Deadlock-Erkennung
- Log-Error-/Warn-Tracking und Degraded-Adapter-Bewertung
- Host-, Disk- und Health-Score-Monitoring
- Optionale Telegram-Alarme und REST-Auswertung
- Übersicht über deaktivierte Adapter
Getestet auf Raspberry Pi, VM, LXC, Docker und Unraid; produktiv läuft es aktuell auf Docker/Unraid.
Ziel ist die Früherkennung schleichender Probleme in produktiven ioBroker-Systemen.Wichtig:
Nach dem Import des Dashboards bitte zuerstDSINFLUXDB,DSINFINITYundiobrokerurlprüfen bzw. auswählen.
Erst danach liefern alle Panels und REST-basierten Tabellen zuverlässig Daten.Im Beitrag:
- Script
- Grafana-Dashboard InfluxDB v1 ( InfluxQL )
- Grafana-Dashboard InfluxDB v2 (flux)
- Die für InfluxDB benötigten Datenpunkte; weitere Tabellen und Zusatzdaten kommen per Infinity direkt über die REST-API
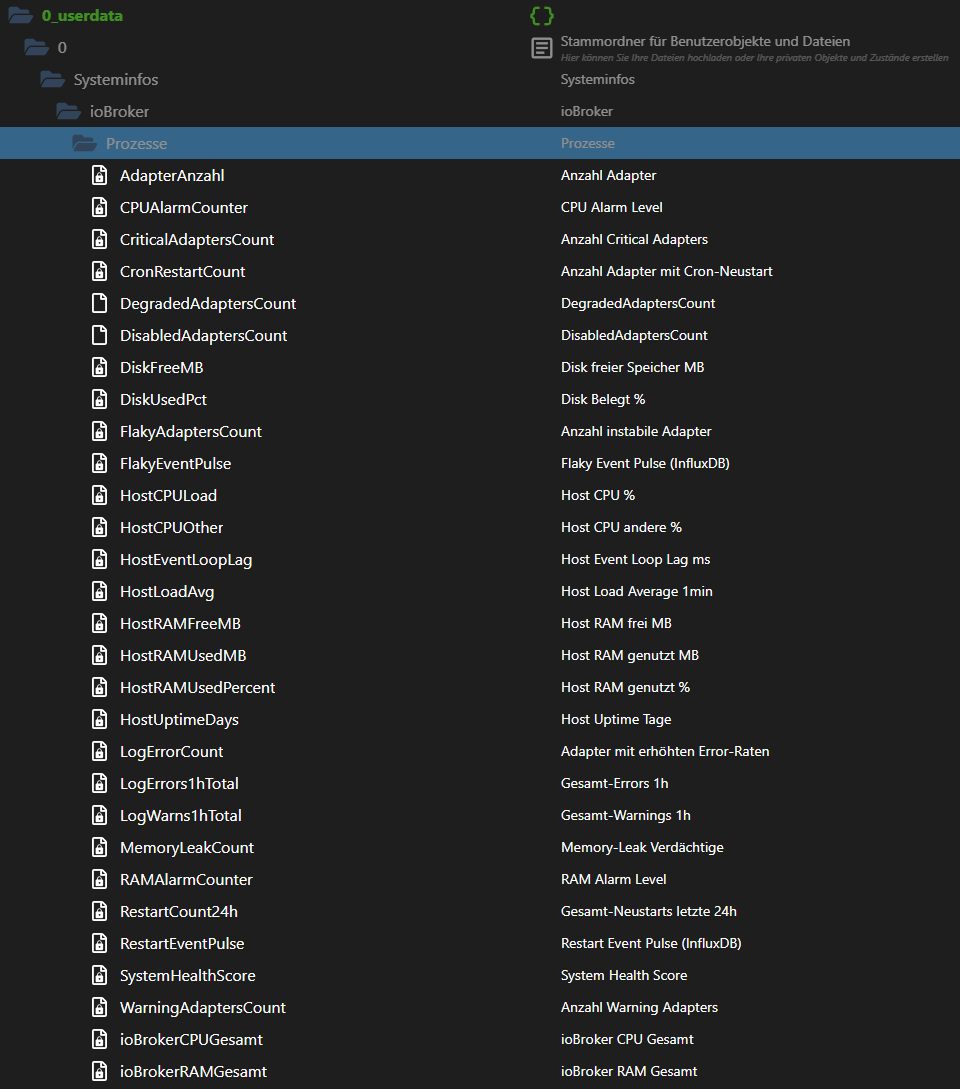
- Variablen anlegen siehe https://forum.iobroker.net/post/1330170
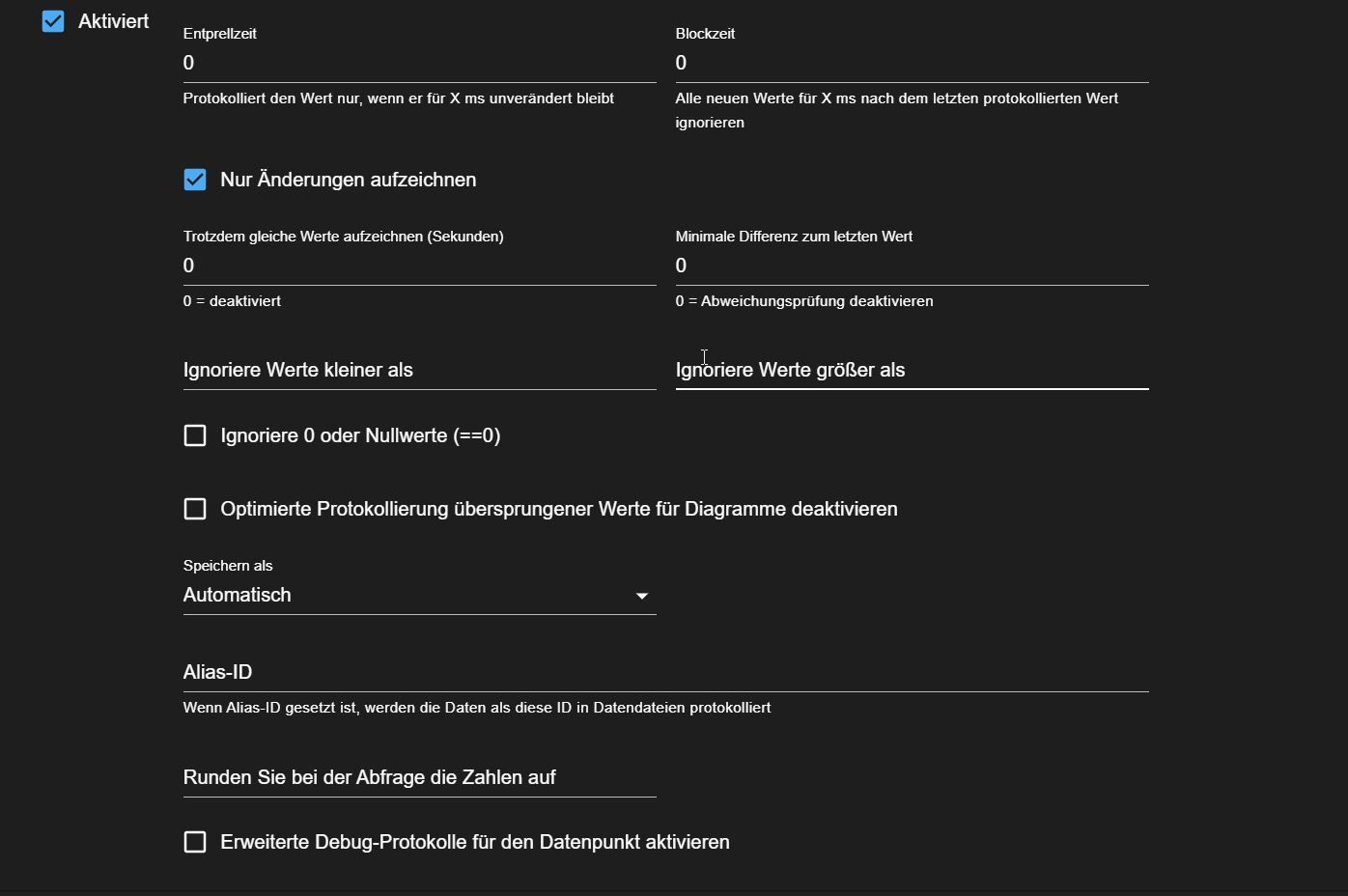
- Für dein Dashboard und die Ressourcen ist entscheidend, wie du die Datenpunkt‑spezifischen Influx‑Einstellungen je Typ setzt – nicht global alles gleich.
Grundprinzip je Datenpunkttyp
- Langsam ändernde Zustände (Booleans, Modus, Error‑Flags, Health‑Scores, Event‑Pulse):
- Nur Änderungen aufzeichnen: an
- Entprellzeit: 300–1000 ms
- Blockzeit: 0
- „Trotzdem gleiche Werte aufzeichnen“: 600–3600 s (je nach gewünschter History‑Auflösung)
- Minimale Differenz: 0 (bei Booleans/Zahlen mit kleinem Bereich)
- Ergebnis: sehr wenige Punkte, aber alle Zustandswechsel sauber im Grafana‑Dashboard.
Kontinuierliche Messwerte mit Trend (CPU‑Last, RAM‑MB, Host‑Disk‑FreeMB, Health‑Score):
- Nur Änderungen aufzeichnen: an
- Entprellzeit: 500 ms wie im Screenshot ist ok
- „Trotzdem gleiche Werte“: auf deinen Script‑Zyklus bzw. Host‑Intervalle ausrichten, z. B. 180–300 s, damit Influx wenigstens alle paar Minuten einen Punkt bekommt, selbst wenn sich nichts ändert.
- Minimale Differenz: z. B. 1 % bei CPU‑Werten, 5–10 MB bei RAM, 1 Punkt beim Health‑Score.
- Ignoriere 0/Nullwerte: an, falls der DP beim Start kurz 0/NULL ist und das im Dashboard nicht stören soll.
Pulse‑Werte für Events (RestartEventPulse, FlakyEventPulse, Deadlock‑Alarm‑Pulse etc.):
- Nur Änderungen: an
- Trotzdem gleiche Werte: 0 s (nicht nötig, der Pulse ist ein kurzer Wechsel 0→1→0)
- Entprellzeit: klein (100–200 ms), damit jeder Pulse als eigener Punkt landet.
- 0/Null ignorieren: aus, sonst siehst du nur die 1, aber keinen „Rückfall“ im Graphen.
Bereich Datenpunkte Grundprinzip / langsam ändernde Zustände SystemHealthScore,DisabledAdaptersCount,ConnectionIssuesCount,DeadlockAdapters,DisconnectedCount,FlakyAdaptersCount,CronRestartCount,MemoryLeakCount,LogErrorCount,LogErrors1hTotal,LogWarns1hTotal,CriticalAdaptersCount,WarningAdaptersCount,CPUAlarmCounter,RAMAlarmCounter,RestartCount24hKontinuierliche Messwerte ioBrokerCPUGesamt,ioBrokerRAMGesamt,HostCPULoad,HostCPUOther,HostRAMFreeMB,HostRAMAvailMB,HostRAMUsedMB,HostRAMTotalMB,HostRAMUsedPercent,HostLoadAvg,HostUptimeDays,HostEventLoopLag,DiskFreeMB,DiskUsedPctPuls-Werte RestartEventPulse,FlakyEventPulseFeedback, Tests in anderen Umgebungen und Verbesserungsvorschläge willkommen! 🚀
🔥 NEU: Prozess-Monitor
// CHANGELOG v4.6.7 (04.05.2026)
// ============================================================
// ✅ E-Mail-Benachrichtigung (email-Adapter): parallel zu Telegram/Pushover,
// gleicher Cooldown, gleiche Alarmtyp-Schalter (EMAIL*ALERT)Changelog_old
Script
iobroker-prozessmonitor_v4.6.7Das Dashboard (InfluxQL )
dashboard-4.6.0-FinalNEU 30.03.2026
Das Dashboard (Flux)
dashboard-4.6.0_flux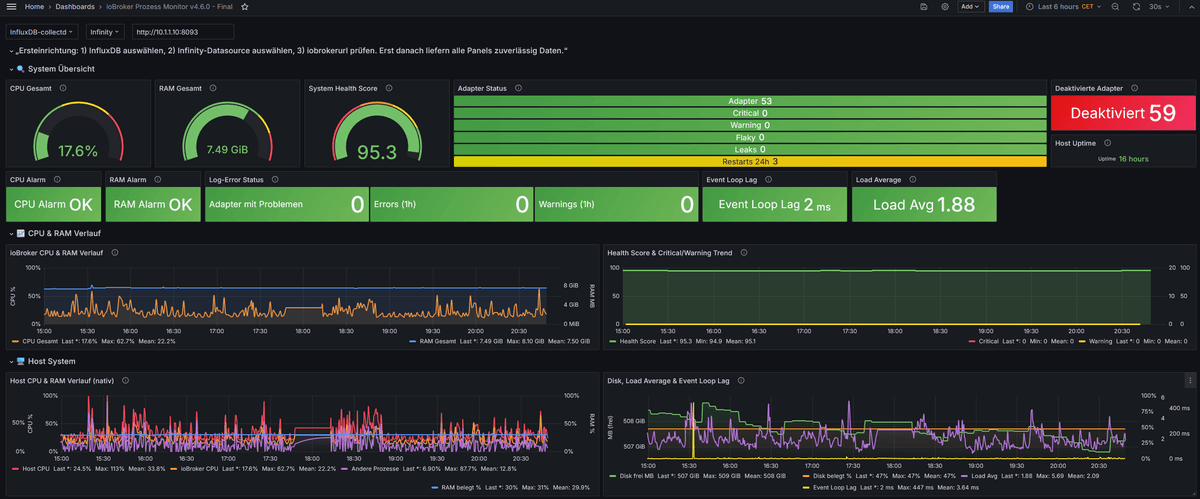
Offene Tuning-Punkte
- Flaky: aktuell 3 Restarts in 24h — sinnvoller Grenzwert, wenn geplante Cron-Restarts toleriert werden?
- Errors: aktuell 3/h Warnung und 20/h kritisch — passen diese Werte in anderen Umgebungen?
- Worst/Best Performer: Gewichtung des Health Scores noch offen für Feintuning.
- Degraded Adapter: aktuell kritische Error-Rate ab 10/h plus CPU > 12 und/oder Event Loop Lag > 100 ms — praxistauglich?
- Event Loop Lag: aktuell 500 ms kritisch als allgemeiner Schwellwert — vermutlich hardwareabhängig?
- Memory Leak: aktuell ab (R^2 > 0.65) und Wachstum > 15 MB/h — Erfahrungswerte willkommen.
- Deadlock: aktuell
alive=trueundconnected=false— eventuell noch erweiterbar.
crunchip sagte:
Grundprinzip je Datenpunkttyp
Langsam ändernde Zustände (Booleans, Modus, Error‑Flags, Health‑Scores, Event‑Pulse):
Nur Änderungen aufzeichnen: an
Entprellzeit: 300–1000 ms
Blockzeit: 0
„Trotzdem gleiche Werte aufzeichnen“: 600–3600 s (je nach gewünschter History‑Auflösung)
Minimale Differenz: 0 (bei Booleans/Zahlen mit kleinem Bereich)
Ergebnis: sehr wenige Punkte, aber alle Zustandswechsel sauber im Grafana‑Dashboard.
Kontinuierliche Messwerte mit Trend (CPU‑Last, RAM‑MB, Host‑Disk‑FreeMB, Health‑Score):Nur Änderungen aufzeichnen: an
Entprellzeit: 500 ms wie im Screenshot ist ok
„Trotzdem gleiche Werte“: auf deinen Script‑Zyklus bzw. Host‑Intervalle ausrichten, z. B. 180–300 s, damit Influx wenigstens alle paar Minuten einen Punkt bekommt, selbst wenn sich nichts ändert.
Minimale Differenz: z. B. 1 % bei CPU‑Werten, 5–10 MB bei RAM, 1 Punkt beim Health‑Score.
Ignoriere 0/Nullwerte: an, falls der DP beim Start kurz 0/NULL ist und das im Dashboard nicht stören soll.
Pulse‑Werte für Events (RestartEventPulse, FlakyEventPulse, Deadlock‑Alarm‑Pulse etc.):Nur Änderungen: an
Trotzdem gleiche Werte: 0 s (nicht nötig, der Pulse ist ein kurzer Wechsel 0→1→0)
Entprellzeit: klein (100–200 ms), damit jeder Pulse als eigener Punkt landet.
0/Null ignorieren: aus, sonst siehst du nur die 1, aber keinen „Rückfall“ im Graphen.@rallef hast du aber schon beachtet? und auch Punkt4 im ersten Beitrag?
-
super vielen dank das habe ich noch nie berücksichtigt bei den anderen Datenpunkten meiner anderen Anwendungen. Vielleicht habe ich das problem schon vorher gehabt. aber das die Influxdb Instanz mehrmals täglich sich restartet ist neu. Werde alle Datenpunkte unter Prozesse heute abend mir anschauen und ggfls ändern. Hoffe das reicht dann damit Influxdb nicht mehr sich restartet
-
ok aber was ist was
Langsam ändernde Zustände (Booleans, Modus, Error‑Flags, Health‑Scores, Event‑Pulse): welche dp's sind das? -
hallo, hab jetzt die Werte angepasst bekomme aber trotzdem eine Hohe Anzahl an Warnungen bei der influxdb. Habe danach deins Skript gestoppt und seitdem keine Warnungen und kein restart der influxdb mehr.
kurzer Auschnitt der Warnungen:
on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812395,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812438,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812500,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812544,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812602,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812678,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812720,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812791,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],
Ich vermute es können nicht alle Daten geschrieben werden in die influxdb. Was könnte ich noch überprüfen?
-
hallo, hab jetzt die Werte angepasst bekomme aber trotzdem eine Hohe Anzahl an Warnungen bei der influxdb. Habe danach deins Skript gestoppt und seitdem keine Warnungen und kein restart der influxdb mehr.
kurzer Auschnitt der Warnungen:
on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812395,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812438,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812500,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812544,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812602,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812678,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812720,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"modbus.1\\\":{\\\"errors\\\":[{\\\"timestamp\\\":17781361"},{"timestamp":1778221812791,"severity":"warn","message":"influxdb.0 (29205) Error on writePoint(\"{\"value\":\"{\\\"javascript.0\\\":{\\\"errors\\\":[],\\\"warns\\\":[]},\\\"weatherunderground.0\\\":{\\\"errors\\\":[],
Ich vermute es können nicht alle Daten geschrieben werden in die influxdb. Was könnte ich noch überprüfen?
ch vermute es können nicht alle Daten geschrieben werden in die influxdb.
möglich, eventuell hast du bei den Datenpunkten den falschen Datentyp gewählt und dann umgestellt, somit doppelt drin stehen
falls es zeitweise doch eine Schreiblast sein, könntest du deine Influxdb Einstellungen überprüfen bzw so einstellen wie gezeigt

-
@rallef klar könntest du,
aber- alle Influxdb Einstellungen musst du wieder tätigen und alle benötigten DP`s wieder in influx aktivieren.
- die alten Daten stehen trotzdem mit falschen Datentypen in der Influx

Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
445
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge