

[gelöst] Parser und Umlaute
-
@homoran sagte in Parser und Umlaute:
So aufgedröselt und fein erklärt gehts ja, aber selbst auszudenken - da ist bei mir schon lange Schluss

Ein bisschen verwirrend ist, dass regex101 nicht die gleichen Resultate liefert.und zuletzt bestimmt die 0 (null) keine weiteren Zeichen mehr auszugeben?
@tom_33 sagte in Parser und Umlaute:
Ein bisschen verwirrend ist, dass regex101 nicht die gleichen Resultate liefert.
Bei mir schon. (Ich nutze ja auch nur dokumentierte Befehle ;-) )
Hast du auch auf Javascript eingestellt?@tom_33 sagte in Parser und Umlaute:
und zuletzt bestimmt die 0 (null) keine weiteren Zeichen mehr auszugeben?
????
erst einmal ist 0 nicht
null
und zweitens weiß ich nicht was du meinst.Der RegEx enthält eine Gruppe, die das Ergebnis bereitstellt
Die Kunst liegt darin, diesen RegEx eindeutig zu machen -
@tom_33 sagte in Parser und Umlaute:
Ein bisschen verwirrend ist, dass regex101 nicht die gleichen Resultate liefert.
Bei mir schon. (Ich nutze ja auch nur dokumentierte Befehle ;-) )
Hast du auch auf Javascript eingestellt?@tom_33 sagte in Parser und Umlaute:
und zuletzt bestimmt die 0 (null) keine weiteren Zeichen mehr auszugeben?
????
erst einmal ist 0 nicht
null
und zweitens weiß ich nicht was du meinst.Der RegEx enthält eine Gruppe, die das Ergebnis bereitstellt
Die Kunst liegt darin, diesen RegEx eindeutig zu machen@homoran sagte in Parser und Umlaute:
Hast du auch auf Javascript eingestellt?
natürlich nicht! Mein Fehler!
und zweitens weiß ich nicht was du meinst.
Versuch mal Wind<[^:]+[^>]+[^\w]+(.+), Num = 0ohne "0" bekomme ich das Ergebnis:
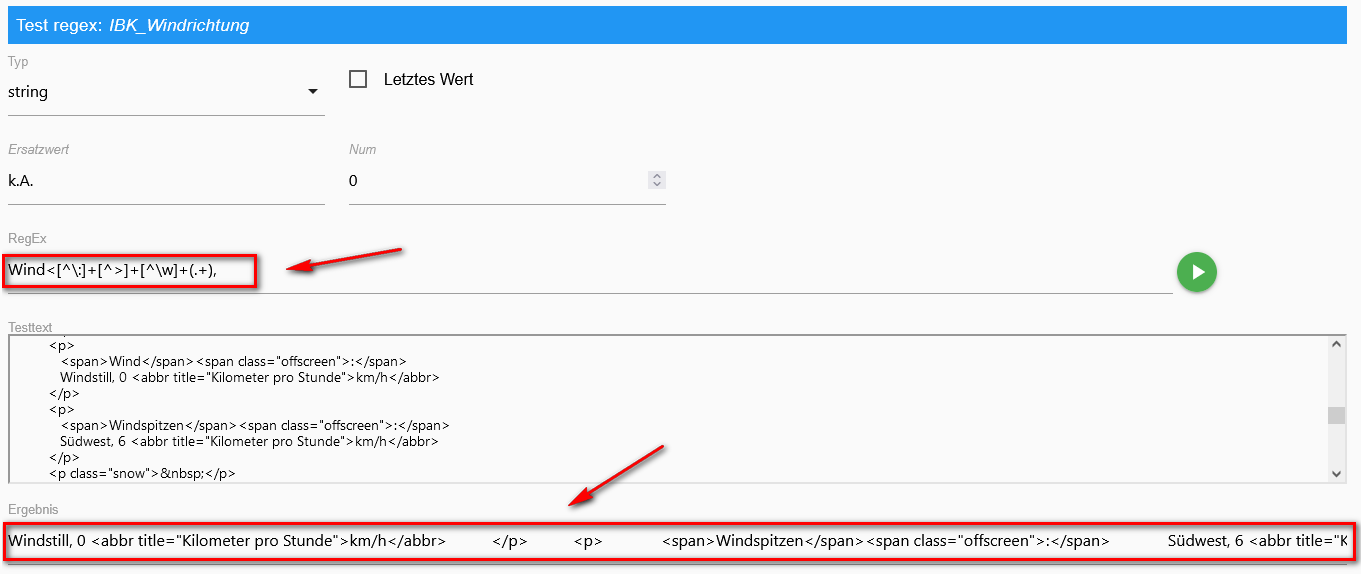
mit "0" dieses (so wie ich es möchte):
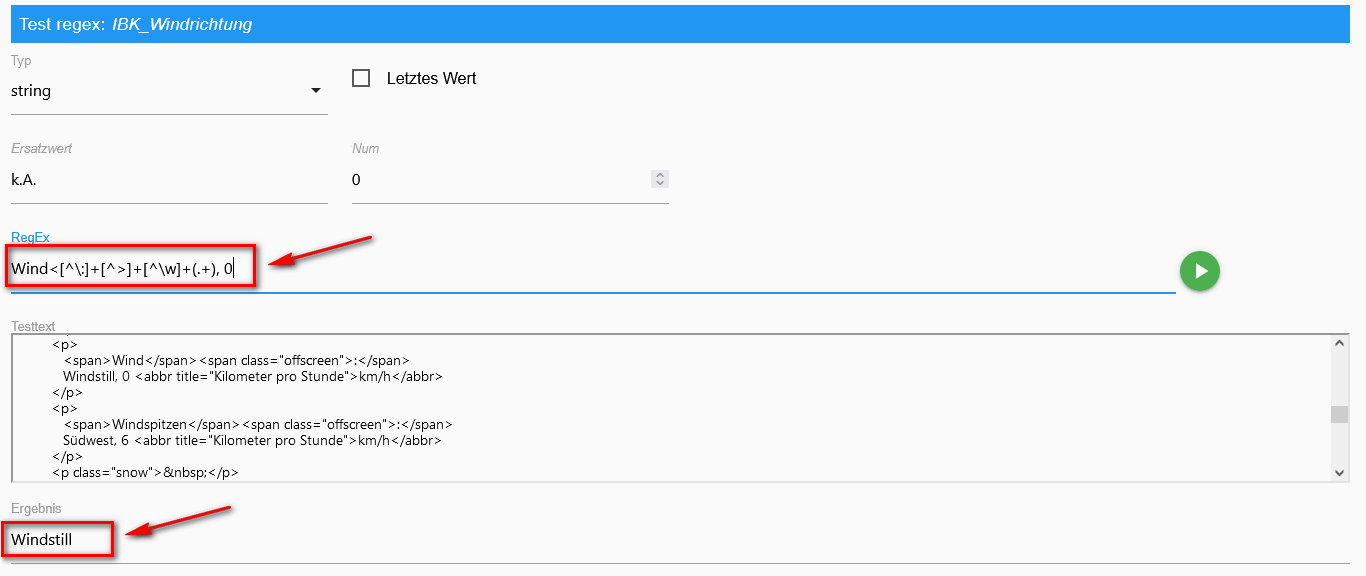
-
@homoran sagte in Parser und Umlaute:
Hast du auch auf Javascript eingestellt?
natürlich nicht! Mein Fehler!
und zweitens weiß ich nicht was du meinst.
Versuch mal Wind<[^:]+[^>]+[^\w]+(.+), Num = 0ohne "0" bekomme ich das Ergebnis:
mit "0" dieses (so wie ich es möchte):
@tom_33 sagte in Parser und Umlaute:
ohne "0" bekomme ich das Ergebnis:
Sollte aber nicht.
kann sein, dass das > escaped werden muss\> -
@tom_33 sagte in Parser und Umlaute:
ohne "0" bekomme ich das Ergebnis:
Sollte aber nicht.
kann sein, dass das > escaped werden muss\> -
@homoran
Mir ist erst bei den Screenshots aufgefallen, dass das Dropdownfeld Num = 0 gemeint ist. Sorry!Ein escape bringt leider keine Änderung.
Mein Irrtum bringt das gewünschte Ergebnis

@tom_33 sagte in Parser und Umlaute:
ir ist erst bei den Screenshots aufgefallen, dass das Dropdownfeld Num = 0 gemeint ist. Sorry!

@tom_33 sagte in Parser und Umlaute:
Ein escape bringt leider keine Änderung.
Hab es jetzt erkannt (
Windstillist die Himmelsrichtung) Da muss ich nochmal ran,
Hab leider gerade alles zu gemacht :-(Edit:
versuch mal:Wind<[^:]+[^>]+[^\w]+([\w,ü]+), -
@tom_33 sagte in Parser und Umlaute:
ir ist erst bei den Screenshots aufgefallen, dass das Dropdownfeld Num = 0 gemeint ist. Sorry!
@tom_33 sagte in Parser und Umlaute:
Ein escape bringt leider keine Änderung.
Hab es jetzt erkannt (
Windstillist die Himmelsrichtung) Da muss ich nochmal ran,
Hab leider gerade alles zu gemacht :-(Edit:
versuch mal:Wind<[^:]+[^>]+[^\w]+([\w,ü]+), -
@homoran sagte in Parser und Umlaute:
Wind<[^:]+[^>]+[^\w]+([\w,ü]+),
Bingo!
Eine Spende ist inzwischen an die GmbH gegangen.
Vielen, vielen Dank
sg tom@tom_33 sagte in Parser und Umlaute:
Bingo!
und nimm das Komma wieder in den
[ ]raus ;-)
das hat sich dahin verirrtkorrekt:
Wind<[^:]+[^>]+[^\w]+([\wü]+), -
@homoran sagte in Parser und Umlaute:
So aufgedröselt und fein erklärt gehts ja, aber selbst auszudenken - da ist bei mir schon lange Schluss
Ein bisschen verwirrend ist, dass regex101 nicht die gleichen Resultate liefert.und zuletzt bestimmt die 0 (null) keine weiteren Zeichen mehr auszugeben?
@tom_33 sagte in Parser und Umlaute:
@homoran sagte in Parser und Umlaute:
So aufgedröselt und fein erklärt gehts ja, aber selbst auszudenken - da ist bei mir schon lange Schluss
Ein bisschen verwirrend ist, dass regex101 nicht die gleichen Resultate liefert.und zuletzt bestimmt die 0 (null) keine weiteren Zeichen mehr auszugeben?
Regex liefert eigentlich schon die gleichen Ergebnisse. Nur sind die voreingestellten Optionen bei regex101 andere wie beim parser
Regex101 = gm
Parser = siWenn man in regex 101 si als Optionen auswählt dann kommt man dem parser Verhalten näher.
Ich hatte mal in den source reingeschaut, aber unter bestimmten Umständen ändert er die Optionen wiederOk Korrektur, hab gerade mal in den source geschaut.
Wenn eine item Nummer angegeben wurde dann Option g
Wenn item Nummer nicht angegeben, dann keine Option.
Dafür werden aber generell alle Zeilenumbrüche vor dem parsen in Leerzeichen umgewandelt. -
@tom_33 sagte in Parser und Umlaute:
@homoran sagte in Parser und Umlaute:
So aufgedröselt und fein erklärt gehts ja, aber selbst auszudenken - da ist bei mir schon lange Schluss
Ein bisschen verwirrend ist, dass regex101 nicht die gleichen Resultate liefert.und zuletzt bestimmt die 0 (null) keine weiteren Zeichen mehr auszugeben?
Regex liefert eigentlich schon die gleichen Ergebnisse. Nur sind die voreingestellten Optionen bei regex101 andere wie beim parser
Regex101 = gm
Parser = siWenn man in regex 101 si als Optionen auswählt dann kommt man dem parser Verhalten näher.
Ich hatte mal in den source reingeschaut, aber unter bestimmten Umständen ändert er die Optionen wiederOk Korrektur, hab gerade mal in den source geschaut.
Wenn eine item Nummer angegeben wurde dann Option g
Wenn item Nummer nicht angegeben, dann keine Option.
Dafür werden aber generell alle Zeilenumbrüche vor dem parsen in Leerzeichen umgewandelt.@oliverio sagte in Parser und Umlaute:
Nur sind die voreingestellten Optionen bei regex101 andere wie beim parser
Regex101 = gm
Parser = sija, aber was ist si, ich habe auf gs gestellt.
\n kann der Parser z.B. nicht
$ anscheinend auch nichtgefährlich ist aber, wenn man die Voreinstellung nicht auf javascript ändert
kein Support per PN! - Fragen im Forum stellen -
Benutzt das Voting rechts unten im Beitrag wenn er euch geholfen hat.
Das Forum freut sich über eine Spende. Benutzt dazu den Spendenbutton oben rechts. Danke!
der Installationsfixer: curl -fsL https://iobroker.net/fix.sh | bash - -
@oliverio sagte in Parser und Umlaute:
Nur sind die voreingestellten Optionen bei regex101 andere wie beim parser
Regex101 = gm
Parser = sija, aber was ist si, ich habe auf gs gestellt.
\n kann der Parser z.B. nicht
$ anscheinend auch nichtgefährlich ist aber, wenn man die Voreinstellung nicht auf javascript ändert
@homoran sagte in Parser und Umlaute:
@oliverio sagte in Parser und Umlaute:
Nur sind die voreingestellten Optionen bei regex101 andere wie beim parser
Regex101 = gm
Parser = sija, aber was ist si, ich habe auf gs gestellt.
\n kann der Parser z.B. nicht
$ anscheinend auch nichtgefährlich ist aber, wenn man die Voreinstellung nicht auf javascript ändert
Siebe mein angepasster Post oben.
Zeilen Anfang ^ und Zeitenende $ gibt es halt dann nur ein einziges Mal. Nämlich am Anfang der Datei und am Ende der Datei, da alles dann nur noch aus einer Zeile besteht.
Ich fände es schön wenn der parser Adapter oder parser2? Adapter genau so wie regex101 funktionieren würde und man nur noch den regex String und Optionen übernehmen müsste.
g heißt global Match und gibt alle gefundenen Ergebnisse und nicht nur das erste zurück.
i ist case insensitive also keine Unterscheidung von gross und Kleinbuchstaben
s steht für single line , dass heist Zeilenumbrüche werden herausgefiltert (und nicht mit einem Leerzeichen ersetzt wie im parser Adapter) -
@homoran sagte in Parser und Umlaute:
@oliverio sagte in Parser und Umlaute:
Nur sind die voreingestellten Optionen bei regex101 andere wie beim parser
Regex101 = gm
Parser = sija, aber was ist si, ich habe auf gs gestellt.
\n kann der Parser z.B. nicht
$ anscheinend auch nichtgefährlich ist aber, wenn man die Voreinstellung nicht auf javascript ändert
Siebe mein angepasster Post oben.
Zeilen Anfang ^ und Zeitenende $ gibt es halt dann nur ein einziges Mal. Nämlich am Anfang der Datei und am Ende der Datei, da alles dann nur noch aus einer Zeile besteht.
Ich fände es schön wenn der parser Adapter oder parser2? Adapter genau so wie regex101 funktionieren würde und man nur noch den regex String und Optionen übernehmen müsste.
g heißt global Match und gibt alle gefundenen Ergebnisse und nicht nur das erste zurück.
i ist case insensitive also keine Unterscheidung von gross und Kleinbuchstaben
s steht für single line , dass heist Zeilenumbrüche werden herausgefiltert (und nicht mit einem Leerzeichen ersetzt wie im parser Adapter)@oliverio sagte in Parser und Umlaute:
Ich fände es schön wenn der parser Adapter oder parser2? Adapter genau so wie regex101 funktionieren würde und man nur noch den regex String und Optionen übernehmen müsste.

und wenn man dann in parser3 noch (optional) einen Browser-Header und Credentials mitgeben könnte wäre das die Kirsche auf der Sahne
@oliverio sagte in Parser und Umlaute:
i ist case insensitive also keine Unterscheidung von gross und Kleinbuchstaben
heisst das, dass der Parser case insensitiv arbeitet?
Das wärte natüerlich wichtig zu wissenkein Support per PN! - Fragen im Forum stellen -
Benutzt das Voting rechts unten im Beitrag wenn er euch geholfen hat.
Das Forum freut sich über eine Spende. Benutzt dazu den Spendenbutton oben rechts. Danke!
der Installationsfixer: curl -fsL https://iobroker.net/fix.sh | bash - -
@oliverio sagte in Parser und Umlaute:
Ich fände es schön wenn der parser Adapter oder parser2? Adapter genau so wie regex101 funktionieren würde und man nur noch den regex String und Optionen übernehmen müsste.
und wenn man dann in parser3 noch (optional) einen Browser-Header und Credentials mitgeben könnte wäre das die Kirsche auf der Sahne
@oliverio sagte in Parser und Umlaute:
i ist case insensitive also keine Unterscheidung von gross und Kleinbuchstaben
heisst das, dass der Parser case insensitiv arbeitet?
Das wärte natüerlich wichtig zu wissen@homoran
Nein nicht case insensitive.
Option I ist nicht angegeben.
Wobei da etwas vorgesehen ist was aber wohl nicht von der Oberfläche aus angesprochen wirdWenn im jeweiligen datenpunkt eines oder mehrere der folgenden Schlüsselworte mit angegeben ist, dann werden diese Optionen verwendet.
https://github.com/ioBroker/ioBroker.parser/blob/e34122ce3aee43c24c44fe3b9375b07a49c551d0/main.js#L148Das kann man aber nur im raw Modus auf dem datenpunkt direkt pflegen.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden271
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge