Adapter - Parser (regEx)
-
ahhh okay und im parser Adapter passiert erst die unterscheidung welchen Wert über NUM !
Ich glaub jetzt hab ichs")
Ich werds mal so versuchen anzulegen und schaue wie es sich verhält.
Vielen Dank für die Hilfe!
Beste Grüße
-
@Qlink Mein zweiter Vorschlag war ja auch für den Parser. Hab ja geschrieben dass der Adapter keinen Zeilenumbruch braucht.
Um mit regex101 wirklich den regex für den Adapter erarbeiten zu können, muss man die Quell Daten "minified" machen. Also alle Einrückungen und Zeilenumbrüche entfernen.
Der Rest wurde hier glaube ausreichend erklärt. -
@Qlink sagte in Adapter - Parser (regEx):
im parser Adapter passiert erst die unterscheidung welchen Wert über NUM !
Ja!
Entweder musst du für jeden Fall ein eindeutiges RegEx bauen, so dass es nur ein match gibt, oder du nimmst ein möglichst universelles (aber Achtung, da sollte kein Mist bei rauskommen) und filterst dann die z.B.21 matches über die Num
-
@Homoran Ich bevorzuge eindeutige Matches so es denn unique Werte gibt mit denen das möglich ist. Wenn man mehrere Werte aus einer Quelle will, muss man so oder so mehrere Objekte mit jeweils einem RegEx erstellen. Man kann natürlich bei z.B. 3 Werten und einem universellen RegEx mit 3 Klammerpaaren dann mit Num 0-2 arbeiten, aber ich hab eben lieber 3 verschiedene RegEx die exakt nur da matchen wo einer der 3 Werte existiert.
Je nach Quelldaten kann es aber sein dass man Num braucht. -
@Diginix
ich eigentlich auch.Nur für Einsteiger mit dem Parser-Adapter kann es einfacher sein, den RegEx zu kopieren und die num einzustellen
-
Ich habe jetzt soweit alle Werte.
Einzig die geschätzte Laufzeit meiner USV ärgert mich etwas. Ich würde gerne 1 oder 2 Nachkommastellen ebenfalls auslesen, bekomme aber nur Stellen vor dem Komma:
mit
"Estimated Runtime"[^\:]+:\s\"(\d+){ "SensorApp": "HWiNFO", "SensorClass": "UPS", "SensorName": "Estimated Runtime", "SensorValue": "51,6833333333333", "SensorUnit": "min", "SensorUpdateTime": 1559130047 },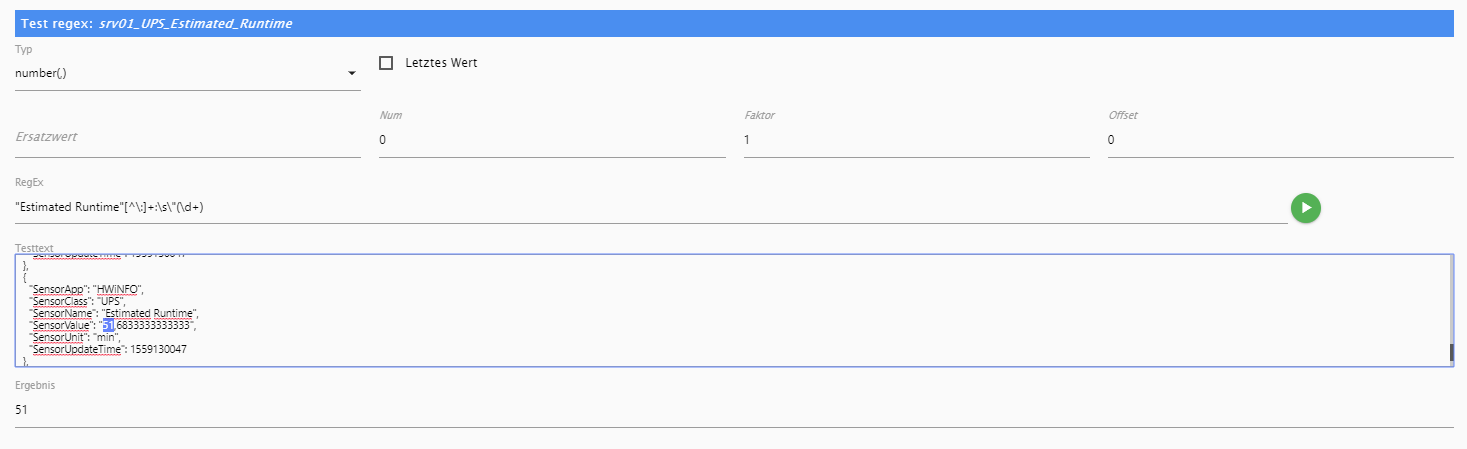
-
@Qlink
Die zahl beinhaltet ein komma.Versuch mal als typ "zahl mit komma"
-
Nummer mit Komma ist im Parser Adapter ausgewählt:

-
@Qlink \d matcht nur bei Ziffern. Gebrochene Zahlen enthalten aber Ziffern plus Dezimaltrennzeichen. Auch wenn dieser ein Punkt ist, würde \d nicht matchen. Alle Trennzeichen müssen explizit mit ins regex.
So sollte es funktionieren:
"Estimated Runtime"[^\:]+:\s\"(\d+,\d+) -
Super, danke so klappts auch mit den Nachkommastellen !
Beste Grüße
-
Hallo zusammen,
ich komme mit dem Parser nicht zurecht. Ich versuche von der Seite https://abfahrten.hvv.de/75870033-9dd4-41c0-81bb-903c93fdc819 Bus-Nummer, Richtung und Abfahrzeit auszulesen. Ich habe dunkle Views erstellt, da passt die weiße Farbe einfach nicht rein. Leider schaffe ich jedoch nicht, mit dem Parser etwas auszulesen. Kann mir dabei jemand helfen?
Danke schon vorab!
-
So wie es aussieht werden die Werte per Javascript in der Seite gesetzt. Ich weiß nicht ob der Parser das erst noch interpretiert oder ob der nur mit statischem html umgehen kann.
-
Schade... Gibt es denn eine andere Möglichkeit die Daten auszulesen? Oder zumindest die Farben der eingebundenen Webseite zu invertieren?
-
Kurze Verständnis Frage, ich parse auf der clever-tanken Seite einen Super Plus Wert z.B. Tanke
Mit dem RegEx
(?:4">)(\d+.\d.)bekomme ich auch über die regex101 Seite einen entsprechenden Match der auch wunderbar passt. Wenn ich mir nun den erzeugten Datenpunkt anschaue, finde ich dort nur den Wert ohne Punkt angezeigt:

Ansonsten steht die Regel auf Rolle "Wert" und der Typ ist "Nummer mit Komma", wo hab ich den Denkfehler?
Danke für Hinweise.
-
@hannoi sagte in Adapter - Parser (regEx):
der Typ ist "Nummer mit Komma", wo hab ich den Denkfehler?
Wo ist das Komma?
-
Genau das Komma suche ich in den Objekten

In den Parser Settings habe ich es entsprechend als Typ "Nummer mit Komma" deklariert... -
@hannoi sagte in Adapter - Parser (regEx):
Genau das Komma suche ich in den Objekten
Aber du hast doch auch kein Komma im Match, oder?
-
Hier noch der Link mit dem Quellcode und dem Regex
-
@hannoi sagte in Adapter - Parser (regEx):
finde ich dort nur den Wert ohne Punkt angezeigt:
-
Okay verstanden, dann ist das "Komma" nicht mit dem "Punkt" gleichzusetzen als Trennzeichen.
