Meeting für ioBroker Core/Dev/Admin 14.07.20 20:30
-
@Mic sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
ioBroker ist zum allergrößten Teil einfach Deutsch.
91,81 %
Das sagt Alles. -
Hm ... @Mic muss ehrlich sagen das ich das einerseits verstehen kann, andererseits seehr shwierig finde.
Projektseitig haben wir die weiteren Sprachen (Sehr lange gab es deutsch,englisch und Russisch) nach Absprache mit (einer damals noch etwas kleineren) Entwicklergruppe und auch User-Gruppe eingeführt um genau ioBroker aus dem "nur Deutschland" rauszubringen und auch um besser andere Smart-Home Systeme angreifen zu können! Chinesisch kam dazu als es dort losging und sich eine eigene Community gebildet hat. So ein switch dauert aber Zeit! Und fehlende Übersetzungen schrecken dann neue User aus anderen Sprachregionen ganz einfach ab! Das ist die andere Seite der Medallie
Es gibt Tools um die Übersetzungen für die Entwickler zu erleichtern bzw zu automatisieren. @ldittmar hat gulp Skripte dazu gebaut die integriert sein sollten, es gibt https://translator.iobroker.in/ für manuellere Übersetzungen.
Die Realität ist das ein User das was Du beschreibst ggf nicht akzeptiert sondern einfach den Adapter nicht nutzt ...oder Ihn fluchend nutzt weil er anders tickt als die 352 anderen Adapter")
Was das Thema "usebility" und "Admin UIs besser machen" mit den Übersetzungen zu tun hat weiss ich nicht nicht, aber ja wenn es darum geht texte nicht auslagern zu müssen ... naja
")
Ich hatte auch vor einiger Zeit mal mit Optionen überlegt (Fragezeichen Icons mit mouse-over Erklärungen der Einstellungen), aber am Ende bin ich kein Web-Designer ... Womit wir am Ende wieder beim Adapter-Konfiguration Styleguide und so wärenGitHub ist in meinen Augen sprachlich ob Deutsch oder Englisch fast egal ... ich zwinge keinen dort englisch zu sprechen
Mehrsprachige Log Ausgaben finde ich persönlich wiederum überflüssig und sogar komplett nicht hilfreich - vor allem wenn die Logs zur Fehlersuche genutzt werden durch MICH dem Entwickler dann muss ich danach suchen können im Code ... und ich muss damit die Logik verstehen können. Mehrsprachigkeit hier hilft MIR nicht ... und da behaupte ich jetzt das 90% der User keine Logs lesen und daher
Fakt ist auch - und das macht die Thematik sehr grenzwertig - das der Adapter Checker im Repo die Übersetzungen prüft und mal mindestens neue Adapter die nicht wenigstens teilweise die Hauptsprachen unterstützen in jedem Fall nach den aktuellen Regeln nicht ins Repo kommen. Das würde auch auf Deinen Adapter zutreffen.
Bestandsadapter geniessen aktuell noch irgendwie so eine Art Vogelfreien Status, aber auch diese prüfen wir bei stable updates mit dem Repo-Checker ...
Du schaffst hier gerade einen Präzedenzfall ... und ich hätte es besser gefunden wenn Du solche Entscheidungen vorher vllt mal angesprochen hättest. Versteh mich bitte nicht falsch und ich will Dir garantiert keine Stöcke zwischen die Füsse werfen oder gar das du jetzt angepisst keine Adapter mehr baust ... aber irgendwie ist es halt ein miteinander und eine Balance ...
Ingo
-
@apollon77
Hi Ingo,Zunächst: Ich bin absolut dafür, dass wir Internationalisierung brauchen. Ich zitiere mich mal selbst vom August 2018:
Mich persönlich nervt noch, dass ioBroker viel zu wenig bekannt im englischsprachigen Raum ist, obwohl die Community alles dafür macht (englische Hilfe, englischsprachiges Forum, GitHub so weit es geht in Englisch, etc.). Bin mir da noch nicht sicher, wie wir das weiter unterstützen können…. :roll: Aber auch das wird noch kommen. Ein Blog hilft hier schon mal sehr um in den Fokus zu kommen, und ich bin gerne auch mal bei englischsprachigen Artikeln behilflich, falls das angedacht ist.
Hier mal ein einfaches Beispiel, was ich meine:
Ich füge eine neue Tabellenspalte in den Optionen in der
index_m.htmlein.<th style="width: 120px" class="header translate" data-name="offValue">'off' value</th>Diese neue Option beschreibe ich in der
index_m.htmlentsprechend:<td> State value, which is set in 'state for switching device off'. You can use <code>true</code>, <code>false</code>, numbers like <code>144</code>, or strings like <code>Turn Radio on</code>. Note: Any white spaces or quotation marks (like <code>"</code>) at the beginning or end will be disregarded. </td>Das dauert wohl so 2-3 Minuten als Entwickler.
Nun wäre ich eigentlich schon fertig.
Schritte die ich als Entwickler nun manuell durchführen muss:
admin/i18n/en/translations.json: Übersetzung für "'off' value" hinzufügen.- Das HTML in
index_m.htmlfür "State value, which is set ..." umformatieren, so dass es mir z.B.trueoderfalsenicht übersetzt, die zusätzlichen HTML-Tags "code" usw. beibehält, etc. Sehr mühsam und zeitaufwändig. Und passt auch nicht von der Reihenfolge her für die einzelnen Sprachen (Satzbau, Grammatik, Zeichensetzung, etc.):
<td> <span class="translate">State value, which is set in 'state for switching device off'. You can use </span><code>true</code>, <code>false</code>, <span class="translate">numbers like </span><code>144</code><span class="translate">, or strings like </span><code><span class="translate">Turn Radio on</span></code>. <span class="translate">Note: Any white spaces or quotation marks (like </span><code>"</code>)<span class="translate"> at the beginning or end will be disregarded.</span> </td>(hab das hier reingetippt jetzt, sicherlich noch Fehler im HTML, die ich jetzt noch debuggen müsste, prüfen wie es aussieht im Admin, ...)
admin/i18n/en/translations.json: Alle nun neuen Übersetzungen derindex_m.htmlwieder hier mühsam manuell per Copy & Paste einfügen- Gulp Übersetzung ausführen. Ggf. muss ich nach erfolglosem Google Translate (zu viel in kurzer Zeit übersetzt ) auf Yandex aufweichen (mit schlechterer Übersetzungsqualität und mehr Arbeit im Nachgang für mich)
- Deutsche Übersetzung korrigieren, weil oft schlecht übersetzt und manche Begriffe wie z.B. "State" irreführend für den Anwender übersetzt werden. Dabei muss ich mühsam die Quelle ansehen und vergleichen, auch weil Satzteile übersetzt wurden die so nicht zusammen passen, einzeln zusammen suchen, usw.
- Ggf. zurückgehen zu Punkt 2 (
index_m.html) und diese noch mal korrigieren und 3-5 erneut durchlaufen.
Der zusätzliche Aufwand für dieses Beispiel geschätzt: 30 Minuten. Das steht für mich in keinem Verhältnis zu den ursprünglich 2-3 Minuten.
Wenn man sich etwas umschaut, dann liest man z.B. Folgendes auf github.com/thomas-darling/gulp-translate:
In a traditional localization workflow, localizable content is assigned unique ids and stored in a separate file. Templates that need the content can then import it by referencing its id. While this approach can work in some apps, it has significant drawbacks that often make it annoying, inefficient and error prone in larger apps.
Scheint aber immer noch eher aufwändig, habe es mir noch nicht näher angesehen. Unique Ids ist jedenfalls wirklich nicht Entwickler-freundlich wie hier beschrieben:
In many solutions, all strings that need to be translated are stored in a separate string-file, and the templates then reference those strings by id, often using client-side data binding. While this approach does work, it has significant drawbacks that make it annoying, inefficient and error prone in larger apps.
@apollon77 sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
Mehrsprachige Log Ausgaben finde ich persönlich wiederum überflüssig und sogar komplett nicht hilfreich - vor allem wenn die Logs zur Fehlersuche genutzt werden durch MICH dem Entwickler dann muss ich danach suchen können im Code ... und ich muss damit die Logik verstehen können. Mehrsprachigkeit hier hilft MIR nicht ... und da behaupte ich jetzt das 90% der User keine Logs lesen und daher
Sehr guter Punkt wegen Fehlersuche, du hast absolut recht, und da geht's mir genau so
Ich dachte da auch hauptsächlich an den Endanwender wegen Info-Log-Ausgaben. Aber das lässt sich wohl auch alternativ gut bzw. besser über Adapter-Konfig lösen, in der dann der User die Ino-Log-Texte für die einzelnen Szenarien selbst hinterlegen kann.@apollon77 sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
Fakt ist auch - und das macht die Thematik sehr grenzwertig - das der Adapter Checker im Repo die Übersetzungen prüft und mal mindestens neue Adapter die nicht wenigstens teilweise die Hauptsprachen unterstützen in jedem Fall nach den aktuellen Regeln nicht ins Repo kommen. Das würde auch auf Deinen Adapter zutreffen.
Aktuell besteht der https://adapter-check.iobroker.in/ meine "Übersetzungen" von https://github.com/Mic-M/ioBroker.smartcontrol tatsächlich wunderbar
Die index_m.htmlwird wohl nicht näher gecheckt wird aufclass:translateversus vorhandener Ids inwords.jsund evtueller Diskrepanzen. Aber ich weiß, was du meinst, der Adapter entspricht so sicherlich nicht dem gewünschten "Standard". Ich bin sehr gerne regelkonform, die Gründe für die Abweichung beschreibe ich auch hier@apollon77 sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
Du schaffst hier gerade einen Präzedenzfall ... und ich hätte es besser gefunden wenn Du solche Entscheidungen vorher vllt mal angesprochen hättest.
Ich bin absolut deiner Meinung, dass mein alternatives Vorgehen eine Abstimmung erfordert und das ganze ein Miteinander ist. Sorry für das vorpreschen. Aber für meine Alpha/Beta-Version des Adapters muss(te) ich jedoch priorisieren und zügig eine Entscheidung treffen, denn sonst würde sich das wohl wochen- bzw. monatelang ziehen und ich müsste zwischenzeitlich nach dem alten, gewohnten Schema vorgehen, wofür ich einfach keine Zeit habe (siehe oben das kleine Beispiel) und den Adapter damit komplett einstampfen mangels Zeit. Hab da auch einfach keine Lust zu, sorry.
Ich bin daher auch schmerzfrei, wenn der Adapter dadurch nicht ins Latest kommt, weil ich einfach nicht die Zeit für diese Zusatztätigkeiten habe und keine Lust auf eine Sehnenscheidenentzündung wegen dem vielen manuellen Copy/Paste etc.
Mein Ziel ist es, dem Anwender einen möglichst einfach zu konfigurierenden Adapter zu bieten, das muss ich als "Adapter-Schöpfer" einfach bieten. Da Smart Control komplex (im Vergleich zu einigen andern Adaptern) in den Einstellungen ist, ist es aus meiner Sicht aus User Acceptence Gründen umso wichtiger, dass Erklärungen zu den Optionen intuitiv und direkt ohne Medienbruch verfügbar sind. Kann doch nicht sein, dass in der Konfig gefühlt nur "Hieroglyphen" sind und man nicht weiter kommt. Da verliert man schnell die Lust als Anwender, und da spreche ich selbst aus Erfahrung, deswegen will ich das unbedingt selbst besser machen.@apollon77 sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
Versteh mich bitte nicht falsch und ich will Dir garantiert keine Stöcke zwischen die Füsse werfen oder gar das du jetzt angepisst keine Adapter mehr baust ... aber irgendwie ist es halt ein miteinander und eine Balance ...
Keine Sorge, ich werfe nicht hin
Vielen Dank für deine konstruktive Antwort und Kritik. Ich bin absolut deiner Meinung, dass das ganze ein Miteinander und eine Balance ist und kann all deine Punkte sehr gut nachvollziehen.
Ich hoffe, ich konnte oben meine Beweggründe verständlicher darlegen.Zusammengefasst ist mein Haupt-Beweggrund: in begrenzter Zeit möglichst viel dem ioBroker-Anwender als Entwickler zu bieten, und Manuelles in der Entwicklung so weit es geht zu vermeiden. Im Quellcode verwendet man ja auch Klassen, Funktionen und Eigenschaften, in Verbindung mit Schleifen etc., um wiederkehrendes zu kapseln und den Code nur einmalig schreiben zu müssen. Analog dazu sollte das auch bei den Übersetzungen sein um uns als Entwicklern möglichst manuelle Arbeit zu vermeiden bei der Entwicklung und Pflege des Adapters...
-
Test. HTML scheint defekt im letzten Beitrag von mir
-
ja irgendwie hats das jetzt zerballert

Ich verstehe auch Deine Argumente und sind natürlich auch immer ein nerviges Thema als Entwickler, wie ich nur zu gut selbst kenne :-).
Das der Ansatz mit dem "eindeutigen IDs für lokalisierbare Inhalte" nicht perfekt ist ist denke überall bekannt ... aber eine echte Alternative gibts irgendwie auch nichtWäre damit nicht eine Idee ein "gulp" Dingens oder ein Skript zu schreiben was es erlaubt bestimmt "geschriebenes html" zu parsen und anzupassen?
Also sowas wie ein tag "translate" was als property die text-ID oder sowas hat und ggf. eine Notation "nicht zu übersetzende teile" zu markieren die dann auch behandelt werden. Dann kann man das initial einfach so schreiben und am Ende lässt man das Skript drüber rennen was diese Art von Sonder-Tags nimmt, in die transpation files einfügt und so ... Das text Polishing (De/en) ist denke immer mit dabei ... da kommt man nicht drum rum fürchte ich.Lasst uns doch mal Kreativ werden wie wir dieses nervige Problem so angehen können mit dem was wir können ... Coden
Vllt kriegen wir die 30 mins so auf 10 "am Ende einer Änderung" runter
Ingo
-
@ldittmar sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
Nicht Open Source Abhängigkeiten im ioBroker Core -> Redis Protokoll (Jey Cee)
Object in Redis - Bluefox, Apollon77 und Foxriver haben Zugriff
SocketIO war nicht stabil und verursachte Probleme
Alles geht jetzt über Redis
Object Kommunikation wird wieder OpenSourceSeit 29.07.20 ist objects-redis Open Source unter Apache 2.0 Lizenz.
-
Ich konnte jetzt nur durch einen Trick hier antworten (weiter oben vor dem Fehler bei einem Beitrag auf "Antwort" klicken. Siehe Thread: https://forum.iobroker.net/topic/35464/fehler-in-forum-thread-html-markdown-problem
Wäre damit nicht eine Idee ein "gulp" Dingens oder ein Skript zu schreiben was es erlaubt bestimmt "geschriebenes html" zu parsen und anzupassen?
An gulp dachte ich auch, wollte auch schon selbst was implementieren, aber dann schnell festgestellt, dass ich zu wenig/keine Erfahrung mit gulp hab und daher aus Zeitgründen verworfen.
Also sowas wie ein tag "translate" was als property die text-ID oder sowas hat und ggf. eine Notation "nicht zu übersetzende teile" zu markieren die dann auch behandelt werden.
Ja, genau, also
index_m.htmlper gulp.Beispiel, so etwas sollte halt dann übersetzt werden:
<td class="translate"> Sobald der Wert vom Datenpunkt mit diesem Wert übereinstimmt, wird der Auslöser aktiviert. <br>Du kannst <code>true</code>, <code>false</code>, Nummern wie <code>144</code>, or Strings wie <code>ABCDEF</code> verwenden. <br> <br>Ebenso kannst du die Vergleichs-Operatoren <code>></code>, <code><</code>, <code>>=</code> und <code><=</code> vor Zahlen schreiben. <br>Um also auszulösen, wenn z.B. die Temperatur größer als 20°C ist, trägst du <code>>20</code> ein. <br> <br>Sämtliche Leerzeichen und Anführungszeichen (wie <code>"</code>) am Anfang und Ende werden automatisch entfernt. </td>Ausgangstext muss dann aber in Englisch sein, wobei auch als gulp-Option in Landessprache vorstellbar wäre...
Hierbei müssen ein paar HTML-Tags ignoriert werden, z.b.
<code>. Satzteile formatiert (z.B.<bold>etc.) sollen übersetzt werden.
Evtl. noch eine "translate-ignore" CSS-Klasse für manche Teile (z.B.<span class="translate-ignore">Mich ignorieren</span>Soweit die Idee
Dann kann man das initial einfach so schreiben und am Ende lässt man das Skript drüber rennen was diese Art von Sonder-Tags nimmt, in die transpation files einfügt und so ... Das text Polishing (De/en) ist denke immer mit dabei ... da kommt man nicht drum rum fürchte ich.
Das wäre super. Und klar, deutsch/englisch Anpassungen werden immer sein. Wobei man theoretisch auch die Quellsprache per gulp Option festlegen könnte.
Nachteil wäre aber:index_m.htmlenthält dann deutsche Texte (oder spanische, etc.), also nicht so schön zu pflegen für andere Entwickler.Weitere Ideen?
-
@Mic
Das klingt nach einer super Lösung. -
@Mic Ich denke für die "nicht zu übersetzenden texte" müsste man sie erkennen, durch Platzhalter ersetzen die nicht übersetzt werden und dann nach der Übersetzung zurück-einsetzen. müsste man in entsprechende "Tags" einschliessen ...(zB wie Du in "code").
Aber auch wichtig für die erkennung wäre noch ein "<div>" aussen rum.
Also etwas wie
<td class="translate">
<div translation_id="meinCoolerText">....<code>do not translate</code>...</div>
</td>... müsste man jetzt nur noch bauen
@ldittmar Schon nach dem Urlaub was vor? ;-)))
-
@apollon77 said in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
<div translation_id="meinCoolerText">
Wofür brauchst du die id dann noch? Ich hatte den Ansatz von @Mic so verstanden, dass er ja gerade das mit den IDs nicht mehr will und das im Grunde alles automatisch generiert werden soll -> das könnte ja dann die IDs direkt mit generieren, damit man da nicht wieder in das Problem läuft, dass IDs nicht gepflegt werden (nicht eindeutig, ungenutzt, blah).
Oder hab ich da was falsch verstanden / übersehen?
-
@Garfonso Naja die Idee ist ja das Mapping zu Loca-IDs und damit das "auslagern in die words.js" zu automatisieren. ich kennen aktuell noch keinen sinnvollen Weg ohne dies. Bei einfachen texten geht es auch ihne indem der Text zum KEy wird, aber sobald das komplexer wird wird das ziemlich blöd finde ich ...
-
@apollon77 sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
Bei einfachen texten geht es auch ihne indem der Text zum KEy wird, aber sobald das komplexer wird wird das ziemlich blöd finde ich ...
Die Fehlermeldungen vom TypeScript-Compiler werden beispielsweise genau so generiert.
-
Hi zusammen,
- Hier noch mal der initiale Beitrag von mir zu dieser Diskussion.
- Und hier der derzeitige Aufwand für Entwickler aus meiner Sichtweise.
@AlCalzone sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
@apollon77 sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
Bei einfachen texten geht es auch ihne indem der Text zum KEy wird, aber sobald das komplexer wird wird das ziemlich blöd finde ich ...
Die Fehlermeldungen vom TypeScript-Compiler werden beispielsweise genau so generiert.
Ich kenne jetzt die Übersetzungs-Funktionalität (Stichwort
word.js) noch nicht wirklich, aber ich denke, der dafür zuständige Code müsste auch angepasst werden.Wie auch immer:
So wie ich die JavaScript-Spezifikation verstehe, darf ein Objekt-Key (also derkeybei{'key':'val'}ein beliebiges String beinhalten. Somit sind also keine Grenzen gesetzt. Lasse mich da gerne korrigieren
Damit ist es also egal, wie komplex das String ist, (Browser-)Performance mal außen vor.Jetzt kann doch ein Script folgendes machen:
index_m.htmlper jQuery: alle Inhalte, dietranslateals Klassen-Zuweisung enthalten, per Loop durchlaufen:- Inhalte übersetzen und Ergebnis in Variable und dann Zieldatei.
- Für Übersetzung: vorher definierte Tags zur Übersetzung ignorieren (z.B.
<code>true</true>oderText <span="non-translate">ioBroker<span>und einzelne Teile separat übersetzen. - Nach Übersetzung: ignorierte Bestandteile wieder in HTML-Variable hinzufügen
- Für Übersetzung: vorher definierte Tags zur Übersetzung ignorieren (z.B.
- Ergebnis ab in die
words.js:- hier dann auch bereinigen zum Schluss, d.h. unbenutzte Einträge löschen. Geht natürlich nur, wenn global verfügbar, welche Keys gesetzt wurden.
Falls das on-the-fly nicht möglich oder aus Browser-Performance-Gründen nicht sinnvoll, könnte man auch entsprechend komplilieren und "_min.xxx" Dateien generieren lassen, wie z.B. "words_min.js"
-
@Mic Also ja natürlich kann man den beliebigen Text in die Words packen ... Dann bräuchte man beim zurückschreiben noch eine Erkennung das ein text schon übersetzt ist damit er nicht nochmal wird - und man muss sich selbst dran halten sowas nicht nochmal zu editieren sondern die words.js ab der initialen Übersetzung zu nutzen ... sonst landet der neue text beim nächsten "übersetzungslauf ausführen" unter dem neuen text nochmal drin und es entstehen doubletten und riiiesige words.js Files
Daher meine Idee es durch ne unique ID zu ersetzen ... dann sieht man das gleich. geht aber bestimt auch anders.Die Logik mit Übersetzung und so (geht ja nicht in words.js sondern in die translation files denke ich) ist glaube im gulp drin. Am Ende passt eine neue Logik denke da am besten hin. Also im gulp das html parsen, texte finden und "bearbeiten".
Ansonsten: einzelne Teile überstzen geht nicht wiel sonst der Satzaufbau komplett zerstört wird. Also man muss wirklich die nicht zu übersetzenden Teile rausholen und durch etwas ersetzen was er nicht übersetzt, und danach den ganzen Text mit den Platzhaltern übersetzen lassen und dann wieder die platzhalter zurück-einfügen
-
Ich werfe auch mal https://weblate.org/de/ in den Raum, UncleSam hat mich darauf aufmerksam gemacht
@UncleSam sagte in Gulp ist kein Hexenwerk - Auto translation:
Hallo ldittmar
Übersetzungen sind ein schwieriges Thema. Bis jetzt müssen wir Adapter Entwickler mit Google/Yandex übersetzen und dann "native speaker" im GIT Korrekturen per PR einbringen. Bei meinem aktuellen Arbeitgeber sind wir von einem teilweise manuellen Prozess (mit Excel-Listen!) auf https://weblate.org/en/ umgestiegen.
Die Installation und Konfiguration war innert wenigen Stunden erledigt und nun können wir alle Übersetzungen in einem Online Tool pflegen - wenn nötig auch mit externen Übersetzern. Wir sind schon nach wenigen Wochen begeistert - der Prozess benötigt keine manuellen Schritte mehr für die Entwickler!
Wäre das nicht ein interessantes Tool für all die Übersetzungen von Adaptern? Es liesse sich auch jeder Adapter mit seinem eigenen GitHub Repo einbinden (sofern die entsprechenden Autoren einverstanden sind).
Wenn das Interesse vorhanden ist, kann ich auch noch etwas detaillierter über das Tool berichten und euch bei der Inbetriebnahme / Integration helfen.
/UncleSam
@UncleSam sagte in Gulp ist kein Hexenwerk - Auto translation:
Es ist Open Source und wie gesagt innert kürzester Zeit eingerichtet. Ich gehe davon aus, dass ioBroker schon eine gewisse Server Infrastruktur (respektive Cloud Infrastruktur) hat, damit würde der Preis aus meiner Sicht 0 € betragen.
@UncleSam sagte in Gulp ist kein Hexenwerk - Auto translation:
Die Einrichtung ist keine grosse Sache; ein Aufwand besteht natürlich pro GIT Repo, das man anhängen will (für uns: pro Adapter).
Weblate nimmt die Übersetzungen direkt aus dem GIT und kann sie auch wieder ins GIT zurückspielen. Für GitHub gibt es die Möglichkeit über Pull Requests: https://docs.weblate.org/en/latest/vcs.html#github Damit muss Weblate nicht einmal spezielle Rechte für ein Repository haben.
Wie gesagt bin ich gerne bereit, bei der Umsetzung zu helfen und würde das auch einfach mal mit einem meiner Adapter testen, bevor wir das "ausrollen" würden. Ich will nur nicht für mich eine "Insellösung" erarbeiten, wenn wir gleich eine Lösung für (fast) alle bauen können.
Ich kenne Weblate null, aber das klingt wirklich hochinteressant!
der Prozess benötigt keine manuellen Schritte mehr für die Entwickler!
-
@Mic Danke für die zahlreichen Zitate
I18N (Internationalization) ist ein häufiges Problem und wir sind sicherlich nicht die ersten (und nicht die letzten), die sich dem annehmen müssen. Als Schweizer Softwareentwickler bin ich fast in jedem Projekt zweisprachig unterwegs (DE/FR); meist kommt noch Englisch dazu.
Die Problematik muss an zwei Stellen angegangen werden:
- Die Software muss übersetzbar sein
- Die Übersetzungen müssen einfach gepflegt werden können
Die Diskussion hier dreht sich vor allem um den ersten Punkt, mein Vorschlag für Weblate konzentriert sich auf den zweiten (nur damit wir hier nicht allzu wirr durcheinander reden).
Für 1. gibt es gute Frameworks und gute Beschreibungssprachen. Hier einige Beispiele: https://docs.weblate.org/en/latest/formats.html
Dabei ist wichtig, dass das Tool nicht nur einfache Texte übersetzen kann, sondern zum Beispiel auch mit Plural/Daten umgehen kann. ICU macht das sehr schön: http://userguide.icu-project.org/formatparse/messages :"{num_guests, plural, offset:1 " "=0 {{host} does not give a party.}" "=1 {{host} invites {guest} to her party.}" "=2 {{host} invites {guest} and one other person to her party.}" "other {{host} invites {guest} and # other people to her party.}}}"Ich denke wir müssen uns für beide Punkte auf etwas einigen und beides muss zusammen passen. Dabei würde ich versuchen, auf Standard-Tools zu setzen und nicht zu viel selber zu erfinden/entwickeln. Bis jetzt habe ich im Web-Bereich nur mit Angular I18N gearbeitet - und allein schon dort gibt es drei populäre Lösungen.
"Im Nachhinein Übersetzen" ist IMHO eine schlechte Strategie, sprich: Übersetzungen müssen von Anfang an in der Software vorgesehen sein. Irgendwie versuchen, Texte herauszusuchen und diese dann in eine Datei abzufüllen funktioniert sehr schlecht. Gerade auch Teilsätze (beim Einsetzen von Daten) können ein heilloses Durcheinander auslösen.
Automatische Übersetzungen sind ein guter erster Schritt, damit ioBroker internationaler wird, aber wer mag Software schlecht die Übersetzung sein or not all translated?
Teilweise ist schon Deutsch schwierig, beim Englisch holpert es dann doch öfters in ioBroker.Ich freue mich auf einen guten Austausch und bin gerne bereit in den nächsten Wochen Zeit in eine gute Lösung zu stecken.
-
Vielen Dank für deine Initiative, Super
Wie ist das denn mit Weblate hinsichtlich Dokumentation versus Applikation (Frontend) selbst:
Mein persönlicher Anstoß war, dass ich in
ioBroker.adapter-xyz/admin/index_m.htmlauch eine direkte Hilfe dem Anwender biete (https://github.com/Mic-M/ioBroker.smartcontrol).Dort habe ich etwa folgendes, also eine "Online-Hilfe/Dokumentation" für den Anwender:
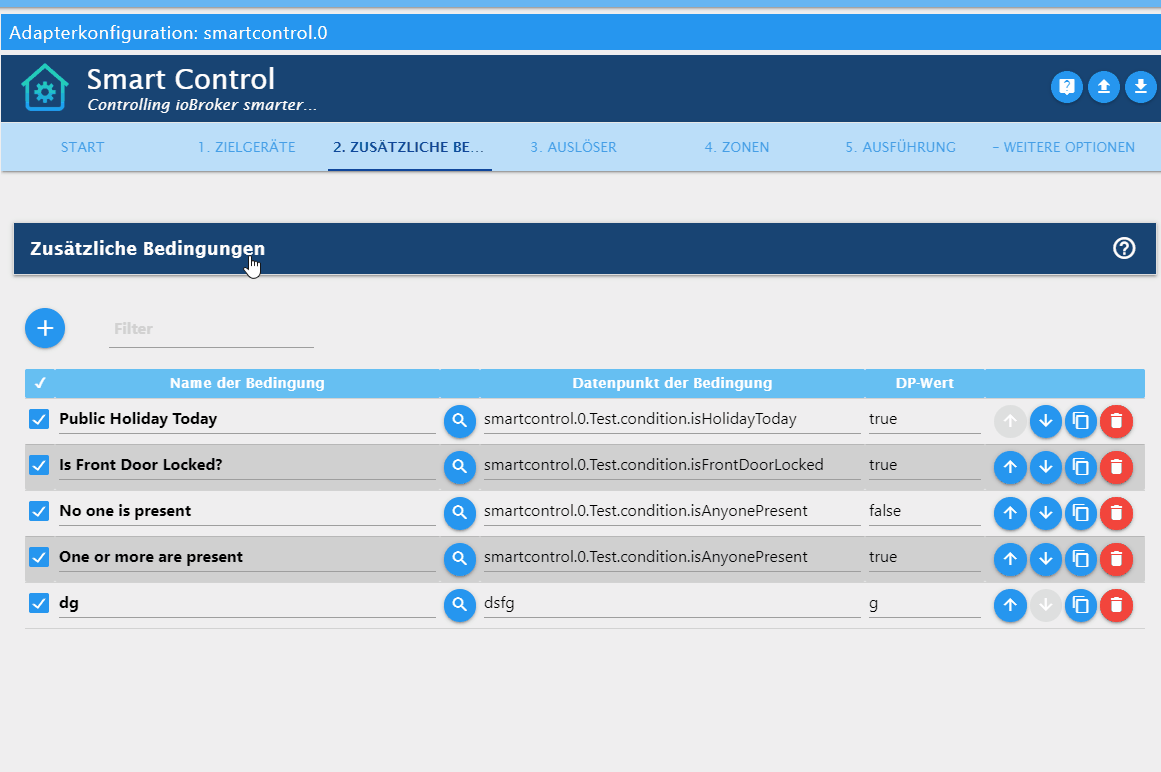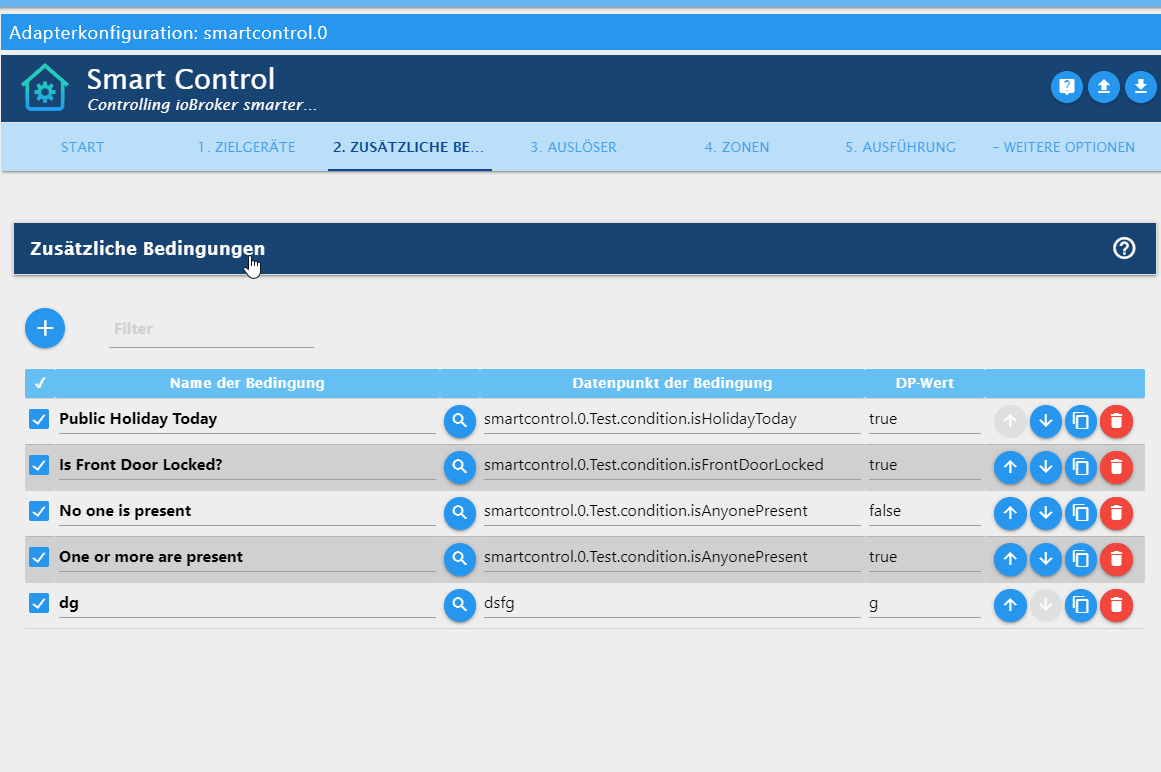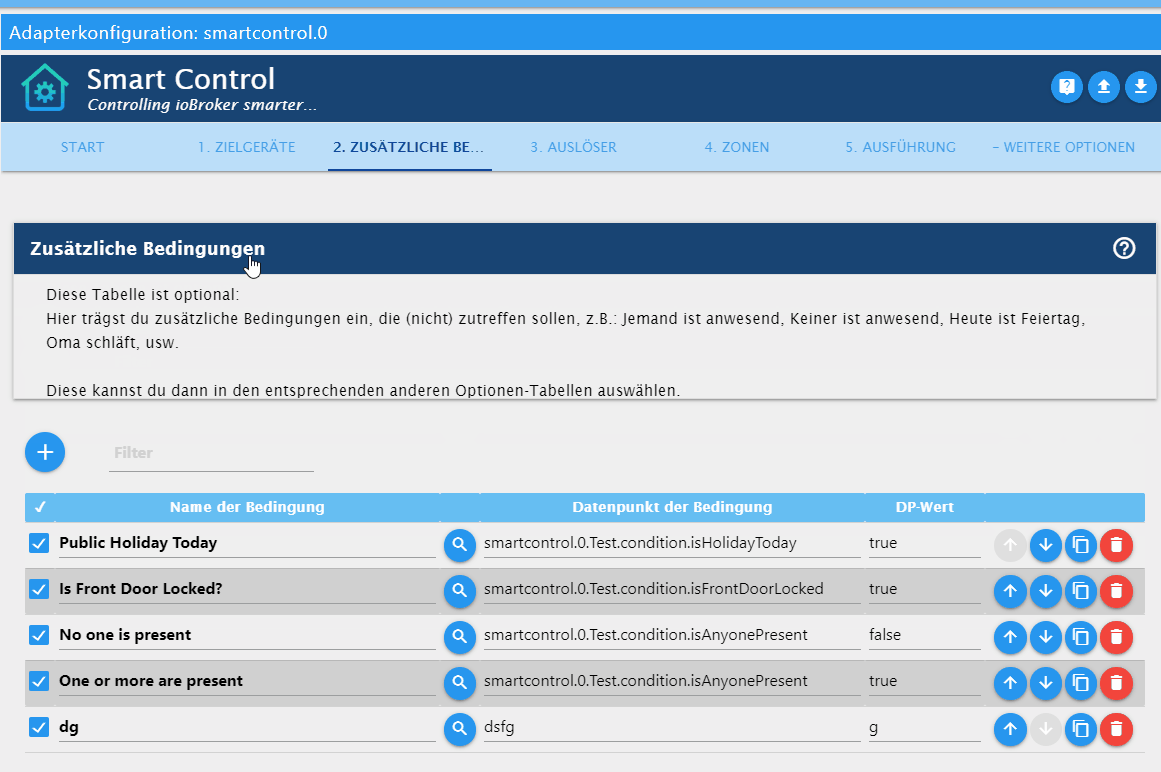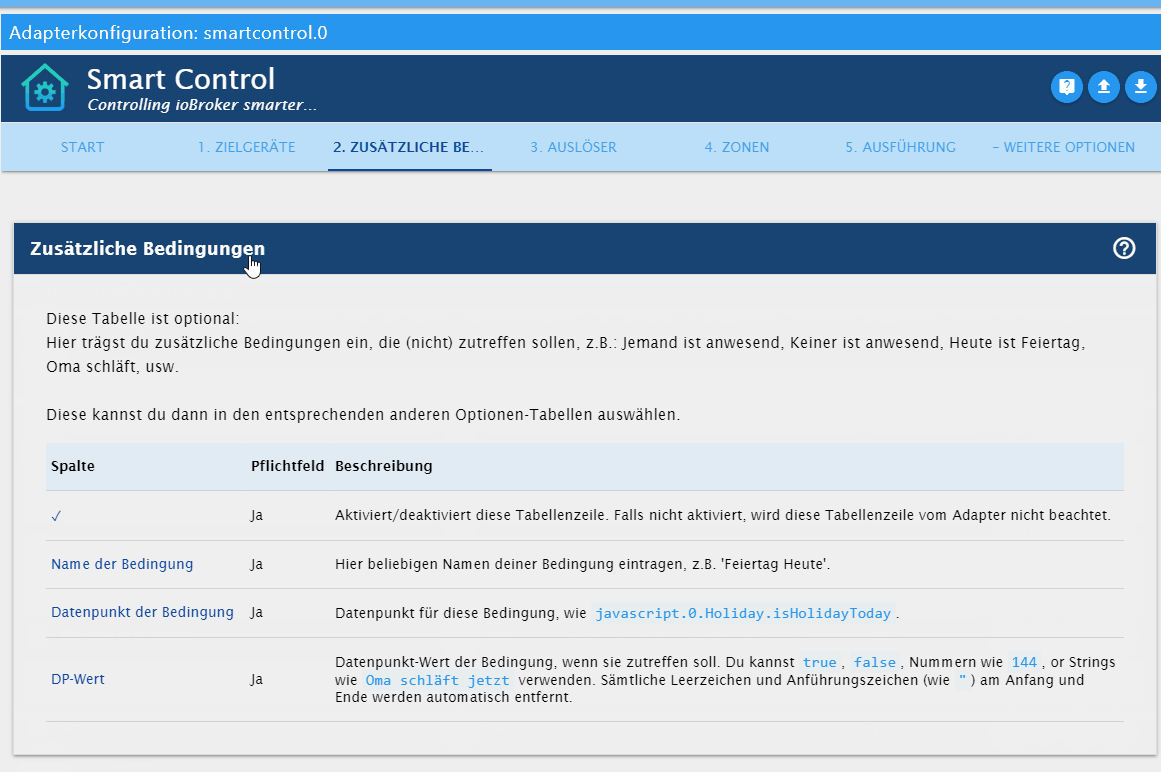
Lässt sich denn so etwas, also der Text mit der Tabelle, auch einfach mit Weblate abbilden?
Quellcode:
Oder ist Weblate primär für die "eigentliche" Software gedacht, also Auswahlfelder, Feldbezeichnungen, usw.?
-
@UncleSam Weblate kostet aber, oder ?!
-
@apollon77 selfhosted ist kostenlos.
-
@Mic sagte in Online Meeting für ioBroker Core/Dev/Admin 14.07.2020 20:30:
Lässt sich denn so etwas, also der Text mit der Tabelle, auch einfach mit Weblate abbilden?
Weblate übersetzt - nicht mehr und nicht weniger. Du hast ja bereits
class="translate"hinzugefügt, das muss dann ein Tool extrahieren (geht in deinem Fall sehr einfach) und Weblate bietet dann einfach alle Teil-Strings zur Übersetzung an.Ganze Seiten mit HTML Tags etc. würde ich nicht von Weblate übersetzen lassen (das bedingt, dass der Übersetzer HTML versteht), allerdings kann ich mir vorstellen, einfaches Markdown übersetzen zu lassen (z.B. für https://raw.githubusercontent.com/ioBroker/ioBroker.docs/master/docs/en/dev/adaptervis.md, aber eher nicht für grosse Dokumente wie https://raw.githubusercontent.com/ioBroker/ioBroker.docs/master/docs/en/dev/adapterdev.md).
Das mit dem Extrahieren ist ein wichtiger Punkt: der Entwickler muss natürlich zu übersetzenden Text irgendwie markieren, aber den markierten Text zu extrahieren sollte man unbedingt einem Tool überlassen. Sprich für ioBroker: words.js (oder was es dann auch immer sein wird) wird komplett von Weblate erzeugt, der Entwickler muss nur etwas (z.B.
class="translate"eventuell mitid="unique-id") zu jedem Tag hinzufügen, den er übersetzt haben will.
