

Test paperless-ngx Adapter
-
Hallo zusammen,
vielen Dank für den Adapter, ich bin tatsächlich der Meinung dass dieser seine Berechtigung hat. Wie ich paperless bisher in verbindung mit iobroker nutze habe ich bereits hier skizziert:
https://forum.iobroker.net/topic/70115/verzeichnis-überwachen-und-datei-in-datenpunkt-schreiben
Nun aber zu meiner Frage: mit deinem Adapter könnte ich meine bisherige Vorgehesnweise deutlich vereinfachen. Leider habe ich es bisher nicht geschafft die Dokumentensuche im Adapter so einzuschränken, dass die Suchbegriffe nur auf Dokumente mit bestimmten Tags angewendet werden. Ist dies möglich? Falls ja wie?
-
Hallo zusammen,
vielen Dank für den Adapter, ich bin tatsächlich der Meinung dass dieser seine Berechtigung hat. Wie ich paperless bisher in verbindung mit iobroker nutze habe ich bereits hier skizziert:
https://forum.iobroker.net/topic/70115/verzeichnis-überwachen-und-datei-in-datenpunkt-schreiben
Nun aber zu meiner Frage: mit deinem Adapter könnte ich meine bisherige Vorgehesnweise deutlich vereinfachen. Leider habe ich es bisher nicht geschafft die Dokumentensuche im Adapter so einzuschränken, dass die Suchbegriffe nur auf Dokumente mit bestimmten Tags angewendet werden. Ist dies möglich? Falls ja wie?
-
bisher frage ich das wie folgt über die API ab
http://paperless:8000/api/documents/?title__istartswith=&title__iendswith=&title__icontains=&title__iexact=&content__istartswith=&content__iendswith=&content__icontains=&content__iexact=&archive_serial_number=&archive_serial_number__gt=&archive_serial_number__gte=&archive_serial_number__lt=&archive_serial_number__lte=&archive_serial_number__isnull=&created__year=&created__month=&created__day=&created__date__gt=&created__gt=&created__date__lt=&created__lt=&added__year=&added__month=&added__day=&added__date__gt=&added__gt=&added__date__lt=&added__lt=&modified__year=&modified__month=&modified__day=&modified__date__gt=&modified__gt=&modified__date__lt=&modified__lt=&original_filename__istartswith=&original_filename__iendswith=&original_filename__icontains=&original_filename__iexact=&checksum__istartswith=&checksum__iendswith=&checksum__icontains=&checksum__iexact=&correspondent__isnull=&correspondent__id__in=&correspondent__id=&correspondent__name__istartswith=&correspondent__name__iendswith=&correspondent__name__icontains=&correspondent__name__iexact=&tags__id__in=&tags__id=3&tags__id=4&tags__id__all=16&tags__name__istartswith=&tags__name__iendswith=&tags__name__icontains=&tags__name__iexact=&document_type__isnull=&document_type__id__in=&document_type__id=&document_type__name__istartswith=&document_type__name__iendswith=&document_type__name__icontains=&document_type__name__iexact=&storage_path__isnull=&storage_path__id__in=&storage_path__id=&storage_path__name__istartswith=&storage_path__name__iendswith=&storage_path__name__icontains=&storage_path__name__iexact=&owner__isnull=&owner__id__in=&owner__id=&is_tagged=&tags__id__all= 3%2C4%2C16& tags__id__none=&correspondent__id__none=&document_type__id__none=&storage_path__id__none=&is_in_inbox=&title_content=&owner__id__none=wobei die mittlere Zeile eine einschränkung auf Dokumente mit den Tags 3,4 und 16 bedeutet.
-
bisher frage ich das wie folgt über die API ab
http://paperless:8000/api/documents/?title__istartswith=&title__iendswith=&title__icontains=&title__iexact=&content__istartswith=&content__iendswith=&content__icontains=&content__iexact=&archive_serial_number=&archive_serial_number__gt=&archive_serial_number__gte=&archive_serial_number__lt=&archive_serial_number__lte=&archive_serial_number__isnull=&created__year=&created__month=&created__day=&created__date__gt=&created__gt=&created__date__lt=&created__lt=&added__year=&added__month=&added__day=&added__date__gt=&added__gt=&added__date__lt=&added__lt=&modified__year=&modified__month=&modified__day=&modified__date__gt=&modified__gt=&modified__date__lt=&modified__lt=&original_filename__istartswith=&original_filename__iendswith=&original_filename__icontains=&original_filename__iexact=&checksum__istartswith=&checksum__iendswith=&checksum__icontains=&checksum__iexact=&correspondent__isnull=&correspondent__id__in=&correspondent__id=&correspondent__name__istartswith=&correspondent__name__iendswith=&correspondent__name__icontains=&correspondent__name__iexact=&tags__id__in=&tags__id=3&tags__id=4&tags__id__all=16&tags__name__istartswith=&tags__name__iendswith=&tags__name__icontains=&tags__name__iexact=&document_type__isnull=&document_type__id__in=&document_type__id=&document_type__name__istartswith=&document_type__name__iendswith=&document_type__name__icontains=&document_type__name__iexact=&storage_path__isnull=&storage_path__id__in=&storage_path__id=&storage_path__name__istartswith=&storage_path__name__iendswith=&storage_path__name__icontains=&storage_path__name__iexact=&owner__isnull=&owner__id__in=&owner__id=&is_tagged=&tags__id__all= 3%2C4%2C16& tags__id__none=&correspondent__id__none=&document_type__id__none=&storage_path__id__none=&is_in_inbox=&title_content=&owner__id__none=wobei die mittlere Zeile eine einschränkung auf Dokumente mit den Tags 3,4 und 16 bedeutet.
-
@banis OK, ich kenne von der API nur:
/api/documents/?query=your%20search%20queryAber für deine Suche müsste man ja die ids der tags kennen, richtig?
@ben1983 ja genau die IDs der Tags könnten dann z.B. in einem weiteren Feld wie bisher das Suchfeld angegeben werden. Im Optimalfall kombiniert mit einem weiteren Feld in dem man angeben kann, ob die IDs ein "und" oder eine "oder" Verknüpfung sein sollen.
-
@ben1983 ja genau die IDs der Tags könnten dann z.B. in einem weiteren Feld wie bisher das Suchfeld angegeben werden. Im Optimalfall kombiniert mit einem weiteren Feld in dem man angeben kann, ob die IDs ein "und" oder eine "oder" Verknüpfung sein sollen.
@banis OK.
-
Wo finde ich eine Doku zum Aufbau der Abfrage?
Hier: REST API von Paperless
finde ich nichts, oder ich sehe es nicht. -
Man muss doch dann die IDs der Tags kennen.
Ist das wirklich sinnvoll und wäre es nicht schöner die Tags auszuschreiben?
Das wird aber bestimmt nicht von der API unterstützt.
-
-
@ben1983 ja genau die IDs der Tags könnten dann z.B. in einem weiteren Feld wie bisher das Suchfeld angegeben werden. Im Optimalfall kombiniert mit einem weiteren Feld in dem man angeben kann, ob die IDs ein "und" oder eine "oder" Verknüpfung sein sollen.
-
@ben1983
Ich hab' den Adapter gerade erst entdeckt.
Damit erspare ich mir das Auslesen der Datenbank per SQL, um mich über neue Dokumente benachrichtigen zu lassen.Ich habe Dir 'nen PR mit 2 kleinen Textkorrekturen eingestellt. Sowas stört meinen inneren Monk

Edit
Was mir aufgefallen ist: Wenn man den Adapter auf 'ne falsche IP schickt, wird er trotzdem grün, produziert aber (logischerweise) fleißig Fehlermeldungen."Any fool can write code that a computer can understand. Good programmers write code that humans can understand." (Martin Fowler, "Refactoring")
Proxmox 9.1.1 LXC|8 GB|Core i7-6700
HmIP|ZigBee|Tasmota|Unifi
Zabbix Certified Specialist
Konnte ich Dir helfen? Dann benutze bitte das Voting unten rechts im Beitrag -
Super! Mit der neuen Version 0.1.1 kann ich jetzt Trigger auf die Korrespondenten legen.
Damit lasse ich mich benachrichtigen, wenn aus den Mail-Accounts Dokumente importiert wurden.Das Script möchte ich euch nicht vorenthalten:
const ignoreList = ['Scanner']; // paperless-ngx.0.correspondents.detailed.001.document_count on({id: /^paperless-ngx\.0\.correspondents\.detailed\..+\.document_count$/, change: "gt"}, function(obj) { console.log(obj); const id = obj.id.replace('document_count', 'name'); const correspondent = getState(id).val; if (!ignoreList.includes(correspondent)) { const documentCount = obj.state.val; const lastCount = obj.oldState.val; const count = documentCount - lastCount; // hier nur als Log. Ich lasse mir das per Signal senden console.log(`Es wurden ${count} neue Dokumente für den Korrespondenten ${correspondent} verarbeitet.`); } });"Any fool can write code that a computer can understand. Good programmers write code that humans can understand." (Martin Fowler, "Refactoring")
Proxmox 9.1.1 LXC|8 GB|Core i7-6700
HmIP|ZigBee|Tasmota|Unifi
Zabbix Certified Specialist
Konnte ich Dir helfen? Dann benutze bitte das Voting unten rechts im Beitrag -
@ben1983
Ich hab' den Adapter gerade erst entdeckt.
Damit erspare ich mir das Auslesen der Datenbank per SQL, um mich über neue Dokumente benachrichtigen zu lassen.Ich habe Dir 'nen PR mit 2 kleinen Textkorrekturen eingestellt. Sowas stört meinen inneren Monk
Edit
Was mir aufgefallen ist: Wenn man den Adapter auf 'ne falsche IP schickt, wird er trotzdem grün, produziert aber (logischerweise) fleißig Fehlermeldungen. -
@codierknecht Was für ne Textkorrektur, sehe keinen PR.
@ben1983
Sollte jetzt vorhanden sein.
Direktes Editieren im Original-Repo produziert wohl keinen PR."Any fool can write code that a computer can understand. Good programmers write code that humans can understand." (Martin Fowler, "Refactoring")
Proxmox 9.1.1 LXC|8 GB|Core i7-6700
HmIP|ZigBee|Tasmota|Unifi
Zabbix Certified Specialist
Konnte ich Dir helfen? Dann benutze bitte das Voting unten rechts im Beitrag -
@ben1983
Sollte jetzt vorhanden sein.
Direktes Editieren im Original-Repo produziert wohl keinen PR.@codierknecht sagte in Test paperless-ngx Adapter:
Direktes Editieren im Original-Repo produziert wohl keinen PR
eigentlich schon, aber man muss noch einen weiteren Schritt machen.
Das ist bei github aber nicht immer so ganz ersichtlich.
Editieren im original Repo macht die folgenden Schritte:- fork des originalRepos in dein Github account
- einen branchnamen vergeben
- einchecken der Änderungen
Wenn du dann mit deinen Änderungen fertig bist, müsste da was davon stehen das das Repo soundsoviel "ahead" des eigentlichen Repos ist.
Das steht etwas zwischendrin. ungefähr auf der Höhe wo auch die Anzahl commits des Repos ausgegeben werden.
Da klickt man dann drauf und "schon" kommt automatisch der PR-Dialog.
Wenn man dann den abspeichert, dann ist der PR angekommen. -
@codierknecht sagte in Test paperless-ngx Adapter:
Direktes Editieren im Original-Repo produziert wohl keinen PR
eigentlich schon, aber man muss noch einen weiteren Schritt machen.
Das ist bei github aber nicht immer so ganz ersichtlich.
Editieren im original Repo macht die folgenden Schritte:- fork des originalRepos in dein Github account
- einen branchnamen vergeben
- einchecken der Änderungen
Wenn du dann mit deinen Änderungen fertig bist, müsste da was davon stehen das das Repo soundsoviel "ahead" des eigentlichen Repos ist.
Das steht etwas zwischendrin. ungefähr auf der Höhe wo auch die Anzahl commits des Repos ausgegeben werden.
Da klickt man dann drauf und "schon" kommt automatisch der PR-Dialog.
Wenn man dann den abspeichert, dann ist der PR angekommen.@oliverio
Mit Git bin ich noch nie so richtig warm geworden.
Mir persönlich hat SVN bislang immer gereicht."Any fool can write code that a computer can understand. Good programmers write code that humans can understand." (Martin Fowler, "Refactoring")
Proxmox 9.1.1 LXC|8 GB|Core i7-6700
HmIP|ZigBee|Tasmota|Unifi
Zabbix Certified Specialist
Konnte ich Dir helfen? Dann benutze bitte das Voting unten rechts im Beitrag -
@oliverio
Mit Git bin ich noch nie so richtig warm geworden.
Mir persönlich hat SVN bislang immer gereicht.hier meinte ich github
git ist meiner Meinung nach gegenüber svn um einiges fortschrittlicher und hat bei der collaboriativen zusammenarbeit vorteile.
mehrfach erlebt:
der entwickler hat vor seinem urlaub vergessen seine sourcen wieder einzuchecken.
ist immer ein riesen ding gewesen und hat, weil auch andere regeln nicht beachtet wurde öfters zu inkompatiblen code ständen geführt. -
@oliverio
Mit Git bin ich noch nie so richtig warm geworden.
Mir persönlich hat SVN bislang immer gereicht.@codierknecht sagte in Test paperless-ngx Adapter:
Mir persönlich hat SVN bislang immer gereicht.
na herzlich willkommen in den 90-ern
-
Super! Mit der neuen Version 0.1.1 kann ich jetzt Trigger auf die Korrespondenten legen.
Damit lasse ich mich benachrichtigen, wenn aus den Mail-Accounts Dokumente importiert wurden.Das Script möchte ich euch nicht vorenthalten:
const ignoreList = ['Scanner']; // paperless-ngx.0.correspondents.detailed.001.document_count on({id: /^paperless-ngx\.0\.correspondents\.detailed\..+\.document_count$/, change: "gt"}, function(obj) { console.log(obj); const id = obj.id.replace('document_count', 'name'); const correspondent = getState(id).val; if (!ignoreList.includes(correspondent)) { const documentCount = obj.state.val; const lastCount = obj.oldState.val; const count = documentCount - lastCount; // hier nur als Log. Ich lasse mir das per Signal senden console.log(`Es wurden ${count} neue Dokumente für den Korrespondenten ${correspondent} verarbeitet.`); } });@codierknecht sollte jetzt auch möglich sein, dass man entweder die Dokumente mit allen Tags durchsucht, oder einzelnen ausblendet, oder nur in einzelnen sucht.
-
mal ne kurze Frage... Ich bin heute über paperless-ngx gestolpert und habe auf meinem RaspberryPi 4 iobroker, zigbee2mqtt und einen Kamera-Server laufen. Alles läuft bisher wie geschmiert.
Kann ich paperless-ngx noch installieren oder geht der Raspi dann in die Knie? Wie sind eure Erfahrungen? -
mal ne kurze Frage... Ich bin heute über paperless-ngx gestolpert und habe auf meinem RaspberryPi 4 iobroker, zigbee2mqtt und einen Kamera-Server laufen. Alles läuft bisher wie geschmiert.
Kann ich paperless-ngx noch installieren oder geht der Raspi dann in die Knie? Wie sind eure Erfahrungen?@android51 said in Test paperless-ngx Adapter:
mal ne kurze Frage... Ich bin heute über paperless-ngx gestolpert und habe auf meinem RaspberryPi 4 iobroker, zigbee2mqtt und einen Kamera-Server laufen. Alles läuft bisher wie geschmiert.
Kann ich paperless-ngx noch installieren oder geht der Raspi dann in die Knie? Wie sind eure Erfahrungen?Naja, hängt von mehreren Parametern ab... wenn Deine Paperless NGX Instanz in der Regel nicht viel tut und fast ausschließlich zum Anschauen von Dokumenten verwendet wird, sollte das sicherlich gehen. Anders sieht es aber aus, wenn Du Dokumente hochlädst. Wenn es nur ein oder zwei oder so sind ist das wahrscheinlich auch noch kein Problem - aber wenn Du anfängst, Dein Gesamtes Archiv mit -zig oder gar hunderten oder tausenden Dokumenten da reinzuwerfen, wird der Pi4 wahrscheinlich doch etwas an seine Grenzen stoßen, selbst, wenn Du die 8GB Variante hast.
An meinem Beispiel: Bei mir läuft Paperless NDX als Proxmox Container (LXC) mit 3 CPUs und (anfangs) 6GB RAM. Darin läuft das Docker-Image. Wenn ich jetzt einen ganzen Stapel Dokumente (so um die 10, 12 gleichzeitig, habe ich bisher getestet) in den consume Ordner werfe, dann ist diese Konstellation schon ziemlich in die Knie gegangen. Memory war zu 100% voll und das Ding hat schon reichlich angefangen zu swappen. Nachdem ich den LXC jetzt nochmal mit 6GB Mem auf insgesamt 12GB aufgestockt habe, werden auch größere Dokumentenstapel wieder recht zügig verarbeitet.
Meine Antwort auf Deine Frage ist also ein eindeutiges "ja, aber" :-)
-
@android51 said in Test paperless-ngx Adapter:
mal ne kurze Frage... Ich bin heute über paperless-ngx gestolpert und habe auf meinem RaspberryPi 4 iobroker, zigbee2mqtt und einen Kamera-Server laufen. Alles läuft bisher wie geschmiert.
Kann ich paperless-ngx noch installieren oder geht der Raspi dann in die Knie? Wie sind eure Erfahrungen?Naja, hängt von mehreren Parametern ab... wenn Deine Paperless NGX Instanz in der Regel nicht viel tut und fast ausschließlich zum Anschauen von Dokumenten verwendet wird, sollte das sicherlich gehen. Anders sieht es aber aus, wenn Du Dokumente hochlädst. Wenn es nur ein oder zwei oder so sind ist das wahrscheinlich auch noch kein Problem - aber wenn Du anfängst, Dein Gesamtes Archiv mit -zig oder gar hunderten oder tausenden Dokumenten da reinzuwerfen, wird der Pi4 wahrscheinlich doch etwas an seine Grenzen stoßen, selbst, wenn Du die 8GB Variante hast.
An meinem Beispiel: Bei mir läuft Paperless NDX als Proxmox Container (LXC) mit 3 CPUs und (anfangs) 6GB RAM. Darin läuft das Docker-Image. Wenn ich jetzt einen ganzen Stapel Dokumente (so um die 10, 12 gleichzeitig, habe ich bisher getestet) in den consume Ordner werfe, dann ist diese Konstellation schon ziemlich in die Knie gegangen. Memory war zu 100% voll und das Ding hat schon reichlich angefangen zu swappen. Nachdem ich den LXC jetzt nochmal mit 6GB Mem auf insgesamt 12GB aufgestockt habe, werden auch größere Dokumentenstapel wieder recht zügig verarbeitet.
Meine Antwort auf Deine Frage ist also ein eindeutiges "ja, aber" :-)
@mccavity
Vielen Dank für dein Feedback.
Da ich mir noch nicht sicher bin, ob ich paperless auf Dauer nutzen möchte und eigentlich erstmal eine gewisse Testphase durchlaufen möchte, in der ich nach und nach mal ein paar eingehende Dokumente darin ablege, dürfte das System ausreichend sein.
Meine größte Sorge ist aber, was passiert, wenn paperless irgendwann nicht mehr weiterentwickelt und eingestellt wird. Dann habe ich ein riesen Durcheinander von Dokumenten und muss sie mühsam wieder zusortieren. -
@mccavity
Vielen Dank für dein Feedback.
Da ich mir noch nicht sicher bin, ob ich paperless auf Dauer nutzen möchte und eigentlich erstmal eine gewisse Testphase durchlaufen möchte, in der ich nach und nach mal ein paar eingehende Dokumente darin ablege, dürfte das System ausreichend sein.
Meine größte Sorge ist aber, was passiert, wenn paperless irgendwann nicht mehr weiterentwickelt und eingestellt wird. Dann habe ich ein riesen Durcheinander von Dokumenten und muss sie mühsam wieder zusortieren.@android51 Da kannst Du vorbeugen, wenn Du Dir von vornherein eine saubere Verzeichnis- und Dateinamenstruktur überlegst. Paperless speichert die Dokumente einfach nur als Dateien im Verzeichnispfad ab, d.h., wenn Du da schon eine gute Ordnerstruktur hast, kannst Du einfach den gesamten Verzeichnisbaum nehmen und ggf. in ein anderes System übertragen - oder sogar ganz ohne System nutzen.
Anregungen dazu gibt es zum Beispiel bei Digitalisierung mit Kopf oder bei Digital Cleaning (mit einer Fortsetzung hier).
Mit beiden habe ich nichts zu tun, die verkaufen m.W. auch Kurse zu dem Thema, habe ich aber weder selbst genutzt, noch kenne jemanden, der das nutzt - aber auch die öffentlich verfügbaren Anleitungen da sind schon sehr hilf- und umfangreich.
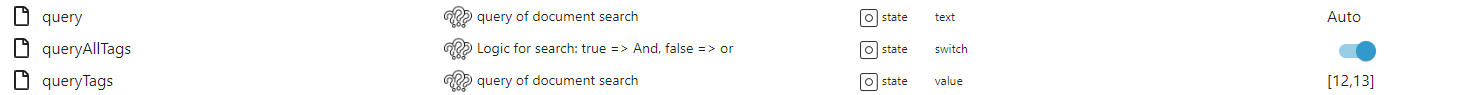
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
355
Online33.0k
Benutzer83.3k
Themen1.3m
Beiträge