

Grafana Tages/Monatsverbräuche Performance u. Darstellung?
-
@meister-mopper sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Wenn ich dort share auswähle, gibt es keine embed-Option, oder klicke ich mal wieder falsch?
Meines Wissens kann man nur einzelne Panels ("Solo Dashboard") als iFrame bereitstellen. Für ein Dashboard geht das nicht.
Danke, schade, denn ich habe nur wenige 'Solos'.
Trotzdem, die wenigen habe ich dank deines Tipps umgestellt.
-
@meister-mopper sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Wenn ich dort share auswähle, gibt es keine embed-Option, oder klicke ich mal wieder falsch?
Meines Wissens kann man nur einzelne Panels ("Solo Dashboard") als iFrame bereitstellen. Für ein Dashboard geht das nicht.
@marc-berg, @Meister-Mopper ,
doch das geht.
Das Dashboard als public dashboard freigeben. ggf. localhost im Link durch die lokale IP-Adresse des Grafana-Hosts ersetzten.Vorher natürlich /usr/share/grafana/conf/defaults.ini im Grafana-Host anpassen.
Darin muss allow_embedding auf true gesetzt werden.
Anschließend des Service neustarten. -
Hi
um Verbräuche zu Visualisieren hab ich nun doch mal Grafana ausprobiert.
Leider hab ich den Beitrag hier verloren und noch einmal Danke für die Flux-Schnipsel um mir das so zu bauen:
Tagesverbrauch im aktuellen Monat:
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d , fn: last, timeSrc: "_start") |> difference(nonNegative: true, columns: ["_value"]) |> yield(name: "last")Monatsverbräuche im aktuellen Jahr:
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1mo , fn: last, timeSrc: "_start") |> difference(nonNegative: true, columns: ["_value"]) |> yield(name: "last")Nun brauchen die Grafana Dashboards ca. 5 Sekunden eh sieh auf der VIS-View geladen sind, was schon ein extremer Nachteil ist. Liegt dass an den InfluxDB Abfragen und könnte ich das Beschleunigen indem man die Werte einzeln abfragt und in DPs speichert und dann mittels Grafana visualisiert oder gibt es bessere Ansätze?
Desweiteren, kann man nur die Panels im iFrame darstellen ohne das Grafana Menü der Dashborads drumherum ?
Thx
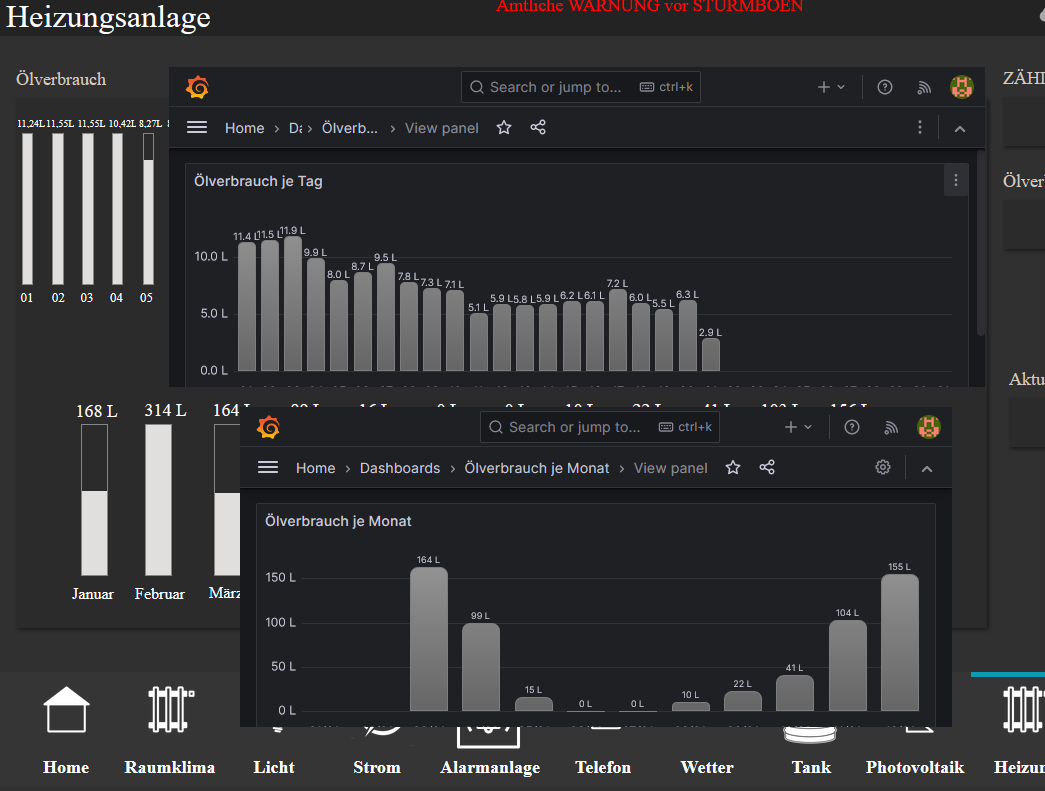
@dieter_p Schau dir mal die Infos von @haus-automatisierung an:
https://haus-automatisierung.com/software/2023/05/11/influxdb2-pv-dashboard.htmlIn dem Beitrag geht es zwar um eine PV-Anlage, aber die Reduzierung der Datenmenge durch tasks ist sicher auch für dich hilfreich.
Ggf. kann bei den Abfragen auf die range optzimiert werden, auch dazu gibt es in dem Beitrag einige Infos.
-
@dieter_p Schau dir mal die Infos von @haus-automatisierung an:
https://haus-automatisierung.com/software/2023/05/11/influxdb2-pv-dashboard.htmlIn dem Beitrag geht es zwar um eine PV-Anlage, aber die Reduzierung der Datenmenge durch tasks ist sicher auch für dich hilfreich.
Ggf. kann bei den Abfragen auf die range optzimiert werden, auch dazu gibt es in dem Beitrag einige Infos.
Danke. Die allgemeine Info, dass es eine Performancesache ist hilft mir auch schon sehr.
Wie oben bei den Screenshots andeuteutungsweise zu sehen ist, gibt es eine Welt vor Grafana wo ich mir diese Visualisierung mit Datenpunkten und Queries in die Datenpunkte selbst gebaut hab.
Vom Prinzip, empfinde ich es ja auch unnötig außer für den aktuellen Tag und den aktuellen Monat bei jedem Aufruf die DB fürs ganze Jahr zu durchwurschteln. An den anderen Werte ändert sich ja erstmal nix.
Die manuell gebauten Abfragen sind nur recht komplex geworden durch viele Wenn/dann Fälle und die Visualisierung vielleicht nicht "brillant-bright". Hier der Versuch mit Grafana das mit einem Wisch zu verbessern.
Da das nicht geht, muß ich mal überlegen ob ich eine optimierte Version mit Grafana baue oder wieder ganz drauf verzichte.
-
@dieter_p Schau dir mal die Infos von @haus-automatisierung an:
https://haus-automatisierung.com/software/2023/05/11/influxdb2-pv-dashboard.htmlIn dem Beitrag geht es zwar um eine PV-Anlage, aber die Reduzierung der Datenmenge durch tasks ist sicher auch für dich hilfreich.
Ggf. kann bei den Abfragen auf die range optzimiert werden, auch dazu gibt es in dem Beitrag einige Infos.
Hab nun etwas probiert bzgl. reduzierter Datenmengen und wie ich nun festgestellt hab, hatte ich eh schon Aggregationen der Tagesverbräuche in der Datenbank die ich jeden Tag um 23:59h bilde und dareinschreibe.
Die Nutzung in Grafana also
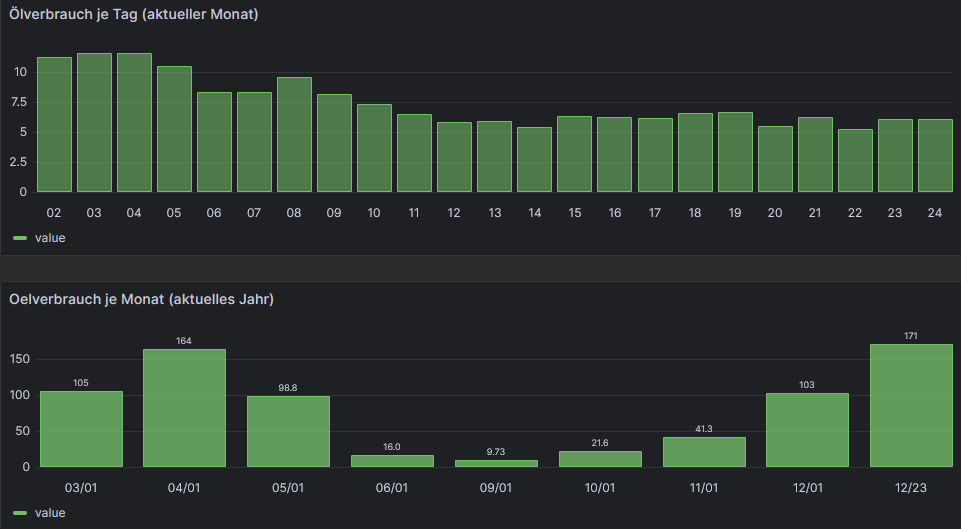
Tageswerte:
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> yield(name: "sum")Monatswerte:
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> yield(name: "sum")Wirkt sich deutlich spürbar auf die Performance aus und lesbare "Loading"-Anzeigen oder Grafana-Symbole sind verschwunden.
Nun hab ich jedoch noch eine Frage was besonders gut in der Tagesdarstellung sichtbar ist. Dort eine Verschiebung in der Zeitachse um 1Tag drin. Ich schreibe den Tagesverbrauch defintiv vor 24h in die Datenbank somit ist der Zeitstempel auch vom gleichen Tag, aber die Aggregation verschiebt das.
Wie ist das anpassbar?b) Kann ich eine eine 2te Abfrage in das gleiche Panel reinbringen für den aktuellen Tag/Monat (je nach Panel)? Hier ändert sich ja mit jedem aktuellen Verbrauch gemäß dem Zeitpunkt des Abrufs etwas und ich müßte den einen Bargraph für den Tag/monat wirklich so fein dynamisch nach Aufrufzeitpunkt haben. Lässt Grafana das zu?
Thx!
-
Hab nun etwas probiert bzgl. reduzierter Datenmengen und wie ich nun festgestellt hab, hatte ich eh schon Aggregationen der Tagesverbräuche in der Datenbank die ich jeden Tag um 23:59h bilde und dareinschreibe.
Die Nutzung in Grafana also
Tageswerte:
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> yield(name: "sum")Monatswerte:
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> yield(name: "sum")Wirkt sich deutlich spürbar auf die Performance aus und lesbare "Loading"-Anzeigen oder Grafana-Symbole sind verschwunden.
Nun hab ich jedoch noch eine Frage was besonders gut in der Tagesdarstellung sichtbar ist. Dort eine Verschiebung in der Zeitachse um 1Tag drin. Ich schreibe den Tagesverbrauch defintiv vor 24h in die Datenbank somit ist der Zeitstempel auch vom gleichen Tag, aber die Aggregation verschiebt das.
Wie ist das anpassbar?b) Kann ich eine eine 2te Abfrage in das gleiche Panel reinbringen für den aktuellen Tag/Monat (je nach Panel)? Hier ändert sich ja mit jedem aktuellen Verbrauch gemäß dem Zeitpunkt des Abrufs etwas und ich müßte den einen Bargraph für den Tag/monat wirklich so fein dynamisch nach Aufrufzeitpunkt haben. Lässt Grafana das zu?
Thx!
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Dort eine Verschiebung in der Zeitachse um 1Tag drin. Ich schreibe den Tagesverbrauch defintiv vor 24h in die Datenbank somit ist der Zeitstempel auch vom gleichen Tag, aber die Aggregation verschiebt das.
Wie ist das anpassbar?Du solltest jeweils vor deine Query
import "timezone" option location = timezone.location(name: "Europe/Berlin")reinschreiben. (Ich nehme an, dass du mit "23:59h" lokale Zeit meinst?)
b) Kann ich eine eine 2te Abfrage in das gleiche Panel reinbringen für den aktuellen Tag/Monat (je nach Panel)? Hier ändert sich ja mit jedem aktuellen Verbrauch gemäß dem Zeitpunkt des Abrufs etwas und ich müßte den einen Bargraph für den Tag/monat wirklich so fein dynamisch nach Aufrufzeitpunkt haben. Lässt Grafana das zu?
ja, das geht:
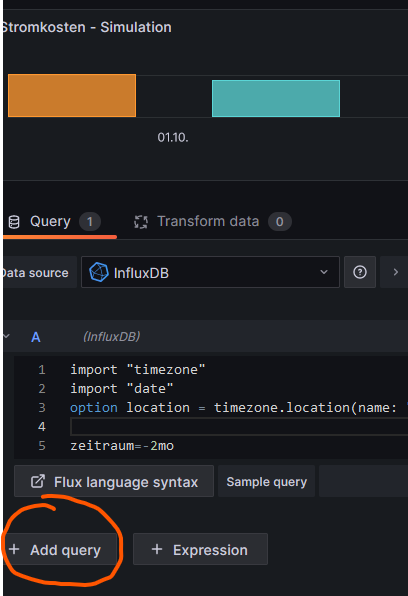
Was du damit erreichen willst, habe ich aber leider nicht verstanden. Eine zweite Abfrage ergibt aus meiner Sicht nur Sinn, wenn es um die gleichen Zeitbereiche geht.
-
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Dort eine Verschiebung in der Zeitachse um 1Tag drin. Ich schreibe den Tagesverbrauch defintiv vor 24h in die Datenbank somit ist der Zeitstempel auch vom gleichen Tag, aber die Aggregation verschiebt das.
Wie ist das anpassbar?Du solltest jeweils vor deine Query
import "timezone" option location = timezone.location(name: "Europe/Berlin")reinschreiben. (Ich nehme an, dass du mit "23:59h" lokale Zeit meinst?)
b) Kann ich eine eine 2te Abfrage in das gleiche Panel reinbringen für den aktuellen Tag/Monat (je nach Panel)? Hier ändert sich ja mit jedem aktuellen Verbrauch gemäß dem Zeitpunkt des Abrufs etwas und ich müßte den einen Bargraph für den Tag/monat wirklich so fein dynamisch nach Aufrufzeitpunkt haben. Lässt Grafana das zu?
ja, das geht:
Was du damit erreichen willst, habe ich aber leider nicht verstanden. Eine zweite Abfrage ergibt aus meiner Sicht nur Sinn, wenn es um die gleichen Zeitbereiche geht.
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Was du damit erreichen willst, habe ich aber leider nicht verstanden. Eine zweite Abfrage ergibt aus meiner Sicht nur Sinn, wenn es um die gleichen Zeitbereiche geht.
Danke, was ich möchte: Die Datenbankeinträge "Tagesverbrauch" stehen für jeden Tag "erst" um 23:59h zur Verfügung. Wenn ich jetzt aber die Graphen aufrufe möchte ich möglichst auch den aktuellen temporären Wert für den heutigen Tag sehen. Die Abfrage kann ich mir nicht über den measurement Tagesverbrauch holen, sondern muß ich wirklich "just in time" für den heutigen Tag berechnen lassen über die Zählerstände (nur für den heutigen Tag).
Alles mit der Intention eine möglichst performance-optimierte Ansicht zu bekommen.
-
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Dort eine Verschiebung in der Zeitachse um 1Tag drin. Ich schreibe den Tagesverbrauch defintiv vor 24h in die Datenbank somit ist der Zeitstempel auch vom gleichen Tag, aber die Aggregation verschiebt das.
Wie ist das anpassbar?Du solltest jeweils vor deine Query
import "timezone" option location = timezone.location(name: "Europe/Berlin")reinschreiben. (Ich nehme an, dass du mit "23:59h" lokale Zeit meinst?)
b) Kann ich eine eine 2te Abfrage in das gleiche Panel reinbringen für den aktuellen Tag/Monat (je nach Panel)? Hier ändert sich ja mit jedem aktuellen Verbrauch gemäß dem Zeitpunkt des Abrufs etwas und ich müßte den einen Bargraph für den Tag/monat wirklich so fein dynamisch nach Aufrufzeitpunkt haben. Lässt Grafana das zu?
ja, das geht:
Was du damit erreichen willst, habe ich aber leider nicht verstanden. Eine zweite Abfrage ergibt aus meiner Sicht nur Sinn, wenn es um die gleichen Zeitbereiche geht.
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Dort eine Verschiebung in der Zeitachse um 1Tag drin. Ich schreibe den Tagesverbrauch defintiv vor 24h in die Datenbank somit ist der Zeitstempel auch vom gleichen Tag, aber die Aggregation verschiebt das.
Wie ist das anpassbar?Du solltest jeweils vor deine Query
import "timezone" option location = timezone.location(name: "Europe/Berlin")reinschreiben. (Ich nehme an, dass du mit "23:59h" lokale Zeit meinst?)
Danke. Ja, ist 23:59h über ein Blockly in IOB.
Leider ändert sich in der Darstellung in Grafana nichts mit:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> yield(name: "sum")-> Start: 02. Dezember und alles um einen Tag versetzt.
-
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Dort eine Verschiebung in der Zeitachse um 1Tag drin. Ich schreibe den Tagesverbrauch defintiv vor 24h in die Datenbank somit ist der Zeitstempel auch vom gleichen Tag, aber die Aggregation verschiebt das.
Wie ist das anpassbar?Du solltest jeweils vor deine Query
import "timezone" option location = timezone.location(name: "Europe/Berlin")reinschreiben. (Ich nehme an, dass du mit "23:59h" lokale Zeit meinst?)
Danke. Ja, ist 23:59h über ein Blockly in IOB.
Leider ändert sich in der Darstellung in Grafana nichts mit:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> yield(name: "sum")-> Start: 02. Dezember und alles um einen Tag versetzt.
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false)
jep, du musst die Zeile hier noch erweitern:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc="_start")
-
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Was du damit erreichen willst, habe ich aber leider nicht verstanden. Eine zweite Abfrage ergibt aus meiner Sicht nur Sinn, wenn es um die gleichen Zeitbereiche geht.
Danke, was ich möchte: Die Datenbankeinträge "Tagesverbrauch" stehen für jeden Tag "erst" um 23:59h zur Verfügung. Wenn ich jetzt aber die Graphen aufrufe möchte ich möglichst auch den aktuellen temporären Wert für den heutigen Tag sehen. Die Abfrage kann ich mir nicht über den measurement Tagesverbrauch holen, sondern muß ich wirklich "just in time" für den heutigen Tag berechnen lassen über die Zählerstände (nur für den heutigen Tag).
Alles mit der Intention eine möglichst performance-optimierte Ansicht zu bekommen.
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Die Abfrage kann ich mir nicht über den measurement Tagesverbrauch holen, sondern muß ich wirklich "just in time" für den heutigen Tag berechnen lassen über die Zählerstände (nur für den heutigen Tag).
Achso, ja das geht, mit einem "union". Hier fügst du zwei Abfragen "vertikal" zusammen. Ungetestet:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrLive") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) union(tables: [tagesverbrauch, live]) -
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false)
jep, du musst die Zeile hier noch erweitern:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc="_start")
jep, du musst die Zeile hier noch erweitern:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc="_start")
gemacht und nun möchte der Bargraph "Bar garph requires a string or time field".
Brauch ich etwas in Flux (killt mir das nicht dann die dynamische Anpassung "This month" aus Grafana oder ist etwas rechts in den Optionen des Panels für die X-Achse zu konfigurieren?
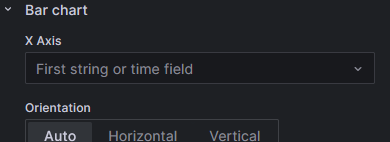
Danke
-
jep, du musst die Zeile hier noch erweitern:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc="_start")
gemacht und nun möchte der Bargraph "Bar garph requires a string or time field".
Brauch ich etwas in Flux (killt mir das nicht dann die dynamische Anpassung "This month" aus Grafana oder ist etwas rechts in den Optionen des Panels für die X-Achse zu konfigurieren?
Danke
-
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Die Abfrage kann ich mir nicht über den measurement Tagesverbrauch holen, sondern muß ich wirklich "just in time" für den heutigen Tag berechnen lassen über die Zählerstände (nur für den heutigen Tag).
Achso, ja das geht, mit einem "union". Hier fügst du zwei Abfragen "vertikal" zusammen. Ungetestet:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrLive") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) union(tables: [tagesverbrauch, live])Achso, ja das geht, mit einem "union". Hier fügst du zwei Abfragen "vertikal" zusammen. Ungetestet:
Danke.
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Query:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) |> yield(name: "last") union(tables: [tagesverbrauch, live])Query Inspector:
{ "request": { "url": "api/ds/query?ds_type=influxdb&requestId=Q119", "method": "POST", "data": { "queries": [ { "datasource": { "type": "influxdb", "uid": "fe97a43e-a484-468d-ba5f-dff87870a54a" }, "query": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n |> yield(name: \"last\")\r\n \r\n union(tables: [tagesverbrauch, live])", "refId": "A", "datasourceId": 1, "intervalMs": 3600000, "maxDataPoints": 848 } ], "from": "1701385200000", "to": "1704063599999" }, "hideFromInspector": false }, "response": { "results": { "A": { "status": 200, "frames": [ { "schema": { "name": "OelVerbrTag", "refId": "A", "meta": { "typeVersion": [ 0, 0 ], "executedQueryString": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: 2023-11-30T23:00:00Z, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n |> yield(name: \"last\")\r\n \r\n union(tables: [tagesverbrauch, live])" }, "fields": [ { "name": "Time", "type": "time", "typeInfo": { "frame": "time.Time", "nullable": true } }, { "name": "value", "type": "number", "typeInfo": { "frame": "float64", "nullable": true }, "labels": {} } ] }, "data": { "values": [ [ 1701471600000, 1701558000000, 1701644400000, 1701730800000, 1701817200000, 1701903600000, 1701990000000, 1702076400000, 1702162800000, 1702249200000, 1702335600000, 1702422000000, 1702508400000, 1702594800000, 1702681200000, 1702767600000, 1702854000000, 1702940400000, 1703026800000, 1703113200000, 1703199600000, 1703286000000, 1703372400000 ], [ 11.24, 11.55, 11.55, 10.42, 8.27, 8.29, 9.52, 8.1, 7.29, 6.5, 5.79, 5.87, 5.42, 6.28, 6.19, 6.12, 6.59, 6.64, 5.46, 6.26, 5.19, 6.07, 6.08 ] ] } } ], "refId": "A" } } } }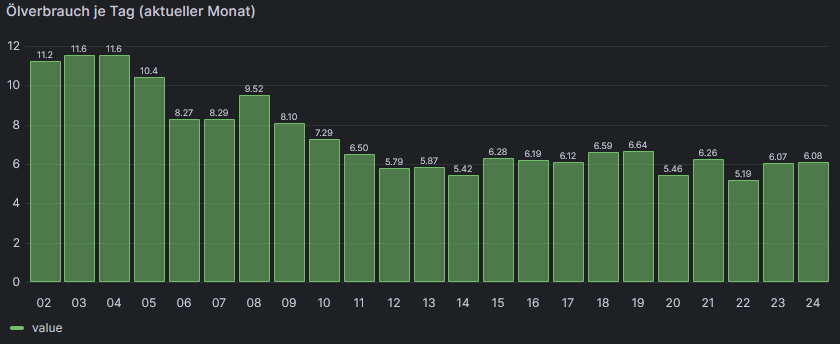
-
Achso, ja das geht, mit einem "union". Hier fügst du zwei Abfragen "vertikal" zusammen. Ungetestet:
Danke.
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Query:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) |> yield(name: "last") union(tables: [tagesverbrauch, live])Query Inspector:
{ "request": { "url": "api/ds/query?ds_type=influxdb&requestId=Q119", "method": "POST", "data": { "queries": [ { "datasource": { "type": "influxdb", "uid": "fe97a43e-a484-468d-ba5f-dff87870a54a" }, "query": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n |> yield(name: \"last\")\r\n \r\n union(tables: [tagesverbrauch, live])", "refId": "A", "datasourceId": 1, "intervalMs": 3600000, "maxDataPoints": 848 } ], "from": "1701385200000", "to": "1704063599999" }, "hideFromInspector": false }, "response": { "results": { "A": { "status": 200, "frames": [ { "schema": { "name": "OelVerbrTag", "refId": "A", "meta": { "typeVersion": [ 0, 0 ], "executedQueryString": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: 2023-11-30T23:00:00Z, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n |> yield(name: \"last\")\r\n \r\n union(tables: [tagesverbrauch, live])" }, "fields": [ { "name": "Time", "type": "time", "typeInfo": { "frame": "time.Time", "nullable": true } }, { "name": "value", "type": "number", "typeInfo": { "frame": "float64", "nullable": true }, "labels": {} } ] }, "data": { "values": [ [ 1701471600000, 1701558000000, 1701644400000, 1701730800000, 1701817200000, 1701903600000, 1701990000000, 1702076400000, 1702162800000, 1702249200000, 1702335600000, 1702422000000, 1702508400000, 1702594800000, 1702681200000, 1702767600000, 1702854000000, 1702940400000, 1703026800000, 1703113200000, 1703199600000, 1703286000000, 1703372400000 ], [ 11.24, 11.55, 11.55, 10.42, 8.27, 8.29, 9.52, 8.1, 7.29, 6.5, 5.79, 5.87, 5.42, 6.28, 6.19, 6.12, 6.59, 6.64, 5.46, 6.26, 5.19, 6.07, 6.08 ] ] } } ], "refId": "A" } } } }@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Die Zeile muss weg
|> yield(name: "last") -
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Das ist seltsam, zeig nochmal die ganze Query.
Gleiches auch hier mit dem "union":
Query:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false, createEmpty: false, timeSrc="_start") live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) |> yield(name: "last") union(tables: [tagesverbrauch, live]) -
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Die Zeile muss weg
|> yield(name: "last")@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Die Zeile muss weg
|> yield(name: "last")ok, gleiche Ausgabe:
{ "request": { "url": "api/ds/query?ds_type=influxdb&requestId=Q124", "method": "POST", "data": { "queries": [ { "datasource": { "type": "influxdb", "uid": "fe97a43e-a484-468d-ba5f-dff87870a54a" }, "query": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n \r\n union(tables: [tagesverbrauch, live])", "refId": "A", "datasourceId": 1, "intervalMs": 3600000, "maxDataPoints": 848 } ], "from": "1701385200000", "to": "1704063599999" }, "hideFromInspector": false }, "response": { "results": { "A": { "status": 200, "frames": [ { "schema": { "name": "OelVerbrTag", "refId": "A", "meta": { "typeVersion": [ 0, 0 ], "executedQueryString": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: 2023-11-30T23:00:00Z, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n \r\n union(tables: [tagesverbrauch, live])" }, "fields": [ { "name": "Time", "type": "time", "typeInfo": { "frame": "time.Time", "nullable": true } }, { "name": "value", "type": "number", "typeInfo": { "frame": "float64", "nullable": true }, "labels": {} } ] }, "data": { "values": [ [ 1701471600000, 1701558000000, 1701644400000, 1701730800000, 1701817200000, 1701903600000, 1701990000000, 1702076400000, 1702162800000, 1702249200000, 1702335600000, 1702422000000, 1702508400000, 1702594800000, 1702681200000, 1702767600000, 1702854000000, 1702940400000, 1703026800000, 1703113200000, 1703199600000, 1703286000000, 1703372400000 ], [ 11.24, 11.55, 11.55, 10.42, 8.27, 8.29, 9.52, 8.1, 7.29, 6.5, 5.79, 5.87, 5.42, 6.28, 6.19, 6.12, 6.59, 6.64, 5.46, 6.26, 5.19, 6.07, 6.08 ] ] } } ], "refId": "A" } } } } -
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Die Zeile muss weg
|> yield(name: "last")ok, gleiche Ausgabe:
{ "request": { "url": "api/ds/query?ds_type=influxdb&requestId=Q124", "method": "POST", "data": { "queries": [ { "datasource": { "type": "influxdb", "uid": "fe97a43e-a484-468d-ba5f-dff87870a54a" }, "query": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n \r\n union(tables: [tagesverbrauch, live])", "refId": "A", "datasourceId": 1, "intervalMs": 3600000, "maxDataPoints": 848 } ], "from": "1701385200000", "to": "1704063599999" }, "hideFromInspector": false }, "response": { "results": { "A": { "status": 200, "frames": [ { "schema": { "name": "OelVerbrTag", "refId": "A", "meta": { "typeVersion": [ 0, 0 ], "executedQueryString": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: 2023-11-30T23:00:00Z, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n \r\n union(tables: [tagesverbrauch, live])" }, "fields": [ { "name": "Time", "type": "time", "typeInfo": { "frame": "time.Time", "nullable": true } }, { "name": "value", "type": "number", "typeInfo": { "frame": "float64", "nullable": true }, "labels": {} } ] }, "data": { "values": [ [ 1701471600000, 1701558000000, 1701644400000, 1701730800000, 1701817200000, 1701903600000, 1701990000000, 1702076400000, 1702162800000, 1702249200000, 1702335600000, 1702422000000, 1702508400000, 1702594800000, 1702681200000, 1702767600000, 1702854000000, 1702940400000, 1703026800000, 1703113200000, 1703199600000, 1703286000000, 1703372400000 ], [ 11.24, 11.55, 11.55, 10.42, 8.27, 8.29, 9.52, 8.1, 7.29, 6.5, 5.79, 5.87, 5.42, 6.28, 6.19, 6.12, 6.59, 6.64, 5.46, 6.26, 5.19, 6.07, 6.08 ] ] } } ], "refId": "A" } } } }Schwierig, so ohne Quelldaten. Was liefert
from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])Edit: und sehe ich das richtig? In "0_userdata.0.Heizöl.Zaehlerstandverbrauch" stehen keine Verbräuche, sondern Stände?
-
Schwierig, so ohne Quelldaten. Was liefert
from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])Edit: und sehe ich das richtig? In "0_userdata.0.Heizöl.Zaehlerstandverbrauch" stehen keine Verbräuche, sondern Stände?
Edit: und sehe ich das richtig? In "0_userdata.0.Heizöl.Zaehlerstandverbrauch" stehen keine Verbräuche, sondern Stände?
Ja, richtig. In der Version die bei mir zuviel Performance kostet, hatte ich die Zählerstände so abgefragt:
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d , fn: last, timeSrc: "_start") |> difference(nonNegative: true, columns: ["_value"]) |> yield(name: "last")Das möchten wir ja übers "union" nur für den aktuellen Tag ergänzen, richtig?
-
Schwierig, so ohne Quelldaten. Was liefert
from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])Edit: und sehe ich das richtig? In "0_userdata.0.Heizöl.Zaehlerstandverbrauch" stehen keine Verbräuche, sondern Stände?
aaah, Fortschritt :)
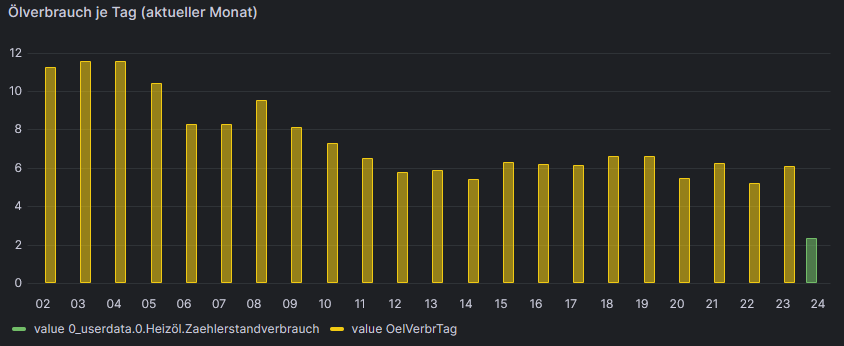
mit:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])somit bleibt noch das Thema warum er den Tagesverbrauch auf der Zeitachse verschiebt. Wird jetzt ja besonders deutlich da es 2 Werte für den 24.12. gibt und nur der grüne ist richtig. Alle gelben sind um einen Tag verschoben.
-
aaah, Fortschritt :)
mit:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])somit bleibt noch das Thema warum er den Tagesverbrauch auf der Zeitachse verschiebt. Wird jetzt ja besonders deutlich da es 2 Werte für den 24.12. gibt und nur der grüne ist richtig. Alle gelben sind um einen Tag verschoben.
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
somit bleibt noch das Thema warum er den Tagesverbrauch auf der Zeitachse verschiebt. Wird jetzt ja besonders deutlich da es 2 Werte für den 24.12. gibt und nur der grüne ist richtig. Alle gelben sind um einen Tag verschoben.
Das kriegen wir auch noch hin. Zeig mal einen Screenshot von den unveränderten / unaggregierten Daten im InfluxDB Data Explorer.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
486
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge