NEWS


Frage : Migrate MySQL nach Influxdb
Frage : Migrate MySQL nach Influxdb
-
Ich habe Version 1.7.9, installiert im Docker.
Habe das auch erst vor ein paar Tagen alles installiert bzw. umgestellt auf Influxdb, daher sollte die Version aktuell sein.Ich hatte auf jeden Fall Probleme mit den "ack"-Werten, da die in meinen MariaDB-Tabellen aus 0en oder 1en bestehen und Influx daraus dann einen Zahlenwert und keinen Boolean gemacht hat.
Daher wird oben im Python-Skript einfach alles auf true gesetzt (und die Zeilen mit 0er-Werten hatte ich ausgeschlossen).@gender Bei mir auch die neueste nur in einem Container unter Proxmox... Dann verstehe ich das ja gar nicht mehr... Trotzdem danke und vielleicht hat jemand ja noch eine andere Idee bzw. kann mal kurz aufzeigen wie er die Migration großer DB's vorgenommen hat...
Könnte mir ja auch vorstellen ne Batchverarbeitung zu schreiben nur fehlt mir dazu erst der Ansatz/Knowhow... Idee wäre jeden Datenpunkt einzeln in eine Datei zu schreiben (geht sowas mit dem Javascript Adapter getHistory etc.?) und dann einzeln per Bash etc. in Influx einzulesen...
-
Wollte hier nur mal hinterlassen, dass ich die Daten (über 90% ca. 4 GB) migrieren konnte mit den Beispiel, was weiter oben von @gender genannt wurde. Der einzige Fehler den man nicht machen darf ist, dass Du erst die Daten migrieren musst ehe du in ioBroker den Adapter aktivierst / einrichtest. Ansonsten ging das sehr gut:
- Alle Daten in mehreren csv-Dateien aus mysql exportiert (so ca. 2000000 pro Datei)
- Per python csv_to_line.py alle Dateien konvertiert in txt (wichtig dabei # DML und # CONTEXT-DATABASE: NameDatabase ergänzen in den ersten 2 Zeilen)
- Per influx-Befehl die konvertierten Dateien eingelesen
- ioBroker-Adapter aktivieren
-
Moin zusammen,
mein erster post in diesem Forum...
Zu aller erst vielen Dank für diese tolle Plattform und den vielen die mit enormem Aufwand das smarte home nach vorne treiben, tolle Ideen weiter geben, absolut geile Visualisierungen bauen usw. Ich habe bislang selten ein Forum gesehen, in dem so konstruktiv und freundlich miteinander umgegangen wird...weiter so
Seit ca 2 Jahren betreibe ich Iobroker und habe bislang die Daten zuerst in MySQL und später dann in PostgreSQL abgelegt. Über die Zeit wurden die ganzen Abfragen und Diagramme mit Grafana nach und nach deutlich träger. Nach kurzer Testphase mit InfluxDB war die Frage geklärt

Mit dem Wechsel auf InfluxDB stellt sich die Frage für den nicht Programmierer wie die Daten von alt nach neu...Die genannten Lösungen haben bei mir nicht zuverlässig funktioniert also die nächste Klappe
- In einem SQL GUI (phpmyadmin, HeidiSQL oder DBeaver, etc) oder auf der SQL-Konsole die zu exportierenden Daten in einem View zur Verfügung stellen
Der View enthält alles was Influx benötigt
create view xxx as SELECT datapoints.name, ts_number.ack as "ack", (ts_number.q*1.0) as "q", sources.name as "from", (ts_number.val*1.0) as "value", (ts_number.ts*1000000) as "time" from ts_number left join datapoints on ts_number.id=datapoints.id left join sources on ts_number._from=sources.id where datapoints.id>=70 and datapoints.id<=73 and q=0 order by ts_number.ts desc;"xxx" Name des View anpassen
in der WHERE Klausel die Datenpunkte entsprechend anpassen, einen Bereich wie hier oder auch eine einzelne id
Für kleine Datenbestände kann die WHERE Klausel auch auf "WHERE q=0" gesetzt werden und über den View in einem Rutsch in Influx übertragen werden.
Beispiel:
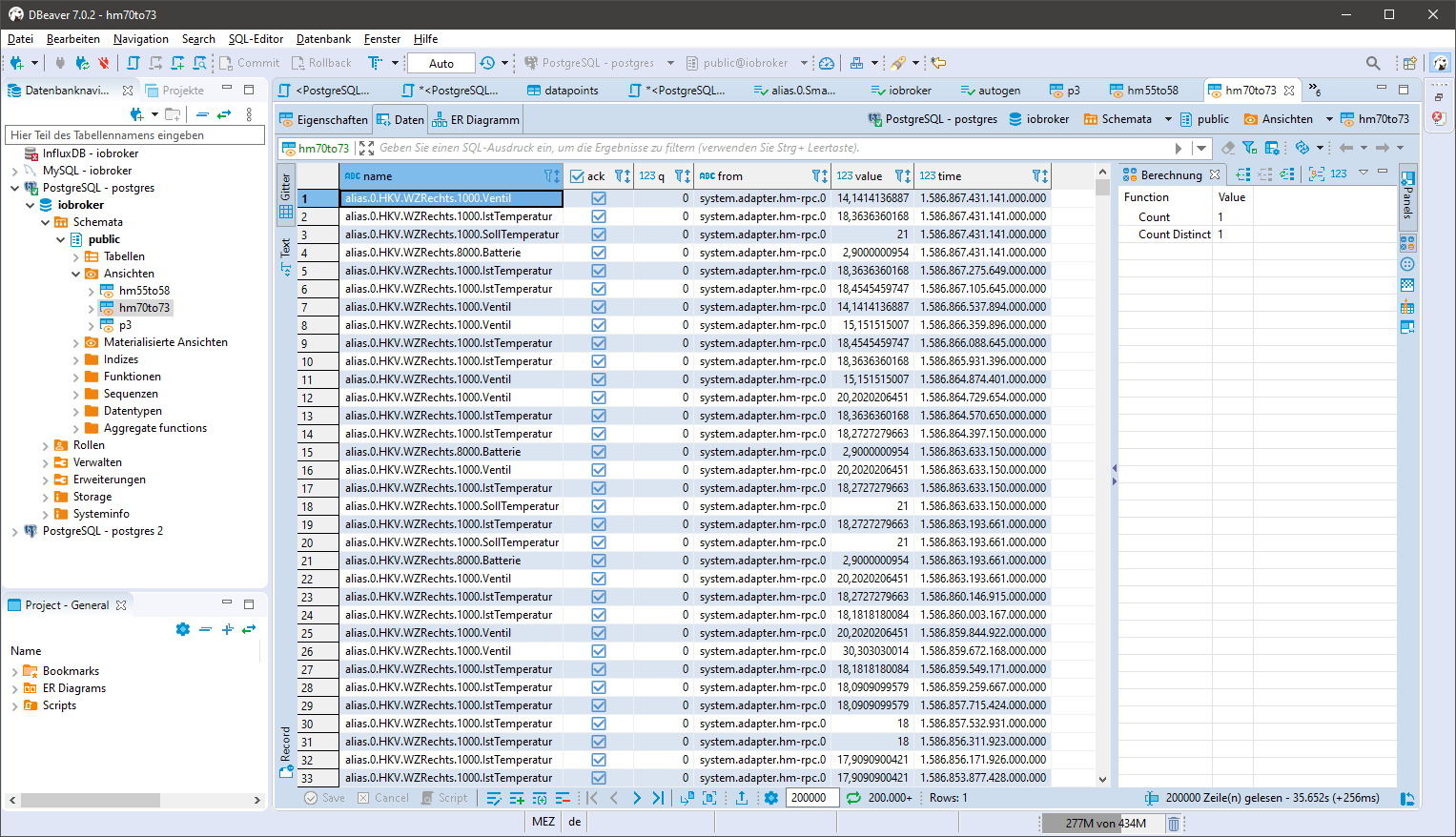
- Python installieren und ggf. die Zusätze installieren
- psycopg2 für PostgreSQL bzw. MySQLdb für MySQL
- influxdb-client und influxdb.
- das Skript von Muntazir Fadhel "Easily Migrate Postgres/MySQL Records to InfluxDB" nehmen (modifizierte Variante hier)
### MySQL DB info ### #import MySQLdb #conn = MySQLdb.connect(host="localhost", # your host, usually localhost # user="john", # your username # passwd="megajonhy", # your password # db="jonhydb") # name of the data base ### PostgreSQL DB info ### import psycopg2 import psycopg2.extras ##### # connection data for PostgreSQL conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='xxx.xxx.xxx.xxx', port=8086, username='xxx', password='xxx', database='xxx') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records curr = conn.cursor('cursor', cursor_factory=psycopg2.extras.RealDictCursor) # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from xxx;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close()Im Skript sind
- in Zeile 15 die Datenbankverbindung für Postgre anzupassen,
- in Zeile 22 die Datenbankverbindung für Influx
- weiter unten Zeile 65 statt xxx ist der Name des Views einzutragen der auf der Datenbank mit der Abfrage aus 1 erzeugt wurde
curr.execute("Select * from xxx;") - der Abschnitt "schema" gibt das mapping der Spalten vor und muss nur angepasst werden wenn die Spaltenbezeichner in der Abfrage aus 1 geändert werden
- für die MySQL user sind die Verbindungsdaten in den Zeilen 2-6 auskommentiert und an eure Umgebung anzupassen.
- In der Python Umgebung das Skript starten...alle 1000 Zeilen/Datensätze kommt eine Fortschrittsmeldung. Während die Abfrage auf der SQL Seite läuft steht da "Processing row # 1"
Bei umfangreichen Abfragen und je nach Umgebung kann das Ganze ein wenig dauern. Teilweise dauerten bei mir die SQL Abfragen bis zu 20min bei 20Mio Datensätzen (Nuc i3 mit 12GB für die SQL VM unter proxmox). Das Skript läuft zuverlässig und mehrere 10 Mio Datensätze von A nach B wurden migriert. Vielleicht kann es jemand brauchen und nochmals Danke für das tolle Projekt und die hilfsbereiten Menschen hier
VG
UlliProxmox auf iNuc, VM's IOB, Raspberrymatic, lxc für InfluxDB2, Grafana, u.a. *** Homematic & Homematic IP, Shellies etc
- In einem SQL GUI (phpmyadmin, HeidiSQL oder DBeaver, etc) oder auf der SQL-Konsole die zu exportierenden Daten in einem View zur Verfügung stellen
-
Moin zusammen,
mein erster post in diesem Forum...
Zu aller erst vielen Dank für diese tolle Plattform und den vielen die mit enormem Aufwand das smarte home nach vorne treiben, tolle Ideen weiter geben, absolut geile Visualisierungen bauen usw. Ich habe bislang selten ein Forum gesehen, in dem so konstruktiv und freundlich miteinander umgegangen wird...weiter soSeit ca 2 Jahren betreibe ich Iobroker und habe bislang die Daten zuerst in MySQL und später dann in PostgreSQL abgelegt. Über die Zeit wurden die ganzen Abfragen und Diagramme mit Grafana nach und nach deutlich träger. Nach kurzer Testphase mit InfluxDB war die Frage geklärt
Mit dem Wechsel auf InfluxDB stellt sich die Frage für den nicht Programmierer wie die Daten von alt nach neu...Die genannten Lösungen haben bei mir nicht zuverlässig funktioniert also die nächste Klappe
- In einem SQL GUI (phpmyadmin, HeidiSQL oder DBeaver, etc) oder auf der SQL-Konsole die zu exportierenden Daten in einem View zur Verfügung stellen
Der View enthält alles was Influx benötigt
create view xxx as SELECT datapoints.name, ts_number.ack as "ack", (ts_number.q*1.0) as "q", sources.name as "from", (ts_number.val*1.0) as "value", (ts_number.ts*1000000) as "time" from ts_number left join datapoints on ts_number.id=datapoints.id left join sources on ts_number._from=sources.id where datapoints.id>=70 and datapoints.id<=73 and q=0 order by ts_number.ts desc;"xxx" Name des View anpassen
in der WHERE Klausel die Datenpunkte entsprechend anpassen, einen Bereich wie hier oder auch eine einzelne id
Für kleine Datenbestände kann die WHERE Klausel auch auf "WHERE q=0" gesetzt werden und über den View in einem Rutsch in Influx übertragen werden.
Beispiel:
- Python installieren und ggf. die Zusätze installieren
- psycopg2 für PostgreSQL bzw. MySQLdb für MySQL
- influxdb-client und influxdb.
- das Skript von Muntazir Fadhel "Easily Migrate Postgres/MySQL Records to InfluxDB" nehmen (modifizierte Variante hier)
### MySQL DB info ### #import MySQLdb #conn = MySQLdb.connect(host="localhost", # your host, usually localhost # user="john", # your username # passwd="megajonhy", # your password # db="jonhydb") # name of the data base ### PostgreSQL DB info ### import psycopg2 import psycopg2.extras ##### # connection data for PostgreSQL conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='xxx.xxx.xxx.xxx', port=8086, username='xxx', password='xxx', database='xxx') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records curr = conn.cursor('cursor', cursor_factory=psycopg2.extras.RealDictCursor) # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from xxx;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close()Im Skript sind
- in Zeile 15 die Datenbankverbindung für Postgre anzupassen,
- in Zeile 22 die Datenbankverbindung für Influx
- weiter unten Zeile 65 statt xxx ist der Name des Views einzutragen der auf der Datenbank mit der Abfrage aus 1 erzeugt wurde
curr.execute("Select * from xxx;") - der Abschnitt "schema" gibt das mapping der Spalten vor und muss nur angepasst werden wenn die Spaltenbezeichner in der Abfrage aus 1 geändert werden
- für die MySQL user sind die Verbindungsdaten in den Zeilen 2-6 auskommentiert und an eure Umgebung anzupassen.
- In der Python Umgebung das Skript starten...alle 1000 Zeilen/Datensätze kommt eine Fortschrittsmeldung. Während die Abfrage auf der SQL Seite läuft steht da "Processing row # 1"
Bei umfangreichen Abfragen und je nach Umgebung kann das Ganze ein wenig dauern. Teilweise dauerten bei mir die SQL Abfragen bis zu 20min bei 20Mio Datensätzen (Nuc i3 mit 12GB für die SQL VM unter proxmox). Das Skript läuft zuverlässig und mehrere 10 Mio Datensätze von A nach B wurden migriert. Vielleicht kann es jemand brauchen und nochmals Danke für das tolle Projekt und die hilfsbereiten Menschen hier
VG
Ulli - In einem SQL GUI (phpmyadmin, HeidiSQL oder DBeaver, etc) oder auf der SQL-Konsole die zu exportierenden Daten in einem View zur Verfügung stellen
-
Moin zusammen,
mein erster post in diesem Forum...
Zu aller erst vielen Dank für diese tolle Plattform und den vielen die mit enormem Aufwand das smarte home nach vorne treiben, tolle Ideen weiter geben, absolut geile Visualisierungen bauen usw. Ich habe bislang selten ein Forum gesehen, in dem so konstruktiv und freundlich miteinander umgegangen wird...weiter soSeit ca 2 Jahren betreibe ich Iobroker und habe bislang die Daten zuerst in MySQL und später dann in PostgreSQL abgelegt. Über die Zeit wurden die ganzen Abfragen und Diagramme mit Grafana nach und nach deutlich träger. Nach kurzer Testphase mit InfluxDB war die Frage geklärt
Mit dem Wechsel auf InfluxDB stellt sich die Frage für den nicht Programmierer wie die Daten von alt nach neu...Die genannten Lösungen haben bei mir nicht zuverlässig funktioniert also die nächste Klappe
- In einem SQL GUI (phpmyadmin, HeidiSQL oder DBeaver, etc) oder auf der SQL-Konsole die zu exportierenden Daten in einem View zur Verfügung stellen
Der View enthält alles was Influx benötigt
create view xxx as SELECT datapoints.name, ts_number.ack as "ack", (ts_number.q*1.0) as "q", sources.name as "from", (ts_number.val*1.0) as "value", (ts_number.ts*1000000) as "time" from ts_number left join datapoints on ts_number.id=datapoints.id left join sources on ts_number._from=sources.id where datapoints.id>=70 and datapoints.id<=73 and q=0 order by ts_number.ts desc;"xxx" Name des View anpassen
in der WHERE Klausel die Datenpunkte entsprechend anpassen, einen Bereich wie hier oder auch eine einzelne id
Für kleine Datenbestände kann die WHERE Klausel auch auf "WHERE q=0" gesetzt werden und über den View in einem Rutsch in Influx übertragen werden.
Beispiel:
- Python installieren und ggf. die Zusätze installieren
- psycopg2 für PostgreSQL bzw. MySQLdb für MySQL
- influxdb-client und influxdb.
- das Skript von Muntazir Fadhel "Easily Migrate Postgres/MySQL Records to InfluxDB" nehmen (modifizierte Variante hier)
### MySQL DB info ### #import MySQLdb #conn = MySQLdb.connect(host="localhost", # your host, usually localhost # user="john", # your username # passwd="megajonhy", # your password # db="jonhydb") # name of the data base ### PostgreSQL DB info ### import psycopg2 import psycopg2.extras ##### # connection data for PostgreSQL conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='xxx.xxx.xxx.xxx', port=8086, username='xxx', password='xxx', database='xxx') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records curr = conn.cursor('cursor', cursor_factory=psycopg2.extras.RealDictCursor) # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from xxx;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close()Im Skript sind
- in Zeile 15 die Datenbankverbindung für Postgre anzupassen,
- in Zeile 22 die Datenbankverbindung für Influx
- weiter unten Zeile 65 statt xxx ist der Name des Views einzutragen der auf der Datenbank mit der Abfrage aus 1 erzeugt wurde
curr.execute("Select * from xxx;") - der Abschnitt "schema" gibt das mapping der Spalten vor und muss nur angepasst werden wenn die Spaltenbezeichner in der Abfrage aus 1 geändert werden
- für die MySQL user sind die Verbindungsdaten in den Zeilen 2-6 auskommentiert und an eure Umgebung anzupassen.
- In der Python Umgebung das Skript starten...alle 1000 Zeilen/Datensätze kommt eine Fortschrittsmeldung. Während die Abfrage auf der SQL Seite läuft steht da "Processing row # 1"
Bei umfangreichen Abfragen und je nach Umgebung kann das Ganze ein wenig dauern. Teilweise dauerten bei mir die SQL Abfragen bis zu 20min bei 20Mio Datensätzen (Nuc i3 mit 12GB für die SQL VM unter proxmox). Das Skript läuft zuverlässig und mehrere 10 Mio Datensätze von A nach B wurden migriert. Vielleicht kann es jemand brauchen und nochmals Danke für das tolle Projekt und die hilfsbereiten Menschen hier
VG
Ulli@UlliJ danke für die Idee mit dem Script.
Hab das script etwas angepasst, damit alle Daten übernommen werden und diese auch auf einem leistungsschwachen Rasperry Pi ausgelesen werden können.
Hab so ca. 22 Millionen Datensätze in die InfluxDB gepackt.GitHub iobroker_mysql_2_influxdb
- In einem SQL GUI (phpmyadmin, HeidiSQL oder DBeaver, etc) oder auf der SQL-Konsole die zu exportierenden Daten in einem View zur Verfügung stellen
-
@UlliJ danke für die Idee mit dem Script.
Hab das script etwas angepasst, damit alle Daten übernommen werden und diese auch auf einem leistungsschwachen Rasperry Pi ausgelesen werden können.
Hab so ca. 22 Millionen Datensätze in die InfluxDB gepackt.GitHub iobroker_mysql_2_influxdb
@JackGruber danke für die coole Ergänzung, habe ich gerade erst gesehen. Das hätte meine Möglichkeiten schon wieder weit überfordert

-
@UlliJ danke für die Idee mit dem Script.
Hab das script etwas angepasst, damit alle Daten übernommen werden und diese auch auf einem leistungsschwachen Rasperry Pi ausgelesen werden können.
Hab so ca. 22 Millionen Datensätze in die InfluxDB gepackt.GitHub iobroker_mysql_2_influxdb
Ich habe nun versucht mit dem Git-Projekt von @JackGruber meine Daten zu Influx zu migrieren.
Nach anfänglichen Schwierigkeiten scheint es augenscheinlich durch zu laufen.
Tatsächlich werden die Daten jedoch nicht migriert und ich kenne mich mit Python nicht aus, um mir z. B. Debug-Points o.ä. zu setzen...
Was kann ich tun, um zu sehen, wo es denn nun hakt?
-
Ich habe nun versucht mit dem Git-Projekt von @JackGruber meine Daten zu Influx zu migrieren.
Nach anfänglichen Schwierigkeiten scheint es augenscheinlich durch zu laufen.
Tatsächlich werden die Daten jedoch nicht migriert und ich kenne mich mit Python nicht aus, um mir z. B. Debug-Points o.ä. zu setzen...
Was kann ich tun, um zu sehen, wo es denn nun hakt?
@MezzoDO was ist genau das problem?
Gibt es ausgaben oder fehlermeldungen? -
@MezzoDO was ist genau das problem?
Gibt es ausgaben oder fehlermeldungen?@JackGruber
ich habe es mittlerweile geschafft, die Daten zu importieren.
Allerdings besteht nun, wie oben schon beschrieben das Problem mit den Bool-Werten.
Wenn ich einerseits eine leere Datenbank mit meinem Import befülle ist "ack" ein Integer.
Lasse ich die InfluxDB erst durch ioBroker anlegen ist es korrekterweise ein bool, aber dann bekomme ich die Fehlermeldung:influxdb.exceptions.InfluxDBClientError: 400: {"error":"partial write: field type conflict: input field \"ack\" on measurement \"info.0.sysinfo.cpu.currentLoad.currentload\" is type integer, already exists as type boolean dropped=1000"}Ich glaube also dass ich im besten Falle den Datentypen beim Import angeben sollte, oder?
Nur: wie? -
@JackGruber
ich habe es mittlerweile geschafft, die Daten zu importieren.
Allerdings besteht nun, wie oben schon beschrieben das Problem mit den Bool-Werten.
Wenn ich einerseits eine leere Datenbank mit meinem Import befülle ist "ack" ein Integer.
Lasse ich die InfluxDB erst durch ioBroker anlegen ist es korrekterweise ein bool, aber dann bekomme ich die Fehlermeldung:influxdb.exceptions.InfluxDBClientError: 400: {"error":"partial write: field type conflict: input field \"ack\" on measurement \"info.0.sysinfo.cpu.currentLoad.currentload\" is type integer, already exists as type boolean dropped=1000"}Ich glaube also dass ich im besten Falle den Datentypen beim Import angeben sollte, oder?
Nur: wie?@MezzoDO ok, das ack feld ist bereits als boolen angelegt, kommt nun aber als int.
Ihc könnte es anpassen, dass dies beim import convertiert wird. -
@MezzoDO ok, das ack feld ist bereits als boolen angelegt, kommt nun aber als int.
Ihc könnte es anpassen, dass dies beim import convertiert wird.@JackGruber said in Frage : Migrate MySQL nach Influxdb:
@MezzoDO ok, das ack feld ist bereits als boolen angelegt, kommt nun aber als int.
Ihc könnte es anpassen, dass dies beim import convertiert wird.Das wäre grandios
")
Mein Script, was ich einsetze:### MySQL DB info ### #import MySQLdb import pymysql conn = pymysql.connect(host="localhost", # your host, usually localhost user="xxx", # your username passwd="xxx", # your password db="iobroker") # name of the data base ### PostgreSQL DB info ### import psycopg2 import psycopg2.extras ##### # connection data for PostgreSQL #conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='localhost', port=8086, username='xxx', password='xxx', database='iobroker') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records #curr = conn.cursor('cursor', cursor_factory=psycopg2.extras.RealDictCursor) curr = conn.cursor(cursor=pymysql.cursors.DictCursor) # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from InfluxData;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close() -
@JackGruber said in Frage : Migrate MySQL nach Influxdb:
@MezzoDO ok, das ack feld ist bereits als boolen angelegt, kommt nun aber als int.
Ihc könnte es anpassen, dass dies beim import convertiert wird.Das wäre grandios
Mein Script, was ich einsetze:### MySQL DB info ### #import MySQLdb import pymysql conn = pymysql.connect(host="localhost", # your host, usually localhost user="xxx", # your username passwd="xxx", # your password db="iobroker") # name of the data base ### PostgreSQL DB info ### import psycopg2 import psycopg2.extras ##### # connection data for PostgreSQL #conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='localhost', port=8086, username='xxx', password='xxx', database='iobroker') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records #curr = conn.cursor('cursor', cursor_factory=psycopg2.extras.RealDictCursor) curr = conn.cursor(cursor=pymysql.cursors.DictCursor) # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from InfluxData;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close() -
Ersetze in deinem Script Zeile 47 mit folgenden zwei zeilen. Auf das einrücken achten!:
if field_label == "ack": record[field_label] = bool(record[field_label])@JackGruber
Ich komme leider auch nicht weiter ...
Habe deinen Script von Github installiert und bekomme folgende Ausgabe:pi@raspberrypi:~/iobroker_mysql_2_influxdb $ python3 migrate.py all Migrate 'all' datapoint(s) ... Total metrics in ts_number: 0 Total metrics in ts_bool: 0 Total metrics in ts_string: 0 Migrated: 0Das ganze passiert innerhalb einer Sekunde .
Die Influxdb habe ich über den iobroker Adapter angelegt.
-
@JackGruber
Ich komme leider auch nicht weiter ...
Habe deinen Script von Github installiert und bekomme folgende Ausgabe:pi@raspberrypi:~/iobroker_mysql_2_influxdb $ python3 migrate.py all Migrate 'all' datapoint(s) ... Total metrics in ts_number: 0 Total metrics in ts_bool: 0 Total metrics in ts_string: 0 Migrated: 0Das ganze passiert innerhalb einer Sekunde .
Die Influxdb habe ich über den iobroker Adapter angelegt.
-
Hi @simatec, hab einen mini Fehler im Script gefunden. Durch einen BUG musste das
ALLgroßgeschrieben werden.
Hab das Script angepasst, einfach neu herunterladen oder dasALLgroßschreiben.@JackGruber
Danke für den Tipp ... Ich hatte es auch einzeln versucht und dann auch jedes Objekt einzeln importiert.
War zwar etwas Aufwand aber ging super")
-
Wie und wo kann ich das Script benutzen? In iobroker javascript oder Konsole? iobroker läuft bei mir im Docker Container....
@base python auf deinem PC installieren, das script wie auf der git seite beschrieben installieren und benutzen.
-
@base python auf deinem PC installieren, das script wie auf der git seite beschrieben installieren und benutzen.
ich bekomme in diese Zeile einen Syntax Error:
print(f"Processing row {processed_rows + 1:,} to {processed_rows + len(selected_rows):,} from LIMIT {start_row:,} / {start_row + query_max_rows:,} " + table + " - " + metric['name'] + " (" + str(metric_nr) + "/" + str(metric_count) + ")")er meckert die Anführungsstriche vor table an
-
ich bekomme in diese Zeile einen Syntax Error:
print(f"Processing row {processed_rows + 1:,} to {processed_rows + len(selected_rows):,} from LIMIT {start_row:,} / {start_row + query_max_rows:,} " + table + " - " + metric['name'] + " (" + str(metric_nr) + "/" + str(metric_count) + ")")er meckert die Anführungsstriche vor table an

631
Online32.4k
Users81.3k
Topics1.3m
Posts