

Grafana - aggregierte Werte addieren und subtrahieren
-
Hallo zusammen.
Ich lasse mir über folgenden Syntax die monatlichen Werte ausrechnen:
Ich habe mehrere Werte: ZB: Z1, Z2, Z3, Z4
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z1" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start")jetzt würde ich gerne die monatlichen Werte addieren oder subtrahieren.
zB: Monatswert Z1 - Monatswert Z2Ich habe leider keine so richtige Idee, hat zufällig jemand ein Beispiel?
lg
bit@bitwicht sagte in Grafana - aggregierte Werte addieren und subtrahieren:
Ich habe leider keine so richtige Idee, hat zufällig jemand ein Beispiel?
So ähnlich müsste es gehen, in der letzten Zeile musst du dann die Operationen anpassen:
Z1= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "measurementZ1") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) Z2= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "measurementZ2") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) |>map(fn: (r) => ({_time: r._time, _Erg:r._value_Z1 - r._value_Z2}))Edit: "timeSrc" muss noch angepasst werden. Das sollte aber klar sein.
NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
Danke.
jetzt habe ich noch ein anderes Problem festgestellt :-(
der Z1 Wert ist in der Datenbank als Watt Wert. der Z2 Wert als KW Wert.
Kann ich das dem Syntax beibringen?@bitwicht sagte in Grafana - aggregierte Werte addieren und subtrahieren:
der Z1 Wert ist in der Datenbank als Watt Wert. der Z2 Wert als KW Wert.
Kann ich das dem Syntax beibringen?je nachdem, was die Zielgröße sein soll:
|>map(fn: (r) => ({_time: r._time, _Erg:r._value_Z1/1000.0 + r._value_Z2}))oder
|>map(fn: (r) => ({_time: r._time, _Erg:r._value_Z1 + r._value_Z2*1000.0})) -
Danke, das teste ich gleich mal.
Wo würde ich es hier einbauen:
from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z1" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start") -
Danke, das teste ich gleich mal.
Wo würde ich es hier einbauen:
from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z1" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start")@bitwicht sagte in Grafana - aggregierte Werte addieren und subtrahieren:
Danke, das teste ich gleich mal.
Wo würde ich es hier einbauen:
einfach meine letzte Zeile ersetzen, wo schon die "map" Funktion steht.
-
ich meine wenn ich nicht addiere/subtrahiere kann ich es dann direkt hier einbauen oder muss ich dann auch Z1= ......... und mit map arbeiten?
from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z1" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start") -
ich meine wenn ich nicht addiere/subtrahiere kann ich es dann direkt hier einbauen oder muss ich dann auch Z1= ......... und mit map arbeiten?
from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z1" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start") -
ich habe ein Panel mit:
Querry1:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z1" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start")Querry 2:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z2" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start")Z1 Wert in der Datenbank zB: 1,5 (weil es kW sind)
Z2 Wert in der Datenbank zB: 1500 (weil es Watt sind)Die Unit gilt ja für das ganze Board, nicht pro Query.
Wenn ich die Unit jetzt auf Watt stelle, passt der Z1 Wert nicht.
Wenn ich sie auf kW stelle, passt der Z2 wert nicht.Ich müsste dem Query mit Z1 beibringen, dass der Wert *1000 ist und die Unit dann auf Watt stellen.
-
ich habe ein Panel mit:
Querry1:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z1" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start")Querry 2:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Z2" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start")Z1 Wert in der Datenbank zB: 1,5 (weil es kW sind)
Z2 Wert in der Datenbank zB: 1500 (weil es Watt sind)Die Unit gilt ja für das ganze Board, nicht pro Query.
Wenn ich die Unit jetzt auf Watt stelle, passt der Z1 Wert nicht.
Wenn ich sie auf kW stelle, passt der Z2 wert nicht.Ich müsste dem Query mit Z1 beibringen, dass der Wert *1000 ist und die Unit dann auf Watt stellen.
@bitwicht sagte in Grafana - aggregierte Werte addieren und subtrahieren:
Ich müsste dem Query mit Z1 beibringen, dass der Wert *1000 ist und die Unit dann auf Watt stellen.
Ah, das hatte ich falsch verstanden. Dann einfach unten anhängen:
|>map(fn: (r) => ({_time: r._time, Z1:r._value*1000.0})) -
super, das hat geklappt.
aktuell zerreißt er mir noch die Grafik:
Z1= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-SH-Wolf-Heizung-GESAMT") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) Z2= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-PV-Einspeisung") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) |>map(fn: (r) => ({_time: r._time, _Erg:r._value_Z1 + r._value_Z2*1000.0}))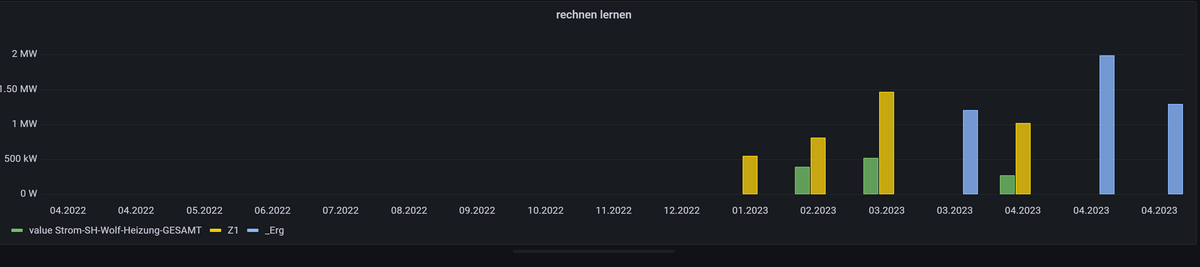
Die blauen Balken sind nach rechts verschoben ?!
Siehst du meinen Fehler?
-
super, das hat geklappt.
aktuell zerreißt er mir noch die Grafik:
Z1= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-SH-Wolf-Heizung-GESAMT") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) Z2= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-PV-Einspeisung") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) |>map(fn: (r) => ({_time: r._time, _Erg:r._value_Z1 + r._value_Z2*1000.0}))Die blauen Balken sind nach rechts verschoben ?!
Siehst du meinen Fehler?
@bitwicht
<meinen Unsinn gelöscht>nimm am Ende diese Map-Funktion, dann kannst du dir die anderen beiden Queries sparen, so hast du direkt eine Tabelle mit drei Spalten:
Z1= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-SH-Wolf-Heizung-GESAMT") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) Z2= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-PV-Einspeisung") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) |>map(fn: (r) => ({_time: r._time, Z1: r._value_Z1, Z2: r._value_Z2*1000.0, Summe: r._value_Z2*1000.0+r._value_Z1})) -
Perfekt! Danke!
Das geht. Jetzt muss ich nur noch das ganze Zeug zusammen bauen das ich brauche :-) -
Unten in dem "map" ist doch die Summe eine Variable ?
Kann ich diese dann gleich nutzen um weiter zu rechnen?zB:
|>map(fn: (r) => ({_time: r._time, Z1: r._value_Z1, Z2: r._value_Z2*1000.0, Summe: r._value_Z2*1000.0+r._value_Z1, Summe2: r._value_Summe-r._value_Z2 }))oder kann ich eine neue definieren mit:
Z3 = Z1-Z2 -
Unten in dem "map" ist doch die Summe eine Variable ?
Kann ich diese dann gleich nutzen um weiter zu rechnen?zB:
|>map(fn: (r) => ({_time: r._time, Z1: r._value_Z1, Z2: r._value_Z2*1000.0, Summe: r._value_Z2*1000.0+r._value_Z1, Summe2: r._value_Summe-r._value_Z2 }))oder kann ich eine neue definieren mit:
Z3 = Z1-Z2@bitwicht sagte in Grafana - aggregierte Werte addieren und subtrahieren:
oder kann ich eine neue definieren mit:Z3 = Z1-Z2
Nein, so funktioniert das leider nicht. "Summe", "Z1" und "Z2" sind Spaltennamen, mit denen man meines Wissens nicht weiter rechnen kann.
Variablen kann man in Flux zwar verwenden, wenn diese allerdings einmal festgelegt sind, sind sie nicht mehr änderbar. Das kann man z.B. nutzen, um vor den Queries Start- und Stop-Zeitstempel zu berechnen. Diese Zeitstempel gelten dann für die gesamte Query.
Du könntest unten eine weitere map Funktion dranhängen und weiterechnen, wobei ich nicht weiß, was du erreichen willst.
|>map(fn: (r) => ({_time: r._time, Z3: r.Z1+r.Z2})) -
Hast du eine Idee ?
Ich habe jetzt:
Z1=
from(Z2=
from(Z3=
from(Z4=
from(Jetzt müsste ich berechnen:
Z1-Z2 = Summe und dann Summe + Z3Ich sehe aber gerade, könnte ich das einfach in eine Klammer packen wie ich es mathematisch berechnen würde?
((Z1-Z2) + Z3) -
Hast du eine Idee ?
Ich habe jetzt:
Z1=
from(Z2=
from(Z3=
from(Z4=
from(Jetzt müsste ich berechnen:
Z1-Z2 = Summe und dann Summe + Z3Ich sehe aber gerade, könnte ich das einfach in eine Klammer packen wie ich es mathematisch berechnen würde?
((Z1-Z2) + Z3)@bitwicht sagte in Grafana - aggregierte Werte addieren und subtrahieren:
Ich sehe aber gerade, könnte ich das einfach in eine Klammer packen wie ich es mathematisch berechnen würde?
((Z1-Z2) + Z3)ja, das geht natürlich, also Summe2: (r._value_Z1-r._value_Z2)+r._value_Z3. Wobei in diesem Fall die Klammer mathematisch unnötig ist, oder?
-
da hast du recht, wär dann ja nur bei +/- mit *// relevant.
kann ich mir in diesem map() nur 3 werte anzeigen lassen?
Wenn ich da 4,5,6 Werte anzeigen lassen will zeit es immer keine Balken an?
Muss ich die Z1 bis Z4 im join alle einbauen ?
join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) dann
join(tables: {Z1: Z1, Z2: Z2, Z3:Z3, Z4:Z4}, on: ["_time"])Muss ich im map immer mit r.value arbeiten?
also:
{_time: r._time, Z1: r._value_Z1, Z2: r._value_Z2, Z3: r._value_Z3,
oder
{_time: r._time, Z1: Z1, Z2: Z2, Z3:Z3, -
da hast du recht, wär dann ja nur bei +/- mit *// relevant.
kann ich mir in diesem map() nur 3 werte anzeigen lassen?
Wenn ich da 4,5,6 Werte anzeigen lassen will zeit es immer keine Balken an?
Muss ich die Z1 bis Z4 im join alle einbauen ?
join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) dann
join(tables: {Z1: Z1, Z2: Z2, Z3:Z3, Z4:Z4}, on: ["_time"])Muss ich im map immer mit r.value arbeiten?
also:
{_time: r._time, Z1: r._value_Z1, Z2: r._value_Z2, Z3: r._value_Z3,
oder
{_time: r._time, Z1: Z1, Z2: Z2, Z3:Z3,@bitwicht sagte in Grafana - aggregierte Werte addieren und subtrahieren:
kann ich mir in diesem map() nur 3 werte anzeigen lassen?
Wenn ich da 4,5,6 Werte anzeigen lassen will zeit es immer keine Balken an?
Nein, das können beliebig viele werden. Am besten mal in den Dataexplorer der Influxdb eingeben und sich die Daten anzeigen lassen. Da lernt man auch gut, was man da eigentlich macht. Was Grafana aus dem Ergebnis macht, steht auf einem anderen Blatt, sollte aber gehen.
Muss ich die Z1 bis Z4 im join alle einbauen ?
join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) dann
join(tables: {Z1: Z1, Z2: Z2, Z3:Z3, Z4:Z4}, on: ["_time"])Stimmt, in einem Join können immer nur zwei Streams verarbeitet werden. D.h, du müsstest zunächst Z1+Z2 joinen, dann Z3+Z4 und zum Schluss Z12+Z34. Habe ich noch nicht gemacht, müsste aber gehen.
Muss ich im map immer mit r.value arbeiten?
Ja, weil die Spalten so heißen. In einer Map-Funktion ist "r" immer die Referenz auf die gerade zu verarbeitende Zeile.
NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
@bitwicht sagte in Grafana - aggregierte Werte addieren und subtrahieren:
kann ich mir in diesem map() nur 3 werte anzeigen lassen?
Wenn ich da 4,5,6 Werte anzeigen lassen will zeit es immer keine Balken an?
Nein, das können beliebig viele werden. Am besten mal in den Dataexplorer der Influxdb eingeben und sich die Daten anzeigen lassen. Da lernt man auch gut, was man da eigentlich macht. Was Grafana aus dem Ergebnis macht, steht auf einem anderen Blatt, sollte aber gehen.
Muss ich die Z1 bis Z4 im join alle einbauen ?
join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) dann
join(tables: {Z1: Z1, Z2: Z2, Z3:Z3, Z4:Z4}, on: ["_time"])Stimmt, in einem Join können immer nur zwei Streams verarbeitet werden. D.h, du müsstest zunächst Z1+Z2 joinen, dann Z3+Z4 und zum Schluss Z12+Z34. Habe ich noch nicht gemacht, müsste aber gehen.
Muss ich im map immer mit r.value arbeiten?
Ja, weil die Spalten so heißen. In einer Map-Funktion ist "r" immer die Referenz auf die gerade zu verarbeitende Zeile.
@marc-berg sagte in Grafana - aggregierte Werte addieren und subtrahieren:
Stimmt, in einem Join können immer nur zwei Streams verarbeitet werden. D.h, du müsstest zunächst Z1+Z2 joinen, dann Z3+Z4 und zum Schluss Z12+Z34. Habe ich noch nicht gemacht, müsste aber gehen.
Sieht dann z.B. so aus:
Z12=join(tables: {Z1: Z1, Z2: Z2}, on: ["_time"]) Z34=join(tables: {Z3: Z3, Z4: Z4}, on: ["_time"]) join(tables: {Z12: Z12, Z34: Z34}, on: ["_time"]) -
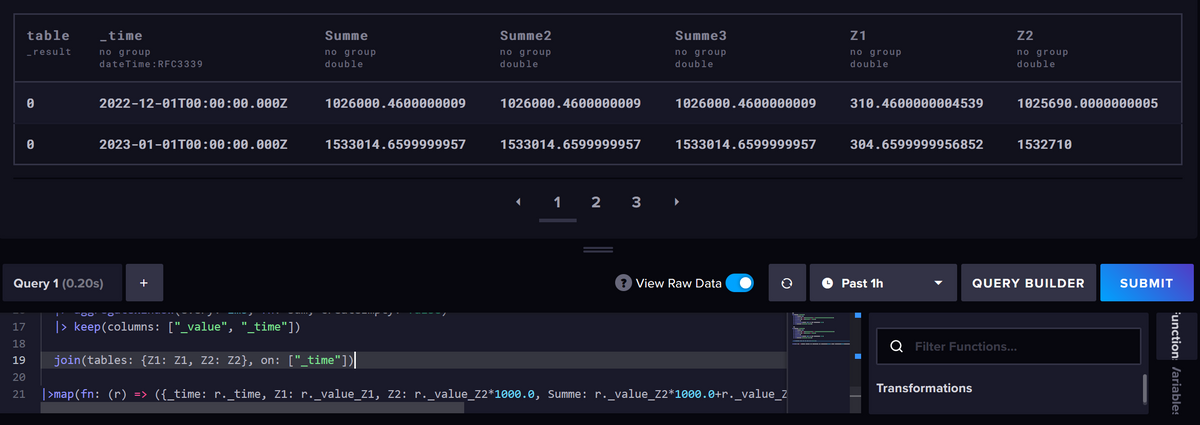
klappt super, Danke.
Nur die Monate der Balken sind um einen Monat verschoben was ich nicht verstehe.
Wenn ich den großen Syntax nehme ist es verschoben:
import "timezone" option location = timezone.location(name: "Europe/Berlin") StromIRHausEinspeisung= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-Haus-Einspeisung") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) StromIRHausBezug= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-Haus-Bezug") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) StromIRPVEinspeisung= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-PV-Einspeisung") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) StromIRPVBezug= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-PV-Bezug") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) |> keep(columns: ["_value", "_time"]) Z2= from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-PV-Einspeisung") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false) join1= join(tables: {StromIRHausEinspeisung: StromIRHausEinspeisung, StromIRPVEinspeisung: StromIRPVEinspeisung}, on: ["_time"]) join2= join(tables: {StromIRHausBezug: StromIRHausBezug, StromIRPVBezug: StromIRPVBezug}, on: ["_time"]) join(tables: {join1: join1, join2: join2}, on: ["_time"]) |>map(fn: (r) => ({_time: r._time, StromIRHausEinspeisung: r._value_StromIRHausEinspeisung, StromIRPVEinspeisung: r._value_StromIRPVEinspeisung, StromIRPVBezug: r._value_StromIRPVBezug, StromIRHausBezug: r._value_StromIRHausBezug, PV_Eigenverbrauch: r._value_StromIRPVEinspeisung-r._value_StromIRHausEinspeisung, Verbrauch_Haus: r._value_StromIRPVEinspeisung-r._value_StromIRHausEinspeisung+r._value_StromIRHausBezug }))Wenn ich den kleinen nehme passt es:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: -1y) |> filter(fn: (r) => r["_measurement"] == "Strom-IR-Haus-Einspeisung" and r["_field"] == "value" ) |> difference() |> aggregateWindow(every: 1mo, fn: sum, timeSrc: "_start")Ich sehe aber nicht, was bei dem großen anders ist, dass es den Monat um einen nach rechts verschiebt ?!
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
381
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge