

Werte der influxDB als Excel ausleiten
-
Guten Abend,
das habe ich gerade noch einmal versucht. das Diagramm für 7 Tage und dann als csv ausgeleitet.
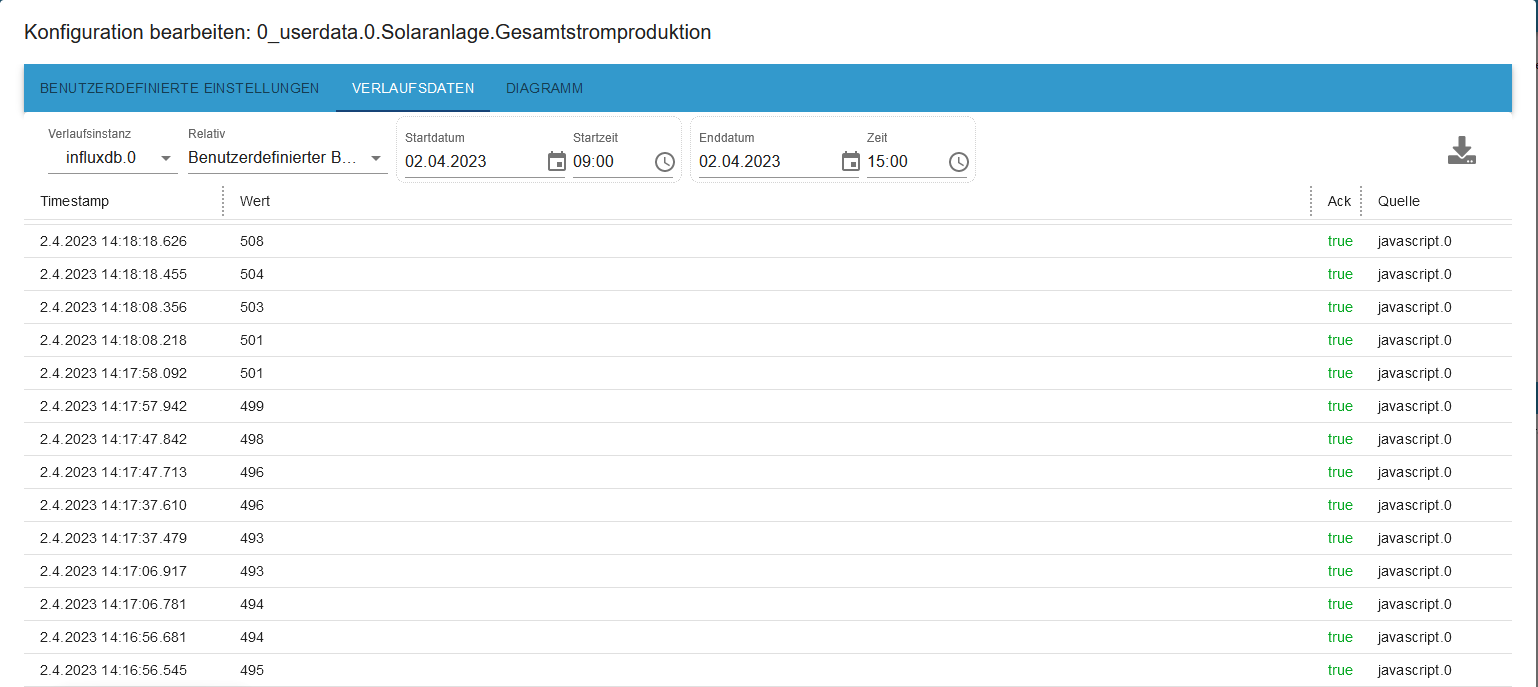
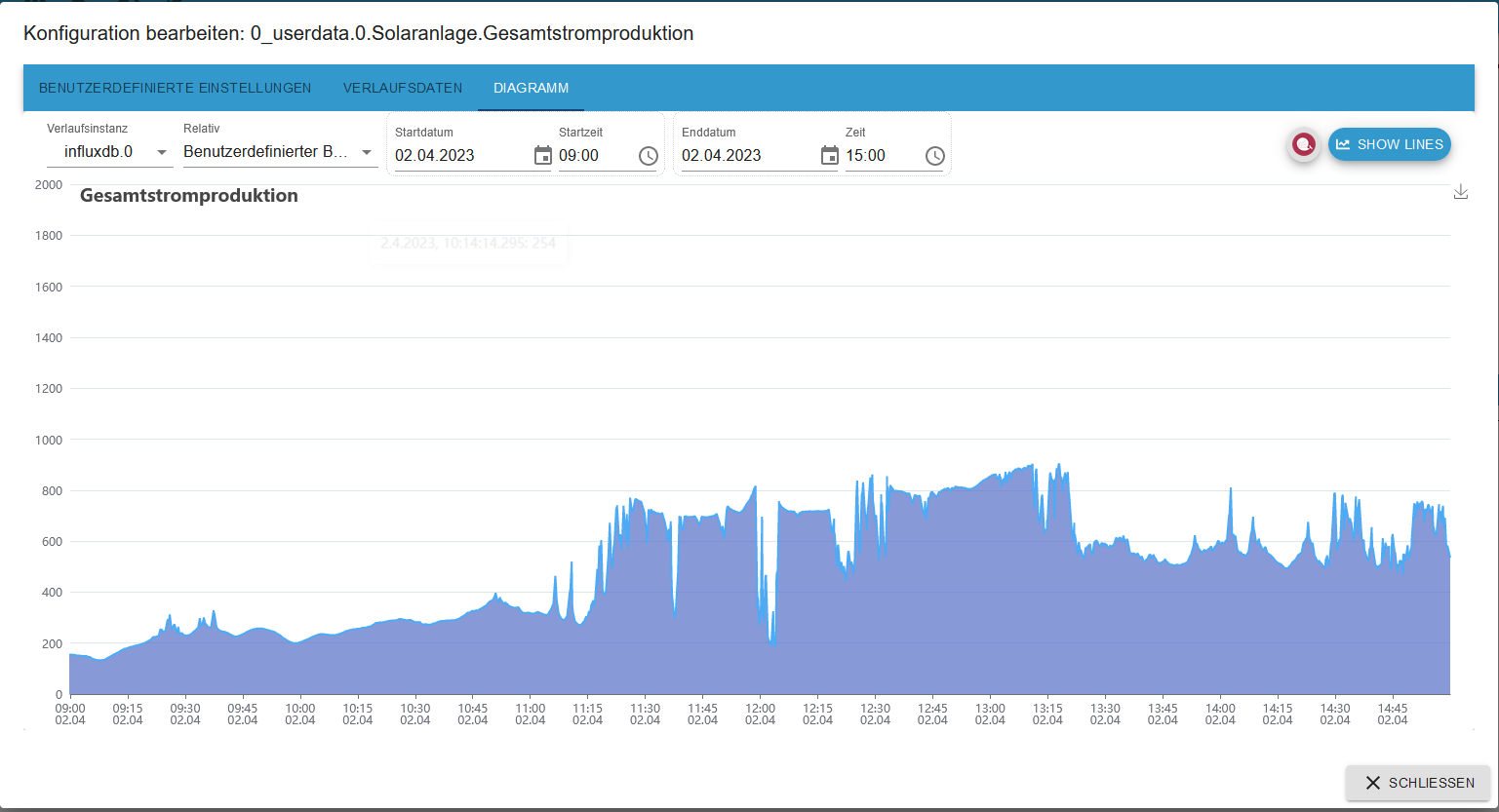
In der cvs sind jetzt aber nur noch Daten im 30 min Abständen, alles dazwischen fehlt.
Aber was noch merkwürdiger ist, laut csv hat meine Anlage gegen 5:30 angefangen zu produzieren, da ist es aber noch stock dunkel. In der Grafik dagegen kann man sehen das die Produktion erst um 7:30 begonnen hat.
Das Problem mit der falschen Zeit ist mir auch schon vor der Zeitumstellung aufgefallen, da wars halt ne Stunde, jetzt sind es 2. (Das gleiche habe ich schon beim History Adapter festgestellt und ja, der Pi ist auf Deutschland /Berlin eingestellt ;-) )
Gibt es für das Phänomen der 2 Stunden eine Erklärung und kann man die Daten auch abrufen ohne nur 30 min Schritte zu bekommen?
Gruß Duffy
PS: wenn ich die Daten beim Datenpunkt selber anschaue passt die Zeit im übrigen.
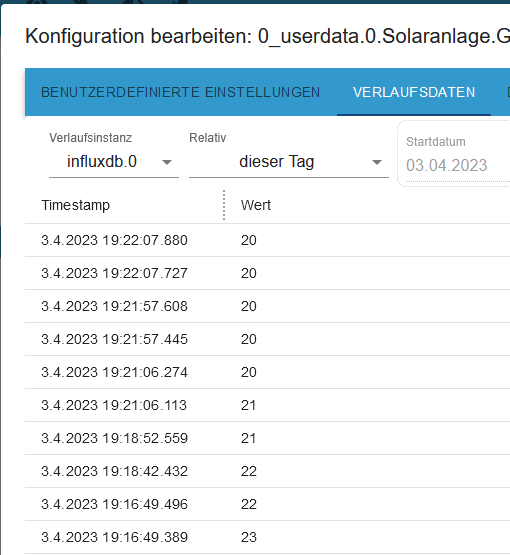
Leite ich die Daten hier aus kommt das heraus:
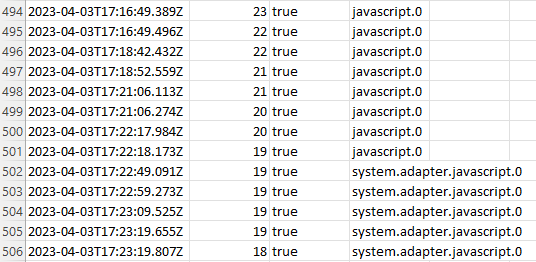
Moin,
die Aufzeichnungszeit in
influxDBist dieUTC Zeit
Das bedeutet, dass du, wenn wir Winterzeit (Normalzeit) haben auf den Wert in derinfluxDBeine Stunde und, wenn wir Sommerzeit haben zwei Stunden drauf rechnen musst.Hier mal zwei Bilder, hoffe, es ist verständlich, was ich meine.
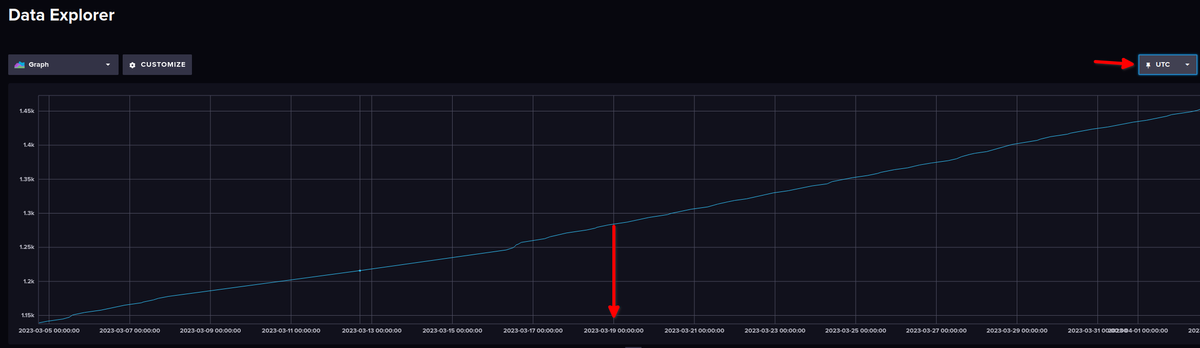
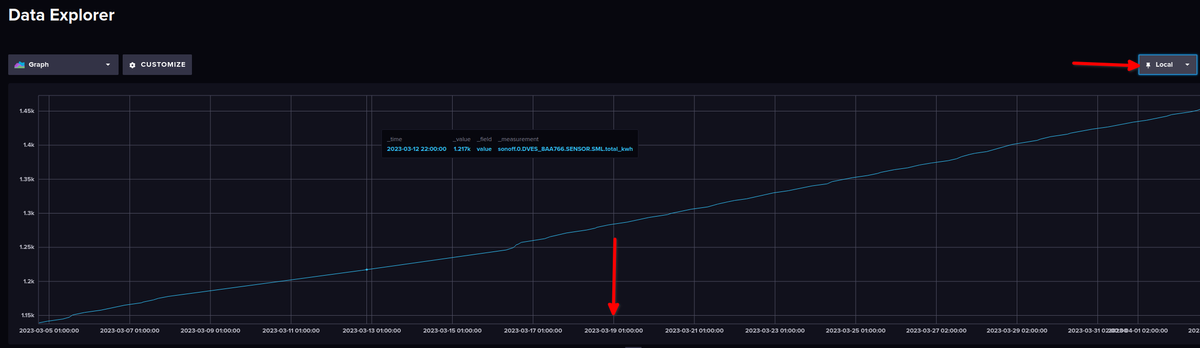
Dadurch, dass ich die Anzeige von UTC auf Local (Europa/Berlin) ändere, ist der Wert, der um 00:00 Uhr nach UTC aufgezeichnet wurde, ja eigentlich schon 01:00 Uhr in Deutschland.
Daher muss man das in den Abfragen, berücksichtigen, siehe → https://docs.influxdata.com/flux/v0.x/stdlib/timezone/location/Beispiel:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker_strom") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh") |> filter(fn: (r) => r["_field"] == "value") |> set(key: "_field", value: "Tag") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference()VG
Bernd -
Guten Abend,
das habe ich gerade noch einmal versucht. das Diagramm für 7 Tage und dann als csv ausgeleitet.
In der cvs sind jetzt aber nur noch Daten im 30 min Abständen, alles dazwischen fehlt.
Aber was noch merkwürdiger ist, laut csv hat meine Anlage gegen 5:30 angefangen zu produzieren, da ist es aber noch stock dunkel. In der Grafik dagegen kann man sehen das die Produktion erst um 7:30 begonnen hat.Das Problem mit der falschen Zeit ist mir auch schon vor der Zeitumstellung aufgefallen, da wars halt ne Stunde, jetzt sind es 2. (Das gleiche habe ich schon beim History Adapter festgestellt und ja, der Pi ist auf Deutschland /Berlin eingestellt ;-) )
Gibt es für das Phänomen der 2 Stunden eine Erklärung und kann man die Daten auch abrufen ohne nur 30 min Schritte zu bekommen?
Gruß Duffy
PS: wenn ich die Daten beim Datenpunkt selber anschaue passt die Zeit im übrigen.
Leite ich die Daten hier aus kommt das heraus:
@duffy sagte in Werte der influxDB als Excel ausleiten:
Gibt es für das Phänomen der 2 Stunden eine Erklärung und kann man die Daten auch abrufen ohne nur 30 min Schritte zu bekommen?
Du musst auf "Script Editor" gehen und die Zeile mit "aggregateWindow" löschen, standardmäßig werden die Datensätze sonst zusammengefasst.
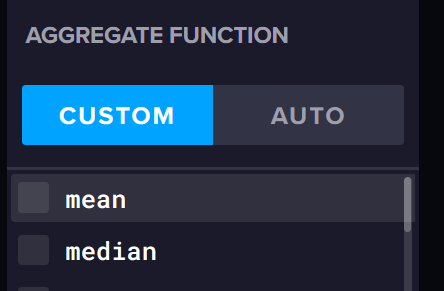
Oder alternativ die "Aggregate Function" deaktivieren, das Ergebnis ist das Gleiche:
NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
@duffy sagte in Werte der influxDB als Excel ausleiten:
Gibt es für das Phänomen der 2 Stunden eine Erklärung und kann man die Daten auch abrufen ohne nur 30 min Schritte zu bekommen?
Du musst auf "Script Editor" gehen und die Zeile mit "aggregateWindow" löschen, standardmäßig werden die Datensätze sonst zusammengefasst.
Oder alternativ die "Aggregate Function" deaktivieren, das Ergebnis ist das Gleiche:
Guten Morgen,
vielen Dank für den Hinweis das werde ich heute Abend gleich mal testen.
Gruß Duffy
-
Moin,
die Aufzeichnungszeit in
influxDBist dieUTC Zeit
Das bedeutet, dass du, wenn wir Winterzeit (Normalzeit) haben auf den Wert in derinfluxDBeine Stunde und, wenn wir Sommerzeit haben zwei Stunden drauf rechnen musst.Hier mal zwei Bilder, hoffe, es ist verständlich, was ich meine.
Dadurch, dass ich die Anzeige von UTC auf Local (Europa/Berlin) ändere, ist der Wert, der um 00:00 Uhr nach UTC aufgezeichnet wurde, ja eigentlich schon 01:00 Uhr in Deutschland.
Daher muss man das in den Abfragen, berücksichtigen, siehe → https://docs.influxdata.com/flux/v0.x/stdlib/timezone/location/Beispiel:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker_strom") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh") |> filter(fn: (r) => r["_field"] == "value") |> set(key: "_field", value: "Tag") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference()VG
Bernd@dp20eic
Hallo Bernd,
Hölle ist das kompliziert. Wo finde ich den die Datei aus deinem Screenshot?
Ich meine den Screenshot um die Zeit zu "Synchronisieren"
Ich glaub in der Datei kann man so viel verbiegen das die 1-2 Stunden das geringere Übel sind .
.Zu deinem 2 Post mit der Aggregatfunktion, was muss ich da dann einstellen? Das ist das Fenster im Data Explorer unten rechts, richtig?
und wenn ich schon dabei bin
 in deiner ersten Datei verweist du auf iobroker_strom. Ich habe mal gelesen das man verschiedene Buckets anlegen kann (muss) alleine schon wegen wegen der Datenvorhaltung. Wie lege ich weitere angelegte Buckets im iobroker bzw. unter influxDB an?
in deiner ersten Datei verweist du auf iobroker_strom. Ich habe mal gelesen das man verschiedene Buckets anlegen kann (muss) alleine schon wegen wegen der Datenvorhaltung. Wie lege ich weitere angelegte Buckets im iobroker bzw. unter influxDB an?
und wie beinflusse ich welche Daten in welches Buckt gehen?
Momentan rutscht alles in "iobroker-data" und dort hebe ich alles (überflüssigerweise) ewig auf. Eigentlich würden mir die Daten von der PV dauerhaft reichen.Viele Grüße Duffy987
-
@dp20eic
Hallo Bernd,
Hölle ist das kompliziert. Wo finde ich den die Datei aus deinem Screenshot?
Ich meine den Screenshot um die Zeit zu "Synchronisieren"
Ich glaub in der Datei kann man so viel verbiegen das die 1-2 Stunden das geringere Übel sind .Zu deinem 2 Post mit der Aggregatfunktion, was muss ich da dann einstellen? Das ist das Fenster im Data Explorer unten rechts, richtig?
und wenn ich schon dabei bin
in deiner ersten Datei verweist du auf iobroker_strom. Ich habe mal gelesen das man verschiedene Buckets anlegen kann (muss) alleine schon wegen wegen der Datenvorhaltung. Wie lege ich weitere angelegte Buckets im iobroker bzw. unter influxDB an?und wie beinflusse ich welche Daten in welches Buckt gehen?
Momentan rutscht alles in "iobroker-data" und dort hebe ich alles (überflüssigerweise) ewig auf. Eigentlich würden mir die Daten von der PV dauerhaft reichen.Viele Grüße Duffy987
Moin,
@duffy sagte in Werte der influxDB als Excel ausleiten:
@dp20eic
Hallo Bernd,
Hölle ist das kompliziert. Wo finde ich den die Datei aus deinem Screenshot?
Ich meine den Screenshot um die Zeit zu "Synchronisieren"
Ich glaub in der Datei kann man so viel verbiegen das die 1-2 Stunden das geringere Übel sind .Nein, ist eigentlich nicht so kompliziert, das ist durch die Implementierung, wenn es richtig gemacht wurde, alles schon vorgegeben. Geht jetzt aber hier zu weit.
Ich habe meine Screenshots in aus dem UI voninfluxDb→ https://deine-influxdb-ip:8086/
Das ist auch keine Synchronisierung, sondern die Implementierung voninfluxDBum schnell von UTC auf Lokal Europa/Berlin umzuschalten, diese Einstellung ist somit kein Bestandteil der FLUX Abfrage.
Wenn Du in Grafana die korrekten Werte brauchst, dann musst Du immer das am Anfang einfügenimport "timezone" option location = timezone.location(name: "Europe/Berlin")Zu deinem 2 Post mit der Aggregatfunktion, was muss ich da dann einstellen? Das ist das Fenster im Data Explorer unten rechts, richtig?
Kann Dir gerade nicht folgen, welches Fenster Du meinst, etwa das was @Marc-Berg gepostet hat?
Ja, das ist auch aus der UI voninfluxDB.Ich baue immer erst in der UI meine Abfrage und kopiere diese dann bei
Grafanarein, da es aktuell noch keine gute Vervollständigung inGrafanafürFLUXgibt.und wenn ich schon dabei bin
in deiner ersten Datei verweist du auf iobroker_strom. Ich habe mal gelesen das man verschiedene Buckets anlegen kann (muss) alleine schon wegen wegen der Datenvorhaltung. Wie lege ich weitere angelegte Buckets im iobroker bzw. unter influxDB an?und wie beinflusse ich welche Daten in welches Buckt gehen?
Momentan rutscht alles in "iobroker-data" und dort hebe ich alles (überflüssigerweise) ewig auf. Eigentlich würden mir die Daten von der PV dauerhaft reichen.Jetzt wird es kompliziert, :) denn es gibt da mehrere Wege und hängt etwas vom Wissensstand ab.
Möglichkeit 1:
- Du legst Dir mehrere
influxDb - Adapter InstanzenimioBrokeran- in der jeweiligen Instanz, kannst Du dann die Retention Police (Vorhaltezeit) anpasst,
- vielleicht 1 Jahr in der einen Instanz und
- 90 Tage in der anderen Instanz.
- ich handhabe das anders, es gibt bei mir nur eine Instanz im
ioBroker- Diese ist auf nur 30 Tage eingestellt und sammelt alles, was ich auswerten möchte.
- in
influxDBhabe ich dann verschiedene Tasks, die mir die Daten dann auf unterschiedlicheBucketsschreiben, welche dann auch die Vorhaltezeiten haben, die ich dann für sinnvoll halte. - das kann so weit gehen, dass ich aus dem 30 Tages Bucket, ein Task habe, der mir auch gleich die Daten auf z.B.: 24 aggregiert und in das Tages Bucket schreibt, wo wieder ein Task läuft, der aus 7 Tagen eine Woche aggregiert und in das Wochen Bucket schreibt, wo wieder ein Task aus 4 Wochen ein Monat aggregiert, ....
Du siehst, kann das schon ein ganzes Stück Arbeit sein, ich bin mit meiner Lösung auch nicht fertig und übe noch :)
VG
Bernd - Du legst Dir mehrere
-
@duffy sagte in Werte der influxDB als Excel ausleiten:
Gibt es für das Phänomen der 2 Stunden eine Erklärung und kann man die Daten auch abrufen ohne nur 30 min Schritte zu bekommen?
Du musst auf "Script Editor" gehen und die Zeile mit "aggregateWindow" löschen, standardmäßig werden die Datensätze sonst zusammengefasst.
Oder alternativ die "Aggregate Function" deaktivieren, das Ergebnis ist das Gleiche:
Hallo marc berg
Ich benötige glaube da noch mal Deine Unterstützung.
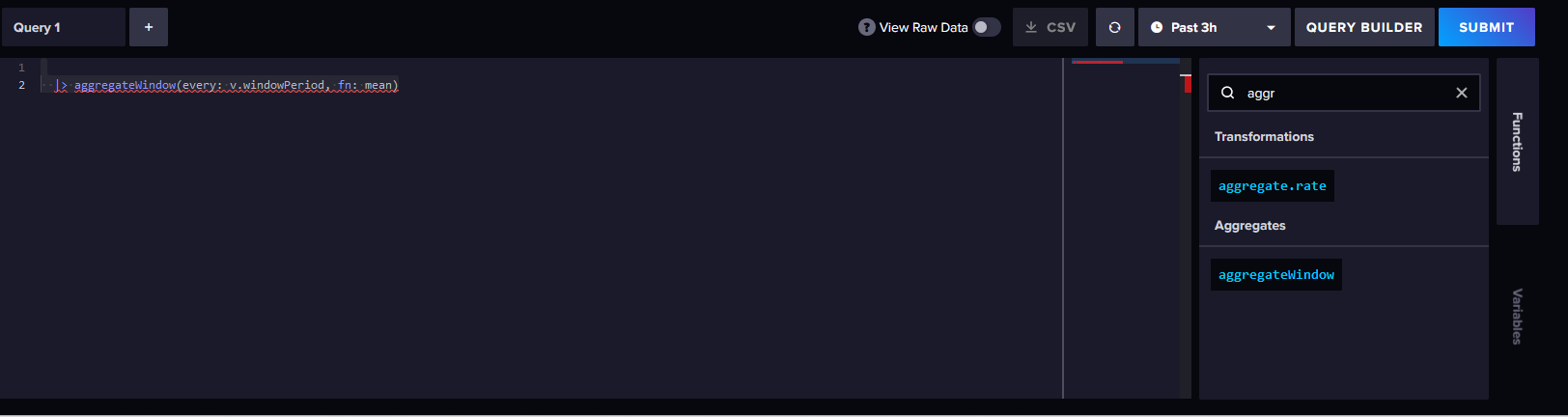
Bin ich hier richtig und wenn ja wie deaktiviere ich die "Aggregate Function" bzw wie speichere ich die Änderung?
VG Duffy
Nix besonderes; iob auf Respberry pi 4 (8GB) mit 32 GB SSD
Node.js: v22.23.1
NPM: 10.9.4
js-controller 7.1.2
Linux: Trixie -
Moin,
@duffy sagte in Werte der influxDB als Excel ausleiten:
@dp20eic
Hallo Bernd,
Hölle ist das kompliziert. Wo finde ich den die Datei aus deinem Screenshot?
Ich meine den Screenshot um die Zeit zu "Synchronisieren"
Ich glaub in der Datei kann man so viel verbiegen das die 1-2 Stunden das geringere Übel sind .Nein, ist eigentlich nicht so kompliziert, das ist durch die Implementierung, wenn es richtig gemacht wurde, alles schon vorgegeben. Geht jetzt aber hier zu weit.
Ich habe meine Screenshots in aus dem UI voninfluxDb→ https://deine-influxdb-ip:8086/
Das ist auch keine Synchronisierung, sondern die Implementierung voninfluxDBum schnell von UTC auf Lokal Europa/Berlin umzuschalten, diese Einstellung ist somit kein Bestandteil der FLUX Abfrage.
Wenn Du in Grafana die korrekten Werte brauchst, dann musst Du immer das am Anfang einfügenimport "timezone" option location = timezone.location(name: "Europe/Berlin")Zu deinem 2 Post mit der Aggregatfunktion, was muss ich da dann einstellen? Das ist das Fenster im Data Explorer unten rechts, richtig?
Kann Dir gerade nicht folgen, welches Fenster Du meinst, etwa das was @Marc-Berg gepostet hat?
Ja, das ist auch aus der UI voninfluxDB.Ich baue immer erst in der UI meine Abfrage und kopiere diese dann bei
Grafanarein, da es aktuell noch keine gute Vervollständigung inGrafanafürFLUXgibt.und wenn ich schon dabei bin
in deiner ersten Datei verweist du auf iobroker_strom. Ich habe mal gelesen das man verschiedene Buckets anlegen kann (muss) alleine schon wegen wegen der Datenvorhaltung. Wie lege ich weitere angelegte Buckets im iobroker bzw. unter influxDB an?und wie beinflusse ich welche Daten in welches Buckt gehen?
Momentan rutscht alles in "iobroker-data" und dort hebe ich alles (überflüssigerweise) ewig auf. Eigentlich würden mir die Daten von der PV dauerhaft reichen.Jetzt wird es kompliziert, :) denn es gibt da mehrere Wege und hängt etwas vom Wissensstand ab.
Möglichkeit 1:
- Du legst Dir mehrere
influxDb - Adapter InstanzenimioBrokeran- in der jeweiligen Instanz, kannst Du dann die Retention Police (Vorhaltezeit) anpasst,
- vielleicht 1 Jahr in der einen Instanz und
- 90 Tage in der anderen Instanz.
- ich handhabe das anders, es gibt bei mir nur eine Instanz im
ioBroker- Diese ist auf nur 30 Tage eingestellt und sammelt alles, was ich auswerten möchte.
- in
influxDBhabe ich dann verschiedene Tasks, die mir die Daten dann auf unterschiedlicheBucketsschreiben, welche dann auch die Vorhaltezeiten haben, die ich dann für sinnvoll halte. - das kann so weit gehen, dass ich aus dem 30 Tages Bucket, ein Task habe, der mir auch gleich die Daten auf z.B.: 24 aggregiert und in das Tages Bucket schreibt, wo wieder ein Task läuft, der aus 7 Tagen eine Woche aggregiert und in das Wochen Bucket schreibt, wo wieder ein Task aus 4 Wochen ein Monat aggregiert, ....
Du siehst, kann das schon ein ganzes Stück Arbeit sein, ich bin mit meiner Lösung auch nicht fertig und übe noch :)
VG
Bernd@dp20eic
Hallo Bernd,
ich muß das von mir geschrieben etwas entwirren und vielleicht thematisch aufteilen.
Zu Deiner Antwort:
Kann Dir gerade nicht folgen, welches Fenster Du meinst, etwa das was @Marc-Berg gepostet hat?
Ja, das ist auch aus der UI von influxDB.Sorry, war meine Fehler, habe die Frage gerade noch mal an marc berg gestellt.
....................................................
Nun noch mal zum ersten Punkt und deiner Antwort:
"Nein, ist eigentlich nicht so kompliziert, das ist durch die Implementierung, wenn es richtig..............................."Also bisher nutze ich Grafana noch nicht.
Ich will (bis jetzt) eigentlich nur das die Zeit wenn ich sie als csv auslese passt.
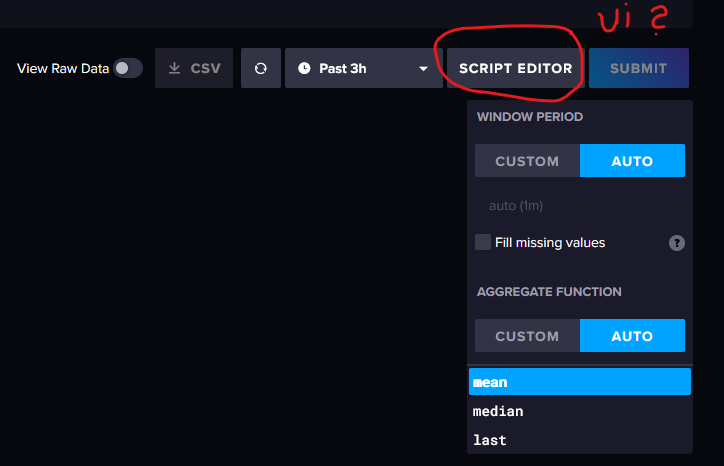
Wenn ich dich richtig verstanden habe machst du das über das Skript, den Code ich weis nicht mal wie man das nennt deshalb (d)ein Bild:
deshalb (d)ein Bild: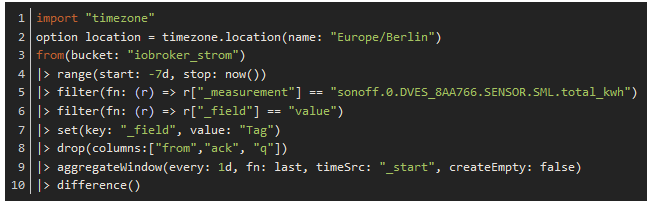
Jetzt stelle ich mir das mal so vor, das wenn ich erst mal weis wo ich das eingeben muß UI* von influxDb → https://meine-influxdb-ip:8086/ das ich dann nur den Bucket iobroker_Strom und den Datenpunkt, bei dir sonoff.0.DEVS... ändern muß mit meinen Daten.
Wobei ich sehe das du da auch schon was mit "aggregatewindows" eingepflegt hast.
Was müsste ich wo aus den 10 Zeilen übernehmen um eine passende Zeit zu haben?*) Was ist eine UI, ldt. Google User Interface
Die Frage mit mehreren Buckets vertage ich erst mal wegen der Übersicht.
Wäre nett wenn du bitte einem influxDB-Blinden auf die Sprünge helfen könntest.Gruß Duffy
- Du legst Dir mehrere
-
Hallo marc berg
Ich benötige glaube da noch mal Deine Unterstützung.
Bin ich hier richtig und wenn ja wie deaktiviere ich die "Aggregate Function" bzw wie speichere ich die Änderung?
VG Duffy
@duffy sagte in Werte der influxDB als Excel ausleiten:
Bin ich hier richtig und wenn ja wie deaktiviere ich die "Aggregate Function" bzw wie speichere ich die Änderung?
VG Duffy
Jetzt geht aber hier etwas durcheinander. Oben hattest Du noch einen Screenshot von der InfluxDB Web UI gepostet, jetzt aber Grafana. Mein Hinweis bezog sich auf den Data Explorer in der InfluxDB Web UI. Ziel ist es doch, Excel zu exportieren, oder?
NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
@duffy sagte in Werte der influxDB als Excel ausleiten:
Bin ich hier richtig und wenn ja wie deaktiviere ich die "Aggregate Function" bzw wie speichere ich die Änderung?
VG Duffy
Jetzt geht aber hier etwas durcheinander. Oben hattest Du noch einen Screenshot von der InfluxDB Web UI gepostet, jetzt aber Grafana. Mein Hinweis bezog sich auf den Data Explorer in der InfluxDB Web UI. Ziel ist es doch, Excel zu exportieren, oder?
Hi marc-berg,
ich habe gar kein Grafana, noch nicht, der Screenshot ist von influx DB.
aus:
Data-Explorer und dann in dem Fenster unten rechts Skript editor.
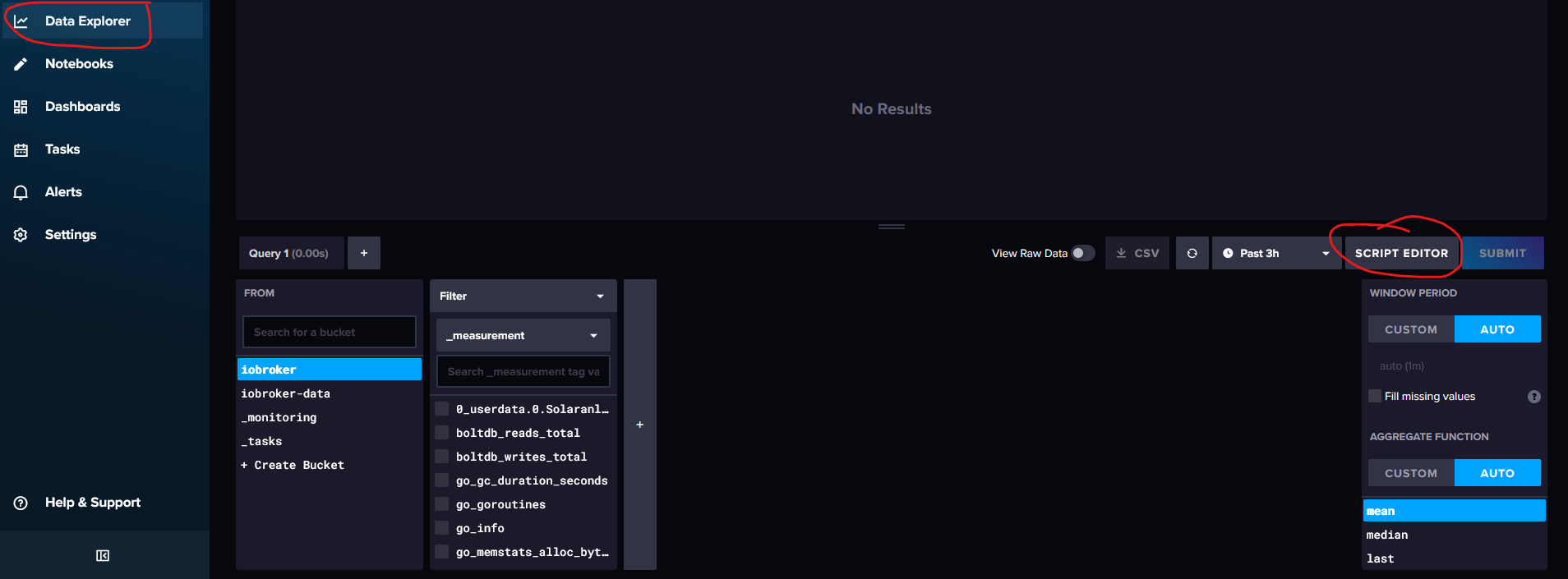
dort nach aggregatewindow gesucht und dort auf injekt gecklickt.
Dann kam das Fenster:
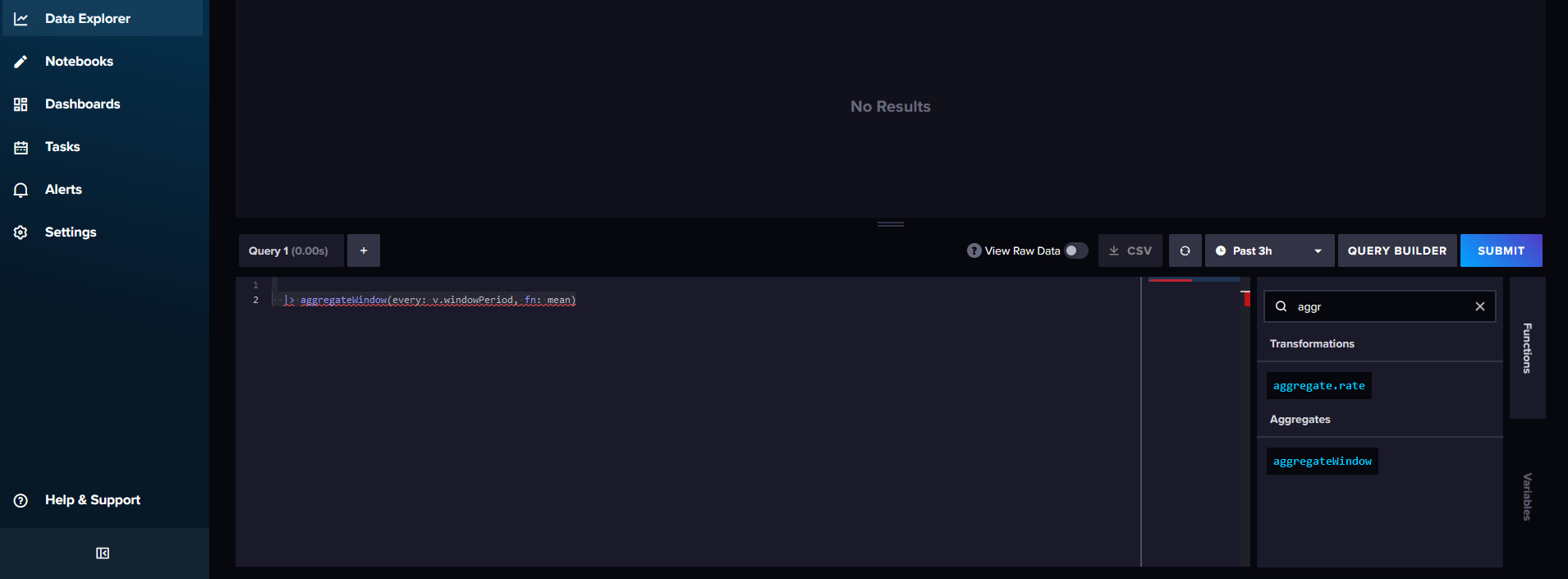
VG Duffy und eine gute Nacht
-
@duffy sagte in Werte der influxDB als Excel ausleiten:
Hi marc-berg,
ich habe gar kein Grafana, noch nicht, der Screenshot ist von influx DB.
aus:
Data-Explorer und dann in dem Fenster unten rechts Skript editor.
dort nach aggregatewindow gesucht und dort auf injekt gecklickt.
Dann kam das Fenster:
VG Duffy und eine gute Nacht
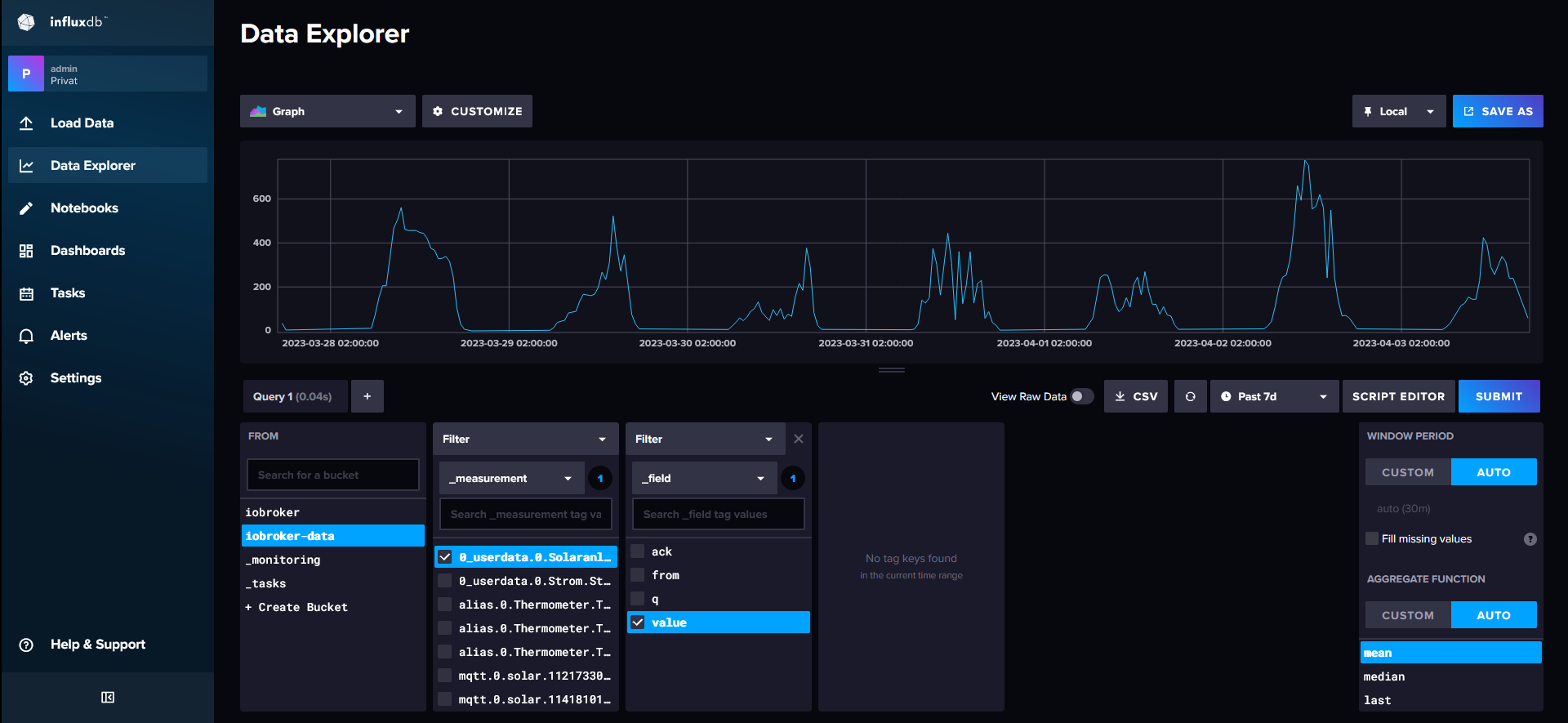
Moin,
fast richtig gemacht :)
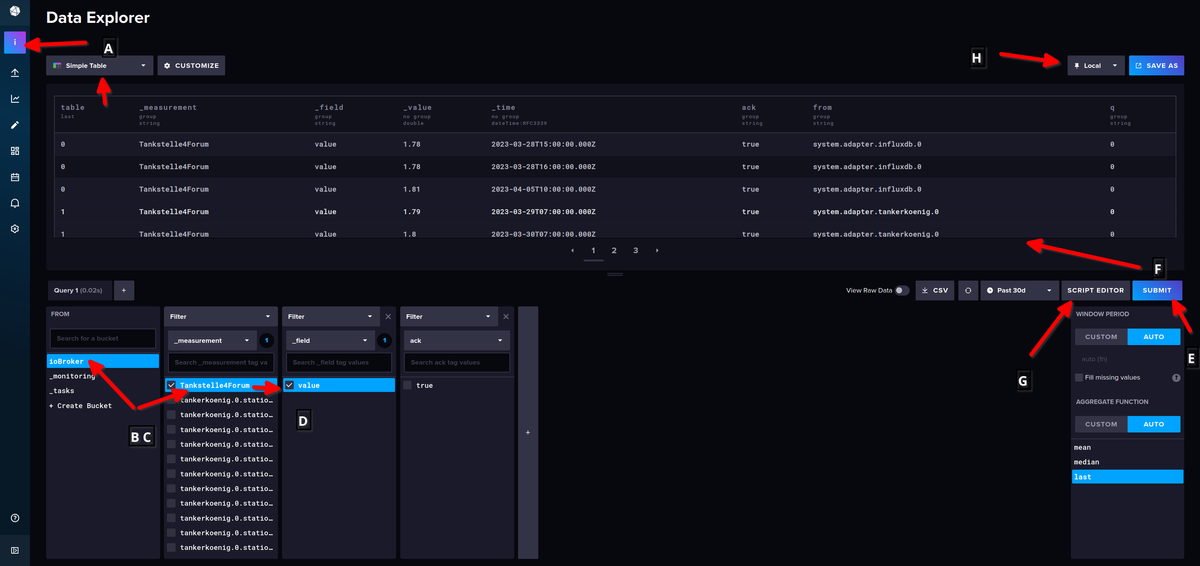
A= Organisation
B= Bucket
C= Datenpunkt/Messung
D= Messwert
E= Abfrage starten
F= Ergebnis der Abfrage
G= Abfrage im Skript Editor bearbeiten
H= umschalten, ob man die Werte in UTC oder als Lokale Zeit angezeigt bekommen möchteIm Skript Editor kannst Du dann die Abfrage so bearbeiten, wie Du das haben möchtest.
Spiel mal etwas, mit den Einstellungen und Möglichkeiten herum, um zu verstehen, was sich wie auswirkt, Du kannst nichts kaputt machen, außer Du löschst ein Bucket oder so ;)
VG
Bernd -
@duffy sagte in Werte der influxDB als Excel ausleiten:
Hi marc-berg,
ich habe gar kein Grafana, noch nicht, der Screenshot ist von influx DB.
aus:
Data-Explorer und dann in dem Fenster unten rechts Skript editor.
dort nach aggregatewindow gesucht und dort auf injekt gecklickt.
Dann kam das Fenster:
VG Duffy und eine gute Nacht
Moin,
fast richtig gemacht :)
A= Organisation
B= Bucket
C= Datenpunkt/Messung
D= Messwert
E= Abfrage starten
F= Ergebnis der Abfrage
G= Abfrage im Skript Editor bearbeiten
H= umschalten, ob man die Werte in UTC oder als Lokale Zeit angezeigt bekommen möchteIm Skript Editor kannst Du dann die Abfrage so bearbeiten, wie Du das haben möchtest.
Spiel mal etwas, mit den Einstellungen und Möglichkeiten herum, um zu verstehen, was sich wie auswirkt, Du kannst nichts kaputt machen, außer Du löschst ein Bucket oder so ;)
VG
Bernd -
@duffy sagte in Werte der influxDB als Excel ausleiten:
Nun noch mal zum ersten Punkt und deiner Antwort:
"Nein, ist eigentlich nicht so kompliziert, das ist durch die Implementierung, wenn es richtig..............................."
Also bisher nutze ich Grafana noch nicht.
Ich will (bis jetzt) eigentlich nur das die Zeit wenn ich sie als csv auslese passt.Moin,
also wenn es nur um den Export geht, dann ist das ganz einfach :)
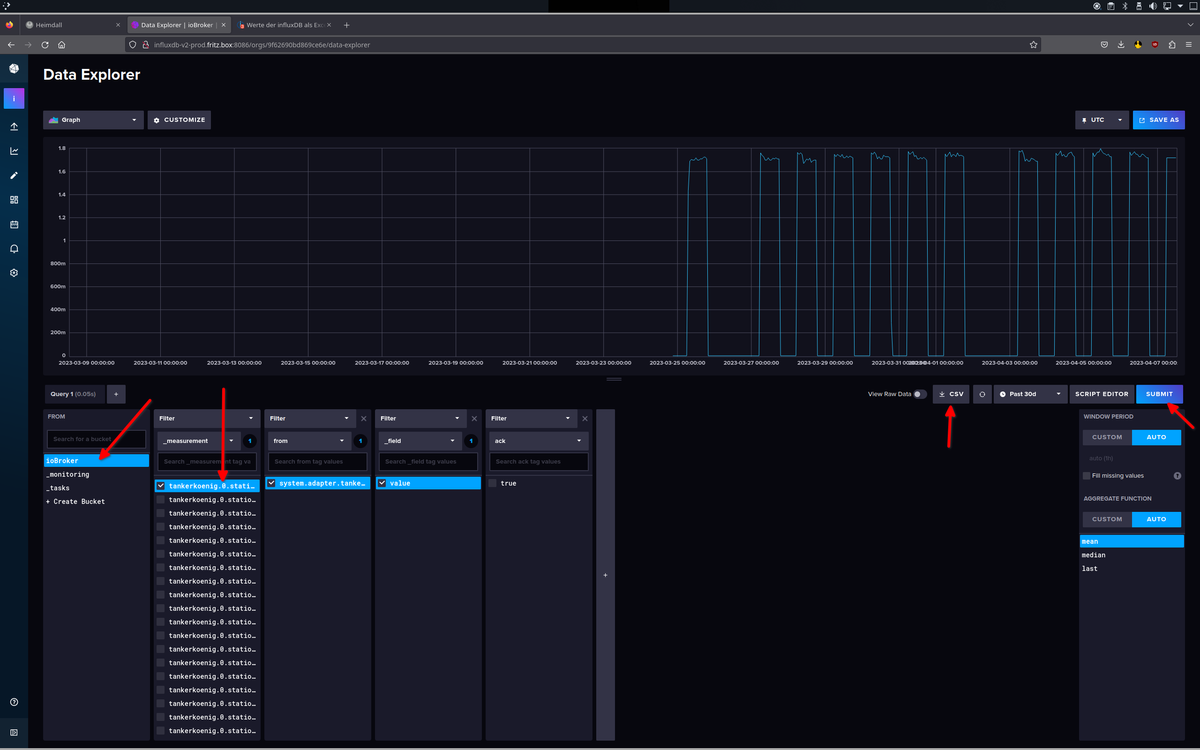
1= Bucket auswählen
2= measurement auswählen
3= query / Abfrage einmal ausführen, zum check
4= CSV Export, exportiert die Werte, für den eingestellten AbrufzeitraumDamit bekommst Du die Zeiten in UTC, zu erkennen am
Z->Zulu Zeit = UTCin den Zeitspalten_start, _stopu._time, wenn Du jetzt die CSV Datei in Excel oder einer anderen Tabellenkalkulation weiterverarbeiten möchtest, musst Du Dir anschauen, mit welcher Formel Du die_timeSpalte manipulieren musst, um auf die lokale Zeit zu kommen.
Kann ich Dir nicht wirklich helfen, Excel ist nicht meins, da muss ich auch immer googeln ;)Wenn ich dich richtig verstanden habe machst du das über das Skript, den Code ich weis nicht mal wie man das nennt 😞 deshalb (d)ein Bild:
Nein, diese Query/Abfrage veränder den Export nicht, die Daten in der Datenbank liegen nur im UTC Format vor und können auch nur so aus der Datenbank gelesen werden.
Jetzt stelle ich mir das mal so vor, das wenn ich erst mal weis wo ich das eingeben muß UI* von influxDb → https://meine-influxdb-ip:8086/ das ich dann nur den Bucket > iobroker_Strom und den Datenpunkt, bei dir sonoff.0.DEVS... ändern muß mit meinen Daten.
Ja, das kannst Du so machen, aber Du kannst auch ganz einfach über die erste Seite dir das zusammen Klicken.
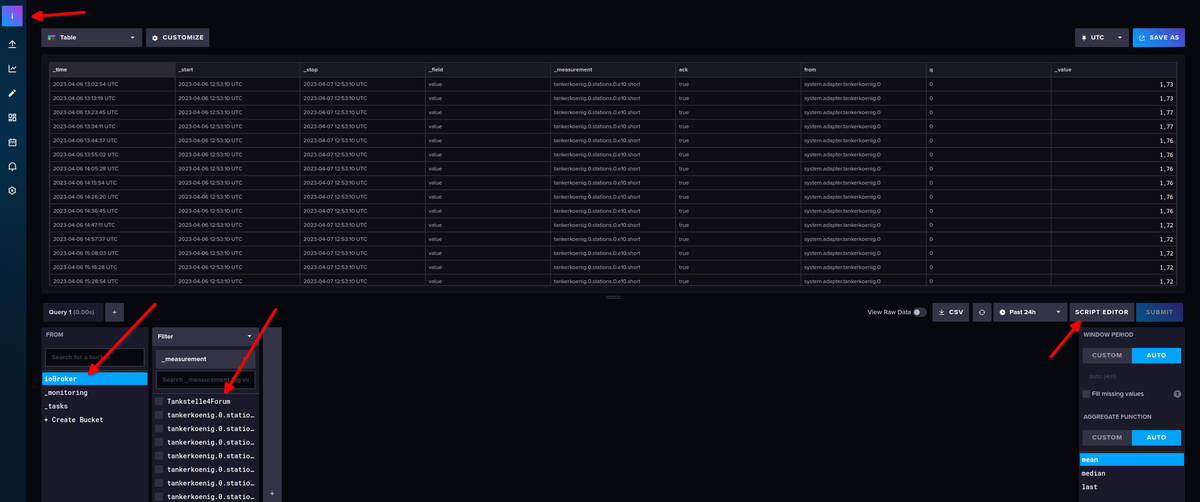
Wenn Du dann im Skript Editor bist, sieht das dann so aus:
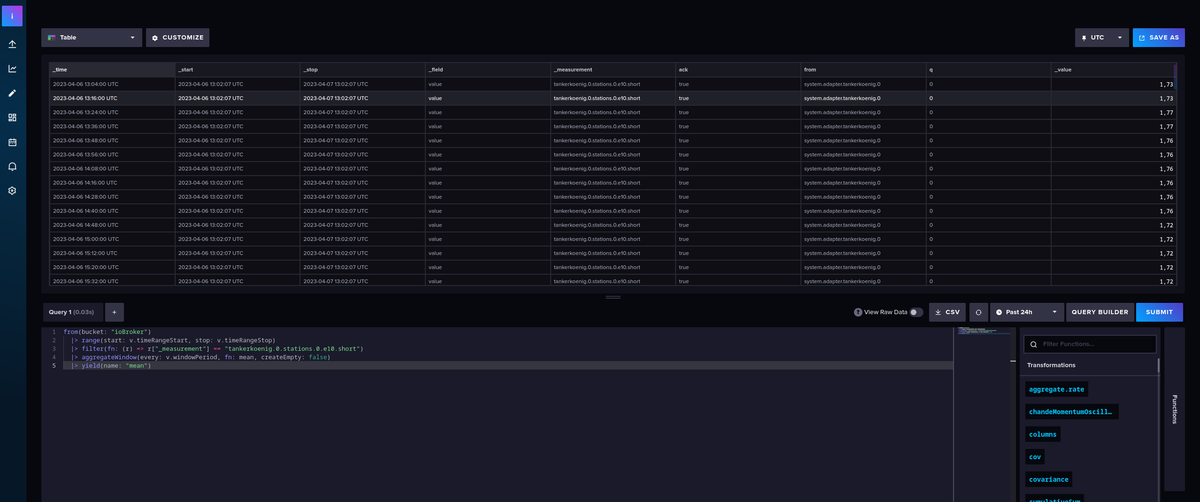
Ab hier kannst Du aus den rechts unten aufgeführten Funktionen das, was Du brauchst, hinzufügen,
submitnicht vergessen, um die Auswirkung zu sehen oder schauen, ob Fehler auftauchen :)So jetzt zu dem, was da passiert, bei dieser Abfrage der Datenbank:
from(bucket: "ioBroker") // von welchem Bucket wird gelesen |> range(start: v.timeRangeStart, stop: v.timeRangeStop) // welche Zeit von - bis soll betrachtet werden, im Beisiel von `past 24 h` bis `now` |> filter(fn: (r) => r["_measurement"] == "tankerkoenig.0.stations.0.e10.short") // welcher MesswertErgebnis:
_time _start _stop 2023-04-06 13:16:00 UTC 2023-04-06 13:05:43 UTC 2023-04-07 13:05:43 UTC ... ... ... 2023-04-07 13:12:40 UTC 2023-04-06 13:20:15 UTC 2023-04-07 13:20:15 UTC Der Export aus der Abfrage:
2023-04-07_15 26_influxdb_data.csvWenn ich jetzt in der UI von
influxDBvon UTC auf Lokal wechsle
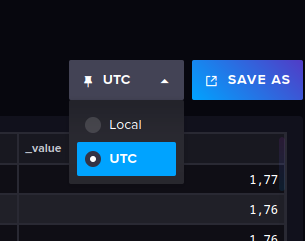
Dann änder sich bei der Abfrage, die Darstellung der Zeit, jetzt ist es die lokale Zeit hier in Deutschland
_time _start _stop 2023-04-06 15:34:11 GMT+2 2023-04-06 15:25:11 GMT+2 2023-04-07 15:25:11 GMT+2 ... ... ... 2023-04-07 15:23:06 GMT+2 2023-04-06 15:25:11 GMT+2 2023-04-07 15:25:11 GMT+2 Der Export, ändert sich nicht
2023-04-07_15 33_influxdb_data.csvWobei ich sehe das du da auch schon was mit "aggregatewindows" eingepflegt hast.
Wenn ich jetzt das
aggregatewindowsnutze, wirkt sich das auf die Anzahl der Werte aus, aber nicht auf den Zeitstempel.from(bucket: "ioBroker") // von welchem Bucket wird gelesen |> range(start: v.timeRangeStart, stop: v.timeRangeStop) // Time Range die betrachtet wird `past 24h` bis `now` |> filter(fn: (r) => r["_measurement"] == "tankerkoenig.0.stations.0.e10.short") // welcher Messwert |> aggregateWindow(every: 24h, fn: mean, createEmpty: false) // Aus der time Range sollen alle Werte zu einem 24h Wert aggregiert werdenUTC
_time _start _stop 2023-04-07 00:00:00 UTC 2023-04-06 14:12:11 UTC 2023-04-07 14:12:11 UTC 2023-04-07 14:12:11 UTC 2023-04-06 14:12:11 UTC 2023-04-07 14:12:11 UTC Lokal
_time _start _stop 2023-04-07 02:00:00 GMT+2 2023-04-06 16:28:29 GMT+2 2023-04-07 16:28:29 GMT+2 2023-04-07 16:28:29 GMT+2 2023-04-06 16:28:29 GMT+2 2023-04-07 16:28:29 GMT+2 Der Export
2023-04-07_16 14_influxdb_data.csvBei dieser Aggregation wird leider nicht
Europa/Berlinals Zeitzone berücksichtigt, daher muss das noch mit einfließen:import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "ioBroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "tankerkoenig.0.stations.0.e10.short") |> aggregateWindow(every: 24h, fn: mean, createEmpty: false)UTC
_time _start _stop 2023-04-06 22:00:00 UTC 2023-04-06 14:22:00 UTC 2023-04-07 14:22:00 UTC 2023-04-07 14:22:00 UTC 2023-04-06 14:22:00 UTC 2023-04-07 14:22:00 UTC Lokal
_time _start _stop 2023-04-07 00:00:00 GMT+2 2023-04-06 16:22:00 GMT+2 2023-04-07 16:22:00 GMT+2 2023-04-07 16:22:00 GMT+2 2023-04-06 16:22:00 GMT+2 2023-04-07 16:22:00 GMT+2 Export
2023-04-07_16 30_influxdb_data.csvAuch hier ist die exportierte Zeit
UTCWas müsste ich wo aus den 10 Zeilen übernehmen um eine passende Zeit zu haben?
Nichts, denn Du wirst immer einen Export mit
UTCZeit bekommen.Mir ist noch nicht ganz klar, was Du mit den Daten machen möchtest und wie Du sie weiter nutzen willst, weil Du immer sagst
CSV -> Excel, deswegen hilft Dir das ganze auch nicht wirklich, weil wie oben schon geschrieben die Zeiten in UTC vorliegen und Du musst das dann in dem Programm anpassen, mit dem Du weiter arbeitest.Wenn Du Grafiken in der VIS brauchst, dann gibt es ja verschiedene Möglichkeiten, z.B.:
eChart,FlotalsioBrokerAdapter oderGrafanaals externes Tool. WieeChartoderFlotmit den Zeiten umgeht, kann ich nicht sagen, inGrafanafunktioniert es ohne, dass ich da etwas umbiege.VG
Bernd -
@duffy sagte in Werte der influxDB als Excel ausleiten:
Nun noch mal zum ersten Punkt und deiner Antwort:
"Nein, ist eigentlich nicht so kompliziert, das ist durch die Implementierung, wenn es richtig..............................."
Also bisher nutze ich Grafana noch nicht.
Ich will (bis jetzt) eigentlich nur das die Zeit wenn ich sie als csv auslese passt.Moin,
also wenn es nur um den Export geht, dann ist das ganz einfach :)
1= Bucket auswählen
2= measurement auswählen
3= query / Abfrage einmal ausführen, zum check
4= CSV Export, exportiert die Werte, für den eingestellten AbrufzeitraumDamit bekommst Du die Zeiten in UTC, zu erkennen am
Z->Zulu Zeit = UTCin den Zeitspalten_start, _stopu._time, wenn Du jetzt die CSV Datei in Excel oder einer anderen Tabellenkalkulation weiterverarbeiten möchtest, musst Du Dir anschauen, mit welcher Formel Du die_timeSpalte manipulieren musst, um auf die lokale Zeit zu kommen.
Kann ich Dir nicht wirklich helfen, Excel ist nicht meins, da muss ich auch immer googeln ;)Wenn ich dich richtig verstanden habe machst du das über das Skript, den Code ich weis nicht mal wie man das nennt 😞 deshalb (d)ein Bild:
Nein, diese Query/Abfrage veränder den Export nicht, die Daten in der Datenbank liegen nur im UTC Format vor und können auch nur so aus der Datenbank gelesen werden.
Jetzt stelle ich mir das mal so vor, das wenn ich erst mal weis wo ich das eingeben muß UI* von influxDb → https://meine-influxdb-ip:8086/ das ich dann nur den Bucket > iobroker_Strom und den Datenpunkt, bei dir sonoff.0.DEVS... ändern muß mit meinen Daten.
Ja, das kannst Du so machen, aber Du kannst auch ganz einfach über die erste Seite dir das zusammen Klicken.
Wenn Du dann im Skript Editor bist, sieht das dann so aus:
Ab hier kannst Du aus den rechts unten aufgeführten Funktionen das, was Du brauchst, hinzufügen,
submitnicht vergessen, um die Auswirkung zu sehen oder schauen, ob Fehler auftauchen :)So jetzt zu dem, was da passiert, bei dieser Abfrage der Datenbank:
from(bucket: "ioBroker") // von welchem Bucket wird gelesen |> range(start: v.timeRangeStart, stop: v.timeRangeStop) // welche Zeit von - bis soll betrachtet werden, im Beisiel von `past 24 h` bis `now` |> filter(fn: (r) => r["_measurement"] == "tankerkoenig.0.stations.0.e10.short") // welcher MesswertErgebnis:
_time _start _stop 2023-04-06 13:16:00 UTC 2023-04-06 13:05:43 UTC 2023-04-07 13:05:43 UTC ... ... ... 2023-04-07 13:12:40 UTC 2023-04-06 13:20:15 UTC 2023-04-07 13:20:15 UTC Der Export aus der Abfrage:
2023-04-07_15 26_influxdb_data.csvWenn ich jetzt in der UI von
influxDBvon UTC auf Lokal wechsle
Dann änder sich bei der Abfrage, die Darstellung der Zeit, jetzt ist es die lokale Zeit hier in Deutschland
_time _start _stop 2023-04-06 15:34:11 GMT+2 2023-04-06 15:25:11 GMT+2 2023-04-07 15:25:11 GMT+2 ... ... ... 2023-04-07 15:23:06 GMT+2 2023-04-06 15:25:11 GMT+2 2023-04-07 15:25:11 GMT+2 Der Export, ändert sich nicht
2023-04-07_15 33_influxdb_data.csvWobei ich sehe das du da auch schon was mit "aggregatewindows" eingepflegt hast.
Wenn ich jetzt das
aggregatewindowsnutze, wirkt sich das auf die Anzahl der Werte aus, aber nicht auf den Zeitstempel.from(bucket: "ioBroker") // von welchem Bucket wird gelesen |> range(start: v.timeRangeStart, stop: v.timeRangeStop) // Time Range die betrachtet wird `past 24h` bis `now` |> filter(fn: (r) => r["_measurement"] == "tankerkoenig.0.stations.0.e10.short") // welcher Messwert |> aggregateWindow(every: 24h, fn: mean, createEmpty: false) // Aus der time Range sollen alle Werte zu einem 24h Wert aggregiert werdenUTC
_time _start _stop 2023-04-07 00:00:00 UTC 2023-04-06 14:12:11 UTC 2023-04-07 14:12:11 UTC 2023-04-07 14:12:11 UTC 2023-04-06 14:12:11 UTC 2023-04-07 14:12:11 UTC Lokal
_time _start _stop 2023-04-07 02:00:00 GMT+2 2023-04-06 16:28:29 GMT+2 2023-04-07 16:28:29 GMT+2 2023-04-07 16:28:29 GMT+2 2023-04-06 16:28:29 GMT+2 2023-04-07 16:28:29 GMT+2 Der Export
2023-04-07_16 14_influxdb_data.csvBei dieser Aggregation wird leider nicht
Europa/Berlinals Zeitzone berücksichtigt, daher muss das noch mit einfließen:import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "ioBroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "tankerkoenig.0.stations.0.e10.short") |> aggregateWindow(every: 24h, fn: mean, createEmpty: false)UTC
_time _start _stop 2023-04-06 22:00:00 UTC 2023-04-06 14:22:00 UTC 2023-04-07 14:22:00 UTC 2023-04-07 14:22:00 UTC 2023-04-06 14:22:00 UTC 2023-04-07 14:22:00 UTC Lokal
_time _start _stop 2023-04-07 00:00:00 GMT+2 2023-04-06 16:22:00 GMT+2 2023-04-07 16:22:00 GMT+2 2023-04-07 16:22:00 GMT+2 2023-04-06 16:22:00 GMT+2 2023-04-07 16:22:00 GMT+2 Export
2023-04-07_16 30_influxdb_data.csvAuch hier ist die exportierte Zeit
UTCWas müsste ich wo aus den 10 Zeilen übernehmen um eine passende Zeit zu haben?
Nichts, denn Du wirst immer einen Export mit
UTCZeit bekommen.Mir ist noch nicht ganz klar, was Du mit den Daten machen möchtest und wie Du sie weiter nutzen willst, weil Du immer sagst
CSV -> Excel, deswegen hilft Dir das ganze auch nicht wirklich, weil wie oben schon geschrieben die Zeiten in UTC vorliegen und Du musst das dann in dem Programm anpassen, mit dem Du weiter arbeitest.Wenn Du Grafiken in der VIS brauchst, dann gibt es ja verschiedene Möglichkeiten, z.B.:
eChart,FlotalsioBrokerAdapter oderGrafanaals externes Tool. WieeChartoderFlotmit den Zeiten umgeht, kann ich nicht sagen, inGrafanafunktioniert es ohne, dass ich da etwas umbiege.VG
Bernd@dp20eic
Hallo Bernd,
danke für deine mühenvolle Aufbereitung.
Ja, vielleicht habe ich mich da zu sehr in das csv verrannt.
Im Grunde wollte ich die Meßwerte mit der Zeit nur als Tabelle haben, einfach um die Werte zu sehen, und da habe ich halt nur die csv als möglichkeit gesehen. (Wirklich übersichtlich war die CSV ja auch nicht)Die Grafiken funktionieren mit Flot oder echart recht gut.
Wie gehst du vor wenn du die Daten in Tabellen und nicht in Grafikform sehen willst.
Viele Grüße und noch einen schönen Tag, Duffy
-
@dp20eic
Hallo Bernd,
danke für deine mühenvolle Aufbereitung.
Ja, vielleicht habe ich mich da zu sehr in das csv verrannt.
Im Grunde wollte ich die Meßwerte mit der Zeit nur als Tabelle haben, einfach um die Werte zu sehen, und da habe ich halt nur die csv als möglichkeit gesehen. (Wirklich übersichtlich war die CSV ja auch nicht)Die Grafiken funktionieren mit Flot oder echart recht gut.
Wie gehst du vor wenn du die Daten in Tabellen und nicht in Grafikform sehen willst.
Viele Grüße und noch einen schönen Tag, Duffy
@duffy sagte in Werte der influxDB als Excel ausleiten:
Wie gehst du vor wenn du die Daten in Tabellen und nicht in Grafikform sehen willst.
Moin,
da ich
Grafananutze, nutze ich da einfach einen der vielen Möglichkeiten zur Visualisierung, Auszug der Möglichkeiten:
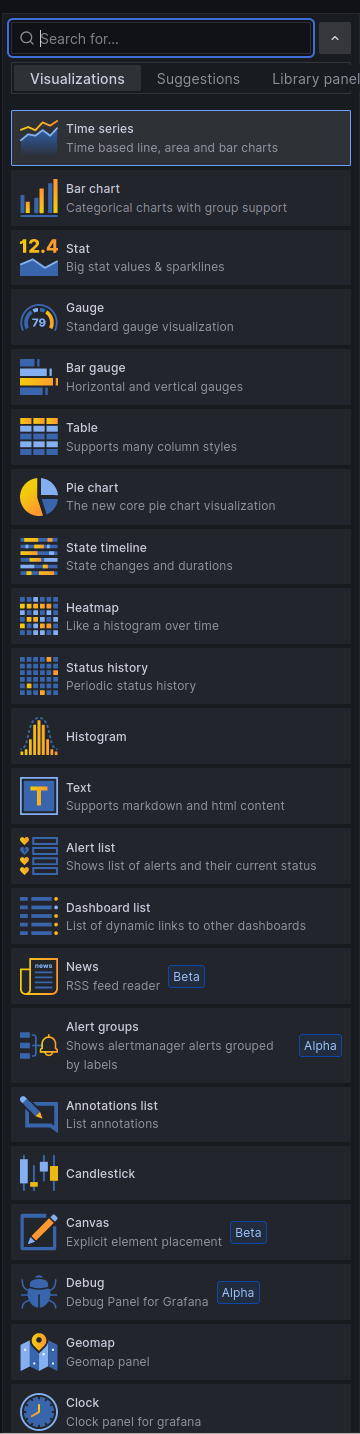
Ich kenne mich da nicht so gut aus, aber es ist auch möglich, dass man per
Blockly, oderJSDaten holt und alsJsonin einen eigenen Datenpunkt schreibt, denn man dann z.B. als Tabelle in der VIS seiner Wahl ausgeben kann.VG
Bernd -
@duffy sagte in Werte der influxDB als Excel ausleiten:
Wie gehst du vor wenn du die Daten in Tabellen und nicht in Grafikform sehen willst.
Moin,
da ich
Grafananutze, nutze ich da einfach einen der vielen Möglichkeiten zur Visualisierung, Auszug der Möglichkeiten:
Ich kenne mich da nicht so gut aus, aber es ist auch möglich, dass man per
Blockly, oderJSDaten holt und alsJsonin einen eigenen Datenpunkt schreibt, denn man dann z.B. als Tabelle in der VIS seiner Wahl ausgeben kann.VG
Bernd -
@duffy sagte in Werte der influxDB als Excel ausleiten:
Wie gehst du vor wenn du die Daten in Tabellen und nicht in Grafikform sehen willst.
Moin,
da ich
Grafananutze, nutze ich da einfach einen der vielen Möglichkeiten zur Visualisierung, Auszug der Möglichkeiten:
Ich kenne mich da nicht so gut aus, aber es ist auch möglich, dass man per
Blockly, oderJSDaten holt und alsJsonin einen eigenen Datenpunkt schreibt, denn man dann z.B. als Tabelle in der VIS seiner Wahl ausgeben kann.VG
Bernd@dp20eic
Hallo Bernd,
ich habe da noch mal eine Infux DB Frage an dich.
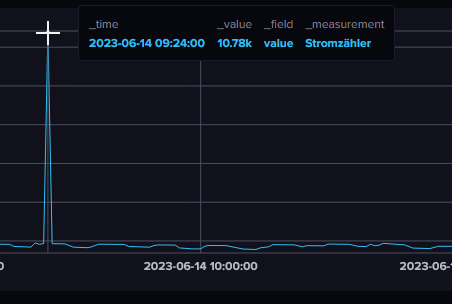
Mit hat es heute eine Messung bei meinem Stromzähler rein gehauen mit über 10.000 Watt und zwar am 14.03.2023 um 09:24:00.
Ich kann zwar ganze Datensätze löschen mit:
influx delete --bucket iobroker-data --start 1970-01-01T00:00:00Z --stop $(date +"%Y-%m-%dT%H:%M:%SZ") --predicate '_measurement="DATENPUNKT-HIER-REIN"'
aber wie muß der Befehl aussehen um nur en einen fehlerhaften Messpunkt zu löschen oder zu korrigieren mit einem Durchschnittswert?
Hatte das mal gefunden aber finde es nicht mehr.
Kannst du mir da bitte noch mal helfen?
Gruß Duffy
-
@dp20eic
Hallo Bernd,
ich habe da noch mal eine Infux DB Frage an dich.
Mit hat es heute eine Messung bei meinem Stromzähler rein gehauen mit über 10.000 Watt und zwar am 14.03.2023 um 09:24:00.
Ich kann zwar ganze Datensätze löschen mit:
influx delete --bucket iobroker-data --start 1970-01-01T00:00:00Z --stop $(date +"%Y-%m-%dT%H:%M:%SZ") --predicate '_measurement="DATENPUNKT-HIER-REIN"'
aber wie muß der Befehl aussehen um nur en einen fehlerhaften Messpunkt zu löschen oder zu korrigieren mit einem Durchschnittswert?
Hatte das mal gefunden aber finde es nicht mehr.
Kannst du mir da bitte noch mal helfen?
Gruß Duffy
@duffy sagte in Werte der influxDB als Excel ausleiten:
Kannst du mir da bitte noch mal helfen?
Moin,
ich versuch’ es mal.
!!!Achtung!!!
Wie immer, ein Backup zuhaben ist besser, als eins zu brauchen :)
Also lieber eines mehr machen :)-
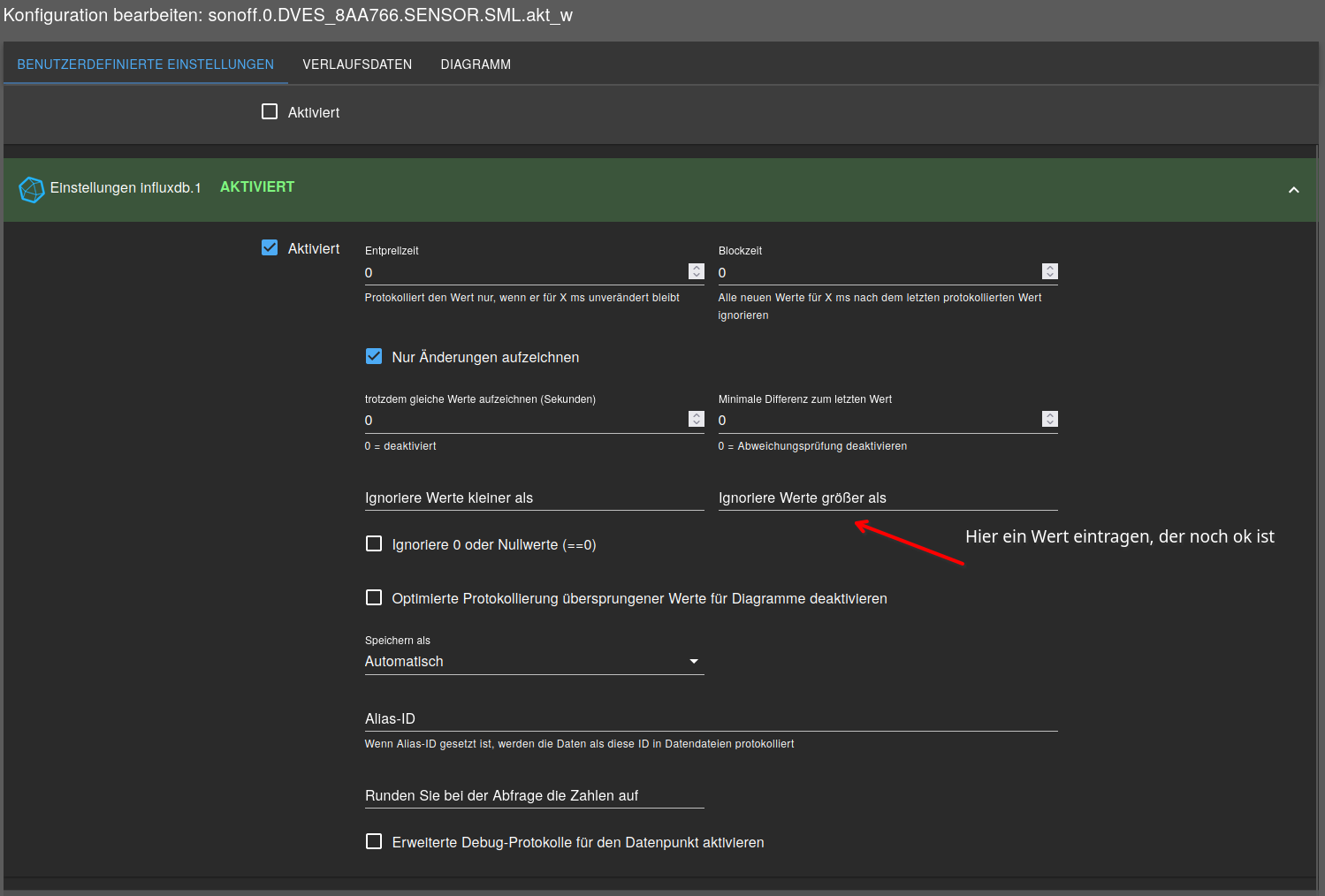
Damit das nicht wieder passiert, sollte man erst einmal schauen, was im zu loggenden DP steht und dann evtl. dort werte die Größer als sind nicht Loggen.
-
eine Methode Werte zu änder wäre, den Wert als CSV zu exportieren, dann ändern und wieder laden.
- das geht aber leider nicht mehr mit der aktuellen Web-UI, welche Version von
influxDBist bei Dir installiert?
- das geht aber leider nicht mehr mit der aktuellen Web-UI, welche Version von
-
Dein delete Statement passt schon, Du musst nur die
StartundStopZeit genau auf den einen Wert einstellen.
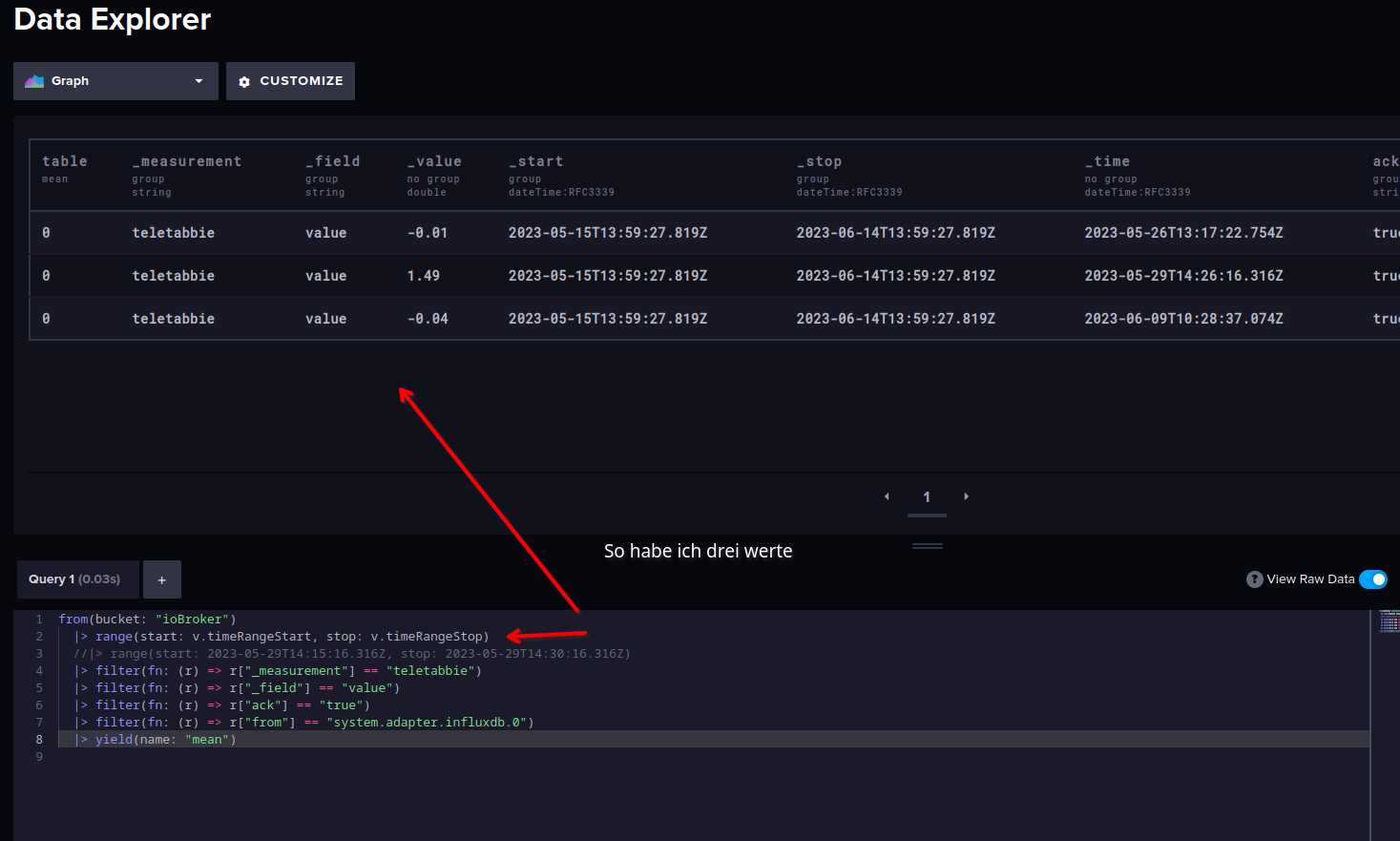
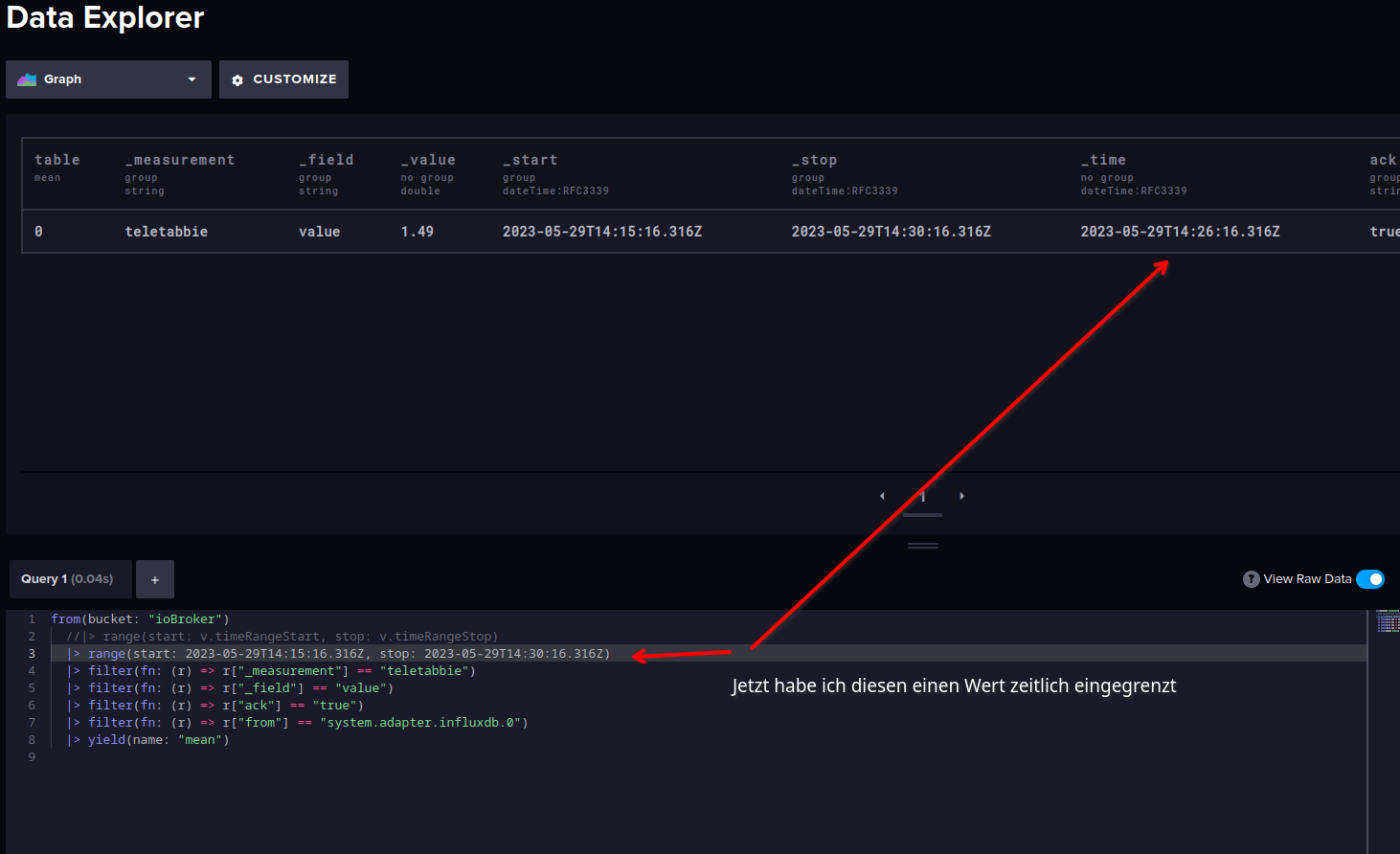
Wenn Du schaust, dass Du nur diesen einen Wert erwischst, dann sollte das mit dem Löschen klappen. -
Ich versuche mal einen Task zu schreiben, wie man den einen Wert ändern kann.
VG
Bernd -
-
@duffy sagte in Werte der influxDB als Excel ausleiten:
Kannst du mir da bitte noch mal helfen?
Moin,
ich versuch’ es mal.
!!!Achtung!!!
Wie immer, ein Backup zuhaben ist besser, als eins zu brauchen :)
Also lieber eines mehr machen :)-
Damit das nicht wieder passiert, sollte man erst einmal schauen, was im zu loggenden DP steht und dann evtl. dort werte die Größer als sind nicht Loggen.
-
eine Methode Werte zu änder wäre, den Wert als CSV zu exportieren, dann ändern und wieder laden.
- das geht aber leider nicht mehr mit der aktuellen Web-UI, welche Version von
influxDBist bei Dir installiert?
- das geht aber leider nicht mehr mit der aktuellen Web-UI, welche Version von
-
Dein delete Statement passt schon, Du musst nur die
StartundStopZeit genau auf den einen Wert einstellen.
Wenn Du schaust, dass Du nur diesen einen Wert erwischst, dann sollte das mit dem Löschen klappen. -
Ich versuche mal einen Task zu schreiben, wie man den einen Wert ändern kann.
VG
Bernd@dp20eic
Hi Bernd,
danke für deine schnelle Antwort.
Nun habe ich doch noch einen Datenpunkt gefunden der in Frage kommen könnte.
Nur hat der in dem Zeitraum nur 5325,5 Watt und nicht wie in der Grafik (mein Post zuvor) 10.78K
Jetzt habe ich etwas weiter versucht an mehr Details zu kommen und schon ist der Wert weg und ich finde ihn nicht mehr. Ich weis nicht woran es liegt aber mal ist mehr Zeit zwischen den Werten und mal weniger; also was ich sagen will, die Datendichte der einzelnen Werte hinterinander ist unterschiedlich, mal alle paar Sek. mal nur Min. dann wieder Std. Abstände. Ich weis nicht wovon das abhängt.
Was noch komisch ist, ich will es mal in Bildern veruchen zu zeigen:
Darstellung in Influx DB
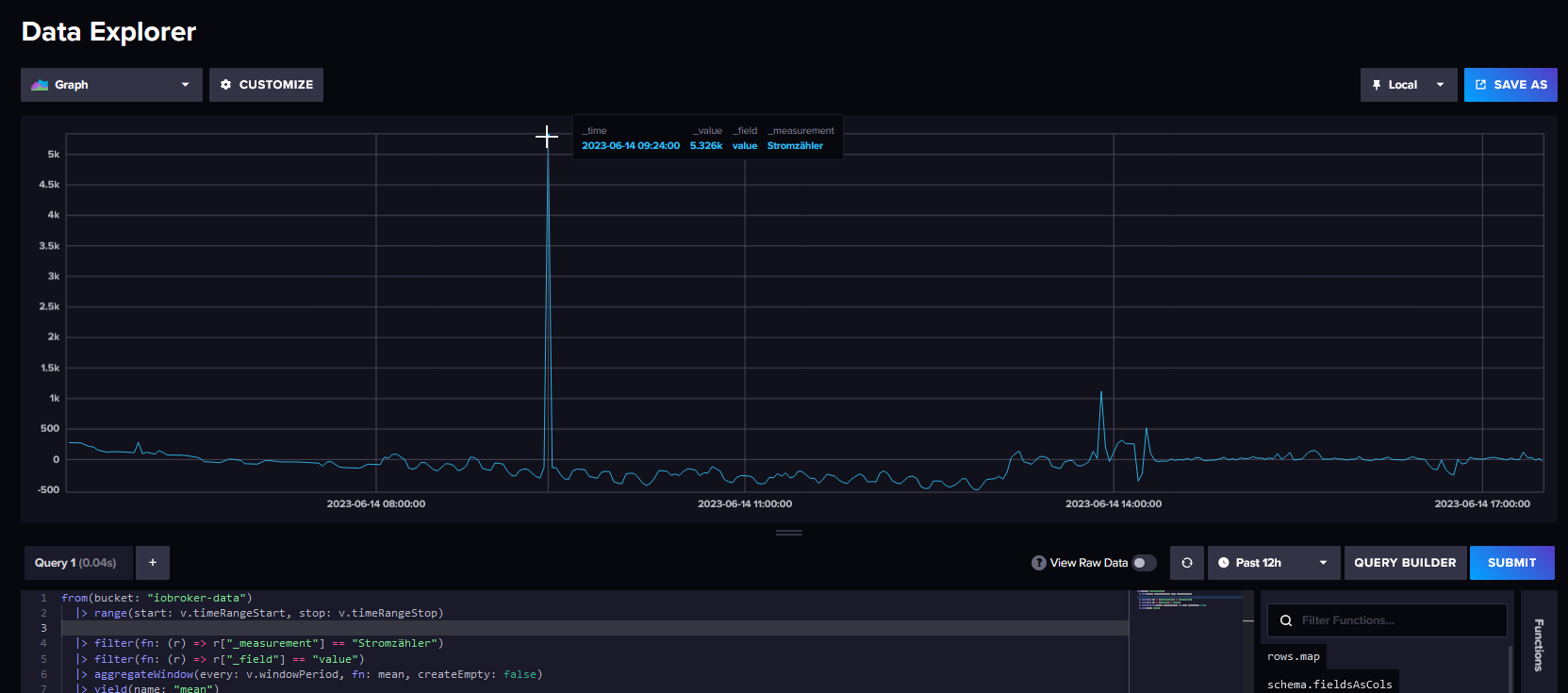
Darstellung in Grafana:

Hier sind sogar die Werte (W) an sich unterschiedlich und auch die Zeit geringfügig anders.
Also wirklich verstehen tue ich das nicht das Daten in Influx DB 5326 und in Grafana 32628 sind und vor allem war es im ersten Screenshot von Infux DB ja noch 10780 Watt.Aber gut das würde ja vielleicht verschwinden wenn ich den Datenpunkt löschen könnte.
Da ich ja schon die Werte von dem Datenpunkt als Screenshot hatte habe ich die mal eingetippt:
Komme jetzt aber damit nicht weiter.
Sehe schon das läuft auf eine Löschung des ganzen Datenpunkts heraus

Gruß Duffy
Edit:
Habe den Datenpunkt noch mal gefunden dafür sieht er jetzt anders aus :-( (die start und stop Zeit)
-
-
@dp20eic
Hi Bernd,
danke für deine schnelle Antwort.
Nun habe ich doch noch einen Datenpunkt gefunden der in Frage kommen könnte.
Nur hat der in dem Zeitraum nur 5325,5 Watt und nicht wie in der Grafik (mein Post zuvor) 10.78KJetzt habe ich etwas weiter versucht an mehr Details zu kommen und schon ist der Wert weg und ich finde ihn nicht mehr. Ich weis nicht woran es liegt aber mal ist mehr Zeit zwischen den Werten und mal weniger; also was ich sagen will, die Datendichte der einzelnen Werte hinterinander ist unterschiedlich, mal alle paar Sek. mal nur Min. dann wieder Std. Abstände. Ich weis nicht wovon das abhängt.
Was noch komisch ist, ich will es mal in Bildern veruchen zu zeigen:
Darstellung in Influx DB
Darstellung in Grafana:
Hier sind sogar die Werte (W) an sich unterschiedlich und auch die Zeit geringfügig anders.
Also wirklich verstehen tue ich das nicht das Daten in Influx DB 5326 und in Grafana 32628 sind und vor allem war es im ersten Screenshot von Infux DB ja noch 10780 Watt.Aber gut das würde ja vielleicht verschwinden wenn ich den Datenpunkt löschen könnte.
Da ich ja schon die Werte von dem Datenpunkt als Screenshot hatte habe ich die mal eingetippt:
Komme jetzt aber damit nicht weiter.
Sehe schon das läuft auf eine Löschung des ganzen Datenpunkts heraus
Gruß Duffy
Edit:
Habe den Datenpunkt noch mal gefunden dafür sieht er jetzt anders aus :-( (die start und stop Zeit)@duffy sagte in Werte der influxDB als Excel ausleiten:
Sehe schon das läuft auf eine Löschung des ganzen Datenpunkts heraus
Moin,
erst mal langsam und tief Luft holen.
Zu Deinen Grafiken, ohne die Abfragen dahinter, kann man da nicht viel machen, dann muss ich erst mal verstehen, um welche Daten es sich handelt, bei meinem Stromzähler gibt es zwei Datenpunkte
sonoff.0.DVES_8AA766.SENSOR.SML.akt_w <- der aktuelle Verbrauch sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh <- der gesamte Verbrauch seitWenn es sich um aktuelle Werte handelt, kann es nicht sein, dass Du einen Verbraucher eingeschaltet hast?
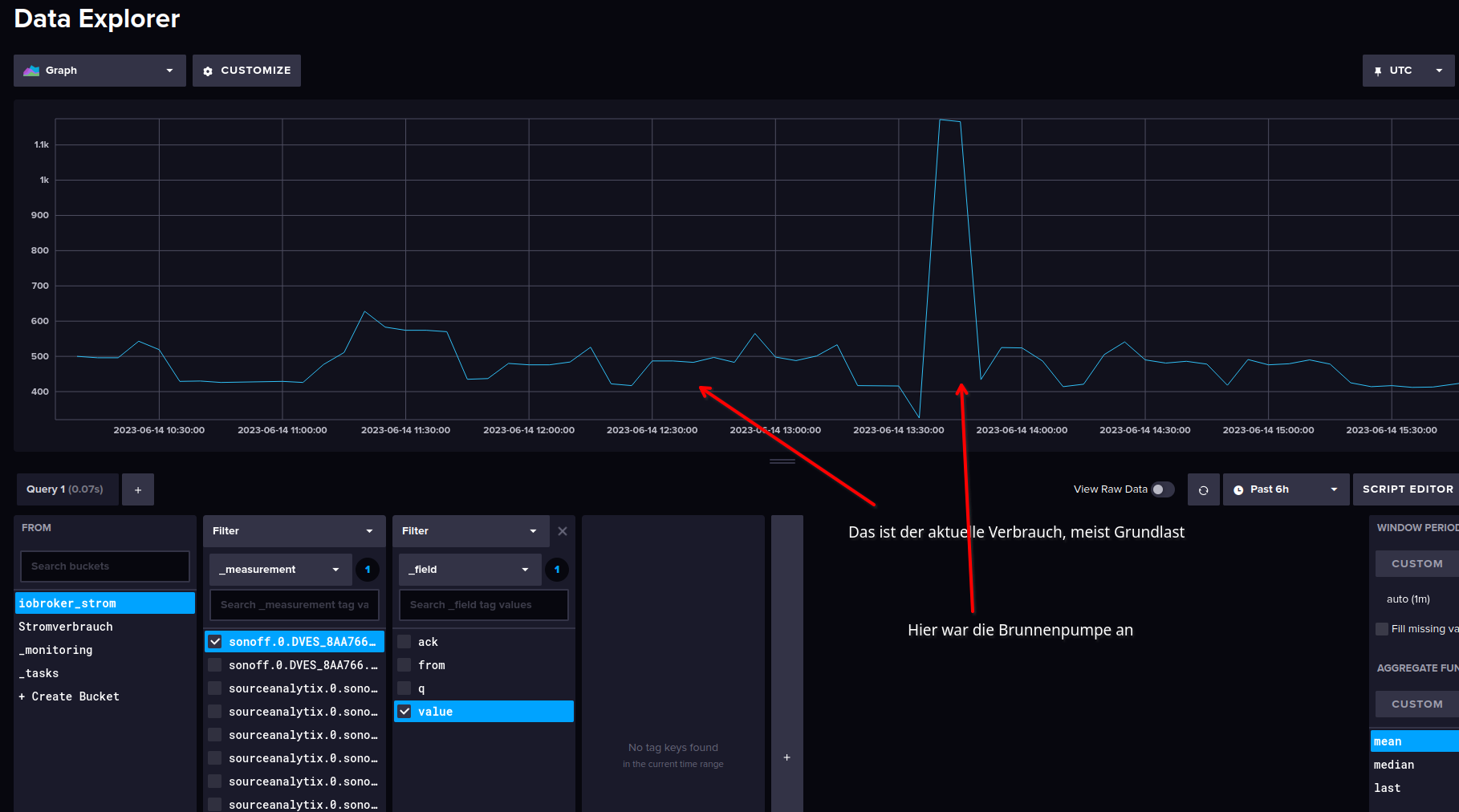
Dann hast Du meine beiden Bilder nicht richtig angeschaut ;) im ersten war die
range (start: v.time...., damit bekam ich drei Werte, das zweite Bild war dann genau 15 Minuten vor und 15 Minuten nach der Meldezeit eingestellt.
Dein Wert von ~5000 war heute um 7:24 Zulu Zeit, das ist 9:24 in Deutschland
Hier mal ein anderes Beispiel:
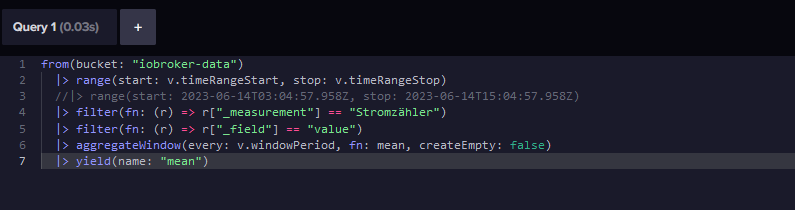
from(bucket: "iobroker_strom") |> range(start: 2023-06-14T13:35:00Z, stop: 2023-06-14T13:40:00Z ) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.akt_w") |> filter(fn: (r) => r["_field"] == "value") //|> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false) |> yield(name: "last")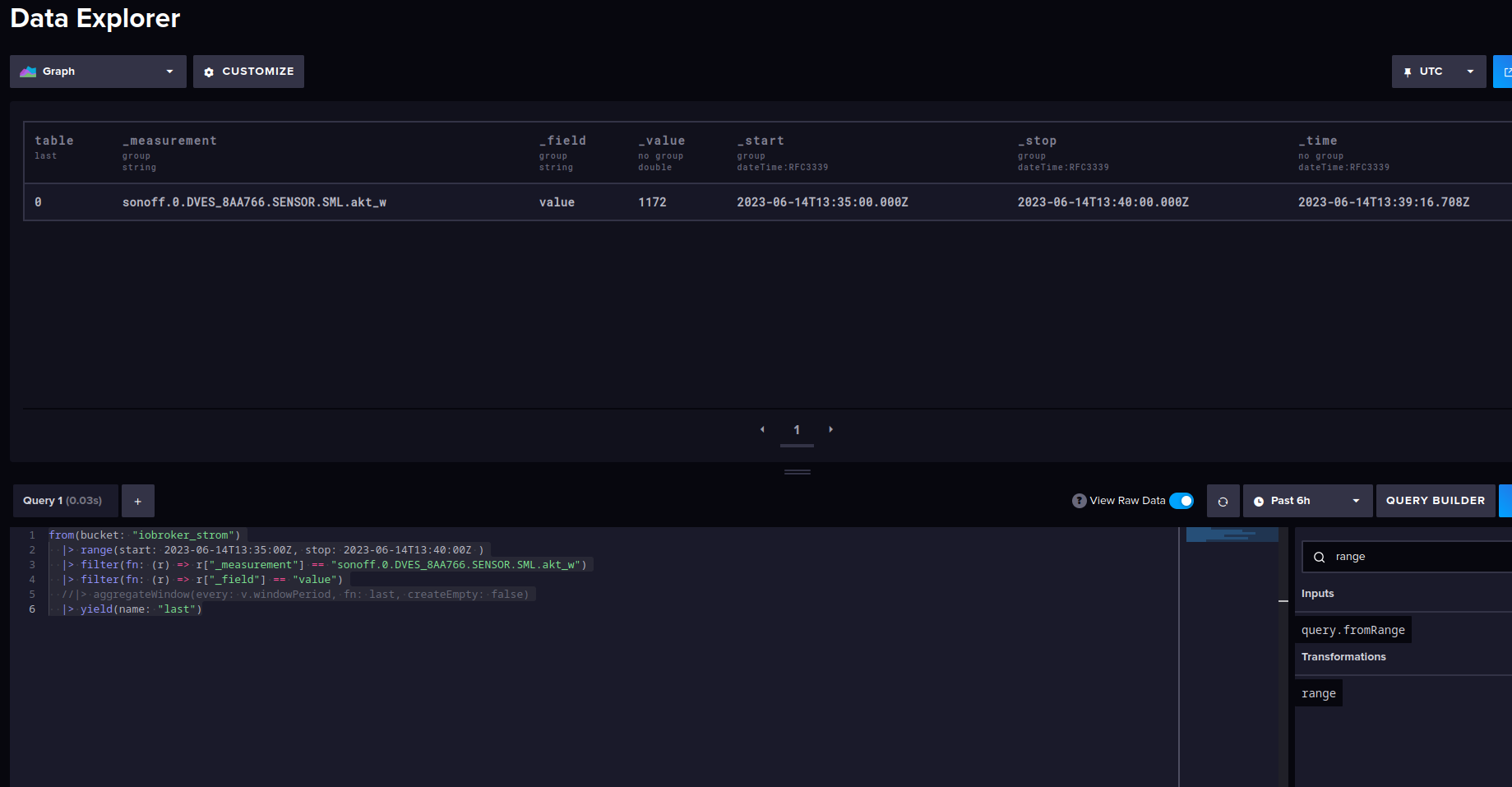
Wenn Du Deinen Wert gefunden hast, dann kannst Du ihn auch genau mit dieser Eingrenzung, mittels delete löschen.
influx delete --bucket iobroker-data --start
hier_zeitpunktanfang--stopzeitpunktende--predicate '_measurement="Stromzähler"'Er findet in diesem Zeitraum ja nur den einen Wert und löscht dann auch nur den und nicht das ganze Bucket.
Ich kann das aber erst morgen mal testen.
VG
Bernd -
Hallo Bernd,
ich versuche hier mal Antworten zu geben:
"Zu Deinen Grafiken, ohne die Abfragen dahinter, kann man da nicht viel machen, dann muss ich erst mal verstehen, um welche Daten es sich handelt, bei meinem Stromzähler gibt es zwei Datenpunkte"
Es ist der Datenpunkt in bei dem der aktuelle Verbauch angezeigt wird.

++++++++++++++++++++
"Wenn es sich um aktuelle Werte handelt, kann es nicht sein, dass Du einen Verbraucher eingeschaltet hast?"
Nein, es war von 6:45 - 11:30 keiner Zuhause und keine Verbraucher mit so hoher Leistung an)
++++++++++++++++++++++
"Dann hast Du meine beiden Bilder nicht richtig angeschaut 😉 im ersten war die range (start: v.time...., damit bekam ich drei Werte, das zweite Bild war dann genau 15 Minuten vor und 15 Minuten nach der Meldezeit eingestellt."
Doch das habe ich aber bei mir kamen da keine Daten raus.
Jetzt habe ich es noch einmal versucht: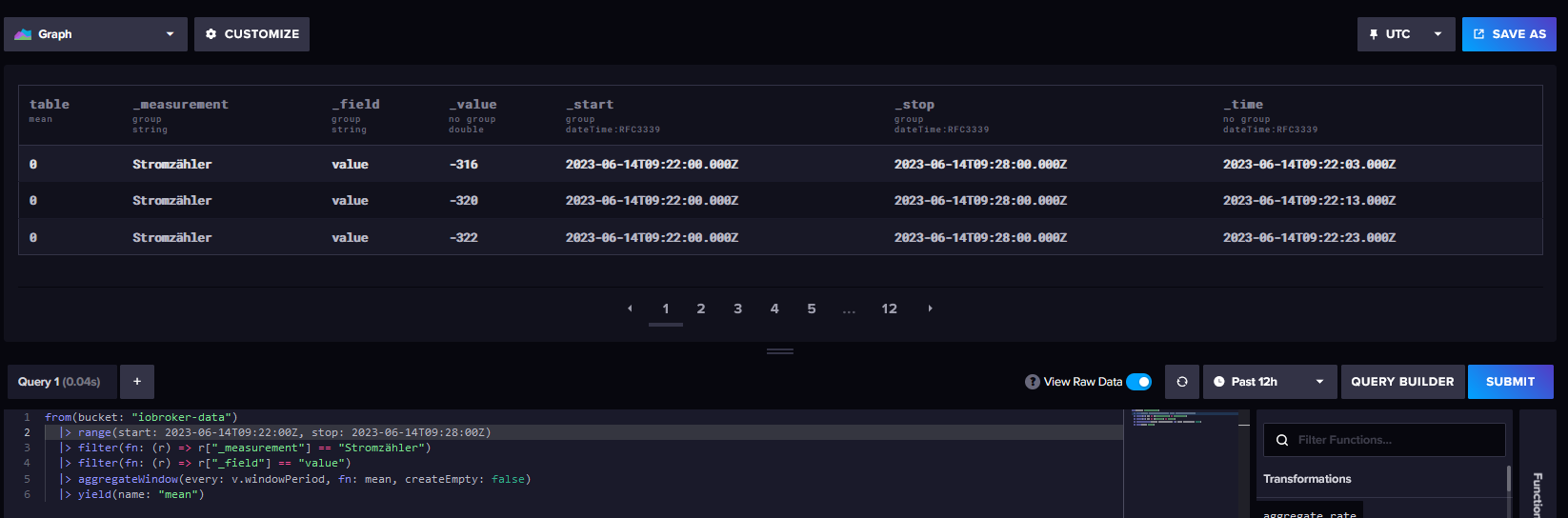
Sowohl mit 7:24 und 9:24 aber der Wert kam nicht (Denke mal das Z steht für Zulu?)
Immerhin kamen jetzt die 3 Werte.
+++++++++++++++++++++++++++++
"Wenn Du Deinen Wert gefunden hast, dann kannst Du ihn auch genau mit dieser Eingrenzung, mittels delete löschen.
influx delete --bucket iobroker-data --start hier_zeitpunktanfang --stop zeitpunktende --predicate '_measurement="Stromzähler"'
Er findet in diesem Zeitraum ja nur den einen Wert und löscht dann auch nur den und nicht das ganze Bucket.
Ich kann das aber erst morgen mal testen."
Ich werde den Wert noch mal versuchen zu finden und dann noch mal warten bis du es getestet hast.
Was hat das mit dem Screenshot von dir auf sich?
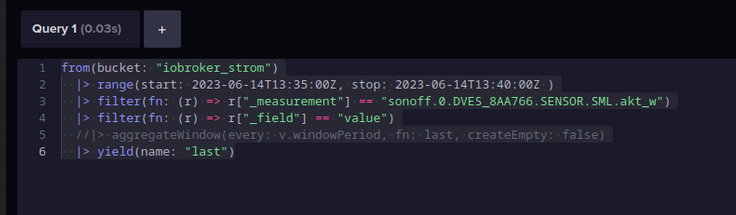
Ich sehe du hast da vermutlich was eingefügt //> aggregat .............Edit:
Habe gerade noch mal den Punkt gesucht und gefunden:

Dann den Wert so wie gezeigt eingegeben:
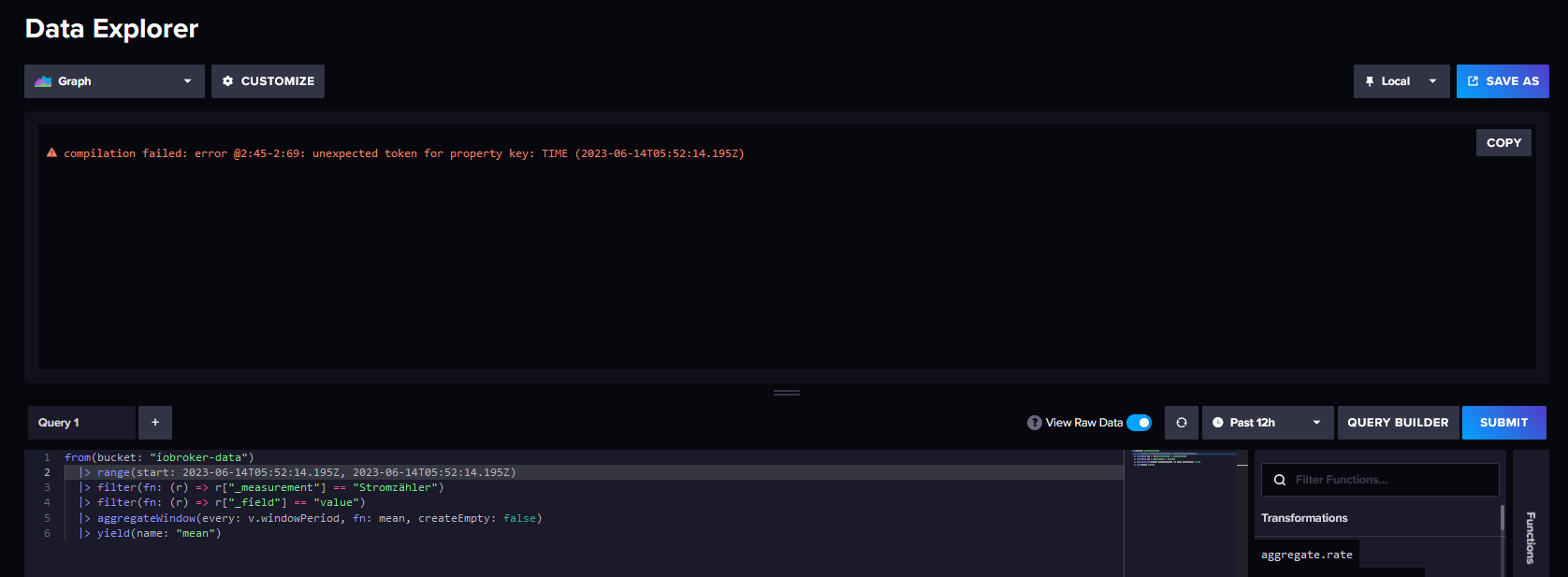
und auch das haut nicht hin.
Habe es in der Zeile 5 mit//|>und ohne probiert.
Das interessante ist ja auch das die Werte Watt und _time gleich sind wie im ersten Screenshot und _start und _stop die Zeit schon wieder anders.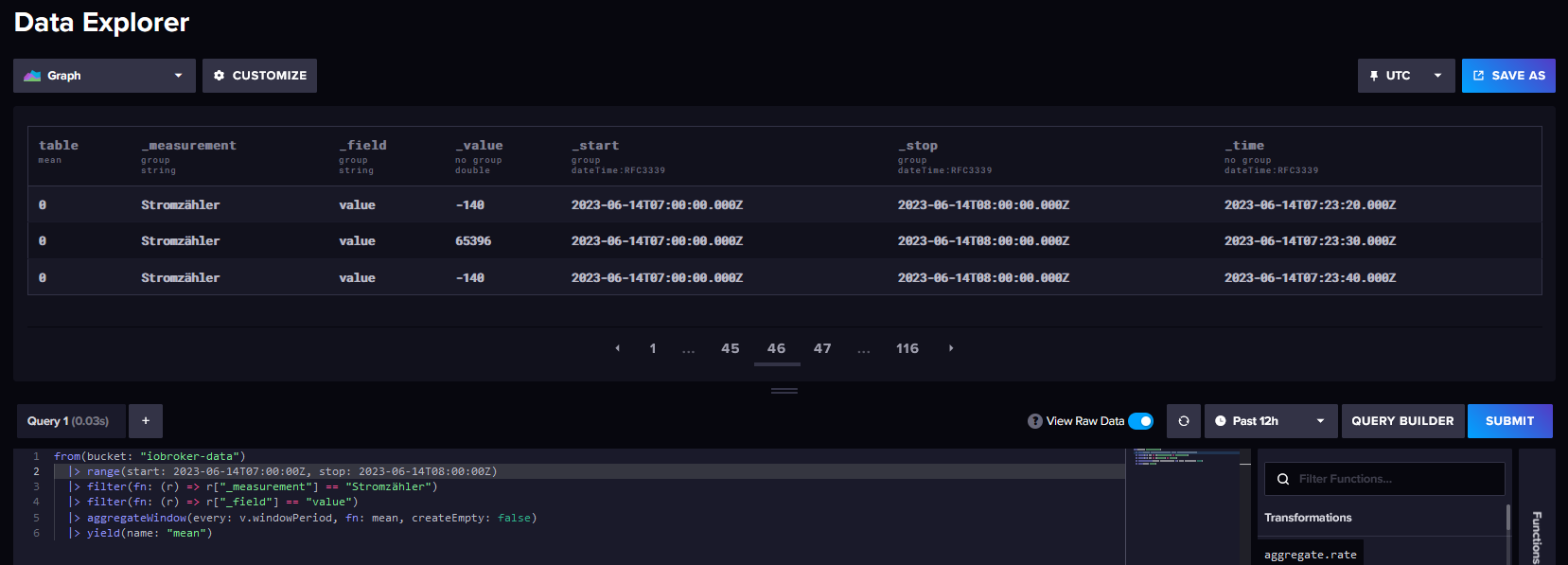
...... und noch einen zu hohen Wert gefunden im ähnlichen Zeitbereich??.
Der Wert ist vorher nie erschiene, ich glaube das Influx DB will mich in den Wahnsinn treiben
Ich finde hier keine Systematik.Gruß Duffy
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
324
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge