

[Linux Shell-Skript] WLAN-Wetterstation
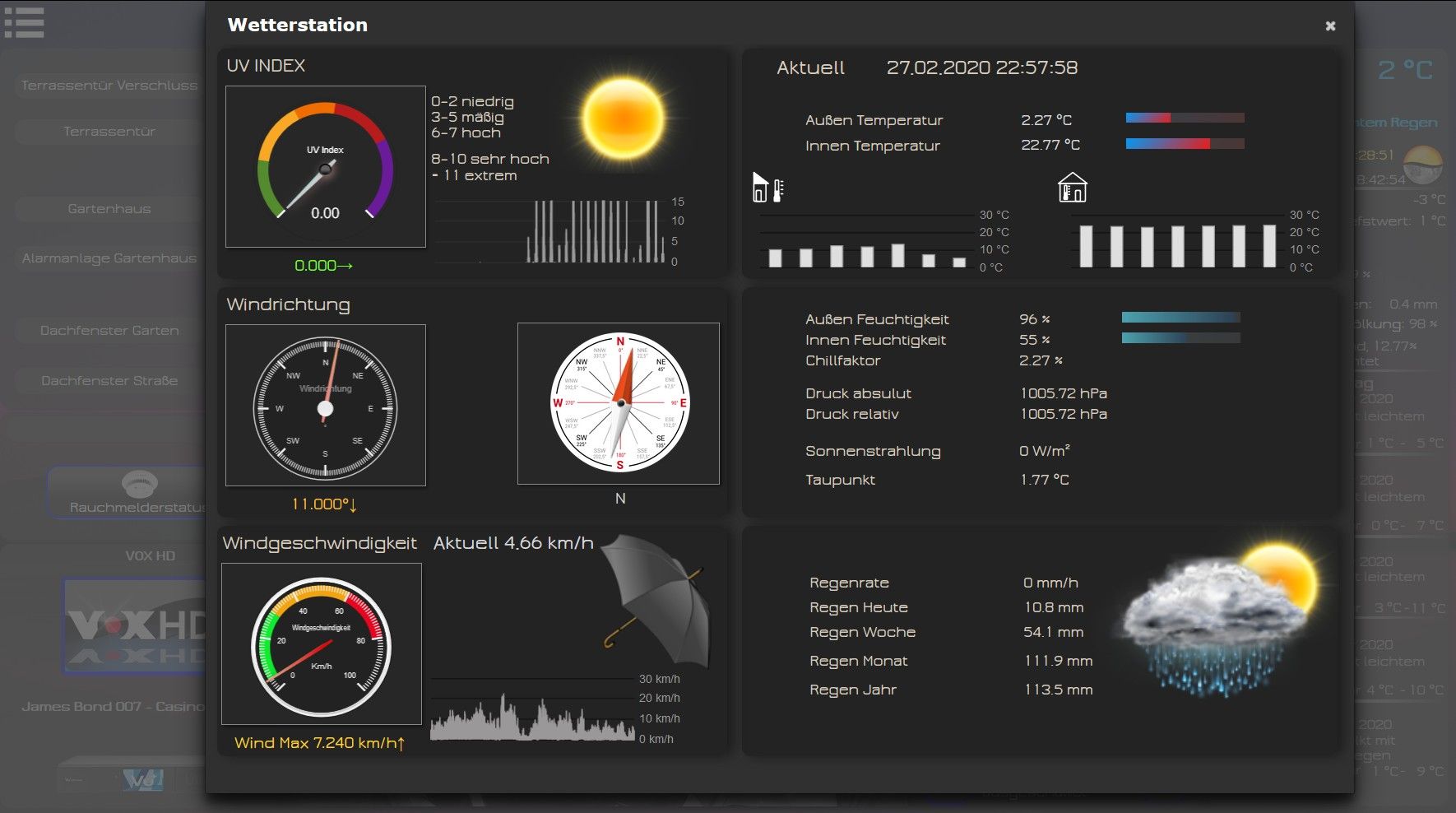
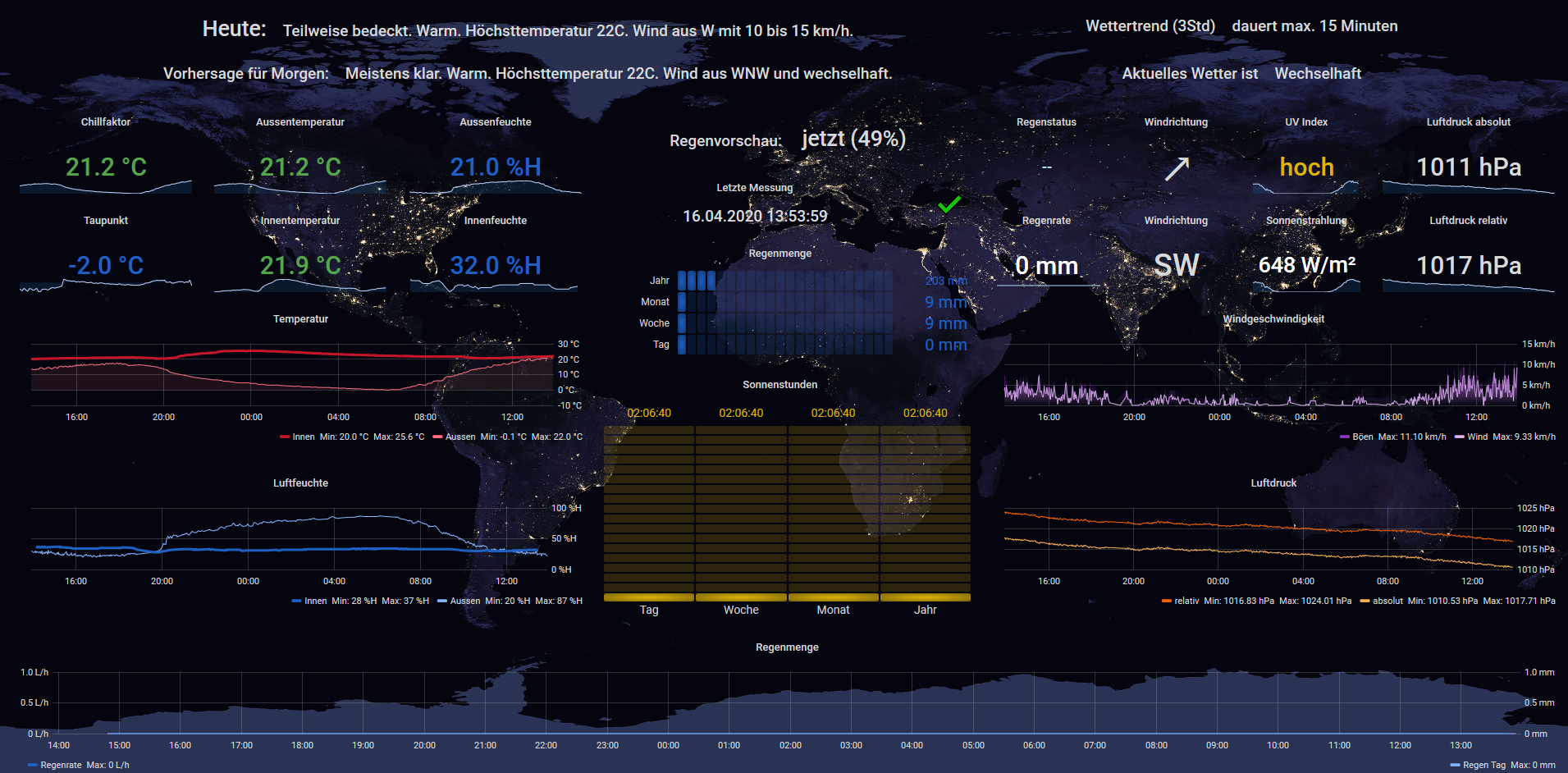
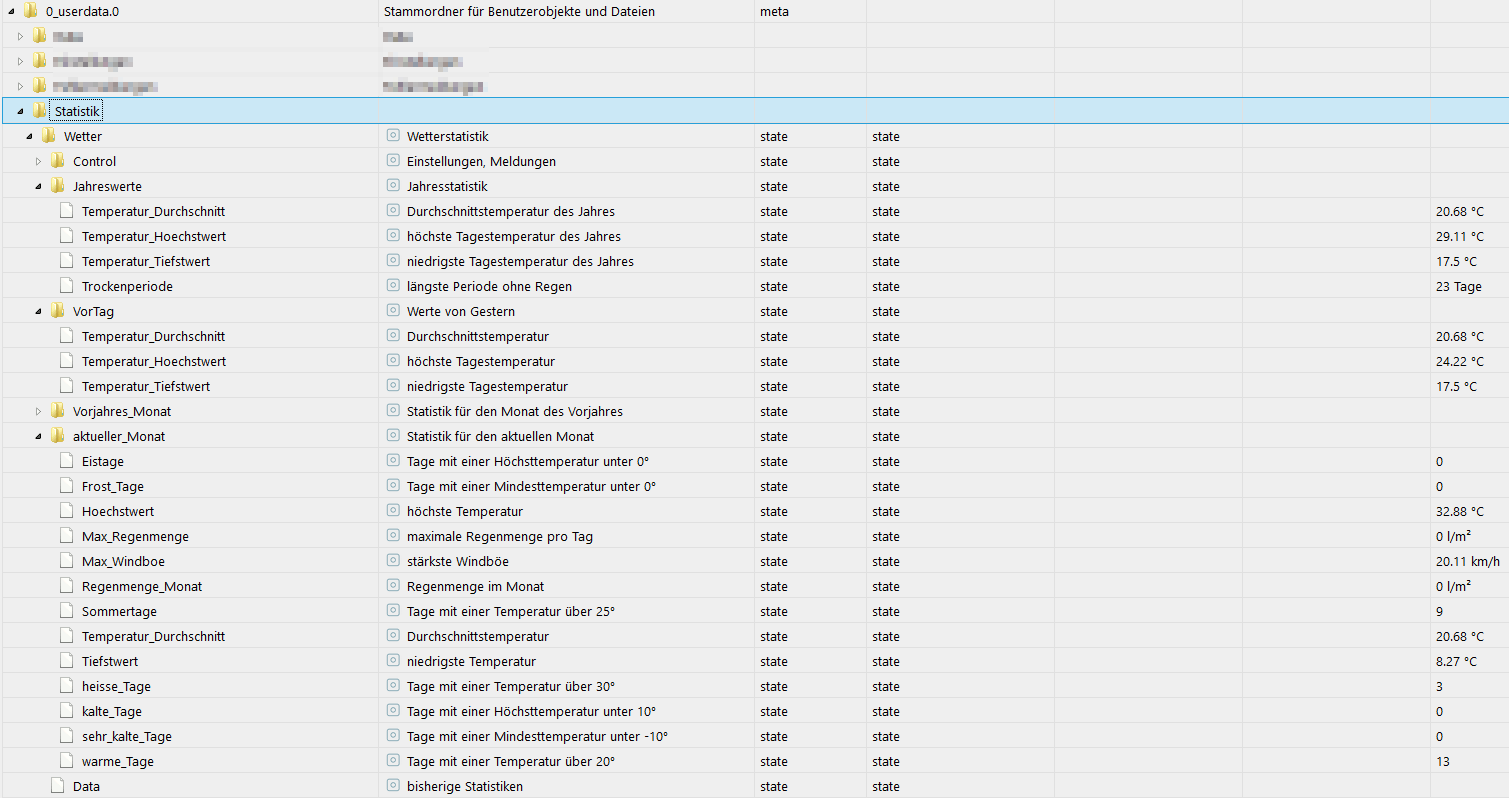
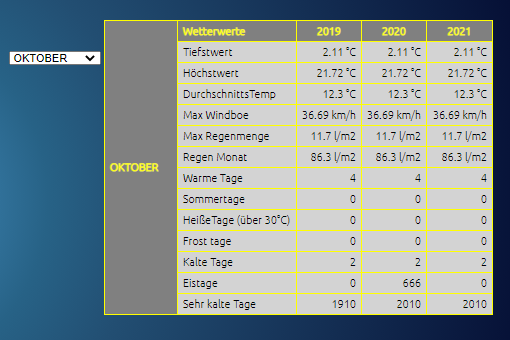
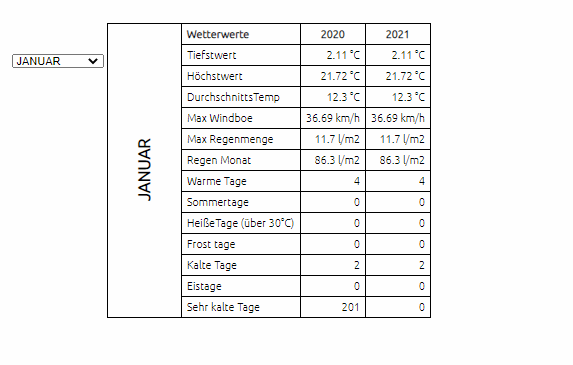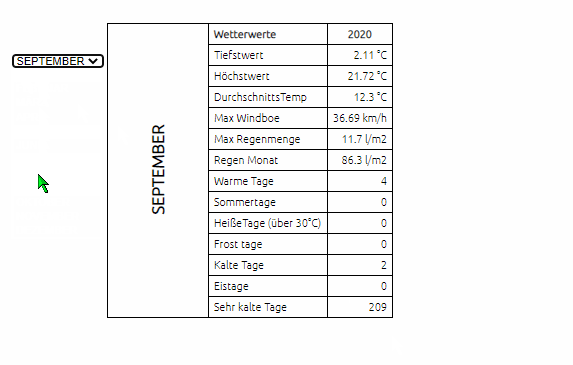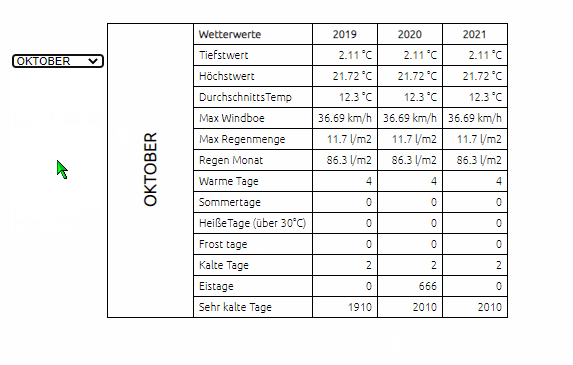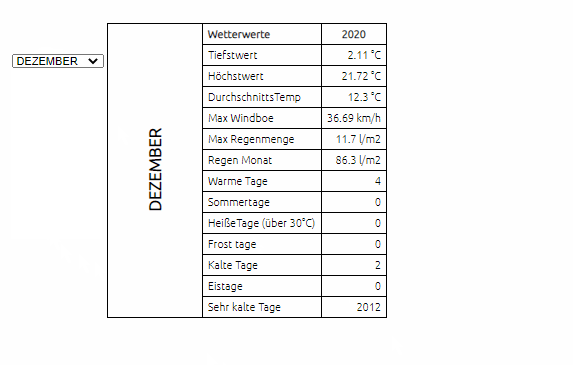
-
@da_woody musst du nicht, ich hab auch nur ein bucket fuer den iobroker, andere Dinge haben ihr eigenes Bucket.. aber fuer verschiedene Buckets in iobroker braucht man auch mehrere Influx-Instanzen und das alles raus zu sortieren ist mir auch zu umstaendlich.
Ansonsten einfach den Link in influx von dem neuen Bucket auf ne Influxv1 Datenbank setzen und du kannst alle Grafana-Views nehmen, musst nur die Source in Grafana anpassen.
Bisher ohne Probleme, bis auf den 24h Temp Wert, der nicht geschrieben wird.. da gibts wohl noch keine Loesung..
@ilovegym sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Ansonsten einfach den Link in influx von dem neuen Bucket auf ne Influxv1 Datenbank setzen und du kannst alle Grafana-Views nehmen, musst nur die Source in Grafana anpassen.
jau, wieder mal eine geschichte durchs knie in die brust.
ich mach von mir aus ein Bucket, wie find ich das in grafana?
muss da noch weiterlesen um das zu verstehen... :) -
@sborg
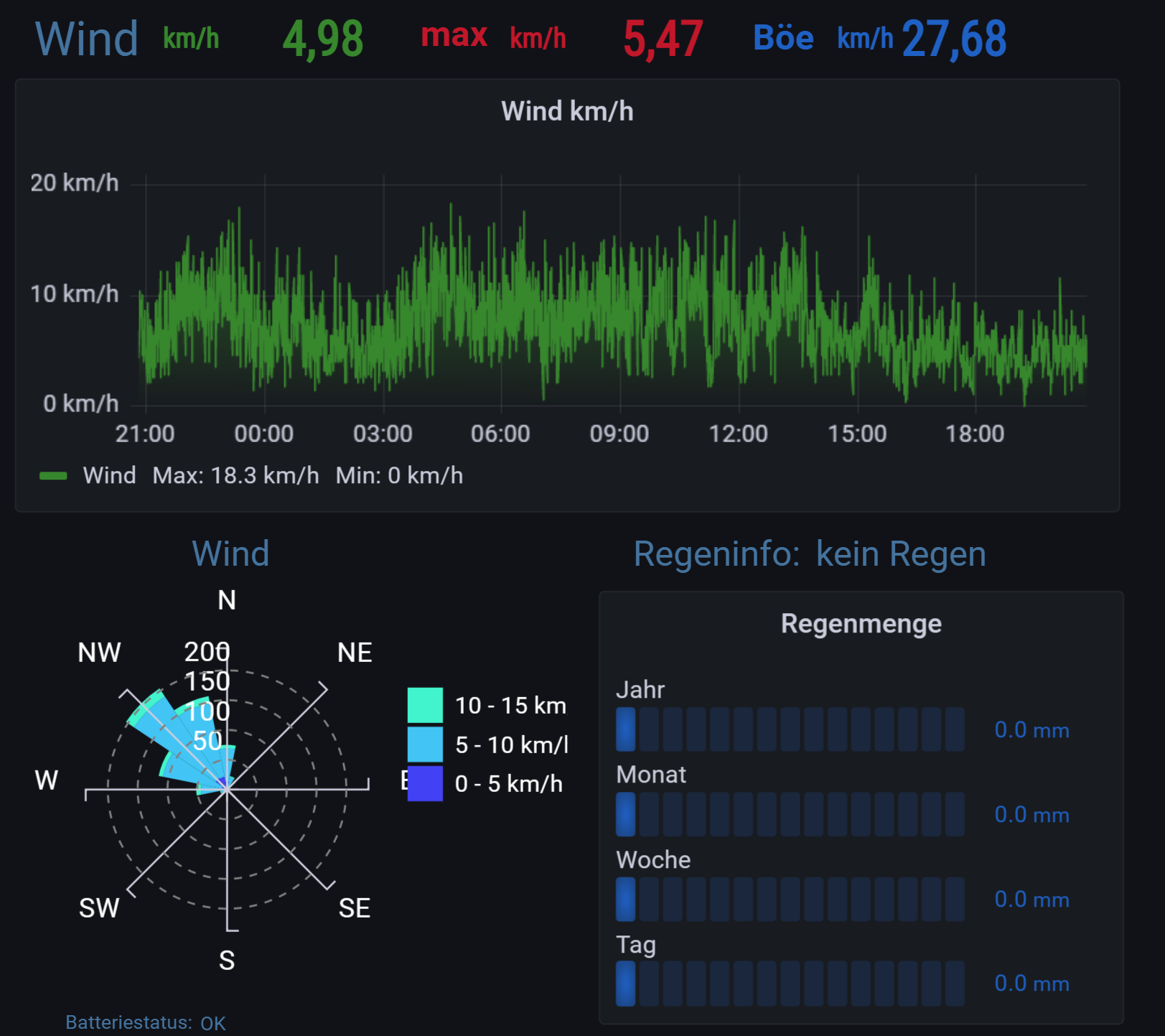
die line 9 und 10 mit den Divisionen sind doch Umrechnungen. Line 9 von rad auf Grad und der Divisor von 0.514 ist doch eine Umrechnung von m/s in Knoten.Benötigt man diese überhaupt, die Felder 0_userdata.0.Wetterstation.Windrichtung liefert doch schon km/h und
0_userdata.0.Wetterstation.Wind_max sollte doch auch schon Grad liefern.Liege ich hier mit meiner Annahme richtig?
@tritor sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@sborg
die line 9 und 10 mit den Divisionen sind doch Umrechnungen. Line 9 von rad auf Grad und der Divisor von 0.514 ist doch eine Umrechnung von m/s in Knoten.Benötigt man diese überhaupt, die Felder 0_userdata.0.Wetterstation.Windrichtung liefert doch schon km/h und
0_userdata.0.Wetterstation.Wind_max sollte doch auch schon Grad liefern.Liege ich hier mit meiner Annahme richtig?
Ich experimentiere aktuell selbst noch. Bei der Umrechnung von Rad in Grad hast du Recht, habe ich rausgeschmissen.
Bei der Geschwindigkeit bin ich noch unschlüssig. Steht mal beim Plugin überhaupt nix bei was es will/braucht.
Im Text steht aber "convert knots from m/s", könnte also bedeuten, dass er es in Knoten will? Ich habe jetzt mal versuchsweise durch 1.852 geteilt. Sieht mir nun schlüssig aus wenn ich es mit meinen Werten vergleiche. -
@ilovegym sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Ansonsten einfach den Link in influx von dem neuen Bucket auf ne Influxv1 Datenbank setzen und du kannst alle Grafana-Views nehmen, musst nur die Source in Grafana anpassen.
jau, wieder mal eine geschichte durchs knie in die brust.
ich mach von mir aus ein Bucket, wie find ich das in grafana?
muss da noch weiterlesen um das zu verstehen... :)@SBorg
Könntest du vielleicht in der Grafana Readme noch die DPs benennen, die in den shorttermBucket und in den longtermBucket landen sollen?
Oder zumindest eins von beiden, dann weiß man, dass der Rest in dem anderen Bucket landen muss.
Danke. -
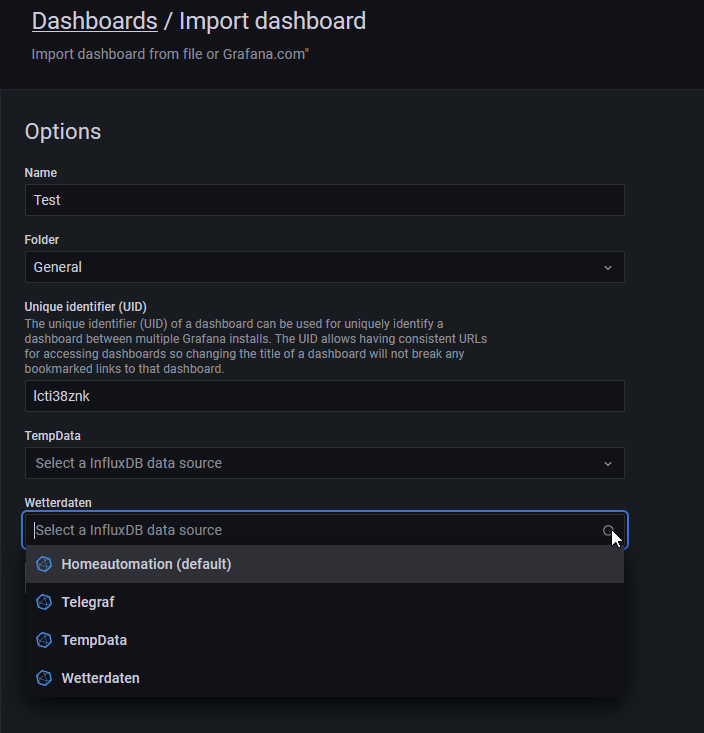
Ich habe eine neue Version des Dashboard-Exports hochgeladen (bei wem es mittlerweile läuft braucht nichts zu tun ;) ), welche das Import-Problem fixen sollte.
Problem ist/war, dass er die UID (anhand derer kann Grafana eindeutig alles identifizieren, selbst wenn man den Namen ändern sollte) auch mit den (meinen) Datenquellen verknüpft. Deswegen kann meine UID nur absolut zufällig mit der eurigen übereinstimmen. In der neuen Version wird man nun beim Import gefragt und muss die passenden Datenquellen auswählen.
Hat man nur eine für alles, bei beiden die selbe auswählen:
LG SBorg ( SBorg auf GitHub)
Projekte: Lebensmittelwarnung.de | WLAN-Wetterstation | PimpMyStation -
@SBorg
Könntest du vielleicht in der Grafana Readme noch die DPs benennen, die in den shorttermBucket und in den longtermBucket landen sollen?
Oder zumindest eins von beiden, dann weiß man, dass der Rest in dem anderen Bucket landen muss.
Danke.@viper4iob sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@SBorg
Könntest du vielleicht in der Grafana Readme noch die DPs benennen, die in den shorttermBucket und in den longtermBucket landen sollen?
Oder zumindest eins von beiden, dann weiß man, dass der Rest in dem anderen Bucket landen muss.
Danke.Ich bin mir aktuell noch nicht sicher ob ich das überhaupt so lassen soll. Viele haben Probleme (oder wollen einfach nicht) mit mehreren Buckets zu arbeiten. Ev. wäre es besser mit einem "Wetter-Bucket" zu arbeiten und das per Influx-Tasks entsprechend zu befüllen. Das würde auch die Datenmenge stark reduzieren.
Wenn man alles nutzen will muss man aktuell auch alle Daten von zB. der Außentemperatur aufheben. Aber braucht irgendwer auch wirklich vom 22.04.2022 um 13:10 Uhr die Temperatur? Mir genügt eigentlich, um mal aktuell zu sein, die Min/Max/Avg-Temperatur vom 27.02.2022...
Das wären dann pro Jahr gerade mal 3 x 365 Datensätze (aktuell sind es pro Tag etwa ~3.000). Da könnte man auch über Jahre hinweg speichern (und bald Temperatur von vor 5 Jahren abfragen )
)LG SBorg ( SBorg auf GitHub)
Projekte: Lebensmittelwarnung.de | WLAN-Wetterstation | PimpMyStation -
Ich habe eine neue Version des Dashboard-Exports hochgeladen (bei wem es mittlerweile läuft braucht nichts zu tun ;) ), welche das Import-Problem fixen sollte.
Problem ist/war, dass er die UID (anhand derer kann Grafana eindeutig alles identifizieren, selbst wenn man den Namen ändern sollte) auch mit den (meinen) Datenquellen verknüpft. Deswegen kann meine UID nur absolut zufällig mit der eurigen übereinstimmen. In der neuen Version wird man nun beim Import gefragt und muss die passenden Datenquellen auswählen.
Hat man nur eine für alles, bei beiden die selbe auswählen:
@sborg sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Hat man nur eine für alles, bei beiden die selbe auswählen:
Danke
Also hier noch zusätzlich für
short......eine Datenquelle erstellen?
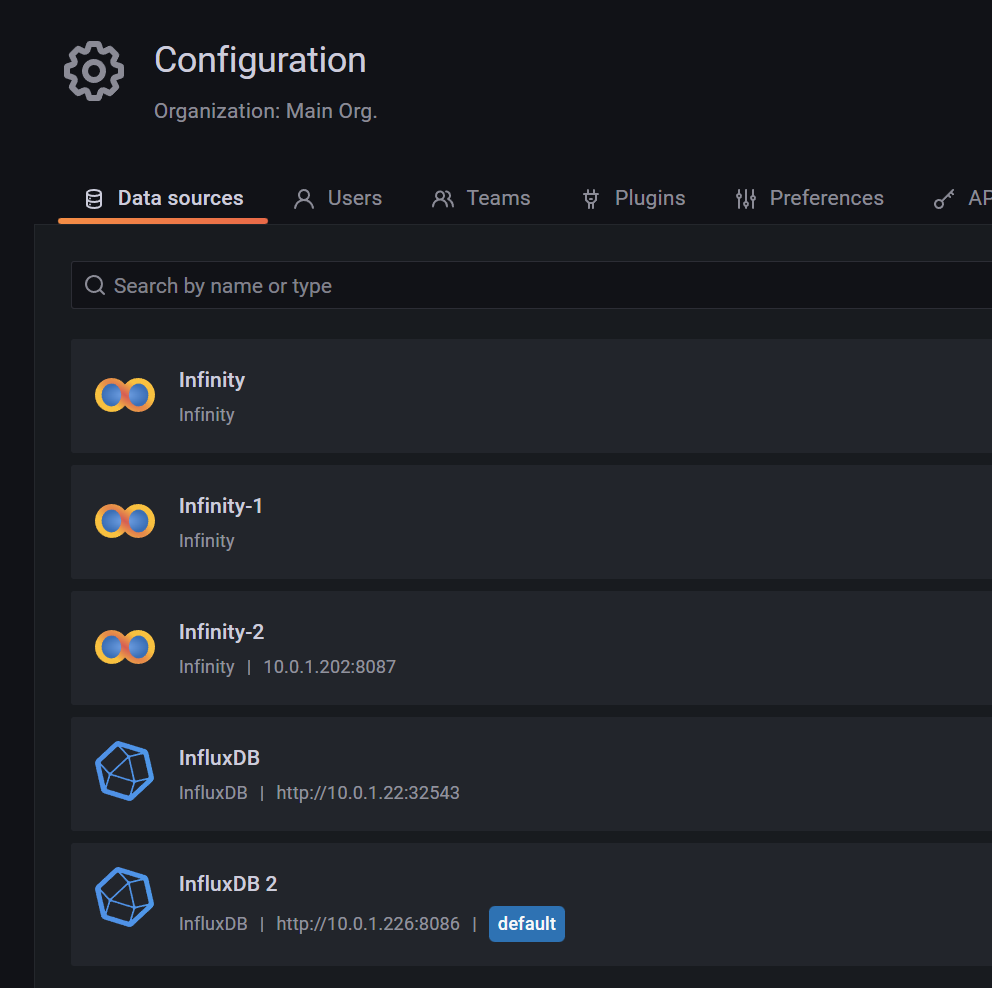
Ich hab jetzt in ioB influx.1 für
long(Bucket: iobroker) und fürshort(Bucket: iobroker-1w).Es reicht also nicht, 1 Datenquelle mit 2 Buckets?
° Node.js & System Update ---> sudo apt update, iob stop, sudo apt full-upgrade
° Node.js Fixer ---> iob nodejs-update
° Fixer ---> iob fix -
@viper4iob sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@SBorg
Könntest du vielleicht in der Grafana Readme noch die DPs benennen, die in den shorttermBucket und in den longtermBucket landen sollen?
Oder zumindest eins von beiden, dann weiß man, dass der Rest in dem anderen Bucket landen muss.
Danke.Ich bin mir aktuell noch nicht sicher ob ich das überhaupt so lassen soll. Viele haben Probleme (oder wollen einfach nicht) mit mehreren Buckets zu arbeiten. Ev. wäre es besser mit einem "Wetter-Bucket" zu arbeiten und das per Influx-Tasks entsprechend zu befüllen. Das würde auch die Datenmenge stark reduzieren.
Wenn man alles nutzen will muss man aktuell auch alle Daten von zB. der Außentemperatur aufheben. Aber braucht irgendwer auch wirklich vom 22.04.2022 um 13:10 Uhr die Temperatur? Mir genügt eigentlich, um mal aktuell zu sein, die Min/Max/Avg-Temperatur vom 27.02.2022...
Das wären dann pro Jahr gerade mal 3 x 365 Datensätze (aktuell sind es pro Tag etwa ~3.000). Da könnte man auch über Jahre hinweg speichern (und bald Temperatur von vor 5 Jahren abfragen ) -
@tritor sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@sborg
die line 9 und 10 mit den Divisionen sind doch Umrechnungen. Line 9 von rad auf Grad und der Divisor von 0.514 ist doch eine Umrechnung von m/s in Knoten.Benötigt man diese überhaupt, die Felder 0_userdata.0.Wetterstation.Windrichtung liefert doch schon km/h und
0_userdata.0.Wetterstation.Wind_max sollte doch auch schon Grad liefern.Liege ich hier mit meiner Annahme richtig?
Ich experimentiere aktuell selbst noch. Bei der Umrechnung von Rad in Grad hast du Recht, habe ich rausgeschmissen.
Bei der Geschwindigkeit bin ich noch unschlüssig. Steht mal beim Plugin überhaupt nix bei was es will/braucht.
Im Text steht aber "convert knots from m/s", könnte also bedeuten, dass er es in Knoten will? Ich habe jetzt mal versuchsweise durch 1.852 geteilt. Sieht mir nun schlüssig aus wenn ich es mit meinen Werten vergleiche. -
Ich habe da mal eine Frage zum Thema Performance der InfluxDB V2:
Ich habe auf Ubuntu 22.04 ein Direkt-Update von v1 auf v2 gemacht, was im Prinzip ohne Probleme funktioniert hat.
Da ich vorher eigene User für iobroker und Wetterstationsskript angelegt hatte, wurden diese mit migriert und als v1 User weiter geführt. Das hat den Vorteil, dass ich nun weiterhin die DB im v1 Modus abfragen kann.
Nun hatte ich im iobroker die InfluxDB Instanz auf V2 umgestellt und ich muss sagen, dass das Abfragen der Verlaufsdaten eines DP deutlich langsamer geworden sind.
Auch wenn ich irgendwelche ECharts abfrage, dauert das Laden dieser deutlich länger. Die CPU Last des influxdb Dienstes ist während der Abfrage auch extrem hoch.
Wenn ich dann einfach die iobroker Instanz wieder auf V1 umstelle und den migrierten V1 User dafür nutze, geht alles wieder gewohnt schnell, wie vorher.
Das Ganze läuft auf einer VM mit 4 Kernen je 3,3 GHz.
Die migrierten Daten von v1 auf v2 waren 320 MB, nur um mal die Größenordnung zu haben.
Ich würde also gerne mal wissen wie bei euch so die Performance der InfluxDB V2 in iobroker ist? -
Ich habe da mal eine Frage zum Thema Performance der InfluxDB V2:
Ich habe auf Ubuntu 22.04 ein Direkt-Update von v1 auf v2 gemacht, was im Prinzip ohne Probleme funktioniert hat.
Da ich vorher eigene User für iobroker und Wetterstationsskript angelegt hatte, wurden diese mit migriert und als v1 User weiter geführt. Das hat den Vorteil, dass ich nun weiterhin die DB im v1 Modus abfragen kann.
Nun hatte ich im iobroker die InfluxDB Instanz auf V2 umgestellt und ich muss sagen, dass das Abfragen der Verlaufsdaten eines DP deutlich langsamer geworden sind.
Auch wenn ich irgendwelche ECharts abfrage, dauert das Laden dieser deutlich länger. Die CPU Last des influxdb Dienstes ist während der Abfrage auch extrem hoch.
Wenn ich dann einfach die iobroker Instanz wieder auf V1 umstelle und den migrierten V1 User dafür nutze, geht alles wieder gewohnt schnell, wie vorher.
Das Ganze läuft auf einer VM mit 4 Kernen je 3,3 GHz.
Die migrierten Daten von v1 auf v2 waren 320 MB, nur um mal die Größenordnung zu haben.
Ich würde also gerne mal wissen wie bei euch so die Performance der InfluxDB V2 in iobroker ist?Bei mir im Docker deutlich schneller, und braucht weniger Ressourcen als v1
-
Ich habe da mal eine Frage zum Thema Performance der InfluxDB V2:
Ich habe auf Ubuntu 22.04 ein Direkt-Update von v1 auf v2 gemacht, was im Prinzip ohne Probleme funktioniert hat.
Da ich vorher eigene User für iobroker und Wetterstationsskript angelegt hatte, wurden diese mit migriert und als v1 User weiter geführt. Das hat den Vorteil, dass ich nun weiterhin die DB im v1 Modus abfragen kann.
Nun hatte ich im iobroker die InfluxDB Instanz auf V2 umgestellt und ich muss sagen, dass das Abfragen der Verlaufsdaten eines DP deutlich langsamer geworden sind.
Auch wenn ich irgendwelche ECharts abfrage, dauert das Laden dieser deutlich länger. Die CPU Last des influxdb Dienstes ist während der Abfrage auch extrem hoch.
Wenn ich dann einfach die iobroker Instanz wieder auf V1 umstelle und den migrierten V1 User dafür nutze, geht alles wieder gewohnt schnell, wie vorher.
Das Ganze läuft auf einer VM mit 4 Kernen je 3,3 GHz.
Die migrierten Daten von v1 auf v2 waren 320 MB, nur um mal die Größenordnung zu haben.
Ich würde also gerne mal wissen wie bei euch so die Performance der InfluxDB V2 in iobroker ist?@viper4iob sagte in [Linux Shell-Skript] WLAN-Wetterstation:
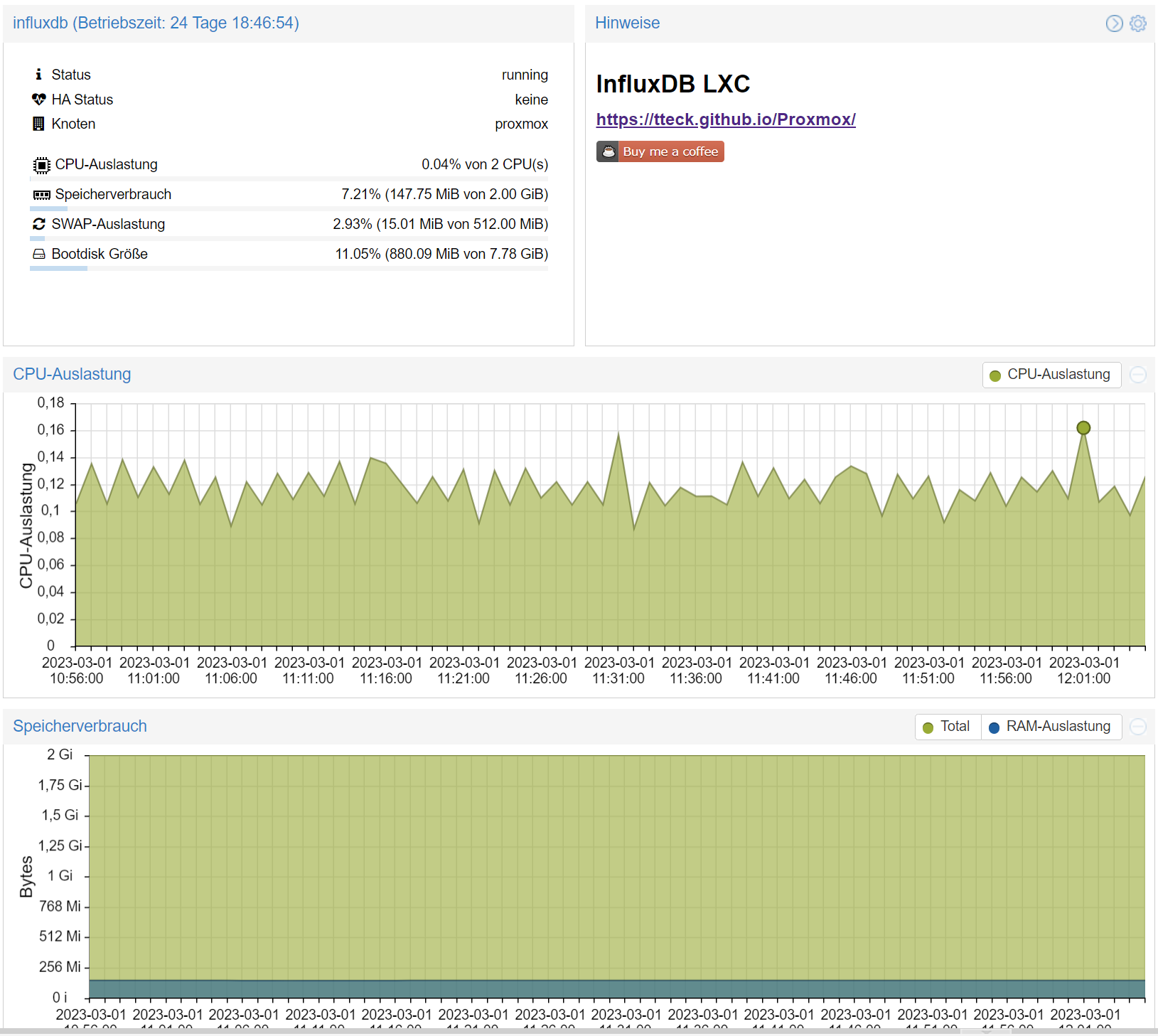
Performance der InfluxDB V2:
kann ich auch nicht bestätigen.
Geschwindigkeit gleich oder minimal schneller.
Speicherverbrauch und Auslastung, siehe selbst.
-
Nur um nochmal sicher zu gehen, ich rede nicht vom normalen Betrieb, wenn Daten hinein geschrieben werden.
Sondern, wenn größere Zeiträume für Graphen (z.B. über ECharts im iobroker) abgerufen werden oder wenn man in iobroker bei einem DP auf die Benutzerdefinierten Einstellungen geht und sich die Verlaufsdaten anzeigen lassen will.
Wenn ich die InfluxDB Instanz im iobroker im V2 Modus habe, dauert das deutlich länger als wenn ich sie im alten V1 Modus habe.Bei Grafana habe ich noch das alte Dashboard, das den v1 User nutzt, das geht weiterhin ohne Probleme.
Das neue Dashboard für die v2 muss ich erst noch testen, kann also nicht sagen, ob ich da dann die gleichen Probleme habe. -
@sborg sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Hat man nur eine für alles, bei beiden die selbe auswählen:
Danke
Also hier noch zusätzlich für
short......eine Datenquelle erstellen?
Ich hab jetzt in ioB influx.1 für
long(Bucket: iobroker) und fürshort(Bucket: iobroker-1w).Es reicht also nicht, 1 Datenquelle mit 2 Buckets?
@negalein sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Es reicht also nicht, 1 Datenquelle mit 2 Buckets?
Doch :)
Die Datenquelle ist ja nur eine Schnittstelle wo die Daten herkommen. Die beiden Buckets waren aber so gedacht, eines für Daten die man aufhebt (z.B. Außentemperatur, sonst kann ich auch nicht abfragen wie warm/kalt es vor einem Jahr war), und ein zweites für eher "unwichtiges" wie die Stati der Datenübertragung AWEKAS, OSeM etc. Mich interessiert weder ob die Datenübertragung vor drei Wochen um 12:35 Uhr funktioniert hat, noch ob der Wind vor sechs Wochen um 18:12 Uhr aus Norden geblasen hat...
Also kann das doch alles in ein Bucket was dann die Daten bspw. nach 30 Tagen automatisch löscht. -
Ich habe da mal eine Frage zum Thema Performance der InfluxDB V2:
Ich habe auf Ubuntu 22.04 ein Direkt-Update von v1 auf v2 gemacht, was im Prinzip ohne Probleme funktioniert hat.
Da ich vorher eigene User für iobroker und Wetterstationsskript angelegt hatte, wurden diese mit migriert und als v1 User weiter geführt. Das hat den Vorteil, dass ich nun weiterhin die DB im v1 Modus abfragen kann.
Nun hatte ich im iobroker die InfluxDB Instanz auf V2 umgestellt und ich muss sagen, dass das Abfragen der Verlaufsdaten eines DP deutlich langsamer geworden sind.
Auch wenn ich irgendwelche ECharts abfrage, dauert das Laden dieser deutlich länger. Die CPU Last des influxdb Dienstes ist während der Abfrage auch extrem hoch.
Wenn ich dann einfach die iobroker Instanz wieder auf V1 umstelle und den migrierten V1 User dafür nutze, geht alles wieder gewohnt schnell, wie vorher.
Das Ganze läuft auf einer VM mit 4 Kernen je 3,3 GHz.
Die migrierten Daten von v1 auf v2 waren 320 MB, nur um mal die Größenordnung zu haben.
Ich würde also gerne mal wissen wie bei euch so die Performance der InfluxDB V2 in iobroker ist?@viper4iob Ich habe bis dato noch nichts nachteiliges bemerkt. Auch das "umshiften" von größeren Datenmengen innerhalb Influx klappt schnell. Größere Anfragen per Influx-Adapter habe ich allerdings keine, denn ev. hängt es hier auch am Adapter.
Per JS, Grafana etc. ist alles subjektiv gleich schnell, zumindest nicht spürbar schneller/langsamer.
LG SBorg ( SBorg auf GitHub)
Projekte: Lebensmittelwarnung.de | WLAN-Wetterstation | PimpMyStation -
@viper4iob Ich habe bis dato noch nichts nachteiliges bemerkt. Auch das "umshiften" von größeren Datenmengen innerhalb Influx klappt schnell. Größere Anfragen per Influx-Adapter habe ich allerdings keine, denn ev. hängt es hier auch am Adapter.
Per JS, Grafana etc. ist alles subjektiv gleich schnell, zumindest nicht spürbar schneller/langsamer.
@sborg sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@viper4iob Ich habe bis dato noch nichts nachteiliges bemerkt. Auch das "umshiften" von größeren Datenmengen innerhalb Influx klappt schnell. Größere Anfragen per Influx-Adapter habe ich allerdings keine, denn ev. hängt es hier auch am Adapter.
Per JS, Grafana etc. ist alles subjektiv gleich schnell, zumindest nicht spürbar schneller/langsamer.
Dann hab ich es richtig gemacht.
Aber beim Import des Dashboard, bei der Abfrage nach der Source, kann ich jeweils nur die Datasource auswählen.
Nicht jedochinfluxfür permanent undinflux-1wfür temporär.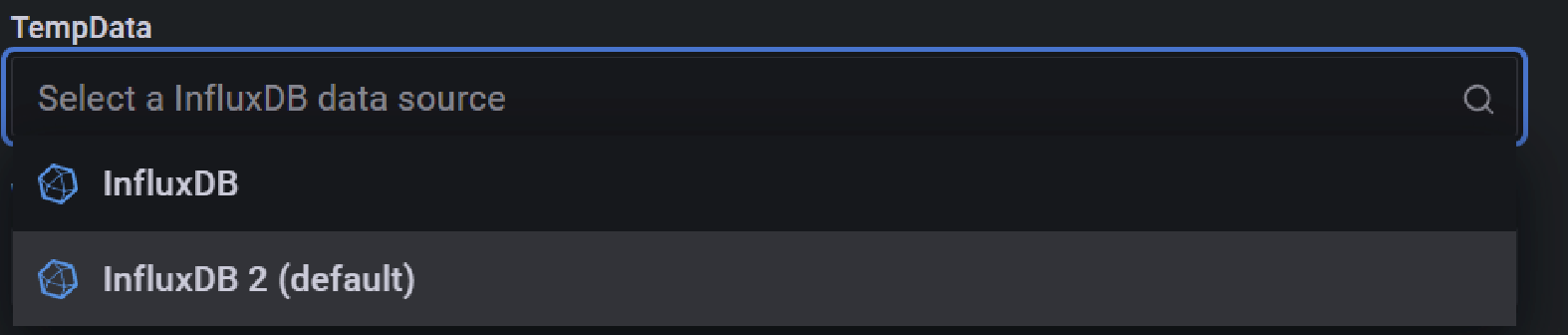
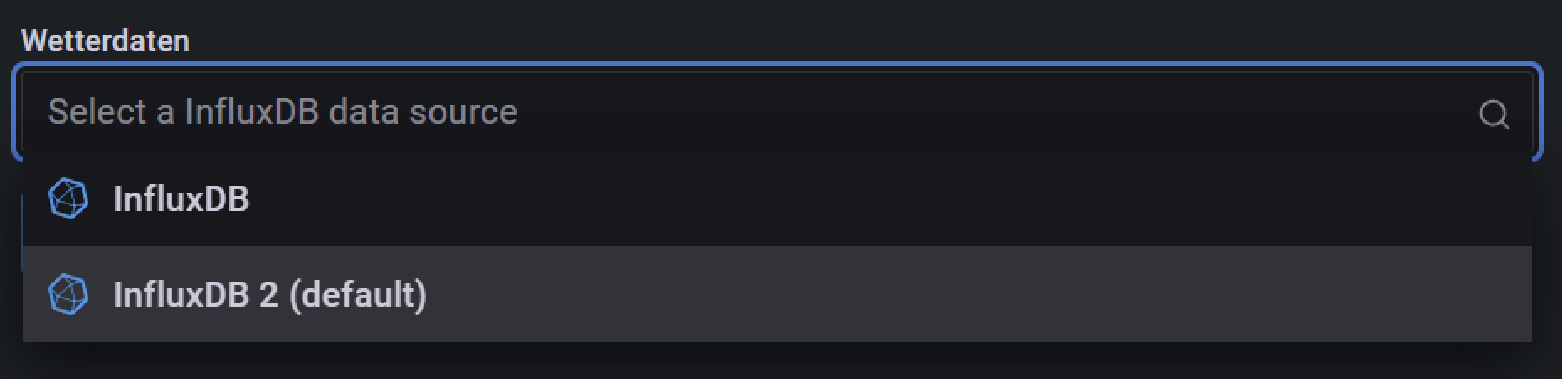
Oder mach ich wiedermal wo was falsch?
° Node.js & System Update ---> sudo apt update, iob stop, sudo apt full-upgrade
° Node.js Fixer ---> iob nodejs-update
° Fixer ---> iob fix -
Ich habe jetzt mal mein Konzept überdacht und überarbeitet.
Dabei kam dann "tabula rasa" heraus, oder der obligatorische Frühjahrsputz...Für meinen Teil werde ich zukünftig nur noch mit einer Influx-Instanz arbeiten die ein Bucket mit einer Retention von xx Tagen (irgendwo so bei ~30-90 Tage [wird sich noch zeigen]) bedient.
Daraus zieht sich erst mal alles seine Daten was so gebraucht wird (Grafana, JS, NodeRED usw).Nicht wichtiges/permanentes (hier rot):
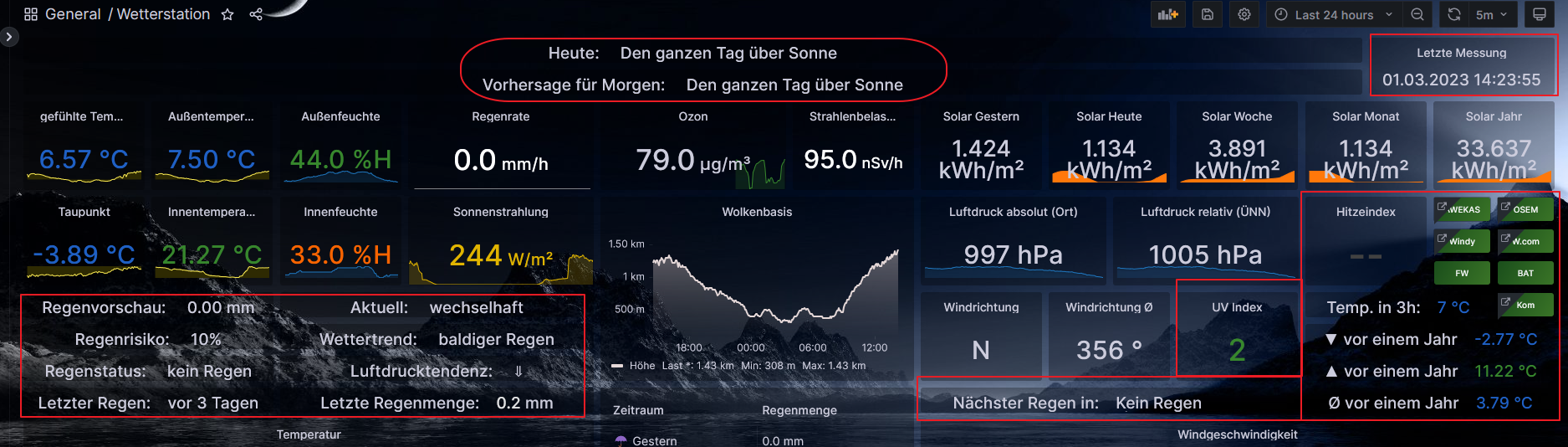
logge ich überhaupt nicht mehr in Influx, sondern beziehe es per Infinity-Datenquelle per RestAPI direkt aus dem ioB.
Das was mich längerfristig interessiert (zB. Außentemperatur [für "vor einem Jahr"], der Gaspreisverlauf etc.] shifte ich dann per Influx-Tasks in ein neues Bucket mit einer Retention von "never". Das Bucket lässt sich dann natürlich noch in Grafana & Co. benutzen, man kann aber auch die Datenflut minimieren (zB. beim Regen nicht "1-2-3-4-n... mm" schreiben, sondern gleich den Gesamtwert).
-
@sborg sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@viper4iob Ich habe bis dato noch nichts nachteiliges bemerkt. Auch das "umshiften" von größeren Datenmengen innerhalb Influx klappt schnell. Größere Anfragen per Influx-Adapter habe ich allerdings keine, denn ev. hängt es hier auch am Adapter.
Per JS, Grafana etc. ist alles subjektiv gleich schnell, zumindest nicht spürbar schneller/langsamer.
Dann hab ich es richtig gemacht.
Aber beim Import des Dashboard, bei der Abfrage nach der Source, kann ich jeweils nur die Datasource auswählen.
Nicht jedochinfluxfür permanent undinflux-1wfür temporär.Oder mach ich wiedermal wo was falsch?
@negalein sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Oder mach ich wiedermal wo was falsch?
Jein, das ist bisserl blöd in Grafana. Du kannst es da erst auswählen wenn du
influx-1wauch wirklich als Datenquelle hinzugefügt hast. In dem Fall hast du dann doch zwei Datenquellen und 2 Buckets aus Sicht von Grafana, auch wenn es technisch gesehen 2 Buckets aus einer Datenquelle sind
LG SBorg ( SBorg auf GitHub)
Projekte: Lebensmittelwarnung.de | WLAN-Wetterstation | PimpMyStation -
@negalein sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Oder mach ich wiedermal wo was falsch?
Jein, das ist bisserl blöd in Grafana. Du kannst es da erst auswählen wenn du
influx-1wauch wirklich als Datenquelle hinzugefügt hast. In dem Fall hast du dann doch zwei Datenquellen und 2 Buckets aus Sicht von Grafana, auch wenn es technisch gesehen 2 Buckets aus einer Datenquelle sind@sborg sagte in [Linux Shell-Skript] WLAN-Wetterstation:
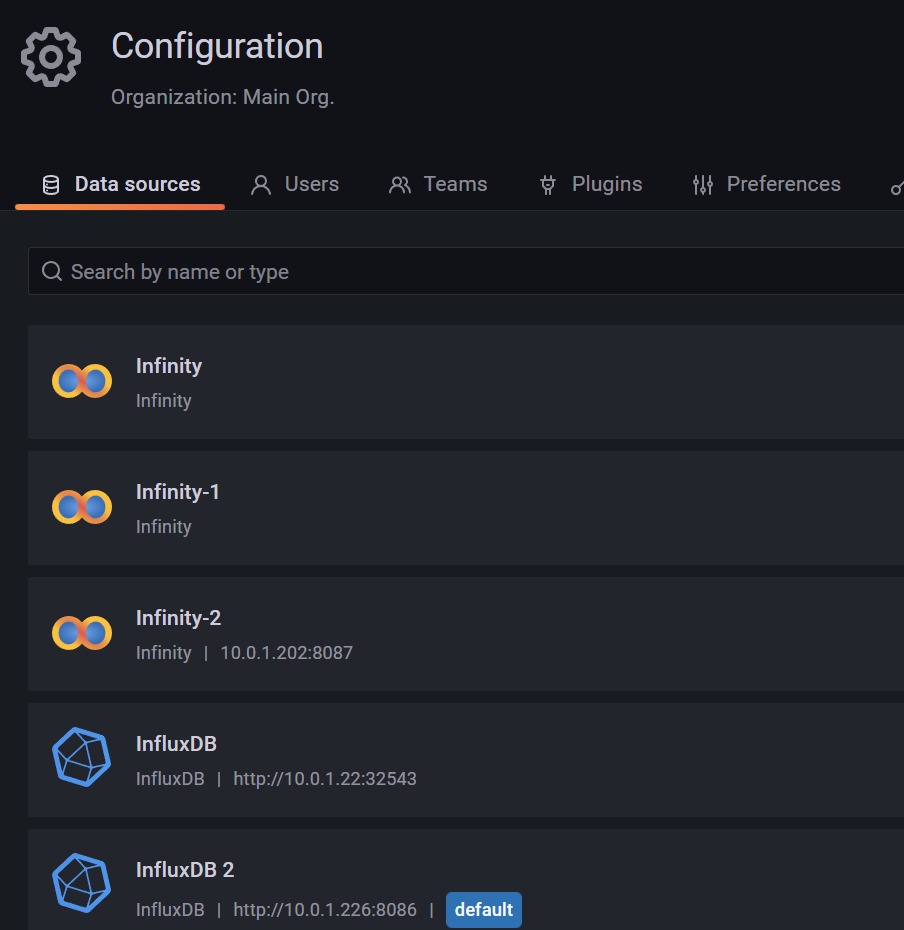
Du kannst es da erst auswählen wenn du influx-1w auch wirklich als Datenquelle hinzugefügt hast
Ok, also hier zusätzlich eine Datenquelle (ident mit InfluxDB 2), und diese dann nur für
influx-1wverwenden.
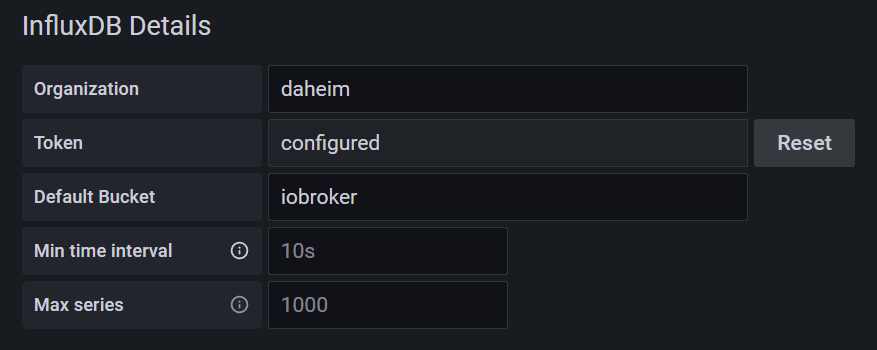
Und hier bei
Default Bucketdanninflux-1weintragen.
° Node.js & System Update ---> sudo apt update, iob stop, sudo apt full-upgrade
° Node.js Fixer ---> iob nodejs-update
° Fixer ---> iob fix -
@viper4iob Ich habe bis dato noch nichts nachteiliges bemerkt. Auch das "umshiften" von größeren Datenmengen innerhalb Influx klappt schnell. Größere Anfragen per Influx-Adapter habe ich allerdings keine, denn ev. hängt es hier auch am Adapter.
Per JS, Grafana etc. ist alles subjektiv gleich schnell, zumindest nicht spürbar schneller/langsamer.
@sborg said in [Linux Shell-Skript] WLAN-Wetterstation:
@viper4iob Ich habe bis dato noch nichts nachteiliges bemerkt. Auch das "umshiften" von größeren Datenmengen innerhalb Influx klappt schnell. Größere Anfragen per Influx-Adapter habe ich allerdings keine, denn ev. hängt es hier auch am Adapter.
Per JS, Grafana etc. ist alles subjektiv gleich schnell, zumindest nicht spürbar schneller/langsamer.
Ok, danke für die Info.
Werde es als nächstes mit dem neuem Grafana Dashboard von dir testen (danke schon mal im Voraus dafür).
Dann werde ich sehen, ob es generell an der InfluxDB liegt oder nur am Influx Adapter vom iobroker. -
@SBorg
Erst einmal wieder ein großes Dankeschön fürs updaten des Wetterstations-Skripts, funktioniert soweit ohne Probleme, auch die Abfrage der Werte per Influx läuftDann generell:
Ich habe jetzt nochmal ein paar Tests zur Performance der InfluxDB V2 durchgeführt.- Auf der Influx DB Web UI habe ich im Data Explorer mal 60 Measurements markiert, die letzten 30 Tage abgefragt und das Ergebnis als Simple Table angezeigt. Der Query hat 0,1 Sekunden gedauert
- Ich habe das neue Grafana Dashboard importiert, das hat etwas gedauert, weil erstens die Änderung der Variablen bei mir nichts bewirkt hat (habs dann vorm Import in der json angepasst) und dann standen bei vielen Queries noch nicht die Variablen drin, was dann mit einem Suchen/Ersetzen in der json Datei erledigt wurde
 . Auf jeden Fall läd das neue Dashboard, das die Daten über die neue Data Source per Flux Sprache und Token abfragt, auch sehr schnell.
. Auf jeden Fall läd das neue Dashboard, das die Daten über die neue Data Source per Flux Sprache und Token abfragt, auch sehr schnell.
Es sieht also tatsächlich so aus, dass nur der Influx Adapter im iobroker beim Auslesen größerer Datenmengen zumindest bei mir Probleme macht.
Falls jemand mal Lust hat, bitte folgendes Script im iobroker anlegen, ggf. Influx Instanz / Bucket Namen anpassen und ausführen:sendTo('influxdb.0', 'query', 'from(bucket: "iobroker") |> range(start: -24h)', function (result) { if (result.error) { console.error(result.error); } else { // show result //console.log('Rows: ' + JSON.stringify(result)); console.log('fertig'); } });Das Skript fragt einfach mal die Werte aller Measurements der letzten 24 Stunden ab.
Danach mal ins iobroker Protokoll gehen und checken wie viel Zeit zwischen dem Skriptstart und der "fertig" Meldung vergangen ist. Bei mir hat das ca. 35 Sekunden gedauert
Natürlich ist es schwierig das zu vergleichen, weil das sehr davon abhängt wie viele Measurements man hat und wie viele Werte darin gespeichert sind. Ich habe aktuell um die 150 Measurements in der DB.
Eine Tendenz sollte aber trotzdem sichtbar sein und es würde mich interessieren, ob nur ich ein Problem damit habe oder ob das generell am Adapter liegt.
Danke schon mal im Voraus.Mir ist das Ganze auch nur aufgefallen, weil ich auch den ECharts Adapter zum Anzeigen von Graphen nutze und der zieht die Daten eben aus der Historie über den Influx Adapter des iobrokers.
Das Laden der Graphen dauert im V2 Modus des Influx Adapters nun deutlich länger als im V1 Modus (Ich kann noch den V1 Modus nutzen, weil ich die User aus v1 mit migriert habe, die dann weiterhin per Basic Auth und InfluxQL abfragen können). Ich habe mehrmals zwischen beiden Modi gewechselt und es ist reproduzierbar.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
372
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge