

[Umfrage] Hochverfügbarer ioBroker auf RPIs
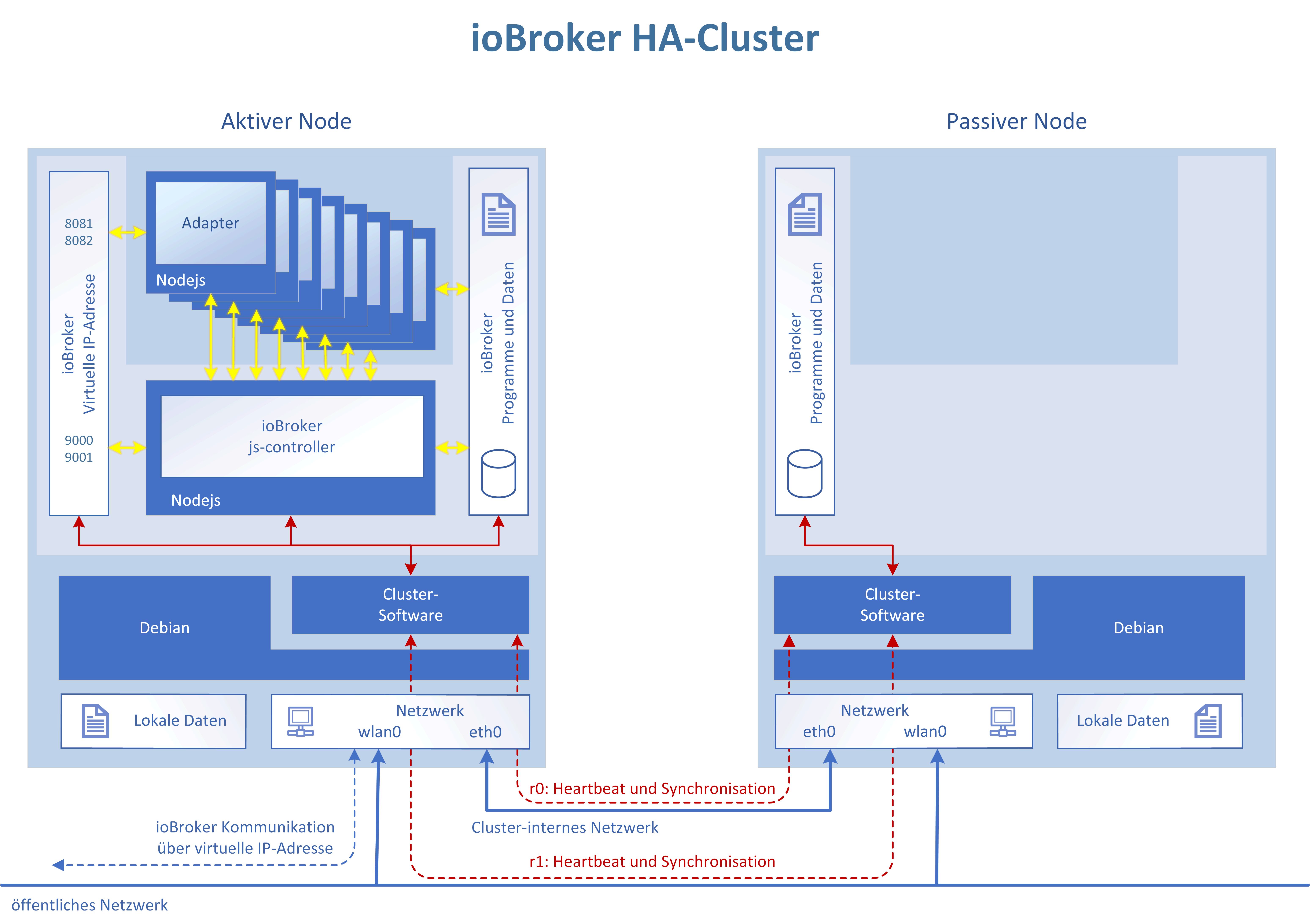
-
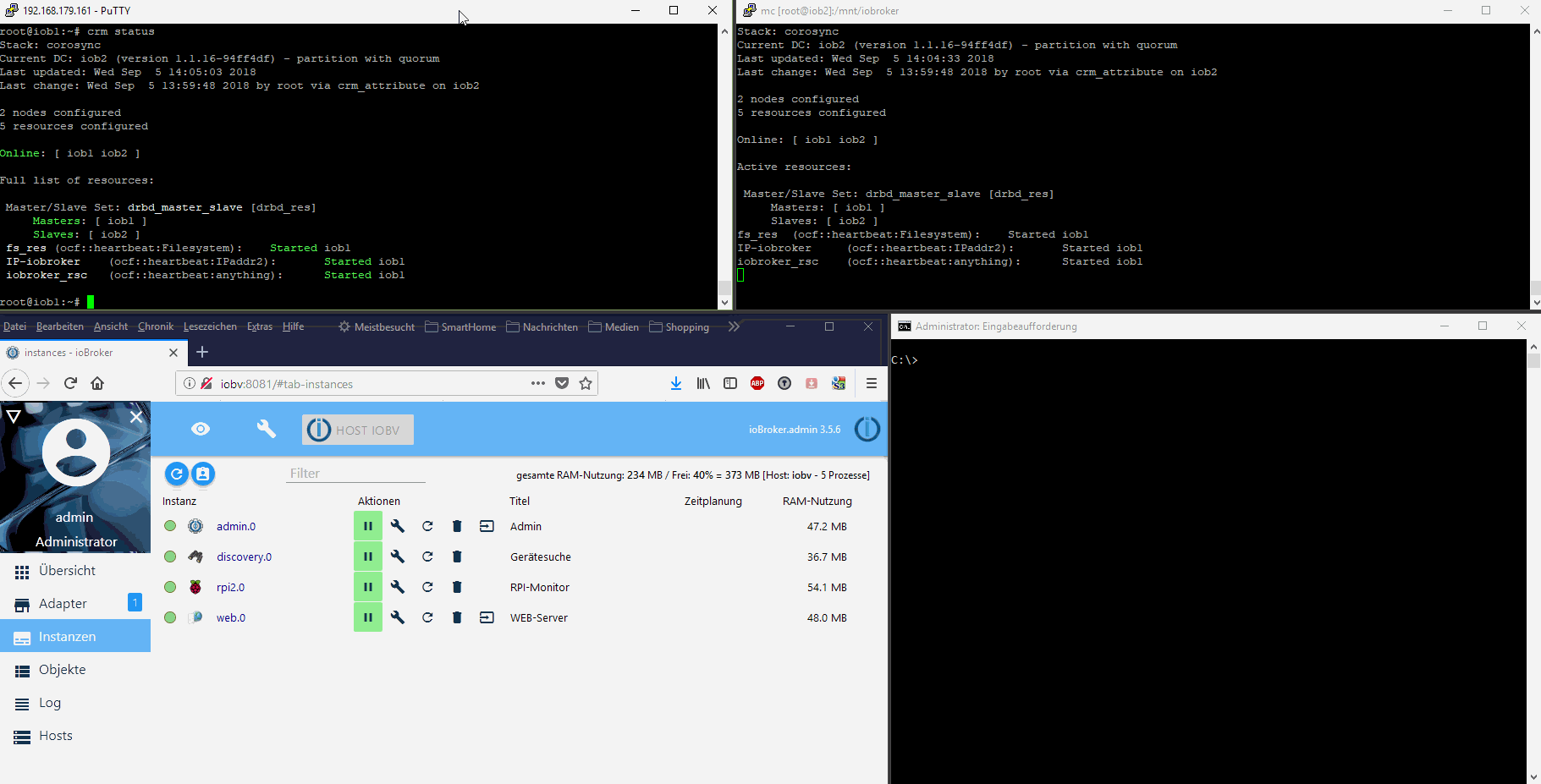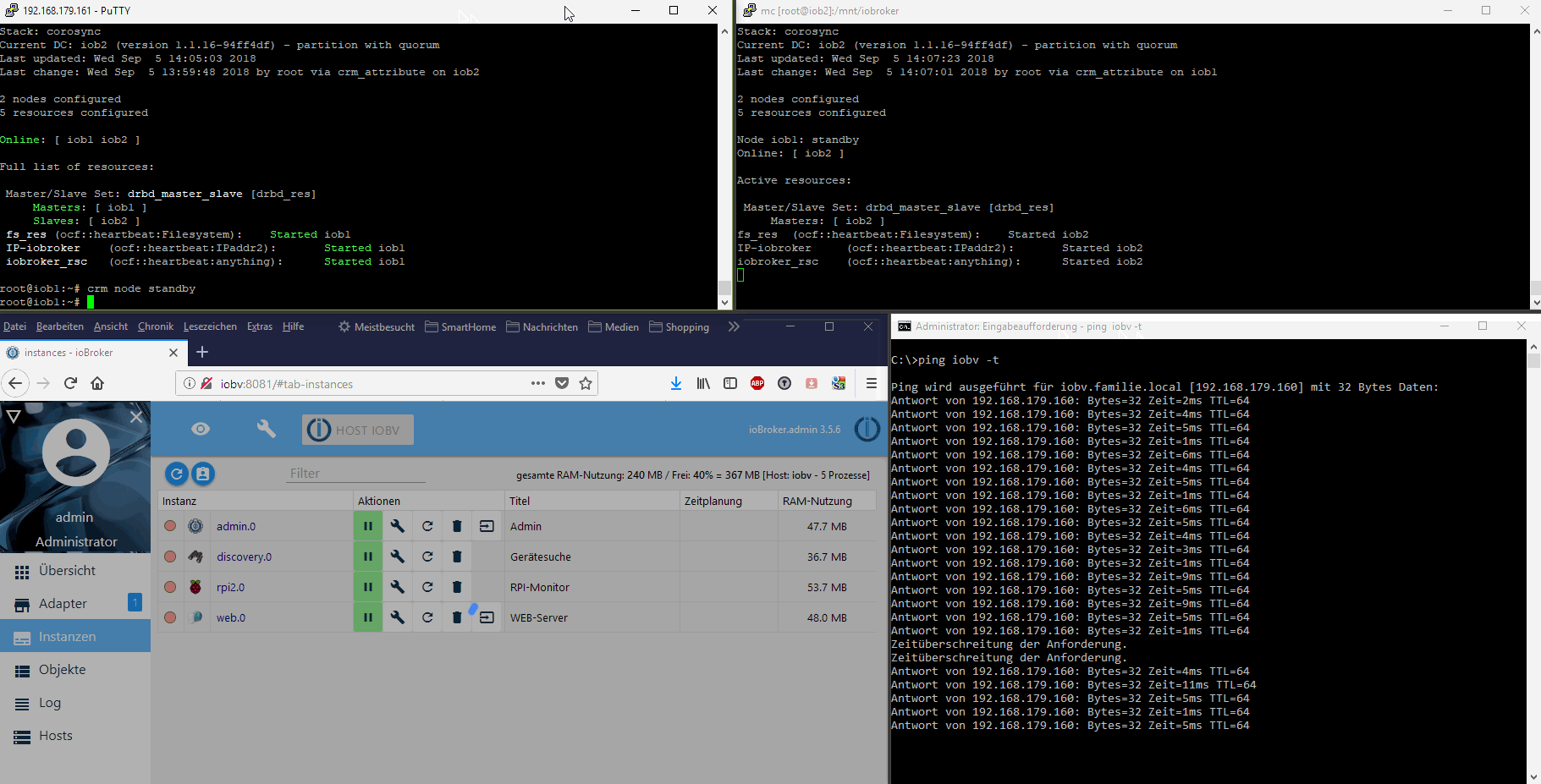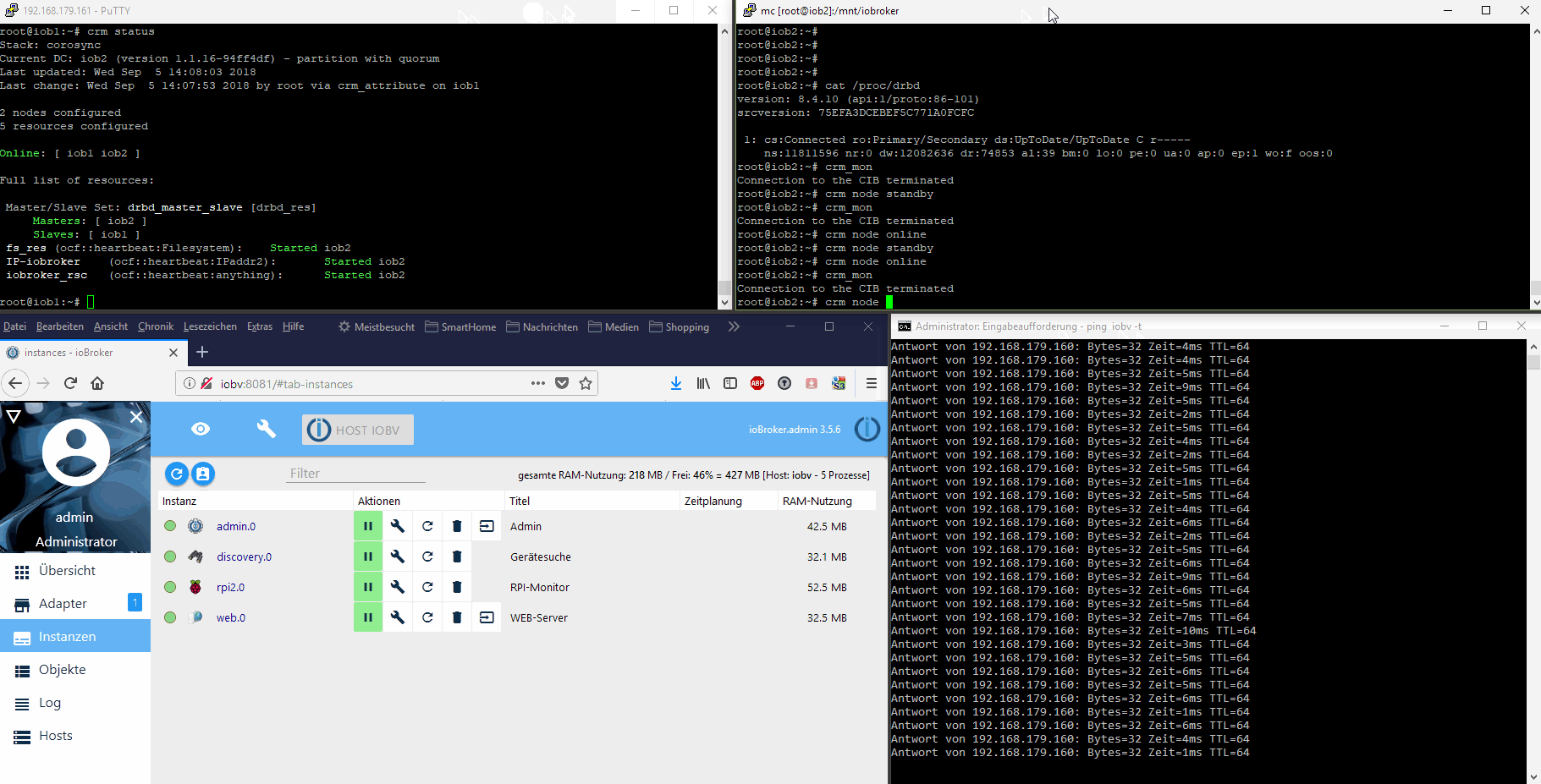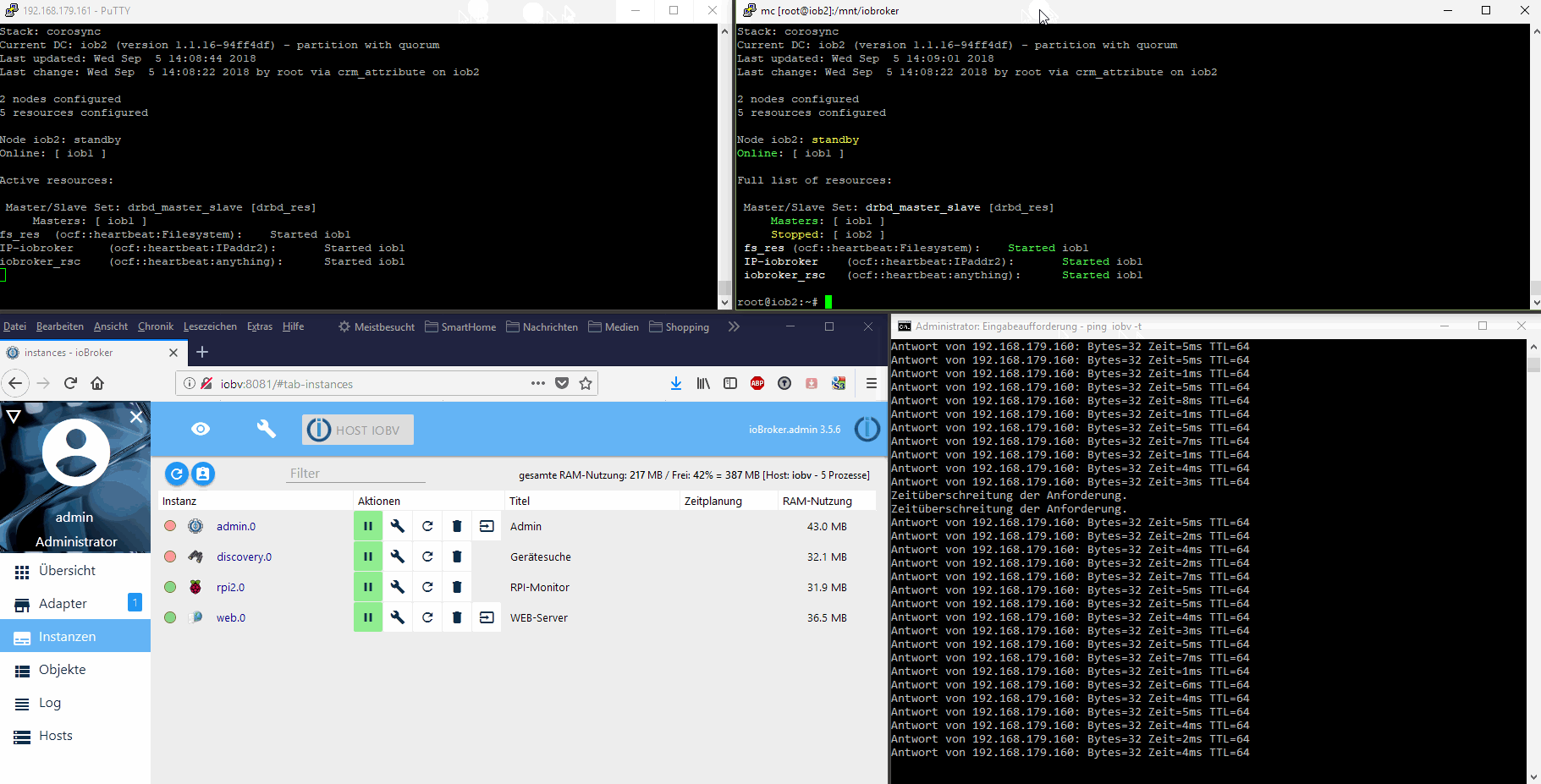
Was für ein Aufriss.
Ich hab es auch "ausfallsicher" und es hat nichts gekostet.
Bei mir liegt der Ordner /opt/iobroker auf einem RAID Netzwerk-Share und wird von dort gestartet. Wenn Raspberry1 3 mal binnen 30 Sekunden nicht auf einen Ping reagiert, wird der zweite Raspberry gestartet und greift auf das gleiche Netzwerkshare zu.
Das ist zwar nicht "hochverfügbar" reicht mir aber aus. Einem Privatanwender wird kaum auffallen, dass der Raspberry 2 minuten weg war. Es sei denn, man löst genau in dem Moment ein Kommando aus. Aber da reicht mir simple Wahrscheinlichkeitsrechnung.
-
1. Raspberry 2 hat eine andere ip-Adresse als raspberry 1, oder? Was machst Du, wenn die Schalter ihre Infos beim ioBroker abliefern?
2. Wie verhindert Du, dass beide Raspberries gleichzeitig laufen (Ein kurzzeitiger Netzwerkausfal kann durchaus passieren?)
3. Zentraler Point of Failure: Netzwerk Share.
-
@ramses: Der "Aufriss" genau aus dem Grund um "Split Brain" zu vermeiden und mal als "Proof-of-concept" zu zeigen wie es gehen könnte.
Bei echtem "HA" ist immer das Problem das eigentlich zwei Server nicht reichen - da ist der DRBD Ansatz fast der einzige der so geht. Ansonsten brauchst Du formal mindestens 3 Rechner die über Quorum entscheiden können ob ein problem vorliegt oder nicht.
Aber ja, wenn es für Deine zwecke reicht ist doch super
Ich persönlich habe einen 4er NUC Proxmox HA-Cluster mit verteiltem Dateisystem auf den 4 Nodes und alles als VMs mit HW-Watchdogs und Autp-Failover (aber das ist nicht ganz die Raspi-Liga) :-)
-
@ramses: Der "Aufriss" genau aus dem Grund um "Split Brain" zu vermeiden und mal als "Proof-of-concept" zu zeigen wie es gehen könnte.
Bei echtem "HA" ist immer das Problem das eigentlich zwei Server nicht reichen - da ist der DRBD Ansatz fast der einzige der so geht. Ansonsten brauchst Du formal mindestens 3 Rechner die über Quorum entscheiden können ob ein problem vorliegt oder nicht.
Aber ja, wenn es für Deine zwecke reicht ist doch super
Ich persönlich habe einen 4er NUC Proxmox HA-Cluster mit verteiltem Dateisystem auf den 4 Nodes und alles als VMs mit HW-Watchdogs und Autp-Failover (aber das ist nicht ganz die Raspi-Liga) :-) ` Wow das Ist echt nicht schlecht. Darf ich wissen weshalb solche Ansprüche bestehen für HA oder machst du es weil du das kannst?
Gesendet von meinem ONEPLUS A6013 mit Tapatalk
-
Ich persönlich habe einen 4er NUC Proxmox HA-Cluster mit verteiltem Dateisystem auf den 4 Nodes und alles als VMs mit HW-Watchdogs und Autp-Failover (aber das ist nicht ganz die Raspi-Liga) :-)
Wow das Ist echt nicht schlecht. Darf ich wissen weshalb solche Ansprüche bestehen für HA oder machst du es weil du das kannst?Bei mir ist ioBroker inzwischen recht tief integriert. Es geht zwar das meiste immer auch noch ohne, aber es wäre durchaus blöd. Auch die Gartenberegnung, Rasenmäher, Heizungsthermostatsteuerung und Tür-Steuerung und so ist aber inzwischen dabei. Wenn es weg ist sterbe ich zwar nicht, aber es fehlt viel Komfort.
Mein eigener Anspruch ist aber wegen der ganzen automatischen Funktionalität das es auch tun muss wenn ich nicht da bin (sei es Urlaub oder sei es Familie da und ich unterwegs oder so). Und damit war der weg zu VMs recht klar, auch wegen Snapshots bei Updates und all sowas. Und ja dann war auch ein bissl Spielerei dabei als ich dann mal 2 Nucs hatte und auch noch meine Dev-Umgebung virtualisieren wollte kam Nummer 3 … und aus Redundanzgründen Nummer 4 und dann ja auch ein bissl "weils halt geht". ;-)
-
Wie wäre es mit Kubernetes als Cluster.... Dabei ist es egal, was unten drunter liegt, z.b. Docker.
also ioBroker im Docker: https://github.com/nils/docker-ioBroker
als Hypervisor der Nodes ein Master, das deployment auf einem Pod (z.b. RasPI).Oder Docker im Swarm Mode..... nicht ganz so flexibel aber einfacher.
Falls keiner Docker nutzen möchte und eine normale Installation nutzen möchte, gibt es Pacemaker:
https://www.linuxhelp.com/how-to-configure-high-availability-linux-cluster-with-pacemaker-in-centoswas haltet ihr von den Varianten ?
-
Hat man lokale Storage? Ich denke das ist das Thema in dem Fall, oder ?
Aktuell werden immer noch lokale Files genutzt und selbst wenn mal bald alles per Redis wäre was States, Objekte und "uploaded Files" ist gibts immer noch einige Files drum herum ...
-
Was spricht gegen lokale Storages ?
Auf jedem Storage ist von einem anderen ein Teil oder ganzes vorhanden einer anderen Node. Somit verhält es sich wie SAN-Multicluster. Wozu also ein dedizierter Storage, der dann wieder redundant sein muss ?Beispiel Pacemaker mit Corosync als Cluster - Engine:
Die Corosync Cluster Engine besteht im Aufbau aus vier Kernkomponenten:
Einer zwischen den einzelnen Nodes verteilten Zustandsmaschine deren Zustände und gespeicherte Information virtuell synchronisiert ist.
Einer Instanz zum Starten, Stoppen und Verteilen von den jeweiligen Anwendungen auf die einzelnen Nodes.
Einem Quorum, das über die Anzahl der verfügbaren Nodes im Verbund informiert und dazu dient, bei Teilausfällen die Datenintegrität im Cluster sicherzustellen.
Einer Datenbank zum Sammeln von Zustandsinformationen und deren zeitlichen Verlauf und Konfigurationseinstellung des Clusters. Inhalte dieser Datenbank können bei entsprechender Auswertung beispielsweise Auskunft über verschiedene Betriebsparameter wie die Ausfallzeiten einzelner Nodes liefern.
MIninal braucht man hier gerade mal 2 Maschinen.Bei Docker Swarm , kommt es auf die Konfiguration an, die du selber bestimmst, ob auf allen nodes für deinen Service die Daten liegen , oder ob du eine bestimmte Anzahl von Replicas über deinen Cluster haben möchtest. Ebenso wieviele Worker-Nodes und wieviele Master Nodes du haben möchtest. Eine ungerade Anzahl an Master nodes ist als quorum erforderlich. Man kann eine Master-Node auch gleichzeitig als Worker-Node betreiben . Also minimal sollten es somit 2 Maschinen sein, jedoch ist einer davon gleichzeitig der Master und somit die redundanz nur n. Somit ist eine Redundanz erst mit 3 Maschinen , sowohl Master als auch Worker , mit n+1 möglich.
Bei Kubernetes spricht man von Persistent Volumes (PVs) und Persistent Volume Claims (PVCs) die aus StorageClasses (SC) einzelner Nodes mit einem bind zusammengeführt werden, und so mit einer gewissen Redundanz und Kapazität über dem Cluster (Pod) verteilt sind. Somit ist es sehr flexibel den bedürfnissen anpassbar. Auch hier braucht man minimum 3 Maschinen , damit auch die Konfiguration (etcd) redundant ausgelegt ist und ein quorum entstehen kann. Kubernetes ist hier nur über dem Docker , somit als manager und provider , aber bietet diverse vorteile, entsprechend mehr komplexität als docker swarm.
Mesos lasse ich mal lieber weg, denn das wird zu groß für unser Ziel.....(ab 9 Maschinen , wenn ich es richtig interpretiert habe)
-
Was spricht gegen lokale Storages ?
Auf jedem Storage ist von einem anderen ein Teil oder ganzes vorhanden einer anderen Node. Somit verhält es sich wie SAN-Multicluster. Wozu also ein dedizierter Storage, der dann wieder redundant sein muss ?Beispiel Pacemaker mit Corosync als Cluster - Engine:
Die Corosync Cluster Engine besteht im Aufbau aus vier Kernkomponenten:
Einer zwischen den einzelnen Nodes verteilten Zustandsmaschine deren Zustände und gespeicherte Information virtuell synchronisiert ist.
Einer Instanz zum Starten, Stoppen und Verteilen von den jeweiligen Anwendungen auf die einzelnen Nodes.
Einem Quorum, das über die Anzahl der verfügbaren Nodes im Verbund informiert und dazu dient, bei Teilausfällen die Datenintegrität im Cluster sicherzustellen.
Einer Datenbank zum Sammeln von Zustandsinformationen und deren zeitlichen Verlauf und Konfigurationseinstellung des Clusters. Inhalte dieser Datenbank können bei entsprechender Auswertung beispielsweise Auskunft über verschiedene Betriebsparameter wie die Ausfallzeiten einzelner Nodes liefern.
MIninal braucht man hier gerade mal 2 Maschinen.Bei Docker Swarm , kommt es auf die Konfiguration an, die du selber bestimmst, ob auf allen nodes für deinen Service die Daten liegen , oder ob du eine bestimmte Anzahl von Replicas über deinen Cluster haben möchtest. Ebenso wieviele Worker-Nodes und wieviele Master Nodes du haben möchtest. Eine ungerade Anzahl an Master nodes ist als quorum erforderlich. Man kann eine Master-Node auch gleichzeitig als Worker-Node betreiben . Also minimal sollten es somit 2 Maschinen sein, jedoch ist einer davon gleichzeitig der Master und somit die redundanz nur n. Somit ist eine Redundanz erst mit 3 Maschinen , sowohl Master als auch Worker , mit n+1 möglich.
Bei Kubernetes spricht man von Persistent Volumes (PVs) und Persistent Volume Claims (PVCs) die aus StorageClasses (SC) einzelner Nodes mit einem bind zusammengeführt werden, und so mit einer gewissen Redundanz und Kapazität über dem Cluster (Pod) verteilt sind. Somit ist es sehr flexibel den bedürfnissen anpassbar. Auch hier braucht man minimum 3 Maschinen , damit auch die Konfiguration (etcd) redundant ausgelegt ist und ein quorum entstehen kann. Kubernetes ist hier nur über dem Docker , somit als manager und provider , aber bietet diverse vorteile, entsprechend mehr komplexität als docker swarm.
Mesos lasse ich mal lieber weg, denn das wird zu groß für unser Ziel.....(ab 9 Maschinen , wenn ich es richtig interpretiert habe)
@MarkusDe sagte in [Umfrage] Hochverfügbarer ioBroker auf RPIs:
Was spricht gegen lokale Storages ?
Nichts. Und weil es am besten mit kostengünstigen Komponenten, die man ggf. in der Grabbelkiste hat, realisiert werden soll, habe ich das mit Raspberries und lokalem aber replizierten Storage gelöst.
-
Wie wäre es mit Kubernetes als Cluster.... Dabei ist es egal, was unten drunter liegt, z.b. Docker.
also ioBroker im Docker: https://github.com/nils/docker-ioBroker
als Hypervisor der Nodes ein Master, das deployment auf einem Pod (z.b. RasPI).Oder Docker im Swarm Mode..... nicht ganz so flexibel aber einfacher.
Falls keiner Docker nutzen möchte und eine normale Installation nutzen möchte, gibt es Pacemaker:
https://www.linuxhelp.com/how-to-configure-high-availability-linux-cluster-with-pacemaker-in-centoswas haltet ihr von den Varianten ?
Jupp, ich möchte gerne Centos ohne Compilierungsorgien auf einem Raspberry sehen. Habe ich inkl. Pacemaker durchexerziert und für mich wegen Komplexität abgehakt.
-
Sehr interessantes Thema, ähnliches hatte ich ja selber gerade hier angesprochen, wenn auch deutlich simpler.
Wenn iobroker die breite Masse weiter erreichen soll, dann kann ich euch sagen dass es eine simple Lösung sein sollte. Ich bin durchaus Technik und IT - interessiert, aber die Lösungsansätze die hier geschrieben sind halte ich für zu komplex für ein Großteil der Anwender.
Meine simple Lösungslogik ist:
2 Systeme nutzen:- io.broker auf Raspi oder Mini Windows Server.
- Homematic oder anderes Hardware System welches Aktoren bedient.
Ggenseitige Ausfallüberwachung:
-io.broker prüft die Homematic auf "aktivität" und bei Ausfall wird eine Homematic-unabhängige schaltbare Steckdose vom io.broker angesteuert, die die Homematic per Strom-Reset neustartet- Die Homematic macht selbiges umgekehrt für io.broker auf dem Raspi / Win Server
Im Schlimmsten Fall habe ich 5 Minuten Ausfallzeit, also die Überprüfungszeit und die Bootzeit der Systeme, aber dann läuft es weiter.
Wenn der ganze Raspi / Win Server / dessen Festplatte schrott ist, dann tauscht man entweder manuell oder hält sich tatsächlich ein komplett 2. System vor, welches dann per selbigen Prinzip gestartet wird. -
Naja, iobroker im Docker und dann Docker Swarm.... das dürfte fast jeder, der iobroker installieren kann auch hinbekommen.
Anleitung hier:
https://docs.docker.com/engine/swarm/swarm-tutorial/und dann als Service den iobroker installieren:
-
Hallo zusammen,
hier hat sich eine Weile nichts getan. Lebt das Thema noch?
Für mich ist das Thema Ausfallsicherheit/Verfügbarkeit aus leidvoller Erfahrung wichtig geworden.Ich hatte vor einigen Jahren mal den Ausfall der Zentralheizung, weil der Zündtrafo gesponnen hat.
Es war glücklicherweise nicht so kalt, das die Leitungen eingefroren sind, aber als ich aus dem Urlaub wiederkam, war die Haustemperatur auf 5° C abgesunken und es hat 3 Tage gedauert, bis das Haus wieder angenehm durchgewärmt war.Das war der Auslöser mir Gedanken über das Thema Ausfallsicherheit im privaten Bereich zu machen.
Alles ausfallsicher zu gestalten ist zu teuer bis unmöglich. Schliesslich gilt dafür immer noch: 2n+1 Instanzen müssen existieren, damit davon n Instanzen ausfallen dürfen.
Also braucht es clevere Ideen, um ein Maximum an Sicherheit zu bekommen. Das Zauberwort heißt dabei Ausfalltoleranz.Der Beitrag Nr 24 von Karl_999 zeigt die grundsätzliche Konzeption einer solchen Lösung auf:
- Zuverlässige Benachrichtigung, wenn etwas nicht stimmt (oder nicht stimmen könnte)
- Kritische Komponenten ausfallsicher (wenn bezahlbar)
- Wichtige Komponenten standby Ersatz (wenn bezahlbar)
- Jede Komponente muss autark arbeiten wenn die übergeordnete Instanz ausfällt
Beim ersten Punkt kommt bei mir der Bedarf an einem HA-IoBroker-Server auf und einem leistungsfähigen Monitoring innerhalb des IoBroker.
Für letzteres entwickle ich gerade einen Adapter (https://forum.iobroker.net/topic/22026/neuer-adapter-iobroker-moma bzw. https://github.com/AWhiteKnight/ioBroker.moma).Meine HA-Lösung des Servers plane ich auf Basis von einem Docker-Swarm mit 3 Knoten im Swarm-Mode.
Docker hat laut Doku die Thematik der "Hochverfügbarkeit" bei der Swarm-Implementierung ermöglicht.
Also warum das Rad nochmal erfinden?
Hardwarebasis werden SBC der Raspi-Klasse sein. Ich habe ein paar Odroid C2 in der Bastelkiste, die haben mehr RAM as ein Raspi und arbeiten mit EMMC + SD-Karte.
Docker läuft auch drauf, Anleitung: https://magazine.odroid.com/article/odroid-c2-docker-swarm/.
Als Betriebssystem habe ich Armbian genommen, das ist beim Kernel aktueller als das Ubuntu von Hardkernel.
Ein Docker-Swarm läuft bei mir, aktuell nur mit einem Manager/Master, auf jedem Rechner läuft direkt auf dem Armbian auch schon eine IoBroker Instanz. Portainer läuft auf dem Swarm als grafisches Verwaltungstool, soll aber optional bleiben.Aktuelle To Dos:
- Verteiltes Dateisystem, damit alle Docker-Instanzen die gleichen Container nutzen können
- Monitoring um Docker erweitern (von aussen und innen)
- Einen IoBroker-Container mit IoBroker als Multihost-Server für arm64 erstellen
- Multi-Manager-Docker-Swarm aus 3 SBC mit Mini-USV zusammenstellen.
Bevor jemand fragt. Ich habe jetzt 3 weitgehend unabhängige Heizsysteme zu Hause:
- die bisherige Zentralheizung
- einen wasserführenden Kachelofen
- Solarthermie auf dem (Garagen)Dach
Die Stromversorgung erfolgt über Photovoltaik und inselfähigem Hauskraftwerk im netzparallelen Betrieb.
Ein paar kleine USV für Steuerungsrechner, NAS etc. gibt es auch schon.Ausfallstolerante Grüße
-
Hi,
interessanter Ansatz generell. Ich bin mir nur nicht sicher ob (vor allem auf Deine Todos blickend) das wirklich auch einfach für viele Leute nutzbar wäre. Vor allem verteilte Dateisystem sind seeehr komplex (wei ssich aus Erfahrung, habe gluster am laufen und drbd kenn ich auch). Und das ist ggf ein Grund "das Rad neu zu erfinden". Wenn man die nötige Ahnung hat ist das alles machbar, aber ohne?
Ich persönlich wäre da generell bei dem folgenden Grundansatz:
- State- und Objects-DBs werden auf alle Nodes repliziert, damit ist überall alles da und man braucht kein verteiltes Dateisystem. DIe InMem-DBs bekommen also Replikations-Support. Alternativ nutzt man Redis. Ab js-controller 2.0 geht das auch mit Objekten.
- Man implementiere einen an Redis-Sentinel angelehnten Quorum Dienst der als Teil des js-controllers läuft und aus mehreren Nodes einen Master bestimmt und auch Neu-Abstimmungen. Alternativ geht ggf auch der echte Redis-Sentinel (geht weil ab js-controller 2.0 das Haupt-InMem-DB Protokoll auch auf Redis basiert auch wenn es kein Redis ist). Vorteil von etwas eigenem: Man kann auch Strategien für "2 Node Szenarien" mit weiteren Quorum-Optionen wir FileShare-Witness oder so einbauen was Redis-Sentinel nicht erlaubt.
- Dazu dann noch ein "HA-Manager" im ioBroker als Adapter oder ioBroker-Core-Teil der nach bestimmten Regeln die Instanzen auf andere Hosts schiebt und neu startet. Die ganze Basis dafür existiert schon inkl. dynamischem npm-install und so. Die Verteilstrategien und so werden interessant.
Was denkst Du zu so einem Ansatz? Die Redis-Protokoll-Implementierung für States und Objekte habe ich in den letzten Wochen gemacht und ist im jsmcontroller 2.0 (GitHub Master) schon fast fertig drin. Wir planen hier gerade Performancetests.
Dann sehen wir weiterAm Ende kann man die einzelnen Nodes immer noch auf Docker, Raspis, echter HW VMs oder sonst wie laufen lassen, Das geht alles flexibel.
-
Hallo apollon77,
ich bin bisher davon ausgegangen, das ioBroker keine HA-Implementierung hat und macht. Mit den für mich neuen Informationen sieht die Welt anders aus.
Der Ansatz ist natürlich besser und zu bevorzugen.Dann warte ich mal auf Version 2.0 des js-controller und sehe dann weiter.
Punkt 2 der Liste und von 4 die Mini-USV bleiben zum Werkeln bestehen.
3 Odroid C2 liegen noch in der Bastelkiste.
Der Docker-Swarm kriegt dann andere Aufgaben :-) -
Hi,
naja, das ganze Thema ist eine Größere Nummer und aktuell nur eine Idee in meinem Kopf. Der Plan von Socket.io weg zu gehen zu einem "schlankeren "Protokoll ist auch schon länger da und hat erst einmal nichts direkt mit HA zu tun ... mir ist nur bei der Umsetzung klar geworden das diese neue Basis durchaus Grundlage für weitere Dinge sein könnte.
Beim HM-Usertreffen wo sich auch viele ioBroker-User treffen ist in Gesprächen auch klar geworden das hier verschiedenste Theman existieren die User gern wollen. Angefangen bei fklexibler "Skalierung" der Adapter, über einfache Fallback-Systeme mit zwei Nodes (denke da kommen die meisten User her) bis hinzu "echter selbstheilender" HA wo wieder egal ist wo der Master ist ... und alles einfach verständlich und nicht zu kompliziert :-)
Naja mal schauen ... Und so oder so ist das ganze zu bauen noch ein weiter Weg.
-
Hallo zusammen,
hier hat sich eine Weile nichts getan. Lebt das Thema noch?
Für mich ist das Thema Ausfallsicherheit/Verfügbarkeit aus leidvoller Erfahrung wichtig geworden.Ich hatte vor einigen Jahren mal den Ausfall der Zentralheizung, weil der Zündtrafo gesponnen hat.
Es war glücklicherweise nicht so kalt, das die Leitungen eingefroren sind, aber als ich aus dem Urlaub wiederkam, war die Haustemperatur auf 5° C abgesunken und es hat 3 Tage gedauert, bis das Haus wieder angenehm durchgewärmt war.Das war der Auslöser mir Gedanken über das Thema Ausfallsicherheit im privaten Bereich zu machen.
Alles ausfallsicher zu gestalten ist zu teuer bis unmöglich. Schliesslich gilt dafür immer noch: 2n+1 Instanzen müssen existieren, damit davon n Instanzen ausfallen dürfen.
Also braucht es clevere Ideen, um ein Maximum an Sicherheit zu bekommen. Das Zauberwort heißt dabei Ausfalltoleranz.Der Beitrag Nr 24 von Karl_999 zeigt die grundsätzliche Konzeption einer solchen Lösung auf:
- Zuverlässige Benachrichtigung, wenn etwas nicht stimmt (oder nicht stimmen könnte)
- Kritische Komponenten ausfallsicher (wenn bezahlbar)
- Wichtige Komponenten standby Ersatz (wenn bezahlbar)
- Jede Komponente muss autark arbeiten wenn die übergeordnete Instanz ausfällt
Beim ersten Punkt kommt bei mir der Bedarf an einem HA-IoBroker-Server auf und einem leistungsfähigen Monitoring innerhalb des IoBroker.
Für letzteres entwickle ich gerade einen Adapter (https://forum.iobroker.net/topic/22026/neuer-adapter-iobroker-moma bzw. https://github.com/AWhiteKnight/ioBroker.moma).Meine HA-Lösung des Servers plane ich auf Basis von einem Docker-Swarm mit 3 Knoten im Swarm-Mode.
Docker hat laut Doku die Thematik der "Hochverfügbarkeit" bei der Swarm-Implementierung ermöglicht.
Also warum das Rad nochmal erfinden?
Hardwarebasis werden SBC der Raspi-Klasse sein. Ich habe ein paar Odroid C2 in der Bastelkiste, die haben mehr RAM as ein Raspi und arbeiten mit EMMC + SD-Karte.
Docker läuft auch drauf, Anleitung: https://magazine.odroid.com/article/odroid-c2-docker-swarm/.
Als Betriebssystem habe ich Armbian genommen, das ist beim Kernel aktueller als das Ubuntu von Hardkernel.
Ein Docker-Swarm läuft bei mir, aktuell nur mit einem Manager/Master, auf jedem Rechner läuft direkt auf dem Armbian auch schon eine IoBroker Instanz. Portainer läuft auf dem Swarm als grafisches Verwaltungstool, soll aber optional bleiben.Aktuelle To Dos:
- Verteiltes Dateisystem, damit alle Docker-Instanzen die gleichen Container nutzen können
- Monitoring um Docker erweitern (von aussen und innen)
- Einen IoBroker-Container mit IoBroker als Multihost-Server für arm64 erstellen
- Multi-Manager-Docker-Swarm aus 3 SBC mit Mini-USV zusammenstellen.
Bevor jemand fragt. Ich habe jetzt 3 weitgehend unabhängige Heizsysteme zu Hause:
- die bisherige Zentralheizung
- einen wasserführenden Kachelofen
- Solarthermie auf dem (Garagen)Dach
Die Stromversorgung erfolgt über Photovoltaik und inselfähigem Hauskraftwerk im netzparallelen Betrieb.
Ein paar kleine USV für Steuerungsrechner, NAS etc. gibt es auch schon.Ausfallstolerante Grüße
@AWhiteKnight sagte in [Umfrage] Hochverfügbarer ioBroker auf RPIs:
3 SBC mit Mini-USV
Was nimmst Du denn für Mini-USV? Ich habe Intel Nucs und siche noch nach einer "mini-USV (19V am Ende oder halt 230V) die am Ende nur sicherstellt das der Shutdown sinnvoll verläuft ... Finde nur "Die großen"
-
Hallo apollon77,
ich bin bisher davon ausgegangen, das ioBroker keine HA-Implementierung hat und macht. Mit den für mich neuen Informationen sieht die Welt anders aus.
Der Ansatz ist natürlich besser und zu bevorzugen.Dann warte ich mal auf Version 2.0 des js-controller und sehe dann weiter.
Punkt 2 der Liste und von 4 die Mini-USV bleiben zum Werkeln bestehen.
3 Odroid C2 liegen noch in der Bastelkiste.
Der Docker-Swarm kriegt dann andere Aufgaben :-)Das mit den Mini-USV interessiert mich auch brennend, wegen Kabelmodem, Router/Switch und ein paar Raspis! Die Raspis mögen es garnicht wenn denen einfach der Strom abgewürgt wird.
Und für meinen HP Proliant, wo ioBroker drauf ist, suche ich auch noch eine passende USV... ich fahre im Moment auf Risiko

-
Also ich bin generell auf APC, hab ich zwei stück von einmal im Arbeitszimmer (Haupt-Router und Homemetaic CCU und 3 Nucs) und eine im Keller (NAS, weitere Nucs, PoE zu CCU Repeater). Einmal ne 550er kleine und ne 700er grosse APC Back UPS.
Die halten auch einiges aus und so gehen 15-60 Minuten problemlos. Kann ich generell empfehlen.
Habe jetzt aber noch einen Nuc woanders stehen und den würde ich gern sicher runterfahren können.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden430
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge