

[Umfrage] Hochverfügbarer ioBroker auf RPIs
-
Mir wurde gesagt, Feedback von 5% aller Leser zu erhalten, wäre ein außerordentlich gutes Ergebnis. [emoji26]
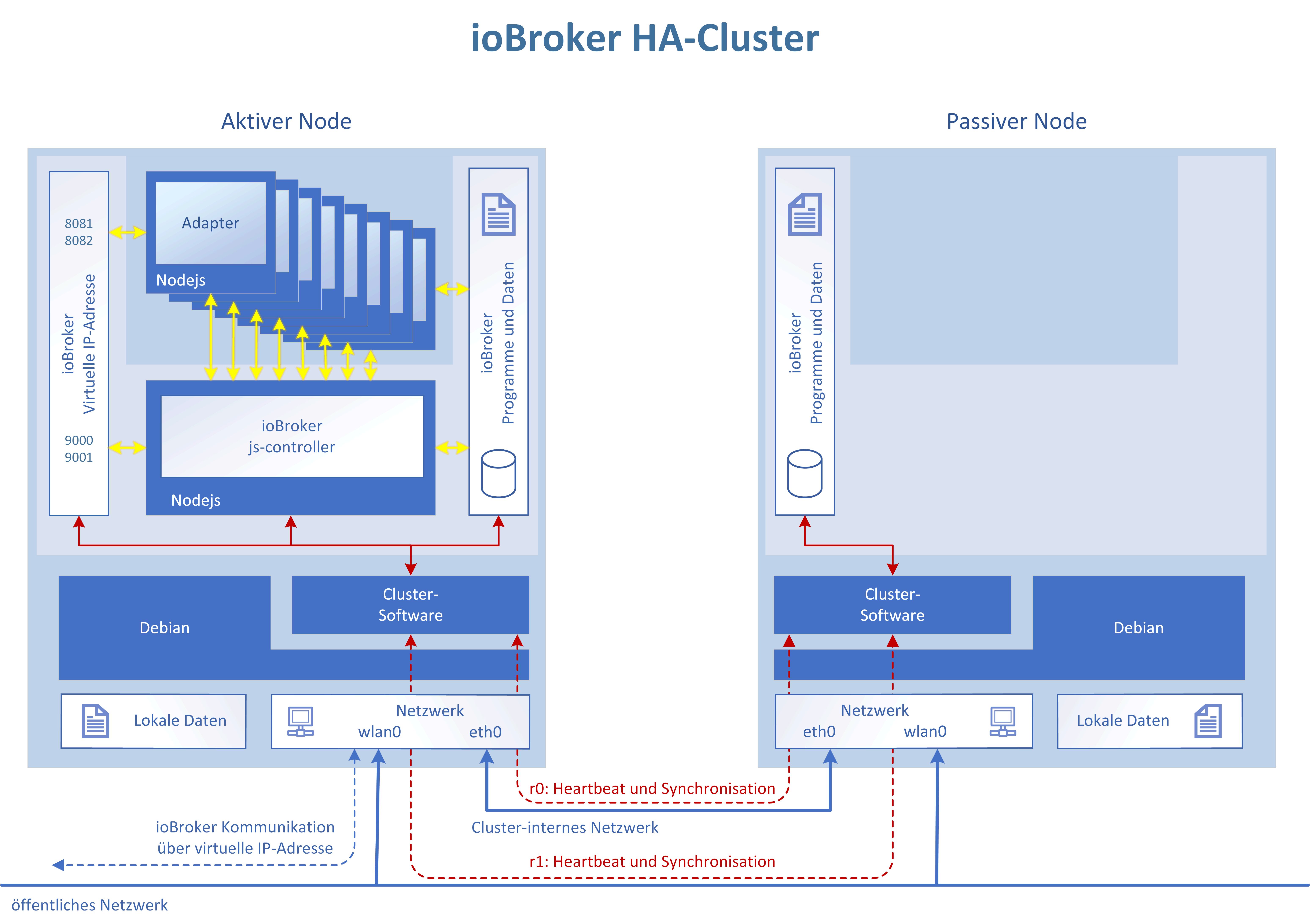
Es ist korrekt, man kann den ioBroker und seine Adapter auch wieder in Verfügbarkeitsklassen aufteilen.
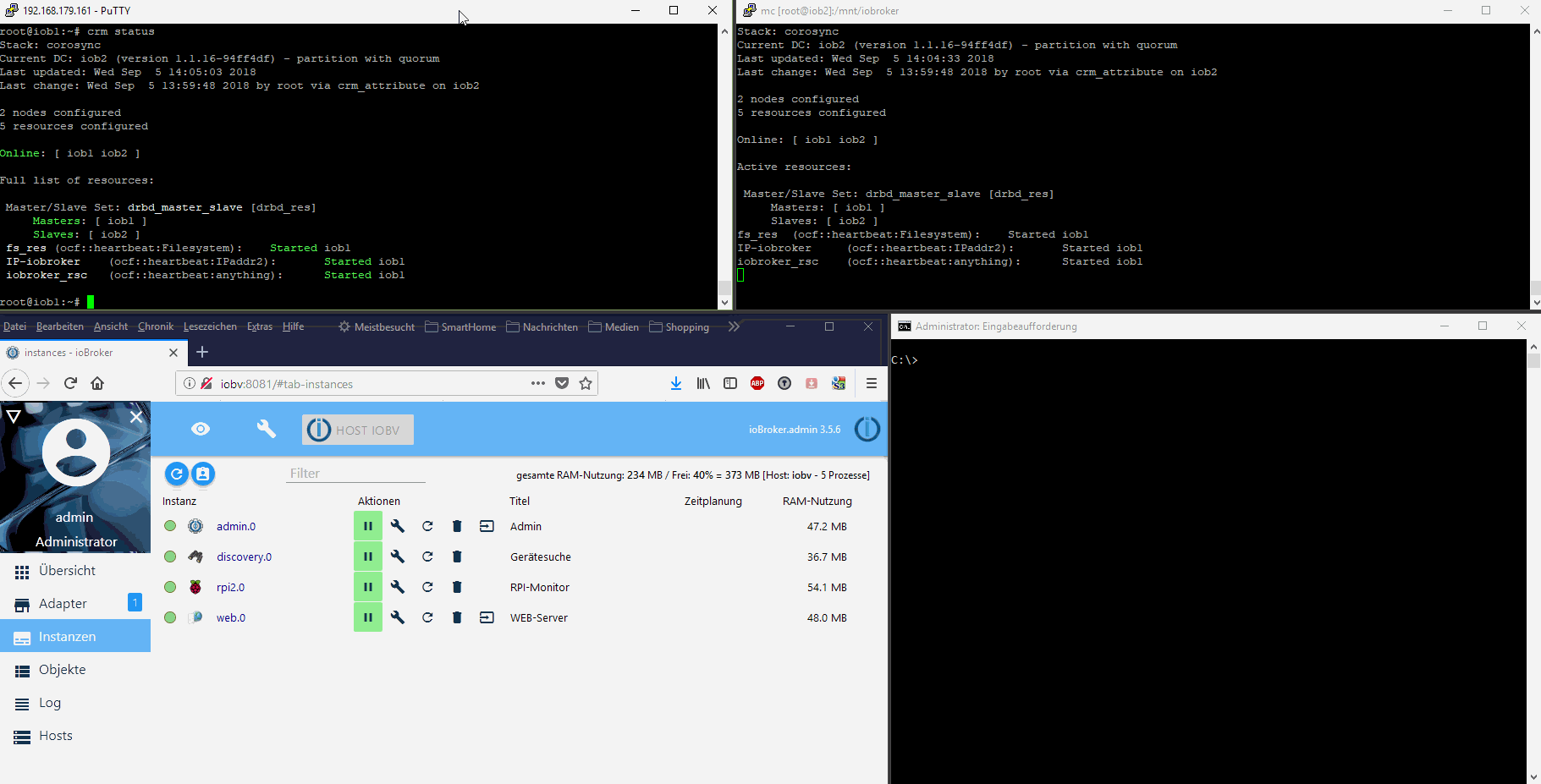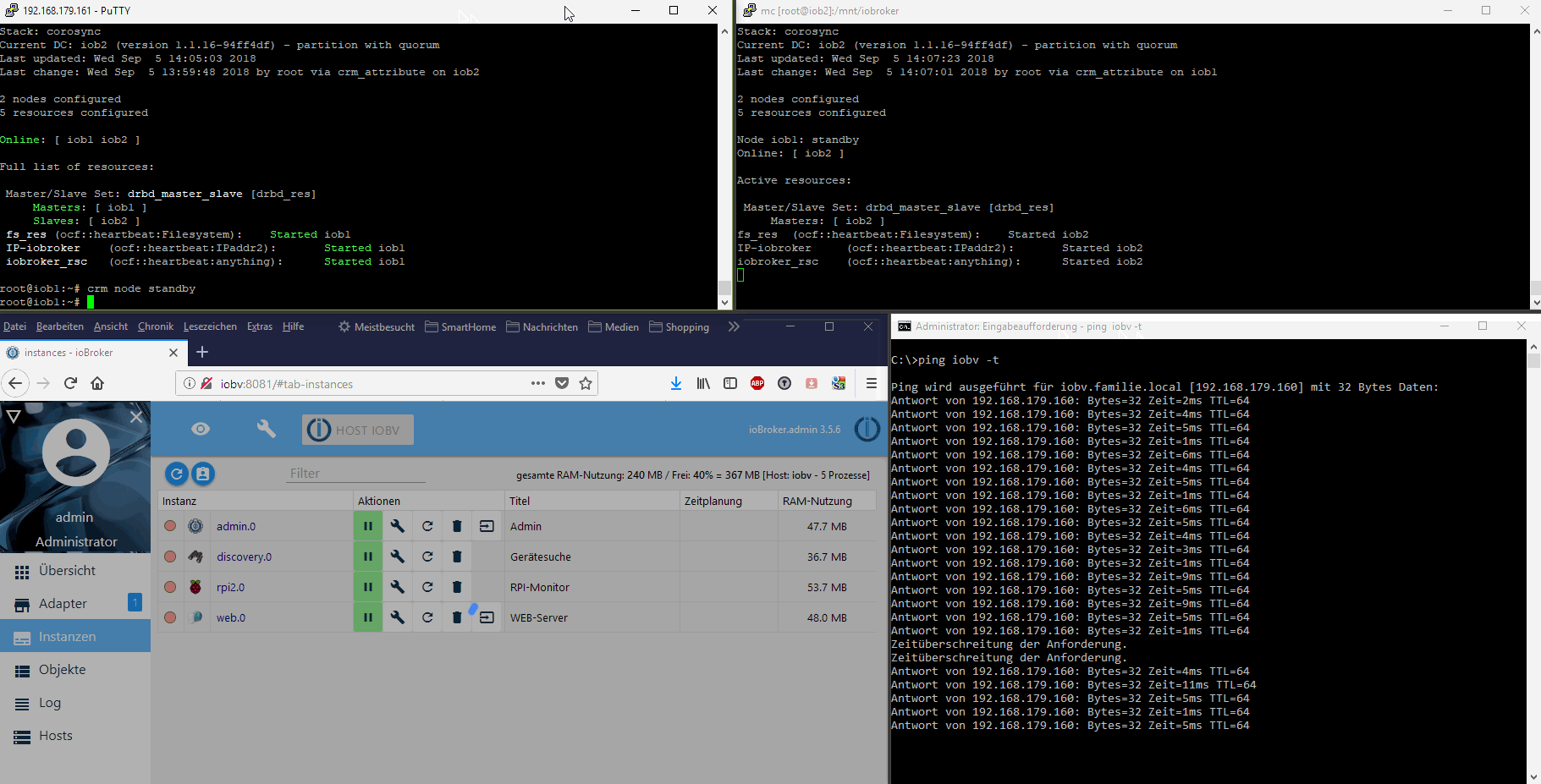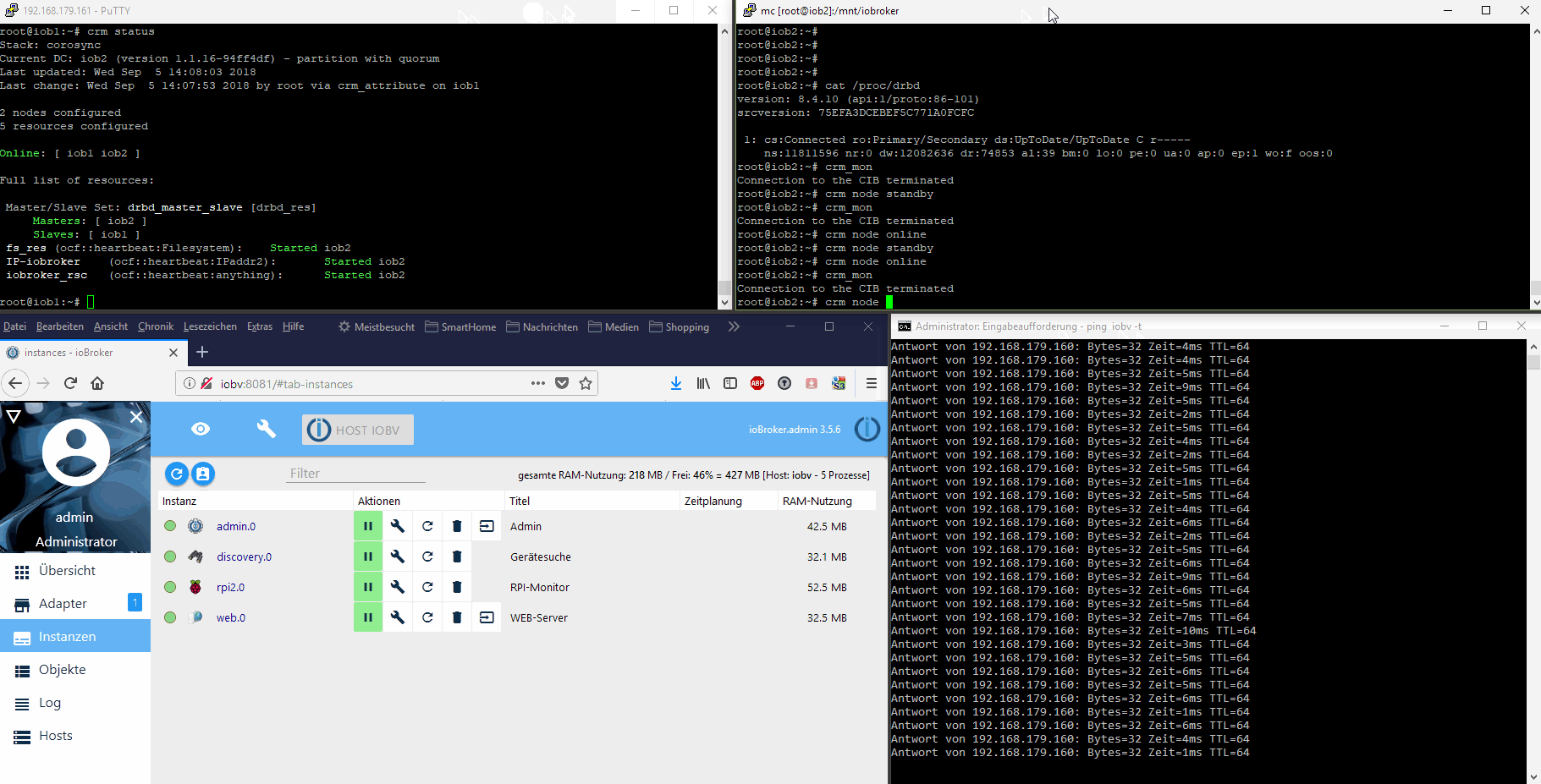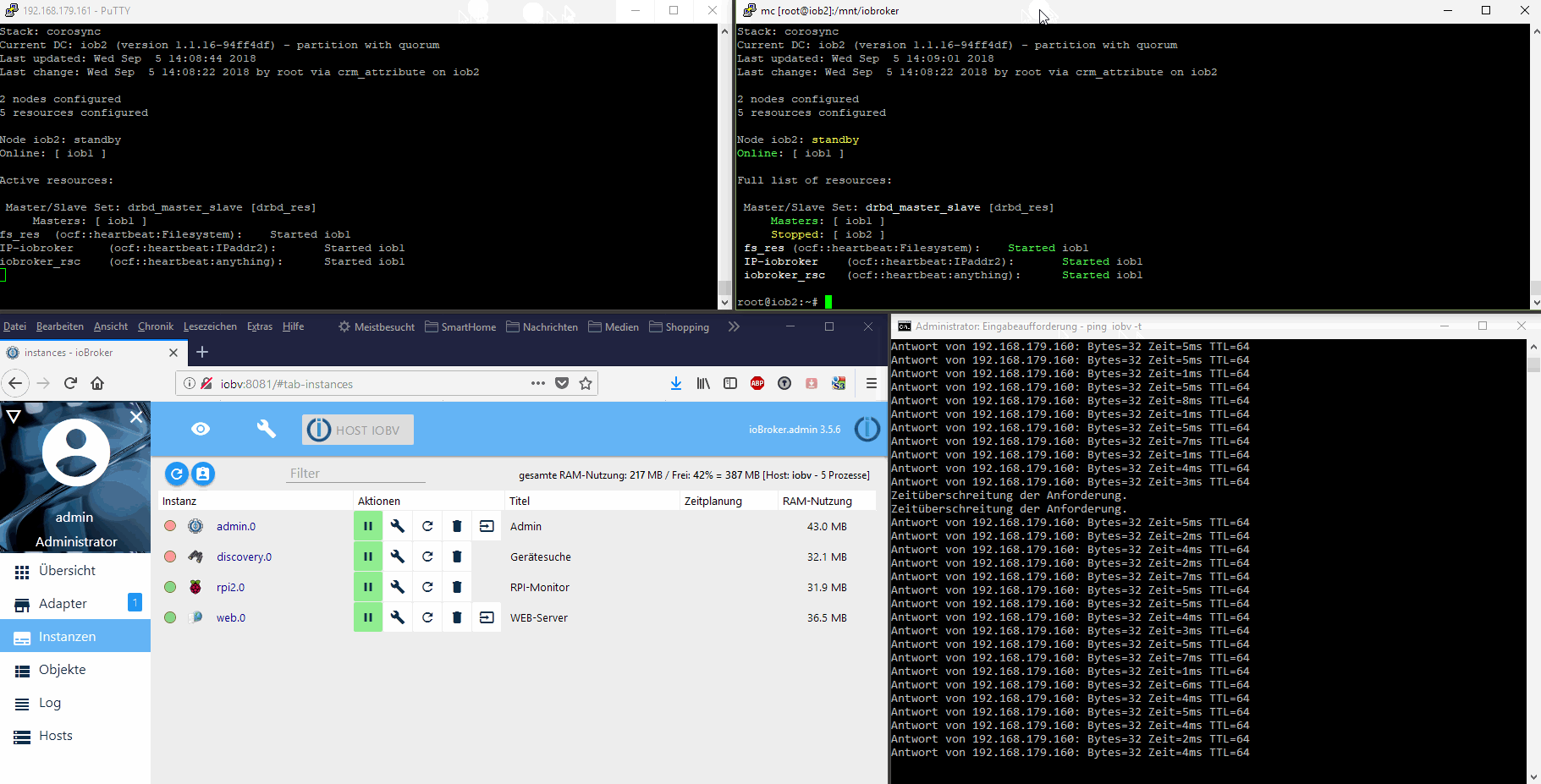
Das habe ich aber vorerst nicht vor. Ich wollte den im ioBroker integrierten Restartmechanismus der Adapter nutzen und direkt den Nodejs-Prozess, der den js-Controller mit seinen beiden Datenbanken bereitstellt, überwachen. Wenn der stirbt oder die Überwachungsprozesse fehlschlagen, dann ist ein Kriterium für einen Neustartversuch, bzw. wenn der fehlschlägt ein Kriterium für ein vollständiges Failover auf den Standby-Node gegeben.
Ein Failover ist dabei immer mit einem kurzfristigen Verbindungsverlust verbunden. Die in-Memory-Datenbanken von ioBroker werden ca. alle 30s auf den Datenträger gespeichert. Die Daten und ioBroker-Programmdateien sind auf beiden Cluster-Nodes immer gleich. Man verliert bei einem Fehler also Daten von max. 30s+Startzeit des ioBrokers+Adapter. Das sind letztendlich 1-2 Minuten. Danach läuft ioBroker weiter, als sei außer einem Restart nichts geschehen. Siehe Video oben im ersten Post.
-
Die in-Memory-Datenbanken von ioBroker werden ca. alle 30s auf den Datenträger gespeichert. `
Das trifft normal für die Zustände (states) bei Verwendung der Datei states.json zu (habe ich bei mir auf 10 Minuten erhöht). Redis speichert bei typischer Ereignisfrequenz alle 5 Minuten in eine Datei. Die statischen Objekte werden normalerweise viel seltener in objects.json gespeichert. -
Danke für den Hinweis. Ich werde mir die Konfigurationsoptionen und den Quelltext anschauen.
Redis ist erst einmal außen vor. Das hat eigene Hochverfügbarkeitsoptionen.
-
Ich habe im ersten Artikel eine Übersichtsbild der angedachten Lösung angefügt. DIe Umfage läuft noch kurze Zeit. Wer noch nicht abgestimmt hat, ist eingeladen das noch schnell nachzuholen. ;)
Ich würde mich freuen, wenn diejenigen, die direkt mitmachen wollen, mir eine kurze PN zukommen lassen würden.
Erstes Ziel wird es ein, die HW-Auswahl "festzuklopfen" und eine für alle nachvollziehbare Dokumentation zur Einrichtung einer Filesystemspiegelung (RAID 1 over LAN :D ) zu erstellen.
-
Ich hatte mir früher auch mal Gedanken gemacht, unter anderem war da der Gedanke, eine IObroker Instanz auf einem Webserver zu hosten und per Internet Verbindung zu synchronisieren, als Callback Leitung dann per Handynetz.
Da dann eine laufende, angreifbare Instanz außerhalb der Wohnung liegt, kommt das nicht in Frage.
Dann geht es weiter, theoretisch müßten alle Module z.B. Zwave doppelt vorhanden sein, aber Komponenten lassen sich nur an ein Gateway anbinden.
Für mich war also eines klar, alles wirklich alles, was wichtig ist, muß von Hand bedienbar sein, so das die Frau auch ohne mich klar kommt.
IOBroker läuft jetzt virtualisiert, mit regelmäßigen Snapshots und Backups auf NAS und Webcloud (verschlüsselt).
Fällt das System aus, bekomme ich es in kürzester Zeit wieder Online, liege ich im Krankenhaus, habe ich andere Sorgen als Kompfort.
Was aber nicht heißt, das ich an einem dauerhaft verfügbaren System kein Interesse hätte, wenn ich helfen kann, würde ich dies natürlich tun. Aber wie gesagt, ich sehe die Probleme nicht bei IOBroker an sich, sondern an den Modulen der Hersteller.
-
Wie verhält sich das mit den Modulen? Kann man das durch einfaches umstecken zwischen den Raspberries lösen? Z.B. alles über das Netzwerk geht automatisch, USB-Sticks aber manuell umstecken? Alternativen dazu? USB Device Server und dann per LAN? SPoF…
-
Bei einem USB Device Server hat man wieder eine Komponente die ausfallen kann. Backups ziehe ich zur Zeit von Hand. Wenn die Hardware ausfallen würde, neue kaufen, Proxmox drauf, Sticks einstecken, Container einspielen fertig.
Für meinen Teil habe ich festgestellt, es geht leider nicht ohne Handeingriff bei einem Ausfall der Hardware. Und genau da fängt dann der Punkt Frau an, nicht weil sie es nicht kann, sondern weil es sie nervt.
Für mich bedeutet höchste Verfügbarkeit mitlerweile nur noch, wie minimiere ich die Ausfallzeit.
To do Liste für mich:
-
Abgleich der SQL Historie mit einer SQL Datenbank auf meinem Webbspace
-
Spiegelung der Container anlegen, so das bei einem Software defekt der entsprechende Container über eine VPN Verbindung gestoppt und der Backup Container gestartet werden kann.
Was ich noch suche ist ein Script für den Webspace, das den Status des Systems abfragt und bei Ausfall, also z.B. Strom weg, Hardware Ausfall, einen Error wirft und dies per Pushover an mich weiterleitet.
-
-
So,
ich bin vor Tagen schon auf dieses Thema gestoßen und will nun auch mal mein Senf dazu abgeben. Ich würde von einer HOCHVERFÜGBARKEIT per Definition davon absehen. Das ist mit geringen, finanziellen Mitteln nicht machbar. "Ein System gilt als hochverfügbar, wenn eine Anwendung auch im Fehlerfall weiterhin verfügbar ist und ohne unmittelbaren menschlichen Eingriff weiter genutzt werden kann."
Eine Hochverfügbarkeit im Sinne der 'Verfügbarkeitsklassen' wären wir hier bei der VK5, VK6 oder VK7. Wozu das ganze? Das ganze hat eine Wahnsinnige Anforderung an alle Komponenten sowie dokumentierte und festgelegte Handlungen. Ich würde mir als Ziel maximal VK2 setzen (3,5 Tage Ausfallzeit im Jahr).
Hochverfügbarkeit erreicht man nicht über:
-
Festlegung auf einer Hardware (leider wird das 'schwierig' bei INTEL / ARM Mischumgebung)
-
Knausern bei USB / Serial / GPIO Geräten oder Spezialhardware. Sprich, das zWave Netwerk bräuchte auf jeden Fall zwei Sticks. Geht das - keine Ahnung. GPIO wird schon haariger.
-
Festlegung auf spezielle Produkte die eine Koexistenz von irgendwie geartete Netzwerke benötigt (Zigbee, zWave etc.) => Also Sensoren usw selber bauen die über WLAN und LAN arbeiten - denn das ist Hochverfügbar
-
Einfachen Hausmitteln ohne viel Zeit zu investieren.
Hochverfügbarkeit nur mal so im Anfang
=> Also geht es los: du brauchst 2 versch. Räume in unterschiedlichen Brandabschnitten
=> In jeden Raum müssen zwei versch. Stromkreise sein, Einspeisung von außen über zwei Wege.
=> Jeder Raum muss vollständig versorgt sein, USV, Switch, Patchfelder und Monitoring wie Rauchmelder, CO / Wassermelder bei Kellerebene
=> Wenn Cloud /Internet wichtig: dann untersch. Anbindung, sowohl vom Anbieter als auch von der Physik: (DSL über Kabel, DSL über LTE), der Hochverfügbarkeit wegen muss in jeden Raum einmal LTE und einmal DSL sein.
=> WLAN, Accesspoints aufgeteilt auf beide Serverräume. Sprich, mindestens 2, sonst 4, sonst 6
=> Dienste dürfen nicht hardwarebezogen sein, also müssen diese virtuell laufen -> Virtualisierungsschicht einplanen
=> Virtualisierung ist auch ein Stichwort: Netzwerk, Storage usw. müssen virtuell laufen
=> Storage fehlt auch, also 2x Ausfallsicheres SAN (NAS) inkl. Spiegelung untereinander, zum ablegen der virtuellen Maschine…
=> Backups nach dem Generationsprinzip: ab und zu können BUGs auch erst Wochen später auftreten.
=> Da fehlt noch einiges, müsste aber jetzt in mich gehen....
ALSO in Summe: Lieber ein vernünftigen Wideranlaufplan ausarbeiten - möglichst mit allen Aspekten und ein 'Cold-Standby'-System fahren.
-
-
Was für ein Aufriss.
Ich hab es auch "ausfallsicher" und es hat nichts gekostet.
Bei mir liegt der Ordner /opt/iobroker auf einem RAID Netzwerk-Share und wird von dort gestartet. Wenn Raspberry1 3 mal binnen 30 Sekunden nicht auf einen Ping reagiert, wird der zweite Raspberry gestartet und greift auf das gleiche Netzwerkshare zu.
Das ist zwar nicht "hochverfügbar" reicht mir aber aus. Einem Privatanwender wird kaum auffallen, dass der Raspberry 2 minuten weg war. Es sei denn, man löst genau in dem Moment ein Kommando aus. Aber da reicht mir simple Wahrscheinlichkeitsrechnung.
-
1. Raspberry 2 hat eine andere ip-Adresse als raspberry 1, oder? Was machst Du, wenn die Schalter ihre Infos beim ioBroker abliefern?
2. Wie verhindert Du, dass beide Raspberries gleichzeitig laufen (Ein kurzzeitiger Netzwerkausfal kann durchaus passieren?)
3. Zentraler Point of Failure: Netzwerk Share.
-
@ramses: Der "Aufriss" genau aus dem Grund um "Split Brain" zu vermeiden und mal als "Proof-of-concept" zu zeigen wie es gehen könnte.
Bei echtem "HA" ist immer das Problem das eigentlich zwei Server nicht reichen - da ist der DRBD Ansatz fast der einzige der so geht. Ansonsten brauchst Du formal mindestens 3 Rechner die über Quorum entscheiden können ob ein problem vorliegt oder nicht.
Aber ja, wenn es für Deine zwecke reicht ist doch super
Ich persönlich habe einen 4er NUC Proxmox HA-Cluster mit verteiltem Dateisystem auf den 4 Nodes und alles als VMs mit HW-Watchdogs und Autp-Failover (aber das ist nicht ganz die Raspi-Liga) :-)
-
@ramses: Der "Aufriss" genau aus dem Grund um "Split Brain" zu vermeiden und mal als "Proof-of-concept" zu zeigen wie es gehen könnte.
Bei echtem "HA" ist immer das Problem das eigentlich zwei Server nicht reichen - da ist der DRBD Ansatz fast der einzige der so geht. Ansonsten brauchst Du formal mindestens 3 Rechner die über Quorum entscheiden können ob ein problem vorliegt oder nicht.
Aber ja, wenn es für Deine zwecke reicht ist doch super
Ich persönlich habe einen 4er NUC Proxmox HA-Cluster mit verteiltem Dateisystem auf den 4 Nodes und alles als VMs mit HW-Watchdogs und Autp-Failover (aber das ist nicht ganz die Raspi-Liga) :-) ` Wow das Ist echt nicht schlecht. Darf ich wissen weshalb solche Ansprüche bestehen für HA oder machst du es weil du das kannst?
Gesendet von meinem ONEPLUS A6013 mit Tapatalk
-
Ich persönlich habe einen 4er NUC Proxmox HA-Cluster mit verteiltem Dateisystem auf den 4 Nodes und alles als VMs mit HW-Watchdogs und Autp-Failover (aber das ist nicht ganz die Raspi-Liga) :-)
Wow das Ist echt nicht schlecht. Darf ich wissen weshalb solche Ansprüche bestehen für HA oder machst du es weil du das kannst?Bei mir ist ioBroker inzwischen recht tief integriert. Es geht zwar das meiste immer auch noch ohne, aber es wäre durchaus blöd. Auch die Gartenberegnung, Rasenmäher, Heizungsthermostatsteuerung und Tür-Steuerung und so ist aber inzwischen dabei. Wenn es weg ist sterbe ich zwar nicht, aber es fehlt viel Komfort.
Mein eigener Anspruch ist aber wegen der ganzen automatischen Funktionalität das es auch tun muss wenn ich nicht da bin (sei es Urlaub oder sei es Familie da und ich unterwegs oder so). Und damit war der weg zu VMs recht klar, auch wegen Snapshots bei Updates und all sowas. Und ja dann war auch ein bissl Spielerei dabei als ich dann mal 2 Nucs hatte und auch noch meine Dev-Umgebung virtualisieren wollte kam Nummer 3 … und aus Redundanzgründen Nummer 4 und dann ja auch ein bissl "weils halt geht". ;-)
-
Wie wäre es mit Kubernetes als Cluster.... Dabei ist es egal, was unten drunter liegt, z.b. Docker.
also ioBroker im Docker: https://github.com/nils/docker-ioBroker
als Hypervisor der Nodes ein Master, das deployment auf einem Pod (z.b. RasPI).Oder Docker im Swarm Mode..... nicht ganz so flexibel aber einfacher.
Falls keiner Docker nutzen möchte und eine normale Installation nutzen möchte, gibt es Pacemaker:
https://www.linuxhelp.com/how-to-configure-high-availability-linux-cluster-with-pacemaker-in-centoswas haltet ihr von den Varianten ?
-
Hat man lokale Storage? Ich denke das ist das Thema in dem Fall, oder ?
Aktuell werden immer noch lokale Files genutzt und selbst wenn mal bald alles per Redis wäre was States, Objekte und "uploaded Files" ist gibts immer noch einige Files drum herum ...
-
Was spricht gegen lokale Storages ?
Auf jedem Storage ist von einem anderen ein Teil oder ganzes vorhanden einer anderen Node. Somit verhält es sich wie SAN-Multicluster. Wozu also ein dedizierter Storage, der dann wieder redundant sein muss ?Beispiel Pacemaker mit Corosync als Cluster - Engine:
Die Corosync Cluster Engine besteht im Aufbau aus vier Kernkomponenten:
Einer zwischen den einzelnen Nodes verteilten Zustandsmaschine deren Zustände und gespeicherte Information virtuell synchronisiert ist.
Einer Instanz zum Starten, Stoppen und Verteilen von den jeweiligen Anwendungen auf die einzelnen Nodes.
Einem Quorum, das über die Anzahl der verfügbaren Nodes im Verbund informiert und dazu dient, bei Teilausfällen die Datenintegrität im Cluster sicherzustellen.
Einer Datenbank zum Sammeln von Zustandsinformationen und deren zeitlichen Verlauf und Konfigurationseinstellung des Clusters. Inhalte dieser Datenbank können bei entsprechender Auswertung beispielsweise Auskunft über verschiedene Betriebsparameter wie die Ausfallzeiten einzelner Nodes liefern.
MIninal braucht man hier gerade mal 2 Maschinen.Bei Docker Swarm , kommt es auf die Konfiguration an, die du selber bestimmst, ob auf allen nodes für deinen Service die Daten liegen , oder ob du eine bestimmte Anzahl von Replicas über deinen Cluster haben möchtest. Ebenso wieviele Worker-Nodes und wieviele Master Nodes du haben möchtest. Eine ungerade Anzahl an Master nodes ist als quorum erforderlich. Man kann eine Master-Node auch gleichzeitig als Worker-Node betreiben . Also minimal sollten es somit 2 Maschinen sein, jedoch ist einer davon gleichzeitig der Master und somit die redundanz nur n. Somit ist eine Redundanz erst mit 3 Maschinen , sowohl Master als auch Worker , mit n+1 möglich.
Bei Kubernetes spricht man von Persistent Volumes (PVs) und Persistent Volume Claims (PVCs) die aus StorageClasses (SC) einzelner Nodes mit einem bind zusammengeführt werden, und so mit einer gewissen Redundanz und Kapazität über dem Cluster (Pod) verteilt sind. Somit ist es sehr flexibel den bedürfnissen anpassbar. Auch hier braucht man minimum 3 Maschinen , damit auch die Konfiguration (etcd) redundant ausgelegt ist und ein quorum entstehen kann. Kubernetes ist hier nur über dem Docker , somit als manager und provider , aber bietet diverse vorteile, entsprechend mehr komplexität als docker swarm.
Mesos lasse ich mal lieber weg, denn das wird zu groß für unser Ziel.....(ab 9 Maschinen , wenn ich es richtig interpretiert habe)
-
Was spricht gegen lokale Storages ?
Auf jedem Storage ist von einem anderen ein Teil oder ganzes vorhanden einer anderen Node. Somit verhält es sich wie SAN-Multicluster. Wozu also ein dedizierter Storage, der dann wieder redundant sein muss ?Beispiel Pacemaker mit Corosync als Cluster - Engine:
Die Corosync Cluster Engine besteht im Aufbau aus vier Kernkomponenten:
Einer zwischen den einzelnen Nodes verteilten Zustandsmaschine deren Zustände und gespeicherte Information virtuell synchronisiert ist.
Einer Instanz zum Starten, Stoppen und Verteilen von den jeweiligen Anwendungen auf die einzelnen Nodes.
Einem Quorum, das über die Anzahl der verfügbaren Nodes im Verbund informiert und dazu dient, bei Teilausfällen die Datenintegrität im Cluster sicherzustellen.
Einer Datenbank zum Sammeln von Zustandsinformationen und deren zeitlichen Verlauf und Konfigurationseinstellung des Clusters. Inhalte dieser Datenbank können bei entsprechender Auswertung beispielsweise Auskunft über verschiedene Betriebsparameter wie die Ausfallzeiten einzelner Nodes liefern.
MIninal braucht man hier gerade mal 2 Maschinen.Bei Docker Swarm , kommt es auf die Konfiguration an, die du selber bestimmst, ob auf allen nodes für deinen Service die Daten liegen , oder ob du eine bestimmte Anzahl von Replicas über deinen Cluster haben möchtest. Ebenso wieviele Worker-Nodes und wieviele Master Nodes du haben möchtest. Eine ungerade Anzahl an Master nodes ist als quorum erforderlich. Man kann eine Master-Node auch gleichzeitig als Worker-Node betreiben . Also minimal sollten es somit 2 Maschinen sein, jedoch ist einer davon gleichzeitig der Master und somit die redundanz nur n. Somit ist eine Redundanz erst mit 3 Maschinen , sowohl Master als auch Worker , mit n+1 möglich.
Bei Kubernetes spricht man von Persistent Volumes (PVs) und Persistent Volume Claims (PVCs) die aus StorageClasses (SC) einzelner Nodes mit einem bind zusammengeführt werden, und so mit einer gewissen Redundanz und Kapazität über dem Cluster (Pod) verteilt sind. Somit ist es sehr flexibel den bedürfnissen anpassbar. Auch hier braucht man minimum 3 Maschinen , damit auch die Konfiguration (etcd) redundant ausgelegt ist und ein quorum entstehen kann. Kubernetes ist hier nur über dem Docker , somit als manager und provider , aber bietet diverse vorteile, entsprechend mehr komplexität als docker swarm.
Mesos lasse ich mal lieber weg, denn das wird zu groß für unser Ziel.....(ab 9 Maschinen , wenn ich es richtig interpretiert habe)
@MarkusDe sagte in [Umfrage] Hochverfügbarer ioBroker auf RPIs:
Was spricht gegen lokale Storages ?
Nichts. Und weil es am besten mit kostengünstigen Komponenten, die man ggf. in der Grabbelkiste hat, realisiert werden soll, habe ich das mit Raspberries und lokalem aber replizierten Storage gelöst.
-
Wie wäre es mit Kubernetes als Cluster.... Dabei ist es egal, was unten drunter liegt, z.b. Docker.
also ioBroker im Docker: https://github.com/nils/docker-ioBroker
als Hypervisor der Nodes ein Master, das deployment auf einem Pod (z.b. RasPI).Oder Docker im Swarm Mode..... nicht ganz so flexibel aber einfacher.
Falls keiner Docker nutzen möchte und eine normale Installation nutzen möchte, gibt es Pacemaker:
https://www.linuxhelp.com/how-to-configure-high-availability-linux-cluster-with-pacemaker-in-centoswas haltet ihr von den Varianten ?
Jupp, ich möchte gerne Centos ohne Compilierungsorgien auf einem Raspberry sehen. Habe ich inkl. Pacemaker durchexerziert und für mich wegen Komplexität abgehakt.
-
Sehr interessantes Thema, ähnliches hatte ich ja selber gerade hier angesprochen, wenn auch deutlich simpler.
Wenn iobroker die breite Masse weiter erreichen soll, dann kann ich euch sagen dass es eine simple Lösung sein sollte. Ich bin durchaus Technik und IT - interessiert, aber die Lösungsansätze die hier geschrieben sind halte ich für zu komplex für ein Großteil der Anwender.
Meine simple Lösungslogik ist:
2 Systeme nutzen:- io.broker auf Raspi oder Mini Windows Server.
- Homematic oder anderes Hardware System welches Aktoren bedient.
Ggenseitige Ausfallüberwachung:
-io.broker prüft die Homematic auf "aktivität" und bei Ausfall wird eine Homematic-unabhängige schaltbare Steckdose vom io.broker angesteuert, die die Homematic per Strom-Reset neustartet- Die Homematic macht selbiges umgekehrt für io.broker auf dem Raspi / Win Server
Im Schlimmsten Fall habe ich 5 Minuten Ausfallzeit, also die Überprüfungszeit und die Bootzeit der Systeme, aber dann läuft es weiter.
Wenn der ganze Raspi / Win Server / dessen Festplatte schrott ist, dann tauscht man entweder manuell oder hält sich tatsächlich ein komplett 2. System vor, welches dann per selbigen Prinzip gestartet wird.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden451
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge