

Influx DB schon wieder sehr groß
-
Ich habe eben mal geschaut wie groß meine InfluxDB 2 ist und da werden mir stolze 5,5GB angezeigt. Gut ich logge auch sehr viele Daten um sie dann in Grafana zu verwenden.
Meine Frage ist wie ich mir die Daten anzeigen lassen kann, die dem meisten Speicherplatz benötigen, ich dann das loggen wieder etwas runtersetzen kann um auf eine annehmbare Größe zu kommen, den 5,5 GB ist doch etwas viel denke ich.@damrak2022 na ja so einfach ist es nicht.. du kannst mal schauen was du alles logst.. und dann wie viele datenelemente pro measurement hast.. und die alten löschen
ich halte meine daten so 2 Jahre.. danach können die weg..
-
Ich habe eben mal geschaut wie groß meine InfluxDB 2 ist und da werden mir stolze 5,5GB angezeigt. Gut ich logge auch sehr viele Daten um sie dann in Grafana zu verwenden.
Meine Frage ist wie ich mir die Daten anzeigen lassen kann, die dem meisten Speicherplatz benötigen, ich dann das loggen wieder etwas runtersetzen kann um auf eine annehmbare Größe zu kommen, den 5,5 GB ist doch etwas viel denke ich.@damrak2022
Mit der Abfrage hier kannst du dir zwar nicht direkt die Speichergröße anzeigen lassen, aber zumindest die Measurements und die darin enthaltene Anzahl an Datensätzen:from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
@damrak2022
Mit der Abfrage hier kannst du dir zwar nicht direkt die Speichergröße anzeigen lassen, aber zumindest die Measurements und die darin enthaltene Anzahl an Datensätzen:from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})@marc-berg Okay, also bei dem Shelly wo mein Mac dranhängt sind es z.B. 410200 Messpunkte. Da ich alle Datenpunkte auch weiterhin nutzen werde, sind die 5,5 GB wohl in Ordnung
-
@marc-berg Okay, also bei dem Shelly wo mein Mac dranhängt sind es z.B. 410200 Messpunkte. Da ich alle Datenpunkte auch weiterhin nutzen werde, sind die 5,5 GB wohl in Ordnung
-
@damrak2022 es bleibt dir ja noch Downsampling. Es ist je nach deinen Umständen vielleicht auch nicht nötig jede Sekunde einen Datenpunkt zu behalten.
@spacerx Momentan sehen meine Einstellungen bei den geloggten Datenpunkten so aus:
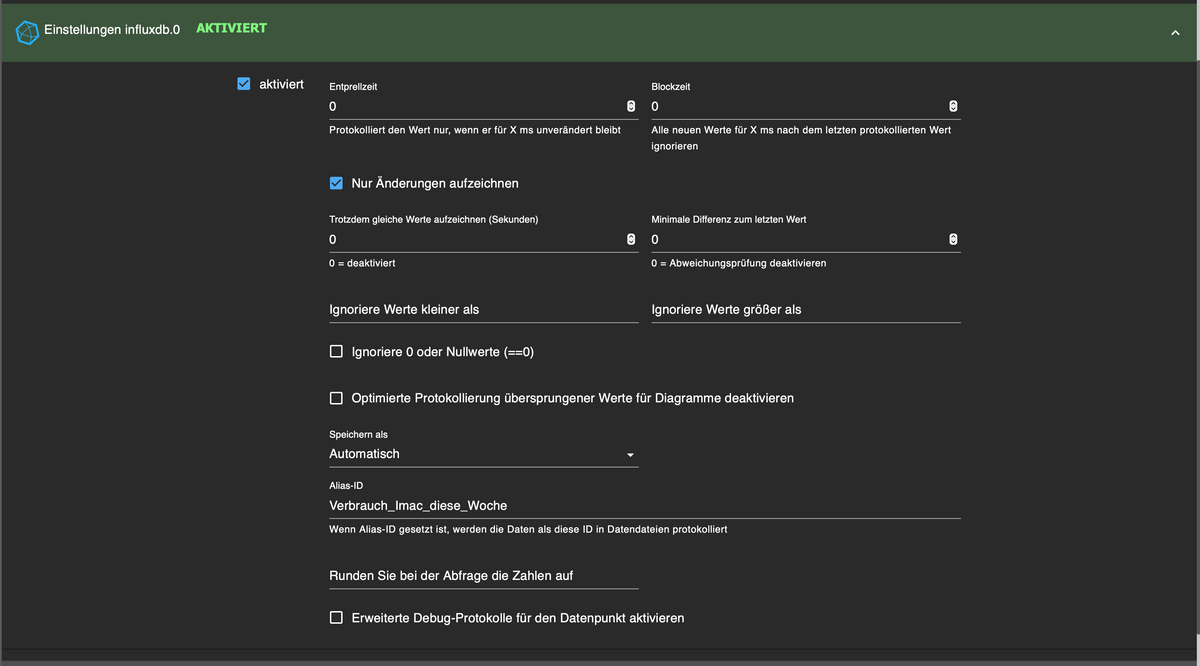
Ist das richtig das ich bei der Blockzeit z.B. 5000 eintragen müsste, damit nur alle 5 Sekunden ein Wert geschrieben wird?
-
Hallo, ich habe gerade bemerkt, dass mein influxdb Verzeichnis 162GB groß ist
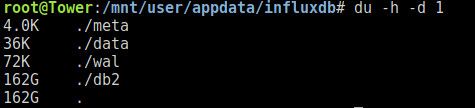
und ich habe keine Ahnung warum. In den Konfiguration der Instanz habe ich 1 Jahr als Speicherdauer ausgewählt
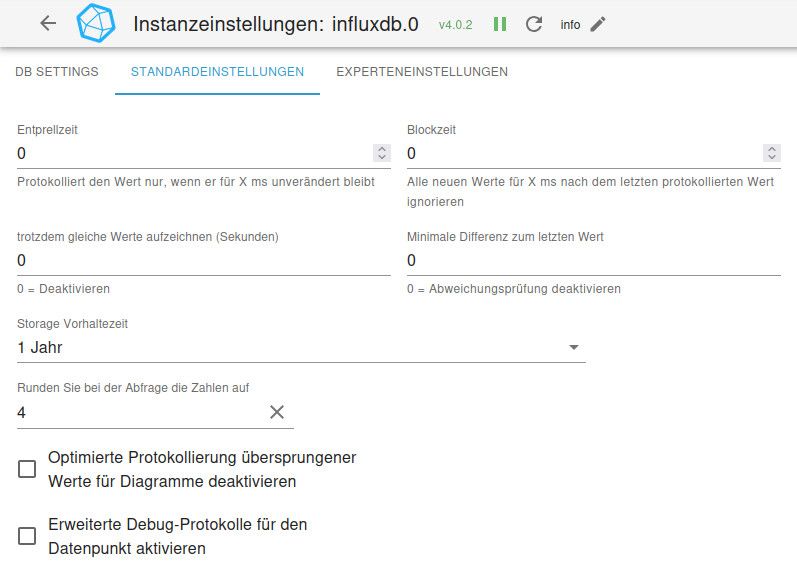
Ich finde 162GB eeetwas zu groß und würde gerne heraus finden was da so massig Daten in die DB schreibt.
Mit der Abfrage aus https://forum.iobroker.net/post/1008873 kann ich nichts anfangen, ich weiß nicht mals wo ich die eintragen müsste.Kann mir da wer weiter helfen?
-
 H Homoran verschob dieses Thema von ioBroker Allgemein am
H Homoran verschob dieses Thema von ioBroker Allgemein am
-
Hallo, ich habe gerade bemerkt, dass mein influxdb Verzeichnis 162GB groß ist
und ich habe keine Ahnung warum. In den Konfiguration der Instanz habe ich 1 Jahr als Speicherdauer ausgewählt
Ich finde 162GB eeetwas zu groß und würde gerne heraus finden was da so massig Daten in die DB schreibt.
Mit der Abfrage aus https://forum.iobroker.net/post/1008873 kann ich nichts anfangen, ich weiß nicht mals wo ich die eintragen müsste.Kann mir da wer weiter helfen?
@bubiman schreibst du vllt noch anderweitig ausserhalb von iobroker in die influxdb?
-
Hast Du die OSS Metrics deaktiviert? Sonst generiert das ziemlich viele Daten über die Zeit.
-
"/mnt/usr/appdata/influxdb" sieht mit nicht nach einem Standard-Pfad für die Datenbank aus.
Vielleicht hat das irgendein Problem verursacht, und z. B. das Retain wird nicht beachtet, und die Daten werden nicht nach einem Jahr gelöscht ...
Kannst Du in Grafana Daten abrufen, die älter, als ein Jahr sind?Was wird denn in der influxDB Web Ui über die Retain Zeit gesagt?
Intel(R) Celeron(R) CPU N3000 @1.04GHz 8G RAM 480G SSD * Virtualization : unprivileged lxc container on Proxmox * 6 GByte RAM für den iobroker Container * Remote-Access über Wireguard meiner Fritzbox
-
"/mnt/usr/appdata/influxdb" sieht mit nicht nach einem Standard-Pfad für die Datenbank aus.
Vielleicht hat das irgendein Problem verursacht, und z. B. das Retain wird nicht beachtet, und die Daten werden nicht nach einem Jahr gelöscht ...
Kannst Du in Grafana Daten abrufen, die älter, als ein Jahr sind?Was wird denn in der influxDB Web Ui über die Retain Zeit gesagt?
-
Hallo, ich habe gerade bemerkt, dass mein influxdb Verzeichnis 162GB groß ist
und ich habe keine Ahnung warum. In den Konfiguration der Instanz habe ich 1 Jahr als Speicherdauer ausgewählt
Ich finde 162GB eeetwas zu groß und würde gerne heraus finden was da so massig Daten in die DB schreibt.
Mit der Abfrage aus https://forum.iobroker.net/post/1008873 kann ich nichts anfangen, ich weiß nicht mals wo ich die eintragen müsste.Kann mir da wer weiter helfen?
Hallo, ich habe gerade bemerkt, dass mein influxdb Verzeichnis 162GB groß ist
und ich habe keine Ahnung warum. In den Konfiguration der Instanz habe ich 1 Jahr als Speicherdauer ausgewählt
Ich finde 162GB eeetwas zu groß und würde gerne heraus finden was da so massig Daten in die DB schreibt.
Mit der Abfrage aus https://forum.iobroker.net/post/1008873 kann ich nichts anfangen, ich weiß nicht mals wo ich die eintragen müsste.Kann mir da wer weiter helfen?
Kochrezept:
Kommandozeile aufmachen auf dem Linux-Rechner, auf dem influx läuft, dann
- Eine Datei des Inhalts von oben anlegen, z.b. "query_count_entries.txt"
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})- Organisations-ID und Token herausfinden und folgendes als Kommandozeile eintippen (ich habe gleich den Anfang des Ergebnisses mitkopiert, org-id und token Großteils unkenntlich gemacht, bis das Ergebnis ausgespuckt wird dauert es etwas):
martin@iobroker-test-sicher:~$ influx query --org-id 9e........ --token 0Blx8.........0Q== --file ./query_count_entries.txt Result: _result Table: keys: [] Anzahl:int _measurement:string -------------------------- ------------------------------------------- 29857440 alias.0.Zaehler.Elektrizität.1.Leistung.L1 29824895 alias.0.Zaehler.Elektrizität.1.Leistung.L2 ...Intel(R) Celeron(R) CPU N3000 @1.04GHz 8G RAM 480G SSD * Virtualization : unprivileged lxc container on Proxmox * 6 GByte RAM für den iobroker Container * Remote-Access über Wireguard meiner Fritzbox
-
Hallo, ich habe gerade bemerkt, dass mein influxdb Verzeichnis 162GB groß ist
und ich habe keine Ahnung warum. In den Konfiguration der Instanz habe ich 1 Jahr als Speicherdauer ausgewählt
Ich finde 162GB eeetwas zu groß und würde gerne heraus finden was da so massig Daten in die DB schreibt.
Mit der Abfrage aus https://forum.iobroker.net/post/1008873 kann ich nichts anfangen, ich weiß nicht mals wo ich die eintragen müsste.Kann mir da wer weiter helfen?
Kochrezept:
Kommandozeile aufmachen auf dem Linux-Rechner, auf dem influx läuft, dann
- Eine Datei des Inhalts von oben anlegen, z.b. "query_count_entries.txt"
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})- Organisations-ID und Token herausfinden und folgendes als Kommandozeile eintippen (ich habe gleich den Anfang des Ergebnisses mitkopiert, org-id und token Großteils unkenntlich gemacht, bis das Ergebnis ausgespuckt wird dauert es etwas):
martin@iobroker-test-sicher:~$ influx query --org-id 9e........ --token 0Blx8.........0Q== --file ./query_count_entries.txt Result: _result Table: keys: [] Anzahl:int _measurement:string -------------------------- ------------------------------------------- 29857440 alias.0.Zaehler.Elektrizität.1.Leistung.L1 29824895 alias.0.Zaehler.Elektrizität.1.Leistung.L2 ...@MartinP Um das rauszufinden, dass es eh an den OSS Metrics liegt und da viele Daten drin stehen, welche man eh nicht nutzt.
- Am besten nicht das Standard-Bucket für ioBroker nutzen, sondern ein separates anlegen
- Dadurch kann man später alles einfacher löschen, was man nicht braucht. Also die
go_*Measurements. Oder im Standard-Bucket direkt eine super kurze Retention Time setzen (1 Tag). - Alternativ in der Config
metrics-disabled = truesetzen, damit die Daten gar nicht erst gesammelt werden
Hatte ich alles ausführlich im Kurs erklärt.
Links
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
455
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge