

Test paperless-ngx Adapter
-
@n3ucr0n Hallo,
das schaue ich mir die Tage, wenn ich dazu komme einmal an.
Mal sehen, ob es mit der Anzahl wirklich nur ein Zufall ist.Edit: Habe gerade gemerkt, dass der wirklich über die API nur die ersten liefert.
Müsste ich dann noch anpassen. -
@ben1983 Super! Ich freue mich auf die neu Version, sag einfach bescheid wenn Du Zeit gefunden hast. Dann teste ich es gerne :-)
@n3ucr0n So. Da ich in den nächsten Wochen wenig / keine Zeit haben werde (Urlaub ;-) )
Habe ich gerade nochmal die 0.06 online gestellt.Hier wird:
a) das Suchen ermöcht
b) das Auflisten aller Tags / Dokumente etc. in den detailed Ordner durchgeführt
(vorher wurde nur die erste Seite [erste Daten] der API geschrieben)
c) eine Aufteilung in basic und detailed vorgenommen, je nach Auswahl, werden dann entsprechende Daten zugewiesen.Die Struktur der Daten, musste ich allerdings anpassen, da es bei den Test zu Fehlern, bzw. Warnungen kam, wenn ich bspw. ein Ordnername so darstellen wollte, wie ein Dokument Betitelt ist. Hier kann es dazu kommen, dass nicht erlaubte Zeichen im Dokumententitel vorkommen. Also musste ich auf die "Arraystruktur" zurückgreifen und habe es numerisch durchnummerieren lassen.
Bspw.
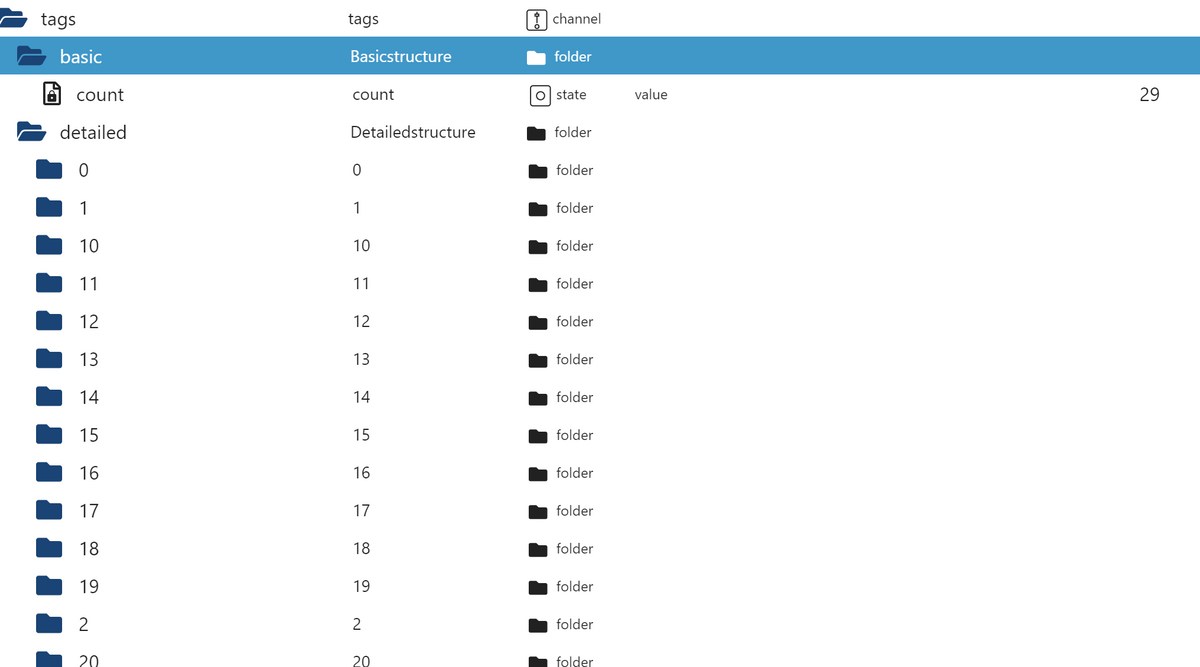
Gerne kann getestet werden.
Am Besten vor installieren der neuen 0.0.6 einmal den Adapter stoppen und das Instanz Verzeichnis löschen. -
@n3ucr0n So. Da ich in den nächsten Wochen wenig / keine Zeit haben werde (Urlaub ;-) )
Habe ich gerade nochmal die 0.06 online gestellt.Hier wird:
a) das Suchen ermöcht
b) das Auflisten aller Tags / Dokumente etc. in den detailed Ordner durchgeführt
(vorher wurde nur die erste Seite [erste Daten] der API geschrieben)
c) eine Aufteilung in basic und detailed vorgenommen, je nach Auswahl, werden dann entsprechende Daten zugewiesen.Die Struktur der Daten, musste ich allerdings anpassen, da es bei den Test zu Fehlern, bzw. Warnungen kam, wenn ich bspw. ein Ordnername so darstellen wollte, wie ein Dokument Betitelt ist. Hier kann es dazu kommen, dass nicht erlaubte Zeichen im Dokumententitel vorkommen. Also musste ich auf die "Arraystruktur" zurückgreifen und habe es numerisch durchnummerieren lassen.
Bspw.
Gerne kann getestet werden.
Am Besten vor installieren der neuen 0.0.6 einmal den Adapter stoppen und das Instanz Verzeichnis löschen.@ben1983 Ja dann genieß den Urlaub in vollen Zügen :-)
Habe die Version grade ausprobiert und es scheint alles erstmal richtig angezeigt zu werden.
Es werden alle Tags aufgelistet und scheinen vom Count her auch zu stimmen.Morgen werde ich mal Tests bezüglich
- Dokumente hinzufügen
- Dokumente löschen
- Tags ändern
- Tags umbenenen
- Tags Löschen
- etc.
durchführen. Ich berichte dann :-)
Das Einzige was mir jetzt schon aufgefallen ist, ist das die Tags bzw. die Ordner der Tags aktuell nur mit der ID dargestellt werden. Da wäre natürlich der Tag-Name sehr schön. Das würde auch vermeiden, dass nach der 19 erstmal die 2 vor der 20 kommt. Aber das sind ja nur Schönheitsfehler :-)
EDIT: Habe grade nochmal mit Verstand Deinen Post gelesen und gesehen, dass es einen guten Grund für die numerische Darstellung gibt. Wenn das erstmal so der klügste Weg ist, dann passt das natürlich super :-)
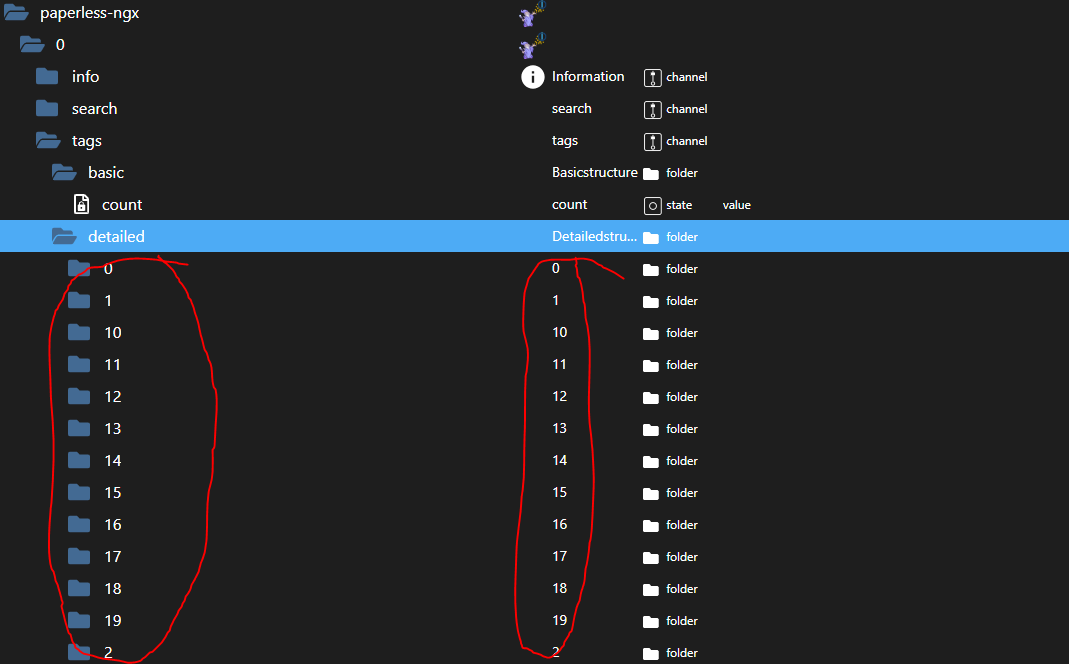
Ansonsten schonmal DANKE für die bisherige Entwicklung! :-)
-
@ben1983 Ja dann genieß den Urlaub in vollen Zügen :-)
Habe die Version grade ausprobiert und es scheint alles erstmal richtig angezeigt zu werden.
Es werden alle Tags aufgelistet und scheinen vom Count her auch zu stimmen.Morgen werde ich mal Tests bezüglich
- Dokumente hinzufügen
- Dokumente löschen
- Tags ändern
- Tags umbenenen
- Tags Löschen
- etc.
durchführen. Ich berichte dann :-)
Das Einzige was mir jetzt schon aufgefallen ist, ist das die Tags bzw. die Ordner der Tags aktuell nur mit der ID dargestellt werden. Da wäre natürlich der Tag-Name sehr schön. Das würde auch vermeiden, dass nach der 19 erstmal die 2 vor der 20 kommt. Aber das sind ja nur Schönheitsfehler :-)
EDIT: Habe grade nochmal mit Verstand Deinen Post gelesen und gesehen, dass es einen guten Grund für die numerische Darstellung gibt. Wenn das erstmal so der klügste Weg ist, dann passt das natürlich super :-)
Ansonsten schonmal DANKE für die bisherige Entwicklung! :-)
@n3ucr0n ja leider ist dass mit den Namen nicht so einfach möglich.
Denn, wie gesagt könnte ja der Name ein in iobroker ungültiges Zeichen erhalten.
Man könnte das natürlich mittels einer Funktion in einen gültigen String ändern, aber dann würde auch der Tag / Ordner wieder nicht ganz so heißen, wie der originalname des Tags. Aus diesem Grund habe ich mich für das numerische entschieden
Man könnte noch überlegen, ob man mit führenden „00“ arbeitet, aber die Nummerierung haben eh nichts mit den Tag IDS zu tun, sondern sind die Reihenfolge, wie sie übertragen wurden.
Hier wäre noch zu überlegen, ob man nach ids benamt. Aber schau mal durch und gib mal Bescheid, was du so dazu meinst.
So wie aktuell ist es halt am einfachsten, aber das muss ja nicht so bleiben.Schau dir auch mal an, wie es dargestellt wird, wie die Auflistung innerhalb eines Dokuments angezeigt wird, welchen Tag das Dokument enthält.
Dort stehen glaube Auktion einzelne States:Documents.5.tags.0 —- wert: 28
Oder so.
Hier wäre eine Option, dass stattdessen:
Documents.5.tags —— wert: array[28,25,2]Bspw. Wäre das sinnvoll, oder anderen Vorschlag. Oder so wie es ist, ok?
-
@ben1983 Ja dann genieß den Urlaub in vollen Zügen :-)
Habe die Version grade ausprobiert und es scheint alles erstmal richtig angezeigt zu werden.
Es werden alle Tags aufgelistet und scheinen vom Count her auch zu stimmen.Morgen werde ich mal Tests bezüglich
- Dokumente hinzufügen
- Dokumente löschen
- Tags ändern
- Tags umbenenen
- Tags Löschen
- etc.
durchführen. Ich berichte dann :-)
Das Einzige was mir jetzt schon aufgefallen ist, ist das die Tags bzw. die Ordner der Tags aktuell nur mit der ID dargestellt werden. Da wäre natürlich der Tag-Name sehr schön. Das würde auch vermeiden, dass nach der 19 erstmal die 2 vor der 20 kommt. Aber das sind ja nur Schönheitsfehler :-)
EDIT: Habe grade nochmal mit Verstand Deinen Post gelesen und gesehen, dass es einen guten Grund für die numerische Darstellung gibt. Wenn das erstmal so der klügste Weg ist, dann passt das natürlich super :-)
Ansonsten schonmal DANKE für die bisherige Entwicklung! :-)
-
@ben1983 Ja dann genieß den Urlaub in vollen Zügen :-)
Habe die Version grade ausprobiert und es scheint alles erstmal richtig angezeigt zu werden.
Es werden alle Tags aufgelistet und scheinen vom Count her auch zu stimmen.Morgen werde ich mal Tests bezüglich
- Dokumente hinzufügen
- Dokumente löschen
- Tags ändern
- Tags umbenenen
- Tags Löschen
- etc.
durchführen. Ich berichte dann :-)
Das Einzige was mir jetzt schon aufgefallen ist, ist das die Tags bzw. die Ordner der Tags aktuell nur mit der ID dargestellt werden. Da wäre natürlich der Tag-Name sehr schön. Das würde auch vermeiden, dass nach der 19 erstmal die 2 vor der 20 kommt. Aber das sind ja nur Schönheitsfehler :-)
EDIT: Habe grade nochmal mit Verstand Deinen Post gelesen und gesehen, dass es einen guten Grund für die numerische Darstellung gibt. Wenn das erstmal so der klügste Weg ist, dann passt das natürlich super :-)
Ansonsten schonmal DANKE für die bisherige Entwicklung! :-)
@n3ucr0n So. jetzt aber vorerst die letzte Änderung:
Habe das Erzeugen nochmal intern etwas verändert.
Nun werden ach ding wie Tags, in der Dokumentenauflistung als Array ausgegeben.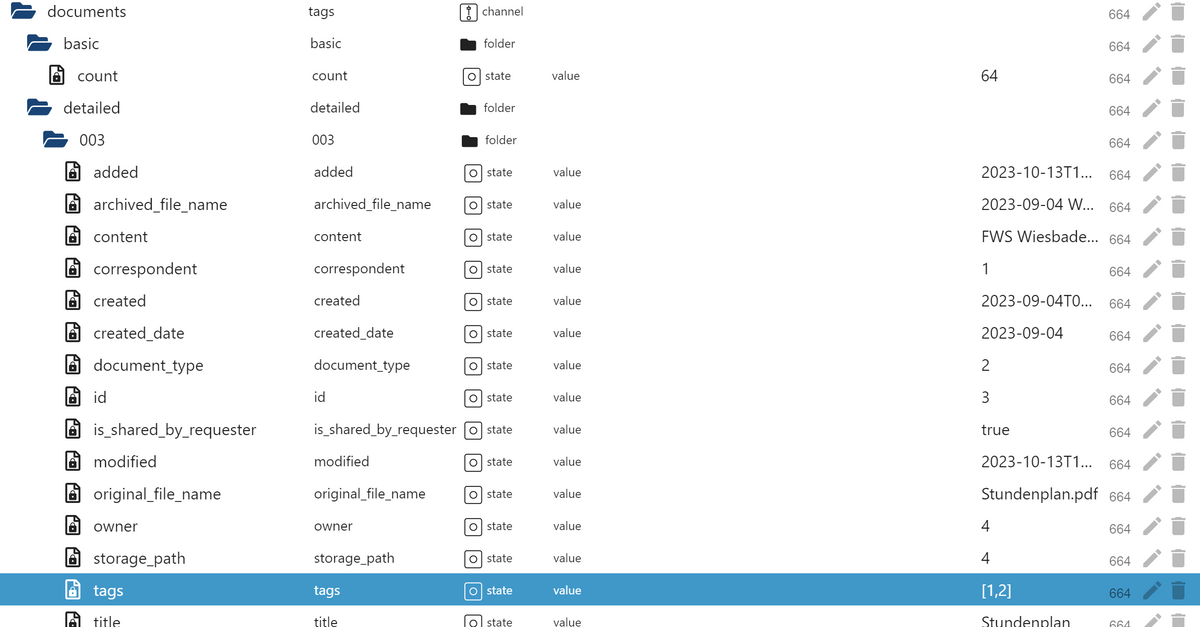
Zusätzlich gibt´s noch etwas "kosmetik" in Form von icons

V0.0.8
-
@n3ucr0n wie findest Du es denn als User,
Dass bspw. die Dokumente (oder die Dokumente bei der Suche in den Resultaten) in einem Unterordner mit ihren IDs angelegt sind?
Wie ein Array sortiert, würde es natürlich immer die „0“ geben und man hätte so immer ein erstes Objekt.
Andererseits ist es aktuell so, das direkt die richtige ID in der Objekt id enthalten ist und man somit direkt auf die angegebenen ids zugreifen kann, eben genau weil die Id Teil der Objekt id ist. -
@n3ucr0n wie findest Du es denn als User,
Dass bspw. die Dokumente (oder die Dokumente bei der Suche in den Resultaten) in einem Unterordner mit ihren IDs angelegt sind?
Wie ein Array sortiert, würde es natürlich immer die „0“ geben und man hätte so immer ein erstes Objekt.
Andererseits ist es aktuell so, das direkt die richtige ID in der Objekt id enthalten ist und man somit direkt auf die angegebenen ids zugreifen kann, eben genau weil die Id Teil der Objekt id ist.@ben1983 Hallo!
Erstmal danke für die ganzen schnellen Updates trotz Urlaub :-)Das Suchen scheint noch nicht so gut zu klappen.
Ich habe ich die Query testweise "Entgeltabrechnung" eingegeben und bekomme auch Ergebnisse aber angeblich nur 4. Da sind DEUTLICH mehr vorhanden
Von der Sortierung her bin ich komplett schmerzfrei. Wenn man einmal weiß, wie die Ergebnisse aufgebaut sind, kann man sich den Rest ja selber zusammenbauen.
Das Arbeiten mit Arrays ist darstellerisch gut, für mich aber bisher noch ohne Erfahrung. Müsste mich erstmal mit den Möglichkeiten der Arrayverarbeitung auseinandersetzen um zu sagen, ob es paraktikabel oder unpraktisch ist. Tut mir leid, dass ich an dieser Stelle kein Feedback geben kann.
Gibt es eine Möglichkeit die IDs in den Datenpunkten Adapterseitig direkt durch Klarnamen zu ändern?
Also Tag ID 2, 3, 4 ist ja über die Tags aufschlüsselbar in den korrekten Namen des Tags. Genauso bei Benutzern etc.Das wäre rein darstellerisch tatsächlich angenehmer.
ABER, und jetzt kommt das, was @Meister-Mopper bereits sagte: Wo genau liegt da der Usecase. Ich selbst habe noch keine Ahnung wofür ich diese Informationen in der VIS oder im ioBroker überhaupt nutzen würde.
Die Counts der Tags sind für mich grandios. Darüber steuere ich das Backup meiner Paperless-Installation, benachrichtige mich über neue Dokumente etc.
Aber die Dokumentensuche etc. würde ich vermutlich auch zukünftig direkt über Paperless und nicht den ioBroker oder die VIS machen....Damit will ich nur verhindern, dass Du viel Zeit und Mühe in ein Feature investierst, welches ggf. gar nicht genutzt wird.
-
@ben1983 Hallo!
Erstmal danke für die ganzen schnellen Updates trotz Urlaub :-)Das Suchen scheint noch nicht so gut zu klappen.
Ich habe ich die Query testweise "Entgeltabrechnung" eingegeben und bekomme auch Ergebnisse aber angeblich nur 4. Da sind DEUTLICH mehr vorhandenVon der Sortierung her bin ich komplett schmerzfrei. Wenn man einmal weiß, wie die Ergebnisse aufgebaut sind, kann man sich den Rest ja selber zusammenbauen.
Das Arbeiten mit Arrays ist darstellerisch gut, für mich aber bisher noch ohne Erfahrung. Müsste mich erstmal mit den Möglichkeiten der Arrayverarbeitung auseinandersetzen um zu sagen, ob es paraktikabel oder unpraktisch ist. Tut mir leid, dass ich an dieser Stelle kein Feedback geben kann.
Gibt es eine Möglichkeit die IDs in den Datenpunkten Adapterseitig direkt durch Klarnamen zu ändern?
Also Tag ID 2, 3, 4 ist ja über die Tags aufschlüsselbar in den korrekten Namen des Tags. Genauso bei Benutzern etc.Das wäre rein darstellerisch tatsächlich angenehmer.
ABER, und jetzt kommt das, was @Meister-Mopper bereits sagte: Wo genau liegt da der Usecase. Ich selbst habe noch keine Ahnung wofür ich diese Informationen in der VIS oder im ioBroker überhaupt nutzen würde.
Die Counts der Tags sind für mich grandios. Darüber steuere ich das Backup meiner Paperless-Installation, benachrichtige mich über neue Dokumente etc.
Aber die Dokumentensuche etc. würde ich vermutlich auch zukünftig direkt über Paperless und nicht den ioBroker oder die VIS machen....Damit will ich nur verhindern, dass Du viel Zeit und Mühe in ein Feature investierst, welches ggf. gar nicht genutzt wird.
@n3ucr0n @Meister-Mopper
Danke für euer Feedback.
Die Anfrage zum Adapter kam ja nicht von mir, sondern von @EuloTV.
@n3ucr0n DU hattest ja auch in dem ISSUE geschrieben.Die Suche, habe ich nochmal erweitert.
Bei paperless gab es eine allgemeine Suche und eine Suche für Schlagworte in Dokumenten.
Die erste lieferte nur 3 Ergebnisse pro typ (Dokument, Tag)....usw.
Die zweite ist wesentlich "besser".Bezüglich der Sortierung sind wir auch frei.
Wenn ich es nach der "Arrymethode" mache, dann gibt es halt immer einen index "0".
Bei der ID igbt es nur die Ordner, der gesendeten Dokumenten/Tag - ID.
Dies ist aber schon mal wesentlich einfacher, um sich zurecht zu finden.Wie genau meinst Du das IDs durch Klarnamen darstellen?
Hast Du ein Beispiel?Aktuell: Tag: Name: "TestTag", id: 5
Dargestellt werden die Tagdaten in dem Unterordner tags.005
Den Namen konnte ich ja nicht nehmen, da es ja sein könnte, das in Paperless ein Tag "TesTä?g" benannt ist und da bekomme ich natürlich von ioBroker eine Meldung, dass das nicht sein sollte / darf.
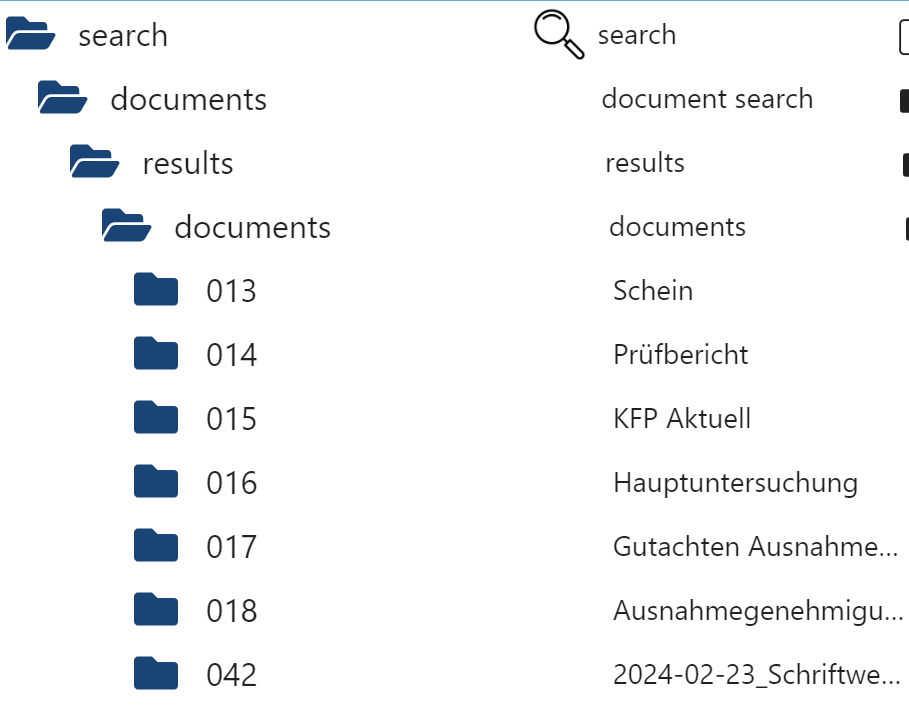
Was natürlich geht, ist zusätzlich zur Id noch den Namen im common.nameDie Version. 0.0.9 ist online.
Hier wurde wie gesagt, hauptsächlich die Suche implementiert:
search.documents.query(Es regnete ja heute Mittag ;-) )
!!!! Ach ja.... bei der neuen Installation einfach vorher wieder ab paperless.instanz alle ordner / ids löschen
Edit: 0.0.10 ist online und beinhaltet die Erweiterte Namensgebung.
-
@n3ucr0n @Meister-Mopper
Danke für euer Feedback.
Die Anfrage zum Adapter kam ja nicht von mir, sondern von @EuloTV.
@n3ucr0n DU hattest ja auch in dem ISSUE geschrieben.Die Suche, habe ich nochmal erweitert.
Bei paperless gab es eine allgemeine Suche und eine Suche für Schlagworte in Dokumenten.
Die erste lieferte nur 3 Ergebnisse pro typ (Dokument, Tag)....usw.
Die zweite ist wesentlich "besser".Bezüglich der Sortierung sind wir auch frei.
Wenn ich es nach der "Arrymethode" mache, dann gibt es halt immer einen index "0".
Bei der ID igbt es nur die Ordner, der gesendeten Dokumenten/Tag - ID.
Dies ist aber schon mal wesentlich einfacher, um sich zurecht zu finden.Wie genau meinst Du das IDs durch Klarnamen darstellen?
Hast Du ein Beispiel?Aktuell: Tag: Name: "TestTag", id: 5
Dargestellt werden die Tagdaten in dem Unterordner tags.005
Den Namen konnte ich ja nicht nehmen, da es ja sein könnte, das in Paperless ein Tag "TesTä?g" benannt ist und da bekomme ich natürlich von ioBroker eine Meldung, dass das nicht sein sollte / darf.
Was natürlich geht, ist zusätzlich zur Id noch den Namen im common.nameDie Version. 0.0.9 ist online.
Hier wurde wie gesagt, hauptsächlich die Suche implementiert:
search.documents.query(Es regnete ja heute Mittag ;-) )
!!!! Ach ja.... bei der neuen Installation einfach vorher wieder ab paperless.instanz alle ordner / ids löschen
Edit: 0.0.10 ist online und beinhaltet die Erweiterte Namensgebung.
Soo, nach längerer Abwesenheit hier ein Feedback.
Aktuell kann ich keine Probleme / Schwierigkeiten feststellen.
Die Tags werden richtig angezeigt und auch aktualisiert.
Die Anzahl der Dokumente in den Tags zählen - soweit ich das sehen kann - auch korrekt.Die Suche scheint zu klappen, wobei ich diese Funktion nur zu Testzwecken genutzt habe. Für mich hat sich aus der Dokumentensuche noch kein nutzbarer Mehrwert erwiesen.
Spannend wären natürlich nun einige mehrere Tester. Dazu müsste der Adapter aber normal über die Adapterliste installierbar gemacht werden. Ich denke, viele scheuen die Installation über GitHub :-)
Ich selbst bin sehr zufrieden. Meine Wünsche hast Du hervorragend erfüllt, danke :-)
-
Soo, nach längerer Abwesenheit hier ein Feedback.
Aktuell kann ich keine Probleme / Schwierigkeiten feststellen.
Die Tags werden richtig angezeigt und auch aktualisiert.
Die Anzahl der Dokumente in den Tags zählen - soweit ich das sehen kann - auch korrekt.Die Suche scheint zu klappen, wobei ich diese Funktion nur zu Testzwecken genutzt habe. Für mich hat sich aus der Dokumentensuche noch kein nutzbarer Mehrwert erwiesen.
Spannend wären natürlich nun einige mehrere Tester. Dazu müsste der Adapter aber normal über die Adapterliste installierbar gemacht werden. Ich denke, viele scheuen die Installation über GitHub :-)
Ich selbst bin sehr zufrieden. Meine Wünsche hast Du hervorragend erfüllt, danke :-)
-
Soo, nach längerer Abwesenheit hier ein Feedback.
Aktuell kann ich keine Probleme / Schwierigkeiten feststellen.
Die Tags werden richtig angezeigt und auch aktualisiert.
Die Anzahl der Dokumente in den Tags zählen - soweit ich das sehen kann - auch korrekt.Die Suche scheint zu klappen, wobei ich diese Funktion nur zu Testzwecken genutzt habe. Für mich hat sich aus der Dokumentensuche noch kein nutzbarer Mehrwert erwiesen.
Spannend wären natürlich nun einige mehrere Tester. Dazu müsste der Adapter aber normal über die Adapterliste installierbar gemacht werden. Ich denke, viele scheuen die Installation über GitHub :-)
Ich selbst bin sehr zufrieden. Meine Wünsche hast Du hervorragend erfüllt, danke :-)
@n3ucr0n sagte in Test paperless-ngx Adapter:
Spannend wären natürlich nun einige mehrere Tester. Dazu müsste der Adapter aber normal über die Adapterliste installierbar gemacht werden. Ich denke, viele scheuen die Installation über GitHub
Ich hatte ihn mal installiert, allerdings sehe ich den Nutzen Dokumente über ioBroker zu suchen oder über VIS anzuzeigen für mich nicht und habe ihn wieder deinstalliert. Sorry
-
Hat vielleicht jemand noch einen Kontakt zu Paperless?
Ich habe sie schon des Öfteren angeschrieben, wegen der Nutzung des Logos.....es kommt null Rückmeldung.@ben1983 said in Test paperless-ngx Adapter:
Hat vielleicht jemand noch einen Kontakt zu Paperless?
Ich habe sie schon des Öfteren angeschrieben, wegen der Nutzung des Logos.....es kommt null Rückmeldung.Ich glaub shamoon ist da einer der aktivisten Entwickler.
The difference beetween Man and Boys:
The price of their toys 😀 -
@ben1983 said in Test paperless-ngx Adapter:
Hat vielleicht jemand noch einen Kontakt zu Paperless?
Ich habe sie schon des Öfteren angeschrieben, wegen der Nutzung des Logos.....es kommt null Rückmeldung.Ich glaub shamoon ist da einer der aktivisten Entwickler.
-
@blockmove und ist der hier aktiv, oder kannst den jemand?
bei contributions/support steht was von einem matrix chat.
evtl mal da rein gehen und fragen. im zweifel dann halt ohne logo
projekt ist gnu v3.
da kann es mit den logos und trademarks schwierig werden, da ohne explizite erweiterung sich gnu nur auf programm-code/programm einschränken lässt.
das jemand von paperless hier aktiv ist ist eher unwahrscheinlich -
Hallo zusammen,
vielen Dank für den Adapter, ich bin tatsächlich der Meinung dass dieser seine Berechtigung hat. Wie ich paperless bisher in verbindung mit iobroker nutze habe ich bereits hier skizziert:
https://forum.iobroker.net/topic/70115/verzeichnis-überwachen-und-datei-in-datenpunkt-schreiben
Nun aber zu meiner Frage: mit deinem Adapter könnte ich meine bisherige Vorgehesnweise deutlich vereinfachen. Leider habe ich es bisher nicht geschafft die Dokumentensuche im Adapter so einzuschränken, dass die Suchbegriffe nur auf Dokumente mit bestimmten Tags angewendet werden. Ist dies möglich? Falls ja wie?
-
Hallo zusammen,
vielen Dank für den Adapter, ich bin tatsächlich der Meinung dass dieser seine Berechtigung hat. Wie ich paperless bisher in verbindung mit iobroker nutze habe ich bereits hier skizziert:
https://forum.iobroker.net/topic/70115/verzeichnis-überwachen-und-datei-in-datenpunkt-schreiben
Nun aber zu meiner Frage: mit deinem Adapter könnte ich meine bisherige Vorgehesnweise deutlich vereinfachen. Leider habe ich es bisher nicht geschafft die Dokumentensuche im Adapter so einzuschränken, dass die Suchbegriffe nur auf Dokumente mit bestimmten Tags angewendet werden. Ist dies möglich? Falls ja wie?
-
bisher frage ich das wie folgt über die API ab
http://paperless:8000/api/documents/?title__istartswith=&title__iendswith=&title__icontains=&title__iexact=&content__istartswith=&content__iendswith=&content__icontains=&content__iexact=&archive_serial_number=&archive_serial_number__gt=&archive_serial_number__gte=&archive_serial_number__lt=&archive_serial_number__lte=&archive_serial_number__isnull=&created__year=&created__month=&created__day=&created__date__gt=&created__gt=&created__date__lt=&created__lt=&added__year=&added__month=&added__day=&added__date__gt=&added__gt=&added__date__lt=&added__lt=&modified__year=&modified__month=&modified__day=&modified__date__gt=&modified__gt=&modified__date__lt=&modified__lt=&original_filename__istartswith=&original_filename__iendswith=&original_filename__icontains=&original_filename__iexact=&checksum__istartswith=&checksum__iendswith=&checksum__icontains=&checksum__iexact=&correspondent__isnull=&correspondent__id__in=&correspondent__id=&correspondent__name__istartswith=&correspondent__name__iendswith=&correspondent__name__icontains=&correspondent__name__iexact=&tags__id__in=&tags__id=3&tags__id=4&tags__id__all=16&tags__name__istartswith=&tags__name__iendswith=&tags__name__icontains=&tags__name__iexact=&document_type__isnull=&document_type__id__in=&document_type__id=&document_type__name__istartswith=&document_type__name__iendswith=&document_type__name__icontains=&document_type__name__iexact=&storage_path__isnull=&storage_path__id__in=&storage_path__id=&storage_path__name__istartswith=&storage_path__name__iendswith=&storage_path__name__icontains=&storage_path__name__iexact=&owner__isnull=&owner__id__in=&owner__id=&is_tagged=&tags__id__all= 3%2C4%2C16& tags__id__none=&correspondent__id__none=&document_type__id__none=&storage_path__id__none=&is_in_inbox=&title_content=&owner__id__none=wobei die mittlere Zeile eine einschränkung auf Dokumente mit den Tags 3,4 und 16 bedeutet.
-
bisher frage ich das wie folgt über die API ab
http://paperless:8000/api/documents/?title__istartswith=&title__iendswith=&title__icontains=&title__iexact=&content__istartswith=&content__iendswith=&content__icontains=&content__iexact=&archive_serial_number=&archive_serial_number__gt=&archive_serial_number__gte=&archive_serial_number__lt=&archive_serial_number__lte=&archive_serial_number__isnull=&created__year=&created__month=&created__day=&created__date__gt=&created__gt=&created__date__lt=&created__lt=&added__year=&added__month=&added__day=&added__date__gt=&added__gt=&added__date__lt=&added__lt=&modified__year=&modified__month=&modified__day=&modified__date__gt=&modified__gt=&modified__date__lt=&modified__lt=&original_filename__istartswith=&original_filename__iendswith=&original_filename__icontains=&original_filename__iexact=&checksum__istartswith=&checksum__iendswith=&checksum__icontains=&checksum__iexact=&correspondent__isnull=&correspondent__id__in=&correspondent__id=&correspondent__name__istartswith=&correspondent__name__iendswith=&correspondent__name__icontains=&correspondent__name__iexact=&tags__id__in=&tags__id=3&tags__id=4&tags__id__all=16&tags__name__istartswith=&tags__name__iendswith=&tags__name__icontains=&tags__name__iexact=&document_type__isnull=&document_type__id__in=&document_type__id=&document_type__name__istartswith=&document_type__name__iendswith=&document_type__name__icontains=&document_type__name__iexact=&storage_path__isnull=&storage_path__id__in=&storage_path__id=&storage_path__name__istartswith=&storage_path__name__iendswith=&storage_path__name__icontains=&storage_path__name__iexact=&owner__isnull=&owner__id__in=&owner__id=&is_tagged=&tags__id__all= 3%2C4%2C16& tags__id__none=&correspondent__id__none=&document_type__id__none=&storage_path__id__none=&is_in_inbox=&title_content=&owner__id__none=wobei die mittlere Zeile eine einschränkung auf Dokumente mit den Tags 3,4 und 16 bedeutet.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
431
Online33.0k
Benutzer83.3k
Themen1.3m
Beiträge