

[Linux Shell-Skript] WLAN-Wetterstation
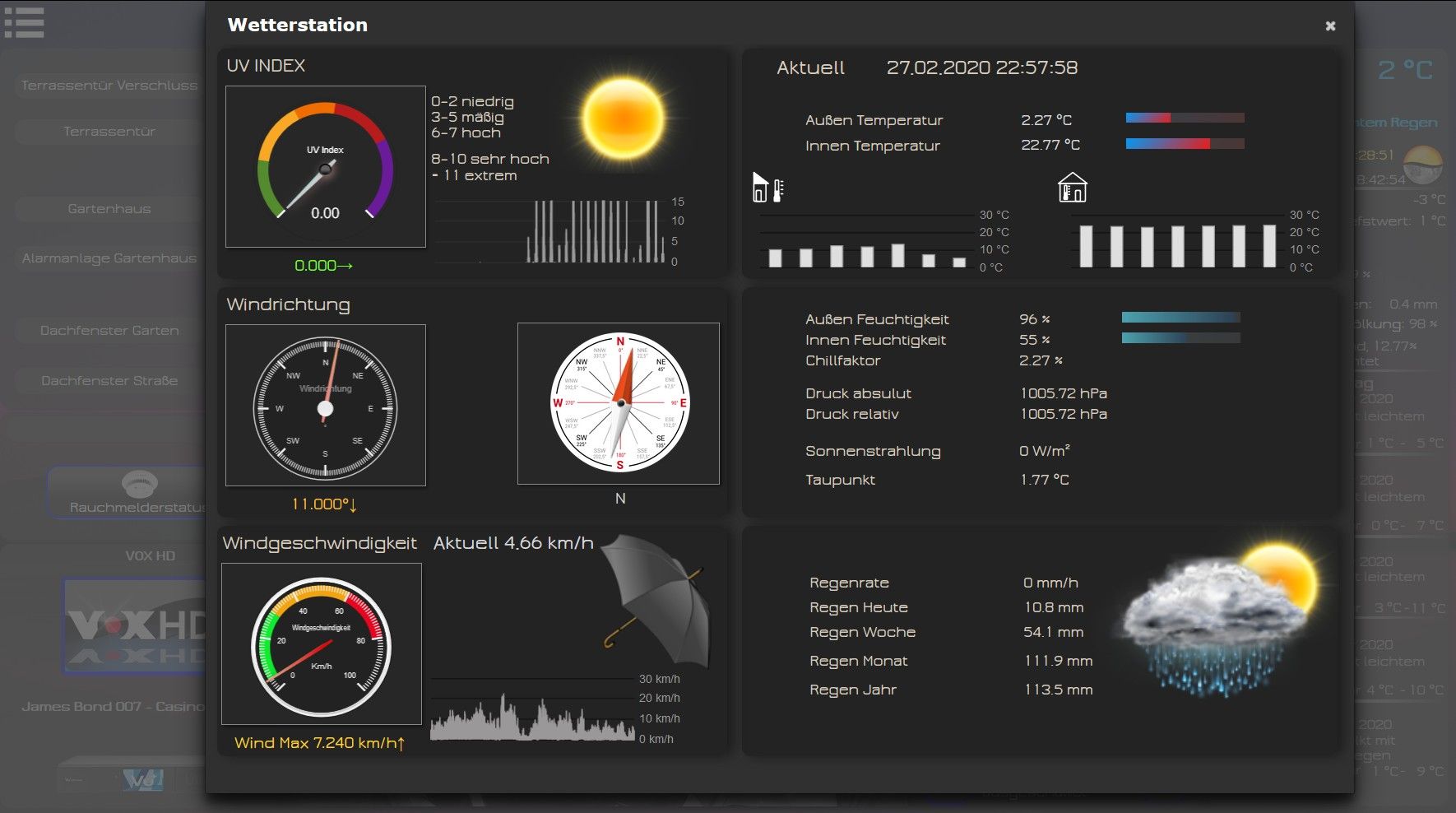
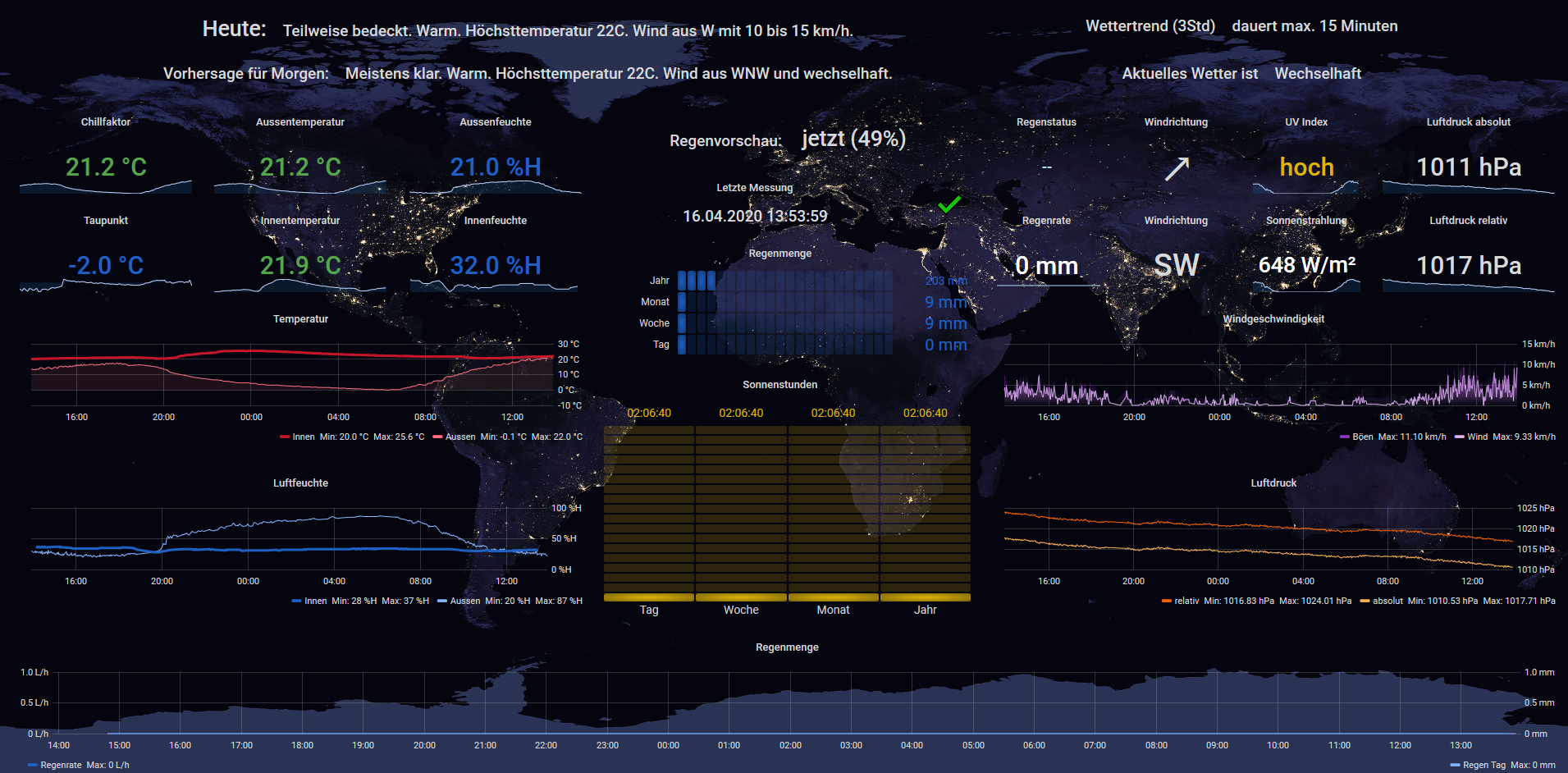
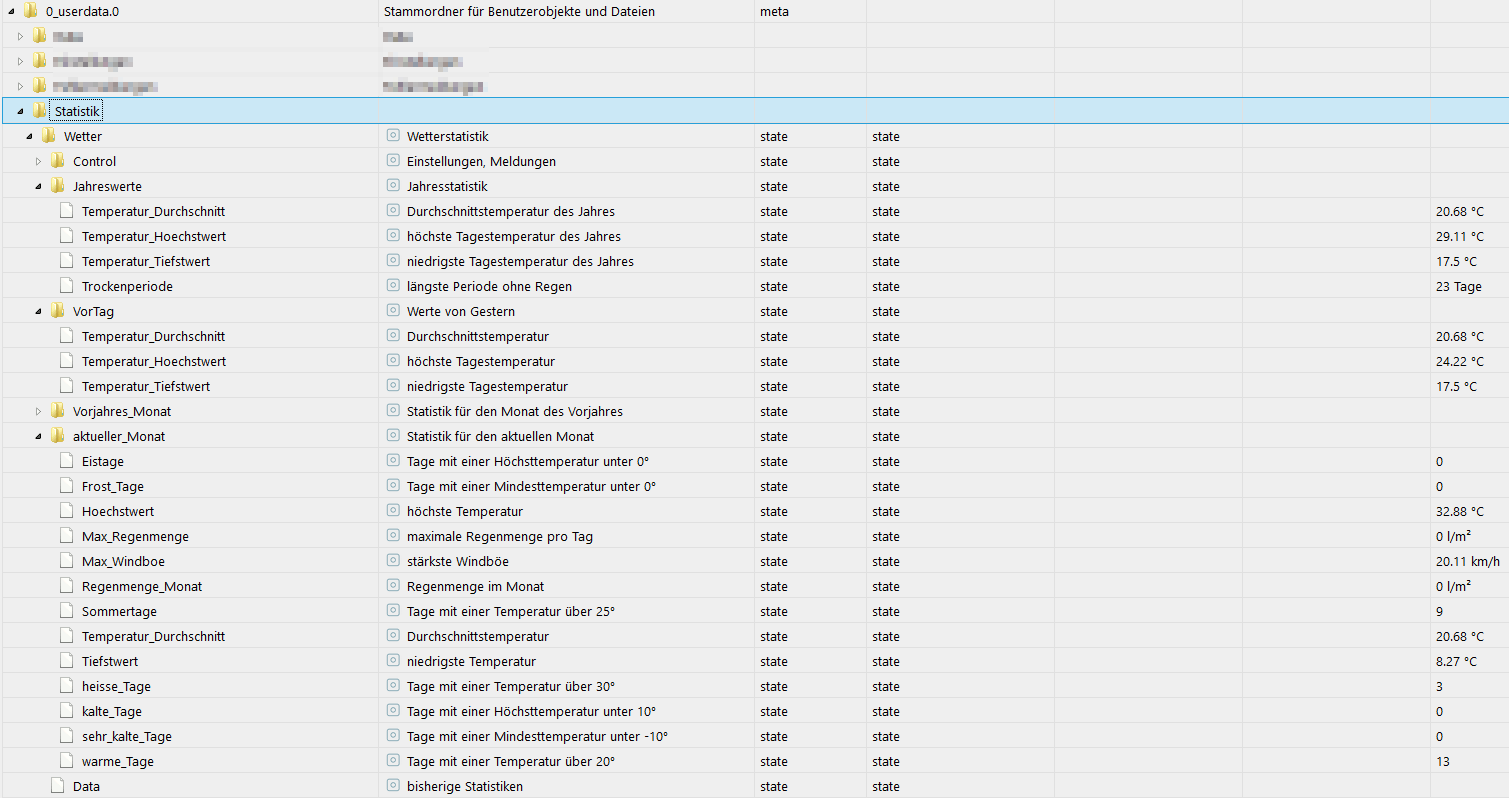
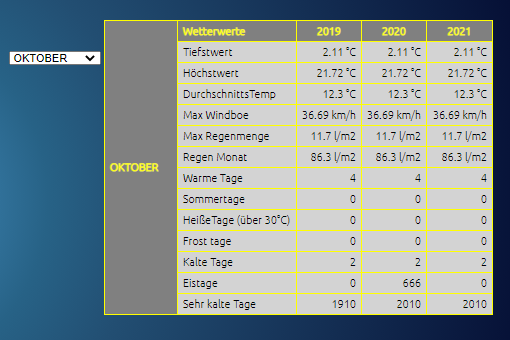
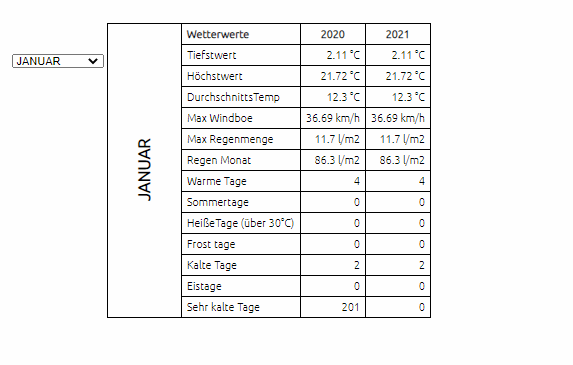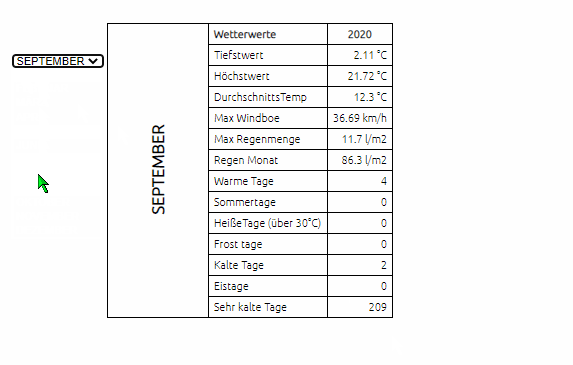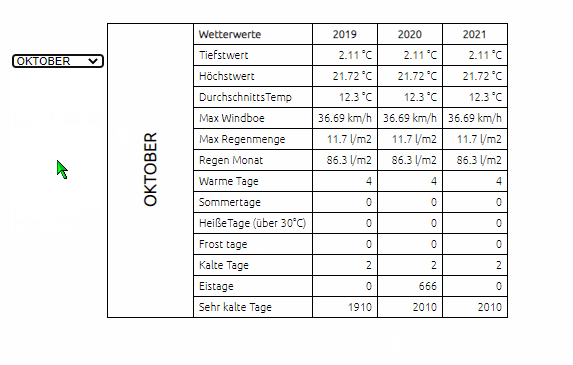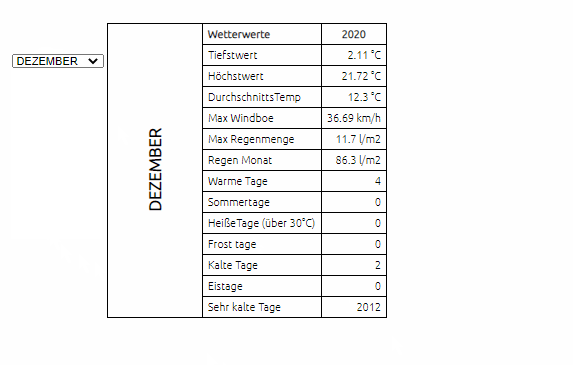
-
@negalein sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Mein Cousin ist gleich in der Nähe von mir.
Wenn er bei "Luftdaten" gemeldet ist, da würde ich dann die Werte aus dem ioB ziehen.
@martybr Sehr gut, der wird unterstützt. Dann können wir die zumindest schon mal mitsenden ;)
@sborg Ich helfe da gerne. Dein Script war der Grund für die Anschaffung der Froggit Wetterstation. Ich kann dir hier nur tausend mal Danken für deinen Unermüdlichen Einsatz. Es ist bemerkenswert, wie du an der Weiterentwicklung arbeitest und deinen Humor bei den vielen Fragen behältst.

Gruß
Martin
Intel NUCs mit Proxmox / Iobroker als VM unter Debian
Raspeberry mit USB Leseköpfen für Smartmeter
Homematic und Homematic IP -
Hallo zusammen,
ich hätte da mal eine Frage. mein Vater hat mich mit dem ganzen Thema etwas angefixt. Er ist Amateurfunker und hat in seinem Hobbyraum eine ganze Station um Wetterbilder von Meteosat zu empfangen.
Aber zu meiner Frage, ich habe vor mir die Froggit HP1000SE PRO Display inkl. Innensensor + DP40 Aussen Temperatur/Luftfeuchte + DP80 Regensensor + DP300 Anemometer zu kaufen. Wie läuft das mit dem DP80 Regensensor? Der steht ja nicht in der Liste der Zusatzsensoren, wird der mit dem Display verbunden und dann so an ioBroker übermittelt oder wie kann ich mir das vorstellen?Danke und liebe Grüße aus dem Westerwald
Michael -
Hallo zusammen,
ich hätte da mal eine Frage. mein Vater hat mich mit dem ganzen Thema etwas angefixt. Er ist Amateurfunker und hat in seinem Hobbyraum eine ganze Station um Wetterbilder von Meteosat zu empfangen.
Aber zu meiner Frage, ich habe vor mir die Froggit HP1000SE PRO Display inkl. Innensensor + DP40 Aussen Temperatur/Luftfeuchte + DP80 Regensensor + DP300 Anemometer zu kaufen. Wie läuft das mit dem DP80 Regensensor? Der steht ja nicht in der Liste der Zusatzsensoren, wird der mit dem Display verbunden und dann so an ioBroker übermittelt oder wie kann ich mir das vorstellen?Danke und liebe Grüße aus dem Westerwald
Michael@sugomojawe sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Der steht ja nicht in der Liste der Zusatzsensoren, wird der mit dem Display verbunden und dann so an ioBroker übermittelt oder wie kann ich mir das vorstellen?
Hi, so ähnlich. Der wird mit dem Display verbunden (ähnlich wir pairing bei BT) und sendet seine Daten an das Display.
Dann muss man allerdings mal schauen ob er seine Werte als "regulärer Sensor" meldet (also so wie der Standardregensensor) oder als "externer". Dann brauche ich den Datenstring (erkläre ich dann) und du etwa 1-2 Tage Geduld, dann gibt es eine Testversion die dann hoffentlich (ich kanns halt selbst nicht testen) die Daten an den ioB meldet. Ansonsten muss ich halt schauen warum und wo es klemmt und eine weitere Version Online stellen bis es eben funktioniert ;)LG SBorg ( SBorg auf GitHub)
Projekte: Lebensmittelwarnung.de | WLAN-Wetterstation | PimpMyStation -
@sborg Ich helfe da gerne. Dein Script war der Grund für die Anschaffung der Froggit Wetterstation. Ich kann dir hier nur tausend mal Danken für deinen Unermüdlichen Einsatz. Es ist bemerkenswert, wie du an der Weiterentwicklung arbeitest und deinen Humor bei den vielen Fragen behältst.
@martybr sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Es ist bemerkenswert, wie du an der Weiterentwicklung arbeitest und deinen Humor bei den vielen Fragen behältst.
Ich denke jedes mal "jetzt ist aber Schluss, was soll denn jetzt noch neues kommen...?" ...und dann kommt doch wieder was

...und seinen Humor darf man nicht verlieren. Wenn irgendwas durch Trübsal blasen besser wird tue ich das auch. Solange dem nicht so ist bin ich gut drauf, lächle, reiße dumme Sprüche, macht einiges leichter.
-
@sugomojawe sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Der steht ja nicht in der Liste der Zusatzsensoren, wird der mit dem Display verbunden und dann so an ioBroker übermittelt oder wie kann ich mir das vorstellen?
Hi, so ähnlich. Der wird mit dem Display verbunden (ähnlich wir pairing bei BT) und sendet seine Daten an das Display.
Dann muss man allerdings mal schauen ob er seine Werte als "regulärer Sensor" meldet (also so wie der Standardregensensor) oder als "externer". Dann brauche ich den Datenstring (erkläre ich dann) und du etwa 1-2 Tage Geduld, dann gibt es eine Testversion die dann hoffentlich (ich kanns halt selbst nicht testen) die Daten an den ioB meldet. Ansonsten muss ich halt schauen warum und wo es klemmt und eine weitere Version Online stellen bis es eben funktioniert ;)@sborg said in [Linux Shell-Skript] WLAN-Wetterstation:
Dann brauche ich den Datenstring (erkläre ich dann) und du etwa 1-2 Tage Geduld
Das ist kein Problem, das werden wir hin bekommen. Ich melde mich dann wenn das gute Stück bei mir eingetrudelt ist.
-
@martybr sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Es ist bemerkenswert, wie du an der Weiterentwicklung arbeitest und deinen Humor bei den vielen Fragen behältst.
Ich denke jedes mal "jetzt ist aber Schluss, was soll denn jetzt noch neues kommen...?" ...und dann kommt doch wieder was
...und seinen Humor darf man nicht verlieren. Wenn irgendwas durch Trübsal blasen besser wird tue ich das auch. Solange dem nicht so ist bin ich gut drauf, lächle, reiße dumme Sprüche, macht einiges leichter.
@sborg mal eine Frage zur INflux DB und der Retention Time
Reicht hier eine Retention Time der Werte von 31 Tage
Natürlich speichere ich die Daten in eine andere Influxdb über Tasks hier werden die Daten dann auf alle 15 minuten gedownsamplet.
Danke für deine Auskunft.
-
@negalein
 Ich will aber auch keine Phantasiewerte in die AWEKAS-DB schreiben. Falls sich keiner melden sollte, hat wohl auch keiner Interesse daran ;)
Ich will aber auch keine Phantasiewerte in die AWEKAS-DB schreiben. Falls sich keiner melden sollte, hat wohl auch keiner Interesse daran ;)
Ich kann natürlich auch bspw. die aktuelle Luftgüte von einem Sensor hier in der Nähe zum testen so einpatchen als hätte ich sie gemessen. 2km auf dem Land werden da nicht so signifikant unterschiedlich sein......und ich überlege da immer 5x, dann kommt meist ein "Nein" dabei raus.
@sborg
Ich habe nur Bodenfeuchte-Sensoren DP100 für Bewässerungssteuerung.
Ich denke AWEKAS interessiert sich auch nicht für die Temperatur und Feuchte im Tomatenhaus... -
@sugomojawe sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Der steht ja nicht in der Liste der Zusatzsensoren, wird der mit dem Display verbunden und dann so an ioBroker übermittelt oder wie kann ich mir das vorstellen?
Hi, so ähnlich. Der wird mit dem Display verbunden (ähnlich wir pairing bei BT) und sendet seine Daten an das Display.
Dann muss man allerdings mal schauen ob er seine Werte als "regulärer Sensor" meldet (also so wie der Standardregensensor) oder als "externer". Dann brauche ich den Datenstring (erkläre ich dann) und du etwa 1-2 Tage Geduld, dann gibt es eine Testversion die dann hoffentlich (ich kanns halt selbst nicht testen) die Daten an den ioB meldet. Ansonsten muss ich halt schauen warum und wo es klemmt und eine weitere Version Online stellen bis es eben funktioniert ;)(ähnlich wir pairing bei BT)Ich glaube nicht dass die Sensoren gepaired werden. Die Station horcht eher nach den ID's
Ich konnte parallel die Daten auf einem GW1000 und GW2000 empfangen! -
@Sugomojawe
Zu den Wetterstationen und Sensoren kann ich das deutsche Wetterstationsforum empfehlen. Dort steht auch im WIKI zu der Station der DP 80 drin drin.
Die sind auch aktuell mit den Infos zu den Firmwares. -
@boronsbruder said in [Linux Shell-Skript] WLAN-Wetterstation:
kann ich das deutsche Wetterstationsforum empfehlen
Danke das werde ich mir mal ansehen.
-
@sborg mal eine Frage zur INflux DB und der Retention Time
Reicht hier eine Retention Time der Werte von 31 Tage
Natürlich speichere ich die Daten in eine andere Influxdb über Tasks hier werden die Daten dann auf alle 15 minuten gedownsamplet.
Danke für deine Auskunft.
@babl sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@sborg mal eine Frage zur INflux DB und der Retention Time
Reicht hier eine Retention Time der Werte von 31 Tage
Natürlich speichere ich die Daten in eine andere Influxdb über Tasks hier werden die Daten dann auf alle 15 minuten gedownsamplet.
Danke für deine Auskunft.
Kann man/ich nicht so pauschal beantworten. Es kommt ganz darauf an was du mit den Daten anstellen willst. Wenn du einen Grafana-Chart über 3 Monate exakt darstellen möchtest, nein. Willst du das nicht bzw. genügen dir die aggregierten Werte, dann ja. Es kann ja auch sein, dass du ein Blockly für xyz nutzt und da die Daten unbedingt brauchst. Deswegen kann ich schlecht ja oder nein sagen, das hängt zu stark vom User ab. Pauschal für die meisten Anwender aber ja ;)
Nimmst du das Beispiel-Grafana genügen die 31 Tage.
Mir genügt ebenfalls ein 15 Minutendurchschnitt. Reduziert die Datenflut maßgeblich und wer braucht schon vom 18.05.2023 um 23:12 Uhr die genaue Temperatur? Der Wert von 23:00 Uhr bis 23:15 Uhr wird sich eh nur wenig oder gar nicht geändert haben, und selbst wenn gibt es ja dafür dann den aggregierten Wert der das berücksichtigt. -
@sborg
Ich habe nur Bodenfeuchte-Sensoren DP100 für Bewässerungssteuerung.
Ich denke AWEKAS interessiert sich auch nicht für die Temperatur und Feuchte im Tomatenhaus...@boronsbruder sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@sborg
Ich habe nur Bodenfeuchte-Sensoren DP100 für Bewässerungssteuerung.
Ich denke AWEKAS interessiert sich auch nicht für die Temperatur und Feuchte im Tomatenhaus...AWEKAS nicht unbedingt, aber du fährst in Urlaub und dein Bruder soll währenddessen auf deine Tomaten aufpassen. Du (ich zumindest nicht) willst aber nicht dein SmartHome ins Inet stellen. Da wäre es doch praktisch er könnte die Bodenwerte in AWEKAS ablesen. Oder, oder ...
Du wirst sie nicht übertragen müssen, dass wird jedem User überlassen werden ob er das will oder nicht. Aktuell wäre es halt gut wenn eine Handvoll zumindest zum testen mal mit macht.@boronsbruder sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Ich glaube nicht dass die Sensoren gepaired werden.
Deswegen auch "ähnlich". Wie bei BT werden sie nicht "fest" und nur pro Device/Gerät verbunden, sie werden aber gekoppelt (der Begriff fiel mir gestern nicht ein). Sonst könnte ich ja bspw. denken "Ups, muss meinen Pool heizen, der ist ja ar*ch kalt", dabei empfange ich gerade nicht mein Thermometer, sondern das vom Nachbarn.
Ich habs wieder vergessen, aber da war was mit x Sekunden Reset am Sensor drücken und irgendwas für x Sekunden am Display/Station (GWs weiß ich überhaupt nicht)....und nein, ich habe weder das Thermometer, noch den/einen Pool, nicht mal ein Plantschbecken ;)
LG SBorg ( SBorg auf GitHub)
Projekte: Lebensmittelwarnung.de | WLAN-Wetterstation | PimpMyStation -
@babl sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@sborg mal eine Frage zur INflux DB und der Retention Time
Reicht hier eine Retention Time der Werte von 31 Tage
Natürlich speichere ich die Daten in eine andere Influxdb über Tasks hier werden die Daten dann auf alle 15 minuten gedownsamplet.
Danke für deine Auskunft.
Kann man/ich nicht so pauschal beantworten. Es kommt ganz darauf an was du mit den Daten anstellen willst. Wenn du einen Grafana-Chart über 3 Monate exakt darstellen möchtest, nein. Willst du das nicht bzw. genügen dir die aggregierten Werte, dann ja. Es kann ja auch sein, dass du ein Blockly für xyz nutzt und da die Daten unbedingt brauchst. Deswegen kann ich schlecht ja oder nein sagen, das hängt zu stark vom User ab. Pauschal für die meisten Anwender aber ja ;)
Nimmst du das Beispiel-Grafana genügen die 31 Tage.
Mir genügt ebenfalls ein 15 Minutendurchschnitt. Reduziert die Datenflut maßgeblich und wer braucht schon vom 18.05.2023 um 23:12 Uhr die genaue Temperatur? Der Wert von 23:00 Uhr bis 23:15 Uhr wird sich eh nur wenig oder gar nicht geändert haben, und selbst wenn gibt es ja dafür dann den aggregierten Wert der das berücksichtigt. -
@sborg jepp so sehe ich das auch, ich meinte nur obe es von dir her reicht mit deinem Statistik Addon
@babl Der nimmt was er kriegt. Bekommt er 5 Werte der Temperatur macht er da min/max/avg daraus, bekommt er 500 dann eben aus den 500 ;)
Ist jetzt zwar extrem abstrakt, aber genau so isses halt. Mit mehr Werten ist es halt etwas genauer, aber irgendwann wird es auch durch mehr Werte nicht mehr genauer (und die rund 3k Werte pro Tag der Station sind dafür wirklich nicht nötig). Für den Tagesverlauf genügen da die 96 Werte völlig und rückwirkend reden wir hier auch von Temperaturen von vor 30 Tagen und mehr.
...und wozu sollte man sich da den Kopf zerbrechen ob es am 03. Juni nun tatsächlich 28.21°C oder 28.12°C waren, wenn die Drift und Genauigkeit des Temperatursensors sowieso +/- 0.5°C beträgt... -
@boronsbruder sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@sborg
Ich habe nur Bodenfeuchte-Sensoren DP100 für Bewässerungssteuerung.
Ich denke AWEKAS interessiert sich auch nicht für die Temperatur und Feuchte im Tomatenhaus...AWEKAS nicht unbedingt, aber du fährst in Urlaub und dein Bruder soll währenddessen auf deine Tomaten aufpassen. Du (ich zumindest nicht) willst aber nicht dein SmartHome ins Inet stellen. Da wäre es doch praktisch er könnte die Bodenwerte in AWEKAS ablesen. Oder, oder ...
Du wirst sie nicht übertragen müssen, dass wird jedem User überlassen werden ob er das will oder nicht. Aktuell wäre es halt gut wenn eine Handvoll zumindest zum testen mal mit macht.@boronsbruder sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Ich glaube nicht dass die Sensoren gepaired werden.
Deswegen auch "ähnlich". Wie bei BT werden sie nicht "fest" und nur pro Device/Gerät verbunden, sie werden aber gekoppelt (der Begriff fiel mir gestern nicht ein). Sonst könnte ich ja bspw. denken "Ups, muss meinen Pool heizen, der ist ja ar*ch kalt", dabei empfange ich gerade nicht mein Thermometer, sondern das vom Nachbarn.
Ich habs wieder vergessen, aber da war was mit x Sekunden Reset am Sensor drücken und irgendwas für x Sekunden am Display/Station (GWs weiß ich überhaupt nicht)....und nein, ich habe weder das Thermometer, noch den/einen Pool, nicht mal ein Plantschbecken ;)
Hallo Zusammen,
nach 3 Tagen ausprobieren bin ich kurz vorm Aufgeben.
Bin vor 3 Wochen auf Influx v2.7 umgestiegen. Nach IOBroker Daten umscheffeln von V1.8 mit ack/q/from als fields in tags war der letzte offene Punkt, dass ich seit dem Umstieg auf V3.1.1 des Wetterstation.sh keine min/max/365t_... mehr bekomme.
Im IOBroker sehen die Objekte so aus:

Ein Wetterstation.sh --influx_test liefert komischer Weise die Temperaturen doppelt, bzw. eine leicht erhöhte Regenmenge...:
pi@rpi-heizung:~/wetterstation $ ./wetterstation.sh --influx_test Testing InfluxDB... min/max Aussentemperatur 24h: 16.27 16.27°C 32 32°C pi@rpi-heizung:~/wetterstation $ ./wetterstation.sh --metsommer Daten vom 01.06.2023 bis 31.08.2023 wurden ermittelt... Ø-Temperatur: 19.697241893242822000 °C Regenmenge : 20230831235959 l/m² pi@rpi-heizung:~/wetterstation $Die Influx Abfrage scheint generell also zu funktionieren.
Zuerst hatte ich die Umlaute in Verdacht, da bei obigem Test nicht °C sondern  ... stand.
Aber nachdem ich das berichtigt hatte landeten immer noch keine richtigen Werte in den Objekten?!In den Objekten stehen als Einheiten die °C richtig drin. Grafana zeigt mir auch einen hübschen Graphen der Außentemperatur.
Hat jemand weitere Ideen?
Im Tausch kann ich gerne mein Bash-Script zum automatischen umscheffeln der V1.8 IOBroker-Daten (mit Fields) in V2.7 (mit Tags) anbieten (natürlich in einem gesonderten Thread). Auch wenn das dank meiner nur rudimentären Programmierkenntnisse bestimmt nicht allzu professionell ist... (aber es funktioniert ;o) )Gruß
Hefo -
@boronsbruder sagte in [Linux Shell-Skript] WLAN-Wetterstation:
@sborg
Ich habe nur Bodenfeuchte-Sensoren DP100 für Bewässerungssteuerung.
Ich denke AWEKAS interessiert sich auch nicht für die Temperatur und Feuchte im Tomatenhaus...AWEKAS nicht unbedingt, aber du fährst in Urlaub und dein Bruder soll währenddessen auf deine Tomaten aufpassen. Du (ich zumindest nicht) willst aber nicht dein SmartHome ins Inet stellen. Da wäre es doch praktisch er könnte die Bodenwerte in AWEKAS ablesen. Oder, oder ...
Du wirst sie nicht übertragen müssen, dass wird jedem User überlassen werden ob er das will oder nicht. Aktuell wäre es halt gut wenn eine Handvoll zumindest zum testen mal mit macht.@boronsbruder sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Ich glaube nicht dass die Sensoren gepaired werden.
Deswegen auch "ähnlich". Wie bei BT werden sie nicht "fest" und nur pro Device/Gerät verbunden, sie werden aber gekoppelt (der Begriff fiel mir gestern nicht ein). Sonst könnte ich ja bspw. denken "Ups, muss meinen Pool heizen, der ist ja ar*ch kalt", dabei empfange ich gerade nicht mein Thermometer, sondern das vom Nachbarn.
Ich habs wieder vergessen, aber da war was mit x Sekunden Reset am Sensor drücken und irgendwas für x Sekunden am Display/Station (GWs weiß ich überhaupt nicht)....und nein, ich habe weder das Thermometer, noch den/einen Pool, nicht mal ein Plantschbecken ;)
@sborg sagte in [Linux Shell-Skript] WLAN-Wetterstation:
und dein Bruder soll währenddessen auf deine Tomaten aufpassen
Ich hab nen Bruder? Cool

-
@sborg sagte in [Linux Shell-Skript] WLAN-Wetterstation:
und dein Bruder soll währenddessen auf deine Tomaten aufpassen
Ich hab nen Bruder? Cool
@boronsbruder sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Ich hab nen Bruder? Cool
Logo, heißt doch Boron...
...so, und jetzt kannst du mal paar Tomaten rüber wachsen lassen...
@Hefo Wie sieht den deine Datenstruktur genau aus? Taggen der Werte unterstütze ich aktuell nämlich nicht, da dies auch vom ioB nur recht rudimentär aktuell umgesetzt ist. Das würde zu deinem Fehlerbild passen. Der Test baut einfach nur eine Verbindung zu Influx auf und ließt dann einen Wert aus. Somit ist einfach sichergestellt, dass Port, IP, Bucket usw. korrekt sind.
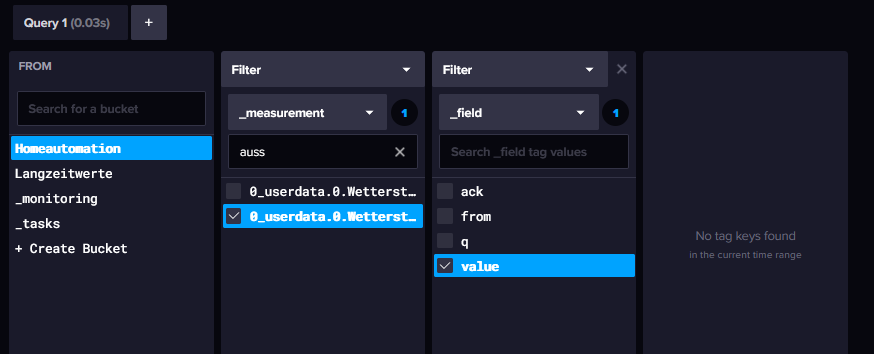
-
@boronsbruder sagte in [Linux Shell-Skript] WLAN-Wetterstation:
Ich hab nen Bruder? Cool
Logo, heißt doch Boron...
...so, und jetzt kannst du mal paar Tomaten rüber wachsen lassen...
@Hefo Wie sieht den deine Datenstruktur genau aus? Taggen der Werte unterstütze ich aktuell nämlich nicht, da dies auch vom ioB nur recht rudimentär aktuell umgesetzt ist. Das würde zu deinem Fehlerbild passen. Der Test baut einfach nur eine Verbindung zu Influx auf und ließt dann einen Wert aus. Somit ist einfach sichergestellt, dass Port, IP, Bucket usw. korrekt sind.
@sborg
Oh Mann, da hätte ich doch auch selbst drauf kommen können. Ich war in einem anderen Zusammenhang schon über Mehrfachwerte bei Flux-Abfragen gestolpert...Aber OK, der Reihe nach.
Ich habe beim Umstieg auf Influx 2.7 eine neue IOBroker DB "iobroker2/global" angelegt. Die alten "iobroker/global" und "iobroker/autogen wurden ja automatisch beim Influx-Umstieg migriert.
Im IOBroker habe ich dann im Influx-Adapter das Häkchen für "Verwende Tags, anstelle von Feldern,..." gesetzt, da es mir immer spanisch vorkam, dass die als Felder geschrieben wurden (passte nicht zu der Erklärung in der Influx-Doku).
Ich hatte auch die Hoffnung, dass das den Arbeitsspeicherhunger der Influx etwas bändigen könnte, an der Stelle hat es aber nicht geholfen, die gönnt sich immer noch 50% mehr als vor dem Umstieg die 1.8.x.
Dafür ist, nach umkopieren der alten "iobroker/global" in die neue "iobroker2/global" die Datenbank auf der SSD keine 1,6GB mehr groß sondern nur noch 600MB.Allerdings zum eigendlichen Problem:
Eine Abfrage in Flux liefert die Ergebnisse dann immer sortiert in "tables". Die Tables haben immer die identischen Werte der Tags gruppiert.
D.h. alles was an Tags q=0, ack=true, from=system.adapter.influxdb.0 hat landet in einem Table. Alles was q=0, ack=true, from=system.adapter.simple-api.0 im nächsten. Wenn q nicht gleich 0 oder ack=false gibt es weitere tables.Heißt, man muß diese Tables vor dem min/max/mean, bzw. generell vor dem Weiterverarbeiten, erstmal zusammenführen.
Das habe ich bei dem oben genannten "anderen Zusammenhang" durch ein zwischengeschaltetes:
|> drop(columns: ["ack", "from", "q"]) |> sort(columns: ["_time"])gemacht.
Was natürlich die Gefahr birgt, dass der Influx-Adapter in Zukunft mal weitere Tags einführt...Es ginge auch mit einem:
|> keep(columns: ["_value"]) |> sort(columns: ["_time"])dann ist die Ausgabe aber anders formatiert.
Beispiele:
Die Ursprungs-query aus der wetterstation.sub "influx_query()" Funktion liefert dieses Ergebnis:influx query 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> max()' Result: _result Table: keys: [_start, _stop, _field, _measurement, ack, from, q] _start:time _stop:time _field:string _measurement:string ack:string from:string q:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ------------------------------------------- ---------------------- ------------------------- ---------------------- ------------------------------ ---------------------------- 2023-08-19T11:50:41.246763433Z 2023-08-20T11:50:41.246763433Z value javascript.0.Wetterstation.Aussentemperatur true system.adapter.influxdb.0 0 2023-08-19T12:16:26.633000000Z 31.22 Table: keys: [_start, _stop, _field, _measurement, ack, from, q] _start:time _stop:time _field:string _measurement:string ack:string from:string q:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ------------------------------------------- ---------------------- --------------------------- ---------------------- ------------------------------ ---------------------------- 2023-08-19T11:50:41.246763433Z 2023-08-20T11:50:41.246763433Z value javascript.0.Wetterstation.Aussentemperatur true system.adapter.simple-api.0 0 2023-08-19T12:15:26.615000000Z 31.22Ergänzt mit dem "drop" und "sort" nur noch ein Table:
influx query 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> drop(columns: ["ack", "from", "q"]) |> sort(columns: ["_time"]) |> max()' Result: _result Table: keys: [_start, _stop, _field, _measurement] _start:time _stop:time _field:string _measurement:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ------------------------------------------- ------------------------------ ---------------------------- 2023-08-19T11:57:11.324077570Z 2023-08-20T11:57:11.324077570Z value javascript.0.Wetterstation.Aussentemperatur 2023-08-19T12:15:26.615000000Z 31.22Das sieht dann meiner Meinung nach so aus, wie dass, was Deine Abfrage liefert (hier an einer anderen meiner DBs, die keine Tags hat, probiert):
influx query 'from(bucket: "vito2/autogen") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "vito" and r._field == "TempAtp") |> max()' Result: _result Table: keys: [_start, _stop, _field, _measurement] _start:time _stop:time _field:string _measurement:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ---------------------------- 2023-08-19T12:03:41.255250302Z 2023-08-20T12:03:41.255250302Z TempAtp vito 2023-08-19T12:35:00.000000000Z 28.6Nur zur Ergänzung: die Ausgabe mit dem "keep" sieht völlig anders (und viel übersichtlicher) aus:
influx query 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> keep(columns: ["_value"]) |> sort(columns: ["_time"]) |> max()' Result: _result Table: keys: [] _value:float ---------------------------- 31.22Was ich jetzt noch nicht ausprobiert habe ist, ob das Resultat identisch aussieht, wenn man anstatt der influx-cli zum Abfragen curl nimmt (wie in Deinem Script)?!
Und was ich so ad hoc auch nicht absehen kann: Ob ein Ergänzen der Query in der Funktion influx_query() um das "drop" und "sort" an anderer Stelle eine negative Auswirkung hat?!
NaJa, Versuch macht kluch... ich baue es mal in die .sub ein und teste mit --influx_test und --metsommer
Gruß
Hefo -
@sborg
Oh Mann, da hätte ich doch auch selbst drauf kommen können. Ich war in einem anderen Zusammenhang schon über Mehrfachwerte bei Flux-Abfragen gestolpert...Aber OK, der Reihe nach.
Ich habe beim Umstieg auf Influx 2.7 eine neue IOBroker DB "iobroker2/global" angelegt. Die alten "iobroker/global" und "iobroker/autogen wurden ja automatisch beim Influx-Umstieg migriert.
Im IOBroker habe ich dann im Influx-Adapter das Häkchen für "Verwende Tags, anstelle von Feldern,..." gesetzt, da es mir immer spanisch vorkam, dass die als Felder geschrieben wurden (passte nicht zu der Erklärung in der Influx-Doku).
Ich hatte auch die Hoffnung, dass das den Arbeitsspeicherhunger der Influx etwas bändigen könnte, an der Stelle hat es aber nicht geholfen, die gönnt sich immer noch 50% mehr als vor dem Umstieg die 1.8.x.
Dafür ist, nach umkopieren der alten "iobroker/global" in die neue "iobroker2/global" die Datenbank auf der SSD keine 1,6GB mehr groß sondern nur noch 600MB.Allerdings zum eigendlichen Problem:
Eine Abfrage in Flux liefert die Ergebnisse dann immer sortiert in "tables". Die Tables haben immer die identischen Werte der Tags gruppiert.
D.h. alles was an Tags q=0, ack=true, from=system.adapter.influxdb.0 hat landet in einem Table. Alles was q=0, ack=true, from=system.adapter.simple-api.0 im nächsten. Wenn q nicht gleich 0 oder ack=false gibt es weitere tables.Heißt, man muß diese Tables vor dem min/max/mean, bzw. generell vor dem Weiterverarbeiten, erstmal zusammenführen.
Das habe ich bei dem oben genannten "anderen Zusammenhang" durch ein zwischengeschaltetes:
|> drop(columns: ["ack", "from", "q"]) |> sort(columns: ["_time"])gemacht.
Was natürlich die Gefahr birgt, dass der Influx-Adapter in Zukunft mal weitere Tags einführt...Es ginge auch mit einem:
|> keep(columns: ["_value"]) |> sort(columns: ["_time"])dann ist die Ausgabe aber anders formatiert.
Beispiele:
Die Ursprungs-query aus der wetterstation.sub "influx_query()" Funktion liefert dieses Ergebnis:influx query 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> max()' Result: _result Table: keys: [_start, _stop, _field, _measurement, ack, from, q] _start:time _stop:time _field:string _measurement:string ack:string from:string q:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ------------------------------------------- ---------------------- ------------------------- ---------------------- ------------------------------ ---------------------------- 2023-08-19T11:50:41.246763433Z 2023-08-20T11:50:41.246763433Z value javascript.0.Wetterstation.Aussentemperatur true system.adapter.influxdb.0 0 2023-08-19T12:16:26.633000000Z 31.22 Table: keys: [_start, _stop, _field, _measurement, ack, from, q] _start:time _stop:time _field:string _measurement:string ack:string from:string q:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ------------------------------------------- ---------------------- --------------------------- ---------------------- ------------------------------ ---------------------------- 2023-08-19T11:50:41.246763433Z 2023-08-20T11:50:41.246763433Z value javascript.0.Wetterstation.Aussentemperatur true system.adapter.simple-api.0 0 2023-08-19T12:15:26.615000000Z 31.22Ergänzt mit dem "drop" und "sort" nur noch ein Table:
influx query 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> drop(columns: ["ack", "from", "q"]) |> sort(columns: ["_time"]) |> max()' Result: _result Table: keys: [_start, _stop, _field, _measurement] _start:time _stop:time _field:string _measurement:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ------------------------------------------- ------------------------------ ---------------------------- 2023-08-19T11:57:11.324077570Z 2023-08-20T11:57:11.324077570Z value javascript.0.Wetterstation.Aussentemperatur 2023-08-19T12:15:26.615000000Z 31.22Das sieht dann meiner Meinung nach so aus, wie dass, was Deine Abfrage liefert (hier an einer anderen meiner DBs, die keine Tags hat, probiert):
influx query 'from(bucket: "vito2/autogen") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "vito" and r._field == "TempAtp") |> max()' Result: _result Table: keys: [_start, _stop, _field, _measurement] _start:time _stop:time _field:string _measurement:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ---------------------------- 2023-08-19T12:03:41.255250302Z 2023-08-20T12:03:41.255250302Z TempAtp vito 2023-08-19T12:35:00.000000000Z 28.6Nur zur Ergänzung: die Ausgabe mit dem "keep" sieht völlig anders (und viel übersichtlicher) aus:
influx query 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> keep(columns: ["_value"]) |> sort(columns: ["_time"]) |> max()' Result: _result Table: keys: [] _value:float ---------------------------- 31.22Was ich jetzt noch nicht ausprobiert habe ist, ob das Resultat identisch aussieht, wenn man anstatt der influx-cli zum Abfragen curl nimmt (wie in Deinem Script)?!
Und was ich so ad hoc auch nicht absehen kann: Ob ein Ergänzen der Query in der Funktion influx_query() um das "drop" und "sort" an anderer Stelle eine negative Auswirkung hat?!
NaJa, Versuch macht kluch... ich baue es mal in die .sub ein und teste mit --influx_test und --metsommer
Gruß
Hefo@SBorg
Schade, das war wohl zu einfach gedacht...pi@rpi-heizung:~/wetterstation $ ./wetterstation.sh --influx_test Testing InfluxDB... min/max Aussentemperatur 24h: 18.77°C 29.61°C pi@rpi-heizung:~/wetterstation $ ./wetterstation.sh --metsommer (standard_in) 12: illegal character: : (standard_in) 12: syntax error (standard_in) 12: illegal character: : Daten vom 01.06.2023 bis 31.08.2023 wurden ermittelt... Ø-Temperatur: °C Regenmenge : 20230831235959 l/m²Die min & max bekommt er so hin, den mean anscheinend nicht... (Regen ist klar, ist ja eine andere Abfrage im sub).
Warum auch immer ist die Sortierung der Felder eine andere bei mean als bei min/max und bei min/max ist auch noch der Zeitpunkt des min/max dabei:
curl -sk --request POST "1.2.3.4:8086/api/v2/query?org=HomeData" --header 'Content-Type: application/vnd.flux' --header 'Accept: application/csv' --header "Authorization: Token MeinToken==" --data 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> drop(columns: ["ack", "from", "q"]) |> sort(columns: ["_time"]) |> min()' ,result,table,_start,_stop,_time,_value,_field,_measurement ,_result,0,2023-08-19T19:04:42.48857557Z,2023-08-20T19:04:42.48857557Z,2023-08-20T02:08:35.984Z,18.77,value,javascript.0.Wetterstation.Aussentemperatur curl -sk --request POST "1.2.3.4:8086/api/v2/query?org=HomeData" --header 'Content-Type: application/vnd.flux' --header 'Accept: application/csv' --header "Authorization: Token MeinToken==" --data 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> drop(columns: ["ack", "from", "q"]) |> sort(columns: ["_time"]) |> mean()' ,result,table,_start,_stop,_field,_measurement,_value ,_result,0,2023-08-19T19:04:46.528387642Z,2023-08-20T19:04:46.528387642Z,value,javascript.0.Wetterstation.Aussentemperatur,23.941339648173376Mit dem "keep" wären beide Results gleich formatiert, nur halt etwas anders / kürzer als bis jetzt in Deinem Script:
curl -sk --request POST "1.2.3.4:8086/api/v2/query?org=HomeData" --header 'Content-Type: application/vnd.flux' --header 'Accept: application/csv' --header "Authorization: Token MeinToken==" --data 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> keep(columns: ["_value"]) |> sort(columns: ["_time"]) |> mean()' ,result,table,_value ,_result,0,23.941460117170056 curl -sk --request POST "1.2.3.4:8086/api/v2/query?org=HomeData" --header 'Content-Type: application/vnd.flux' --header 'Accept: application/csv' --header "Authorization: Token MeinToken==" --data 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> keep(columns: ["_value"]) |> sort(columns: ["_time"]) |> max()' ,result,table,_value ,_result,0,29.61Gruß
Hefo -
@SBorg
Schade, das war wohl zu einfach gedacht...pi@rpi-heizung:~/wetterstation $ ./wetterstation.sh --influx_test Testing InfluxDB... min/max Aussentemperatur 24h: 18.77°C 29.61°C pi@rpi-heizung:~/wetterstation $ ./wetterstation.sh --metsommer (standard_in) 12: illegal character: : (standard_in) 12: syntax error (standard_in) 12: illegal character: : Daten vom 01.06.2023 bis 31.08.2023 wurden ermittelt... Ø-Temperatur: °C Regenmenge : 20230831235959 l/m²Die min & max bekommt er so hin, den mean anscheinend nicht... (Regen ist klar, ist ja eine andere Abfrage im sub).
Warum auch immer ist die Sortierung der Felder eine andere bei mean als bei min/max und bei min/max ist auch noch der Zeitpunkt des min/max dabei:
curl -sk --request POST "1.2.3.4:8086/api/v2/query?org=HomeData" --header 'Content-Type: application/vnd.flux' --header 'Accept: application/csv' --header "Authorization: Token MeinToken==" --data 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> drop(columns: ["ack", "from", "q"]) |> sort(columns: ["_time"]) |> min()' ,result,table,_start,_stop,_time,_value,_field,_measurement ,_result,0,2023-08-19T19:04:42.48857557Z,2023-08-20T19:04:42.48857557Z,2023-08-20T02:08:35.984Z,18.77,value,javascript.0.Wetterstation.Aussentemperatur curl -sk --request POST "1.2.3.4:8086/api/v2/query?org=HomeData" --header 'Content-Type: application/vnd.flux' --header 'Accept: application/csv' --header "Authorization: Token MeinToken==" --data 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> drop(columns: ["ack", "from", "q"]) |> sort(columns: ["_time"]) |> mean()' ,result,table,_start,_stop,_field,_measurement,_value ,_result,0,2023-08-19T19:04:46.528387642Z,2023-08-20T19:04:46.528387642Z,value,javascript.0.Wetterstation.Aussentemperatur,23.941339648173376Mit dem "keep" wären beide Results gleich formatiert, nur halt etwas anders / kürzer als bis jetzt in Deinem Script:
curl -sk --request POST "1.2.3.4:8086/api/v2/query?org=HomeData" --header 'Content-Type: application/vnd.flux' --header 'Accept: application/csv' --header "Authorization: Token MeinToken==" --data 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> keep(columns: ["_value"]) |> sort(columns: ["_time"]) |> mean()' ,result,table,_value ,_result,0,23.941460117170056 curl -sk --request POST "1.2.3.4:8086/api/v2/query?org=HomeData" --header 'Content-Type: application/vnd.flux' --header 'Accept: application/csv' --header "Authorization: Token MeinToken==" --data 'from(bucket: "iobroker2/global") |> range(start: -1d, stop: now()) |> filter(fn: (r) => r._measurement == "javascript.0.Wetterstation.Aussentemperatur" and r._field == "value") |> keep(columns: ["_value"]) |> sort(columns: ["_time"]) |> max()' ,result,table,_value ,_result,0,29.61Gruß
Hefo@SBorg
So, ich glaube, jetzt klappt es...Die Funktionen influx_query und metsommer sehen bei mir jetzt so aus und liefern richtige Werte:
influx_query() { #1 Timerange start #2 Timerange stop #3 Measurement #4 min,max,mean IFS="," ii=0 local TMP_DATA=$(curl -sk --request POST "${INFLUX_WEB}://${INFLUX_API}/api/v2/query?org=${INFLUX_ORG}" --header 'Content-Type: application/vnd.flux' \ --header 'Accept: application/csv' --header "Authorization: Token ${INFLUX_TOKEN}" \ --data 'from(bucket: "'${INFLUX_BUCKET}'") |> range(start: '$1', stop: '$2') |> filter(fn: (r) => r._measurement == "'${PRE_DP}'.'$3'" and r._field == "value") |> keep(columns: ["_value", "_time"]) |> sort(columns: ["_time"]) |> '$4'()') local TDATA=(${TMP_DATA[*]}) echo ${TDATA[-1]}|tr -d '\t\r\n' unset TDATA unset TMP_DATA }Geändert nur die Zeilen 11 & 14 und ein paar Zeilen gelöscht.
metsommer() { if [ ! -z ${INFLUX_BUCKET} ]; then if [ $(date +%m) -ge "6" ] && [ $(date +%m) -le "8" ] || [ ! -z ${metsom_override} ]; then if [ $(date +%m) -le "5" ]; then echo -e "\n ${RE}Eine Berechnung der meteorologischen Sommerwerte kann für das aktuelle Jahr $(date +%Y) erst ab dem 01. Juni durchgeführt werden!${NO}\n";exit 1; fi local FLUXSTART=$(date +%Y-06-01)"T00:00:00Z" local FLUXENDE=$(date +%Y-08-31)"T23:59:59Z" MET_SOMMER_TEMP_AVG=$(influx_query "${FLUXSTART}" "${FLUXENDE}" "Aussentemperatur" "mean") if [ -z "${MET_SOMMER_TEMP_AVG}" ]; then SAPI "Single" "set/${DP_MET_SOMMER_TEMP}?value=99.99&ack=true" else MET_SOMMER_TEMP_AVG=$(round ${MET_SOMMER_TEMP_AVG} 2) SAPI "Single" "set/${DP_MET_SOMMER_TEMP}?value=${MET_SOMMER_TEMP_AVG}&ack=true" fi local TMP_REGEN=$(curl -sk --request POST "${INFLUX_WEB}://${INFLUX_API}/api/v2/query?org=${INFLUX_ORG}" --header 'Content-Type: application/vnd.flux' \ --header 'Accept: application/csv' --header "Authorization: Token ${INFLUX_TOKEN}" \ --data 'from(bucket: "'${INFLUX_BUCKET}'") |> range(start: '${FLUXSTART}', stop: '${FLUXENDE}') |> filter(fn: (r) => r._measurement == "'${PRE_DP}'.Regen_Tag" and r._field == "value") |> keep(columns: ["_value", "_time"]) |> sort(columns: ["_time"]) |> aggregateWindow(every: 1d, fn: max) |> sum()') local IFS="," local TDATA=(${TMP_REGEN[*]}) MET_REGEN=$(echo ${TDATA[-1]} | tr -cd [:digit:]\.) echo $MET_REGEN if [ -z "${MET_REGEN}" ]; then SAPI "Single" "set/${DP_MET_SOMMER_REGEN}?value=999.9&ack=true" else SAPI "Single" "set/${DP_MET_SOMMER_REGEN}?value=${MET_REGEN}&ack=true" fi if [ ! -z ${metsom_override} ]; then echo -e "\n Daten vom 01.06.$(date +%Y) bis 31.08.$(date +%Y) wurden ermittelt...\n" echo -e "\t Ø-Temperatur: ${GR}${MET_SOMMER_TEMP_AVG} °C${NO}" echo -e "\t Regenmenge : ${GR}${MET_REGEN} l/m²${NO}\n" fi unset metsom_override fi fi }Geändert nur die Zeilen 18 & 23
Ich lasse es mal ein paar Tage laufen und melde mich dann mit einem Ergebnis...
Gruß
Hefo
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
267
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge