

Freies Modell bei OpenAI -gpt-4o-mini-
-
Hey, danke , dass Du Dich dem Thema annimmst.
Ich musste 5$ Dollar "hochladen" von meiner Kreditkarte.
Habe eingestellt, dass nicht nachgeladen werden soll.
Ich habe da auch nichts wildes abgeschlossen.
Eigentlich das kostenlose Abo.
Hab das KI Modell gewählt gpt-4o-mini.
Und den Secret Key eingetragen in HA (Blueprint)Es handelt sich um das Projekt:
https://www.youtube.com/watch?v=95qyHtzljsU
Ich hab das Limit schon runtergesetzt.
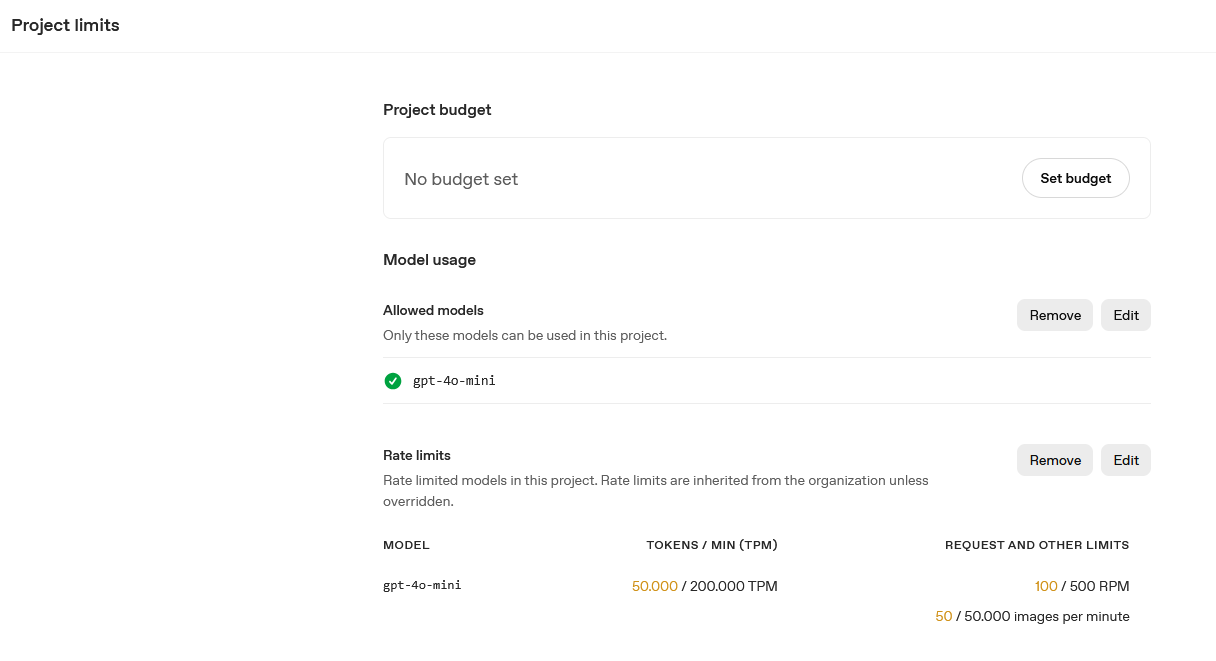
In ein paar Stunden sind 55 Cent zusammengekommen. Wenn ich das mal hochrechne....

Ich wollte das eigentlich in meiner VIS abbilden (Bild mit Beschreibung). Aber , wie ich schon sagte, gerät das Kostentechnisch ausser Kontrolle.
Bilder sind halt immer viele Daten und damit Inputtoken
Je nachdem wie dein prompt lautet gibt die KI viel aus. Das sind dann die Output Token. Per prompt kann man aber vorgeben wie umfangreich ausgegeben werden soll. Bspw könntest du sagen:
Liste mir alle Objekte kommasepariert auf.
Dann wird es schon weniger.4o mini ist jetzt aber auch nicht ganz so intelligent wie die aktuellen Modelle.
Für kontinuierliche Bildanalyse wirst du dich aktuell wahrscheinlich schon tot zahlen.
Da bleibt eigentlich nur ein lokales Modell.
Die passende Hardware ist aber leider auch nicht so ganz günstig und Strom schluckt das dann auch entsprechend.Alles mit Text ist eigentlich unproblematisch von der Menge. OpenAI hat zwar auch ein paar spezielle Modelle, bei denen auch bei Text der Input Output entsprechend teuer ist.. Die braucht der normale Mensch aber nicht.
Meine Adapter und Widgets
TVProgram, SqueezeboxRPC, OpenLiga, RSSFeed, MyTime,, pi-hole2, vis-json-template, skiinfo, vis-mapwidgets, vis-2-widgets-rssfeed
Links im Profil -
Bilder sind halt immer viele Daten und damit Inputtoken
Je nachdem wie dein prompt lautet gibt die KI viel aus. Das sind dann die Output Token. Per prompt kann man aber vorgeben wie umfangreich ausgegeben werden soll. Bspw könntest du sagen:
Liste mir alle Objekte kommasepariert auf.
Dann wird es schon weniger.4o mini ist jetzt aber auch nicht ganz so intelligent wie die aktuellen Modelle.
Für kontinuierliche Bildanalyse wirst du dich aktuell wahrscheinlich schon tot zahlen.
Da bleibt eigentlich nur ein lokales Modell.
Die passende Hardware ist aber leider auch nicht so ganz günstig und Strom schluckt das dann auch entsprechend.Alles mit Text ist eigentlich unproblematisch von der Menge. OpenAI hat zwar auch ein paar spezielle Modelle, bei denen auch bei Text der Input Output entsprechend teuer ist.. Die braucht der normale Mensch aber nicht.
Da ist so das Sparsamste, was man eingeben kann, so denke ich.
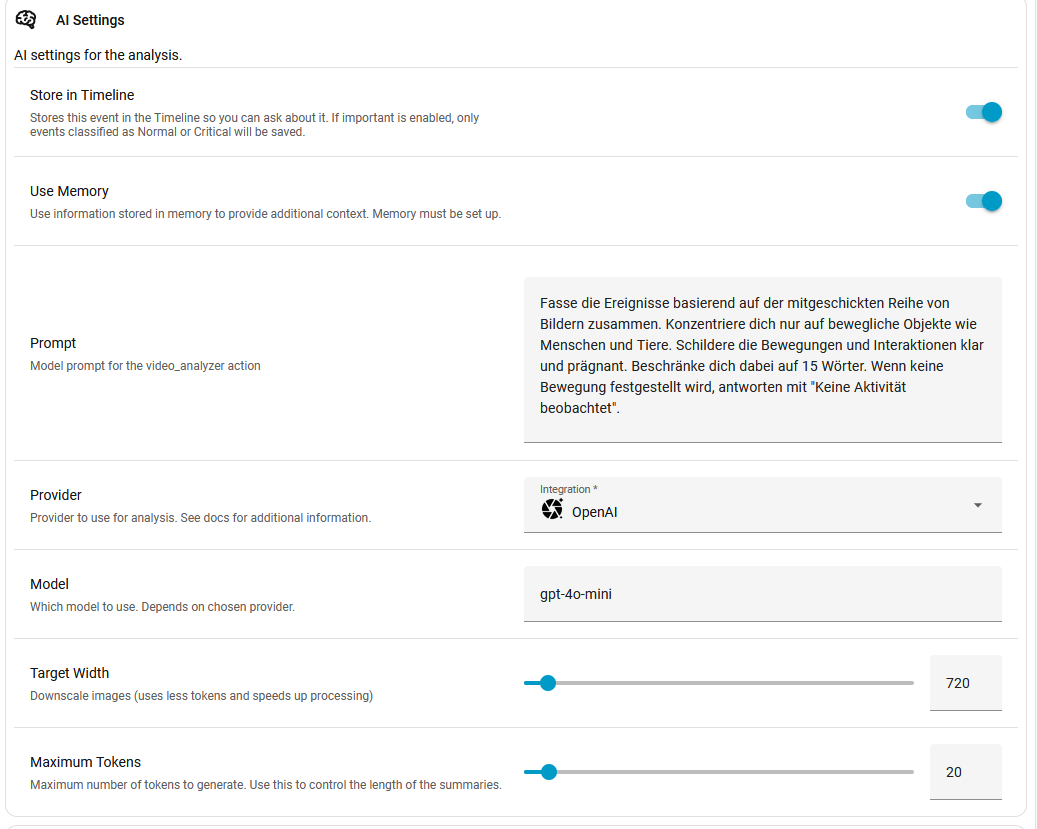
Es kommt ein Bild mit max. 15 Wörtern als Beschreibung. Ich, als Laie würde sagen, spartanisch.
Synology DS218+ & 2 x Fujitsu Esprimo (VM/Container) + FritzBox7590 + 2 AVM 3000 Repeater & Homematic & HUE & Osram & Xiaomi, NPM 10.9.7, Nodejs 22.22.2 ,JS Controller 7.0.7 ,Admin 7.8.24
-
Da ist so das Sparsamste, was man eingeben kann, so denke ich.
Es kommt ein Bild mit max. 15 Wörtern als Beschreibung. Ich, als Laie würde sagen, spartanisch.
Wenn es um Analyse von beweglichen Bildern geht, Gesichtserkennung, Objekterkennung, Tracking
Dann könnte man es auch mit opencv probieren.
Das ist Open Source, läuft auf normaler Hardware und hat auch KI Fähigkeiten (eine andere Art von KI, die aktuell bekannten sind ja alles sogenannte LLMs)
https://opencv.org/Das kann das sogar auf normale Hardware
-
Bilder sind halt immer viele Daten und damit Inputtoken
Je nachdem wie dein prompt lautet gibt die KI viel aus. Das sind dann die Output Token. Per prompt kann man aber vorgeben wie umfangreich ausgegeben werden soll. Bspw könntest du sagen:
Liste mir alle Objekte kommasepariert auf.
Dann wird es schon weniger.4o mini ist jetzt aber auch nicht ganz so intelligent wie die aktuellen Modelle.
Für kontinuierliche Bildanalyse wirst du dich aktuell wahrscheinlich schon tot zahlen.
Da bleibt eigentlich nur ein lokales Modell.
Die passende Hardware ist aber leider auch nicht so ganz günstig und Strom schluckt das dann auch entsprechend.Alles mit Text ist eigentlich unproblematisch von der Menge. OpenAI hat zwar auch ein paar spezielle Modelle, bei denen auch bei Text der Input Output entsprechend teuer ist.. Die braucht der normale Mensch aber nicht.
@OliverIO sagte in Freies Modell bei OpenAI -gpt-4o-mini-:
Bilder sind halt immer viele Daten und damit Inputtoken
Ja und Nein. Ich hab vor ein paar Wochen gelesen das Forscher fest gestellt haben das Bilder mit der selben Token Anzahl wie ein Text deutlich mehr Informationen beinhalten als wenn sie als Text in ein LLM geladen werden.
@haselchen sagte in Freies Modell bei OpenAI -gpt-4o-mini-:
Da ist so das Sparsamste, was man eingeben kann, so denke ich.
LLMs kommen gut damit klar wenn die Bild Auflösung niedriger ist. Je nachdem was man erkennen will kann man also durch Reduzierung der Auflösung auch Token Sparen.
Das machst du bereits wie im Screenshot zu sehen.
Je nachdem was deine Kameras können, kannst du jetzt noch die Bild Anzahl reduzieren. Die Reolink Kameras erkennen Menschen, Tiere und Autos, das kann man sich zu nutze machen und entsprechend nur Bilder nehmen auf denen mindestens eins davon erkannt wurde.@OliverIO sagte in Freies Modell bei OpenAI -gpt-4o-mini-:
Dann könnte man es auch mit opencv probieren.
Damit hab ich auch schon gespielt und das ist wirklich gut. Der größte Vorteil ist das es auch mit Intel Grafik Chips beschleunigt werden kann, die meistens in den Mini PCs zu finden sind.
@OliverIO sagte in Freies Modell bei OpenAI -gpt-4o-mini-:
Da bleibt eigentlich nur ein lokales Modell.
Ich hab qwen3-vl auf dem Smartphone getestet und muss sagen es war Überraschend schnell und hat gute Ergebnisse geliefert.
-
Kleines Update:
Mit dem OpenAI war ich nach Stunden soweit, dass meine 5 Dollar aufgebraucht waren.
Also hab ich auf Google umgestellt.
Erst wieder auf gemini-2.5-flash-lite.
Da wurde dann mal nen Bild interpretiert und dann wieder gabs nen Fehler (Couldn't generate content. Check logs for details.)
Vermutlich das Ratelimit.
Komischerweise wurde dann das nächste Bild wieder interpretiert.
Das macht natürlich wenig Sinn, wenn man vernünftig damit arbeiten will.
Also das nächste Modell genommen. Angeblich die Speerspitze aktuell bei Google: gemini-3-flash-preview
Leute, Leute, was da für ein Mist rauskam. Unglaublich.
"Fehler bei System gesehen oder Fehler bei Inhaltsgenerierung gesehen" war noch das Harmlostete, was die gute KI als Bildüberschrift da rausgeschmissen hat.
Wie gesagt, es soll ein Bild(Snapshot) mit einem Tier interpretiert werden.@oliverio
@jey-cee
Für die KIs, die ihr mir genannt habt, da fehlt mir das Wissen zu und definitiv die Zeit, mich da sicher einzuarbeiten.
Ich geb gerne 5 oder 10€ aus im Monat für die "Spielerei", aber nicht für ne Sache, die ausser Kontrolle gerät.
Und das tut es vermutlich, weil mir das Wissen fehlt.Wenn jemand ein KI Modell kennt, welches sich einfach integrieren lässt und transparent/überschaubar von Nutzen & Kosten ist, immer her damit.
Synology DS218+ & 2 x Fujitsu Esprimo (VM/Container) + FritzBox7590 + 2 AVM 3000 Repeater & Homematic & HUE & Osram & Xiaomi, NPM 10.9.7, Nodejs 22.22.2 ,JS Controller 7.0.7 ,Admin 7.8.24
-
Kleines Update:
Mit dem OpenAI war ich nach Stunden soweit, dass meine 5 Dollar aufgebraucht waren.
Also hab ich auf Google umgestellt.
Erst wieder auf gemini-2.5-flash-lite.
Da wurde dann mal nen Bild interpretiert und dann wieder gabs nen Fehler (Couldn't generate content. Check logs for details.)
Vermutlich das Ratelimit.
Komischerweise wurde dann das nächste Bild wieder interpretiert.
Das macht natürlich wenig Sinn, wenn man vernünftig damit arbeiten will.
Also das nächste Modell genommen. Angeblich die Speerspitze aktuell bei Google: gemini-3-flash-preview
Leute, Leute, was da für ein Mist rauskam. Unglaublich.
"Fehler bei System gesehen oder Fehler bei Inhaltsgenerierung gesehen" war noch das Harmlostete, was die gute KI als Bildüberschrift da rausgeschmissen hat.
Wie gesagt, es soll ein Bild(Snapshot) mit einem Tier interpretiert werden.@oliverio
@jey-cee
Für die KIs, die ihr mir genannt habt, da fehlt mir das Wissen zu und definitiv die Zeit, mich da sicher einzuarbeiten.
Ich geb gerne 5 oder 10€ aus im Monat für die "Spielerei", aber nicht für ne Sache, die ausser Kontrolle gerät.
Und das tut es vermutlich, weil mir das Wissen fehlt.Wenn jemand ein KI Modell kennt, welches sich einfach integrieren lässt und transparent/überschaubar von Nutzen & Kosten ist, immer her damit.
Dann musst du genauer beschreiben was du eigentlich erreichen willst.
Bisher hast du nur von den Erfahrungen mit Bilder und ki geschrieben -
Dann musst du genauer beschreiben was du eigentlich erreichen willst.
Bisher hast du nur von den Erfahrungen mit Bilder und ki geschriebenIch hatte doch oben genau beschrieben worum es geht (mit Link zum Video)
Ich habe das Projekt von Simon42 "nachgebastelt".
Es wird ein Bild gemacht bei Bewegung und die KI beschreibt es.
Ziel ist es, dass mir dann Alexa sagt, wer auf der Terrasse ist.
Dazu müsste das alles schon perfekt funktionieren.Synology DS218+ & 2 x Fujitsu Esprimo (VM/Container) + FritzBox7590 + 2 AVM 3000 Repeater & Homematic & HUE & Osram & Xiaomi, NPM 10.9.7, Nodejs 22.22.2 ,JS Controller 7.0.7 ,Admin 7.8.24
-
Ich hatte doch oben genau beschrieben worum es geht (mit Link zum Video)
Ich habe das Projekt von Simon42 "nachgebastelt".
Es wird ein Bild gemacht bei Bewegung und die KI beschreibt es.
Ziel ist es, dass mir dann Alexa sagt, wer auf der Terrasse ist.
Dazu müsste das alles schon perfekt funktionieren.Habe keine detaillierte Beschreibung gefunden, auch jetzt nicht,
Videos schaue ich mir nicht an, um ein Nutzerproblem zu verstehen. Kostet mir etwas zu viel Zeit und wenn es dem nutzer auch zu viel ist, dann passt es für mich schon -
Ich hatte doch oben genau beschrieben worum es geht (mit Link zum Video)
Ich habe das Projekt von Simon42 "nachgebastelt".
Es wird ein Bild gemacht bei Bewegung und die KI beschreibt es.
Ziel ist es, dass mir dann Alexa sagt, wer auf der Terrasse ist.
Dazu müsste das alles schon perfekt funktionieren.Soweit ich mich an das Video erinnern kann soll alles was den Tag über passiert ist zusammengefasst werden.
Du Schreibst jetzt aber:
@haselchen sagte in Freies Modell bei OpenAI -gpt-4o-mini-:
Ziel ist es, dass mir dann Alexa sagt, wer auf der Terrasse ist.
Da liegen Welten dazwischen. Zum einen könnte man eben die Bild Anzahl drastisch reduzieren wenn man eine Kamera hat die Menschen erkennt. Dann ist Personenerkennung (also wer ist das) nur möglich wenn das LLM entsprechende Informationen hat oder bekommt.
@haselchen sagte in Freies Modell bei OpenAI -gpt-4o-mini-:
Angeblich die Speerspitze aktuell bei Google: gemini-3-flash-preview
Leute, Leute, was da für ein Mist rauskam. Unglaublich.Wundert mich nicht, LLMs werden auf bestimmte Inhalte trainiert. Für Bild braucht es ein LLM das entsprechend darauf trainiert wurde.
Deswegen hab ich ja qwen3-vl in den Raum geworfen das wurde dafür trainiert.
Das ist auch nicht so schwer zu installieren mit ollama, ähnlich wie die ioBroker Installation.
Die Frage ist halt ob deine Software ollama als Anbieter anbietet.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
281
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge