

Grafana & FLUX - count() every day

-
@meister-mopper sagte in Grafana & FLUX - count() every day:
|> difference()
|> aggregateWindow(every: 1d, fn: sum, timeSrc: "_start")```Ah sooooo, erst difference und dann aggregate
Oh man ey.....das sieht gut aus -
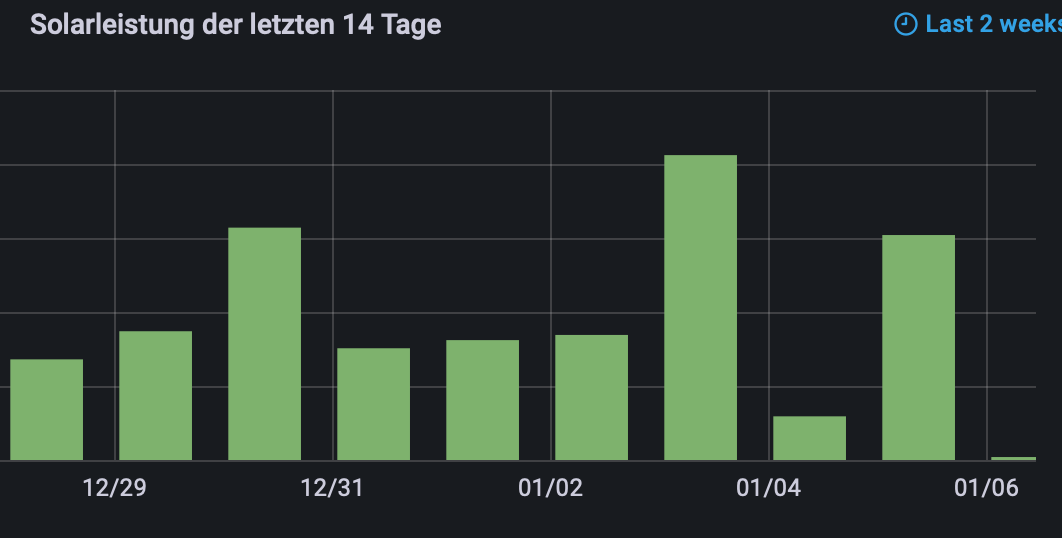
Hier ein Beispiel für anwachsende Werte:
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "iobroker") |> range(start: -30d, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Energie.PV.Tagesverbrauch" and r["_field"] == "value") |> difference() |> aggregateWindow(every: 1d, fn: sum, timeSrc: "_start")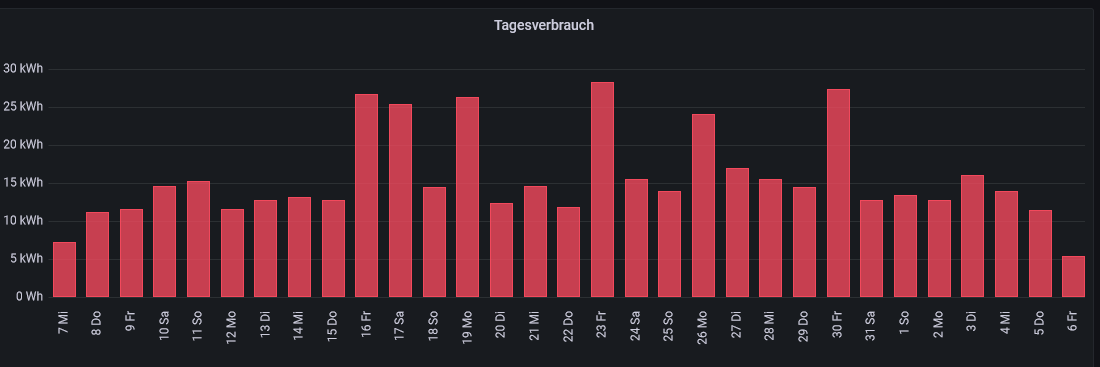
@meister-mopper
Der Wert für den aktuellen Tag stimmt aber nicht. Da steht 21 aber ich habe schon 23 Werte drin:from(bucket: "iobroker") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "meinDP") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1d, fn: count, timeSrc: "_start")Gruß Dirk
Intel Proxmox Cluster (3x NUC) mit Debian & Proxmox / IoB als VM unter Debian / 60+ Adapter installiert -
@meister-mopper
Der Wert für den aktuellen Tag stimmt aber nicht. Da steht 21 aber ich habe schon 23 Werte drin:from(bucket: "iobroker") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "meinDP") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1d, fn: count, timeSrc: "_start")@segway Das dürfte ein Zeitzonenproblem sein, guck doch mal bei @Meister-Mopper
Ansonsten wird UTC als Grundlage genommen und damit die Summe zeitlich verschoben.
NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
@segway Das dürfte ein Zeitzonenproblem sein, guck doch mal bei @Meister-Mopper
Ansonsten wird UTC als Grundlage genommen und damit die Summe zeitlich verschoben.
@marc-berg
Yup, war ein timezone Problem. Nun passt es ! -
mMn kannst du dir
difference()sparen. Du berechnest damit die Differenz der einzelnen values, aber machst damit später nichts sondern zählst einfach nur, und zwar jeweils über ein Zeitfenster von einem Tag. Lass also mal difference weg und schau, ob das gleiche rauskommt.Eigentlich ist flux genial, wenn man mal begriffen hat, wie es funktioniert - ich bin da auch noch gaaanz am Anfang.
-
mMn kannst du dir
difference()sparen. Du berechnest damit die Differenz der einzelnen values, aber machst damit später nichts sondern zählst einfach nur, und zwar jeweils über ein Zeitfenster von einem Tag. Lass also mal difference weg und schau, ob das gleiche rauskommt.Eigentlich ist flux genial, wenn man mal begriffen hat, wie es funktioniert - ich bin da auch noch gaaanz am Anfang.
@ostfrieseunterwegs sagte in Grafana & FLUX - count() every day:
mMn kannst du dir
difference()sparen. Du berechnest damit die Differenz der einzelnen values, aber machst damit später nichts sondern zählst einfach nur, und zwar jeweils über ein Zeitfenster von einem Tag. Lass also mal difference weg und schau, ob das gleiche rauskommt.Habe ich mal weggelassen.
Für den laufenden Tag bleibt es gleich ABER für die vorherigen kommt ein Datenpunkt weniger raus mhhhhEigentlich ist flux genial, wenn man mal begriffen hat, wie es funktioniert - ich bin da auch noch gaaanz am Anfang.
Ja FLUX ist richtig mächtig, aber man muss es erstmal verstehen. Da bin ich noch vor dem Anfang
-
mMn kannst du dir
difference()sparen. Du berechnest damit die Differenz der einzelnen values, aber machst damit später nichts sondern zählst einfach nur, und zwar jeweils über ein Zeitfenster von einem Tag. Lass also mal difference weg und schau, ob das gleiche rauskommt.Eigentlich ist flux genial, wenn man mal begriffen hat, wie es funktioniert - ich bin da auch noch gaaanz am Anfang.
@ostfrieseunterwegs sagte in Grafana & FLUX - count() every day:
mMn kannst du dir difference() sparen.
Dann kommen bei mir komplett andere Werte.
Proxmox und HA - dank KI/AI endlich "blocklyfrei"
-
@ostfrieseunterwegs sagte in Grafana & FLUX - count() every day:
mMn kannst du dir difference() sparen.
Dann kommen bei mir komplett andere Werte.
@meister-mopper Ja bei Dir schon, du summierst ja auch auf, Da brauchst du Difference. Aber @Segway will ja wohl nur zählen und nicht rechnen (summieren)
-
@meister-mopper Ja bei Dir schon, du summierst ja auch auf, Da brauchst du Difference. Aber @Segway will ja wohl nur zählen und nicht rechnen (summieren)
@ostfrieseunterwegs
Jo ich will einfach nur wissen wieviel Datenpunkt pro Tag in dem Datenpunkt drin sind. -
Wahrscheinlich wisst ihr das, aber ich mache mir das mit flux immer folgendermaßen klar
from(bucket: "iobroker")
--> Schau mal in den Datentopf iobroker, zapfe ihn an und liefere mir mal alles was|> range(start: -30d, stop: v.timeRangeStop)
--> in dem Zeitfenster von -30 Tage bis jetzt liegt|> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Energie.PV.Tagesverbrauch" and r["_field"] == "value")
--> aber doch nicht alles sondern nur die Datensätze, die dem Kriterium _measurement == "0_userdata.Energie.PV.Tagesverbrauch" entsprechen. Und da auch nicht alle Werte, sondern nur die, die im Feld 'value' stehenNun habe ich einen stream, der nur noch aus den Paaren Zeitstempel, Wert besteht. Der wird nun weitergereicht an
|> difference()
--> Berechnet jeweils die Differenz aus zwei aufeinanderfolgenden Werten. Daher nun ein Stream aus Zeitstempel, Differenz-zum-Vorgänger-Wert.
Das schieben wir nun in die Aggregate Funktion|> aggregateWindow(every: 1d, fn: sum, timeSrc: "_start")
--> die teilt das Ganze in Blöcke auf, die jeweils die Differenzwerte für einen Tag enthalten. Fängt dabei bei _start (das kommt aus dem Range von ganz oben) an. Und innerhalb dieser Blöcke summiere alles auf. Bei @Segway entsprechen fn: count. Weil da nur gezählt wird, ist egal was im Wert steht, da ist nur wichtig, dass irgendwas drin steht. -
Wahrscheinlich wisst ihr das, aber ich mache mir das mit flux immer folgendermaßen klar
from(bucket: "iobroker")
--> Schau mal in den Datentopf iobroker, zapfe ihn an und liefere mir mal alles was|> range(start: -30d, stop: v.timeRangeStop)
--> in dem Zeitfenster von -30 Tage bis jetzt liegt|> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Energie.PV.Tagesverbrauch" and r["_field"] == "value")
--> aber doch nicht alles sondern nur die Datensätze, die dem Kriterium _measurement == "0_userdata.Energie.PV.Tagesverbrauch" entsprechen. Und da auch nicht alle Werte, sondern nur die, die im Feld 'value' stehenNun habe ich einen stream, der nur noch aus den Paaren Zeitstempel, Wert besteht. Der wird nun weitergereicht an
|> difference()
--> Berechnet jeweils die Differenz aus zwei aufeinanderfolgenden Werten. Daher nun ein Stream aus Zeitstempel, Differenz-zum-Vorgänger-Wert.
Das schieben wir nun in die Aggregate Funktion|> aggregateWindow(every: 1d, fn: sum, timeSrc: "_start")
--> die teilt das Ganze in Blöcke auf, die jeweils die Differenzwerte für einen Tag enthalten. Fängt dabei bei _start (das kommt aus dem Range von ganz oben) an. Und innerhalb dieser Blöcke summiere alles auf. Bei @Segway entsprechen fn: count. Weil da nur gezählt wird, ist egal was im Wert steht, da ist nur wichtig, dass irgendwas drin steht.@ostfrieseunterwegs
Sehr gute Erklärung !!! TOPFrage:
ich habe immer wieder das Problem, dass die Beschriftung der Datenpunkte nicht passt und ich dann per Override arbeiten muss.
Kriegt ich das nicht irgendwie "automatisierter" hin ???Gruß Dirk
Intel Proxmox Cluster (3x NUC) mit Debian & Proxmox / IoB als VM unter Debian / 60+ Adapter installiert -
@ostfrieseunterwegs
Sehr gute Erklärung !!! TOPFrage:
ich habe immer wieder das Problem, dass die Beschriftung der Datenpunkte nicht passt und ich dann per Override arbeiten muss.
Kriegt ich das nicht irgendwie "automatisierter" hin ???@segway sagte in Grafana & FLUX - count() every day:
Kriegt ich das nicht irgendwie "automatisierter" hin ???
Ist mir noch nicht gelungen, ich arbeite auch mit overrides.
Proxmox und HA - dank KI/AI endlich "blocklyfrei"
-
@ostfrieseunterwegs
Sehr gute Erklärung !!! TOPFrage:
ich habe immer wieder das Problem, dass die Beschriftung der Datenpunkte nicht passt und ich dann per Override arbeiten muss.
Kriegt ich das nicht irgendwie "automatisierter" hin ???@segway Jain... in flux funktioniert leider yield nicht mehr, damit konnte man früher den Namen der Ausgabe setzen, Das geht nun nur noch in Grafana per Override.
Aber eine Andere Möglichkeit ist, bei den Einstellungen zum Datenpunkt, einen Alias zu benutzen. Statt dem ellenlangen Namen (oben) kommt es geschmeidig mit dem Alias (unten) in influx an. Da müssten sogar Blanks etc funktionieren, da der Wert ja in das Feld _measurement in der influxdb geschrieben wird.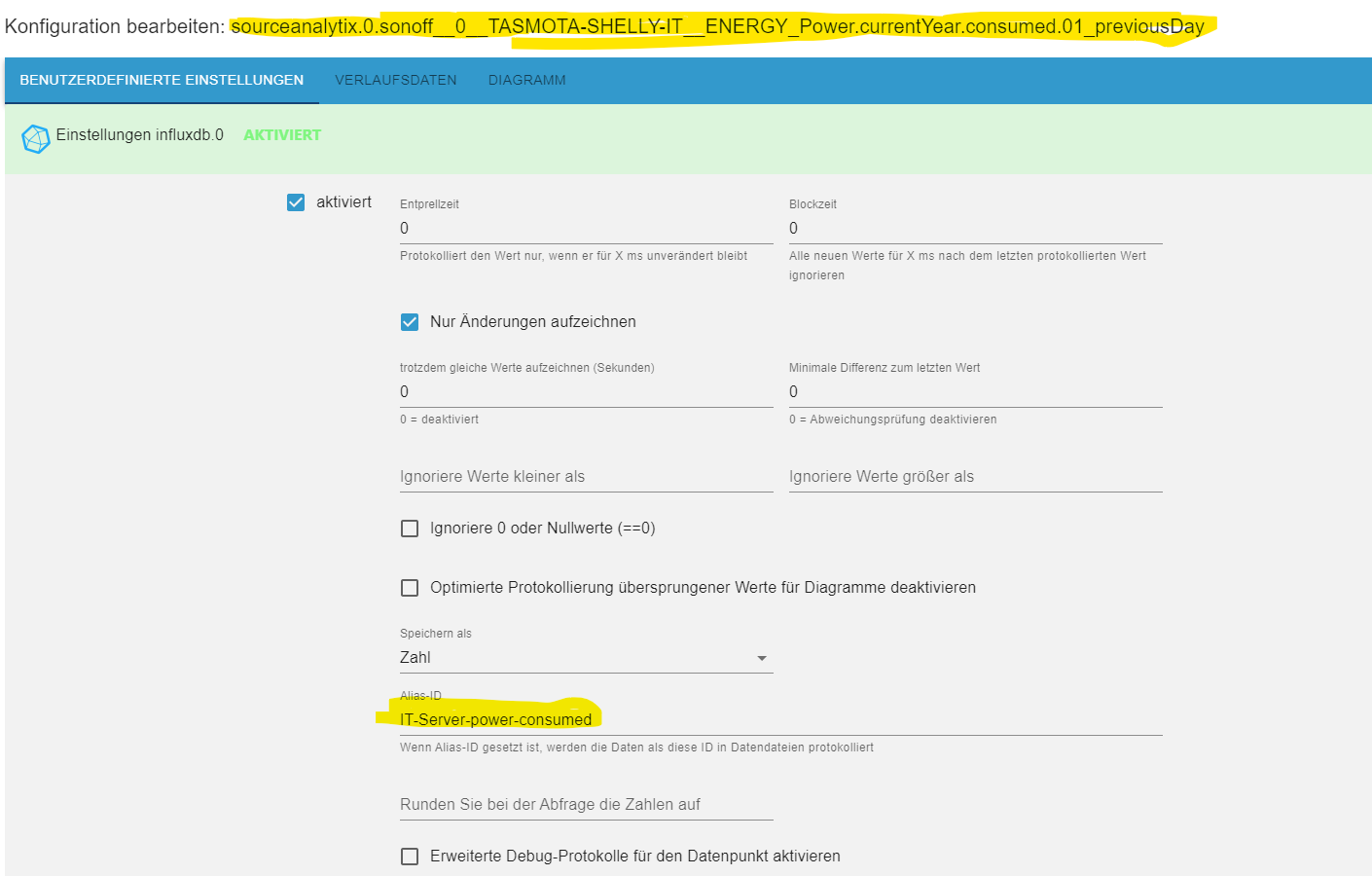
-
@segway sagte in Grafana & FLUX - count() every day:
Kriegt ich das nicht irgendwie "automatisierter" hin ???
Ist mir noch nicht gelungen, ich arbeite auch mit overrides.
@meister-mopper sagte in Grafana & FLUX - count() every day:
Ist mir noch nicht gelungen, ich arbeite auch mit overrides.
Ab 28:50 erklärt , mit Value Mapping REGEX
Synology 918+ 16GB - ioBroker in Docker v9 , VISO auf Trekstor Primebook C13 13,3" , Hikvision Domkameras mit Surveillance Station .. CCU RaspberryMatic in Synology VM .. Zigbee CC2538+CC2592 .. Sonoff .. KNX .. Modbus ..
-
@meister-mopper sagte in Grafana & FLUX - count() every day:
Ist mir noch nicht gelungen, ich arbeite auch mit overrides.
Ab 28:50 erklärt , mit Value Mapping REGEX
@glasfaser Stimmt, damit kann man Value mappen. Das geht auch schon in flux. Unten hab ich aus den Werten das % rausgelöscht, weil ich das im Dashboard nicht brauchen konnte. Das
import "strings"in der ersten Zeile ist wichtig
Außerdem gibt es auch im tab transformation die Möglichkeit, das zu tun. Wie immer gilt: man sollte sich auf eine Art festlegen, sonst sucht man später ewig, wenn mal was nicht funktioniert (also ich: IMMER)import "strings" from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "Device-Status") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 12h, fn: last, createEmpty: false) |> map(fn: (r) => ({r with _value: strings.replaceAll(v: r._value, t: "%", u: "")})) -
@ostfrieseunterwegs
Sehr gute Erklärung !!! TOPFrage:
ich habe immer wieder das Problem, dass die Beschriftung der Datenpunkte nicht passt und ich dann per Override arbeiten muss.
Kriegt ich das nicht irgendwie "automatisierter" hin ???Die Video´s von diesem YouTuber würde ich dir empfehlen ... bin auch gerade bei 1.8 > 2. am wechseln .
Habe aber die Datenbankabfrage schon in Grafana mit diesem API HTTP hinbekommen , so das ich noch die alte Influx Sprache nutzen kann .
-
Ein Umbenennen geht auch einfacher mit der Funktion:
|> rename(columns: {_value: "test"})
Ich weiß nicht, ob das euren Anwendungsfall erschlägt?
Ansonsten arbeite ich gern mit dem "Data Explorer" der Datenbank, damit kann man sich seine Querys schön zusammenklicken und hat auch eine Hilfe bzgl. zusätzlicher Funktionen. Die Query kann man dann nach Grafana kopieren.
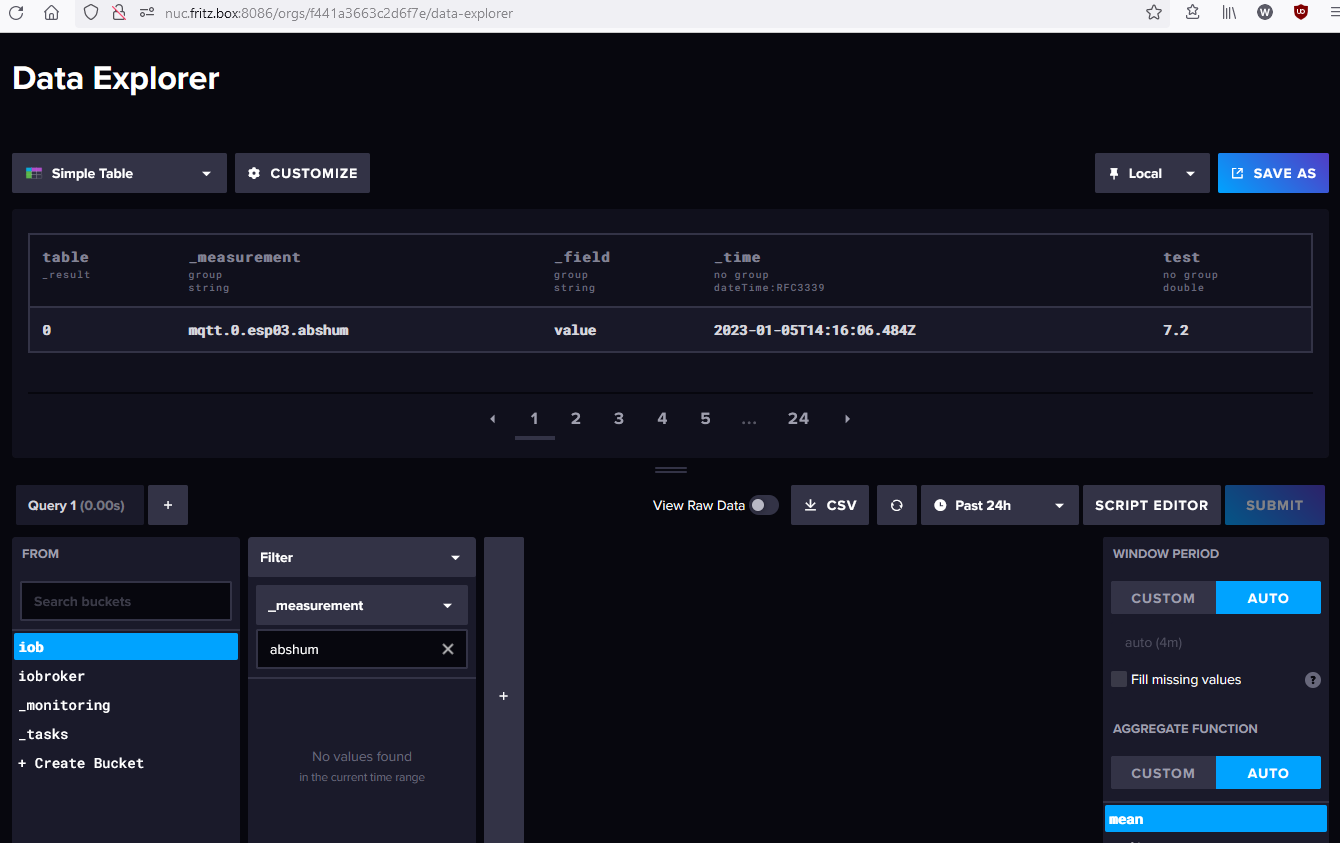
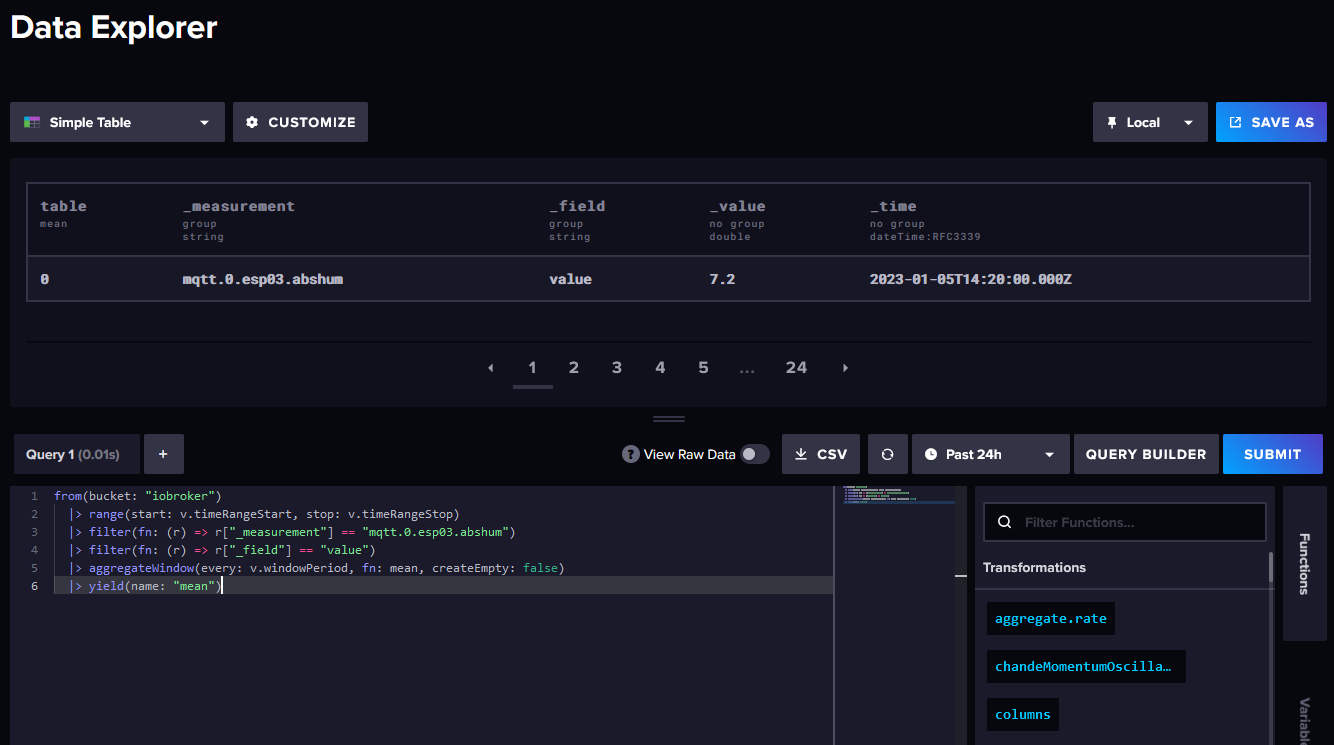
NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
Ein Umbenennen geht auch einfacher mit der Funktion:
|> rename(columns: {_value: "test"})
Ich weiß nicht, ob das euren Anwendungsfall erschlägt?
Ansonsten arbeite ich gern mit dem "Data Explorer" der Datenbank, damit kann man sich seine Querys schön zusammenklicken und hat auch eine Hilfe bzgl. zusätzlicher Funktionen. Die Query kann man dann nach Grafana kopieren.
@marc-berg sagte in Grafana & FLUX - count() every day:
|> rename(columns: {_value: "test"})
Jau, wieder was gelernt.

Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
368
Online32.9k
Benutzer83.2k
Themen1.3m
Beiträge