

Frage : Migrate MySQL nach Influxdb
-
Hatte nun noch weitere Probleme:
Daten waren in MySQL und in InfluxDB als unterschiedliche Formate gespeichert und teilweise hatten sich in MySQL die Datentypen über die Zeit geändert, sodass ein Messwert in mehreren Datentabellen (z.B. ts_number & ts_string) vorhanden war.
Da das Skript den Datentyp über die Quelltabelle ermittelt (ts_number => Zahl, ts_bool => Wahrheitswert, ts_string => Zeichenfolge) führt dieses zu Problemen.
In der Übersichtstabelle (datapoints) gibt es nur eine Angabe des Datentypes. Diese ist in meinen Auge der aktuell gewünschte Datentyp. Daher habe ich das Skript um eine Abfrage des Datentypes aus datapoints erweitert und eine Konvertierung in diesen Datentyp eingebaut.
Nun können Daten z.B. in den Tabellen ts_string und ts_number vorliegen. Bei der Migration werden die Daten dann in den Datentyp konvertiert, der in datapoints angegeben ist.
Damit reicht es das InfluxDB und MySQL für jeden Wert den gleichen Datentypen verwenden.Da ich früher meist als Datentyp "Automatisch" angegeben hatte, konnte dieses hier zu Problemen führen. Nach dem ich alle Datentypen händisch gerade gezogen habe, teilweise direkt in der MySQL-Datenbank, funktionierte die Migration mit der Skriptanpassung problemlos.
Meine Änderungen des Skriptes sind in einem Fork abgelegt und einen Pull request habe ich gestellt.
Aus meiner Sicht könnte man nun noch als Anpassung vornehmen, das er den gewünschten Datentypen nicht aus der MySQL-Datenbank bezieht, sondern aus der InfluxDB, wenn man vorher den Wert dort bereits über iobroker eingefügt hat.
In Summe nochmal danke für das Skript, es hat mir sehr weiter geholfen.
-
@UlliJ danke für die Idee mit dem Script.
Hab das script etwas angepasst, damit alle Daten übernommen werden und diese auch auf einem leistungsschwachen Rasperry Pi ausgelesen werden können.
Hab so ca. 22 Millionen Datensätze in die InfluxDB gepackt.GitHub iobroker_mysql_2_influxdb
@jackgruber sagte in Frage : Migrate MySQL nach Influxdb:
Hab das script etwas angepasst, damit alle Daten übernommen werden und diese auch auf einem leistungsschwachen Rasperry Pi ausgelesen werden können.
Frage:
Läuft das Script auch mit influxdb v2.x?
Hintergrund:
Der externe Zugriff wird ab v2 ja über Token abgesichert.
In der database.json sind aber nur username/password für influxdb hinterlegt. -
Hallo @JackGruber
Erstmal Danke für das Script :)
Ich habe versucht, nach der Anleitung über das Script die Daten von MySQL nach InfluxDB zu migrieren.
Leider lässt sich das Script migrate.py bei mir nicht ohne Fehlermeldung ausführen.
Es erscheint:
File "migrate.py", line 177 print(f"Processing row {processed_rows + 1:,} to {processed_rows + len(selected_rows):,} from LIMIT {start_row:,} / {start_row + query_max_rows:,} " + ^ SyntaxError: invalid syntaxWo da in Zeile 177 der Fehler steckt, verschließt sich mir ...
Hat jemand eine Idee, woran das liegen könnte?
-
Hallo @JackGruber
Erstmal Danke für das Script :)
Ich habe versucht, nach der Anleitung über das Script die Daten von MySQL nach InfluxDB zu migrieren.
Leider lässt sich das Script migrate.py bei mir nicht ohne Fehlermeldung ausführen.
Es erscheint:
File "migrate.py", line 177 print(f"Processing row {processed_rows + 1:,} to {processed_rows + len(selected_rows):,} from LIMIT {start_row:,} / {start_row + query_max_rows:,} " + ^ SyntaxError: invalid syntaxWo da in Zeile 177 der Fehler steckt, verschließt sich mir ...
Hat jemand eine Idee, woran das liegen könnte?
@nureinbenutzer Update dein Python auf eine aktuelle Python 3 version!
Ich vermute du nutzt eine alte 2.x version. -
@nureinbenutzer Update dein Python auf eine aktuelle Python 3 version!
Ich vermute du nutzt eine alte 2.x version.@jackgruber Python liegt in Version 3.7.3 vor ...
Das war auch der Grund.
Der Aufruf muss lauten
python3 migrate.py ALLDanke für den Denkanstoss :)
-
Hallo.
Ich habe gestern das Script von @JackGruber probiert und es lief auch an.
Habe gedacht ich lasse es über Nacht laufen, aber heute Früh habe ich folgenden Fehler gesehen:Processing row 600,001 to 601,000 from LIMIT 600,000 / 700,000 ts_number - Wetter Luftdruck hPa (53/81) InfluxDB error HTTPConnectionPool(host='localhost', port=8086): Max retries exceeded with url: /write?db=iobroker&rp=autogen (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x74d52778>: Failed to establish a new connection: [Errno 111] Connection refused'))Jemand eine Idee?
Danke!
-
Moin zusammen,
mein erster post in diesem Forum...
Zu aller erst vielen Dank für diese tolle Plattform und den vielen die mit enormem Aufwand das smarte home nach vorne treiben, tolle Ideen weiter geben, absolut geile Visualisierungen bauen usw. Ich habe bislang selten ein Forum gesehen, in dem so konstruktiv und freundlich miteinander umgegangen wird...weiter so
Seit ca 2 Jahren betreibe ich Iobroker und habe bislang die Daten zuerst in MySQL und später dann in PostgreSQL abgelegt. Über die Zeit wurden die ganzen Abfragen und Diagramme mit Grafana nach und nach deutlich träger. Nach kurzer Testphase mit InfluxDB war die Frage geklärt

Mit dem Wechsel auf InfluxDB stellt sich die Frage für den nicht Programmierer wie die Daten von alt nach neu...Die genannten Lösungen haben bei mir nicht zuverlässig funktioniert also die nächste Klappe
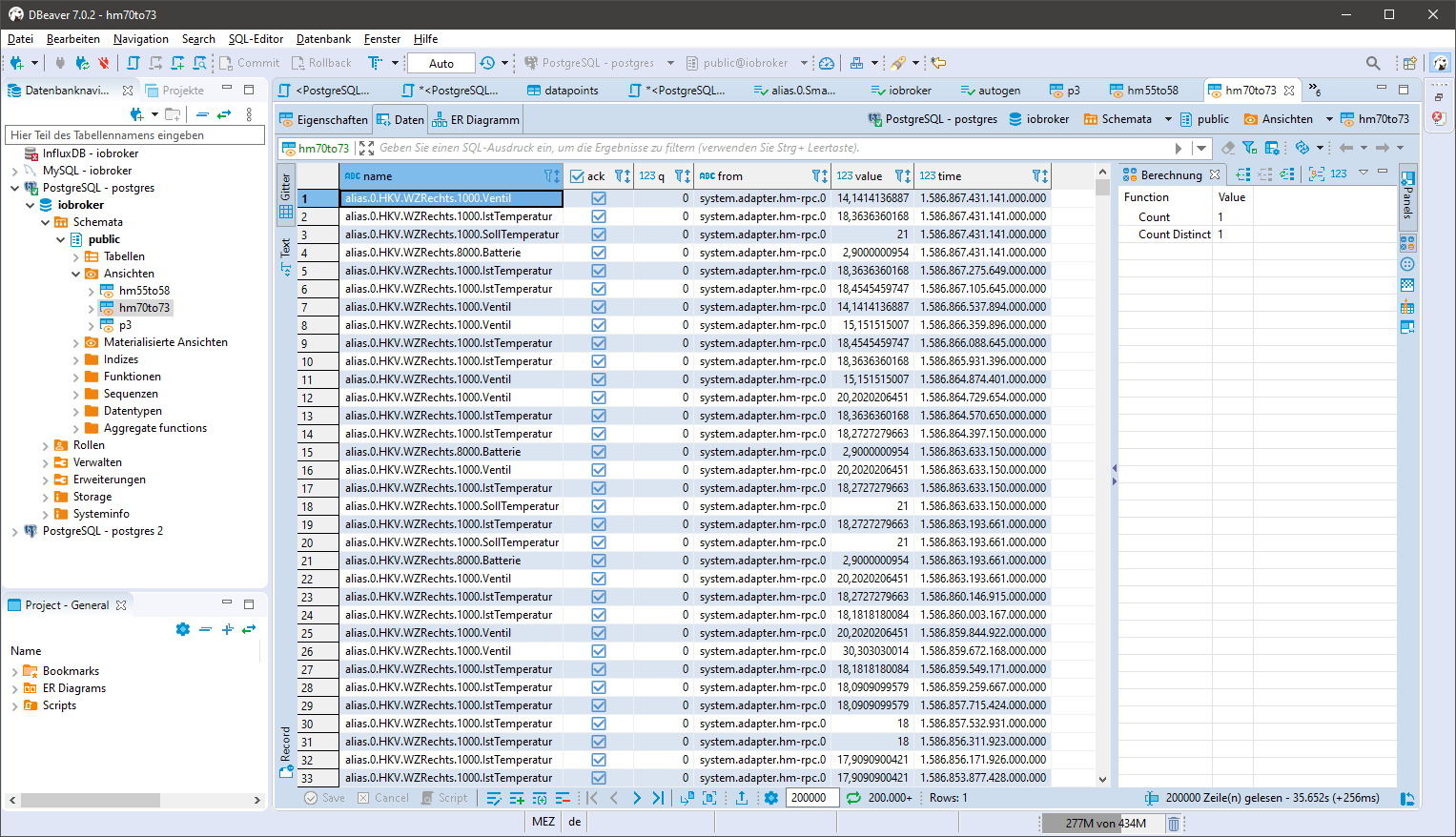
- In einem SQL GUI (phpmyadmin, HeidiSQL oder DBeaver, etc) oder auf der SQL-Konsole die zu exportierenden Daten in einem View zur Verfügung stellen
Der View enthält alles was Influx benötigt
create view xxx as SELECT datapoints.name, ts_number.ack as "ack", (ts_number.q*1.0) as "q", sources.name as "from", (ts_number.val*1.0) as "value", (ts_number.ts*1000000) as "time" from ts_number left join datapoints on ts_number.id=datapoints.id left join sources on ts_number._from=sources.id where datapoints.id>=70 and datapoints.id<=73 and q=0 order by ts_number.ts desc;"xxx" Name des View anpassen
in der WHERE Klausel die Datenpunkte entsprechend anpassen, einen Bereich wie hier oder auch eine einzelne id
Für kleine Datenbestände kann die WHERE Klausel auch auf "WHERE q=0" gesetzt werden und über den View in einem Rutsch in Influx übertragen werden.
Beispiel:
- Python installieren und ggf. die Zusätze installieren
- psycopg2 für PostgreSQL bzw. MySQLdb für MySQL
- influxdb-client und influxdb.
- das Skript von Muntazir Fadhel "Easily Migrate Postgres/MySQL Records to InfluxDB" nehmen (modifizierte Variante hier)
### MySQL DB info ### #import MySQLdb #conn = MySQLdb.connect(host="localhost", # your host, usually localhost # user="john", # your username # passwd="megajonhy", # your password # db="jonhydb") # name of the data base ### PostgreSQL DB info ### import psycopg2 import psycopg2.extras ##### # connection data for PostgreSQL conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='xxx.xxx.xxx.xxx', port=8086, username='xxx', password='xxx', database='xxx') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records curr = conn.cursor('cursor', cursor_factory=psycopg2.extras.RealDictCursor) # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from xxx;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close()Im Skript sind
- in Zeile 15 die Datenbankverbindung für Postgre anzupassen,
- in Zeile 22 die Datenbankverbindung für Influx
- weiter unten Zeile 65 statt xxx ist der Name des Views einzutragen der auf der Datenbank mit der Abfrage aus 1 erzeugt wurde
curr.execute("Select * from xxx;") - der Abschnitt "schema" gibt das mapping der Spalten vor und muss nur angepasst werden wenn die Spaltenbezeichner in der Abfrage aus 1 geändert werden
- für die MySQL user sind die Verbindungsdaten in den Zeilen 2-6 auskommentiert und an eure Umgebung anzupassen.
- In der Python Umgebung das Skript starten...alle 1000 Zeilen/Datensätze kommt eine Fortschrittsmeldung. Während die Abfrage auf der SQL Seite läuft steht da "Processing row # 1"
Bei umfangreichen Abfragen und je nach Umgebung kann das Ganze ein wenig dauern. Teilweise dauerten bei mir die SQL Abfragen bis zu 20min bei 20Mio Datensätzen (Nuc i3 mit 12GB für die SQL VM unter proxmox). Das Skript läuft zuverlässig und mehrere 10 Mio Datensätze von A nach B wurden migriert. Vielleicht kann es jemand brauchen und nochmals Danke für das tolle Projekt und die hilfsbereiten Menschen hier
VG
Ulli@ullij Erstmal vielen Dank..
Ich musste das Skript leicht anpassen auf sqlite, hab jetzt aber einen Fehler, der mit der Anpassung selbst eigentlich nichts zu tun hat:
### MySQL DB info ### #import MySQLdb #conn = MySQLdb.connect(host="localhost", # your host, usually localhost # user="john", # your username # passwd="megajonhy", # your password # db="jonhydb") # name of the data base ### PostgreSQL DB info ### #import psycopg2 #import psycopg2.extras import sqlite3 ##### # connection data for PostgreSQL #conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### conn = sqlite3.connect('/opt/iobroker/iobroker-data/sqlite/sqlite.db') # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='localhost', port=8086, username='xxxx', password='xxxx!', database='xxxx') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: if field_label == "ack": record[field_label] = bool(record[field_label]) fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records curr = conn.cursor() # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from xxx;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close()Fehler:
user@UbuntuHomeAutomation2:~$ python3 sql2influx3.py Processing row #1 Traceback (most recent call last): File "sql2influx3.py", line 75, in <module> influxClient.write_points(generate_influx_points(selected_rows)) File "sql2influx3.py", line 50, in generate_influx_points record[field_label] = bool(record[field_label]) TypeError: tuple indices must be integers or slices, not str user@UbuntuHomeAutomation2:~$Vielleicht hat ja jemand ne Lösung.
- In einem SQL GUI (phpmyadmin, HeidiSQL oder DBeaver, etc) oder auf der SQL-Konsole die zu exportierenden Daten in einem View zur Verfügung stellen
-
@ullij Erstmal vielen Dank..
Ich musste das Skript leicht anpassen auf sqlite, hab jetzt aber einen Fehler, der mit der Anpassung selbst eigentlich nichts zu tun hat:
### MySQL DB info ### #import MySQLdb #conn = MySQLdb.connect(host="localhost", # your host, usually localhost # user="john", # your username # passwd="megajonhy", # your password # db="jonhydb") # name of the data base ### PostgreSQL DB info ### #import psycopg2 #import psycopg2.extras import sqlite3 ##### # connection data for PostgreSQL #conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### conn = sqlite3.connect('/opt/iobroker/iobroker-data/sqlite/sqlite.db') # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='localhost', port=8086, username='xxxx', password='xxxx!', database='xxxx') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: if field_label == "ack": record[field_label] = bool(record[field_label]) fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records curr = conn.cursor() # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from xxx;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close()Fehler:
user@UbuntuHomeAutomation2:~$ python3 sql2influx3.py Processing row #1 Traceback (most recent call last): File "sql2influx3.py", line 75, in <module> influxClient.write_points(generate_influx_points(selected_rows)) File "sql2influx3.py", line 50, in generate_influx_points record[field_label] = bool(record[field_label]) TypeError: tuple indices must be integers or slices, not str user@UbuntuHomeAutomation2:~$Vielleicht hat ja jemand ne Lösung.
@thomas-herrmann
wünsche ein frohes neues Jahr.Du meintest sicherlich @JackGruber.
Ich kann Dir bei dem Skript (leider) nicht helfen.
GrußProxmox auf iNuc, lxc für IoB, InfluxDB2, Grafana, u.a. *** Homematic & Homematic IP, Shellies, Zigbee etc
-
@thomas-herrmann
wünsche ein frohes neues Jahr.Du meintest sicherlich @JackGruber.
Ich kann Dir bei dem Skript (leider) nicht helfen.
Gruß@ullij
Wünsch dir ebenso ein frohes Neues.
Es bezieht sich auf das Skript in deinem Post vom 14. Apr. 2020, 20:42: [https://forum.iobroker.net/topic/12482/frage-migrate-mysql-nach-influxdb/26](Link Adresse)Aber vielleicht hat ja noch jemand eine Idee, woran es liegen kann.
-
@ullij
Wünsch dir ebenso ein frohes Neues.
Es bezieht sich auf das Skript in deinem Post vom 14. Apr. 2020, 20:42: [https://forum.iobroker.net/topic/12482/frage-migrate-mysql-nach-influxdb/26](Link Adresse)Aber vielleicht hat ja noch jemand eine Idee, woran es liegen kann.
@thomas-herrmann
Hallo Thomas,
ich versuche es doch mal, allerdings habe ich die Umgebung dafür nicht mehr aktiv...testen ist also nicht ohne weiteres. Und Sqlite habe ich noch nie nicht verwendet.Das Python skript habe ich 1:1 aus der genanntenten Quelle übernommen und nur den Input bereitgestellt,
Du hast in dem Teil des Skriptes wo die Daten geschrieben werden sollen den Feldtyp geändert (Zeile 50). Die Fehlermeldung deutet darauf hin das Du einen String übergibst, aber ein Integer erwartet wird.
Versuch doch mal das Skript im Original laufen zu lassen und die Inputdaten passend zur Verfügung zu stellen.
Gruß
UlliProxmox auf iNuc, lxc für IoB, InfluxDB2, Grafana, u.a. *** Homematic & Homematic IP, Shellies, Zigbee etc
-
@thomas-herrmann
Hallo Thomas,
ich versuche es doch mal, allerdings habe ich die Umgebung dafür nicht mehr aktiv...testen ist also nicht ohne weiteres. Und Sqlite habe ich noch nie nicht verwendet.Das Python skript habe ich 1:1 aus der genanntenten Quelle übernommen und nur den Input bereitgestellt,
Du hast in dem Teil des Skriptes wo die Daten geschrieben werden sollen den Feldtyp geändert (Zeile 50). Die Fehlermeldung deutet darauf hin das Du einen String übergibst, aber ein Integer erwartet wird.
Versuch doch mal das Skript im Original laufen zu lassen und die Inputdaten passend zur Verfügung zu stellen.
Gruß
Ulli@ullij Danke, aber das habe ich vorher natürlich schon versucht.
Die Änderung stammt von @JackGruber [https://forum.iobroker.net/topic/12482/frage-migrate-mysql-nach-influxdb/36] -
Hallo zusammen,
vielen Dank für das Script und da drumherum hier @JackGruber @UlliJ - ich bin gerade dabei, ca 60mio Datensätze von einer SQL auf eine influx zu migrieren.
Ich stoße hierbei leider immer wieder mitten in der Übertragung auf folgenden Fehler:Total metrics in ts_number: 1 0_userdata.0.Variablen.Strom.Steckdose_Dachgeschoss(ID: 9, type: float) (1/1) Processing row 1 to 1,000 from LIMIT 0 / 100,000 ts_number - 0_userdata.0.Variablen.Strom.Steckdose_Dachgeschoss (1/1) InfluxDB error float() argument must be a string or a real number, not 'NoneType'Kann ich das entweder irgendwie überspringen oder gar besser konvertieren in eine 0 oder etwas in der Art?
Vielen Dank
Gruß
Christoph
-
Hallo zusammen,
vielen Dank für das Script und da drumherum hier @JackGruber @UlliJ - ich bin gerade dabei, ca 60mio Datensätze von einer SQL auf eine influx zu migrieren.
Ich stoße hierbei leider immer wieder mitten in der Übertragung auf folgenden Fehler:Total metrics in ts_number: 1 0_userdata.0.Variablen.Strom.Steckdose_Dachgeschoss(ID: 9, type: float) (1/1) Processing row 1 to 1,000 from LIMIT 0 / 100,000 ts_number - 0_userdata.0.Variablen.Strom.Steckdose_Dachgeschoss (1/1) InfluxDB error float() argument must be a string or a real number, not 'NoneType'Kann ich das entweder irgendwie überspringen oder gar besser konvertieren in eine 0 oder etwas in der Art?
Vielen Dank
Gruß
Christoph
Hatte gerade genau das gleiche Problem. Scheinbar sind da teilweise "nicht" float Werte in mysql DB vorhanden.
z.b. nullHabe es recht simple gelöst, indem einfach alle Werte die nicht Float sind auf 0 gesetzt werden.
Änderung im Script war einfach beim float konvertieren ein "or 0" anfügen:# Daten in richtigen Typ wandeln if field_label == "value": if datatype == 0: # ts_number fields["value"] = float(record["value"] or 0) elif datatype == 1: # ts_string fields["value"] = str(record["value"]) elif datatype == 2: # ts_bool fields["value"] = bool(record["value"])@JackGruber
Vielen Dank für das coole Script. Einfach genial! -
@jackgruber sagte in Frage : Migrate MySQL nach Influxdb:
Hab das script etwas angepasst, damit alle Daten übernommen werden und diese auch auf einem leistungsschwachen Rasperry Pi ausgelesen werden können.
Frage:
Läuft das Script auch mit influxdb v2.x?
Hintergrund:
Der externe Zugriff wird ab v2 ja über Token abgesichert.
In der database.json sind aber nur username/password für influxdb hinterlegt. -
Ich muss 3 Jahre Daten importieren, aber irgendwann bekomme ich folgende Fehlermeldung:
InfluxDB error HTTPConnectionPool(host='192.168.178.155', port=8086): Max retries exceeded with url: /write?db=iobroker&rp=autogen (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fb8267db6d0>: Failed to establish a new connection: [Errno 111] Connection refused'))Die Batchsize habe ich hoch und runter getestet. Der Fehler ist sehr sporadisch, aber kommt defintiv, entweder am Datensatz X oder Y.
Hat jemand noch eine Idee. Könnte mir vorstellen, dass es nur eine Server-Einstellung ist, aber ich finde die Stelle nicht. In Google findet man auch kaum etwas. Danke
Gruß
-
Jetzt muss ich auch noch mal was Banales nachfragen:
Bei den Datenpunkten ist ja im Moment die Aufzeichnung bei SQL aktiviert.
Ich nehme an ich muss erst die Aufzeichnung bei InfluxDB aktivieren damit es die Datenpunkte dort gibt und dann die Daten migrieren?Oder?
-
Jetzt muss ich auch noch mal was Banales nachfragen:
Bei den Datenpunkten ist ja im Moment die Aufzeichnung bei SQL aktiviert.
Ich nehme an ich muss erst die Aufzeichnung bei InfluxDB aktivieren damit es die Datenpunkte dort gibt und dann die Daten migrieren?Oder?
@bananajoe sagte in Frage : Migrate MySQL nach Influxdb:
Jetzt muss ich auch noch mal was Banales nachfragen:
Bei den Datenpunkten ist ja im Moment die Aufzeichnung bei SQL aktiviert.
Ich nehme an ich muss erst die Aufzeichnung bei InfluxDB aktivieren damit es die Datenpunkte dort gibt und dann die Daten migrieren?Oder?
Moin,
ich bin mir mal wieder nicht sicher, ob ich alles korrekt verstehe, aber hilft Dir evtl. diese Lösung weiter?
Query SQL-DB und SQL Funktion damit solltest Du dir eigentlich das Bucket und layout in InfluxDb automatisch anlegen.
Alles nicht getestet, da ich gerade keine Postgresql oder mariadb zur Hand habe.
VG
Bernd -
Ich meinte das:
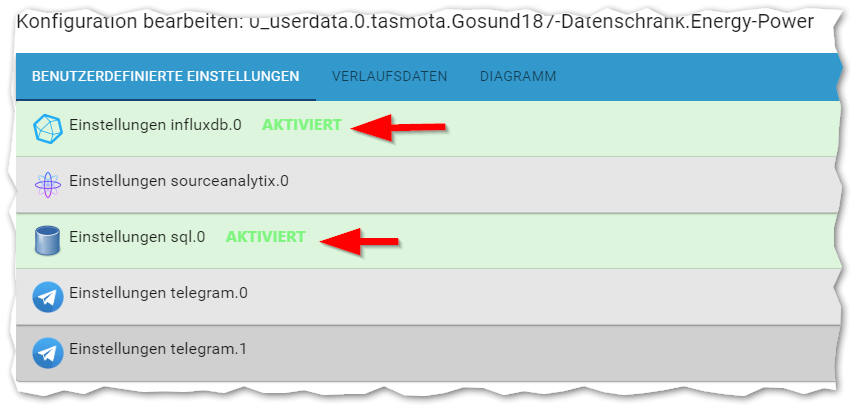
-
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden203
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge