

Grafana Tages/Monatsverbräuche Performance u. Darstellung?
-
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Die Zeile muss weg
|> yield(name: "last")@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Die Zeile muss weg
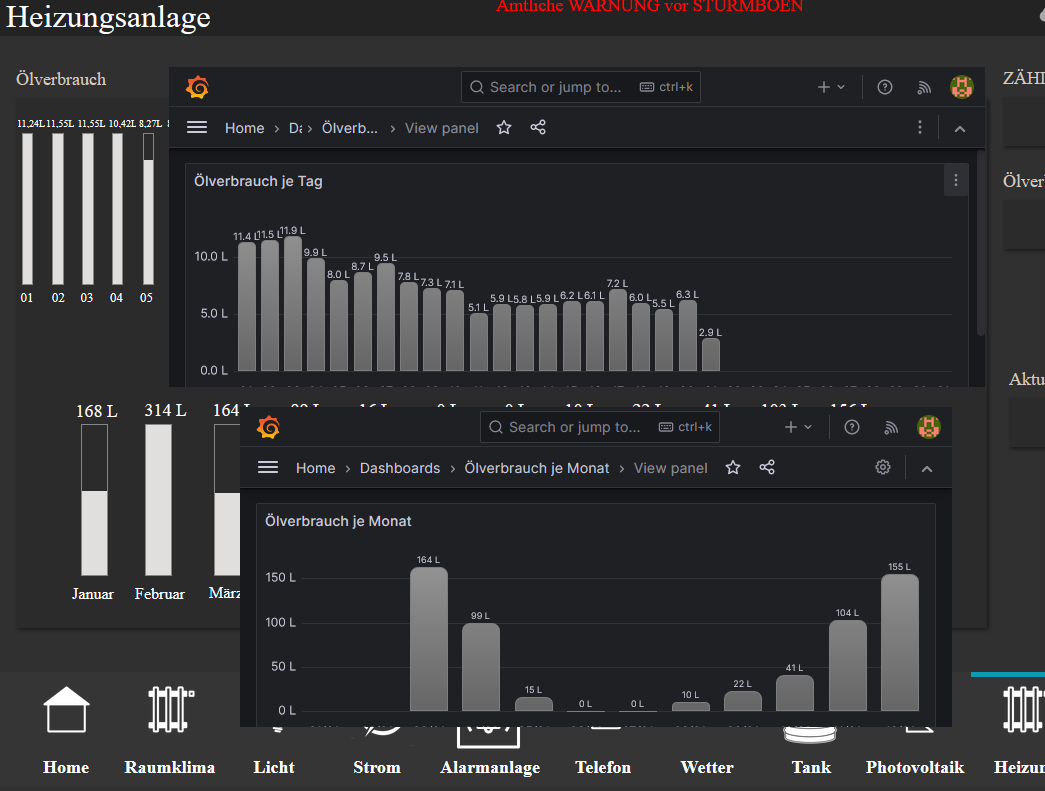
|> yield(name: "last")ok, gleiche Ausgabe:
{ "request": { "url": "api/ds/query?ds_type=influxdb&requestId=Q124", "method": "POST", "data": { "queries": [ { "datasource": { "type": "influxdb", "uid": "fe97a43e-a484-468d-ba5f-dff87870a54a" }, "query": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n \r\n union(tables: [tagesverbrauch, live])", "refId": "A", "datasourceId": 1, "intervalMs": 3600000, "maxDataPoints": 848 } ], "from": "1701385200000", "to": "1704063599999" }, "hideFromInspector": false }, "response": { "results": { "A": { "status": 200, "frames": [ { "schema": { "name": "OelVerbrTag", "refId": "A", "meta": { "typeVersion": [ 0, 0 ], "executedQueryString": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: 2023-11-30T23:00:00Z, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n \r\n union(tables: [tagesverbrauch, live])" }, "fields": [ { "name": "Time", "type": "time", "typeInfo": { "frame": "time.Time", "nullable": true } }, { "name": "value", "type": "number", "typeInfo": { "frame": "float64", "nullable": true }, "labels": {} } ] }, "data": { "values": [ [ 1701471600000, 1701558000000, 1701644400000, 1701730800000, 1701817200000, 1701903600000, 1701990000000, 1702076400000, 1702162800000, 1702249200000, 1702335600000, 1702422000000, 1702508400000, 1702594800000, 1702681200000, 1702767600000, 1702854000000, 1702940400000, 1703026800000, 1703113200000, 1703199600000, 1703286000000, 1703372400000 ], [ 11.24, 11.55, 11.55, 10.42, 8.27, 8.29, 9.52, 8.1, 7.29, 6.5, 5.79, 5.87, 5.42, 6.28, 6.19, 6.12, 6.59, 6.64, 5.46, 6.26, 5.19, 6.07, 6.08 ] ] } } ], "refId": "A" } } } } -
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Seh ich das richtig, dass im Moment der ergänzte "union" teil bei mir noch nichts zurück liefert?
Die Zeile muss weg
|> yield(name: "last")ok, gleiche Ausgabe:
{ "request": { "url": "api/ds/query?ds_type=influxdb&requestId=Q124", "method": "POST", "data": { "queries": [ { "datasource": { "type": "influxdb", "uid": "fe97a43e-a484-468d-ba5f-dff87870a54a" }, "query": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: v.timeRangeStart, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n \r\n union(tables: [tagesverbrauch, live])", "refId": "A", "datasourceId": 1, "intervalMs": 3600000, "maxDataPoints": 848 } ], "from": "1701385200000", "to": "1704063599999" }, "hideFromInspector": false }, "response": { "results": { "A": { "status": 200, "frames": [ { "schema": { "name": "OelVerbrTag", "refId": "A", "meta": { "typeVersion": [ 0, 0 ], "executedQueryString": "import \"timezone\"\r\nimport \"date\"\r\noption location = timezone.location(name: \"Europe/Berlin\")\r\ntagesverbrauch=from(bucket: \"iobroker\")\r\n |> range(start: 2023-11-30T23:00:00Z, stop: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"OelVerbrTag\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n\r\nlive=from(bucket: \"iobroker\")\r\n |> range(start: date.truncate(t:-1s, unit:1d))\r\n |> filter(fn: (r) => r[\"_measurement\"] == \"0_userdata.0.Heizöl.Zaehlerstandverbrauch\")\r\n |> filter(fn: (r) => r[\"_field\"] == \"value\")\r\n |> aggregateWindow(every: 1d, fn: sum, createEmpty: false)\r\n |> difference(nonNegative: true, columns: [\"_value\"])\r\n \r\n union(tables: [tagesverbrauch, live])" }, "fields": [ { "name": "Time", "type": "time", "typeInfo": { "frame": "time.Time", "nullable": true } }, { "name": "value", "type": "number", "typeInfo": { "frame": "float64", "nullable": true }, "labels": {} } ] }, "data": { "values": [ [ 1701471600000, 1701558000000, 1701644400000, 1701730800000, 1701817200000, 1701903600000, 1701990000000, 1702076400000, 1702162800000, 1702249200000, 1702335600000, 1702422000000, 1702508400000, 1702594800000, 1702681200000, 1702767600000, 1702854000000, 1702940400000, 1703026800000, 1703113200000, 1703199600000, 1703286000000, 1703372400000 ], [ 11.24, 11.55, 11.55, 10.42, 8.27, 8.29, 9.52, 8.1, 7.29, 6.5, 5.79, 5.87, 5.42, 6.28, 6.19, 6.12, 6.59, 6.64, 5.46, 6.26, 5.19, 6.07, 6.08 ] ] } } ], "refId": "A" } } } }Schwierig, so ohne Quelldaten. Was liefert
from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])Edit: und sehe ich das richtig? In "0_userdata.0.Heizöl.Zaehlerstandverbrauch" stehen keine Verbräuche, sondern Stände?
-
Schwierig, so ohne Quelldaten. Was liefert
from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])Edit: und sehe ich das richtig? In "0_userdata.0.Heizöl.Zaehlerstandverbrauch" stehen keine Verbräuche, sondern Stände?
Edit: und sehe ich das richtig? In "0_userdata.0.Heizöl.Zaehlerstandverbrauch" stehen keine Verbräuche, sondern Stände?
Ja, richtig. In der Version die bei mir zuviel Performance kostet, hatte ich die Zählerstände so abgefragt:
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d , fn: last, timeSrc: "_start") |> difference(nonNegative: true, columns: ["_value"]) |> yield(name: "last")Das möchten wir ja übers "union" nur für den aktuellen Tag ergänzen, richtig?
-
Schwierig, so ohne Quelldaten. Was liefert
from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])Edit: und sehe ich das richtig? In "0_userdata.0.Heizöl.Zaehlerstandverbrauch" stehen keine Verbräuche, sondern Stände?
aaah, Fortschritt :)
mit:
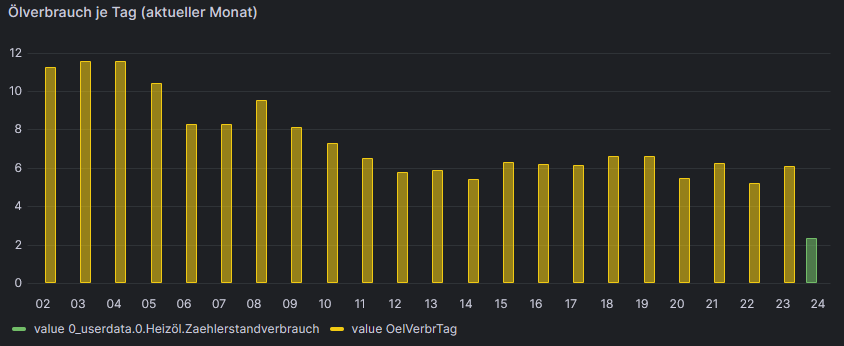
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])somit bleibt noch das Thema warum er den Tagesverbrauch auf der Zeitachse verschiebt. Wird jetzt ja besonders deutlich da es 2 Werte für den 24.12. gibt und nur der grüne ist richtig. Alle gelben sind um einen Tag verschoben.
-
aaah, Fortschritt :)
mit:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])somit bleibt noch das Thema warum er den Tagesverbrauch auf der Zeitachse verschiebt. Wird jetzt ja besonders deutlich da es 2 Werte für den 24.12. gibt und nur der grüne ist richtig. Alle gelben sind um einen Tag verschoben.
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
somit bleibt noch das Thema warum er den Tagesverbrauch auf der Zeitachse verschiebt. Wird jetzt ja besonders deutlich da es 2 Werte für den 24.12. gibt und nur der grüne ist richtig. Alle gelben sind um einen Tag verschoben.
Das kriegen wir auch noch hin. Zeig mal einen Screenshot von den unveränderten / unaggregierten Daten im InfluxDB Data Explorer.
-
aaah, Fortschritt :)
mit:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])somit bleibt noch das Thema warum er den Tagesverbrauch auf der Zeitachse verschiebt. Wird jetzt ja besonders deutlich da es 2 Werte für den 24.12. gibt und nur der grüne ist richtig. Alle gelben sind um einen Tag verschoben.
Ach, jetzt hab ich's. Ich habe dir eine falsche Syntax gegeben
falsch:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc="_start")richtig:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc: "_start") -
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
somit bleibt noch das Thema warum er den Tagesverbrauch auf der Zeitachse verschiebt. Wird jetzt ja besonders deutlich da es 2 Werte für den 24.12. gibt und nur der grüne ist richtig. Alle gelben sind um einen Tag verschoben.
Das kriegen wir auch noch hin. Zeig mal einen Screenshot von den unveränderten / unaggregierten Daten im InfluxDB Data Explorer.
-
Ach, jetzt hab ich's. Ich habe dir eine falsche Syntax gegeben
falsch:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc="_start")richtig:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc: "_start")@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Ach, jetzt hab ich's. Ich habe dir eine falsche Syntax gegeben
falsch:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc="_start")richtig:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc: "_start")Danke, es wird besser:
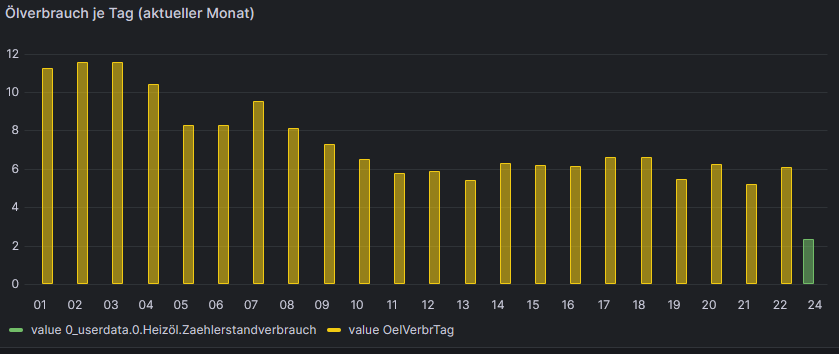
mit:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc: "_start") live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false, timeSrc:"_start") |> difference(nonNegative: true, columns: ["_value"]) union(tables: [tagesverbrauch, live]) -
Das kriegen wir auch noch hin. Zeig mal einen Screenshot von den unveränderten / unaggregierten Daten im InfluxDB Data Explorer.
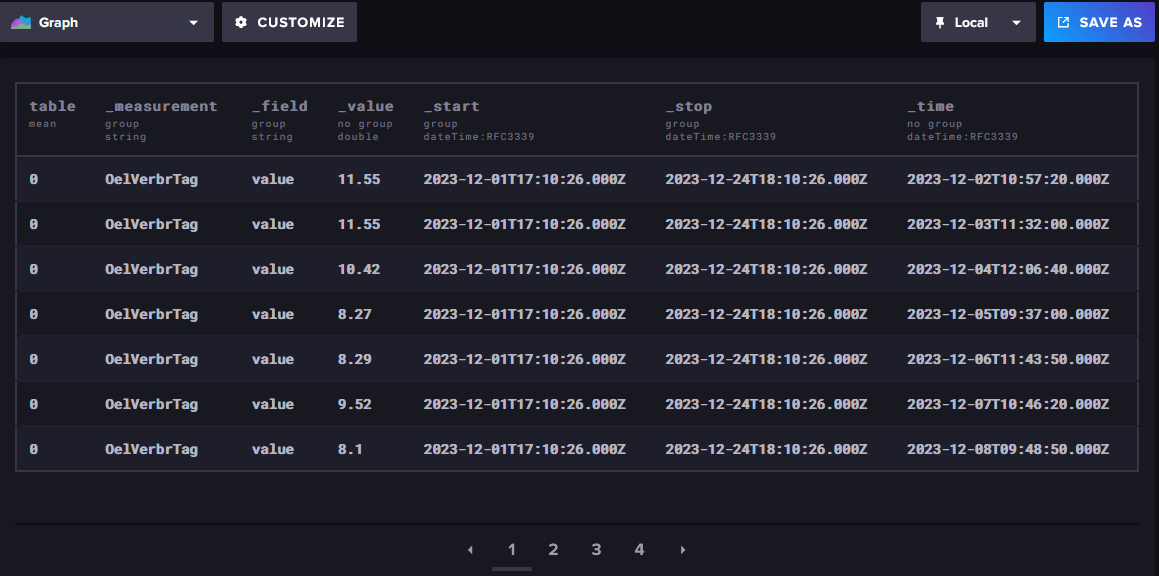
Sowas?
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Das kriegen wir auch noch hin. Zeig mal einen Screenshot von den unveränderten / unaggregierten Daten im InfluxDB Data Explorer.
Sowas?
Ich dachte, die Daten hätten den Zeitstempel 23:59 Uhr (local Time)?
Ist das hier der Verbrauch vom 02.12 oder 01.12.?

-
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Ach, jetzt hab ich's. Ich habe dir eine falsche Syntax gegeben
falsch:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc="_start")richtig:
|> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc: "_start")Danke, es wird besser:
mit:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false, timeSrc: "_start") live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false, timeSrc:"_start") |> difference(nonNegative: true, columns: ["_value"]) union(tables: [tagesverbrauch, live])Okay, wenn ich mir das ansehe, dann wird der Verbrauch des Vortages offensichtlich irgendwann am Folgetag ermittelt. Vor diesem Hintergrund müsste dann "timeSrc: "_start" wieder raus. Und ein "group" ans Ende. Dann sollte es passen.
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) union(tables: [tagesverbrauch, live]) |>group() -
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Das kriegen wir auch noch hin. Zeig mal einen Screenshot von den unveränderten / unaggregierten Daten im InfluxDB Data Explorer.
Sowas?
Ich dachte, die Daten hätten den Zeitstempel 23:59 Uhr (local Time)?
Ist das hier der Verbrauch vom 02.12 oder 01.12.?
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Das kriegen wir auch noch hin. Zeig mal einen Screenshot von den unveränderten / unaggregierten Daten im InfluxDB Data Explorer.
Sowas?
Ich dachte, die Daten hätten den Zeitstempel 23:59 Uhr (local Time)?
Ist das hier der Verbrauch vom 02.12 oder 01.12.?
ah, stimmt. Die Tagesverbräuche werden um 23:59h berechnet und in die DB geschrieben. Der Zeitstempel wird aber übernommen vom letzten Zählerstand. Wenn die Heizung in Nachtabsenkung geht kann der letzte Zählerstand in der DB (Eintrag nur bei Änderung) schon ein paar Stunden alt sein.
Könnte man ändern, aber solange es alles an einem Tag ist....die 11,55 sind vom 2.12.
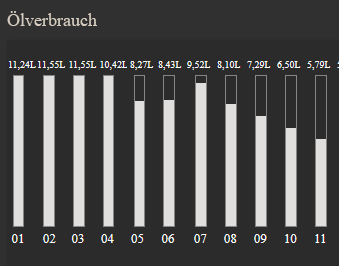
Was mich bei den Raw Data "wundert". Ich habe 1.12-24.12. im explorer selektiert. Der erste Wert in der Tabelle ist 11,55.
Hier fehlt aber 11,24L für den 1.12.
Hakt das irgendwo zwischen UTC und lokaler Zeit?Edit: Selektiere ich im Data Explorer vom 30.11.-24.11. erscheint als erster Wert der Tagesverbrauch vom 1.12. mit 11,24L
-
Okay, wenn ich mir das ansehe, dann wird der Verbrauch des Vortages offensichtlich irgendwann am Folgetag ermittelt. Vor diesem Hintergrund müsste dann "timeSrc: "_start" wieder raus. Und ein "group" ans Ende. Dann sollte es passen.
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) union(tables: [tagesverbrauch, live]) |>group()@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Okay, wenn ich mir das ansehe, dann wird der Verbrauch des Vortages offensichtlich irgendwann am Folgetag ermittelt. Vor diesem Hintergrund müsste dann "timeSrc: "_start" wieder raus. Und ein "group" ans Ende. Dann sollte es passen.
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1d, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) union(tables: [tagesverbrauch, live]) |>group()Leider gar keine Ausgabe "Configured x field not found"
Hab auch keine Idee was gemeint ist. Ist x field der tagesverbrauch von tables: [tagesverbrauch, live]? -
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Leider gar keine Ausgabe "Configured x field not found"
Dann hast du wahrscheinlich die neue Query in ein Grafana Panel reinkopiert, in dem vorher ein Override oder eine andere Option definiert war, die noch den alten Spaltennamen enthält.
Also entweder in Grafana diese Stelle suchen oder ein neues Panel anlegen.
-
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Leider gar keine Ausgabe "Configured x field not found"
Dann hast du wahrscheinlich die neue Query in ein Grafana Panel reinkopiert, in dem vorher ein Override oder eine andere Option definiert war, die noch den alten Spaltennamen enthält.
Also entweder in Grafana diese Stelle suchen oder ein neues Panel anlegen.
Dann hast du wahrscheinlich die neue Query in ein Grafana Panel reinkopiert, in dem vorher ein Override oder eine andere Option definiert war, die noch den alten Spaltennamen enthält.
Danke!
Ja, hab in einem Panel getest und ein Neues zeigt dies: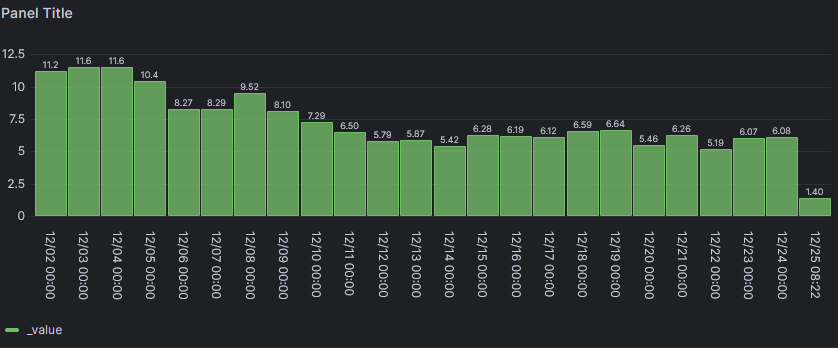
Es besteht noch ein Fehler. 11.2L ist vom 01.12 und die X-Achse entsprechend verschoben. Der "letzte" Tagesverbrauch vom 24.12. (5,64L) wird dann nicht gezeigt.
-
Dann hast du wahrscheinlich die neue Query in ein Grafana Panel reinkopiert, in dem vorher ein Override oder eine andere Option definiert war, die noch den alten Spaltennamen enthält.
Danke!
Ja, hab in einem Panel getest und ein Neues zeigt dies:Es besteht noch ein Fehler. 11.2L ist vom 01.12 und die X-Achse entsprechend verschoben. Der "letzte" Tagesverbrauch vom 24.12. (5,64L) wird dann nicht gezeigt.
Du hattest weiter oben aus "-1s" --> "-1d" gemacht, das hatte ich nicht gemerkt und übernommen, ist jetzt wieder korrigiert. Und mit einem zusätzlichen "truncate" wird es jetzt auch zum Start sauber an der Tagesgrenze ausgerichtet:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start:date.truncate(t:v.timeRangeStart, unit:1d), stop: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) union(tables: [tagesverbrauch, live]) |>group() -
Du hattest weiter oben aus "-1s" --> "-1d" gemacht, das hatte ich nicht gemerkt und übernommen, ist jetzt wieder korrigiert. Und mit einem zusätzlichen "truncate" wird es jetzt auch zum Start sauber an der Tagesgrenze ausgerichtet:
import "timezone" import "date" option location = timezone.location(name: "Europe/Berlin") tagesverbrauch=from(bucket: "iobroker") |> range(start:date.truncate(t:v.timeRangeStart, unit:1d), stop: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "OelVerbrTag") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: sum, createEmpty: false) live=from(bucket: "iobroker") |> range(start: date.truncate(t:-1s, unit:1d)) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Heizöl.Zaehlerstandverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) union(tables: [tagesverbrauch, live]) |>group() -
@marc-berg
Sorry, seh das Problem bei mir einfach nicht. Etliche mal im neuen Panel probiert und Zeitachse passt bei mir nicht und der "union" fehlt. In Grafana die Zeit steht auf "This month".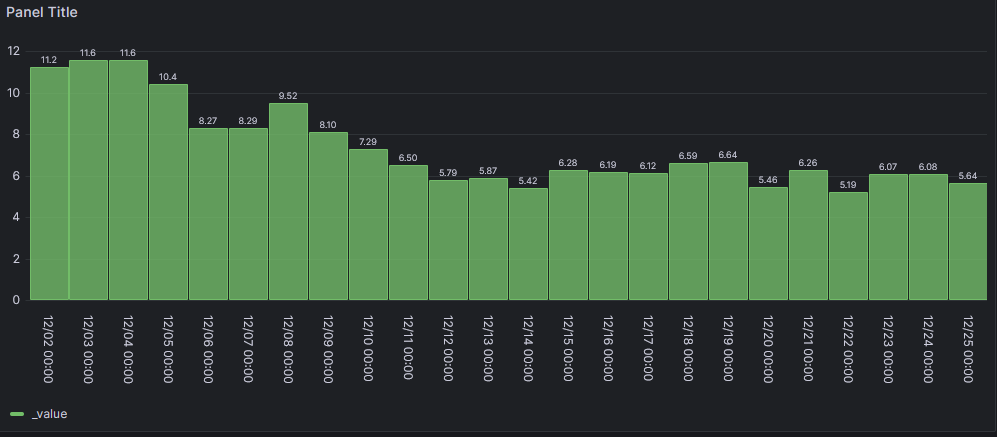
-
Zeig bitte mal die Daten vom 24.12. und von heute im Data Explorer ohne aggregate. Wenn man die Quelldaten nicht hat, ist es schwer zu testen.
-
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
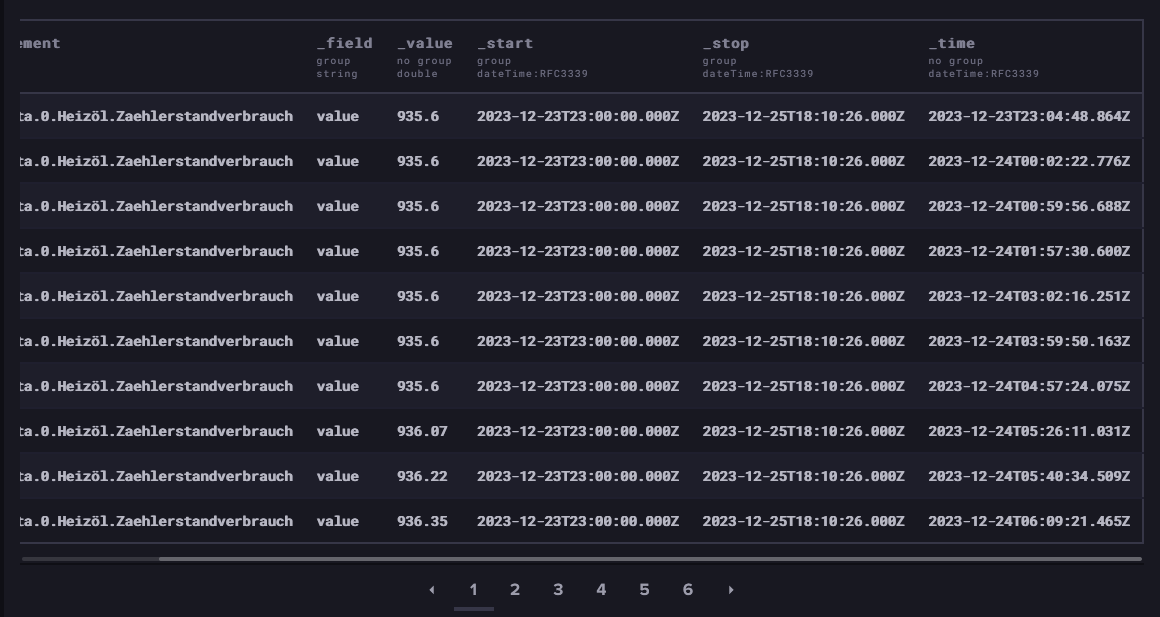
Tagesverbrauch:
Nochmal zum Verständnis, wahrscheinlich habe ich das noch nicht geschnallt: die 5.64 Liter vom 24.12. 09:38 UTC, ist das die Summenberechnung von gestern für den 23.12. oder die Berechnung von heute für den 24.12., wobei um 09:38 (UTC) der letzte Verbrauch vorlag?
-
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Tagesverbrauch:
Nochmal zum Verständnis, wahrscheinlich habe ich das noch nicht geschnallt: die 5.64 Liter vom 24.12. 09:38 UTC, ist das die Summenberechnung von gestern für den 23.12. oder die Berechnung von heute für den 24.12., wobei um 09:38 (UTC) der letzte Verbrauch vorlag?
@marc-berg said in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
@dieter_p sagte in Grafana Tages/Monatsverbräuche Performance u. Darstellung?:
Tagesverbrauch:
Nochmal zum Verständnis, wahrscheinlich habe ich das noch nicht geschnallt: die 5.64 Liter vom 24.12. 09:38 UTC, ist das die Summenberechnung von gestern für den 23.12. oder die Berechnung von heute für den 24.12., wobei um 09:38 (UTC) der letzte Verbrauch vorlag?
Nein. Die Verwirrung bringt da der Zeitstempel rein (die Uhrzeit ist gerade ziemlich sinnfrei)
die 5.64 Liter Tagesverbrauch ist die Summe für den 24.12.-> Man findet in der DB immer genau einen Wert des Tagesverbrauchs mit gleichem Zeitstempel des gleichen Tages (Uhrzeit ist nicht zu beachten). Dies allerdings erst um 23:59h aber mit einem früheren Zeitpunkt vom gleichen Tag.
2023-12-24Txxxx -> liefert den Tagesverbrauch vom 2023-12-24
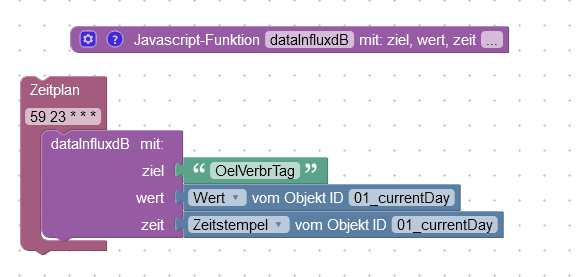
P.S.: Könnte den Zeitstempel auch einfach mal fix auf 23:59:59 setzen, das macht sicher etwas mehr Sinn. Würde aber nichts an unserer derzeitigen Logik ändern, oder?

Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
477
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge