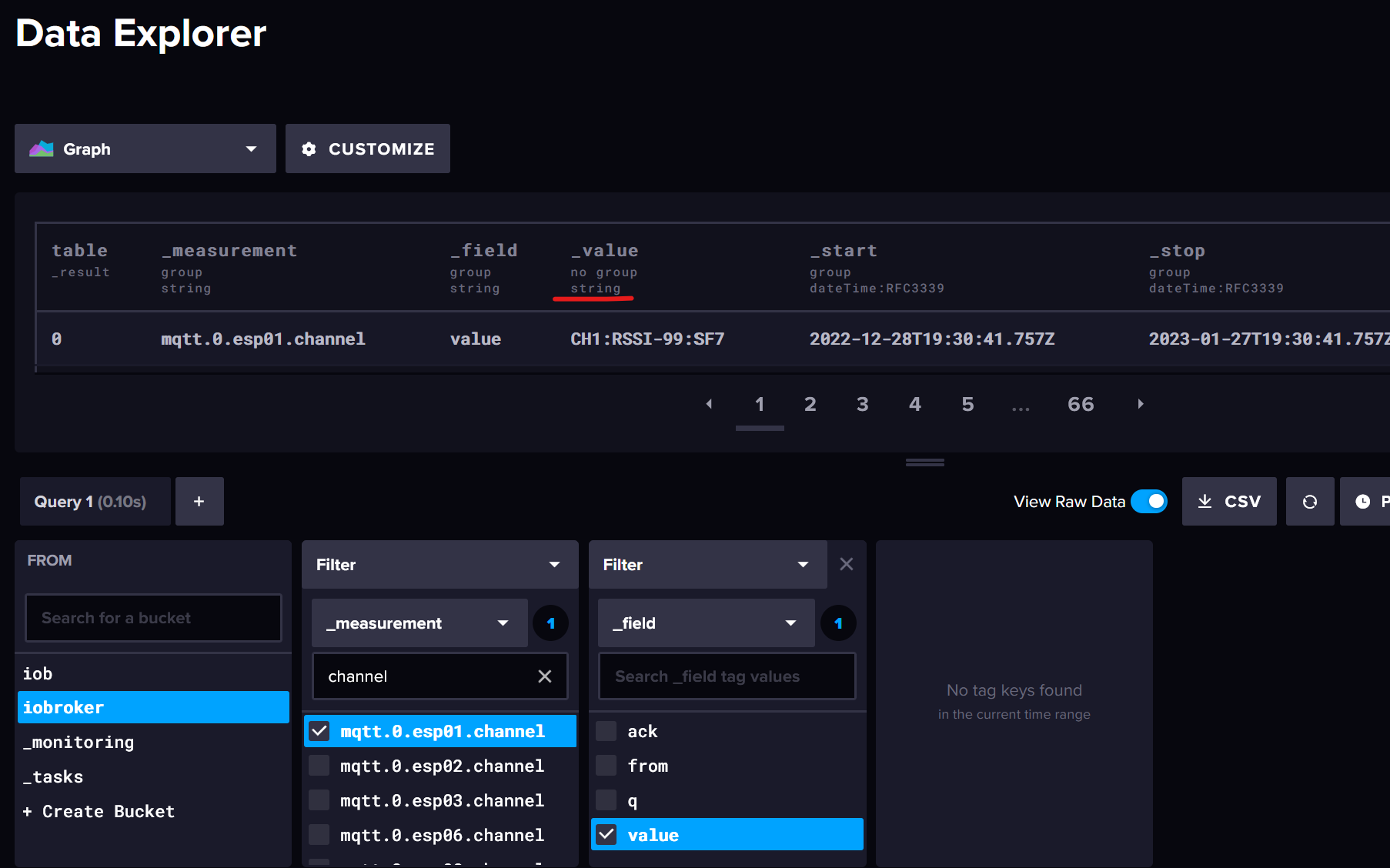
[Gelöst ]measurements definieren für influxdb
-
Hallo zusammen,
ich bin leider noch ziemlich am Anfang mit der Nutzung von influxdb und hänge daher recht oft an kleinen Themen.
Diesmal komme ich aber auch nach der Suche im Netz nicht mehr weiter.Ich habe u.a. BMS Werte, die über die Objekte in influxdb geschrieben werden. Leider wird dabei für jedes Objekt ein eigenes Measurement angelegt.
Kann man das irgendwie abändern, sodass man z.B. nur ein Measurement für BMS, ein weiteres für die Heizung etc. hat?Falls nicht, wäre es schön wenn man für die Tasks einen Filter mit ner Wildcard für die measurements angeben könnte. Die aktuellen Measurements fangen allesamt gleich an (mqtt.0...)
Ich möchte damit die Werte nach x Tagen aggregieren um das Datenvolumen im Zaum zu halten (aktuell alle 2s danach durchschnitt über 1m).Ein einzelner Measurement Wert kann mit dieser query aggregiert werden:
from(bucket: "iobroker")
|> range(start: -7mo)
|> filter(fn: (r) => r["_measurement"] == "mqtt.0.JK_BMS_1.Data.Battery_Voltage")
|> filter(fn: (r) => r["_field"] == "value")
|> aggregateWindow(
every: 1m,
fn: mean,
createEmpty: false
)
|> to(
bucket: "Spielwiese",
)Folgendes habe ich im Netz gefunden und probiert, komme damit aber nicht weiter:
|> filter(fn: (r) => strings.containsStr(v: r._measurement, substr: "mqtt") == true)
--> undefined identifier strings|> filter(fn: (r) => r["_measurement"] =~ /mqtt/)
--> unsupported input type for mean aggregate: stringLasse ich den Filter ganz weg, dann bearbeitet er die ersten 5 Measurements und hört dann auf.
Hat da jemand eine Idee wie man hier weiter voran kommt?Vielen Dank!
Freundliche Grüße
Christian -
@cksit sagte in measurements definieren für influxdb:
Folgendes habe ich im Netz gefunden und probiert, komme damit aber nicht weiter:
|> filter(fn: (r) => strings.containsStr(v: r._measurement, substr: "mqtt") == true)
--> undefined identifier stringsIn dieser Variante musst Du die "Strings" Package vorher importieren:
import "strings" from(bucket: "iobroker") |> range(start: -7mo) |> filter(fn: (r) => strings.containsStr(v: r._measurement, substr: "mqtt") == true) |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1m,fn: mean,createEmpty: false) |> to(bucket: "Spielwiese") -
@cksit sagte in measurements definieren für influxdb:
|> filter(fn: (r) => r["_measurement"] =~ /mqtt/)
--> unsupported input type for mean aggregate: stringDieser Fehler rührt daher, dass Du in Deinen Quelldaten nicht nur Zahlen hast. Strings lassen sich natürlich nicht "mitteln" (mean). Da musst Du die Filterkriterien noch verfeinern, sodass in den Values nur Zahlen auftauchen.
Edit: z.B. so:
import "types" ... |> filter(fn: (r) => types.isType(v: r._value, type: "float")) ... -
@marc-berg
das mit dem import "strings" habe ich natürlich übersehen gehabt
Jetzt macht er wenigstens etwas, aber leider ignoriert er einige Measurements. Ich habe mal in beiden buckets nach "battery" gesucht und statt 8 Measurements habe ich nur noch 5...
Am Namen sieht man, dass sie alle mit mqtt anfangen.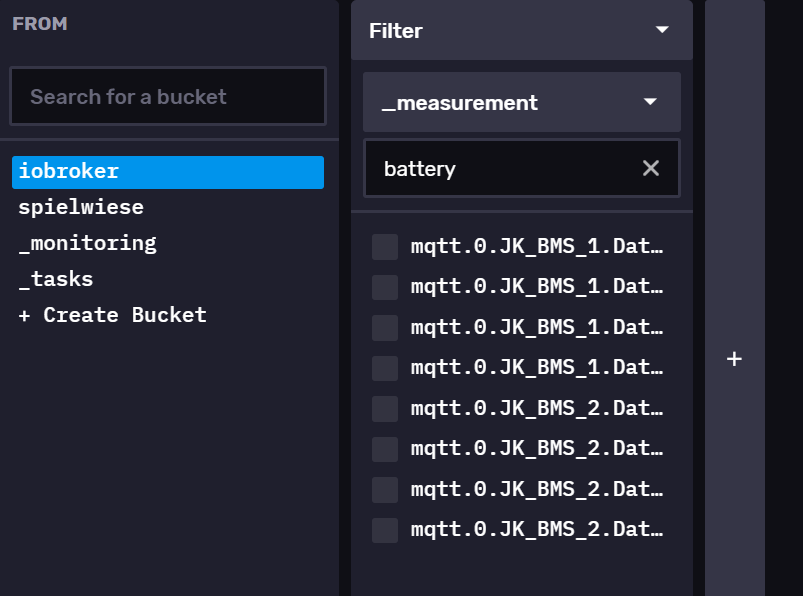
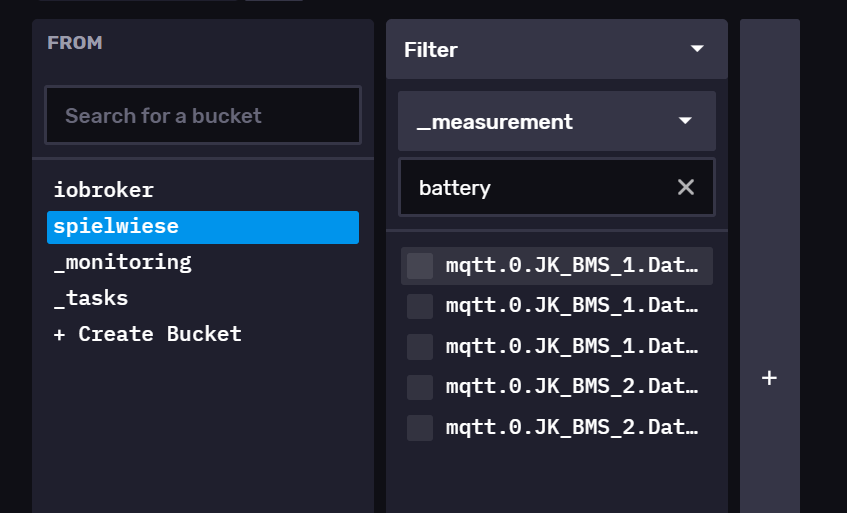
Bezüglich:
|> filter(fn: (r) => r["_measurement"] =~ /mqtt/)
--> unsupported input type for mean aggregate: stringDa hatte ich die Systematik falsch verstanden. Ich dachte ich könnte bei den measurements schon nach string filtern.
so richtig habe ich noch nicht verstanden an was ich es festmachen kann... -
@cksit
wie sieht die Abfrage jetzt konkret aus? -

import"strings"
from(bucket: "iobroker")
|> range(start: -1h)
|> filter(fn: (r) => strings.containsStr(v: r._measurement, substr: "mqtt") == true)
|> filter(fn: (r) => r["_field"] == "value")
|> aggregateWindow(
every: 1m,
fn: mean,
createEmpty: false
)
|> to(
bucket: "spielwiese",
)ich habe sie erstmal auf -1h gesetzt um schnell was sehen zu können.
-
@cksit sagte in measurements definieren für influxdb:
das mit dem import "strings" habe ich natürlich übersehen gehabt
Jetzt macht er wenigstens etwas, aber leider ignoriert er einige Measurements. Ich habe mal in beiden buckets nach "battery" gesucht und statt 8 Measurements habe ich nur noch 5...
Ich kann mir nur vorstellen, dass die Datentypen bei den fehlenden Measurements nicht passen. Mir ist jetzt kein Befehl bekannt, mit dem man sich die Typen "am Stück" anzeigen lassen kann. Im Data Explorer kann man sich aber die fehlenden Measurements anzeigen lassen und den Datentyp checken.
-
@marc-berg
Nicht übertragen:

Übertragen:

Sehen soweit gleich aus...
Noch eine Idee wo man suchen kann?
Vielen Dank!
-
@cksit sagte in measurements definieren für influxdb:
Übertragen:
?
Ansonsten würde ich mich jetzt Stück für Stück an das Problem ranrobben. Also zunächst mal nur eines der Measurement selektieren, welches Probleme macht. Werden die Daten dann übertragen? Was passiert, wenn man das "to(Bucket ...)" weg lässt, kommen Ergebnisse? Was passiert, wenn man nur Zeit-Teilbereiche selektiert?
Und wenn das alles nichts hilft, das Problem bei https://community.influxdata.com vortragen.
Edit: Was sagt eigentlich das Monitoring-Bucket, gibt es dort Meldungen?
-
@cksit said in measurements definieren für influxdb:
Ich habe u.a. BMS Werte, die über die Objekte in influxdb geschrieben werden. Leider wird dabei für jedes Objekt ein eigenes Measurement angelegt.
Kann man das irgendwie abändern, sodass man z.B. nur ein Measurement für BMS, ein weiteres für die Heizung etc. hat?Hallo,
ich habe auch diese Gedanken und würde gerne auch nur ein Measurement haben und dafür mit Tags zu "rangieren"...
Hast Du dazu noch etwas neues gefunden?Ducis hat in einem anderem Post dieses Blockly veröffentlicht:
@ducis sagte in InfluxDB mit eigenen Tags und Measurements schreiben:
Ich könnte mir vorstellen, das mein PI schon ganz schön belastet wird, wenn er die Daten vom Stromzähler über dieses Blockly schreibt...
Gruß
Andreas -
Habe es mittlerweile hinbekommen.
Leider war es tatsächlich so, dass ich in einem Measurement Strings hatte. Manchmal habe ich daraufhin die Fehlermeldung erhalten und manchmal eben nicht....
Habe dann den Filter auf die Measurements gesetzt wo ich genau weiß, dass nur Zahlen enthalten sind. Damit geht es.Muss jetzt also nach und nach per query die Daten in ein neues Bucket umrechnen und sobald das fertig ist wird die Aufbewahrungszeit auf 1 Monat gesetzt.
Über die Tasks können dann die einzelnen Measurements wöchentlich aufgeräumt werden.Ist keine schöne Lösung, aber sie funktioniert.
@Kapitaen31
Leider habe ich nichts dazu gefunden. Über den Weg der Skripte habe ich auch schon nachgedacht, aber die wären in meinem Fall schon sehr groß und würden das System zu arg belasten.Meine Idee ist es daher eher, dass ich später mal einzelne Werte weglasse, sobald das System einwandfrei läuft...
")
-
@cksit sagte in measurements definieren für influxdb:
Leider war es tatsächlich so, dass ich in einem Measurement Strings hatte. Manchmal habe ich daraufhin die Fehlermeldung erhalten und manchmal eben nicht....
Habe dann den Filter auf die Measurements gesetzt wo ich genau weiß, dass nur Zahlen enthalten sind. Damit geht es.Darum hatte ich auch den Hinweis mit dem Filter auf "float" gegeben. Damit wäre es vielleicht einfacher gegangen:
import "types" ... |> filter(fn: (r) => types.isType(v: r._value, type: "float")) ...Aber wenn Du jetzt einen Weg gefunden hast, ist ja alles gut. Das mit dem Bereinigen/Umrechnen ist natürlich nervig.
-
Jetzt wo wir drüber reden...

Ja das wäre sinnvoller gewesen. Aber gut man hat gerade ne steile Lernkurve mit dem System.Vielen Dank für die Unterstützung!