NEWS


-
@SpacerX: Danke für den super Tipp. Inzwischen hab ich mich etwas in Flux eingearbeitet :-)
Da ich auch Probleme mit nicht passenden Werten hatte, kann Ich ja mal zeigen wie Ich es gelöst hab.
fn: last bringt folgendes Problem. Der Stromverbrauch wird nicht von 0:00 - 0:00Uhr berechnet. Sondern mit dem Wert zuvor. Der letzte also. z.B. 23:00 - 23:00Uhr. Finde Ich nicht ganz so schön. Deshalb hab ich fn: first verwendet.
Damit passten die Zeiten aber nicht mehr. Das hab ich folgt gelöst:
|> map(fn: (r) => ({r with _time: date.add(d: -1h, to: r._time)}))mit d: -1h, hab ich den Zeitstempel um eine Stunde verschoben.
Mein kompletter Code um auf Stundenbasis zu Downsampeln sieht wie folgt aus :
import "date" option task = {name: "Stromverbrauch", every: 1h} data = from(bucket: "ioBroker") |> range(start: -24h, stop: 1h) |> filter(fn: (r) => r["_measurement"] == "javascript.0.Info.StromZaehler.Zaehlerstand_Min") |> filter(fn: (r) => r["_field"] == "value") data |> aggregateWindow(every: 1h, fn: first, createEmpty: false) |> difference(nonNegative: true, columns: ["_value"]) |> toInt() |> map(fn: (r) => ({r with _value: r._value / 10})) |> map(fn: (r) => ({r with _time: date.add(d: -1h, to: r._time)})) |> set(key: "_Interval", value: "1h") |> to(bucket: "Energie", org: "inFluxDB", tagColumns: ["_Interval"])Hoffe ich konnte damit helfen....
-
kleine Frage meinerseits. Könnte man so einen Task nicht auch in das gleiche Bucket zurückschreiben.
Dh wenn ich zB Daten die älter als 90Tage filtere und diese aggregiere (zB Tagesdurchschnitt) und diese dann wieder ins gleiche Bucket schreibe...
habe ich dann nicht von ganz alten daten bis heute -90Tage ein Tagesdurchschnitt und -89 Tage bis heute die Minutenaufzeichnung?
evt müsste man ein zwischenspeichern machen?
option task = { name: "AggregationTask", every: 24h, offset: 0h } from(bucket: "iobroker") |> range(start: -2y, stop: -90d) |> filter(fn: (r) => r["_measurement"] == "Aussentemperatur") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: mean, createEmpty: true) |> to(bucket: "temporary_bucket") from(bucket: "iobroker") |> range(start: -2y, stop: -90d) |> drop() from(bucket: "temporary_bucket") |> range(start: -2y, stop: -90d) |> to(bucket: "iobroker")jrgendwie so, jedoch geht das oben so nicht beim versucht
-
kleine Frage meinerseits. Könnte man so einen Task nicht auch in das gleiche Bucket zurückschreiben.
Dh wenn ich zB Daten die älter als 90Tage filtere und diese aggregiere (zB Tagesdurchschnitt) und diese dann wieder ins gleiche Bucket schreibe...
habe ich dann nicht von ganz alten daten bis heute -90Tage ein Tagesdurchschnitt und -89 Tage bis heute die Minutenaufzeichnung?
evt müsste man ein zwischenspeichern machen?
option task = { name: "AggregationTask", every: 24h, offset: 0h } from(bucket: "iobroker") |> range(start: -2y, stop: -90d) |> filter(fn: (r) => r["_measurement"] == "Aussentemperatur") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: mean, createEmpty: true) |> to(bucket: "temporary_bucket") from(bucket: "iobroker") |> range(start: -2y, stop: -90d) |> drop() from(bucket: "temporary_bucket") |> range(start: -2y, stop: -90d) |> to(bucket: "iobroker")jrgendwie so, jedoch geht das oben so nicht beim versucht
@cainam
Du kannst die Daten natürlich in das gleiche Bucket schreiben, das Problem (dass du ja offensichtlich schon gefunden hast) besteht im Löschen der Daten. Das geht meines Wissens aus einem Task heraus nicht, sondern nur per API oder CLI. Theoretisch könnte man das Löschen über einen Cronjob durchführen und die Aggregate Funktionen inkl. Schreiben über ein temporäres Bucket per Task und das Ganze zeitlich synchronisieren ... Schwierig ...Ich glaube, für diese Anforderung sind die Tasks raus. Stattdessen würde ich das ganze über ein Bash-Skript lösen.
-
Bist du sicher geht das mit drop nicht?
Es wäre even einfach die Daten so zu reduzieren anstatt alles neue buckets zu machen… auch vergessen Risiko ist massiv tiefer
@cainam sagte in Datenaufzeichnung Retention InfluxDB 2.0:
Bist du sicher geht das mit drop nicht?
Ja.
-
@spacerx Nun eigentlich sollte man es mit Konsolidierungstasks in andere buckets wegschreiben - so verstehe ich das Konzept der influxdb. Deshalb den iobroker mit der kürzesten Aufbewahrungszeit und dann je nachdem wie man konsolidieren will in weitere Buckets. Der iobroker schreibt ja nur in der Instanz - man ruft die Daten dort ja in der Regel nicht ab.
Re: Datenaufzeichnung Retention InfluxDB 2.0
Dazu hätte ich noch eine Frage.
Das Bucket "iobroker" stelle ich auf 180 Tage.
Das Bucket "iobroker-downsampling" stelle ich auf 5 Jahre.Ich schreibe jetzt monatlich den Wasserverbrauch weg.
Wenn ich nun mit Grafana eine Auswertung über 3 Jahre machen, müsste ein Teil der Daten aus dem iobroker Bucket und der andere Teil aus dem iobroker-downsampling Bucket kommen.
Wäre das so der richtige Aufbau?
Würde ich das dann so umbauen müssen:
from(bucket: "iobroker" & "iobroker-downsampling") |> range(start: -12mo) |> filter(fn: (r) => r["_measurement"] == "Wasserzaehler-CAM-Haus") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false, timeSrc: "_start") |> keep(columns: ["_value", "_time"]) -
Re: Datenaufzeichnung Retention InfluxDB 2.0
Dazu hätte ich noch eine Frage.
Das Bucket "iobroker" stelle ich auf 180 Tage.
Das Bucket "iobroker-downsampling" stelle ich auf 5 Jahre.Ich schreibe jetzt monatlich den Wasserverbrauch weg.
Wenn ich nun mit Grafana eine Auswertung über 3 Jahre machen, müsste ein Teil der Daten aus dem iobroker Bucket und der andere Teil aus dem iobroker-downsampling Bucket kommen.
Wäre das so der richtige Aufbau?
Würde ich das dann so umbauen müssen:
from(bucket: "iobroker" & "iobroker-downsampling") |> range(start: -12mo) |> filter(fn: (r) => r["_measurement"] == "Wasserzaehler-CAM-Haus") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: 1mo, fn: sum, createEmpty: false, timeSrc: "_start") |> keep(columns: ["_value", "_time"])@bitwicht sagte in Datenaufzeichnung Retention InfluxDB 2.0:
Würde ich das dann so umbauen müssen:
So (mit "&") geht das nicht. Dafür sollte die
unionFunktion geeignet sein. Du machst zwei Abfragen auf jeweils ein Bucket und "klebst" die mitunionsozusagen untereinander. -
Das macht natürlich alles viel komplexer.
Die Idee von @SpacerX ein Bucker "forever" und ein Bucket 180 Tage finde ich ja viel scharmanter.
Wäre dann aber nicht "best practice"@bitwicht sagte in Datenaufzeichnung Retention InfluxDB 2.0:
Das macht natürlich alles viel komplexer.
Einfach kann jeder...
Wäre dann aber nicht "best practice"
Best practise gibt es hier m.E nicht. Dazu sind die Anforderungen, Daten(mengen) und das eigene Wissen einfach zu unterschiedlich. Man muss sich den Weg suchen, der einem passt und der einem nicht die Hälfte der Lebenszeit wegfrisst.
-
Wenn ich die Idee von SpacerX umsetzte.
2 Adapter mit je einem Bucket (unterschiedliche Aufbewahrungszeiten).Siehst du da ein Problem in das ich laufen könnte ?
-
Na ich würde es auch nicht zu kompliziert machen. Wenn man nur die Tageswerte wegspeichert, da kann man doch weit zurückgehen und mit einem bucket arbeiten.
Wenn beispielsweise alle 5 Minuten ein Wert in die Datenbank geschrieben wird, dann entspricht das 51.840 Werten, wenn man diese 180 Tage aufbewahrt. Wenn man nun nur die Tageswerte mit der gleichen Werteanzahl benötigt sind das bereits 142 Jahre. Die Frage ist doch nur, wie benötige ich die 5 Minutenwerte und interessiert mich diese Details wirklich noch 10 Jahre später.
Da ich selbst kein Datensammler bin, weiß ich aber nicht, ob man das via grafana in einer Abfrage oder Diagramm umsetzen kann.
-
War nur ein Beispiel.
Ich logge den aktuellen Energieverbrauch von ca. 40 Shellys die ja fast alle Sekunde einen Wert speichern.
Das brauche ich natürlich nicht 1, 2 Jahre zurück.Ich glaube 2 Buckets würden mir reichen.
2 Buckets hätten für mich (Anfänger) gegenüber dem downsampling dein Vorteil, dass ich zB. bei Grafana Auswertungen nicht immer in beiden Buckets suchen muss.
-
@spacerx said in Datenaufzeichnung Retention InfluxDB 2.0:
Der Vollständigkeit halber noch der Erfolg bringende Task.
import "timezone" option location = timezone.location(name: "Europe/Berlin") option task = {name: "Downsampling Vb_Stromzaehler", cron: "1 0 * * *"} data = from(bucket: "ioBroker") |> range(start: -task.every) |> filter(fn: (r) => r["_measurement"] == "Vb_Stromzaehler") |> filter(fn: (r) => r["from"] == "system.adapter.javascript.0") data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start") |> toInt() // in Wh ohne Komma |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "RBE")Zu deinem downsampling Script noch ein paar Fragen ob ich das richtig verstehe.
- Die Werte im Quell-Bucket werden nicht gelöscht, sondern nur der letzte Wert eines Tages in ein anderes Bucket geschrieben oder ?
- In deinem Beispiel schreibst du in das neue Bucket Downsamling und in Measurement Vb_Stromzaehler - oder ?
- Den Job lege ich direkt in der Influx unter Tasks an ?
- Der Job läuft täglich um 00:01 Uhr (glaube 1 Minute, 0 Stunde). Wenn ich jetzt auf das Measuremnt eine Grafana Auswertung lege, würde der aktuelle Tag fehlen. Wenn ich den Job alle Stunde laufen lasse, müsste ich doch zumindest immer den nahezu aktuellen Tageswert haben oder habe ich da einen Denkfehler? Spricht was dagegen den Job jede Stunde laufen zu lassen ?
-
@spacerx said in Datenaufzeichnung Retention InfluxDB 2.0:
Der Vollständigkeit halber noch der Erfolg bringende Task.
import "timezone" option location = timezone.location(name: "Europe/Berlin") option task = {name: "Downsampling Vb_Stromzaehler", cron: "1 0 * * *"} data = from(bucket: "ioBroker") |> range(start: -task.every) |> filter(fn: (r) => r["_measurement"] == "Vb_Stromzaehler") |> filter(fn: (r) => r["from"] == "system.adapter.javascript.0") data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start") |> toInt() // in Wh ohne Komma |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "RBE")Zu deinem downsampling Script noch ein paar Fragen ob ich das richtig verstehe.
- Die Werte im Quell-Bucket werden nicht gelöscht, sondern nur der letzte Wert eines Tages in ein anderes Bucket geschrieben oder ?
- In deinem Beispiel schreibst du in das neue Bucket Downsamling und in Measurement Vb_Stromzaehler - oder ?
- Den Job lege ich direkt in der Influx unter Tasks an ?
- Der Job läuft täglich um 00:01 Uhr (glaube 1 Minute, 0 Stunde). Wenn ich jetzt auf das Measuremnt eine Grafana Auswertung lege, würde der aktuelle Tag fehlen. Wenn ich den Job alle Stunde laufen lasse, müsste ich doch zumindest immer den nahezu aktuellen Tageswert haben oder habe ich da einen Denkfehler? Spricht was dagegen den Job jede Stunde laufen zu lassen ?
@bitwicht genau so.
Wenn du dir in Grafana die Werte aus dem Downsampling anzeigst wird genau wie du sagst der Aktuelle Tag fehlen.
Ich mach das so, das ich mir die vergangenen Tage an im Diagramm anzeigen lasse und den aktuellen Tag aus der Quellaufzeichnung. Das kannst du im Diagramm Mischen. So brauche ich nur einmal am Tag Downsampeln.Das Quellbucket hat bei mir nur eine eine Aufzeichnungsdauer von 3 Monaten. Alle älteren Daten liegen dann komprimiert in einem Bucket mit unbegrenzter Aufzeichnung
-
Wie sieht denn deine Abfrage im Grafana aus, dass du Historie und Tageswert angezeigt bekommst?
Arbeitest du da mit "union" wie es Marc beschrieben hat oder machst du einfach 2 Abfragen die halt in einem Querry sind?
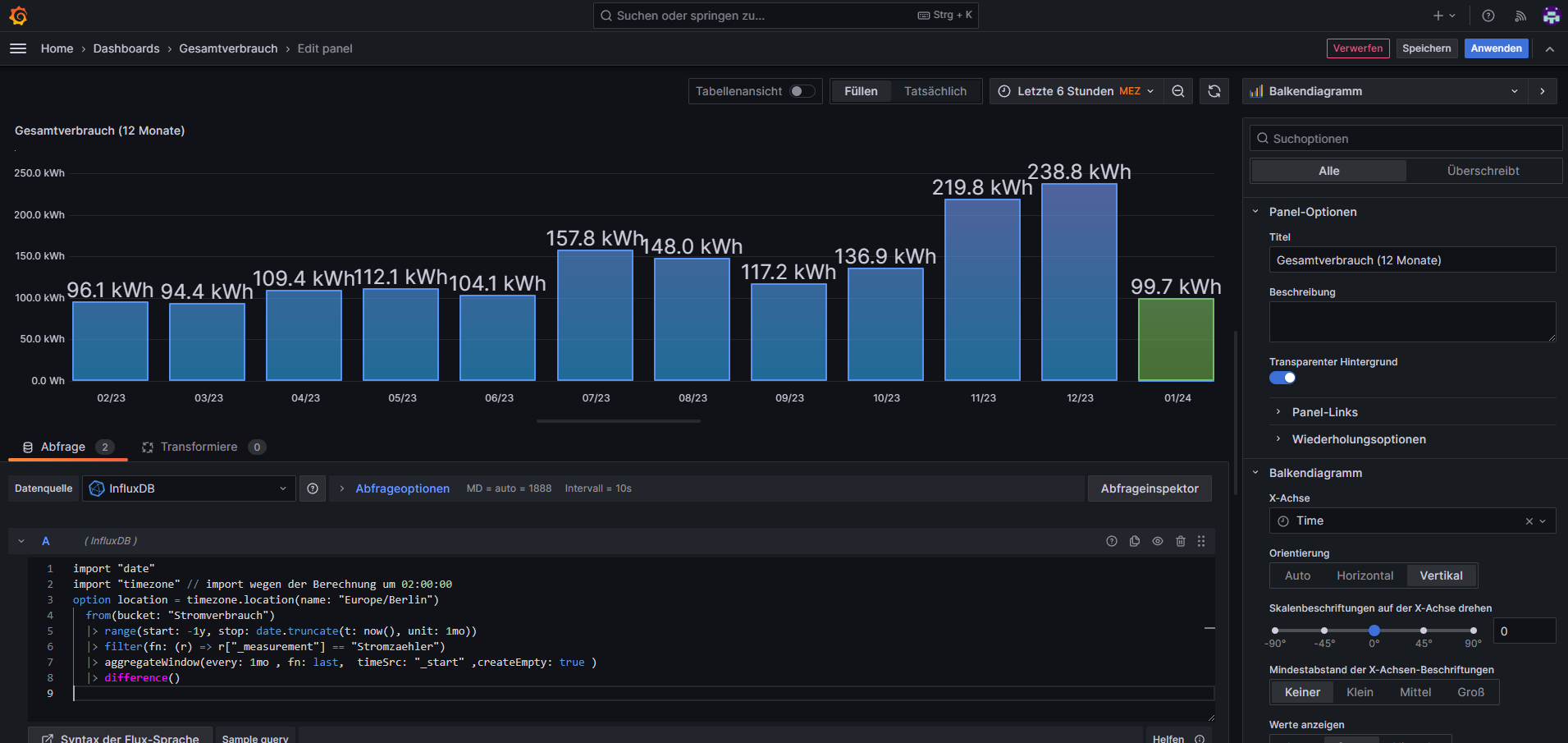
@bitwicht spät aber bin jetzt erst wieder am Rechner.
Abfrage A:
import "date" import "timezone" // import wegen der Berechnung um 02:00:00 option location = timezone.location(name: "Europe/Berlin") from(bucket: "Stromverbrauch") |> range(start: -1y, stop: date.truncate(t: now(), unit: 1mo)) |> filter(fn: (r) => r["_measurement"] == "Stromzaehler") |> aggregateWindow(every: 1mo , fn: last, timeSrc: "_start" ,createEmpty: true ) |> difference()Abfrage B
import "timezone" // import wegen der Berechnung um 02:00:00 option location = timezone.location(name: "Europe/Berlin") from(bucket: "ioBroker") |> range(start: -1mo, stop: now()) |> filter(fn: (r) => r["_measurement"] == "Vb_Stromzaehler") |> filter(fn: (r) => r["from"] == "system.adapter.javascript.0") |> aggregateWindow(every: 1mo , fn: last, timeSrc: "_start") // ,createEmpty: false ) |> difference()Der Screenshot dazu:
Support us
433
Online32.4k
Users81.5k
Topics1.3m
Posts