Test Adapter influxdb 2.0
-
@thomas-braun Habe die Datei hier gefunden:
/usr/lib/influxdb/scripts/influxdb.service
Dort habe ich die beiden Zeilen
#ExecStart=/usr/lib/influxdb/scripts/influxd-systemd-start.sh #Type=forkingauskommentiert und den Dienst neu gestartet:
sudo systemctl daemon-reloadHat aber am Ergebnis nichts geändert. Klappt trotzdem nicht. Noch jemand eine Idee?
EDIT: Ich bin jetzt zurück auf die V1.9.5. Den neuen Adapter bekomme ich nicht zum Rennen.
EDIT2: Habe jetzt noch das gefunden, was mich aber nicht weiter bringt. Gibt wohl keine Lösung. -
Hallo zusammen,
würde den Punkt von Feuersturm gerne nochmal aufgreifen. Ich habe grade den InfluxAdapter von 2.0.0 auf 2.1.1 aktualisiert und "iobroker upgrade self", danach waren alle mein Dashboards ohne Daten und der Query Explorer zeigt die gleiche Meldung kein Mean für Boolean. Ich nutze influxdb 2.0.
Anscheinend hat sich geändert wie die Messungen gespeichert werden, am Beispiel Smartmeter.
Vor dem Update wurde zu dem _measurement in _value der gemessen Wert z.B. 279 gespeichert und zusätzlich gab es Tags ack , from & q. Quasi zu jedem Messwert gab es die 4 Informationen. Ich bekomme meine 279W und könnte jetzt weiter eingrenzen ob z.B. der Wert ack war oder nicht.
Nach dem Update werden vier einzelne Felder zu dem _measurement gespeichert, damit kommt wenn man die abfrage nicht weiter eingrenzt jetzt 4 verschiedene Werte auch ein boolean vom ack zurück. Schlimmer es fehlt die Verknüpfung zwischen den Werten es sind jetzt 4 unabhängige Werte die bis auf den Zeit Stempel nicht korrelieren. Hoffe man kann das auf den folgenden Screenshots nachvollziehen, die gleiche Abfrage direkt auf der Influx GUI man sieht das Chaos nachher.
Vorher:
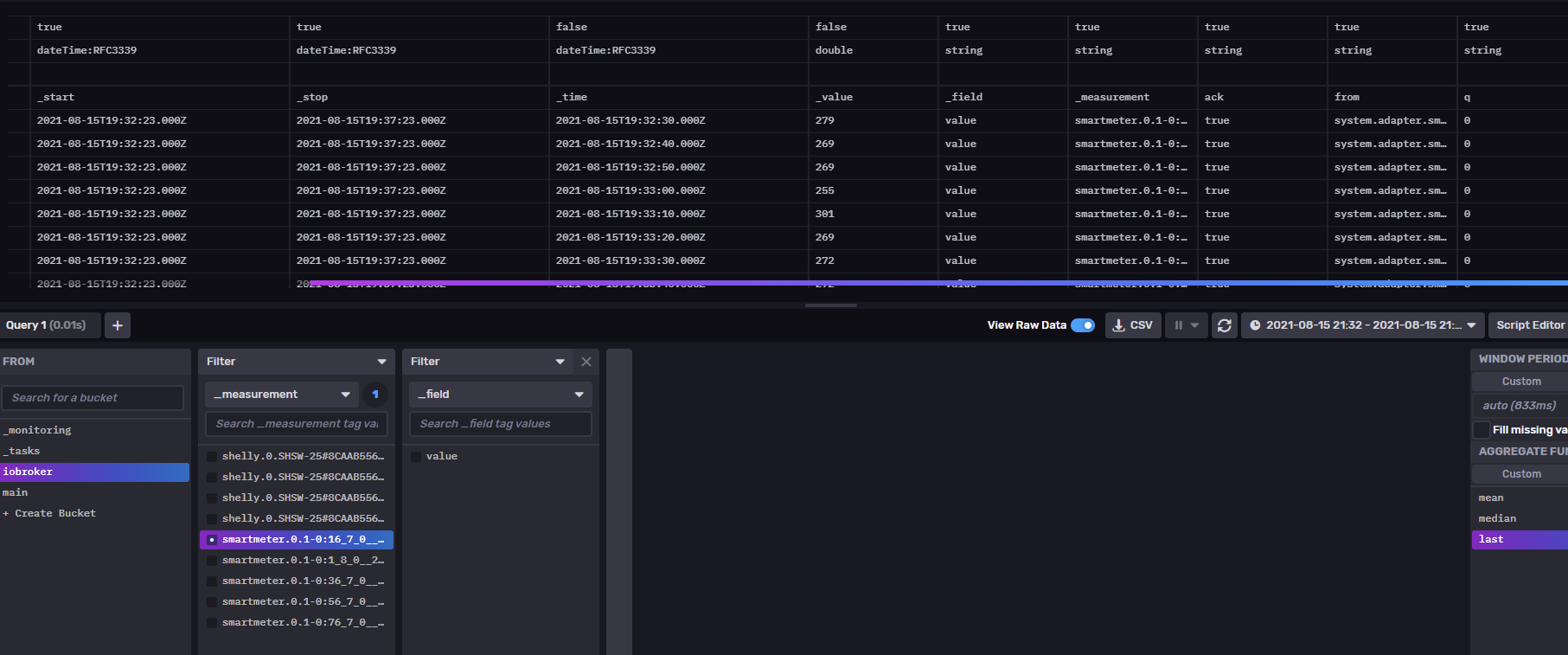
Nachher:
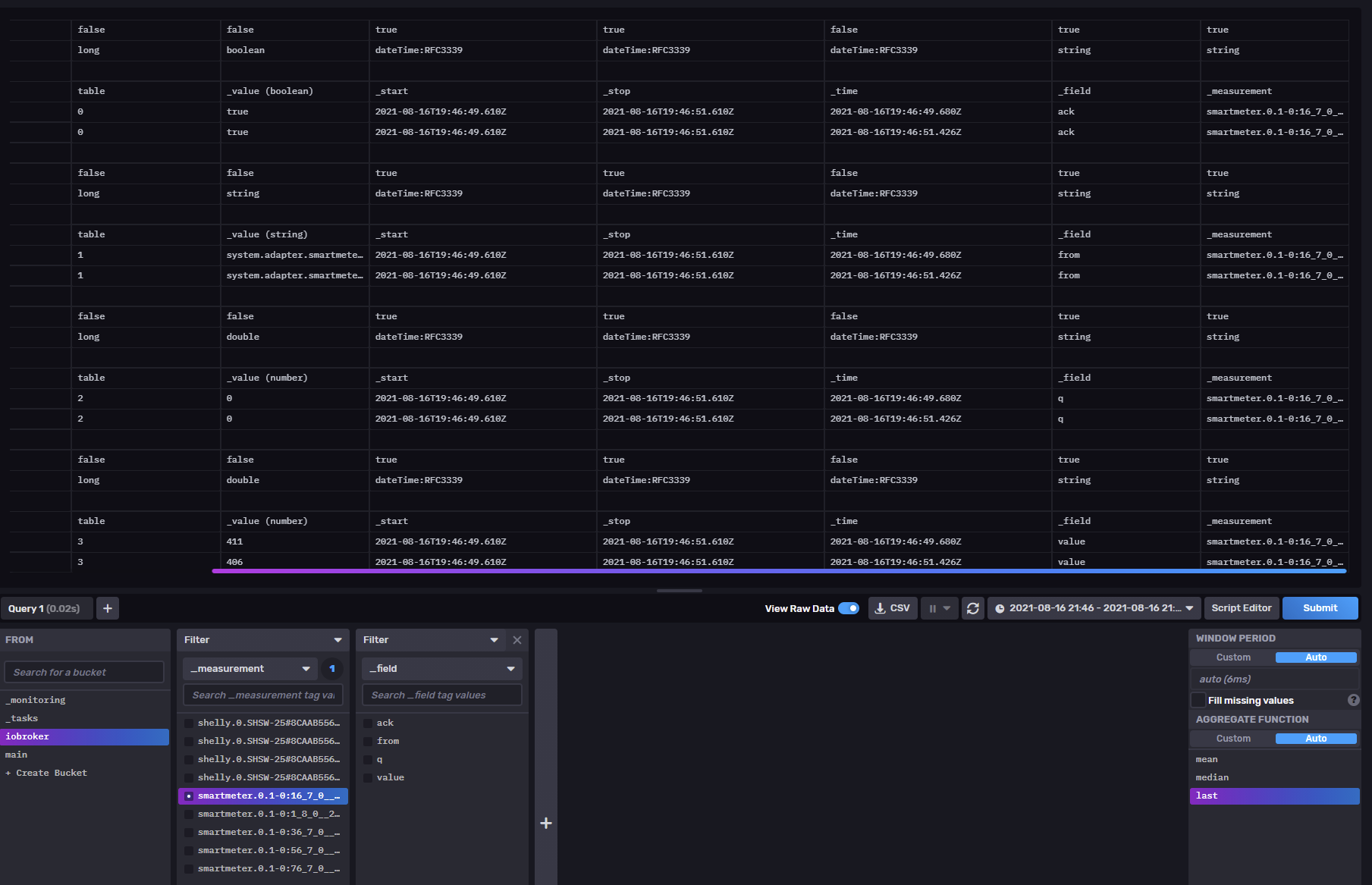
Wurde das Verhalten mit der neuen Adapter Version oder IOBroker Update geändert und gibt es einen weg zurück? Habe natürlich diesmal kein Backup von IOBroker & DB gemacht, grr.
Unabhängig davon, ich nutzte eine lokale Instanz und den kostenlosen Plan, 30 Tage auf der InfluxCloud, bei letzteren kommt im Log -> HttpError: specifying shard-group duration is not supported -> Vorhaltezeit habe ich auf Unbegrenzt im Adapter eingestellt.
Danke & Gruß
-
@sunny1081 Ja in der 2.1 wurde die Art der Datenspeicherung für die InfluxDB 2 geändert - siehe weiter oben hier im Thread als Beitrag von Excodibur. Daher sollte man wenn man den Adapter vorher hatte alle Daten nochmals löschen.
-
Danke für die schnelle Rückmeldung. War das den so beabsichtigt, man verliert doch den Zusammenhang zwischen den Werten die alle zu einer Messung gehören und jetzt 4 beliebige Werte mit zufällig dem gleichen Zeit Stempel sind?
Ja mit pivot kann man die Werte Übersichtlicher anzeigen aber der Schlüssel ist doch eigentlich die Messung.Ich möchte z.B. in Grafana nur die Werte nutzen die durch Smartmeter geschrieben werden und nicht die durch den InfluxAdapter geschrieben werden wenn man sagt schreibe einfach jede Sekunde den Wert den du grade hast. Bisher hat man einfach den Filter um FROM ergänzt und fertig. Jetzt muss ich erstmal alle Werte über den Zeitstempel joinen und dann wieder filtern.
-
Wir haben hier nichts geändert. Influx kann pro Datenpunkt nur ein Feld (field) speichern - by design, d.h. entweder value, ack, from, oder q. Da wir hier vier Felder nutzen, gibt es auch vier getrennte Tabellen in derInfluxDB.
Siehe auch folgender Auszug aus der Doku: https://docs.influxdata.com/influxdb/v1.8/concepts/glossary/#point
Each point: - has a measurement, a tag set, a field key, a field value, and a timestamp; - is uniquely identified by its series and timestamp.Dies hat sich auch nicht zwischen Influx 1.x und 2.x geändert, nur hast du es in Influx 1.x nicht gesehen, da die Darstellung mit SQL-Queries vereinfacht wurde und man Influx dann schnell mal eher wie eine relationale Datenbank verwenden konnte, d.h. mehrere Werte pro Measurement gespeichert hat. Intern wurde es aber immer anders abgebildet, halt wie in einer Time-Series DB verteilt auf mehrere Datenpunkte.
Du kannst auch in deiner alten Influx 1.x DB schon Flux-Queries absetzen, die dir deine "echten" Datenunkte dann ebenfalls auf mehreren Tabellen ausgeben, z.B. mit
influx -type=flux -path-prefix /api/v2/query -execute 'from(bucket: "iobroker/global") |> range(start: 2020-08-06T15:00:00.000Z, stop: 2022-08-07T15:39:34.350Z)'Bei Influx2 gehört InfluxQL nun nicht mehr zum Standard, wobei du wahrscheinlich die gewohnten SQL-Statements noch immer über Compatibility Endpoints absetzen kannst. Ich gehe aber davon aus, dass das irgendwann verschwinden wird.
Bei Flux-Queries ist die pivot Funktion hier zum Zusammenfügen meines Wissens nach der offiziell von Influx vorgesehene Weg um an eine ähnliche Darstellung der Daten zu gelangen. D.h. wir können hier nicht viel mehr machen, als die Empfehlung weiter geben. Der Schlüssel ist immer Messungsname + Zeitstempel (Influx ist eine Time-Series-DB), somit sehe ich hier kein Problem mit Inkonsistenzen.
Was Influx-seitig ginge, ist zu einem Measurement-Datenpunkt neben dem einen Feld "value" noch beliebig viele Tags dran zu hängen und so ack, from und q direkt dort abzubilden. Dann hat man ohne weiteren Query-Aufwand alles in einer Tabelle, allerdings würden bestehende Tabellen aus Influx 1.x nicht nach 2.x migriert und weiter verwendet werden können, da dort nur mit "fields", statt "tags" gearbeitet wird.
-
Danke für die Erläuterung, für mich Bezog sich die Änderung auf die initiale Version 2.0 welche ein Feld + "tags" also einer Serie, gegenüber der aktuellen welche 4 Datenpunkte nutzt. Fange grade erst an mit dem Thema um die Erträge meiner Stecker PV zu messen und bin direkt mit v2 gestartet.
Tags haben den Scharm das sie indiziert sind und sich so schnell auf z.B. ACK filtern lässt ohne alle Werte zu durchscannen evlt. relevant wenn man mal Wochen oder Monate betrachtet. Aber Verstanden es soll damit die Migration von V1 ermöglicht werden.
Bin jetzt erstmal auf NodeRed umgestiegen da mich im Grunde nur der reine Messwert interessiert, evlt. ein Feature für die Zukunft, eine Auswahl was geloggt wird um weniger Daten zu schreiben. Ist ja doch einiges komfortabler eben einen Haken über die GUI setzen und fertig.
Ist es möglich zu konfigurieren das die Retention und / oder Shard duration nicht über den Adapter konfiguriert wird? -> Dadurch lässt sich die InfluxCloud (30 Tage Free Plan) aktuell nicht nutzen -> HttpError: specifying shard-group duration is not supported. Grade um hochfrequent und nicht historisch wichtige Daten zu schreiben eine Super Sache, spart wieder einige GB an schreibzugriffen auf die SD Karte / SSD.
-
@sunny1081 sagte in Test Adapter influxdb 2.0:
Dadurch lässt sich die InfluxCloud (30 Tage Free Plan) aktuell nicht nutzen -> HttpError: specifying shard-group duration is not supported.
Sicher das das blockt? Wenn ich den Code korrekt im Kopf habe dann kommt die Meldung aber es sollte danach trotzdem normal weitergehen und Daten speichern. Wär dann also einfach zu ignorieren
-
Habe es grade nochmal probiert. Dachte es geht gar nicht da ich keine Werte mehr hatte, die Verbindung wird aufgebaut und ein Wert geschrieben, die Updates dann aber nicht mehr. Erst wenn ich den Adapter wieder neu Starte ist der nächste Wert da.
Alle 10s verbindet sich der Adapter neu, es werden aber keine Werte geschrieben.
Anbei ein Ausschnitt aus dem log: -
@sunny1081 gleiches bei mir , grundsätzlich schreibt er aber Werte in die Datenbank. Nur ständige Neustarts

Kleiner Hinweis: Abweichend von den Hinweisen am Anfang hatte ich nen Extra Token angelegt.... ich wüsste auch nicht wo mir am Anfang der Installation ein Token angezeigt werden sollte.

-
@robbsen
Wenn ich die lokale InfluxDB nutzte läuft es gut. Habe auch einen eigenen TOKEN mit allen rechten für IOBroker gemacht. -
@sunny1081 vielleicht ist das unser Problem mit unseren Neustarts
Authentication Token: You need to create an Authentication token that have sufficient rights to basically do all actions on the provided organization! Important: For now just use the initial owner auth token because we still struggle on how to create a token that has sufficient permissions. The Owner Token was generated on InfluxDB setup process. If you know how to create the right tokens let us now :-)Eigentlich sollte man ja den "Owner-Token" nutzen. Allerdings habe ich den bei mir nicht gefunden.
By the way bei mir loggt sich das Frotend alle paar Sekunden aus, hat jemand ähnliches Problem?
-
@robbsen Nee, ich glaube ich hatte da ein Reconnect Verhalten eingebaut, falls es beim Anlegen der DB (und damit einhergehend dem Setzen der Retention Policy zu Problemen kommt, immer in der Annahme, dass Probleme so für nach dem Login auf Schwierigkeiten mit der Verbindung hindeuten. Die Annahme trifft in diesem Fall nicht zu, d.h. ich müsste mir den Adapter-Code nochmal anschauen und da was patchen.
-
@sunny1081 Dann bitte GitHub Issue das er ein nen Fail bei Retention nur loggt aber komplett ignoriert ...
-
@robbsen Das mit dem Owner Token war nur nötig bzw in der Readme wel wir es nicht hinbekommen hatten ein Token zu erzeugen mit dem der Adapter nach dem Anlegen der DB selbst darauf zugreifen durfte ...
-
@apollon77 done
-
Hallo zusammen,
ich habe heute Nachmittag ein Update von der Version 2.0.0 auf die 2.1.1 durchgeführt.
Seit dem erhalte ich allerdings nur noch Influx-Protokollierungen mit ack == null und from == null für die jeweiligen Devices.
In meiner Influx-DB habe ich nun jeweils zwei Messpunkte pro Device - Beispiel:
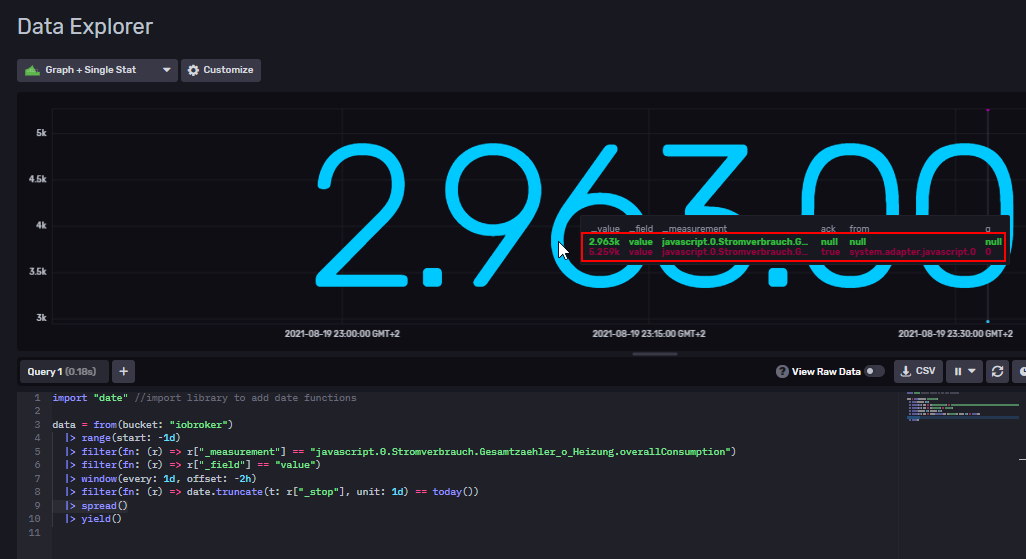
Vor dem Update wurden alle Werte in den alten DP geschrieben:
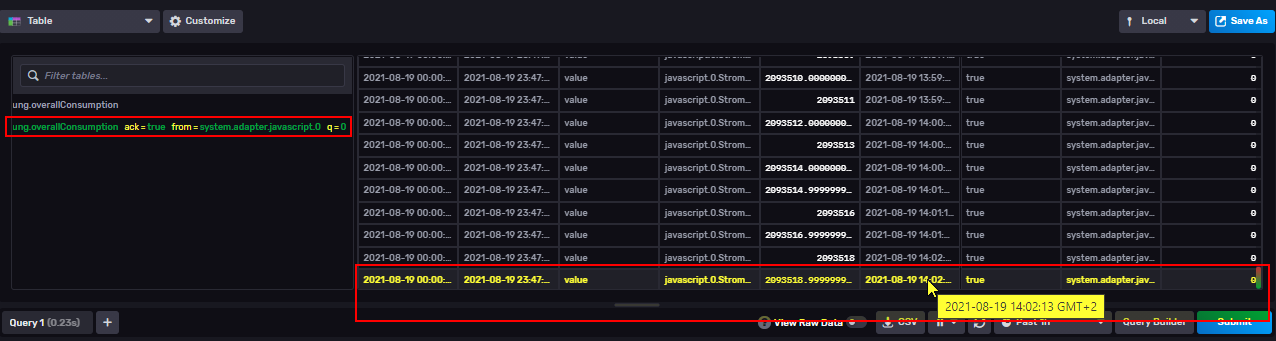
Um 14:02 Uhr wurde dann von mir das Update auf die neue Version eingespielt. Das influx-Token ging bei dem Update kaputt und musste neu gesetzt werden, das hatte ich dann erst gegen 15:00 Uhr aktualisiert, daher gibt es ca. 1 Std. keine weiteren Einträge.
Nach der Aktualisierung des Tokens wurden die Daten allerdings in den neuen Datenpunkt geschrieben:
Somit passen nun leider sämtliche Grafana-Dashboards nicht mehr. Hatte sich hier zwischen den Versionen etwas geändert oder müssen zusätzliche Einstellungen vorgenommen werden?
Danke und viele Grüße,
Sebastian -
@sebi85 Du hast hier gelesen das das Logging Format zwischen 2.0 und 2.1 geändert wurde?? Scroll mal ein paar Tage hoch hier in diesem thread
-
@apollon77 ich hatte "nur" die Changelog im Fokus, da hatte ich keinen Hinweis auf eine Änderung des Logformats gesehen.
Danke für den Hinweis, dann versuche ich mal die Daten irgendwie zu aggregieren.
-
Ok,
der wunderbare @Excodibur hat Euch @sebi85 und @sunny1081 erhört und für InfluxDB 2 eine Einstellung eingeführt mit der man wählen kann wie die Daten abgelegt werden sollen. Im GitHub Readme stehen auch Infos dazu.
Also könntet Ihr jetzt die Daten die euch die 2.1 "falsch" reingeschrieben hat wegwerfen oder irgendwie umstellen (sorry das macht der Adapter nicht für euch). Das neue mit der Einstellung müsste mit dem Format der 2.0 identisch sein.
Oder Ihr fangt nochmal mit einer leeren DB an und schaut wie Ihr die alten Daten reinbekommt.Bitte versucht es mal. Das neue ist erstmal auf GitHub: Von dort installieren und danach manuell Adapter neu starten. Dann in die Settings und unter "Erweiterte Einstellungen" das neue aktivieren. Bitte Feedback geben. Der Adapter checks das Format der existierenden Daten und meckert gegebenenfalls.
-
Die Doku zu dem Feature findet ihr hier: https://github.com/ioBroker/ioBroker.influxdb/blob/master/README.md#Store-metadata-information-as-tags-instead-of-fields
Das funktioniert nur bei Influx 2, d.h. ihr sollte dann in der Adapter Konfiguration die Verwendung von Tags per Checkbox aktivieren können. Wie von Apollon beschrieben, funktioniert das nicht mit alten DBs, die q, from und ack noch in fields speichern. Der Adapter gibt dann in dem Fall eine Fehlermeldung aus und stoppt. Am einfachsten mit einer neuen, leeren DB testen.
