

Test Adapter influxdb 2.0
-
@sunny1081 gleiches bei mir , grundsätzlich schreibt er aber Werte in die Datenbank. Nur ständige Neustarts

Kleiner Hinweis: Abweichend von den Hinweisen am Anfang hatte ich nen Extra Token angelegt.... ich wüsste auch nicht wo mir am Anfang der Installation ein Token angezeigt werden sollte.

-
@robbsen
Wenn ich die lokale InfluxDB nutzte läuft es gut. Habe auch einen eigenen TOKEN mit allen rechten für IOBroker gemacht.@sunny1081 vielleicht ist das unser Problem mit unseren Neustarts
Authentication Token: You need to create an Authentication token that have sufficient rights to basically do all actions on the provided organization! Important: For now just use the initial owner auth token because we still struggle on how to create a token that has sufficient permissions. The Owner Token was generated on InfluxDB setup process. If you know how to create the right tokens let us now :-)Eigentlich sollte man ja den "Owner-Token" nutzen. Allerdings habe ich den bei mir nicht gefunden.
By the way bei mir loggt sich das Frotend alle paar Sekunden aus, hat jemand ähnliches Problem?
-
@sunny1081 vielleicht ist das unser Problem mit unseren Neustarts
Authentication Token: You need to create an Authentication token that have sufficient rights to basically do all actions on the provided organization! Important: For now just use the initial owner auth token because we still struggle on how to create a token that has sufficient permissions. The Owner Token was generated on InfluxDB setup process. If you know how to create the right tokens let us now :-)Eigentlich sollte man ja den "Owner-Token" nutzen. Allerdings habe ich den bei mir nicht gefunden.
By the way bei mir loggt sich das Frotend alle paar Sekunden aus, hat jemand ähnliches Problem?
@robbsen Nee, ich glaube ich hatte da ein Reconnect Verhalten eingebaut, falls es beim Anlegen der DB (und damit einhergehend dem Setzen der Retention Policy zu Problemen kommt, immer in der Annahme, dass Probleme so für nach dem Login auf Schwierigkeiten mit der Verbindung hindeuten. Die Annahme trifft in diesem Fall nicht zu, d.h. ich müsste mir den Adapter-Code nochmal anschauen und da was patchen.
-
Habe es grade nochmal probiert. Dachte es geht gar nicht da ich keine Werte mehr hatte, die Verbindung wird aufgebaut und ein Wert geschrieben, die Updates dann aber nicht mehr. Erst wenn ich den Adapter wieder neu Starte ist der nächste Wert da.
Alle 10s verbindet sich der Adapter neu, es werden aber keine Werte geschrieben.
Anbei ein Ausschnitt aus dem log:@sunny1081 Dann bitte GitHub Issue das er ein nen Fail bei Retention nur loggt aber komplett ignoriert ...
-
@sunny1081 vielleicht ist das unser Problem mit unseren Neustarts
Authentication Token: You need to create an Authentication token that have sufficient rights to basically do all actions on the provided organization! Important: For now just use the initial owner auth token because we still struggle on how to create a token that has sufficient permissions. The Owner Token was generated on InfluxDB setup process. If you know how to create the right tokens let us now :-)Eigentlich sollte man ja den "Owner-Token" nutzen. Allerdings habe ich den bei mir nicht gefunden.
By the way bei mir loggt sich das Frotend alle paar Sekunden aus, hat jemand ähnliches Problem?
-
@sunny1081 Dann bitte GitHub Issue das er ein nen Fail bei Retention nur loggt aber komplett ignoriert ...
@apollon77 done
-
Hallo zusammen,
ich habe heute Nachmittag ein Update von der Version 2.0.0 auf die 2.1.1 durchgeführt.
Seit dem erhalte ich allerdings nur noch Influx-Protokollierungen mit ack == null und from == null für die jeweiligen Devices.
In meiner Influx-DB habe ich nun jeweils zwei Messpunkte pro Device - Beispiel:
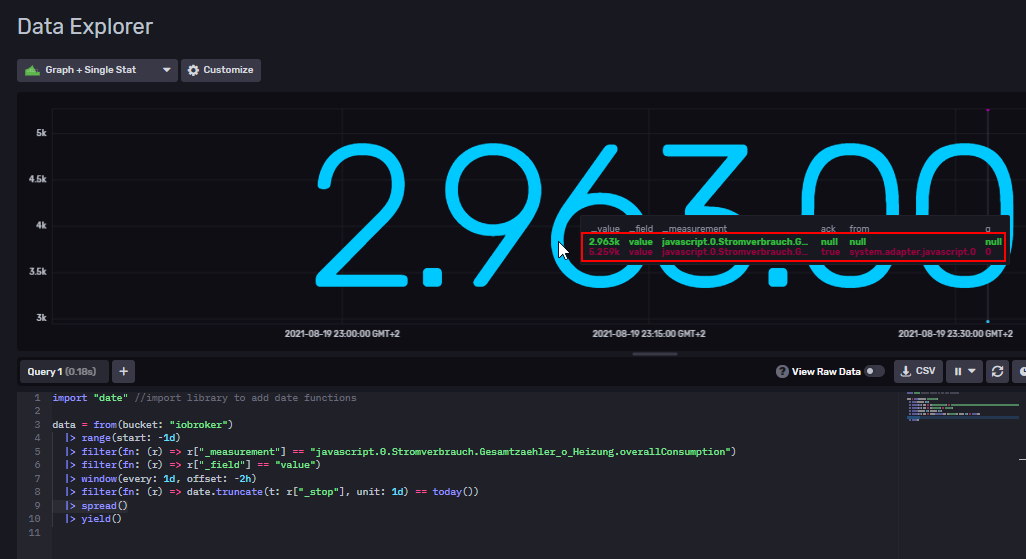
Vor dem Update wurden alle Werte in den alten DP geschrieben:
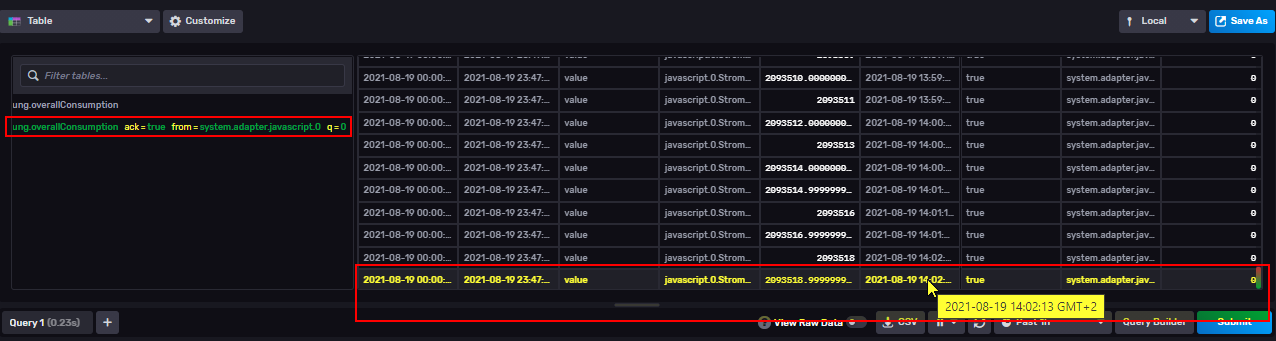
Um 14:02 Uhr wurde dann von mir das Update auf die neue Version eingespielt. Das influx-Token ging bei dem Update kaputt und musste neu gesetzt werden, das hatte ich dann erst gegen 15:00 Uhr aktualisiert, daher gibt es ca. 1 Std. keine weiteren Einträge.
Nach der Aktualisierung des Tokens wurden die Daten allerdings in den neuen Datenpunkt geschrieben:
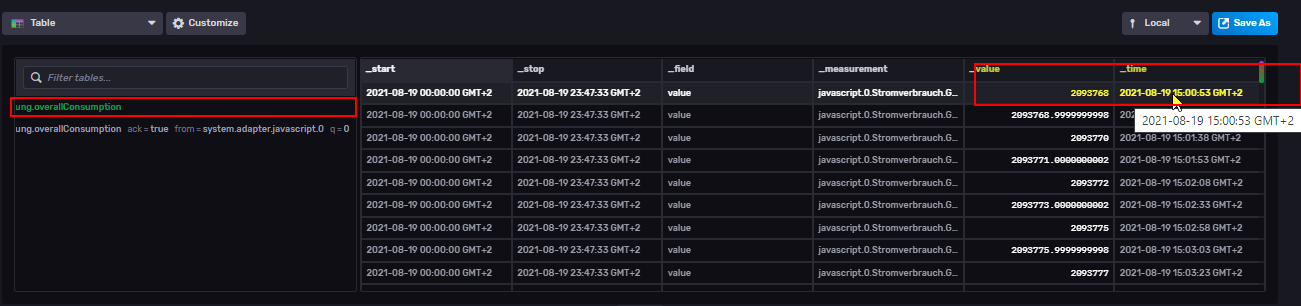
Somit passen nun leider sämtliche Grafana-Dashboards nicht mehr. Hatte sich hier zwischen den Versionen etwas geändert oder müssen zusätzliche Einstellungen vorgenommen werden?
Danke und viele Grüße,
Sebastian -
Hallo zusammen,
ich habe heute Nachmittag ein Update von der Version 2.0.0 auf die 2.1.1 durchgeführt.
Seit dem erhalte ich allerdings nur noch Influx-Protokollierungen mit ack == null und from == null für die jeweiligen Devices.
In meiner Influx-DB habe ich nun jeweils zwei Messpunkte pro Device - Beispiel:
Vor dem Update wurden alle Werte in den alten DP geschrieben:
Um 14:02 Uhr wurde dann von mir das Update auf die neue Version eingespielt. Das influx-Token ging bei dem Update kaputt und musste neu gesetzt werden, das hatte ich dann erst gegen 15:00 Uhr aktualisiert, daher gibt es ca. 1 Std. keine weiteren Einträge.
Nach der Aktualisierung des Tokens wurden die Daten allerdings in den neuen Datenpunkt geschrieben:
Somit passen nun leider sämtliche Grafana-Dashboards nicht mehr. Hatte sich hier zwischen den Versionen etwas geändert oder müssen zusätzliche Einstellungen vorgenommen werden?
Danke und viele Grüße,
Sebastian -
@sebi85 Du hast hier gelesen das das Logging Format zwischen 2.0 und 2.1 geändert wurde?? Scroll mal ein paar Tage hoch hier in diesem thread
@apollon77 ich hatte "nur" die Changelog im Fokus, da hatte ich keinen Hinweis auf eine Änderung des Logformats gesehen.
Danke für den Hinweis, dann versuche ich mal die Daten irgendwie zu aggregieren.
-
Ok,
der wunderbare @Excodibur hat Euch @sebi85 und @sunny1081 erhört und für InfluxDB 2 eine Einstellung eingeführt mit der man wählen kann wie die Daten abgelegt werden sollen. Im GitHub Readme stehen auch Infos dazu.
Also könntet Ihr jetzt die Daten die euch die 2.1 "falsch" reingeschrieben hat wegwerfen oder irgendwie umstellen (sorry das macht der Adapter nicht für euch). Das neue mit der Einstellung müsste mit dem Format der 2.0 identisch sein.
Oder Ihr fangt nochmal mit einer leeren DB an und schaut wie Ihr die alten Daten reinbekommt.Bitte versucht es mal. Das neue ist erstmal auf GitHub: Von dort installieren und danach manuell Adapter neu starten. Dann in die Settings und unter "Erweiterte Einstellungen" das neue aktivieren. Bitte Feedback geben. Der Adapter checks das Format der existierenden Daten und meckert gegebenenfalls.
Beitrag hat geholfen? Votet rechts unten im Beitrag :-) https://paypal.me/Apollon77 / https://github.com/sponsors/Apollon77
- Debug-Log für Instanz einschalten? Admin -> Instanzen -> Expertenmodus -> Instanz aufklappen - Loglevel ändern
- Logfiles auf Platte /opt/iobroker/log/… nutzen, Admin schneidet Zeilen ab
-
Ok,
der wunderbare @Excodibur hat Euch @sebi85 und @sunny1081 erhört und für InfluxDB 2 eine Einstellung eingeführt mit der man wählen kann wie die Daten abgelegt werden sollen. Im GitHub Readme stehen auch Infos dazu.
Also könntet Ihr jetzt die Daten die euch die 2.1 "falsch" reingeschrieben hat wegwerfen oder irgendwie umstellen (sorry das macht der Adapter nicht für euch). Das neue mit der Einstellung müsste mit dem Format der 2.0 identisch sein.
Oder Ihr fangt nochmal mit einer leeren DB an und schaut wie Ihr die alten Daten reinbekommt.Bitte versucht es mal. Das neue ist erstmal auf GitHub: Von dort installieren und danach manuell Adapter neu starten. Dann in die Settings und unter "Erweiterte Einstellungen" das neue aktivieren. Bitte Feedback geben. Der Adapter checks das Format der existierenden Daten und meckert gegebenenfalls.
Die Doku zu dem Feature findet ihr hier: https://github.com/ioBroker/ioBroker.influxdb/blob/master/README.md#Store-metadata-information-as-tags-instead-of-fields
Das funktioniert nur bei Influx 2, d.h. ihr sollte dann in der Adapter Konfiguration die Verwendung von Tags per Checkbox aktivieren können. Wie von Apollon beschrieben, funktioniert das nicht mit alten DBs, die q, from und ack noch in fields speichern. Der Adapter gibt dann in dem Fall eine Fehlermeldung aus und stoppt. Am einfachsten mit einer neuen, leeren DB testen.
-
Die Doku zu dem Feature findet ihr hier: https://github.com/ioBroker/ioBroker.influxdb/blob/master/README.md#Store-metadata-information-as-tags-instead-of-fields
Das funktioniert nur bei Influx 2, d.h. ihr sollte dann in der Adapter Konfiguration die Verwendung von Tags per Checkbox aktivieren können. Wie von Apollon beschrieben, funktioniert das nicht mit alten DBs, die q, from und ack noch in fields speichern. Der Adapter gibt dann in dem Fall eine Fehlermeldung aus und stoppt. Am einfachsten mit einer neuen, leeren DB testen.
@excodibur Besten Dank dafür, es funktioniert.
Nur den alten Bucket konnte ich nicht nutzen. Wie wird den ausgemacht ob bereits TAGS genutzt wurden. Initial wurden den Daten mit TAGS geschrieben und dann einige wenige Tage mit Feldern, kann jetzt aber nicht mit TAGS weiter schreiben.
-
@excodibur Besten Dank dafür, es funktioniert.
Nur den alten Bucket konnte ich nicht nutzen. Wie wird den ausgemacht ob bereits TAGS genutzt wurden. Initial wurden den Daten mit TAGS geschrieben und dann einige wenige Tage mit Feldern, kann jetzt aber nicht mit TAGS weiter schreiben.
@sunny1081 soweit ich weiß so:
Mit fieldKeys und tagKeys kann man das Schema untersuchen. Wenn der Adapter da sieht, das für q, from, ack tags oder fields benutzt wurden, gibt der ggf einen error aus
Reicht das? Sonst muss @Excodibur mehr sagen welche Magie er da gebaut hat.
-
@sunny1081 soweit ich weiß so:
Mit fieldKeys und tagKeys kann man das Schema untersuchen. Wenn der Adapter da sieht, das für q, from, ack tags oder fields benutzt wurden, gibt der ggf einen error aus
Reicht das? Sonst muss @Excodibur mehr sagen welche Magie er da gebaut hat.
-
-
@ilovegym dann ließ mal Changelog. Das tat noch nie auf Datenpunkt Ebene und daher haben wir es mit der 2.0 dort rausgeworfen. Geht nur auf dB Ebene - da tut es aber jetzt was auch vorher nie tat ;-)
@apollon77 ach das war das.. :-D gelesen, vergessen, gewundert... :D
-
Ich sage jetzt mal frech: Versucht es doch mal ... und schreibt es for uns und die anderen auf. Ich denke "adapter stoppen, updaten, Konfig ändern (ip, port, settings) und starten sollte es sein ;-)
@apollon77 said in Test Adapter influxdb 2.0:
Ich sage jetzt mal frech: Versucht es doch mal ... und schreibt es for uns und die anderen auf. Ich denke "adapter stoppen, updaten, Konfig ändern (ip, port, settings) und starten sollte es sein ;-)
Sorry für die späte Rückmeldung. Ich hab die Migration etwas hinausgezögert und wollte das in aller Ruhe machen. Das Mistwetter bietet sich nun dafür an.
Lange Rede: Ich hab heute erfolgreich von v1 auf v2 manuell migriert. Bei mir läuft influxdb als Docker Container auf einer Synology. Hier meine Schritte:
-
Docker Container v2 erstellen, aber noch nicht starten - Umgebungsvariablen passend für setup setzen, z.B.:
DOCKER_INFLUXDB_INIT_MODE: setup
DOCKER_INFLUXDB_INIT_BUCKET: iobroker
DOCKER_INFLUXDB_INIT_ORG: iobroker
DOCKER_INFLUXDB_INIT_USERNAME: iobroker
DOCKER_INFLUXDB_INIT_PASSWORD: iobroker -
optional: Aktuelle v1 DB mit BackItUp sichern (optional, da wir sowieso einen neuen Docker Container für v2 anlegen und damit v1 als Backup vorhanden bleibt)
-
influxDB Instanz stoppen
-
Im Terminal von Docker Container v1 Datenbank exportieren:
service influxdb stop
influx_inspect export -waldir /var/lib/influxdb/wal -datadir /var/lib/influxdb/data -database "iobroker" -retention "autogen" -out /var/lib/influxdb/export.db -lponly -
Docker Container v1 stoppen
-
Docker Container v2 starten und setup abwarten
-
export.db in den gemounteten Data-Ordner Docker Container v2 verschieben
-
Im Terminmal von Docker Containver v2 export db importieren:
influx write --bucket iobroker --file /var/lib/influxdb2/export.db -
influxDB Instanz auf 2.x ändern, token eingeben und starten
Die export.db war bei mir fast 10 GByte groß, entsprechend hat der Import gute 1,5 Stunden gedauert, der Export ging mit ca. 10 min deutlich schneller.
Meine Motivation für die Migration war übrigens, dass flux nach Kalendermonaten und Jahren Daten aggregieren kann. Allerdings gibt es bereits einen ersten Wermutstropfen: flux kann aktuell keine Zeitzonen bei der Datenaggregierung. Damit sind die aggregierten Werte leicht falsch, was v.a. bei den Tageswerten deutlich spürbar ist, bei den Monatswerten weniger ins Gewicht fällt. Workaround wäre, für die Tageswerte mit influxql weiterzuarbeiten, allerdings bekomme ich grad die v1 Authentifizierung nicht hin, oder mit fixen timeshifts zu arbeiten, was aufgrund der Zeitumstellung blöd ist.
Insgesamt bin ich aber froh, dass es dann doch so reibungslos funktioniert hat. Leider hat Grafana noch kein QueryBuilder für flux, aber gut.
Danke für den tollen Support hier.
-
-
@apollon77 said in Test Adapter influxdb 2.0:
Ich sage jetzt mal frech: Versucht es doch mal ... und schreibt es for uns und die anderen auf. Ich denke "adapter stoppen, updaten, Konfig ändern (ip, port, settings) und starten sollte es sein ;-)
Sorry für die späte Rückmeldung. Ich hab die Migration etwas hinausgezögert und wollte das in aller Ruhe machen. Das Mistwetter bietet sich nun dafür an.
Lange Rede: Ich hab heute erfolgreich von v1 auf v2 manuell migriert. Bei mir läuft influxdb als Docker Container auf einer Synology. Hier meine Schritte:
-
Docker Container v2 erstellen, aber noch nicht starten - Umgebungsvariablen passend für setup setzen, z.B.:
DOCKER_INFLUXDB_INIT_MODE: setup
DOCKER_INFLUXDB_INIT_BUCKET: iobroker
DOCKER_INFLUXDB_INIT_ORG: iobroker
DOCKER_INFLUXDB_INIT_USERNAME: iobroker
DOCKER_INFLUXDB_INIT_PASSWORD: iobroker -
optional: Aktuelle v1 DB mit BackItUp sichern (optional, da wir sowieso einen neuen Docker Container für v2 anlegen und damit v1 als Backup vorhanden bleibt)
-
influxDB Instanz stoppen
-
Im Terminal von Docker Container v1 Datenbank exportieren:
service influxdb stop
influx_inspect export -waldir /var/lib/influxdb/wal -datadir /var/lib/influxdb/data -database "iobroker" -retention "autogen" -out /var/lib/influxdb/export.db -lponly -
Docker Container v1 stoppen
-
Docker Container v2 starten und setup abwarten
-
export.db in den gemounteten Data-Ordner Docker Container v2 verschieben
-
Im Terminmal von Docker Containver v2 export db importieren:
influx write --bucket iobroker --file /var/lib/influxdb2/export.db -
influxDB Instanz auf 2.x ändern, token eingeben und starten
Die export.db war bei mir fast 10 GByte groß, entsprechend hat der Import gute 1,5 Stunden gedauert, der Export ging mit ca. 10 min deutlich schneller.
Meine Motivation für die Migration war übrigens, dass flux nach Kalendermonaten und Jahren Daten aggregieren kann. Allerdings gibt es bereits einen ersten Wermutstropfen: flux kann aktuell keine Zeitzonen bei der Datenaggregierung. Damit sind die aggregierten Werte leicht falsch, was v.a. bei den Tageswerten deutlich spürbar ist, bei den Monatswerten weniger ins Gewicht fällt. Workaround wäre, für die Tageswerte mit influxql weiterzuarbeiten, allerdings bekomme ich grad die v1 Authentifizierung nicht hin, oder mit fixen timeshifts zu arbeiten, was aufgrund der Zeitumstellung blöd ist.
Insgesamt bin ich aber froh, dass es dann doch so reibungslos funktioniert hat. Leider hat Grafana noch kein QueryBuilder für flux, aber gut.
Danke für den tollen Support hier.
@sputnik24 Vor der Umstellung graut mir noch ein bissl meine v1-db hat gerade auf der platte 54GB ... keine ahnung was das als export file wird. Was hatte deine denn auf der platte wo 10GB export drauf wurden? :)
-
-
@sputnik24 Vor der Umstellung graut mir noch ein bissl meine v1-db hat gerade auf der platte 54GB ... keine ahnung was das als export file wird. Was hatte deine denn auf der platte wo 10GB export drauf wurden? :)
-
@apollon77 Autsch. Bei mir hatte /var/lib/influxdb 658 MByte
@sputnik24 Krass ... Faktor fast 20? wtf
Mein ioBroker hat 34GB ... mit faktor 20 also ca. 600GB
Na dann überlege ich mal wie ich das storage technisch mache :-)) Oder ich muss zeitraummässig migrierenWieviel ists eigentlich nach der Migration auf Platte? Auch grob die 658MB?
aahh man kann das File auch compressen ... kannst du mal ein "gzip 10GBfile" machen und sagen was rauskommt?
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
437
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge