Parser Adapter Werte Zeilenweise auslesen (Guntamatic)
-
Hallo,
ich möchte gerne meine Heizung auslesen, diese stellt die Werte per Webseite bereit. (http://IP.IP.IP.IP/daqdata.cgi)
Dazu bekomme ich es aber nicht hin mit dem Parser die Werte Zeilenwiese den Variablen zuzuordnen.
Kann mit jemand beim RegEx helfen?
Beispiel Ausschnitt der Seite:
AUS 6.63 66.05 0.00 18.00 0 0 0 62.43 120.00 40.94 AUS 65.32 AUS -20.00 AUS -20.00 AUS 60.00 AUS 60.00 -
@glitzi sagte in Parser Adapter Werte Zeilenweise auslesen (Guntamatic):
Kann mit jemand beim RegEx helfen?
Beispiel Ausschnitt der Seite:Was liefert die Anfrage im Browser vollständig zurück?
-
Hallo,
anbei die gespeicherte Webseite... daraus möchte ich Zeilenweise die Werte Parsen.
-
@glitzi sagte in Parser Adapter Werte Zeilenweise auslesen (Guntamatic):
daraus möchte ich Zeilenweise die Werte Parsen.
Jede Zeile???
oder nur ausgewählte?([\d\.\w\-]+)
gibt dir als Match den Wert jeder Zeile in einer anderen Gruppe (= NUM) -
Super, das funktioniert schon mal perfekt.
Ist es auch möglich leere Zeilen zu berücksichtigen?
-
@glitzi sagte in Parser Adapter Werte Zeilenweise auslesen (Guntamatic):
Ist es auch möglich leere Zeilen zu berücksichtigen?
vielleicht?
aber wonach soll man da suchen? -
In Openhab habe ich es mit String Split gemacht, da hat er die leeren Zeilen berücksichtigt.
eventuell nach dem CR und LF? am ende jeder Zeile?
-
@glitzi sagte in Parser Adapter Werte Zeilenweise auslesen (Guntamatic):
eventuell nach dem CR und LF? am ende jeder Zeile?
Das geht ohne Probleme aber er hat nichts auszugeben
")
Selbst das Leerzeichen (es ist nämlich keine wirklich leere Zeile) bekomme ich nicht als Ausgabe

-
Hintergrund ist wenn da mal was von der Heizung eingetragen wird, bekomme ich einen Versatz in der ganzen Auswertung. z.B. in Zeile 3 kommt mal was, denn würden sich die folgenden um eins versetzen.
-
@glitzi ich fürchte, dann musst du das auch mit split machen, aber eben mit javascript
-
Das ist echt blöd...
gerade in Zeile 79 und 80 schreibt die Heizung die Störungstexte in Klartext, das würde dann den Rest um zwei Zeilen verschieben.
Also muss ich mich jetzt in javascript einarbeiten

Trotzdem Danke für die super Unterstützung!!!
-
@glitzi Hab noch mal ein wenig getestet, versuch mal :
^([\d\-\.\w]+|\s)\naber keine Garantie, dass Zeile 79 und 80 (=NUM78 oder 79) wahlweise nix oder den Klartext anzeigen
steht da jetzt AUS???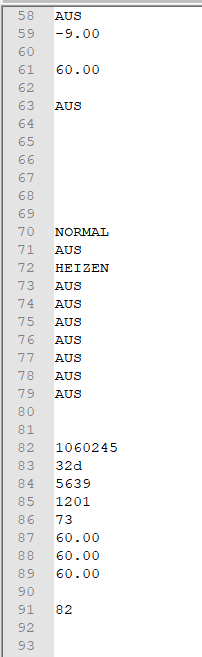
-
Hallo,
so funktioniert es generell nicht mehr (die Richtigen Zeilen sind NUM79 und 80)
MfG
-
@glitzi sagte in Parser Adapter Werte Zeilenweise auslesen (Guntamatic):
so funktioniert es generell nicht mehr
die NUM müssten sich jetzt verschoben haben und für JEDE Zeile ein Match vorhanden sein - jedoch OHNE Group!
Kann sein, dass es deswegen gar nicht mehr klappt.kannst du mal das Editorfenster von dem Parser-Adapter mit dem neuen RegEx zeigen?
-
Da müsste ja jetzt auch AUS stehen und mit NUM 2 NIX
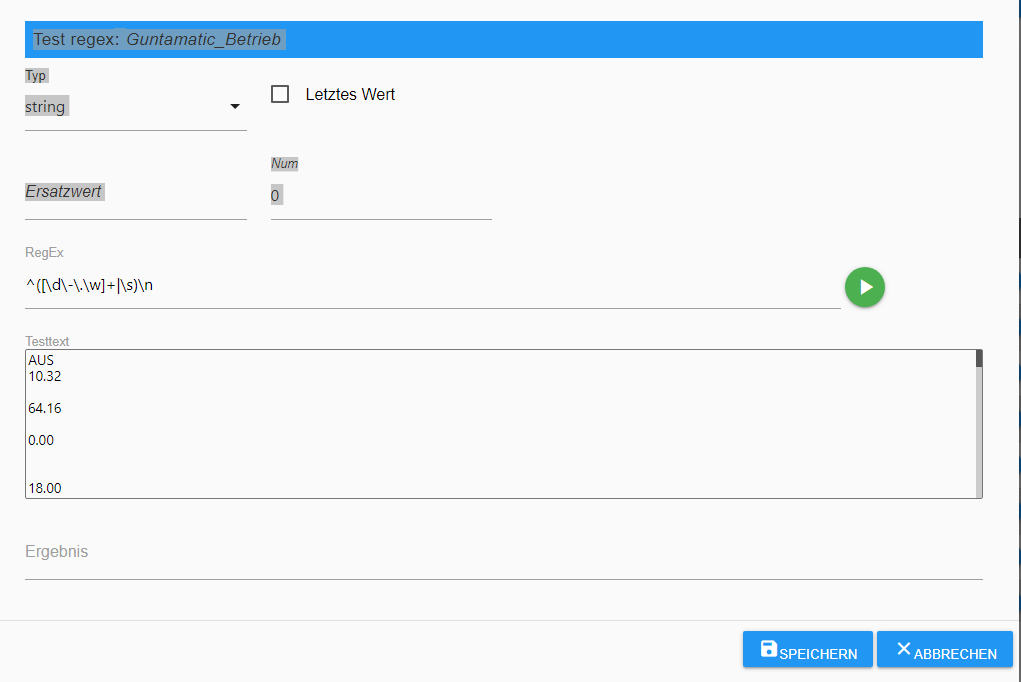
-
@glitzi sehe ich gerade auch.
Habe mir den Text in einer Testumgebung in das Fenster kopiert.Der ioBroker parser tickt manchmal etwas anders.
Suche noch nach der Ursache -
@glitzi
Mit([\d\-\.\w]+|\s)kommt wenigstens wieder etwas, aber die NUMs sind jetzt fast doppelt so hoch, weil anscheinend da immer noch ein Leerzeichen vor dem Zeilenumruch ist -
Mal ganz dämlich, habt ihr es mal einfach nur mit
(.+)als Regex probiert? Das sollte jeweils die ganze Zeile matchen (in der obigen Textdatei enthalten alle "leeren" Zeilen ein Leerzeichen).
Oder tickt da der ioBroker-Parser auch anders? -
Puhhhh irgendwie alles sehr schwierig,
wie wäre es denn mit so einem Script, das habe ich mir eben mal zusammengegoogelt.
würde das so funktionieren?
function() { createState('Guntamatic_Test1'); createState('Guntamatic_Test2'); var request= require('request'); request.post({ url: 'http://10.10.10.7/daqdata.cgi' }, function(error, response, body){ if (body) { var parts_Guntamatic = body.split('\n')[0]; setState('Guntamatic_Test2', parts_Guntamatic, true); var parts_Guntamatic = body.split('\n')[1]; setState('Guntamatic_Test2', parts_Guntamatic, true); } }); } ) -
@AlCalzone sagte in Parser Adapter Werte Zeilenweise auslesen (Guntamatic):
Oder tickt da der ioBroker-Parser auch anders?
das Problem scheinen beim ioBroker Parser die Zeilenumbrüche zu sein.
RegExes mit \n funktionieren z.B. nichtSo ist das Problem auch mit diesem Text. das ^ als Anfang der Zeile führt dann immer nur zum ersten Eintrag, und das (.+) führt zu einem Ergebnis, das den gesamten Quelltext enthält
