

[Umfrage] Hochverfügbarer ioBroker auf RPIs
-
Hallo an alle,
ioBroker ist als zentraler Server zur Kopplung und Steuerung fast beliebiger IoT-Systeme, (Web-)Services und unterschiedlichster Komponenten wirklich super. Auch, dass ich den Server mit all meinen Daten bei mir zuhause betreiben kann und nichts nach Außen geben muss, finde ich toll.
Im Gegensatz zu Lösungen wie z.B. KNX oder der Homematic, wo ich Baugruppen wie Sensoren und Aktuatoren direkt miteinander vernetzt werden können, steckt die Kommunikationslogik bei Systemen wie openHAB, FHEM oder eben ioBroker jedoch in einer zentralen Komponente - dem Server.
Ich mache mir deshalb ernsthaft Sorgen über etwaige Ausfälle, wenn ich mehr als nur ein bisschen Visualisierung oder reine Komfort-Funktionen umsetzen möchte. Einfaches Beispiel ist hier z.B. die Steuerung zum automatischen Einfahren von Markisen bei Regen oder Sturm. Oder die Zugangssteuerung für die Haustüre. Das Schalten von Geräten in einem vernetzten Haus, wenn ich keine direkten Schalter sondern nur noch Aktuatoren habe. Oder die Steuerung der Heizungs-/Photovoltaik- oder sonstiger Anlagen.
Die Beispiele lassen sich fast beliebig fortsetzen und jeder kann für sich selbst festlegen, ab welcher Stelle er den persönlichen "Komfortbereich" verlässt. Oder die beste Ehefrau von allen ärgerlich wird, wenn wieder etwas nicht funktioniert und der Ehemann sich für einige Abende in den Keller zurückziehen muss, um etwas einzurichten, upzudaten, zu bestellen, damit "das Haus" wieder funktioniert.
Deshalb trage ich mich mit dem Gedanken, ioBroker in eine wie auch immer geartete Hochverfügbarkeitslösung zu integrieren. Das Ziel ist, die Dauer einer Betriebsstörung zu reduzieren. Ebenso soll einer gravierenden Störung kein manueller Eingriff zur Wiederherstellung der Funktion von ioBroker erforderlich sein. Um das Umzusetzen, bedarf es Tests, neuer Ideen und Mitstreiter.
Als Motivation zum Thema Hochverfügbarkeit habe ich im Folgenden einige Punkte zusammengefasst:
1. Ein einzelner ioBroker Server ist nicht hochverfügbar
Eine hochverfügbare Lösung kann nicht mit nur einem Server bereitgestellt werden. Ein einzelner Server mit seiner Infrastruktur bildet einen Single Point of Failure. Bei einem Ausfall einer Hochverfügbarkeitslösung darf man keine oder nur eine kurze Unterbrechung bemerken.
2. Eine Lösung mit Backups und Ersatzhardware ist nicht hochverfügbar
Eine Disaster Recovery-Lösung hilft, bei einem etwaigen Ausfall schneller und koordinierter wieder zu einem funktionierenden System zu kommen. Es entsteht jedoch eine Stehzeit von mehreren Stunden bzw. Tagen. Disaster Recovery-Lösungen beinhalten z.B. Ersatzhardware, vorbereitete Images und Backups sowie Wissen, geschultes "Personal" oder detaillierte Anleitungen. Disaster Recovery ist wichtig für den Wiederanlauf, bietet aber keine Hochverfügbarkeit.
3. Eine Stand-By Lösung ist nicht hochverfügbar
Bei einer Stand-By Lösung muss bei einem etwaigen Fehlerfall immer manuell eingegriffen werden. Das heißt, man hat zwangsläufig eine Stehzeit, braucht Wissen zum Aktivieren der Standby-Lösung und es muss je nach Lösung sogar mit einem Datenverlust gerechnet werden.
4. Ein RAID System ist nicht hochverfügbar
Mit RAID-Systemen kann man sich vor Ausfällen einzelner Festplatten schützten. Aber nicht einzelner Server, Software bzw. andere Komponenten. Hochverfügbare Lösungen sorgen dagegen für einen ausfallsicheren Betrieb des Gesamtsystems.
5. Eine Backup-Lösung ist nicht hochverfügbar
Backup-Lösungen dienen der Sicherung der Daten und Einstellungen. Sie sind wichtig zum Wiederanlauf und damit unverzichtbar.
6. Eine USV Anlage ist nicht hochverfügbar
Eine USV schützt IT Geräte vor Störungen im elektrischen Versorgungsnetz. Hochverfügbarkeit setzt den Einsatz einer USV voraus. Allein schützt eine USV aber nicht vor einem Systemausfall - genau so wenig wie der Einsatz eines zweiten Netzteils.
7. Virtualisierung alleine ist nicht hochverfügbar
Die Virtualisierung von Servern verschlechtert sogar die Verfügbarkeit. Hier reicht ein einziger Defekt an einem physischen Server oder Storage, damit eine virtuelle Servergruppe vollständig ausfällt. Für jedes System müssen dann mehr oder weniger aufwändige Maßnahmen zur Wiederherstellung des Betriebs vorgenommen werden. Dafür muss aber eine gewisse Zeitspanne einkalkuliert werden und man benötigt zusätzlich zum Wissen über die virtualisierten Systeme auch Wissen über die Virtualisierungsschicht. Daher müssen gerade virtuelle Server auf einer hochverfügbaren Lösung betrieben werden.
8. Irrtum - Hochverfügbarkeit ist nur in großen Unternehmen wichtig
Meine größte Sorge ist ein Ausfall der Automatisierungslösung - und ich bin nicht da, um korrigierend einzugreifen. Da reicht schon ein Urlaub, plötzlicher Krankenhausaufenthalt, Hardwareausfall, kein VPN- oder Cloud-Zugriff. Andere Personen in der Familie haben in der Regel nicht das Wissen, um etwas zu reparieren. Einen verantwortlichen Systemintegrator, der mit der Reparatur beauftragt werden kann, gibt es nicht. Auf dieser Basis ist der Betrieb eines Systems, das über reine passive Visualisierungsaufgaben hinaus geht, eigentlich unverantwortlich.
9 Irrtum - Hochverfügbarkeit ist teuer
Eine hochverfügbare IT-Lösung, wie sie in großen Unternehmen betrieben wird, hat ihren Preis. Der zusätzliche technische Aufwand, der zur Herstellung von Hochverfügbarkeit betrieben werden muss, gibt es nicht zum Nulltarif. Diese Kosten müssen allerdings in Relation zu möglichen Schäden betrachtet werden.
Deshalb soll die HA Lösung mit Hilfe der folgenden einfachen und günstigen Komponenten aufgebaut werden:
-
2x Raspberry Pi Modell 3(+)
-
2x USB Stick gleicher Größe (z.B. 8GB)
-
2x WLAN Acces Point, z.B. Fritz!Box und ein als AP konfigurierter Repeater
-
1x Netzwerkkabel
-
1x Kleine USV
-
2x Fernsteuerbare Steckdosen zum Abschalten der RPi-Netzteile
Klar ist aber auch, das eine HA-Lösung ein System nicht einfacher sondern deutlich komplexer macht. Wie gesagt, falls genügend Interesse da ist und sich einige Mitsteiter finden, bin ich gerne bereit, Zeit zu investieren.
Hier als Ausblick vorab ein Proof-of-concept mit zwei RPis in einem HA-Cluster als Teaser: (animiertes GIF, einfach anklicken) [emoji1]
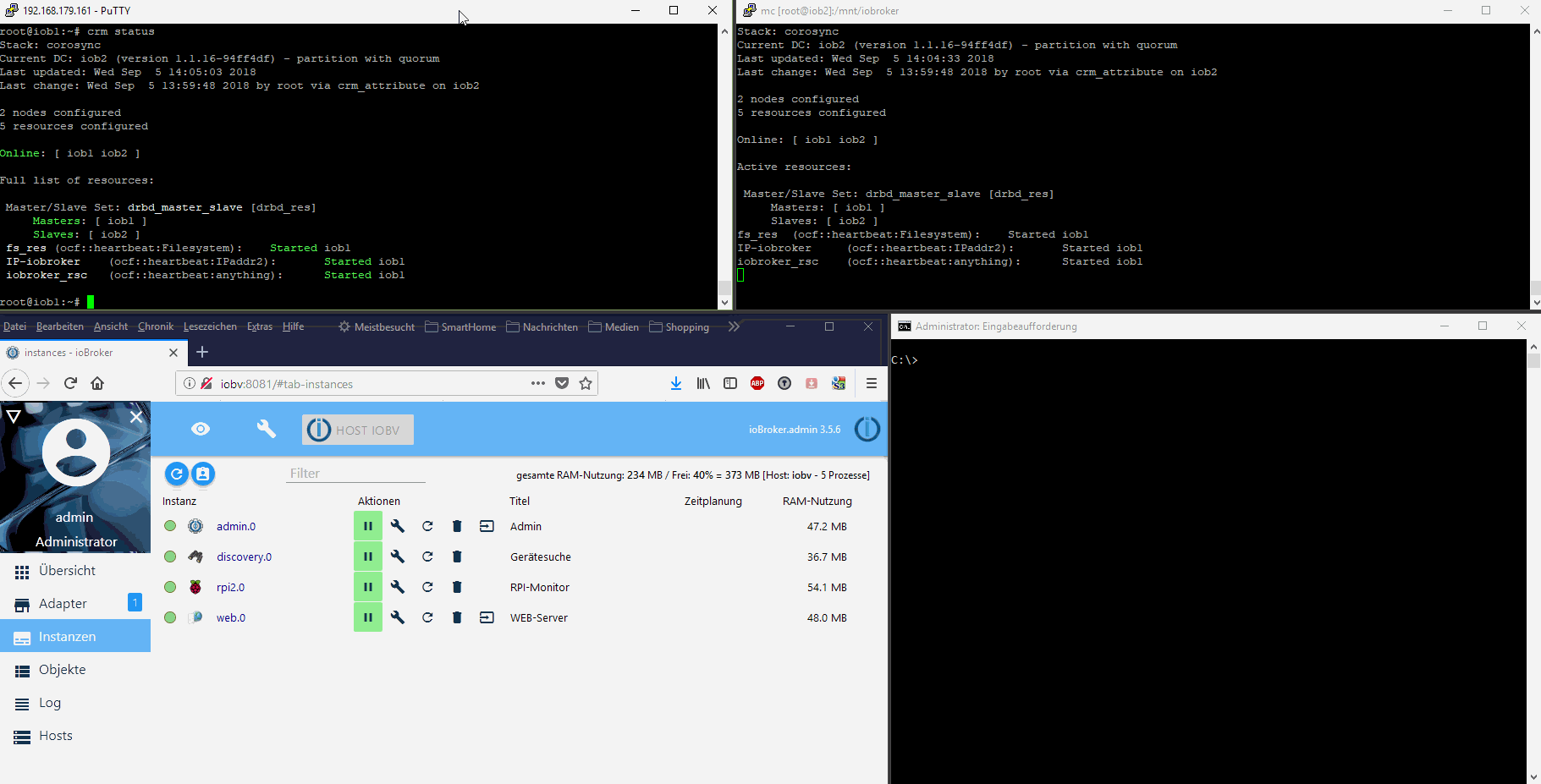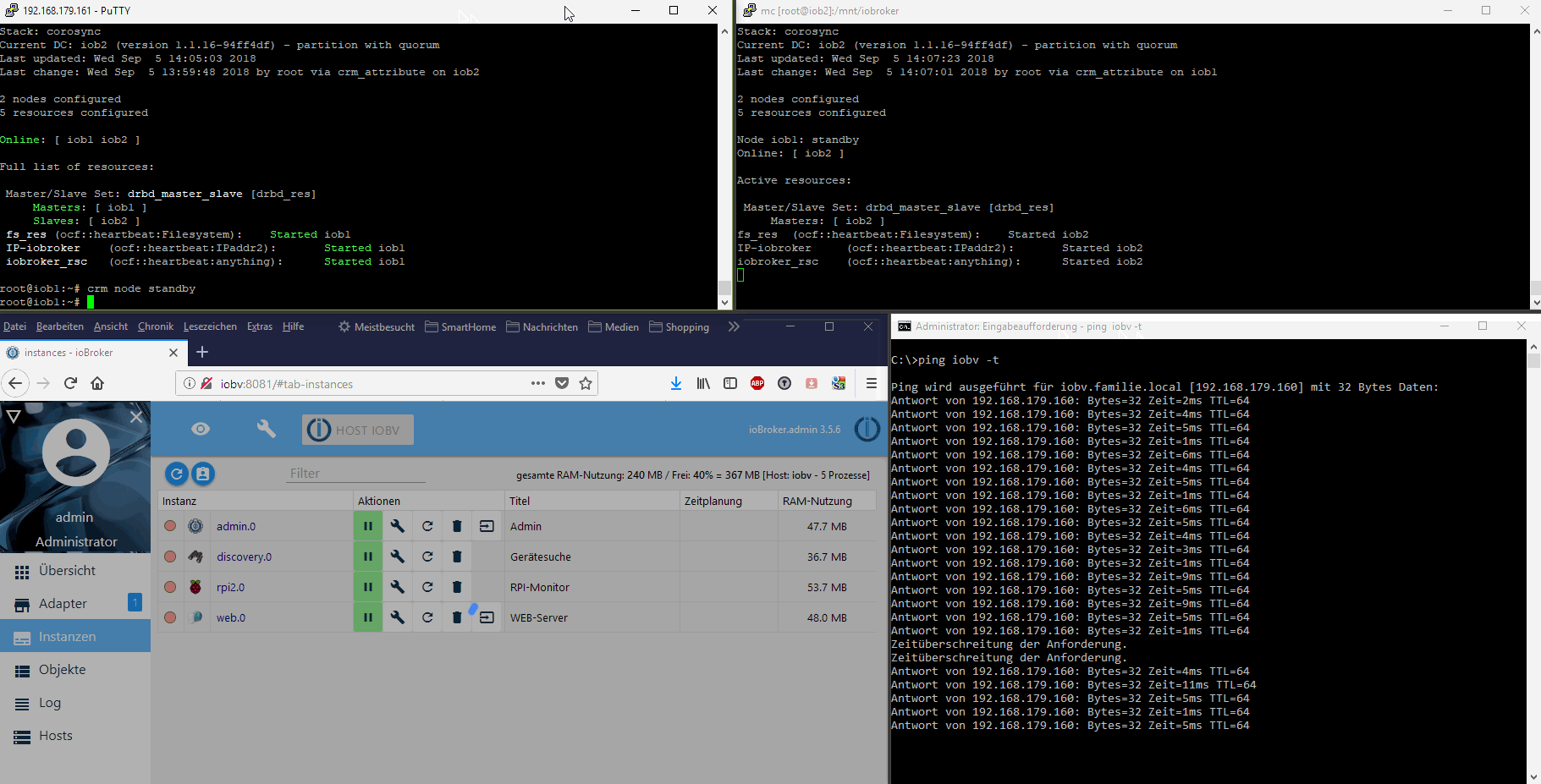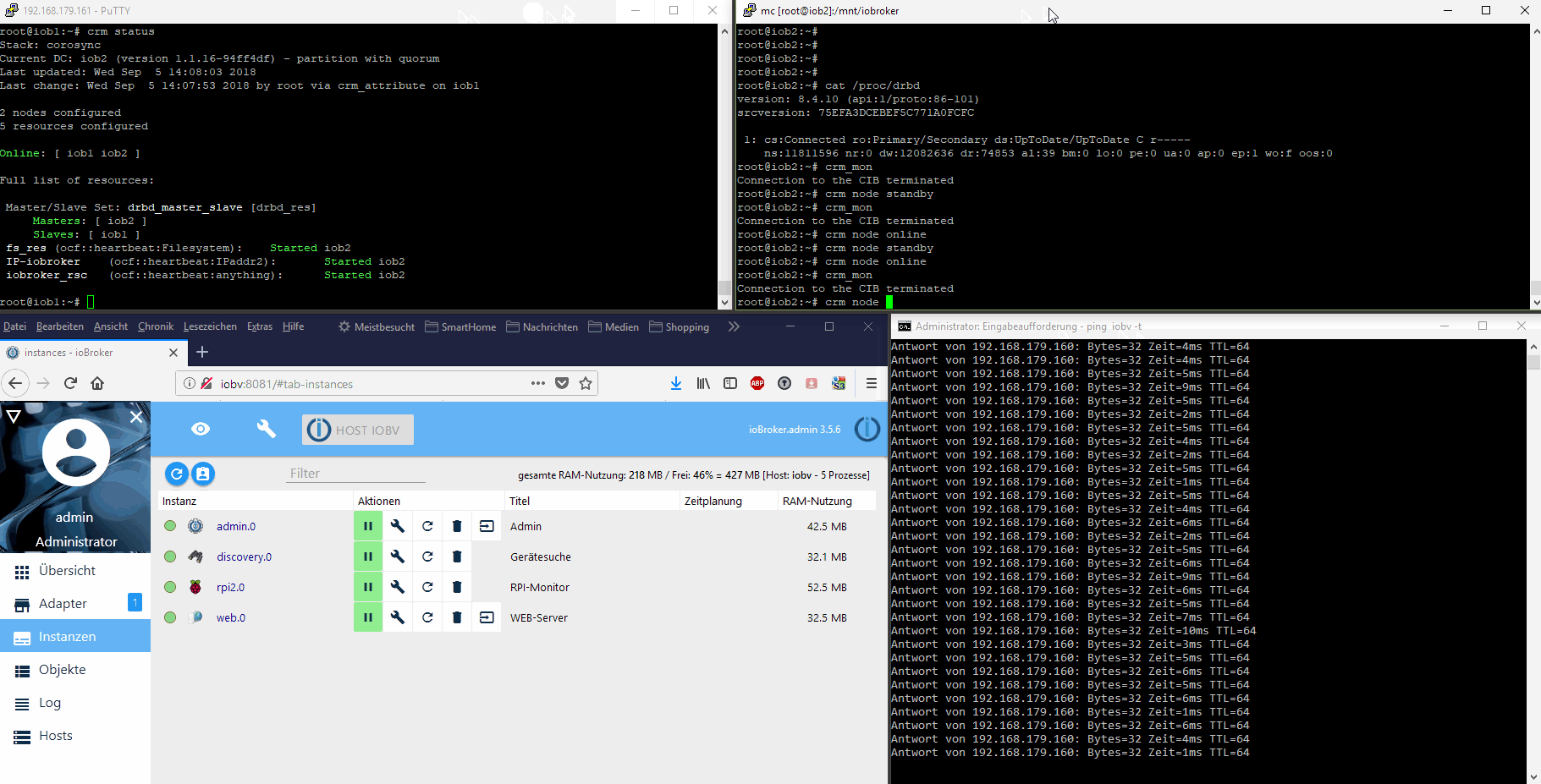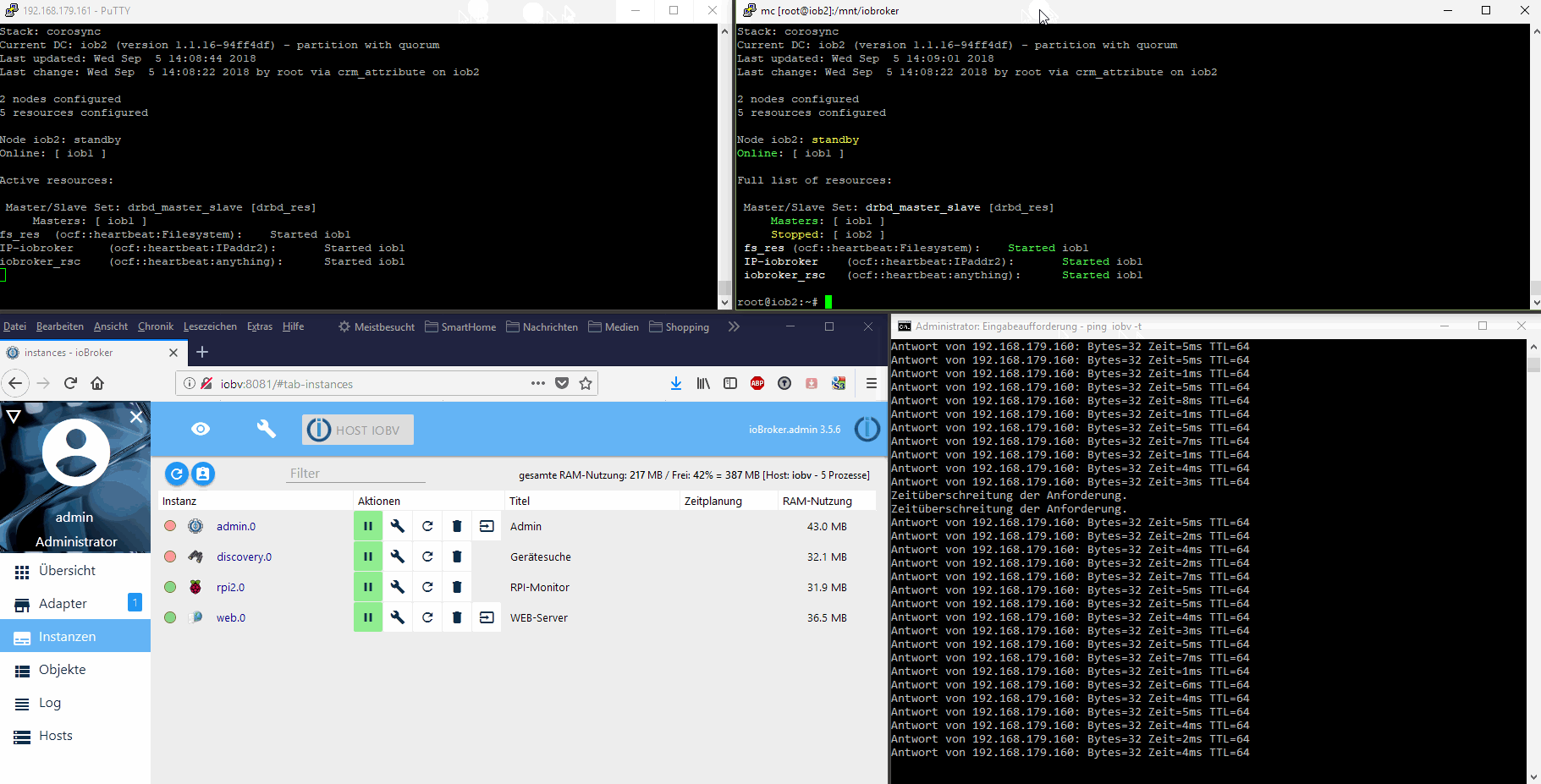
Hier eine Übersicht über die angedachte HA-Lösung:
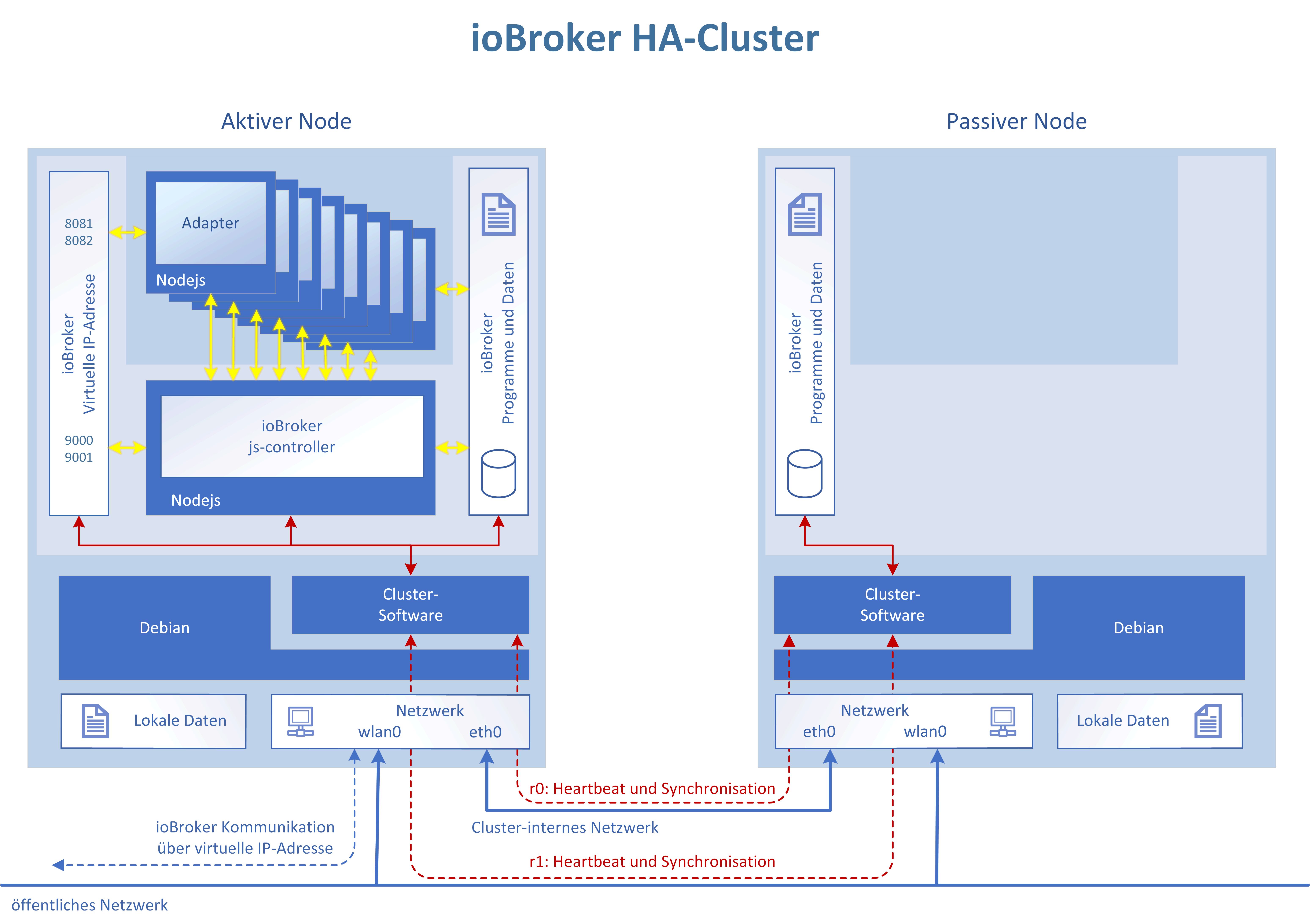
Die Clustersoftware gleicht automatisch immer alle Dateien des ioBrokers zwischen den beiden Knoten ab (Master->Slave Distributed Blockdevice). Im Fehlerfall nimmt die Clustersoftware automatisch die virtuelle IP-Adresse des ioBrokers auf dem passiven Knoten aktiv und startet dort ebenfalls den ioBroker js-controller. Die Adapter werden dann wie gewohnt vom js-controller gestartet.
-
-
2x USB Stick gleicher Größe (z.B. 8GB) `
Besser 2x USB Stick gleicher Größe mit SLC Flash Memory
@Stabilostick:2x WLAN Acces Point, z.B. Fritz!Box und ein als AP konfigurierter Repeater `
Das macht es teuer. Wozu ist das nötig ? -
[WLAN] -> Das macht es teuer. Wozu ist das nötig ? `
Redundante Netzwerkanbindung + um WLAN-Aktoren/-Sensoren weiter in Betrieb zu halten. Natürlich braucht man auch ggf. Kommunikationsmodule wie z.B. Zigbee 2x.
Welche günstige und unter ioBroker-Nutzern verbreitete Plattform wäre den besser geeignet? Also ich habe alles bei mir in meiner Bastelkiste gefunden ;-)
-
Nur mal so als Gedankengang:
Was wäre wenn du das System so aufbaust (wenn das geht) das ein Raspi als Fallback Server arbeitet. Dann kann der Hauptserver im Grunde auf annähernd jeder Linuxplatform laufen.
Damit würdest du nur vorhandene Systeme erweitern.
Bitte verstehe mich nicht falsch. Ich habe absolut keine Ahnung wie das ablaufen wird, aber der Gedanke war eben für mich naheligender weil damit mehr Nutzer abgedeckt werden.
Ich persönlich bin sehr an dieser Idee interessiert, weil ich genau deine Gedankengänge (speziell Punkt 8) nachvollziehen kann. In meiner Hausautomation habe ich bis auf die Scriptsteuerungen alles so aufgebaut das alles im Notfall "von Hand" bedient werden kann. Das ist stellenweise ein gewaltiger Mehraufwand (Punkt 9 relativiert sich dadurch) der durch ein Redundanzsystem nicht ganz so exzessiv betrieben werden müsste.
Redundantes WLan könnte bei mir auch möglich sein mit dem Einsatz eines Unifi. Dadurch habe ich auf der Fritzbox das wlan deaktiviert. Das wäre aber im Zweifelsfall per Tastendruck sofort aktivierbar. Hier wäre eventuell die Überlegung den Hausserver per LAN anzubinden und im Fehlerfall die Fritzbox über den TR064 Adapter und ebenso den Unifi anzusteuern. Ich könnte mir vorstellen das das funktionieren könnte.
-
Was wäre wenn du das System so aufbaust (wenn das geht) das ein Raspi als Fallback Server arbeitet. Dann kann der Hauptserver im Grunde auf annähernd jeder Linuxplatform laufen. Damit würdest du nur vorhandene Systeme erweitern. `
KISS-Prinzip. Keep it stupid, simple. Gleiche Hardware und identische Software auf beiden Knoten. Es geht genügend von selbst schief.
.. dem Einsatz eines Unifi. Dadurch … `
Eines? Dann sind wir wieder beim Single-point-of-Failure? Und beim Ausfall einer Komponente soll der HA-Betrieb ohne Knopfdruck weiter funktionieren. Ich könnte das auch weiterspinnen. Ein DNS? Einen DHCP-Server? …
-
Hi,
es ist eine gute Sache, sich über sowas Gedanken zu machen. Ich werfe da mal ein paar Gedanken zu ein:
-
Hochverfügbarkeit für Arme: Identisches inaktives Standby System, welches durch ein externes System aktiviert werden kann. (Im einfachsten Fall z.B. über den Schalter einer Steckdosenleiste). Ja, ich weiß, ist nicht echtes HA, aber wenn wir nur von Komfortfunktionen reden, sollte es eine Überlegung Wert sein.
-
Bei echter HA brauchst du mind. 3 Systeme, sonst kannst du in ein Split-Brain reinlaufen. Idealerweise kombiniert mit STONITH Mechanismus.
Viele Grüße
Alex
-
-
Hochverfügbarkeit für Arme: Identisches inaktives Standby System, welches durch ein externes System aktiviert werden kann. `
Wie sorgst Du dafür, dass die Daten auf beiden Systemen gleich sind? Das hier ist ein Shared Nothing, Aktiv-Passive-Cluster mit einem Filesystem auf einen Distributed Block Device.
Hier erfolgt die Aktivierung nicht manuell, sondern vollautomatisch. Und ALLE ioBroker-Daten und Adapter sind auf allen Nodes immer zu 100% identisch. Das ist kein HA für Arme. Aber trotzdem günstig (vgl. die HW die Du bei Deiner HA für Arme-Lösung auch vorhalten darfst und nicht die Sicherheit hast). :D
Bei echter HA brauchst du mind. 3 Systeme, sonst kannst du in ein Split-Brain reinlaufen. Idealerweise kombiniert mit STONITH Mechanismus. `
Das hier ist echte HA. Nur - es geht in diesem Fall auch mit zwei Nodes. Und die beiden schaltbaren Steckdosen sind für das erzwungene Ausschalten (Stonith = Shoot The Other Node In The Head) des fehlerbehafteten Knotens - genau wie Du schreibst.
Deswegen aber auch die Bitte um Mithilfe.
-
1x Kleine USV `
Kann eine USV nicht ausfallen ? -
Kann eine USV nicht ausfallen ? `
Kostenreduktion :lol:
Der zweite Knoten läuft auch dann noch, wenn die USV ausfällt. Netz ist ja da. Ist die USV hingegen nicht defekt und das Netz fällt aus, übernimmt die USV. Wenn Die USV leer ist, ist bei einem Raspberry und ein bisschen Netzwerk als Last viel Zeit ins Land geflossen. Und dieselbe USV dürfen wir ja nicht für beide Rechner nehmen. Weil SPoF.
Klar geht es auch mit zwei USVs. Am besten welche von APC, die über Telnet o.ä. steuerbar sind. Dann kann man die als Stonith-Devices nutzen und auf die Steckdosen verzichten. ;)
-
Der Unifi ersetzt in meinem Fall das WLan der Fritzbox. Die Box würde zwar auch reichen, aber es funktioniert mit dem Unifi einfach besser und flüssiger. Scheinbar ist die blöde Box mit 40 Geräten überfordert. Aber als Fallbacklösung wäre sie trotzdem ausreichend.
Aufbau auf zwei Raspi - dann bin ich notgedrungen raus.
Bei mir hat es sich irgendwann ergeben das der Raspi schlicht zu klein war und ich deshalb auf einen NUC ausgewichen bin. Jetzt geht das Arbeiten mit dem Editor und sonstige Spielchen wieder flüssiger.
Dazu möchte ich dir aber noch eine Überlegung auf den Weg geben:
Auf welchen Raspi willst du das aufbauen?
Raspi 3b oder Raspi 3b+?
Was ist im nächsten Jahr wenn voraussichtlich der nächste Raspi auf den Markt kommt?
Nach meiner Meinung solltest du versuchen den ioBroker in Redundanz zu betreiben unabhängig von der Hardwareplatform. Sonst baust du jetzt schon ein System auf das in 2-3 Jahren nicht mehr ernsthaft nutzbar ist mangels Verfügbarkeit der ursprünglichen Hardware.
Ich gebe zu das ich keinerlei Vorstellung davon habe wie das umsetzbar wäre. Nur geht eben mein Gedankengang dahin das du jetzt mit viel Zeit und Herzblut ein System entwickelst das in kürzester Zeit nur ein Nischenprodukt wird. Eine echte Hochverfügbarkeit die Platformunabhängig (sondern nur als Softwarelösung) arbeitet könnte allerdings den ioBroker soweit voranbringen das er dann auch kommerziell nutzbar wäre. Dann könnte man einen beschädigten Server quasi live austauschen und aus dem laufenden Server neu einspiegeln ähnlich einem Raid.
-
Im ersten Schritt soll eine Lösung erarbeitet werden, die nicht das Rad neu erfindet sondern vielmehr auf bewährte Technik setzt. Das ideale OS für Linux-Hochverfügbarkeit wäre IMHO RedHat oder CentOS. Nur darauf mag ich keinen ioBroker installieren. Schon gar nicht auf einem Raspberry.
Nachdem der Raspberry typischerweise auf Debian aufsetzt, und wir vor allem bereits in der Distribution enthaltene Software einsetzen werden, wird mit großer Wahrscheinlichkeit das, was wir erarbeiten, auch auf "größeren" Rechnern wie NUCs u.v.m. funktionieren. Zwischen Raspberry 3 und 3+ sehe ich jetzt keinen diesbezüglich großen Unterschied. Weißt Du mehr?
Nur für den Anfang hatte ich mir ein kleines System, das kostengünstig ist und das man idealerweise eh schon in der Bastelkiste hat, vorgestellt. Bevor man zwei NUCs kauft und dann die Lösung aus irgendwelchen Gründen nichts wird. Und der ioBroker wird, wenn man sich die Zahlen ansieht, sehr häufig auf Raspberrys installiert.
Ziel sollte sein, ein Proof-of Concept in den Händen zu halten, das funktioniert und eine auch für Normalsterbliche nachvollziebare Dokumentation zu schreiben. Dann würde man weiter sehen.
-
Näheres zum Unterschied zwischen den beiden Raspis wüsste ich jetzt nicht. Ich kann mich nur an eine Diskussion hier erinnern das irgendwie das fertige Image nicht kompatibel war. Ist aber schon ein paar Tage her.
Wie gesagt kenne ich mich nicht wirklich mit der Umsetzung als hochverfügbares System aus. Ich gebe dir eben nur meinen Gedankeanstoß damit du die Entwicklung langfristig einplanen kannst. Ich vermute mal das da viel Arbeit dahinter steckt und es wäre jammerschade wenn die Arbeit dann in einer Sackgasse endet. Den überzähligen Raspi haben hier viele in der Bastelkiste liegen. Da bin ich mir recht sicher. Aber auch da wird es schon so sein das dann eben nicht nur 3er liegen sondern wieder 2er aus der Kiste geholt werden.
Der ioBroker selbst scheint ja auf allen Systemen grundsätzlich gleich zu sein. So wäre es eben nach meinem Gefühl vielleicht leichter umsetzbar den ioBroker ständig zu spiegeln und betriebsbereit zu halten. Lediglich der "Einsatzpunkt" müsste dann technisch gelöst werden. Und da denke ich nicht das es einen großen Unterschied machen würde welche Hardware drunter steckt.
Vielleicht noch ein Gedankengang: Wenn der Server per LAN am System hängt und der Raspi per WLan mitläuft. Wäre es dann möglich den Raspi so zu konfigurieren das man den bei einem Serverausfall den LanPort einschaltet und der dann per LAN auf der gleichen IP kommt wie der ausgefallene Server? Der könnte ja beispielsweise erkennen das der Server weg ist und dann würde er den Hardwareport einschalten und die Aufgaben übernehmen. Zusätzlich dann den Server per Steckdose ausschalten damit der nicht spontan dazwischenfunkt.
Bitte verstehe mich nicht falsch. Ich will nichts kritisieren oder verbessern. Ich finde nur deine Idee wirklich spitze und versuche ein paar laienhafte Gedanken einzubringen die vielleicht eine Lösung ermöglichen.
-
Der ioBroker wird auf einer virtuellen IP laufen, die dynamisch dem jeweils aktiven Knoten zugewiesen wird. Er ist also immer unter der selben Adresse erreichbar, egal wo er aktiv ist.
Die LAN-Anbindung des RPIs wird für eine private Verbindung zwischen den Knoten genutzt. Das ist ein spezielles nichtgeroutetes Netz zum Datenabgleich und Interknotenkommunikation.
Die Public-Adresse läuft über das WLAN.
-
Danke für die Erklärung.
Klingt wirklich gut. Aber es scheint so das es ja dann wirklich theoretisch gar nicht von der Hardware abhängig ist sondern nur eine Konfigurationsgeschichte wird (die Netzwerkanbindung). Dann müsste es ja kompatibel zu beliebigen Hardwareplatformen sein.
Stellt sich dann das Problem wie die beiden ioBroker gleichgehalten werden.
-
Ist das nicht vielleicht schon zu Kompliziert gedacht?
Wenn man bedenkt das ein pi recht wenig RAM hat und in deiner Konfiguration eh schon 2 da sind bietet sich doch ein Multihost system an.
Notwendige Erweiterungen:
1. Bei Ausfall des Masters über nimmt ein Slave
2. Dezentrale DB
3. Adapter müssen auf allen Hosts installiert werden
4. Automatische Last Verteilung, Starten/Stoppen von Instanzen je nach Auslastung
Vorteil wäre das die Hardware ständig genutzt würde, das System idealerweise immer Flüssig läuft und mit jedem Host steigt die Ausfall Sicherheit.
Ein großes Problem ich kann nicht an jeden Host ein ZigBee, Z Wave, enOcean Stick hängen, das geht zu sehr ins Geld und ohne Läuft bei mir eh nicht viel.
Davon abgesehen kämpfe ich mehr mit unvorhergesehenen Zuständen als Ausgefallener Hardware.
So oder so ist deine Überlegung gut und auch für die Zukunft notwendig. Bisher hab ich derartige Überlegungen noch bei keinem anderen System gesehen.
Ich glaube iobroker hat mit dem Multihost Betrieb eh schon ein allein Stellungsmerkmal, wenn das noch in die Richtung Hochverfügbarkeit ausgebaut wird ist es der Killer.
Gesendet von meinem m8 mit Tapatalk
-
Chaot, Jey Cee, paul53,
genau wegen Eurer Ideen und Einwände bin ich mit meinen Gedanken "an die Öffentlichkeit" gegangen und suche Mitstreiter. Finde ich ganz toll so, Danke!
` > 1. Bei Ausfall des Masters über nimmt ein Slave
2. Dezentrale DB
3. Adapter müssen auf allen Hosts installiert werden
4. Automatische Last Verteilung, Starten/Stoppen von Instanzen je nach Auslastung `
Das waren anfangs auch meine Gedanken. Natürlich kann man den ioBroker so anpassen, dass er z.B. selbst die Datenbanken und Files auf den HA-Clusterknoten synchron hält. Selbst die Datenbanken könnten auf allen Knoten parallel laufen und sich intern immer abgleichen. Auch mit Redis gibt es da Möglichkeiten.
Man kann die Idee auch weiterspinnen. Die diversen Dateien von VIS oder ioBroker könnten aus dem Filesystem in die Datenbank verschoben werden. Wer sagt zum Beispiel, dass die JavaScript-/usw.-Dateien der Adapter im Filesystem stehen müssen? Die können auch aus einer replizierten DB geladen werden. Dann hat man auch keinen reinen Aktiv/Passiv-Cluster mehr sondern kann bei einem Aktiv/Aktiv-Cluster mit replizierten DB-Instanzen über die Ressourcen beider Knotenrechner gleichzeitig verfügen. Es gibt dann auch keinen Master und keine Slave mehr und alle Rechner sind gleichberechtig.
Träumen darf man. Doch momentan kann der ioBroker das (noch) nicht. Deshalb versuche ich, mit dem auszukommen, was heute möglich ist.
Der aktuelle Multihost-Betrieb ist - bezogen auf HA - nicht so der Burner: Die Knotenanzahl steigt von eins auf zwei inkl. Infrastrukturmehrung und ohne einen Zugewinn an aktiver Sicherheit. Damit verdoppelt sich die Ausfallwahrscheinlichkeit von 100% auf 200%. [emoji2]
-
Ich würde neben dem "Master" auch einmal einen Blick auf den Rest des Systems werfen.
Da gibt es meines Erachtens ebenfalls eine Menge an "Single Points of Failures (SPoF)". Der Server ist da nur einer.
Wenn man die anderen SPoF außer Acht lässt, hat man unter Umständen nicht wirklich etwas gewonnen.
Außer den Konzepten der Architektur könnte es auch sinnvoll sein, Ausfallwahrscheinlichkeiten zu bedenken und zunächst vor allem die Punkte mit (relativ) hoher Ausfallwahrscheinlichkeit zu "stärken".
Dann wäre zu überlegen, was wirklich redundant sein muss und was redundant sein könnte (zusäätzlicher Komfort).
Je geringer die notwendige Redundanz ist, desto einfacher dürfte das Konzept werden.
-
Reicht es, wenn gewisse Grundfuktionen weiter laufen? Welche wären das?
-
Muss Bedienung weiter möglich sein?
-
Muss reine Visualisierung redundant sein?
-
Mit welchen Ausfällen kann ich über eine gewisse Zeit leben?
In der Anlagenautomatisierung versucht man Inseln zu schaffen, die über eine übergeordnete Instanz gesteuert werden (im Sinn von Vorgaben). Diese Inseln sollten möglichst völlig autark weiterlaufen können (natürlich ohne Änderung / Bedienung über die übergeordnete Instanz).
Das gibt einem die Möglichkeit einzelne wichtige Inseln betriebssicherer zu machen (z.B. durch Redundanz), ohne gleich alles redundant zu machen.
Im Redundanzkonzept sollte auch das (bzw. die) Kommunikationsnetz(e) betrachtet werden. Wie stabil sind diese? Welche Fehler können auftreten? Welche SPoF gibt es hier? Welche Auswirkung haben Fehler in den Netzen?
Dann noch die Aktoren und Sensoren: Wie sicher und stabil sind dies? Diese Frage muss auch Messungen und Aktionen umfassen. Es macht wenig Sinn, hier dann unzuverlässige Geräte zu nutzen, wenn hohe Verfügbarkeit gefordert ist.
In der Automatisierung habe ich Systeme realisiert, die neben der Redundanz der Steuerung auch redundante Ansteuerungen (I/O), redundante Netze und Redundanz bei Aktoren und Sensoren beinhaltet haben. Das sind dann echt komplexe Projekte. Und Firmen investieren für so etwas sehr viel Geld, falls dies benötigt wird.
Ich möchte damit den Gedanken von Stabilostick nicht kaputt machen.
Er ist auf jeden Fall ein erster Ansatz für das Thema "Hochverfügbarkeit". Es ist aber wichtig, dass die Grenzen dieser Lösungen auch verstanden werden. Sonst ist mit viel Frust zu rechnen.
-
-
Hochverfügbarkeit für Arme: Identisches inaktives Standby System, welches durch ein externes System aktiviert werden kann. `
Wie sorgst Du dafür, dass die Daten auf beiden Systemen gleich sind? Das hier ist ein Shared Nothing, Aktiv-Passive-Cluster mit einem Filesystem auf einen Distributed Block Device.
Hier erfolgt die Aktivierung nicht manuell, sondern vollautomatisch. Und ALLE ioBroker-Daten und Adapter sind auf allen Nodes immer zu 100% identisch. Das ist kein HA für Arme. Aber trotzdem günstig (vgl. die HW die Du bei Deiner HA für Arme-Lösung auch vorhalten darfst und nicht die Sicherheit hast). :D
Bei echter HA brauchst du mind. 3 Systeme, sonst kannst du in ein Split-Brain reinlaufen. Idealerweise kombiniert mit STONITH Mechanismus. `
Das hier ist echte HA. Nur - es geht in diesem Fall auch mit zwei Nodes. Und die beiden schaltbaren Steckdosen sind für das erzwungene Ausschalten (Stonith = Shoot The Other Node In The Head) des fehlerbehafteten Knotens - genau wie Du schreibst.
Deswegen aber auch die Bitte um Mithilfe. `
Hi,
Die Lösung ist für Arme, weil eben der ganze Automatismus fehlt und man einiges manuell machen muss. Weniger Komfort, weniger Sicherheit, aber halt auch weniger Komplexität und weniger Wissen beim Anwender nötig.
Bei nur zwei Nodes kann es dir beim Ausfall des Netzwerks passieren, dass beide denken, dass der andere tot ist und ihn mit dem STONITH Device abschießen. Mit einem dritten Node hast du einen Mehrheitsentscheid für das Abschießen. Und wenn das Netzwerk ausfallen sollte. gibt es keine Mehrheit und daher wird der aktive Node nicht abgeschossen, aber es übernimmt auch keiner der anderen beiden Nodes. Es läuft dann also erstmal weiter. Schön wär für sowas natürlich ein HA Switch Stack mit redundanter Anbindung zu jeden Node, aber dann wird es für den Privathaushalt schon etwas sehr teuer.
Beim Filesystem wäre GlusterFS vielleicht noch eine Option, es hat ein paar Vorteile, nicht auf Block Ebene, sondern auf File Ebene zu arbeiten. (Aber klar auch Nachteile)
Viele Grüße
Alex
-
Hallo Karl_999,
wie Du selbst schreibst, teilt man das Problem HA in der Regel in viele kleine Teillösungen auf, die über definierte Schnittstellen, klar geregelte Verfügbarkeiten, Service Level Agreements und Leuten mit Wissen und Praxis zusammengehalten werden. Eine Abteilung stellt das SAN bereit, die andere das Netzwerk und die Dritte die Serverhardware. Und dazu gibt es noch Zuständige für Backup/Restore, Betrieb und Monitoring.
Wir müssen es hier einfacher halten. Ich bin zuhause - bezogen auf die Backendtechnik - alleine. Meine Frau mag nichts von Technik wissen, freut sich aber über die Automatismen, an die sie sich inzwischen gewöhnt hat. Und mir graut vor dem Moment, an dem ich nicht mehr bin und etwas nicht geht. Dann bleibt wohl nur der Rückbau.
Bislang haben wir bis auf das automatische Starten von "hängengebliebenen" Adaptern im ioBroker fast nichts. Etwas Monitoring und ein Autostart-Script. Aus- und Einschalten. Keine Watchdog für die Hardware, keine redundante Datenhaltung, kein automatisches Failover, keine … nichts. Mir ist nicht bekannt, ob wir uns da von anderen Lösungen wie openHAB oder FHEM unterscheiden.
Dazu kommt, dass man aufgrund der (positiven) Vielseitigkeit von ioBroker so gut wie keine einheitlichen Standardverfahren für alle möglichen Funk-, Wired, CCU, Homee, .... , Heizungsanlagen und Smartmetern global aus den Ärmeln schütteln kann. Jedes ioBroker-System ist in seiner Gesamtheit individuell.
Ja, man muss sich Gedanken machen, was einem wichtig (und ggf. auch teuer) ist. Aber es gibt eine Komponente, die überall vorhanden ist.
Bei und mit dem ioBroker haben wir auf dem ersten Blick einen SPoF. Er ist das zentrale Logik- und Kommunikationsmodul. Natürlich zusammen mit seiner Infrastrukturanbindung. Er muss mindestens HA sein, damit man sich dann Gedanken machen kann, welche Schnittstellen/Sensoren/Aktoren auch bei einem Stromausfall noch laufen müssen. Dafür muss ich dann ggf. auch Geld in die Hand nehmen, um diese über USV an das Stromnetz anzuschließen. Oder gleich welche mit Batterie nehmen. Oder enOcean. Oder...
Einer HA-Lösung für die ioBroker-Software selbst kann man standardisieren. In dem man wie hier z.B. sagt, wir unterstützen zuerst einmal genau die folgenden Infrasturkurkomponenten. Und genau die Softwareversion. Sonst keine. Und eine gute Dokumentation bereitstellt.
Wie sähe es denn bei Dir aus? Was sagen Dir Deine Erfahrungen mit HA über Deine Hausautomatisationslösung und ioBroker?
-
Hallo Alexander,
auch Dir ein herzliches Danke für Deine kritischen Anmerkungen.
> Die Lösung ist für Arme, weil eben der ganze Automatismus fehltWas fehlt bei meinem Lösungsansatz? Was muss man wann manuell machen? Ich bitte um Beispiele. Hast Du Dir mein Video oben angesehen? Oder meinst Du Deinen Vorschlag, einfach ein Standby-System nebenhin zu stellen. Dann greift aber Punkt 3 aus meiner Liste oben. Keine HA. Nicht mal für Arme.
> Bei nur zwei Nodes kann es dir beim Ausfall des Netzwerks passieren, dass beide denken, dass der andere tot istIch kenne das Thema. Hier letztendlich (hoffentlich) nicht. Die Netzwerkkommunikation ist redundant ausgelegt und die Clusterkommunikation wird über zwei unabhängige Wege geprüft (Public/Private-Network). Eine der beiden Kommunikationenwege geht nicht über einen Switch.

Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden421
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge