

inflxudb kurze Speicherdauer einstellen
-
@cbrocker 2te Instanz von influxdb und in ein zweites Bucket mit kurzer Speicherdauer schreiben.
@spacerx said in inflxudb kurze Speicherdauer einstellen:
2te Instanz von influxdb und in ein zweites Bucket mit kurzer Speicherdauer schreiben.
Hey, danke. Ja, das hatte ich mir auch schon überlegt.
Aber nur deswegen möchte ich keine 2. Instanz.Weißt du, kann man in influxdb aber von einem measurement dann Daten, z.B. älter als 1 Woche, manuell löschen?
-
@cbrocker 2te Instanz von influxdb und in ein zweites Bucket mit kurzer Speicherdauer schreiben.
@spacerx
ich lese gerade in der influxdb Doku folgendes:A database can have multiple retention policies with one set as default. If no retention policy is specified in a query or write request, InfluxDB uses the default retention policy for the specified database. Use the influx CLI or the InfluxDB API to set a retention policy as the default retention policy for a database.
Dann könnte es doch möglich sein, unterschiedl. Aufbewahrungsrichtlinien einzustellen.
Das heißt, rumtüfteln...Proxmox Cluster mit ioBroker, Wireguard, HomeAssistant (Testsystem), paperlessNGX, MariaDB, PiHole, Grafana, InfluxDB, 1 x BKW 600 Wp, 2 x BKW 400 Wp, 2 x SolarFlow 800 Pro mit 11,52 kWh Akku und 3,48 kWp, OpenDTU, AhoyDTU, HmIP, Shellys, AVM LAN/WLAN
-
@spacerx
ich lese gerade in der influxdb Doku folgendes:A database can have multiple retention policies with one set as default. If no retention policy is specified in a query or write request, InfluxDB uses the default retention policy for the specified database. Use the influx CLI or the InfluxDB API to set a retention policy as the default retention policy for a database.
Dann könnte es doch möglich sein, unterschiedl. Aufbewahrungsrichtlinien einzustellen.
Das heißt, rumtüfteln...@cbrocker Nein in der Regel lässt Du iobroker kurzfristig sammeln - das Konsolidieren in langfristige Buckets solltest Du selbst innerhalb von influx machen. Die Vorhaltedauer, die Du im Adapter einstellst wird automatisch auf die Retention Time im Bucket übertragen.
-
@cbrocker Nein in der Regel lässt Du iobroker kurzfristig sammeln - das Konsolidieren in langfristige Buckets solltest Du selbst innerhalb von influx machen. Die Vorhaltedauer, die Du im Adapter einstellst wird automatisch auf die Retention Time im Bucket übertragen.
@mickym
Hey, was meinst du mit, in iobroker kurzfristig sammeln?Diese Einstellung im Adapter ist letzten Endes die Retention Policy in influxdb?

Proxmox Cluster mit ioBroker, Wireguard, HomeAssistant (Testsystem), paperlessNGX, MariaDB, PiHole, Grafana, InfluxDB, 1 x BKW 600 Wp, 2 x BKW 400 Wp, 2 x SolarFlow 800 Pro mit 11,52 kWh Akku und 3,48 kWp, OpenDTU, AhoyDTU, HmIP, Shellys, AVM LAN/WLAN
-
@mickym
Hey, was meinst du mit, in iobroker kurzfristig sammeln?Diese Einstellung im Adapter ist letzten Endes die Retention Policy in influxdb?
-
@mickym ja, verstehe. ok, danke. Ich lese mich gerade bißchen durch die Doku und frage ChatGPT um Rat :-)
Proxmox Cluster mit ioBroker, Wireguard, HomeAssistant (Testsystem), paperlessNGX, MariaDB, PiHole, Grafana, InfluxDB, 1 x BKW 600 Wp, 2 x BKW 400 Wp, 2 x SolarFlow 800 Pro mit 11,52 kWh Akku und 3,48 kWp, OpenDTU, AhoyDTU, HmIP, Shellys, AVM LAN/WLAN
-
@mickym ja, verstehe. ok, danke. Ich lese mich gerade bißchen durch die Doku und frage ChatGPT um Rat :-)
@cbrocker Ja ich habs nur mal im Test gehabt und hab bisschen gelernt - und ein paar Kurse der univeristy durchgemacht - habs dann erst mal wieder auf Eis gelegt, weil ich nicht der große Datensammler bin.
Aber immerhin - 3 Kurse habe ich durchgemacht. ;)
-
@cbrocker Ja ich habs nur mal im Test gehabt und hab bisschen gelernt - und ein paar Kurse der univeristy durchgemacht - habs dann erst mal wieder auf Eis gelegt, weil ich nicht der große Datensammler bin.
Aber immerhin - 3 Kurse habe ich durchgemacht. ;)
@mickym wow, da hast dich echt reingekniet, da ja auch alles auf englisch ist.
Ja, so ein SmartHome System erfordert dann Kenntnisse in 30 weitere Dinge/Programmiersprachen/Datenbanken usw.
Aber das macht echt Spaß :-)Proxmox Cluster mit ioBroker, Wireguard, HomeAssistant (Testsystem), paperlessNGX, MariaDB, PiHole, Grafana, InfluxDB, 1 x BKW 600 Wp, 2 x BKW 400 Wp, 2 x SolarFlow 800 Pro mit 11,52 kWh Akku und 3,48 kWp, OpenDTU, AhoyDTU, HmIP, Shellys, AVM LAN/WLAN
-
@mickym wow, da hast dich echt reingekniet, da ja auch alles auf englisch ist.
Ja, so ein SmartHome System erfordert dann Kenntnisse in 30 weitere Dinge/Programmiersprachen/Datenbanken usw.
Aber das macht echt Spaß :-)@cbrocker Ja aber wieder viel vergessen - da gibts Leute, die hier viel fitter sind. Aber dieser Grundlagen oder dass die Retention Time des Adapters mit dem des iobroker buckets übereinstimmt, habe ich halt selbst schon festgestellt. ;)
Und das Telegraf ist wieder ein eigenes System mit dem Du direkt Dinge überwachen kannst, das habe ich mal auf meinem Windows und auf dem Raspberry ausprobiert. Aber es sind richtige Agenten die auf den Zielsystemen laufen. Der Vorteil ist, dass Du damit Daten systemübergreifend sammeln kannst. Ist aber auch eine Wissenschaft für sich. Manchmal kniet man sich bissi rein und dann lässt man es wieder. In Teilbereichen kannst Du damit auch iobroker Adapter ersetzen. Aber manchmal führen zuviele Wege nach Rom. ;)
Also ich bin da kein Fachmann drin, auch wenn ich Dir glaube für Deine Frage eine fachlich richtige Auskunft gegeben habe.
-
@cbrocker Ja aber wieder viel vergessen - da gibts Leute, die hier viel fitter sind. Aber dieser Grundlagen oder dass die Retention Time des Adapters mit dem des iobroker buckets übereinstimmt, habe ich halt selbst schon festgestellt. ;)
Und das Telegraf ist wieder ein eigenes System mit dem Du direkt Dinge überwachen kannst, das habe ich mal auf meinem Windows und auf dem Raspberry ausprobiert. Aber es sind richtige Agenten die auf den Zielsystemen laufen. Der Vorteil ist, dass Du damit Daten systemübergreifend sammeln kannst. Ist aber auch eine Wissenschaft für sich. Manchmal kniet man sich bissi rein und dann lässt man es wieder. In Teilbereichen kannst Du damit auch iobroker Adapter ersetzen. Aber manchmal führen zuviele Wege nach Rom. ;)
Also ich bin da kein Fachmann drin, auch wenn ich Dir glaube für Deine Frage eine fachlich richtige Auskunft gegeben habe.
-
@cbrocker sagte in inflxudb kurze Speicherdauer einstellen:
ich lese gerade in der influxdb Doku folgendes:
A database can have multiple retention policies with one set as default. If no retention policy is specified in a query or write request, InfluxDB uses the default retention policy for the specified database. Use the influx CLI or the InfluxDB API to set a retention policy as the default retention policy for a database.
Dann könnte es doch möglich sein, unterschiedl. Aufbewahrungsrichtlinien einzustellen.
Das gibt es in der Influxdb 2.x nicht mehr. Ein Bucket = eine Retention Time.
-
@cbrocker sagte in inflxudb kurze Speicherdauer einstellen:
@mickym ja, das hat mir schon weitergeholfen von dir.
Stimmt, mit Telegraf und Chronograph usw. könnte man weitermachen...
Aber ich denke, für das eigene SmartHome braucht man so Zeugs nicht wirklichMoin,
ich nutze ein Bucket für den
ioBrokerin den alle DP geschrieben werden, dieser hat nur eine geringe Halbwertzeit von 15 Tagen :)
Anschließend mache ich innerhalb voninfluxDBDownsampling der Daten aus demioBroker - Bucketin ein Bucket, das die Daten für einen Monat hält, wo ich dann wieder einDownsamplingmache und in ein Quartals - Bucket schreibe und dann nochmal aus dem Quartals - Bucket, in das Jahres - Bucket.Ist am Anfang viel Arbeit, aber ich denke, wenn ich damit fertig bin, habe ich meine Daten gut im Griff und kann dann auch schnell Diagramme auf Basis der Buckets machen.
Das ganze läuft aktuell noch alles in einer Testphase, da ich noch auf meine endgültige Hardware warte, die leider erst Ende Mai, Anfang Juni kommt, da es ein Kickstarter Deal ist 🙃
VG
Bernd -
@cbrocker sagte in inflxudb kurze Speicherdauer einstellen:
@mickym ja, das hat mir schon weitergeholfen von dir.
Stimmt, mit Telegraf und Chronograph usw. könnte man weitermachen...
Aber ich denke, für das eigene SmartHome braucht man so Zeugs nicht wirklichMoin,
ich nutze ein Bucket für den
ioBrokerin den alle DP geschrieben werden, dieser hat nur eine geringe Halbwertzeit von 15 Tagen :)
Anschließend mache ich innerhalb voninfluxDBDownsampling der Daten aus demioBroker - Bucketin ein Bucket, das die Daten für einen Monat hält, wo ich dann wieder einDownsamplingmache und in ein Quartals - Bucket schreibe und dann nochmal aus dem Quartals - Bucket, in das Jahres - Bucket.Ist am Anfang viel Arbeit, aber ich denke, wenn ich damit fertig bin, habe ich meine Daten gut im Griff und kann dann auch schnell Diagramme auf Basis der Buckets machen.
Das ganze läuft aktuell noch alles in einer Testphase, da ich noch auf meine endgültige Hardware warte, die leider erst Ende Mai, Anfang Juni kommt, da es ein Kickstarter Deal ist 🙃
VG
Bernd -
@spacerx
ich lese gerade in der influxdb Doku folgendes:A database can have multiple retention policies with one set as default. If no retention policy is specified in a query or write request, InfluxDB uses the default retention policy for the specified database. Use the influx CLI or the InfluxDB API to set a retention policy as the default retention policy for a database.
Dann könnte es doch möglich sein, unterschiedl. Aufbewahrungsrichtlinien einzustellen.
Das heißt, rumtüfteln...@cbrocker Hier mal mein Beitrag zum Thema Retentionpolice.https://forum.iobroker.net/topic/58462/datenaufzeichnung-retention-influxdb-2-0/16
Ich hab das für mich so gelöst das ich im ioBroker Bucket eine Aufbewahrungzeit von 3 Monaten eingestellt habe.
Alles was ich länger haben möchte, wird mit Downsampling in andere Buckets geschrieben. -
@cbrocker Hier mal mein Beitrag zum Thema Retentionpolice.https://forum.iobroker.net/topic/58462/datenaufzeichnung-retention-influxdb-2-0/16
Ich hab das für mich so gelöst das ich im ioBroker Bucket eine Aufbewahrungzeit von 3 Monaten eingestellt habe.
Alles was ich länger haben möchte, wird mit Downsampling in andere Buckets geschrieben. -
@dp20eic Hey, das ist ein interessanter Ansatz.
Machst du dann Grafana Diagramme nur mit den Daten aus dem Jahres-Bucket oder auch von den anderen?Sprich, deine längste Aufbewahrungsdauer ist aber 1 Jahr?
Was für ne Hardware hast du bestellt?
@cbrocker sagte in inflxudb kurze Speicherdauer einstellen:
@dp20eic Hey, das ist ein interessanter Ansatz.
Moin,
hab den Post von @SpacerX nicht weiter verfolgt, ich lasse alle Datenpunkte in mein
iobrokerBucket schreiben, also alles ob nun sekündlich oder nur alle paar Stunden ein Wert kommt.Machst du dann Grafana Diagramme nur mit den Daten aus dem Jahres-Bucket oder auch von den anderen?
Ich mache auch von den anderen Buckets Diagrammen, z.B. Spritpreise bleiben nur im
iobrokerBucket für 15 Tage, daraus baue ich mir die Anzeige für den Tag, da mir eine Aggregierung auf Tag nicht für den aktuell günstigsten Preis hilft ;)
Bei anderen, wie z. B. Strom, Gas und Wasser ist es auch unterschiedlich, Strom will ich den aktuellen Verbrauch sehen → 15 Tages Bucket, dann aber auch wie war der Verbrauch gestern über den Tag im Vergleich zum Vortag oder Woche zur Vorwoche nehme ich dann aber nicht mehr die Daten aus dem 15 Tages Bucket, sondern schon aggregierte Werte aus einem anderen Bucket. Beim Wasser ist es dann nicht der aktuelle Wert der mich interessiert, sondern vielleicht nur noch der Verbrauch im Monat oder Quartal.Ich stelle ich mir die Frage, welche Werte brauche ich länger als die eingestellten 15 Tage, z. B. Stromverbrauch total, möchte ich mindestens zwei Jahre zurückverfolgen, also aggregiere ich täglich, kurz nach Mitternacht, die Werte des Datenpunkts und schreibe ihn in ein eigenes Bucket, hier speziell noch eins nur für Strom, mit eigener Org. und eigenem Token.
import "timezone" option task = {name: "Downsampling Vb_Stromzaehler", cron: "15 0 * * *"} option location = timezone.location(name: "Europe/Berlin") data = from(bucket: "iobroker_strom") |> range(start: -2mo, stop: now()) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh") |> filter(fn: (r) => r["_field"] == "value") // Spalten "_start", "_stop", "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_time") // In Wh ohne Komma |> toInt() |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "iobroker_strom")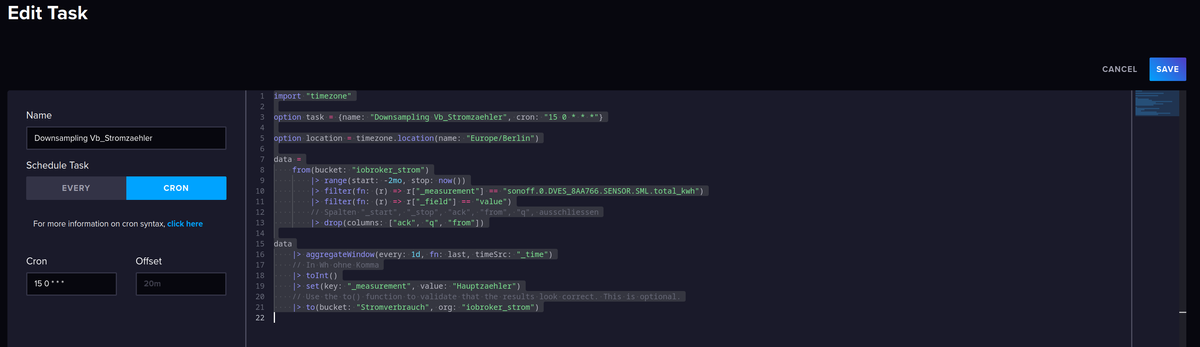
Aktuell erstelle ich mir eine Liste mit den DP, die ich archiviere, damit ich mir einen Überblick verschaffen kann, wie ich welchen Wert brauche
Beispiel:dp 15 T Monatswert Quartalswert Jahreswert für immer sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh X X X tankerkoemig.0.e10 X X Sprich, deine längste Aufbewahrungsdauer ist aber 1 Jahr?
Aktuell Ja, ich habe aber auch erst z. B. mit Strom dieses Jahr im Jan. angefangen, ich beobachte mal wie was anwächst, das ist ja auch ein Vorteil des Downsampling, dass die Menge der gespeicherten Daten geringer wird.
Was für ne Hardware hast du bestellt?
Zwei davon https://www.kickstarter.com/projects/storaxa/fully-customizable-home-cloud-storage-with-remote-access-nas?lang=de

Mit je 64 GB Memory, aber noch ohne M.2 oder SSD, da nutze ich das Vorhandene aus meiner DS716 + DX510, wenn aber die Preise für M.2 weiter so attraktiv sind, werde ich mir da wohl noch die ein oder andere holen :)VG
Bernd -
@cbrocker sagte in inflxudb kurze Speicherdauer einstellen:
@dp20eic Hey, das ist ein interessanter Ansatz.
Moin,
hab den Post von @SpacerX nicht weiter verfolgt, ich lasse alle Datenpunkte in mein
iobrokerBucket schreiben, also alles ob nun sekündlich oder nur alle paar Stunden ein Wert kommt.Machst du dann Grafana Diagramme nur mit den Daten aus dem Jahres-Bucket oder auch von den anderen?
Ich mache auch von den anderen Buckets Diagrammen, z.B. Spritpreise bleiben nur im
iobrokerBucket für 15 Tage, daraus baue ich mir die Anzeige für den Tag, da mir eine Aggregierung auf Tag nicht für den aktuell günstigsten Preis hilft ;)
Bei anderen, wie z. B. Strom, Gas und Wasser ist es auch unterschiedlich, Strom will ich den aktuellen Verbrauch sehen → 15 Tages Bucket, dann aber auch wie war der Verbrauch gestern über den Tag im Vergleich zum Vortag oder Woche zur Vorwoche nehme ich dann aber nicht mehr die Daten aus dem 15 Tages Bucket, sondern schon aggregierte Werte aus einem anderen Bucket. Beim Wasser ist es dann nicht der aktuelle Wert der mich interessiert, sondern vielleicht nur noch der Verbrauch im Monat oder Quartal.Ich stelle ich mir die Frage, welche Werte brauche ich länger als die eingestellten 15 Tage, z. B. Stromverbrauch total, möchte ich mindestens zwei Jahre zurückverfolgen, also aggregiere ich täglich, kurz nach Mitternacht, die Werte des Datenpunkts und schreibe ihn in ein eigenes Bucket, hier speziell noch eins nur für Strom, mit eigener Org. und eigenem Token.
import "timezone" option task = {name: "Downsampling Vb_Stromzaehler", cron: "15 0 * * *"} option location = timezone.location(name: "Europe/Berlin") data = from(bucket: "iobroker_strom") |> range(start: -2mo, stop: now()) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh") |> filter(fn: (r) => r["_field"] == "value") // Spalten "_start", "_stop", "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_time") // In Wh ohne Komma |> toInt() |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "iobroker_strom")Aktuell erstelle ich mir eine Liste mit den DP, die ich archiviere, damit ich mir einen Überblick verschaffen kann, wie ich welchen Wert brauche
Beispiel:dp 15 T Monatswert Quartalswert Jahreswert für immer sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh X X X tankerkoemig.0.e10 X X Sprich, deine längste Aufbewahrungsdauer ist aber 1 Jahr?
Aktuell Ja, ich habe aber auch erst z. B. mit Strom dieses Jahr im Jan. angefangen, ich beobachte mal wie was anwächst, das ist ja auch ein Vorteil des Downsampling, dass die Menge der gespeicherten Daten geringer wird.
Was für ne Hardware hast du bestellt?
Zwei davon https://www.kickstarter.com/projects/storaxa/fully-customizable-home-cloud-storage-with-remote-access-nas?lang=de
Mit je 64 GB Memory, aber noch ohne M.2 oder SSD, da nutze ich das Vorhandene aus meiner DS716 + DX510, wenn aber die Preise für M.2 weiter so attraktiv sind, werde ich mir da wohl noch die ein oder andere holen :)VG
Bernd@dp20eic Hey Bernd,
vielen Dank für die ausführlichen Infos. Sehr interessant und hilft mir bei meinem Brainstorming.Im Thread von SpacerX habe ich auch gelesen, daß es mit der Zeitzone Probleme geben kann.
Ist die timezone.location schon notwendig?Warum hast du bei dem Strom Bucket eine Org und Token?
Wie viel Buckets hast du insgsamt?Grüße Christoph
-
@dp20eic Hey Bernd,
vielen Dank für die ausführlichen Infos. Sehr interessant und hilft mir bei meinem Brainstorming.Im Thread von SpacerX habe ich auch gelesen, daß es mit der Zeitzone Probleme geben kann.
Ist die timezone.location schon notwendig?Warum hast du bei dem Strom Bucket eine Org und Token?
Wie viel Buckets hast du insgsamt?Grüße Christoph
Moin,
@cbrocker sagte in inflxudb kurze Speicherdauer einstellen:
@dp20eic Hey Bernd,
vielen Dank für die ausführlichen Infos. Sehr interessant und hilft mir bei meinem Brainstorming.Gerne doch, deswegen sind wir doch hier, um uns auszutauschen :)
Im Thread von SpacerX habe ich auch gelesen, daß es mit der Zeitzone Probleme geben kann.
Ist die timezone.location schon notwendig?Ich habe bis jetzt immer festgestellt, dass ich
Zulu Zeit = UTCin den Rohdaten habe, daher ist das für mich erst einmal so gesetzt, wenn ich feststelle, dass etwas nicht stimmt in der Abfrage, dann fliegt es raus :)Warum hast du bei dem Strom Bucket eine Org und Token?
Als ich anfing, hatte ich noch alles unter einer Org und einem Token, dann kamen immer mehr, auch andere Sachen, die nichts mit
ioBrokerzu tun haben dazu, dann habe ich auch ab und an Mist gebaut und so fing ich an alles zu trennen, ob das so sein muss, keine Ahnung. Da ich mich immer noch im Aufbau befinde, tut das auch nicht so weh. Wenn dann die Hardware da ist, wird das sauber aufgebaut, und die Daten exportiert und im Zielbucket importiert.Wie viel Buckets hast du insgsamt?
Aktuell sind es glaube ich neun, plus zwei hier für das Forum, falls man mal etwas testen muss,
proxmox metrik,telgraf Metriken LXC Container, Office PCs,Loki Logfile Monitoring,FritzinfluxDB,15T iobroker,Monats-, Quartals-, Jahres-, Immer-Bucket
VG
Bernd -
Moin,
@cbrocker sagte in inflxudb kurze Speicherdauer einstellen:
@dp20eic Hey Bernd,
vielen Dank für die ausführlichen Infos. Sehr interessant und hilft mir bei meinem Brainstorming.Gerne doch, deswegen sind wir doch hier, um uns auszutauschen :)
Im Thread von SpacerX habe ich auch gelesen, daß es mit der Zeitzone Probleme geben kann.
Ist die timezone.location schon notwendig?Ich habe bis jetzt immer festgestellt, dass ich
Zulu Zeit = UTCin den Rohdaten habe, daher ist das für mich erst einmal so gesetzt, wenn ich feststelle, dass etwas nicht stimmt in der Abfrage, dann fliegt es raus :)Warum hast du bei dem Strom Bucket eine Org und Token?
Als ich anfing, hatte ich noch alles unter einer Org und einem Token, dann kamen immer mehr, auch andere Sachen, die nichts mit
ioBrokerzu tun haben dazu, dann habe ich auch ab und an Mist gebaut und so fing ich an alles zu trennen, ob das so sein muss, keine Ahnung. Da ich mich immer noch im Aufbau befinde, tut das auch nicht so weh. Wenn dann die Hardware da ist, wird das sauber aufgebaut, und die Daten exportiert und im Zielbucket importiert.Wie viel Buckets hast du insgsamt?
Aktuell sind es glaube ich neun, plus zwei hier für das Forum, falls man mal etwas testen muss,
proxmox metrik,telgraf Metriken LXC Container, Office PCs,Loki Logfile Monitoring,FritzinfluxDB,15T iobroker,Monats-, Quartals-, Jahres-, Immer-Bucket
VG
Bernd@dp20eic
Hallo Bernd,da hast du dich ja schon sehr reingekniet in influxdb. Kostet viel Zeit, aber ist auch sehr interessant und macht auch Spaß :-)
Habe gerade noch paar Aktualisierungen im iobroker vorgenommen. Bin kürzlich ja von Rasp Pi auf Proxmox umgestiegen. Da sind nun noch einige Sachen komisch...
Die Org. und der Token für Strom benutzt du dann nur in dem Flux-Code?
Denn im influxdb Adapter kann man ja nur einen Token hinterlegen.Da man in Proxmox ja bequem ein Backup erstellen kann, ist es echt halb so wild, wenn man bißchen was verbockt :-)
Grüße
Christoph -
@cbrocker sagte in inflxudb kurze Speicherdauer einstellen:
@dp20eic Hey, das ist ein interessanter Ansatz.
Moin,
hab den Post von @SpacerX nicht weiter verfolgt, ich lasse alle Datenpunkte in mein
iobrokerBucket schreiben, also alles ob nun sekündlich oder nur alle paar Stunden ein Wert kommt.Machst du dann Grafana Diagramme nur mit den Daten aus dem Jahres-Bucket oder auch von den anderen?
Ich mache auch von den anderen Buckets Diagrammen, z.B. Spritpreise bleiben nur im
iobrokerBucket für 15 Tage, daraus baue ich mir die Anzeige für den Tag, da mir eine Aggregierung auf Tag nicht für den aktuell günstigsten Preis hilft ;)
Bei anderen, wie z. B. Strom, Gas und Wasser ist es auch unterschiedlich, Strom will ich den aktuellen Verbrauch sehen → 15 Tages Bucket, dann aber auch wie war der Verbrauch gestern über den Tag im Vergleich zum Vortag oder Woche zur Vorwoche nehme ich dann aber nicht mehr die Daten aus dem 15 Tages Bucket, sondern schon aggregierte Werte aus einem anderen Bucket. Beim Wasser ist es dann nicht der aktuelle Wert der mich interessiert, sondern vielleicht nur noch der Verbrauch im Monat oder Quartal.Ich stelle ich mir die Frage, welche Werte brauche ich länger als die eingestellten 15 Tage, z. B. Stromverbrauch total, möchte ich mindestens zwei Jahre zurückverfolgen, also aggregiere ich täglich, kurz nach Mitternacht, die Werte des Datenpunkts und schreibe ihn in ein eigenes Bucket, hier speziell noch eins nur für Strom, mit eigener Org. und eigenem Token.
import "timezone" option task = {name: "Downsampling Vb_Stromzaehler", cron: "15 0 * * *"} option location = timezone.location(name: "Europe/Berlin") data = from(bucket: "iobroker_strom") |> range(start: -2mo, stop: now()) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh") |> filter(fn: (r) => r["_field"] == "value") // Spalten "_start", "_stop", "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_time") // In Wh ohne Komma |> toInt() |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "iobroker_strom")Aktuell erstelle ich mir eine Liste mit den DP, die ich archiviere, damit ich mir einen Überblick verschaffen kann, wie ich welchen Wert brauche
Beispiel:dp 15 T Monatswert Quartalswert Jahreswert für immer sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh X X X tankerkoemig.0.e10 X X Sprich, deine längste Aufbewahrungsdauer ist aber 1 Jahr?
Aktuell Ja, ich habe aber auch erst z. B. mit Strom dieses Jahr im Jan. angefangen, ich beobachte mal wie was anwächst, das ist ja auch ein Vorteil des Downsampling, dass die Menge der gespeicherten Daten geringer wird.
Was für ne Hardware hast du bestellt?
Zwei davon https://www.kickstarter.com/projects/storaxa/fully-customizable-home-cloud-storage-with-remote-access-nas?lang=de
Mit je 64 GB Memory, aber noch ohne M.2 oder SSD, da nutze ich das Vorhandene aus meiner DS716 + DX510, wenn aber die Preise für M.2 weiter so attraktiv sind, werde ich mir da wohl noch die ein oder andere holen :)VG
Bernd@dp20eic
Hi Bernd,was ich an deinem Beispiel noch nicht verstehe:
import "timezone" option task = {name: "Downsampling Vb_Stromzaehler", cron: "15 0 * * *"} option location = timezone.location(name: "Europe/Berlin") data = from(bucket: "iobroker_strom") |> range(start: -2mo, stop: now()) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh") |> filter(fn: (r) => r["_field"] == "value") // Spalten "_start", "_stop", "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_time") // In Wh ohne Komma |> toInt() |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "iobroker_strom")Der Task läuft ja täglich 00:15 Uhr.
Dann wird von iobroker_strom der Range der letzten 2 Monate in das bucket Stromverbrauch übergeben.
Dort hast du aggregateWindows every 1d (also 1 Tag).Fragen:
-
wenn die Daten der letzten 2 Monate übergeben werden, sind aber dann nicht doppelte Daten im neuen Bucket? (weil sich die Daten der 2 Monate ja ständig überschneiden).
-
wenn der Task nachts um 00:15 Uhr läuft (und du die Daten in Grafana darstellst),
dann fehlen aber doch immer die Daten des Tages vorher in der Grafik von Grafana?
(weil ja erst nachts um 00:15 die aktuellsten Daten übergeben werden (-2mo bis now) -
Das every 1d gilt nur für Aggregate, hat also nichts mit einem Range zu tun?
Danke für deine Hilfe
Grüße
Christoph -
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
216
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge