

Adapter - Parser (regEx)
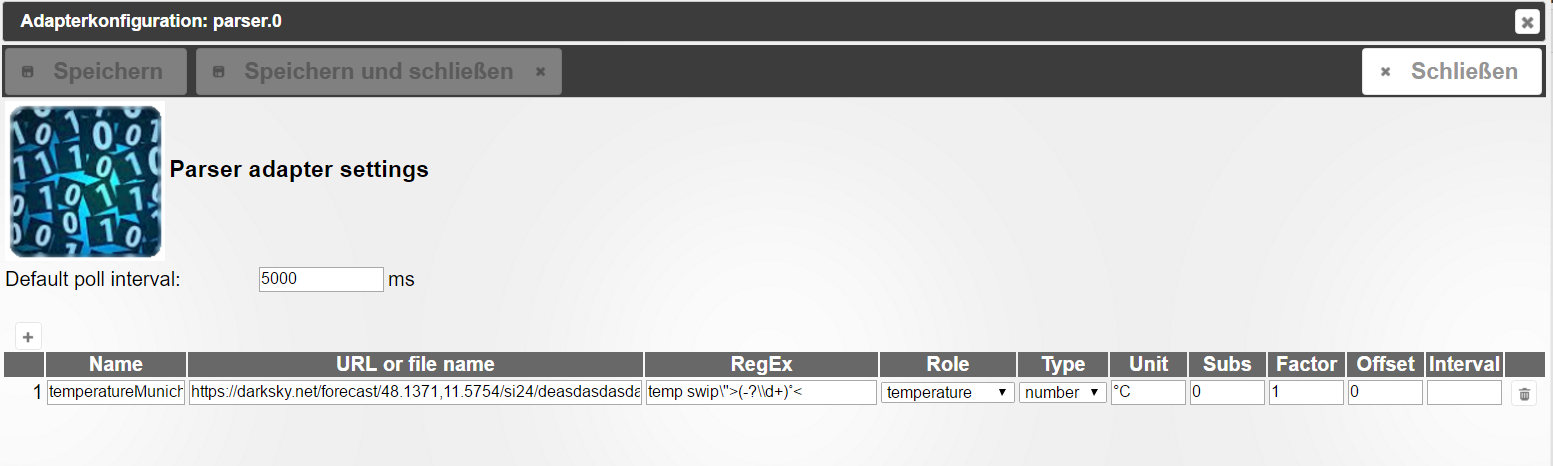
-
Mit Chrome kannst Du Dir mal den "normalen" Weg über die Webseite ansehen.
Über die drei Punkte rechts -> weitere Tools -> Entwicklertools
Und dann dort den Reiter -> Network
Dann auf Deine Anmeldeseite und Du kannst dann nach verfolgen, wie der Ablauf über den Browser ist.
In dem Moment, wo Du auf "anmelden" klickst, müsste auf einer Seite das POST mit der 302 bekommen. Dort sollten die Daten für die Anmeldung (FORM) ersichtlich sein. `
Hallo ruhr70,danke für den Tipp!
Hier eine kurze Zusammenfassung, was ich in der Zwischenzeit gemacht habe.
1.) Gestern hätte ich beinah den passenden Eintrag bei "Chrome->weitere Tools->Entwicklertools->Network" nicht gefunden.
Es heisst bei mir "login" und war am einfachsten unter "Network->Other" zu finden.
2.) Ich habe gesehen, daß im Formular einiges mehr übertragen wird, als ich zuvor eingetragen hatte. Ich war hoffnungsvoll, aber es hat nicht funktioniert.
 Ich beschloß eine Nacht darüber zu schlafen.
Ich beschloß eine Nacht darüber zu schlafen.3.) Heute habe ich mir die Headerinfo näher angeschaut. Ich habe zwei Zeilen von der Debuginfo (die mir erfolgsversprechend erschienen) zu 'User-Agent' und 'Content-Type' hinzugefügt und siehe da: Es tut immer noch nicht.
Eigentlich wollte ich aufgeben, aber wenn man so lange mit etwas herum macht, dann will man eigentlich auch voran kommen. So fügte ich zwei weitere Zeilen von Chrome-Debuginfo und dann hat es (kaum zu glauben) tatsächlich funktioniert und ich bekam das zurück geliefert, was ich haben wollte.4.) Nun ging es darum heraus zu finden, auf welche Zeilen es (in diesem Fall?) wirklich ankam.
Benötigt wird:
a.) Ein "hidden" Formularfeld, das ich bis gestern Abend noch nicht drin hatte.
b.) "followAllRedirects:true," ohne die keine automatische Weiterleitung nach 302 stattfindet.
c.) 'cookie' Zeile aus dem Header in Chrome-Debuginfo.
Das bisher erreichte eine Lösung zu nennen ist wohl etwas verfrüht, weil ich mich vor allem frage ob diese cookie-Infos so ewig drin bleiben können oder alle 30 Tage (oder so) aktualisiert werden müssen.
Das andere Problem ist, wie ich das Ergebnis parsen kann.
@ruhr70: Gibt es in JS (oder node.js) etwas passendes, damit ich in diesem über 300 KB großen String nach irgend etwas suchen kann?
@Bluefox: Gäbe es eine Möglichkeit den selbst abgeholten HTML-String quasi nachträglich in den Parser-Modul zu füttern?
Gruß
Gürol
-
Gibt es in JS (oder node.js) etwas passendes, damit ich in diesem über 300 KB großen String nach irgend etwas suchen kann? `
Du kannst per RegEx im Ergebnis suchen.Ein Online-Tool dafür ist: https://regex101.com/ (dann auf Javascript stellen).
Deinen String kannst Du wahrscheinlich hier nicht posten (oder einen Ausschnitt übere mehrere Zeilen, in dem die gewünschten Daten liegen)?
Prima, wie Du Dich da durchgewühlt hast! Denn Cookie benötigst Du wirklich?
Du meldest Dich ja per Skript per Username/Passwort an.
-
Du kannst per RegEx im Ergebnis suchen.Ein Online-Tool dafür ist: https://regex101.com/ (dann auf Javascript stellen).
…
Prima, wie Du Dich da durchgewühlt hast! Denn Cookie benötigst Du wirklich?
Du meldest Dich ja per Skript per Username/Passwort an. `
Danke, ich habe nicht gewusst, daß man in JavaScript RegEx so einfach (d.h. ohne Zusatzpakete) nutzen kann.
Das müsste ich hinbekommen.
Was die Cookiezeile angeht:
Ja, die Cookiezeile im Header wird wirklich benötigt. (Die Cookiezeile enthielt bei mir 7 Cookiedefinitionen.)
Ich habe inzwischen jedoch rausgefunden, daß man von diesen 7 Cookies nur einen (PHPSESSID) wirklich angeben muß.
Gruß
Gürol
-
Hallo zusammen,
Ich beschäftige mich seit 2-3 Wochen mit ioBroker und versuche grad meine eigene Visualisierung zu erstellen.
Nun bin auf den Tankerkönig Adapter gestoßen, der auch super funktioniert. Allerdings sind für mich eher die Autogas-Preise von Interesse. Also habe ich nach einer Seite gesucht, die mir diese anbietet und bin auch fündig geworden.
Nun meine Frage. Kann ich diese mit dem Parser auslesen?
http://www.clever-tanken.de/tankstelle_details/14452
Gesendet von meinem B3-A30 mit Tapatalk
-
Hallo,
ein neuer Thread wäre durchaus angebracht!
Speziell für diesen Link funktioniert das mit diesen Einstellungen:

(?:Autogas[^]*)(?=[^]* <\/span>Suche zwischen HTML-Code mit Autogas und HTML-Code mit Hochstellung und nimm alle Ziffern und Kommas (Punkte), aber nur 4 davon (zB 0.64)
URL ist````
http://www.clever-tanken.de/tankstelle_details/14452Name ist zB __Autogas 14452__, Rolle ist __eigene__, Typ ist __number__, Einheit ist __€__ Es empfiehlt sich ein Intervall von 5min, also 5*60000 = 300 000 Ergebnis:  Die hochgestellte 9 lasse ich mal einfach weg :-D Gruß Pix EDIT: Regex101-Link zum Prüfen: [https://regex101.com/r/qoUS4j/1](https://regex101.com/r/qoUS4j/1) -
Gibt es auch eine Möglichkeit die hochgestellte letzte Ziffer anzeigen zu lassen? ` Du musst präziser fragen. Meinst du nur die 9 oder ggf. 4 in einen extra Datenpunkt? Oder den Preis als Zahl mit drei Dezimalstellen (zB 0.649 €)?
Sollte eigentlich wirklich langsam in einen eigenen Thread…
Pix
-
Was genau meinst Du?
Siehe Adapter-Doku: Wenn nicht erreichbar kannst Du nen Speziellen Wert definieren und über das "quality-Flag" (sate.q" im JavaScript) kannst du auch rausfinden das der Wert der Fallbackwert ist. Damit kannst Du es prüfen in einem Skript oder so
-
Hallo
ich bekomme im Log folgende Fehlermeldung
parser.0 2017-07-11 12:25:16.784 error Cannot read link "http://xxx.xxx.xxx.xxx/general/informat … ?kind=item": Error: connect ETIMEDOUT xxx.xxx.xxx.xxx:80
und das ganze 16 mal bei 4 Einträgen im Parser Adapter.
Wie bekomme ich das weg wenn die URL nicht erreichbar ist.
-
Ich hab den Parser-Adapter spaßeshalber auch mal ausprobiert.
Wenn man erst einmal die benötigte regEx gefunden hat, dann ist das wirklich ein schöner, weiterer Adapter! :)
Was mir allerdings aufgefallen ist:
Der Adapter ist ein echter Speicherfresser!
Ich habe lediglich eine kleine Abfrage drinnen (siehe Screenshots).
Nach einem Neustart beginnt der Adapter mit einem Speicherbedarf von rund 28MB und schaukelt sich dann recht zügig auf mehr als 60MB hoch.
Wenn man das noch optimieren könnte, dann wäre das sehr hilfreich 8-)
Nachtrag: Version 1.0.0 in /opt/iobroker/node_modules/iobroker.parser, node: v6.11.1
1917_parser__.jpg
1917_parser_2.jpg
1917_parser_3.jpg
1917_parser_4.jpg -
Hallo zusammen,
ich bräuchte bitte bisschen Hilfe beim Parser:
Ich habe mir noch einen zweiten Luftdaten-Sensor gebaut der in der Wohnung verbaut ist. (Kachelofen Überwachung) Dieser soll nicht die Daten an den Luftdaten.info Server senden.
Daher möchte ich die Daten per Parser auslesen (IP-Sensor/values).
Code:
<title>Aktuelle Werte</title> [](/) ### Feinstaubsensor ID: 2221799 MAC: A0:20:A6:21:E6:XX Firmware: NRZ-2017-092 #### Übersicht » Aktuelle Werte | Sensor | Parameter | Wert | | | | SDS011 | PM2.5 | 6.6 µg/m³ | | SDS011 | PM10 | 14.6 µg/m³ | | | | DHT22 | Temperatur | 22.0 °C | | DHT22 | rel. Luftfeuchte | 59.0 % | | | | WiFi | Signal | -62 dBm | | WiFi | Qualität | 76 % | [Zurück zur Startseite](/) [](http://codefor.de/)Laut https://regex101.com/habe ich die Kombinationen gefunden
PM2.5````
(?:PM2[^])(?=[^] class='r'>)([0-9.]{1,9})PM10(?:PM10[^])(?=[^] class='r'>)([0-9.]{1,9})
Temperatur(?:Temper[^])(?=[^] class='r'>)([0-9.]{1,9})
Luftfreuchte(?:rel[^])(?=[^] class='r'>)([0-9.]{1,9})
Hoffe das mir jemand helfen kann. Danke im voraus. Viele Grüße, Fruehwi -
Hallo,
würde für die Partikel mal das probieren https://regex101.com/r/jilwpl/1:
PM2.5
(?:PM2.5<\/td>)(\d+.\d)/gPM10
(?:PM10<\/td>)(\d+.\d)/gTemperatur:
(?:Temperatur<\/td>)(\d+.\d)/gLuftfeuchte:
(?:Luftfeuchte<\/td>)(\d+.\d)/gQualität:
(?:Qualität<\/td>)(\d+)/gGruß
Pix
-
Was mir allerdings aufgefallen ist: Der Adapter ist ein echter Speicherfresser! `
hmmm … was auch immer sich geändert haben mag, ich kann den Vorwurf des Speicherfressens nicht weiter aufrecht halten.Bei mir hat sich der Speicherbedarf nun um die 30 - 32 MB eingependelt.
1917_parser_speicherbedarf.jpg -
Hallo zusammen,
besteht beim parser auch die Möglichkeit eine Website bei der credentials zum einloggen notwendig sind auszulesen?
bei mir geht es um das Webinterface meines Wechselrichters.
Teile laufen davon noch über bash-script mit einem wget-Aufruf:
wget $COMMONWGETARGS --http-user=UserName --http-password=PassWort "http://192.168.xxx.yyy/index.fhtml" | sed -e "s/nbsp/nbsp;/g" | sed -e "s/nbsp;;/nbsp;/g" | sed -e "s/\ //g" | html2text | tr -s " \t\r\n" | sed -e "s/^ //" | sed -e "s/x x x/0/g" >/tmp/power-inverter1.valuesKeine Angst, das habe ich nicht ersonnen, sondern "ausgeliehen".
Gruß
Rainer
-
Habe es mittlerweile anscheinend hinbekommen, zumindest lief es auf einmal mit http://UserName:PassWort@IP.
Dann hatte ich sogar das regex (teilweise) mit viel try and noch mehr Error hinbekommen.
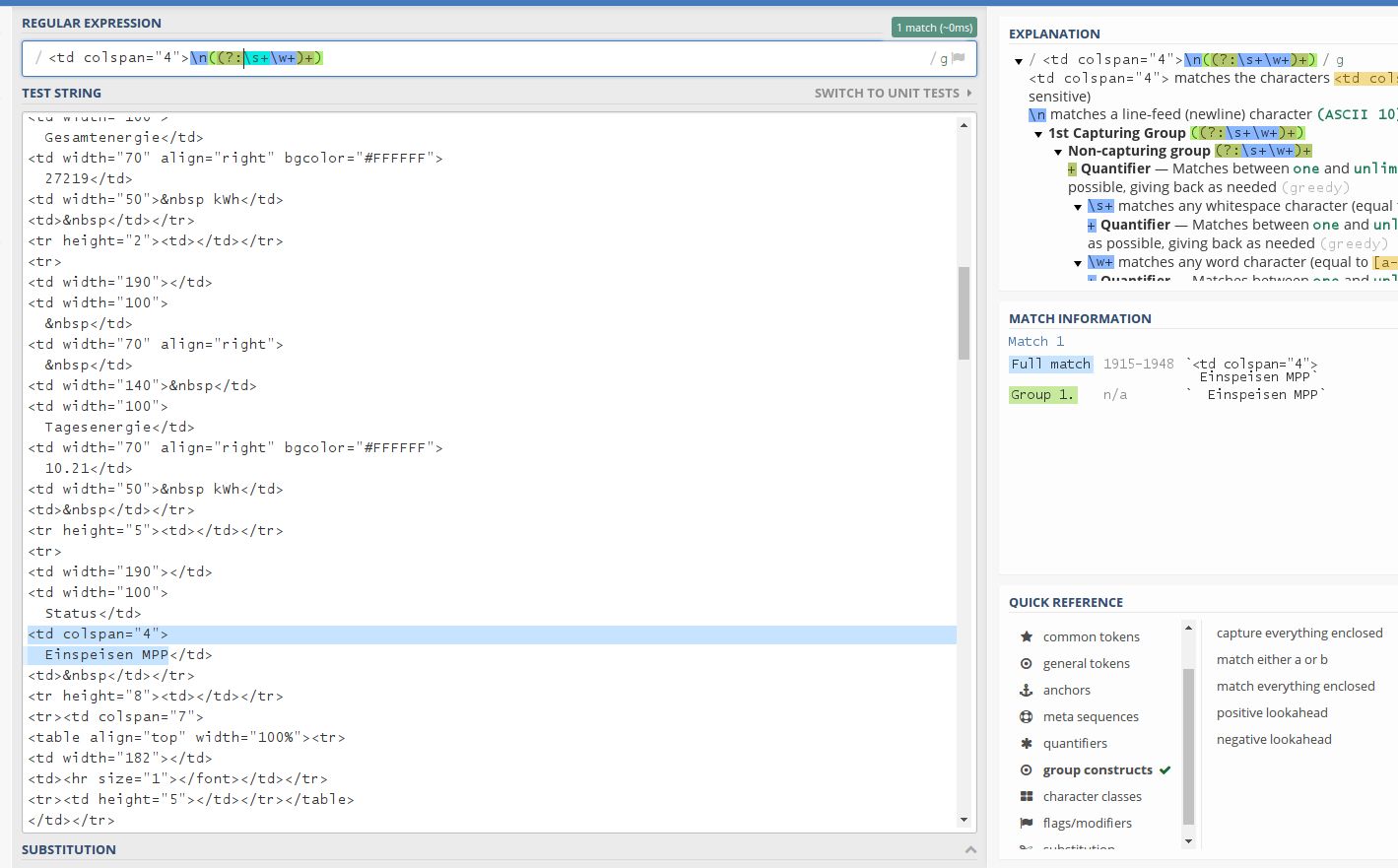
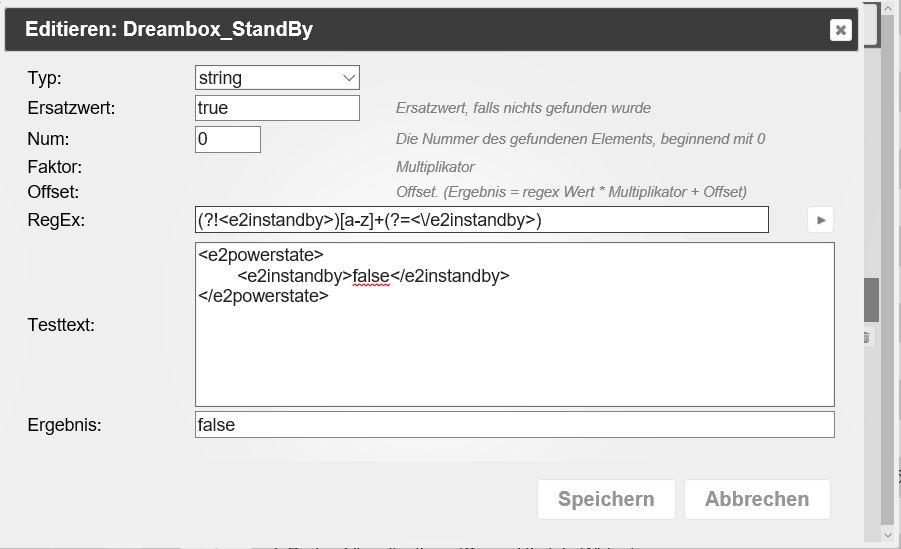
Dabei kam dann nur "Einspeisen" heraus. Das war mir erst einmal egal, bis mir der Gedanke kam, dass ja wer weiß was für Meldungen kommen könnten, die ggf. auch aus noch mehr Worten bestehen könnten. Also habe ich den Regex geändert. Seit dem kommt gar nichts mehr so richtig.Im Objekt steht immer nur null

Ob das jetzt am RegEx liegt oder wo anders dran weiß ich nicht wirklich. Auch der Versuch das ursprüngliche RegEx zu nehmen führt jetzt zu dem Fehler. Der Timestamp ändert sich auch bei einem Restart nicht mehr.
Und so sieht es in der Adapterkonfig aus:
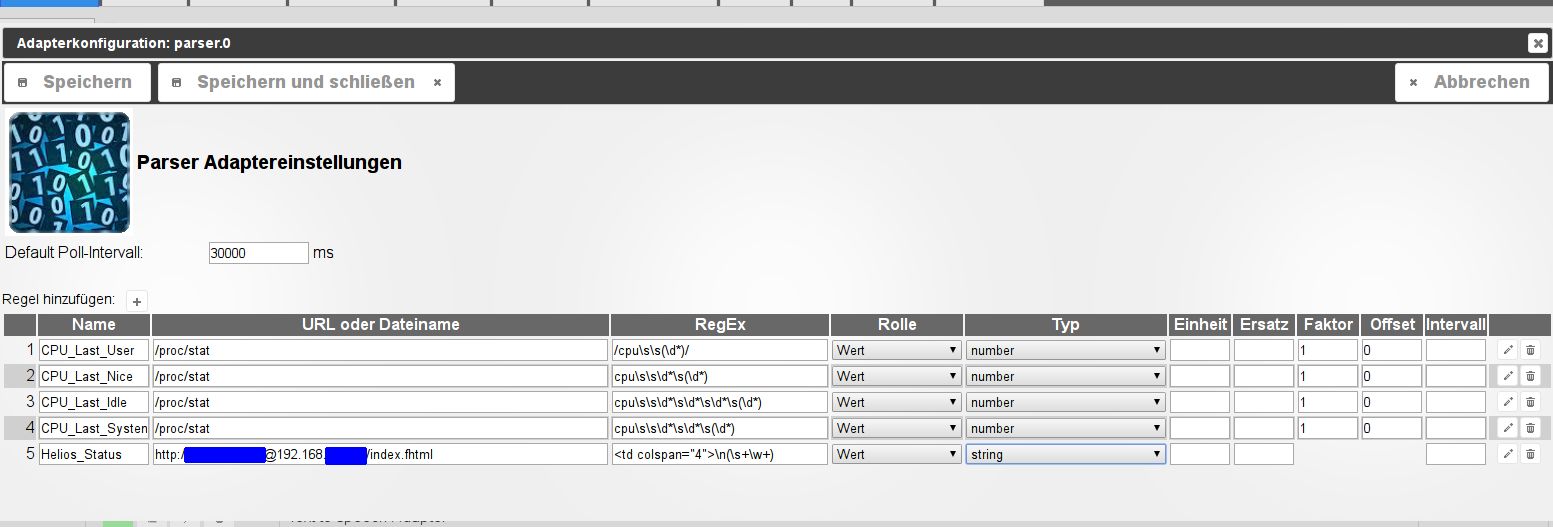
Hülfää büdde!
Gruß
Rainer
-
Auch das habe ich jetzt hinbekommen, ich musste noch das \n aus dem RegEx nehmen (fiel mir beim x-ten drübersehen auf, dass das zu Anfang auch nicht drin war)
Gruß
Rainer
-
Leider muss ich mich nochmal melden.
Mit der ganzen Aktion wollte ich den Status meines Wechselrichters loggen, weil es anscheinend zu Störungen kam. Dies war heute morgen wieder der Fall, da stand dann in dem Datenpunkt nur "St" :shock:
In der WebUI stand dann wo hier Einspeisen MPP steht Störung Isolationsfehler.
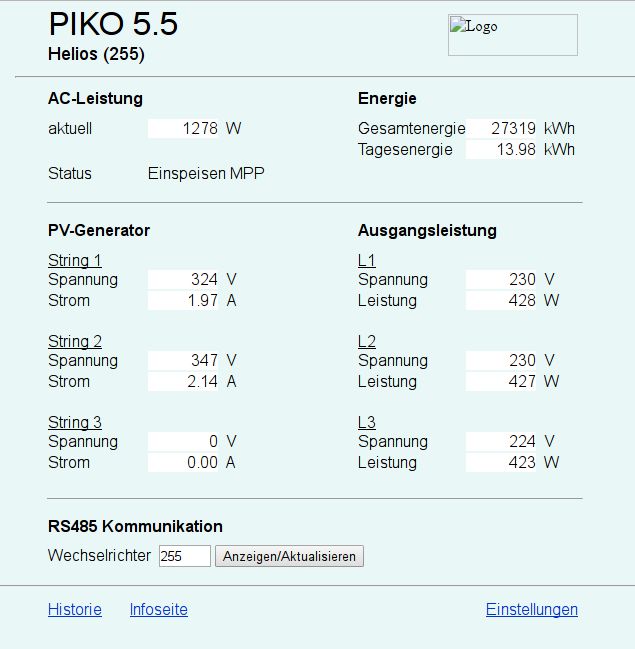
Dies wollte ich loggen.
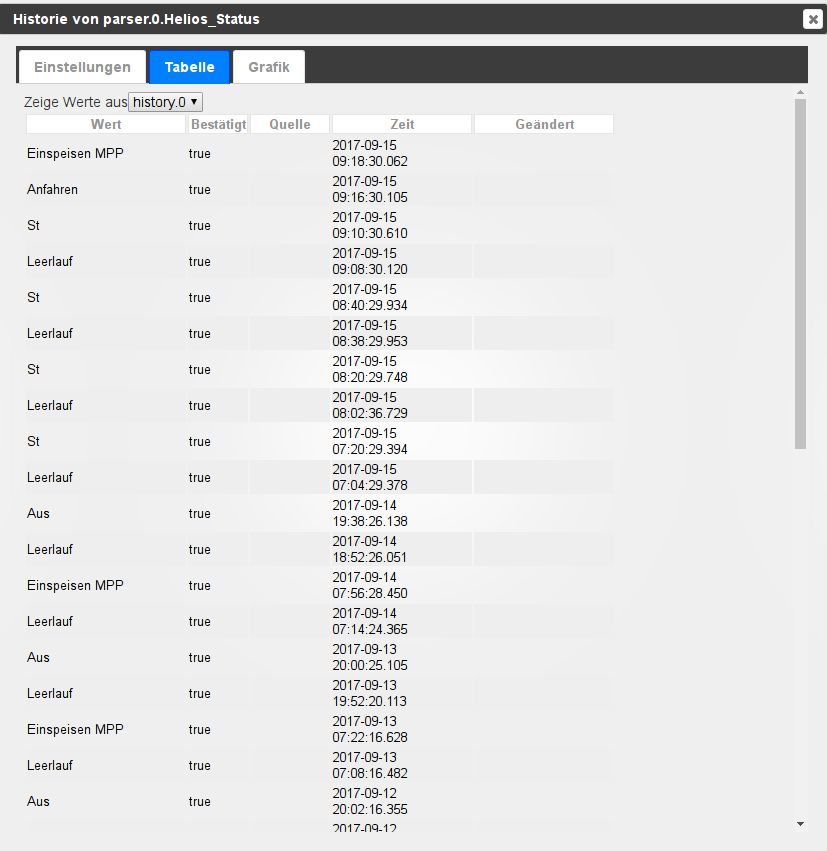
Aber auch dort steht nur "St" und sonst nichts.Ich nehme an, dass der Umlaut ö das Problem erzeugt.
Leider habe ich von dem Zeitpunkt keinen Seitenquelltext, sondern nur von gerade eben:
! ````
! <title>PV Webserver</title>
! <form method="post" action="">
! | |
! | |PIKO 5.5
! Helios (255)
|
 |
|
! |! * * *
! |
! | |
! |AC-Leistung |
|Energie |
! | |
! |aktuell |
1278 |
W |Gesamtenergie |
27319 |
kWh |
|! | |
! ||
|
|Tagesenergie |
13.98 |
kWh |
|! | |
! |Status |
Einspeisen MPP |
|! | |
! |
! |! * * *
! |
! | |
! |
! |PV-Generator |
|Ausgangsleistung |
|
|! | |
! |<u>String 1</u> |
|
|<u>L1</u> |
|
|
|! |
Spannung |
324 |
V |Spannung |
230 |
V |
|! | |
! |Strom |
1.97 |
A |Leistung |
428 |
W |
|! | |
! |<u>String 2</u> |
|
|<u>L2</u> |
|
|
|! |
Spannung |
347 |
V |Spannung |
230 |
V |
|! | |
! |Strom |
2.14 |
A |Leistung |
427 |
W |
|! | |
! |<u>String 3</u> |
|
|<u>L3</u> |
|
|
|! |
Spannung |
0 |
V |
Spannung |
224 |
V |
|! | |
! |Strom |
0.00 |
A |
Leistung |
423 |
W |
|! | |
! |
! | |! * * *
! |
! | |
! |
! | |
RS485 Kommunikation |
! | |
! | |
Wechselrichter |
| |
! * * *
! | |
! | |Einstellungen ! </form>
! ````im Parser Adapter lese ich den Status aus mit
((?:\s+\w+)+)Das klappte mit den Standard zuständen beim online regex-tester problemlos.
EDIT: Habe gerade bei regex101.com manuell "Einspeiden MPP" gegen "Störung Isolationsfehler" ausgetauscht, da ergibt der RegEx auch nur "St"
Kann mir da bitte noch einmal jemand unter die Arme greifen?
EDIT2: Nach einigem googeln klappt es jetzt hoffentlich mit
(?:\s+([a-zA-Z äöüÄÖÜ]+))Gruß
Rainer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
379
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge