

Test Adapter VW Connect für VW, ID, Audi, Seat, Skoda
-
@opossum - Ich hab die View nun eingebunden, mein VW zeigt die Temperatur wohl in Fahrenheit an. Ist das bei Dir auch so. Hast Du eventuell einen Tipp wie man das umrechnen und anzeigen kann? Bei manchen Anzeigen passt auch das Datum nicht, die Werte stimmen ab schon in der Instanz nicht. Ich komme gerad da aber auf keinen grünen Zweig.
Hallo,
ich fahre seit kurzem dem Mii electric, besteht die Aussicht auch diesen in dem Adapter irgendwann einmal zu sehen? Ich kann gerne behilflich sein oder auch einen Gastzugang generieren um den Entwicklern daten zu geben.
Mit welcher Genauigkeit könnt ihr den SOC ablesen? In der App von Seat geht es momentan nur mit 10% Schritten, für die Steuerung der Wallbox teilweise etwas ungenau. -
@aba320
Bitte Textausgaben nicht nur in Spoiler packen sondern (wichtiger) auch in CodeTags </>.@Thomas-Braun Hallo ich hoffe so ist es richtig
PS der Zeitpunkt des Öwechsels wird auch in der Skoda App nicht angezeigt. ist also Kein Problem des Adapters
Gruß Achim -
@tombox
Ich habe seit kurzem einen ID.3.
Hierzu gibt es ja auch eine separate App.
Und prompt findet der Adapter keine Daten.Hier die Fehlermeldung:
vw-connect.0 2020-10-13 13:47:04.800 error (30393) Get Vehicles Failed
vw-connect.0 2020-10-13 13:47:04.799 error (30393) Not able to find vehicle, did you choose the correct type?.
vw-connect.0 2020-10-13 13:47:04.798 error at Gunzip.emit (events.js:326:22)
vw-connect.0 2020-10-13 13:47:04.798 error at Object.onceWrapper (events.js:420:28)
vw-connect.0 2020-10-13 13:47:04.798 error at Gunzip.<anonymous> (/opt/iobroker/node_modules/request/request.js:1083:12)
vw-connect.0 2020-10-13 13:47:04.798 error at Request.EventEmitter.emit (domain.js:483:12)
vw-connect.0 2020-10-13 13:47:04.798 error at Request.emit (events.js:314:20)
vw-connect.0 2020-10-13 13:47:04.798 error at Request.<anonymous> (/opt/iobroker/node_modules/request/request.js:1161:10)
vw-connect.0 2020-10-13 13:47:04.798 error at Request.EventEmitter.emit (domain.js:483:12)
vw-connect.0 2020-10-13 13:47:04.798 error at Request.emit (events.js:314:20)
vw-connect.0 2020-10-13 13:47:04.798 error at Request.self.callback (/opt/iobroker/node_modules/request/request.js:185:22)
vw-connect.0 2020-10-13 13:47:04.798 error at Request._callback (/opt/iobroker/node_modules/iobroker.vw-connect/main.js:959:60)
vw-connect.0 2020-10-13 13:47:04.798 error (30393) TypeError: Cannot read property 'vehicle' of null
vw-connect.0 2020-10-13 13:47:04.792 error (30393) TypeError: Cannot read property 'vehicle' of nullHallo euch zweien,
erstmal Tombox: DANKE für die Arbeit!
Auch ich habe den ID 3 seit kurzem, gibt es hier vielleicht eine Anpassung des Adapters?
Der bisherige "We Connect" Adapter spricht leider nicht mit dem ID, so dass ich hier die Daten nicht auslesen kann (VW-Konto liegt vor; Fahrzeug ist angelegt).
Für mich spannend wäre
auslesen des Ladestandes
starten der Ladung (Wallbox vorhanden)
Starten der Klimatisierung morgens (etwa: Licht im Bad geht an zum Zähneputzen, bedeutet 10 min später fahre ich los --> Klimatisierung anGibt es zusätzlich noch eine Steuerung für die Wallbox "ID Charger Pro?"
-
Hallo euch zweien,
erstmal Tombox: DANKE für die Arbeit!
Auch ich habe den ID 3 seit kurzem, gibt es hier vielleicht eine Anpassung des Adapters?
Der bisherige "We Connect" Adapter spricht leider nicht mit dem ID, so dass ich hier die Daten nicht auslesen kann (VW-Konto liegt vor; Fahrzeug ist angelegt).
Für mich spannend wäre
auslesen des Ladestandes
starten der Ladung (Wallbox vorhanden)
Starten der Klimatisierung morgens (etwa: Licht im Bad geht an zum Zähneputzen, bedeutet 10 min später fahre ich los --> Klimatisierung anGibt es zusätzlich noch eine Steuerung für die Wallbox "ID Charger Pro?"
-
@FrankDCE @tombox
Dem ID.3-Wunsch schließe ich mich auch an. In gut einem Monat werde ich das gleiche "Problem" haben, dass mein ID.3 dann nicht auslesbar ist. -
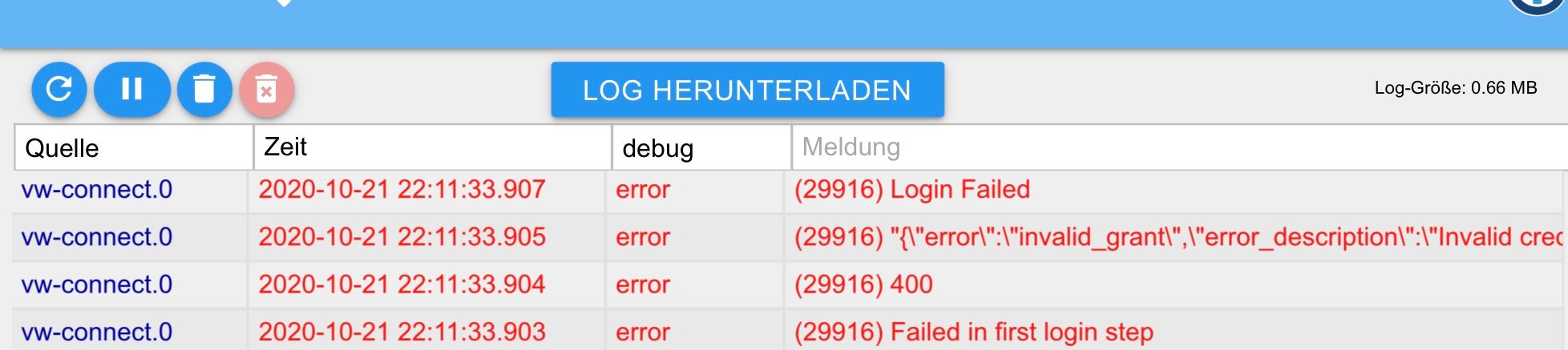
Gibt es was neues bzgl. der Audi-Anmeldung?
Bekomme folgende Fehlermeldung:
-
Gibt es was neues bzgl. der Audi-Anmeldung?
Bekomme folgende Fehlermeldung:
@Sebastian-0 Hallo zusammen, ja es gibt was Neues. Der Login Workflow hat sich geändert. Die Übergabe von Nutzer und Kennwort reicht per Oberfläche, intern im Code müssen aber Abläufe geändert werden.
Jetzt neu muss:- über einen Browser Request eine Login Seite aufgerufen werden, welcher die Anmeldedaten in 2 Schritten zu übergeben sind, erst der Nutzer und per weiterem Request das Kennwort. Daraufhin erhält man einen Code-Token.
- der Code-Token muss an die erste Access-Token Url per POST übergeben werden um einen AZS-Token abzurufen.
- danach muss über eine weitere Url die ClientId abgerufen werden
- als letzten Login Step muss mit dem AZS-Access-Token und der ClientId der MBB-Token per POST abgerufen werden, mit dem man Zugriff auf die Fahrzeugdaten hat.
Wichtig ist noch, dass die 4 Login Steps mit einer HttpClient Session erfolgen müssen.
Alle weiteren Fahrzeugdatenabrufe funktionieren wie bisher mit dem MBB-Token.
Details zum Ablauf: https://github.com/davidgiga1993/AudiAPI/issues/13
-
@Sebastian-0 Hallo zusammen, ja es gibt was Neues. Der Login Workflow hat sich geändert. Die Übergabe von Nutzer und Kennwort reicht per Oberfläche, intern im Code müssen aber Abläufe geändert werden.
Jetzt neu muss:- über einen Browser Request eine Login Seite aufgerufen werden, welcher die Anmeldedaten in 2 Schritten zu übergeben sind, erst der Nutzer und per weiterem Request das Kennwort. Daraufhin erhält man einen Code-Token.
- der Code-Token muss an die erste Access-Token Url per POST übergeben werden um einen AZS-Token abzurufen.
- danach muss über eine weitere Url die ClientId abgerufen werden
- als letzten Login Step muss mit dem AZS-Access-Token und der ClientId der MBB-Token per POST abgerufen werden, mit dem man Zugriff auf die Fahrzeugdaten hat.
Wichtig ist noch, dass die 4 Login Steps mit einer HttpClient Session erfolgen müssen.
Alle weiteren Fahrzeugdatenabrufe funktionieren wie bisher mit dem MBB-Token.
Details zum Ablauf: https://github.com/davidgiga1993/AudiAPI/issues/13
-
@NafIdua Wurde der Login Flow nur bei Audi und VW geändert? Ich kann beim Skoda immer noch den Adapter verwenden?!
-
@Sebastian-0 Hallo zusammen, ja es gibt was Neues. Der Login Workflow hat sich geändert. Die Übergabe von Nutzer und Kennwort reicht per Oberfläche, intern im Code müssen aber Abläufe geändert werden.
Jetzt neu muss:- über einen Browser Request eine Login Seite aufgerufen werden, welcher die Anmeldedaten in 2 Schritten zu übergeben sind, erst der Nutzer und per weiterem Request das Kennwort. Daraufhin erhält man einen Code-Token.
- der Code-Token muss an die erste Access-Token Url per POST übergeben werden um einen AZS-Token abzurufen.
- danach muss über eine weitere Url die ClientId abgerufen werden
- als letzten Login Step muss mit dem AZS-Access-Token und der ClientId der MBB-Token per POST abgerufen werden, mit dem man Zugriff auf die Fahrzeugdaten hat.
Wichtig ist noch, dass die 4 Login Steps mit einer HttpClient Session erfolgen müssen.
Alle weiteren Fahrzeugdatenabrufe funktionieren wie bisher mit dem MBB-Token.
Details zum Ablauf: https://github.com/davidgiga1993/AudiAPI/issues/13
@NafIdua Hast du das hiermit geschafft? Ich bin anscheinend zu blind den genauen Vorgang zu finden :-D
-
Hallo euch zweien,
erstmal Tombox: DANKE für die Arbeit!
Auch ich habe den ID 3 seit kurzem, gibt es hier vielleicht eine Anpassung des Adapters?
Der bisherige "We Connect" Adapter spricht leider nicht mit dem ID, so dass ich hier die Daten nicht auslesen kann (VW-Konto liegt vor; Fahrzeug ist angelegt).
Für mich spannend wäre
auslesen des Ladestandes
starten der Ladung (Wallbox vorhanden)
Starten der Klimatisierung morgens (etwa: Licht im Bad geht an zum Zähneputzen, bedeutet 10 min später fahre ich los --> Klimatisierung anGibt es zusätzlich noch eine Steuerung für die Wallbox "ID Charger Pro?"
-
@tombox scheint wohl gerade nicht verfügbar zu sein. Daher dachte ich mir, ich erstelle mal einen Fork seines Adapters und schaue mir die States unter "status" mal genauer an. Mein Wunsch ist ja, dass die Werte nicht einfach durchnummeriert werden, weil sich durch Hinzukommen oder Wegfallen von Informationen seitens des We Connect-Systems schnell Verschiebungen ergeben können.
Jetzt habe ich mir mal das JSON genauer angesehen, das von VW kommt und aus dem die Daten in den States erstellt werden:Es zeigt sich, dass der Aufbau auf den ersten Blick klar strukturiert wirkt, auf den zweiten aber ein paar Besonderheiten entstehen:
- Die ersten Stellen der ID (z.B. "id":"0x0101010001" => 0x0101 bzw. 0101) stellen die 1. Ebene der Gruppierung dar, die letzten 6 Stellen die Unter-id des Feldes.
- Ab und an (bei den ersten beiden Gruppen) sind die ersten signifikanten Stellen nicht unterschiedlich (beide male 0101), sonst aber eher eindeutig.
- Die letzten 6 Stellen der Gruppe sind entweder FFFFFF oder identisch mit den Werten der darunterliegenden Felder
- Es gibt innerhalb der Gruppe auch mal zwei Einträge mit der gleichen ID. Diese enthalten dan aber identische (leere) Daten
Ein mögliches vorgehen wäre:
Die bisherigen Gruppierung "data" spielt keine wirkliche Rolle, es werden nur alle Werte darunter "field" ausgewertet. Die dortige id wird zerlegt in die ersten 4 und letzten 6 Stellen (0x zu Beginn wird ignoriert). Dann landen die Werte z.B. bei id = 0x0101010001 nicht mehr unter status.data01.field01 sondern unter status.data0101.field010001. Alternativ kann man auch beide id auswerten und die Statenamen länger ausfallen lassen: status.data0x0101010001.field0x0101010001 oder status.data0x0203FFFFFF.field0x0203010001
Doppelte Werte würden nur zu einem überschrieben des vorherigen Wertes führen (da sie identisch sind hat es keine Auswirkungen).
Damit wäre es möglich, Werte ganz gezielt auszulesen (z.B. status.data0x030101FFFF.0x0301010001 für die Lichter) ohne der Gefahr ausgesetzt zu sein, dass bei einer veränderten Informationsbereitstellung die Daten in einem anderen State suchen zu müssen. Besonders ungeschickt wäre es, wenn die Werte über SQL.0 oder History.0 aufgezeichnet werden sollen. Denn dann muss man mal hier und mal da aufzeichnen. Damit wären die Daten nur sehr bedingt auswertbar...
Was meint Ihr? Wäre eine Speicherung nur unter Berücksichtigng der 2. id mit kurzen state-Namen wie status.data0101.field010001 oder mit Berücksichtigung beider ids wie status.data0x0203FFFFFF.field0x0203010001 besser? -
@tombox scheint wohl gerade nicht verfügbar zu sein. Daher dachte ich mir, ich erstelle mal einen Fork seines Adapters und schaue mir die States unter "status" mal genauer an. Mein Wunsch ist ja, dass die Werte nicht einfach durchnummeriert werden, weil sich durch Hinzukommen oder Wegfallen von Informationen seitens des We Connect-Systems schnell Verschiebungen ergeben können.
Jetzt habe ich mir mal das JSON genauer angesehen, das von VW kommt und aus dem die Daten in den States erstellt werden:Es zeigt sich, dass der Aufbau auf den ersten Blick klar strukturiert wirkt, auf den zweiten aber ein paar Besonderheiten entstehen:
- Die ersten Stellen der ID (z.B. "id":"0x0101010001" => 0x0101 bzw. 0101) stellen die 1. Ebene der Gruppierung dar, die letzten 6 Stellen die Unter-id des Feldes.
- Ab und an (bei den ersten beiden Gruppen) sind die ersten signifikanten Stellen nicht unterschiedlich (beide male 0101), sonst aber eher eindeutig.
- Die letzten 6 Stellen der Gruppe sind entweder FFFFFF oder identisch mit den Werten der darunterliegenden Felder
- Es gibt innerhalb der Gruppe auch mal zwei Einträge mit der gleichen ID. Diese enthalten dan aber identische (leere) Daten
Ein mögliches vorgehen wäre:
Die bisherigen Gruppierung "data" spielt keine wirkliche Rolle, es werden nur alle Werte darunter "field" ausgewertet. Die dortige id wird zerlegt in die ersten 4 und letzten 6 Stellen (0x zu Beginn wird ignoriert). Dann landen die Werte z.B. bei id = 0x0101010001 nicht mehr unter status.data01.field01 sondern unter status.data0101.field010001. Alternativ kann man auch beide id auswerten und die Statenamen länger ausfallen lassen: status.data0x0101010001.field0x0101010001 oder status.data0x0203FFFFFF.field0x0203010001
Doppelte Werte würden nur zu einem überschrieben des vorherigen Wertes führen (da sie identisch sind hat es keine Auswirkungen).
Damit wäre es möglich, Werte ganz gezielt auszulesen (z.B. status.data0x030101FFFF.0x0301010001 für die Lichter) ohne der Gefahr ausgesetzt zu sein, dass bei einer veränderten Informationsbereitstellung die Daten in einem anderen State suchen zu müssen. Besonders ungeschickt wäre es, wenn die Werte über SQL.0 oder History.0 aufgezeichnet werden sollen. Denn dann muss man mal hier und mal da aufzeichnen. Damit wären die Daten nur sehr bedingt auswertbar...
Was meint Ihr? Wäre eine Speicherung nur unter Berücksichtigng der 2. id mit kurzen state-Namen wie status.data0101.field010001 oder mit Berücksichtigung beider ids wie status.data0x0203FFFFFF.field0x0203010001 besser? -
@tombox scheint wohl gerade nicht verfügbar zu sein. Daher dachte ich mir, ich erstelle mal einen Fork seines Adapters und schaue mir die States unter "status" mal genauer an. Mein Wunsch ist ja, dass die Werte nicht einfach durchnummeriert werden, weil sich durch Hinzukommen oder Wegfallen von Informationen seitens des We Connect-Systems schnell Verschiebungen ergeben können.
Jetzt habe ich mir mal das JSON genauer angesehen, das von VW kommt und aus dem die Daten in den States erstellt werden:Es zeigt sich, dass der Aufbau auf den ersten Blick klar strukturiert wirkt, auf den zweiten aber ein paar Besonderheiten entstehen:
- Die ersten Stellen der ID (z.B. "id":"0x0101010001" => 0x0101 bzw. 0101) stellen die 1. Ebene der Gruppierung dar, die letzten 6 Stellen die Unter-id des Feldes.
- Ab und an (bei den ersten beiden Gruppen) sind die ersten signifikanten Stellen nicht unterschiedlich (beide male 0101), sonst aber eher eindeutig.
- Die letzten 6 Stellen der Gruppe sind entweder FFFFFF oder identisch mit den Werten der darunterliegenden Felder
- Es gibt innerhalb der Gruppe auch mal zwei Einträge mit der gleichen ID. Diese enthalten dan aber identische (leere) Daten
Ein mögliches vorgehen wäre:
Die bisherigen Gruppierung "data" spielt keine wirkliche Rolle, es werden nur alle Werte darunter "field" ausgewertet. Die dortige id wird zerlegt in die ersten 4 und letzten 6 Stellen (0x zu Beginn wird ignoriert). Dann landen die Werte z.B. bei id = 0x0101010001 nicht mehr unter status.data01.field01 sondern unter status.data0101.field010001. Alternativ kann man auch beide id auswerten und die Statenamen länger ausfallen lassen: status.data0x0101010001.field0x0101010001 oder status.data0x0203FFFFFF.field0x0203010001
Doppelte Werte würden nur zu einem überschrieben des vorherigen Wertes führen (da sie identisch sind hat es keine Auswirkungen).
Damit wäre es möglich, Werte ganz gezielt auszulesen (z.B. status.data0x030101FFFF.0x0301010001 für die Lichter) ohne der Gefahr ausgesetzt zu sein, dass bei einer veränderten Informationsbereitstellung die Daten in einem anderen State suchen zu müssen. Besonders ungeschickt wäre es, wenn die Werte über SQL.0 oder History.0 aufgezeichnet werden sollen. Denn dann muss man mal hier und mal da aufzeichnen. Damit wären die Daten nur sehr bedingt auswertbar...
Was meint Ihr? Wäre eine Speicherung nur unter Berücksichtigng der 2. id mit kurzen state-Namen wie status.data0101.field010001 oder mit Berücksichtigung beider ids wie status.data0x0203FFFFFF.field0x0203010001 besser? -
@tombox scheint wohl gerade nicht verfügbar zu sein. Daher dachte ich mir, ich erstelle mal einen Fork seines Adapters und schaue mir die States unter "status" mal genauer an. Mein Wunsch ist ja, dass die Werte nicht einfach durchnummeriert werden, weil sich durch Hinzukommen oder Wegfallen von Informationen seitens des We Connect-Systems schnell Verschiebungen ergeben können.
Jetzt habe ich mir mal das JSON genauer angesehen, das von VW kommt und aus dem die Daten in den States erstellt werden:Es zeigt sich, dass der Aufbau auf den ersten Blick klar strukturiert wirkt, auf den zweiten aber ein paar Besonderheiten entstehen:
- Die ersten Stellen der ID (z.B. "id":"0x0101010001" => 0x0101 bzw. 0101) stellen die 1. Ebene der Gruppierung dar, die letzten 6 Stellen die Unter-id des Feldes.
- Ab und an (bei den ersten beiden Gruppen) sind die ersten signifikanten Stellen nicht unterschiedlich (beide male 0101), sonst aber eher eindeutig.
- Die letzten 6 Stellen der Gruppe sind entweder FFFFFF oder identisch mit den Werten der darunterliegenden Felder
- Es gibt innerhalb der Gruppe auch mal zwei Einträge mit der gleichen ID. Diese enthalten dan aber identische (leere) Daten
Ein mögliches vorgehen wäre:
Die bisherigen Gruppierung "data" spielt keine wirkliche Rolle, es werden nur alle Werte darunter "field" ausgewertet. Die dortige id wird zerlegt in die ersten 4 und letzten 6 Stellen (0x zu Beginn wird ignoriert). Dann landen die Werte z.B. bei id = 0x0101010001 nicht mehr unter status.data01.field01 sondern unter status.data0101.field010001. Alternativ kann man auch beide id auswerten und die Statenamen länger ausfallen lassen: status.data0x0101010001.field0x0101010001 oder status.data0x0203FFFFFF.field0x0203010001
Doppelte Werte würden nur zu einem überschrieben des vorherigen Wertes führen (da sie identisch sind hat es keine Auswirkungen).
Damit wäre es möglich, Werte ganz gezielt auszulesen (z.B. status.data0x030101FFFF.0x0301010001 für die Lichter) ohne der Gefahr ausgesetzt zu sein, dass bei einer veränderten Informationsbereitstellung die Daten in einem anderen State suchen zu müssen. Besonders ungeschickt wäre es, wenn die Werte über SQL.0 oder History.0 aufgezeichnet werden sollen. Denn dann muss man mal hier und mal da aufzeichnen. Damit wären die Daten nur sehr bedingt auswertbar...
Was meint Ihr? Wäre eine Speicherung nur unter Berücksichtigng der 2. id mit kurzen state-Namen wie status.data0101.field010001 oder mit Berücksichtigung beider ids wie status.data0x0203FFFFFF.field0x0203010001 besser? -
@Sneak-L8 ja da stimme ich zu. ich glaube auch das man die längere Version nutzen sollte, da die Datenstruktur nach meiner Meinung übersichtlicher ist.
@aba320 @jhg @pfried Danke für Eure Rückmeldungen. Ich habe mir das Coding nun mal angesehen und glaube zu wissen, wo ich ansetzen muss. Werde das zunächst mal in einem separaten Branch machen, dann kann man zunächst ungestört den aktuellen Adapter weiternutzen und bei Bedarf auf die neue Version umswitchen. Wenn dann alles passt, merge ich den Branch in den Master.
Bevor ich jetzt anfange hat sich für mich eine weitere Frage ergeben:
Die tripDatas werden derzeit auch einfach durchnummeriert eingetragen. Dabei werden diese von VW "unsortiert" ausgegeben:Das führt dazu, dass diese zwar als state tripdata<nn> durchnummeriert werden, aber nicht immer chronologisch sortiert sind (sieht man auch gut im Beispiel). Hinzu kommt, dass die Nummerierung nur zweistellig mit Null aufgefüllt wird, so dass nach 10 erstmal 100, 101, ... kommt und dann 11, 110, 111, 112, ... Ich kann jetzt die Nummerierung natürlich dreistellig machen, aber so ganz glücklich bin ich damit nicht.
Ich könnte auch hergehen und die tripID nehmen (analog der id beim Status). Dann wären sie schön chronologisch sortiert. Das führt zum schönen Umstand, dass alle trips des Fahrzeugs immer im ioBroker erhalten bleiben, weil keine trips mehr überschrieben würden, aber auch zu dem unschönen Zustand, dass es immer mehr states im iobroker gibt und dieser ein stückweit "vermüllt" wird. Keine Ahnung, ab wievielen States es da zu Problemen kommt.
Mir fallen jetzt verschiedene Optionen für die tripdata ein:- alles wie bisher, nur die lfd. Nummer dreistellig machen
- alle tripdata mit trapID schreiben, ggfs. eine Löschfunktion für alle Trips vorsehen (Zeitraum z.B. über Konfig einstellbar)
- tripdata auswerten und nur die neusten x (z.B. 10) Trips sortiert unter tripdata 01-10 ablegen.
- eine Kombination aus 2. und 3. mit getrennten Rubriken
Was meint Ihr?
-
@aba320 @jhg @pfried Danke für Eure Rückmeldungen. Ich habe mir das Coding nun mal angesehen und glaube zu wissen, wo ich ansetzen muss. Werde das zunächst mal in einem separaten Branch machen, dann kann man zunächst ungestört den aktuellen Adapter weiternutzen und bei Bedarf auf die neue Version umswitchen. Wenn dann alles passt, merge ich den Branch in den Master.
Bevor ich jetzt anfange hat sich für mich eine weitere Frage ergeben:
Die tripDatas werden derzeit auch einfach durchnummeriert eingetragen. Dabei werden diese von VW "unsortiert" ausgegeben:Das führt dazu, dass diese zwar als state tripdata<nn> durchnummeriert werden, aber nicht immer chronologisch sortiert sind (sieht man auch gut im Beispiel). Hinzu kommt, dass die Nummerierung nur zweistellig mit Null aufgefüllt wird, so dass nach 10 erstmal 100, 101, ... kommt und dann 11, 110, 111, 112, ... Ich kann jetzt die Nummerierung natürlich dreistellig machen, aber so ganz glücklich bin ich damit nicht.
Ich könnte auch hergehen und die tripID nehmen (analog der id beim Status). Dann wären sie schön chronologisch sortiert. Das führt zum schönen Umstand, dass alle trips des Fahrzeugs immer im ioBroker erhalten bleiben, weil keine trips mehr überschrieben würden, aber auch zu dem unschönen Zustand, dass es immer mehr states im iobroker gibt und dieser ein stückweit "vermüllt" wird. Keine Ahnung, ab wievielen States es da zu Problemen kommt.
Mir fallen jetzt verschiedene Optionen für die tripdata ein:- alles wie bisher, nur die lfd. Nummer dreistellig machen
- alle tripdata mit trapID schreiben, ggfs. eine Löschfunktion für alle Trips vorsehen (Zeitraum z.B. über Konfig einstellbar)
- tripdata auswerten und nur die neusten x (z.B. 10) Trips sortiert unter tripdata 01-10 ablegen.
- eine Kombination aus 2. und 3. mit getrennten Rubriken
Was meint Ihr?
-
@aba320 @jhg @pfried Danke für Eure Rückmeldungen. Ich habe mir das Coding nun mal angesehen und glaube zu wissen, wo ich ansetzen muss. Werde das zunächst mal in einem separaten Branch machen, dann kann man zunächst ungestört den aktuellen Adapter weiternutzen und bei Bedarf auf die neue Version umswitchen. Wenn dann alles passt, merge ich den Branch in den Master.
Bevor ich jetzt anfange hat sich für mich eine weitere Frage ergeben:
Die tripDatas werden derzeit auch einfach durchnummeriert eingetragen. Dabei werden diese von VW "unsortiert" ausgegeben:Das führt dazu, dass diese zwar als state tripdata<nn> durchnummeriert werden, aber nicht immer chronologisch sortiert sind (sieht man auch gut im Beispiel). Hinzu kommt, dass die Nummerierung nur zweistellig mit Null aufgefüllt wird, so dass nach 10 erstmal 100, 101, ... kommt und dann 11, 110, 111, 112, ... Ich kann jetzt die Nummerierung natürlich dreistellig machen, aber so ganz glücklich bin ich damit nicht.
Ich könnte auch hergehen und die tripID nehmen (analog der id beim Status). Dann wären sie schön chronologisch sortiert. Das führt zum schönen Umstand, dass alle trips des Fahrzeugs immer im ioBroker erhalten bleiben, weil keine trips mehr überschrieben würden, aber auch zu dem unschönen Zustand, dass es immer mehr states im iobroker gibt und dieser ein stückweit "vermüllt" wird. Keine Ahnung, ab wievielen States es da zu Problemen kommt.
Mir fallen jetzt verschiedene Optionen für die tripdata ein:- alles wie bisher, nur die lfd. Nummer dreistellig machen
- alle tripdata mit trapID schreiben, ggfs. eine Löschfunktion für alle Trips vorsehen (Zeitraum z.B. über Konfig einstellbar)
- tripdata auswerten und nur die neusten x (z.B. 10) Trips sortiert unter tripdata 01-10 ablegen.
- eine Kombination aus 2. und 3. mit getrennten Rubriken
Was meint Ihr?
@Sneak-L8 hallo Danke erst mal Dass Du dich um den Adapter kümmern willst.
ich habe immer 4 Tripdatawerte. Skoda Scala. der Trip 4 ist der Wert seit dem Tanken. das haben mir vergleiche mit der skoda Connect App gezeigt.
ich würde ebenfalls den vorschlag 2 begrüßen. würde mir aber eine löschfunktion für einzelne Werte wünschen. man kann natürlich auch manuell in die Objects eingreifen und etwas manuell löschen.

Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
295
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge