

Neuer Adapter 'systeminfo' auf Git und npm

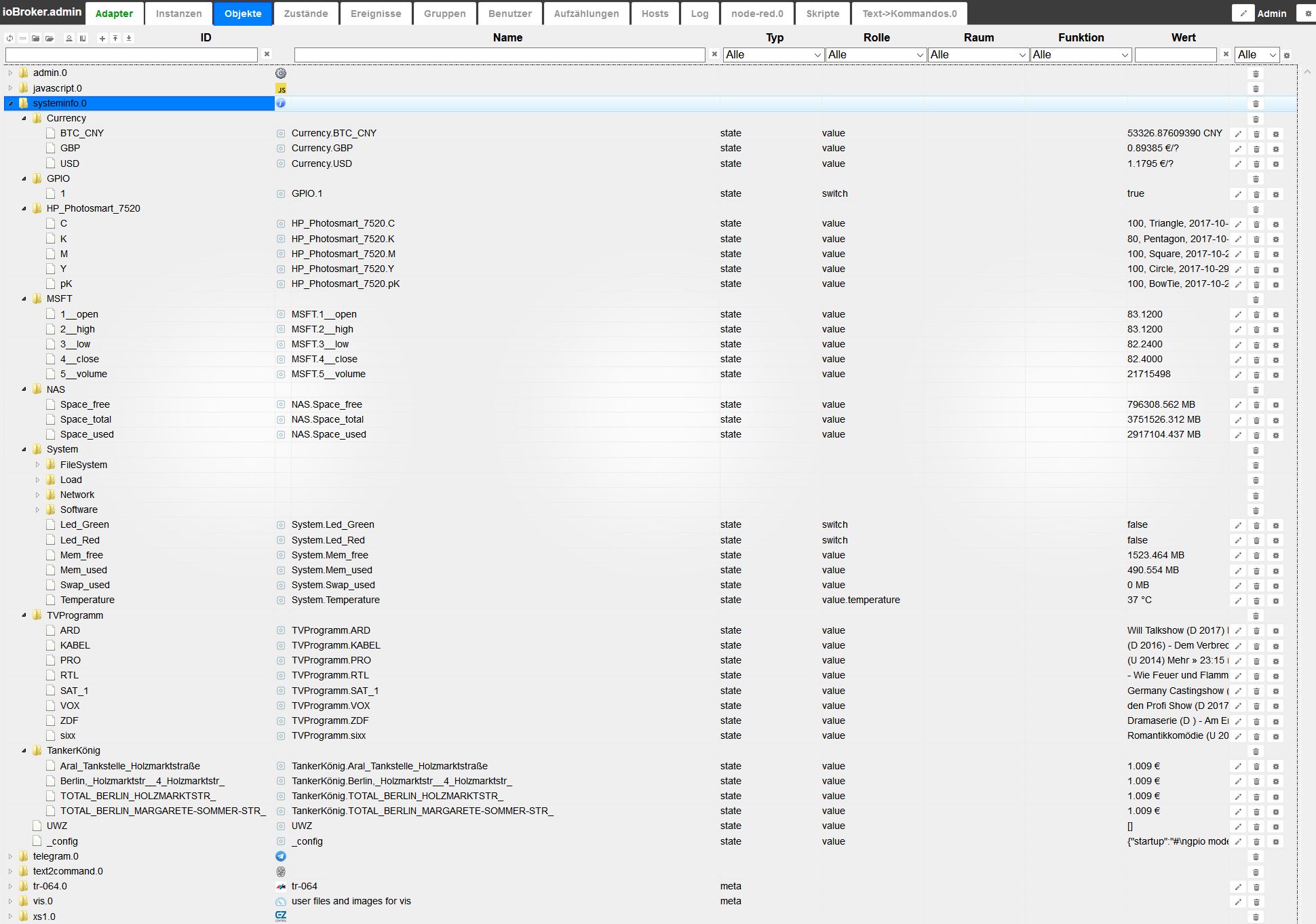
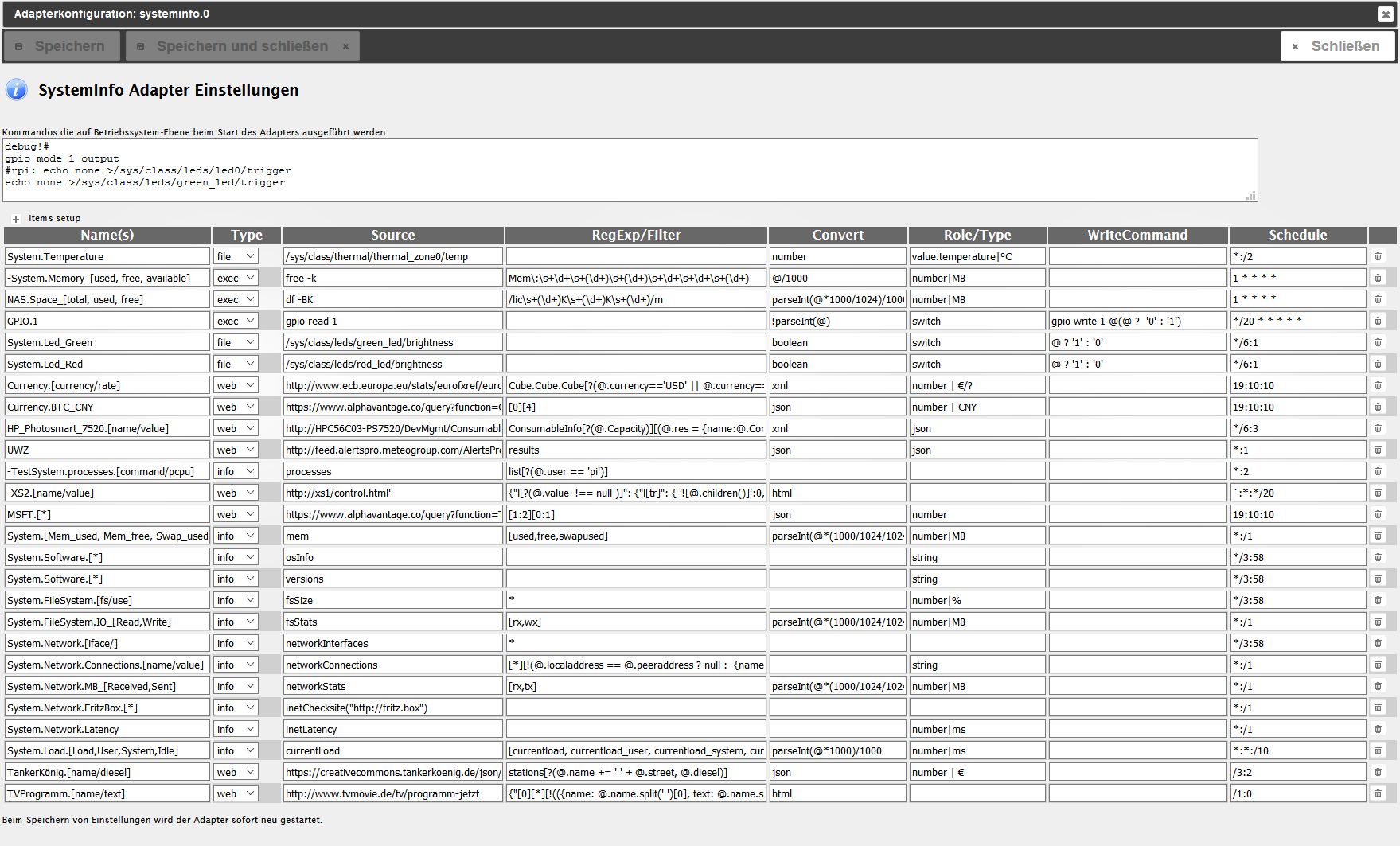
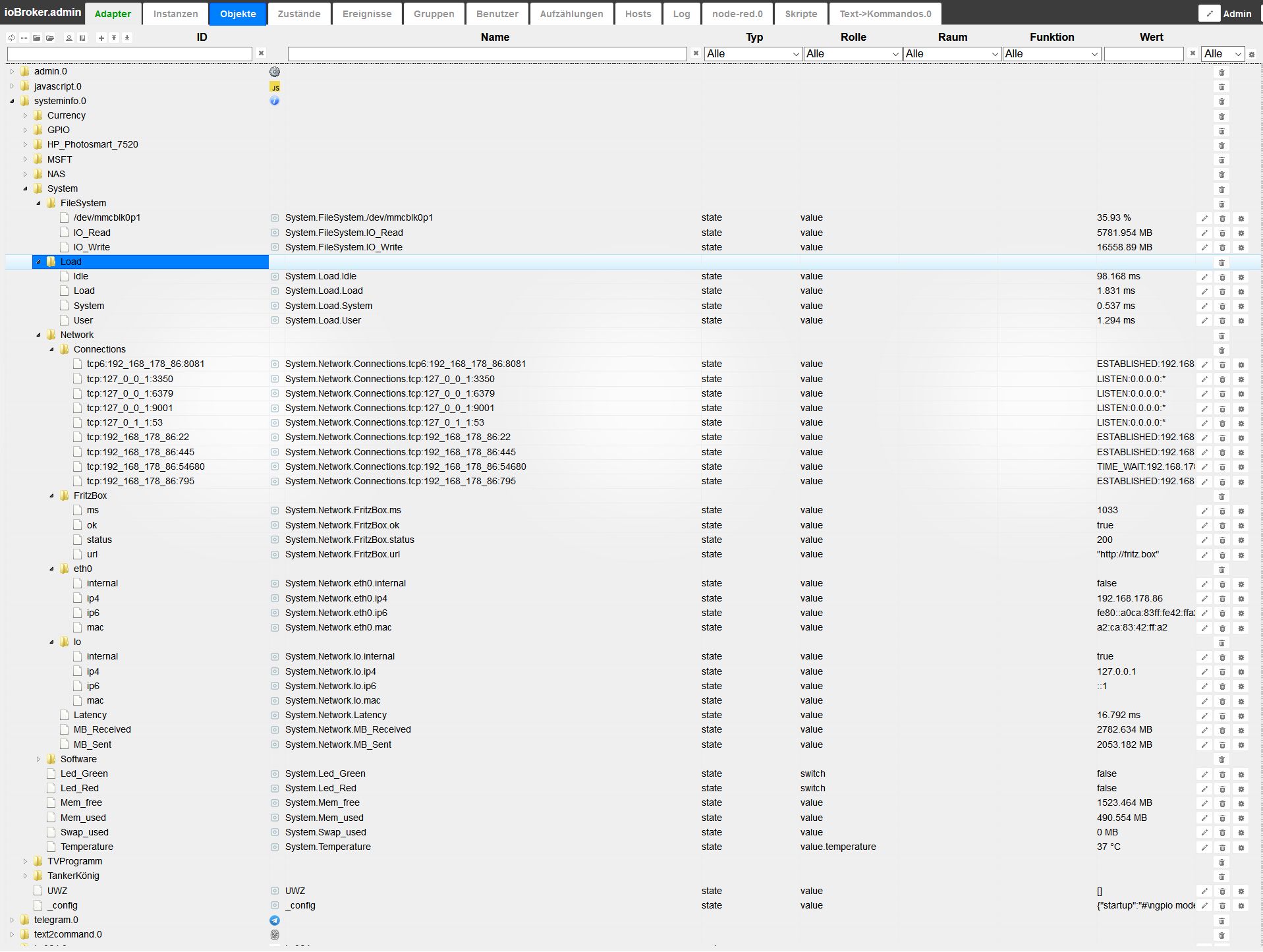
-
Und eine Verständnisfrage.
Bei folgender Einstellung:
{ "name": "SW_Versionen.Echo_[Dot_Gen2]", "type": "web", "source": "https://www.amazon.de/gp/help/customer/display.html?nodeId=201602210", "regexp": "/Echo Dot \(2\. Generation\).+: (\d+)/g", "conv": "", "role": "string", "write": "", "sched": "*:/1" }Hätte ich jetzt erwartet, dass das Objekt sysinfo.0.SW_Versionen.Echo_Dot_Gen2 angelegt wird.
Angelegt wird aber: sysinfo.0.SW_Versionen.Echo_Dot_
Der Inhalt ist leer.
Wenn ich den Quelltext der URL oben (https://www.amazon.de/gp/help/customer/ … =201602210)in https://regex101.com/r/ajcaEP/1 reinkopiere und die regexp oben anwende erhalte ich ich das gewünschte Ergebnis 595459620.
Match 1 Full match 96637-96714 `Echo Dot (2\. Generation) - Aktuelle Software-Version: 595459620` Group 1. n/a `595459620` -
Hallo mitsammen!
Adapter ist auf 0.2.2 in Git und Npm und auch im 'latest' repository von ioBroker.
Kleine Fehler im JsonParser wurden korrigiert (für '..' und […]).
Ein wichtiger Hinweis zum JsonParser: Wenn nichts gefunden wird dann gibt er (als String) das original json in den State. Dadurch könnt ihr sehen was so angekommen ist.
Werde auch anfangen hier Beispiele zu posten.
Den Anfang mach ich mit der Frage von Ruhr70 beginnen:
Bei
"name": "SW_Versionen.Echo_[Dot_Gen2]",ist die eckige klammer nicht sinnvoll bzw wird sogar falsch interpretiert!
Sie ist nur notwendig wenn die regexp MEHRERE Daten übernehmen sollte oder die Namen von den Elementen kommen sollen!
Wenn es nur der Dot_gen2 sein soll dann bitte so:
"name": "SW_Versionen.Echo_Dot_Gen2"Ich hab mal daraus 2 Beispiele gemacht:
{ "name" : "SW.[Echo_1,Echo_2,Echo_Dot_2]", "type" : "web", "source" : "https://www.amazon.de/gp/help/customer/display.html?nodeId=201602210", "regexp" : "Echo .+?Version?:\\s+(\\d+)[^:]+?:\\s+(\\d+)[^:]+?:\\s+(\\d+)", "conv" : "", "role" : "string", "write" : "", "sched" : "*:/1" } und { "name" : "SW.Echo_Dot_2_2", "type" : "web", "source" : "https://www.amazon.de/gp/help/customer/display.html?nodeId=201602210", "regexp" : "Echo Dot \\(.+?: (\\d+)", "conv" : "@[0]", "role" : "string", "write" : "", "sched" : "*:/1" }Bitte die '\' nur als '' eingeben und ohne ' " ', das ist !
Und nochwas, das +? bedeutet dass der kürzeste String ausgegeben wird, wenn man nur + macht im regex kann bei + und * auch längere strings ausgegeben werden, was ich aber nicht will da ich nur das nächste und nicht übernächste Vorkommen suchen will!
Das erste legt 3 Werte an die mit SW.Echo_1, SW.Echo_2 und SW.Echo_Dot_2 benannt sind und mittels einem Regexp aus dem Text gefiltert werden.
Die regexp braucht/soll kein 'g' haben (und braucht auch nicht '/' am Anfang und Ende). Das 'g' matcht nicht die (…)-Inhalte sondern gibt nur gesamte matches zurück!
Das 2. Beispiel gibt nur einen match zurück, deshalb im Namen keine […] sondern ein fester Name(SW.Echo_Dot_2_2).
Dafür, da match aber ein Array zurückgibt wird in conv eine Formel (@[0]) angegeben die das erste (und einzige) Element ermittelt und statt dem Array retourniert.
Übrigens, wenn diese 2 Zeilen in Systeminfo stehen und die gleiche schedule besitzen wird nur beim 1. mal die Webseite heruntergeladen. bei der 2. Zeile wird das gecachte Ergebnis verwendet, beim nächsten Timingdurchlauf wird der cache aber gelöscht. Somit können mehrere Daten ausgelesen werden ohne mehrmals die Daten von der Webseite zu verlangen.
Übrigens, der Adapter kann auch die webseite selbst parsen und daten mittel WebQuery herauspieksen, in diesem Fall wäre das aber schwieriger als das regexp.
-
@fsjoke:"regexp" : "Echo .+?Version?:\\s+(\\d+)[^:]+?:\\s+(\\d+)[^:]+?:\\s+(\\d+)",Bitte die '\' nur als '' eingeben und ohne ' " ', das ist !
Und nochwas, das +? bedeutet dass der kürzeste String ausgegeben wird, wenn man nur + macht im regex kann bei + und * auch längere strings ausgegeben werden, was ich aber nicht will da ich nur das nächste und nicht übernächste Vorkommen suchen will!
Das erste legt 3 Werte an die mit SW.Echo_1, SW.Echo_2 und SW.Echo_Dot_2 benannt sind und mittels einem Regexp aus dem Text gefiltert werden.
Die regexp braucht/soll kein 'g' haben (und braucht auch nicht '/' am Anfang und Ende). Das 'g' matcht nicht die (…)-Inhalte sondern gibt nur gesamte matches zurück! `
Danke noch einmal für diesen klasse Adapter!
Und auch für die ausführliche Erklärung hier. Mir ist da einiges klarer geworden.
Wo holst Du die json für die Konfiguration einer Abfrage her?
Nach copy & paste manuell erstellt sieht es nicht aus. Sonst wären die Backslash \ ja nicht doppelt drin.
Hast Du noch eine Idee, was ich bzgl. der Abfrage inetChecksite mit https:// falsch mache?
-
Hallo ruhr70!
Die momentane Konfiguration in json kann man in einem objekt '_config' auslesen welches angelegt wird wenn der Adapter auf 'debug!' geschaltet wird ('debug!' als erster Text im startup, irgendwo am Bild im 1. Post zu sehen). Das mach ich mit notepad+ oder Visual-Code schön und dann wirds hineinkopiert.
Das mit der inetCecksite muss ich mir später anschauen.
-
Hallo Ruhr70!
Hab mir mal die Melducnegn angeschaut und gesehen dass es hauptsächlich nicht komplette oder weitergeleitete Webanfragen sind.
Die Statuscodes kannst hier anschauen: https://de.wikipedia.org/wiki/HTTP-Statuscode
Viele Webserver verwenden Tricks und leiten an andere Webserver weiter (was der Webbrowser aber nicht Systeminfo bzw normales nodejs versteht).
Ein Beispiel ist dass
http://forum.iobroker.net ````eigentlich auf```` http://forum.iobroker.net/index.php ````weiterleitet oder auf die neuen Einträge wenn es erkennt (anhand von cookies) welcher Benutzer dran ist und was er will. Nun, Systeminfo (oder nodejs) speichert keine cookies und sendet sie also nicht an das Forum. Wenn du gleich [http://forum.iobroker.net/index.php](http://forum.iobroker.net/index.php) angibst dann funktionierts. Die Fritz.box ist bei dir OK und hat funktioniert. google.de funktioniert bei mir mit status code 301 was bedeutet dass Googles es intern weiterleitet. Die anderen lokalen kann ich nicht checken, aber prüfe mal ob da nicht passwörter oder sonst was notwendig ist (z.B. eine Seite auf die der Browser springt (wenn er weitergeleitet wird). -
Hallo fsjoke,
ja, die Statuscodes kenne ich.
Ich habe die Überwachung der Seiten vorher per diverser Javascripts erledigt. Da hatte es funktioniert.
Bei den Statuscodes erhalte ich meistens eine 404 (not found), d.h., dass die Seite nicht gefunden wird.
Ich habe Dein Beispiel für das ioBroker Forum mal ausprobiert und als url http://forum.iobroker.net/index.php eingetragen. Ich erhalte wieder ein 404.
Auch google liefert ein 404 und kein Redirect.
Ich fürchte ich mache noch einen blöden Fehler. Typ Info ist richtig?
-
Hallo ruhr70!
Verstehe nicht dass manches bei dir nicht funktioniert wo es auf bei mir auf Nuc und Raspi funktioniert.
Die 'info'-klasse wird mittels https://github.com/sebhildebrandt/systeminformation ausgeführt, den code hab ich nicht selbst geschrieben.
404 bedeutet nicht gefunden oder abgewiesen und wird vom server aktiv erzeugt, also er findet den server, der server kann (oder will) aber nichts mit dem request anfangen.
Ich habe gerade inetChecksite('http://forum.iobroker.net/index.php') und inetChecksite('http://google.de') probiert und bekomme die ok's mit ms und bei iobroker statuscode 200 und bei google.de statuscode 301 (an eine neue adresse permanent weiterleiten).
Mit curl http://google.de sieht man dass er auf http://www.google.de weiterleitet, also wäre besser gleich diese Adresse abzufragen und nicht die leere adresse für tippfaule :)
-
@fsjoke:Verstehe nicht dass manches bei dir nicht funktioniert wo es auf bei mir auf Nuc und Raspi funktioniert.
Die 'info'-klasse wird mittels https://github.com/sebhildebrandt/systeminformation ausgeführt, den code hab ich nicht selbst geschrieben.
404 bedeutet nicht gefunden oder abgewiesen und wird vom server aktiv erzeugt, also er findet den server, der server kann (oder will) aber nichts mit dem request anfangen.
Ich habe gerade inetChecksite('http://forum.iobroker.net/index.php') und inetChecksite('http://google.de') probiert und bekomme die ok's mit ms und bei iobroker statuscode 200 und bei google.de statuscode 301 (an eine neue adresse permanent weiterleiten).
Mit curl http://google.de sieht man dass er auf http://www.google.de weiterleitet, also wäre besser gleich diese Adresse abzufragen und nicht die leere adresse für tippfaule :) `
Manches nicht funktioniert ist etwas übertrieben. Es funktioniert fast alles :-)
Es ist bei mir nur die inetChecksite. Und soviel kann man da ja nicht falsch machen :mrgreen:
Mit dem 404 ist wirklich komisch.
https://www.google.de hatte ich schon drinstehen. Nun mal mit http versucht… auch 404.
Ich bin immer noch absolut begeistert, was Du da gezaubert hast. in vieles muss ich mich noch "rein denken" (WebQuery sagt mir z.B. nichts.), habe aber schon einiges auf Deinen Adapter umgezogen ( Parser, Skripte).
Also... im Gesamtpaket... ganz großes Kino!
-
Hallo,
@fsjoke:Wenn mir wer hilft werde ich einen save & load-Button einbauen mit dem man Konfig's abspeichern und laden kann. `
das interessiert mich auch (für den Tankerkönig-Adapter). Der S7 Adapter kann dasHTML https://github.com/ioBroker/ioBroker.s7 … index.html
Screenshots in der Readme https://github.com/ioBroker/ioBroker.s7 ... c/en/s7.md
Bluefox sagte mir mal, man müsse das mit URLencode machen, habe es aber nicht weiter verfolgt.
Pix
-
wahrscheinlich nur wenn du eine Instanz dort auch laufen lässt! Eine Frage (habe noch nie ein master/salve gehabt/gebraucht, was ist eigentlich der Vorteil oder Grund warum man 2-3 hosts braucht? Mir kommt da nur unterschiedliche Gebäude oder Netzwerke in den Sinn und beides habe ich nicht!
@pix, danke für die info, werd's mir mal anschauen.
@ruhr70, Ich muss einiges noch besser dokumentieren, wie Webquery.
der JsonParser funktioniert für meine meisten Fälle super, Webquery ist ein 'Vorschalter' welcher im iQuery-Stil Webdaten filtern kann (wenns komplizierter ist und man nicht regExp verwenden kann da die Daten in sich ändernden Orten auftauchen.
-
@fsjoke:, was ist eigentlich der Vorteil oder Grund warum man 2-3 hosts braucht? Mir kommt da nur unterschiedliche Gebäude oder Netzwerke in den Sinn und beides habe ich nicht! `
Die Anwendungsfälle bei mir:
-
Master auf dem ESXi (kein Bluetooth, kein USB)
-
Slaves als Pi 3 z.B. für die Xiaomi Pflanzensensoren
-
Slaves mit USB für CO2 Messungen in den Räumen, inkl Visualisierung
-
dann der Radar Adapter (unterstützt nicht alle Arten der Scans auf dem ESXi)
-
und zur Überprüfung, ob DHCP im Netzwerk verfügbar ist (das Tool lässt sich ebenfalls auf dem ESXi nicht nutzen)
Mein Master ist ein Ubunto Server. Wenn ich Adapter bräuchte, die Windows benötigen, wäre der dies auch als Slave möglich.
-
-
Hallo,
ich als ioBroker-Neuling hab da ein Problem:
Ich bekomme den Adapter nicht installiert/geuploadet. Im admin ist er unter Adapter zu sehen - vorn bei verfügbar nix hinten die 0.3.0 als installiert - aber wenn ich auf upload klicke, dann gibt ihn nicht unter Instanzen.
Das Log sagt:
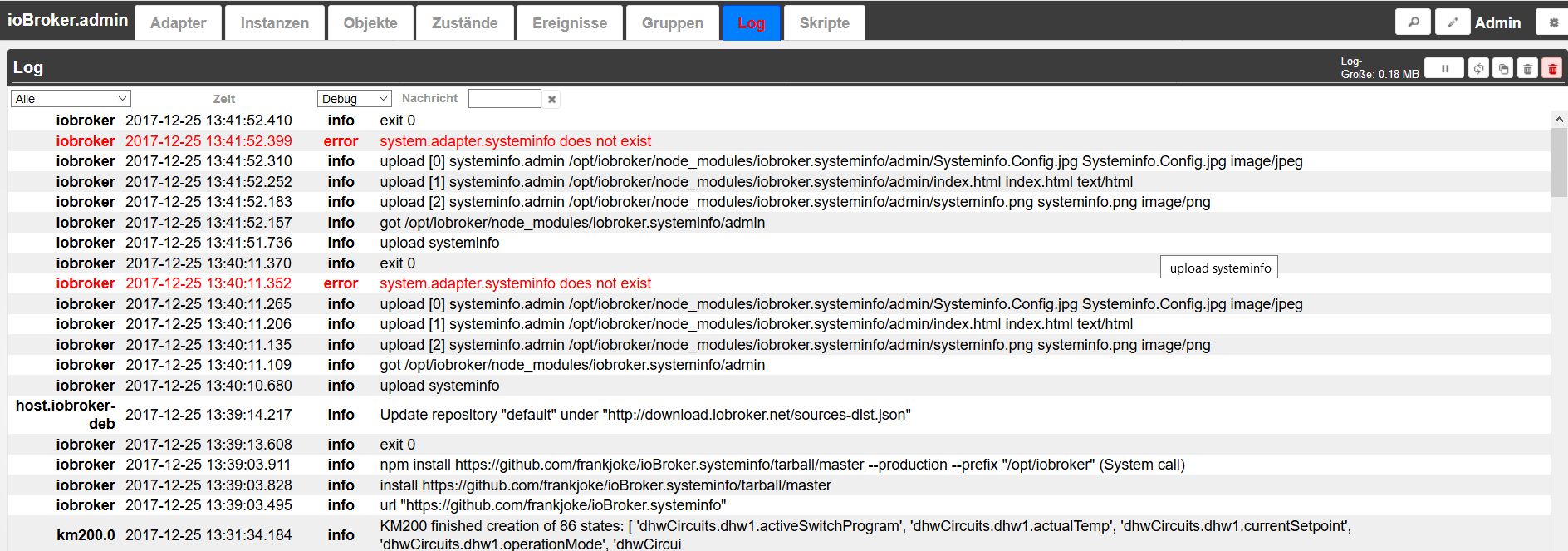
-
Bei der manuellen Installation erhalte ich:
root@iobroker-deb:/opt/iobroker# npm install iobroker.systeminfo
iobroker.systeminfo@0.2.2 node_modules/iobroker.systeminfo
├── systeminformation@3.33.11
├── xml2js@0.4.19 (sax@1.2.4, xmlbuilder@9.0.4)
├── node-schedule@1.2.5 (long-timeout@0.1.1, sorted-array-functions@1.0.0, cron-parser@2.4.3)
└── cheerio@1.0.0-rc.2 (entities@1.1.1, dom-serializer@0.1.0, css-select@1.2.0, htmlparser2@3.9.2, parse5@3.0.3, lodash@4.17.4)
root@iobroker-deb:/opt/iobroker# iobroker upload systeminfo
got /opt/iobroker/node_modules/iobroker.systeminfo/admin
upload [2] systeminfo.admin /opt/iobroker/node_modules/iobroker.systeminfo/admin/systeminfo.png systeminfo.png image/png
upload [1] systeminfo.admin /opt/iobroker/node_modules/iobroker.systeminfo/admin/index.html index.html text/html
upload [0] systeminfo.admin /opt/iobroker/node_modules/iobroker.systeminfo/admin/Systeminfo.Config.jpg Systeminfo.Config.jpg image/jpeg
system.adapter.systeminfo does not exist
root@iobroker-deb:/opt/iobroker# iobroker restart
Stopping iobroker controller daemon…
iobroker controller daemon stopped.
Starting iobroker controller daemon...
iobroker controller daemon started. PID: 9308
root@iobroker-deb:/opt/iobroker#
Was mache ich falsch?
-
http://www.iobroker.net/docu/?page_id=5379&lang=de#8_Installieren
Auf der Konsole wäre der Befehl eine Instanz zu erzeugen
sudo iobroker add AdapterNameupload dient dazu neuere Dateien in die Installationsordner zu kopieren.
Aber selbst diese sind dann nicht in einer bereits existierenden Instanz verfügbar.
Diese muss u.U. dann noch gelöscht und wieder neu angelegt werden.
Gruß
Rainer
-
Du hast im Admin in der Zeile, in dem der Adapter steht hinten das Plus gedrückt, um eine Instanz zu erzeugen? `
:shock: natürlich nicht :o - bei den Standardadaptern erzeugt die sich ja von selbst (jedenfalls hab ich da noch nie drauf gedrückt) :D
jetzt ja :D
Danke!
Funktioniert schön - nur auf meinem Debian gibts keine CPU-Temperatur (da in dem angegeben Pfad nichts liegt):
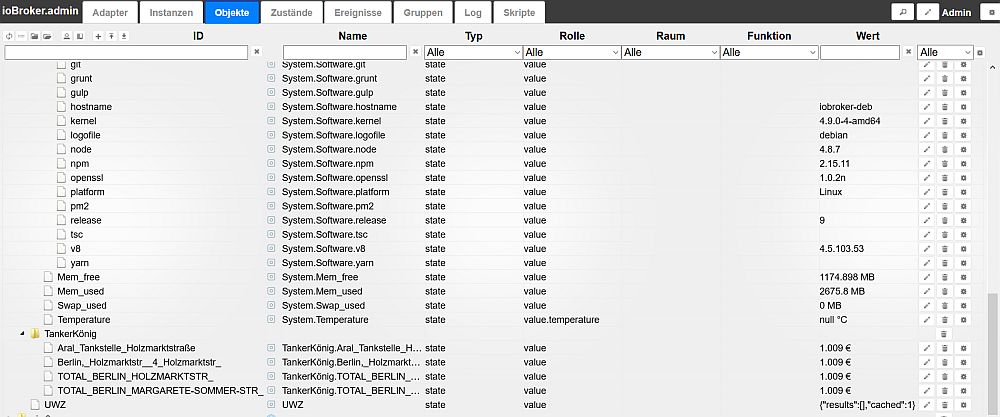
Toll, dass Du die verschiedenen Filesysteme ausliest - kann man (wenn man es dann dann könnte) dann auch statt der %-Auslastung auf gesamten, freien und belegten Speicher erweitern.
Da fehlt dann eine Übersicht mit Eintragungen in Deinen Adapter für die verschiedenen System oder verschiedenen Anwendungen.
… uns so was wie "gewählte Einträge exportieren" und "Einträge importieren" ;)
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden371
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge