

Fragen zu Projektaufbau, Datenpunkten und Archiv
-
Hallo,
ich habe mich einige Tage mit ioBroker beschäftig, da es mir von einem Bekannten empfohlen wurde.
Bisher habe ich mit Home-Assistant oder eigenen Skripten gearbeitet. Da ich jedoch immer wieder in meinen Planungen von neuen Erkenntnissen, Möglichkeiten oder zu großen Javascripten (ich möchte echt kein Javascript lernen) unterbrochen wurde, möchte ich mir hier einmal Rat einholen, wie ich das Projekt am besten aufbaue.Da ich beruflich die Erfahrung gemacht habe, dass es manchmal besser ist, die eigenen Überlegungen hinten anzustellen und einfach mal die Voraussetzungen und Ziele zu beschreiben, starte ich damit. Dann beschreibe ich meine bisherigen eigene Lösungswege für solche Szenarien (welche aber viel kleiner und nicht so Umfangreich wie das geplante Projekt waren) und am Ende meine bisherigen Überlegungen in der Umgebung von ioBroker.
Voraussetzungen und Ziele:
Aktuell läuft ioBroker auf einem Raspberry Pi 3B+, muss aber nicht so bleiben, war jedoch gerade noch vorhanden.
Ich möchte gern einige Objekte mit Sensoren überwachen und Geräte (5V direkt und 230V über Relais) steuern.
Ansteuerung habe ich getestet über Adapter "rpi2.0" und "i2c.0".
Diese Aktivitäten möchte ich Archivieren und über einer Visualisierung alle Objekte welche nicht im Status "Archiv" sind einsehen. Zusätzlich möchte ich neue Objekte anlegen und einige Einstellungen über die Visualisierung vornehmen.eigene Lösung:
Ich habe bisher Apache mit einer mySQL-Datenbank verwendet und eine Visualisierung mit HTML-Script, CSS und PHP aufgebaut. Über PHP habe ich dann Bash- und Python-Scripte ausgeführt welche mir Werte in die DB geschrieben oder Geräte gesteuert haben.
Hier hätte ich mir automatisch zu jedem neuen Objekt eine Tabelle innerhalb der DB erstellt, diese beinhaltet den Status und bei ausgelösten Aktivitäten einen Zeitstempel sowie die Werte der letzten Messung der jeweiligen Sensoren.bisherige Überlegungen in ioBroker:
Ich habe mir Node-Red angesehen, die Möglichkeit direkt eine Visualisierung einzubinden ohne mit VIS zu arbeiten war verlockend. Leider bin ich noch nicht ganz hinter das Konzept mit den Payloads gestiegen. Zudem gestaltet sich die Erstellung von Ordnern und Objekten ohne zusätzlich Javascripte zu verwenden als schwierig.
Danach habe ich mir Blockly angesehen, da brauchte ich für das genannte Problem zwar auch ein Javascript, aber insgesamt war es für mich verständlicher und eingänglicher als Node-Red.Datenwerte wollte ich mit dem Adapter "History" archivieren, habe aktuell jedoch "SQL" verwendet, da ich mit einem Export der DB außerhalb von ioBroker besser umgehen kann. (Die Auswertung der Daten soll sowieso außerhalb ablaufen.) (1)
Daher war die Überlegung die Logik mit Blockly, die Visualisierung mit VIS und die Archivierung mit SQL aufzubauen. (2, 3)
Ich möchte unter "0_userdata.0" einen Ordner anlegen, z. B. "Objekte". Über VIS möchte ich Blockly-Scripte ausführen, welche für jedes neue Objekt Ordner erstellen und die Datenpunkte enthalten; diese sollen mit Messwerten aus den Sensoren-Datenpunkten gefüllt werden. (4)
Objekt_0001:
- Status [New, Stable, Old, Archive]
- Sensor0 [Wert, Zeitstempel]
- Sensor1 [Wert, Zeitstempel]
- ...
Je nach Objekt und Status kann die Zuordnung der Sensoren sich verändern. Im Status New hat das Objekt nur Sensor0, im Status Stable hat es Sensor0 bis Sensor2, etc. (5)
In VIS möchte ich alle Objekte welche nicht im Status Archive sind darstellen. (6)
Fragen:
Hier meine aktuellen offenen Fragen. Ich benötige keine Fertige Lösung, jedoch hier und da einen Ansatz, Alternative Möglichkeiten oder auch nur die Antwort, ob es mit den Boardmitteln der jeweiligen Adapter ohne große Javascript verwenden zu müssen funktioniert. (HTML für VIS und kleine Notlösungen für Blockly sind OK)-
Spricht etwas gegen den Adapter SQL?
-
Kann ich mit Blockly die SQL-Archivierung eines Datenpunktes aktivieren? (So wie ich es manuell in den Einstellung des Datenpunktes unter Objekte machen kann.)
-
Kann ich mit Blockly Datenpunkte inkl. der verwendeten SQL-Tabelle kopieren? Also alle archivierten Werte von Datenpunkt X in Datenpunkt Y verschieben?
-
Die Überlegung war, die Messwerte nur zu bestimmten Zeiten zu Archivieren, jedoch alle Aktionen. So wollte ich pro Aktion und Sensor einen Datenpunkt verwenden um an Ende bei den Exportierten SQL-Daten keine Zuordnung erstellen zu müssen, wann welcher Archivwert von Sensor0 zu welchen Objekt gehörte. So habe ich einen Ordner "Objekt_x" mit allen Werten und Zeitstempeln und nur die Sensordaten welche ich benötige und muss bei der Auswertung nicht jeden Archivwert aus dem Datenpunkt des Sensors dem verwendeten "Objekt_x" zuordnen.
-
Wie sollte ich die Sensoren zuordnen? Normal hätte ich eine zusätzliche Tabelle welche die aktiven Objekte enthält und die Zuordnung der Sensoren. Sollte ich das einfach mit Datenpunkten erledigen?
-
Auch hier hätte ich früher alle Objekte welche nicht den Status Archive haben aufgerufen, lässt sich das in Blockly mit Schleifen für X Objekte in X Ordnern lösen? Vllt über einen Datenwert ID, welcher pro Objekt hochzählt? Oder sollte man eher Datenpunkte für jedes aktive Objekt erstellen und diese später kopieren?
Ich hoffe jemand versteht einige Fragen und kann mir beim Aufbau weiterhelfen, bevor ich nach der halben Umsetzung bei Null beginne, da meine geplante Nutzung der Datenpunkte oder verwendeten Adapter so nicht funktioniert. Gern bin ich auch für alternative Vorschläge zu verwendeten Adaptern oder dem Aufbau an sich Dankbar.
Gruß
reinz -
Hallo,
ich habe mich einige Tage mit ioBroker beschäftig, da es mir von einem Bekannten empfohlen wurde.
Bisher habe ich mit Home-Assistant oder eigenen Skripten gearbeitet. Da ich jedoch immer wieder in meinen Planungen von neuen Erkenntnissen, Möglichkeiten oder zu großen Javascripten (ich möchte echt kein Javascript lernen) unterbrochen wurde, möchte ich mir hier einmal Rat einholen, wie ich das Projekt am besten aufbaue.Da ich beruflich die Erfahrung gemacht habe, dass es manchmal besser ist, die eigenen Überlegungen hinten anzustellen und einfach mal die Voraussetzungen und Ziele zu beschreiben, starte ich damit. Dann beschreibe ich meine bisherigen eigene Lösungswege für solche Szenarien (welche aber viel kleiner und nicht so Umfangreich wie das geplante Projekt waren) und am Ende meine bisherigen Überlegungen in der Umgebung von ioBroker.
Voraussetzungen und Ziele:
Aktuell läuft ioBroker auf einem Raspberry Pi 3B+, muss aber nicht so bleiben, war jedoch gerade noch vorhanden.
Ich möchte gern einige Objekte mit Sensoren überwachen und Geräte (5V direkt und 230V über Relais) steuern.
Ansteuerung habe ich getestet über Adapter "rpi2.0" und "i2c.0".
Diese Aktivitäten möchte ich Archivieren und über einer Visualisierung alle Objekte welche nicht im Status "Archiv" sind einsehen. Zusätzlich möchte ich neue Objekte anlegen und einige Einstellungen über die Visualisierung vornehmen.eigene Lösung:
Ich habe bisher Apache mit einer mySQL-Datenbank verwendet und eine Visualisierung mit HTML-Script, CSS und PHP aufgebaut. Über PHP habe ich dann Bash- und Python-Scripte ausgeführt welche mir Werte in die DB geschrieben oder Geräte gesteuert haben.
Hier hätte ich mir automatisch zu jedem neuen Objekt eine Tabelle innerhalb der DB erstellt, diese beinhaltet den Status und bei ausgelösten Aktivitäten einen Zeitstempel sowie die Werte der letzten Messung der jeweiligen Sensoren.bisherige Überlegungen in ioBroker:
Ich habe mir Node-Red angesehen, die Möglichkeit direkt eine Visualisierung einzubinden ohne mit VIS zu arbeiten war verlockend. Leider bin ich noch nicht ganz hinter das Konzept mit den Payloads gestiegen. Zudem gestaltet sich die Erstellung von Ordnern und Objekten ohne zusätzlich Javascripte zu verwenden als schwierig.
Danach habe ich mir Blockly angesehen, da brauchte ich für das genannte Problem zwar auch ein Javascript, aber insgesamt war es für mich verständlicher und eingänglicher als Node-Red.Datenwerte wollte ich mit dem Adapter "History" archivieren, habe aktuell jedoch "SQL" verwendet, da ich mit einem Export der DB außerhalb von ioBroker besser umgehen kann. (Die Auswertung der Daten soll sowieso außerhalb ablaufen.) (1)
Daher war die Überlegung die Logik mit Blockly, die Visualisierung mit VIS und die Archivierung mit SQL aufzubauen. (2, 3)
Ich möchte unter "0_userdata.0" einen Ordner anlegen, z. B. "Objekte". Über VIS möchte ich Blockly-Scripte ausführen, welche für jedes neue Objekt Ordner erstellen und die Datenpunkte enthalten; diese sollen mit Messwerten aus den Sensoren-Datenpunkten gefüllt werden. (4)
Objekt_0001:
- Status [New, Stable, Old, Archive]
- Sensor0 [Wert, Zeitstempel]
- Sensor1 [Wert, Zeitstempel]
- ...
Je nach Objekt und Status kann die Zuordnung der Sensoren sich verändern. Im Status New hat das Objekt nur Sensor0, im Status Stable hat es Sensor0 bis Sensor2, etc. (5)
In VIS möchte ich alle Objekte welche nicht im Status Archive sind darstellen. (6)
Fragen:
Hier meine aktuellen offenen Fragen. Ich benötige keine Fertige Lösung, jedoch hier und da einen Ansatz, Alternative Möglichkeiten oder auch nur die Antwort, ob es mit den Boardmitteln der jeweiligen Adapter ohne große Javascript verwenden zu müssen funktioniert. (HTML für VIS und kleine Notlösungen für Blockly sind OK)-
Spricht etwas gegen den Adapter SQL?
-
Kann ich mit Blockly die SQL-Archivierung eines Datenpunktes aktivieren? (So wie ich es manuell in den Einstellung des Datenpunktes unter Objekte machen kann.)
-
Kann ich mit Blockly Datenpunkte inkl. der verwendeten SQL-Tabelle kopieren? Also alle archivierten Werte von Datenpunkt X in Datenpunkt Y verschieben?
-
Die Überlegung war, die Messwerte nur zu bestimmten Zeiten zu Archivieren, jedoch alle Aktionen. So wollte ich pro Aktion und Sensor einen Datenpunkt verwenden um an Ende bei den Exportierten SQL-Daten keine Zuordnung erstellen zu müssen, wann welcher Archivwert von Sensor0 zu welchen Objekt gehörte. So habe ich einen Ordner "Objekt_x" mit allen Werten und Zeitstempeln und nur die Sensordaten welche ich benötige und muss bei der Auswertung nicht jeden Archivwert aus dem Datenpunkt des Sensors dem verwendeten "Objekt_x" zuordnen.
-
Wie sollte ich die Sensoren zuordnen? Normal hätte ich eine zusätzliche Tabelle welche die aktiven Objekte enthält und die Zuordnung der Sensoren. Sollte ich das einfach mit Datenpunkten erledigen?
-
Auch hier hätte ich früher alle Objekte welche nicht den Status Archive haben aufgerufen, lässt sich das in Blockly mit Schleifen für X Objekte in X Ordnern lösen? Vllt über einen Datenwert ID, welcher pro Objekt hochzählt? Oder sollte man eher Datenpunkte für jedes aktive Objekt erstellen und diese später kopieren?
Ich hoffe jemand versteht einige Fragen und kann mir beim Aufbau weiterhelfen, bevor ich nach der halben Umsetzung bei Null beginne, da meine geplante Nutzung der Datenpunkte oder verwendeten Adapter so nicht funktioniert. Gern bin ich auch für alternative Vorschläge zu verwendeten Adaptern oder dem Aufbau an sich Dankbar.
Gruß
reinzzuerst ja ich weiss.. bitte doku lesen.. ist so
- ja
2.wozu.. der Datenpunkt wird bei einer Änderung archiviert.. oder nach x milisek. oder kombination aus beiden ..wozu dann noch manuell
3.wozu per blockly ?? sql ist sql nimm irgend ein toll.. womit machst du es jetzt.. aber wozu ??
4.verstehe ich nicht.. sry
5.garnicht.. es hängt von den adapter ab welche mit denen kommunizieren..
6.wie 4. hääääääää
ich glaub du siehts das von der Falschen Seite an..deshalb lese die Doku
ich versuche mal kurz anhand von modbus
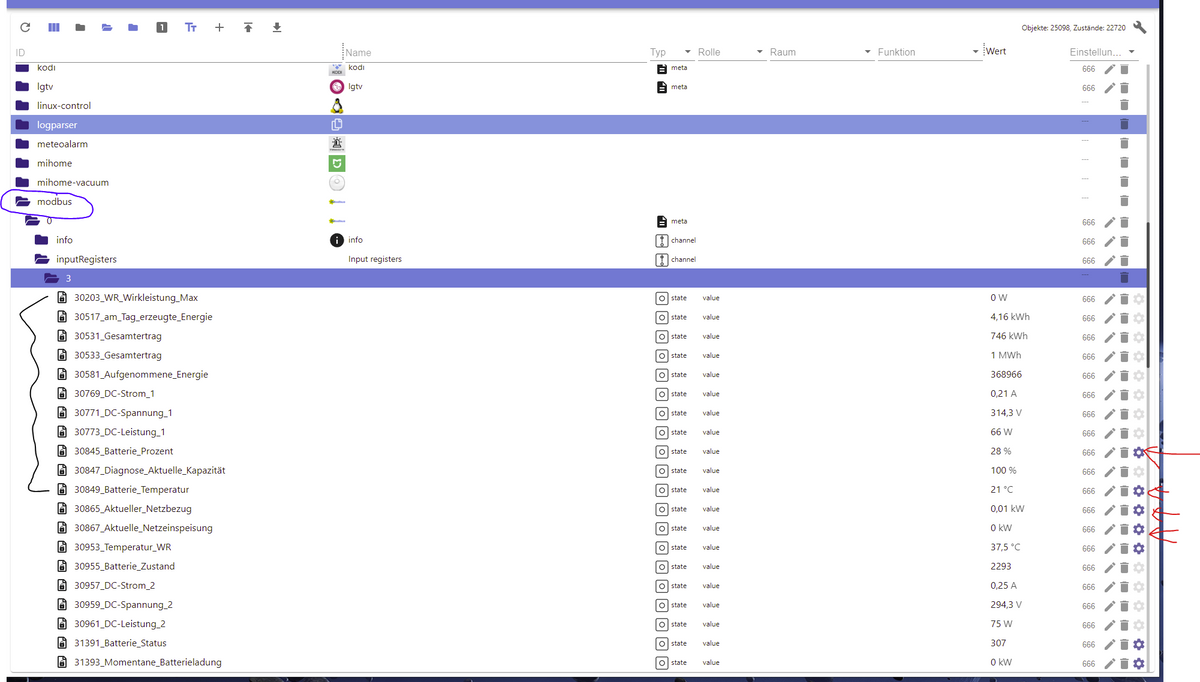
also..
der blaue kringel rechts ist der adapter der mir die datenpunkte/objekte (schwarzes strich rechts) zur verfügung stellt.. diese werden automatisch archiviert (links rote striche) .. ok..nicht sql aber influxdb
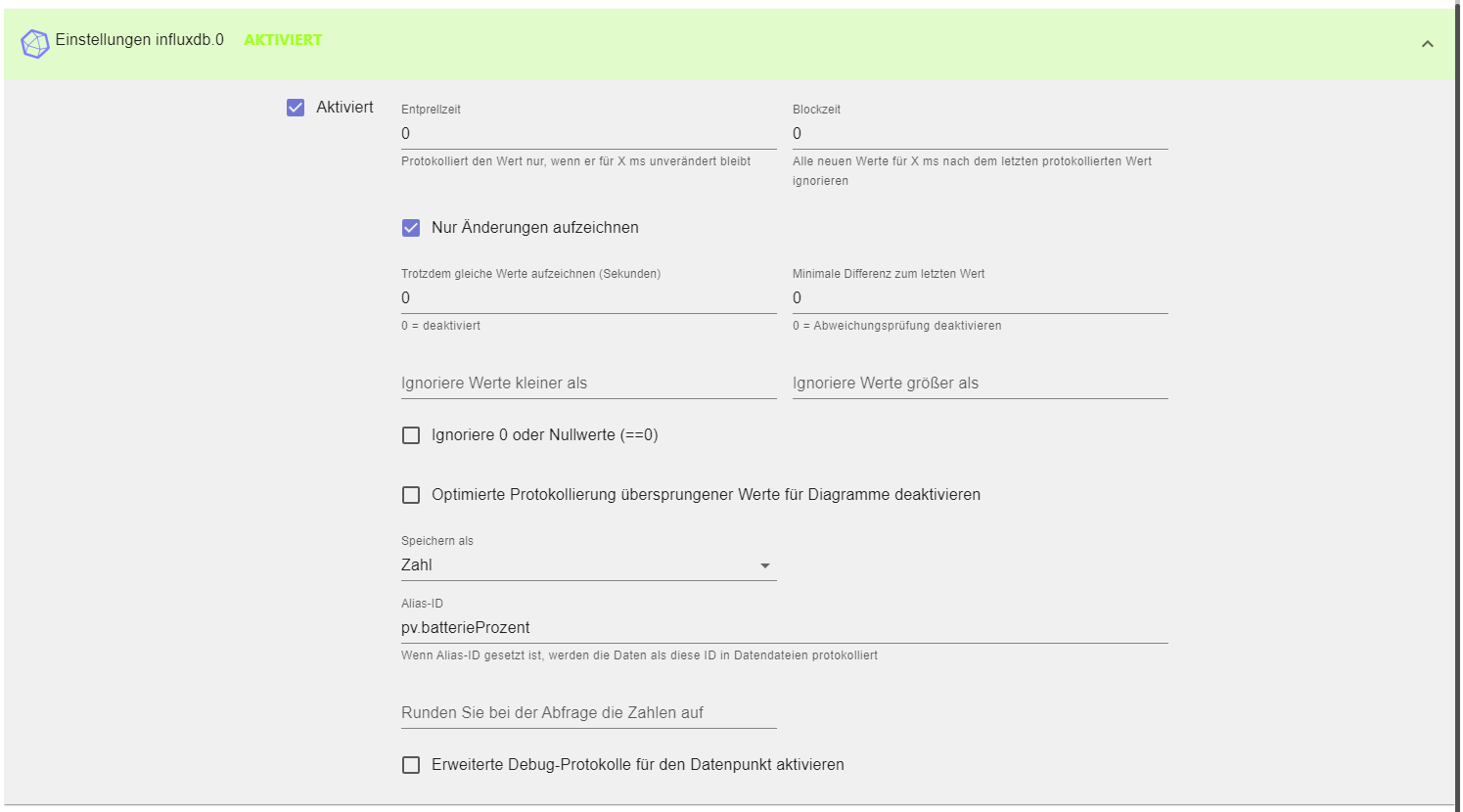
die ich dann per grafanaoder float oder oder visualisieren kann oder per javascript aus der db rausziehen kann..du kannst auch von aussen auf die DB zugreifen.. warum auch nicht..
die Archivierung im klassischen DWH ist hier nicht gegeben.. ausser du schaufelst warum auch immer die Daten von einer DB in eine andere..
-
zuerst ja ich weiss.. bitte doku lesen.. ist so
- ja
2.wozu.. der Datenpunkt wird bei einer Änderung archiviert.. oder nach x milisek. oder kombination aus beiden ..wozu dann noch manuell
3.wozu per blockly ?? sql ist sql nimm irgend ein toll.. womit machst du es jetzt.. aber wozu ??
4.verstehe ich nicht.. sry
5.garnicht.. es hängt von den adapter ab welche mit denen kommunizieren..
6.wie 4. hääääääää
ich glaub du siehts das von der Falschen Seite an..deshalb lese die Doku
ich versuche mal kurz anhand von modbus
also..
der blaue kringel rechts ist der adapter der mir die datenpunkte/objekte (schwarzes strich rechts) zur verfügung stellt.. diese werden automatisch archiviert (links rote striche) .. ok..nicht sql aber influxdb
die ich dann per grafanaoder float oder oder visualisieren kann oder per javascript aus der db rausziehen kann..du kannst auch von aussen auf die DB zugreifen.. warum auch nicht..
die Archivierung im klassischen DWH ist hier nicht gegeben.. ausser du schaufelst warum auch immer die Daten von einer DB in eine andere..
@arteck
Danke für deine Antwort. Ich wollte bevor ich mich tiefer einarbeite und Zeit investiere nur abklären, ob sich die genannten Lösungen prinzipiell eignen.zu 1.) Wieso?
zu 2. a) Wird er doch nur, wenn ich einen entsprechenden Adapter verwende? In deinem Bsp. influx, in meinem SQL. Was ist der Vorteil von influx?
zu 2. b) Ich möchte den Datenpunkt nicht manuell archivieren. Jedoch nur zu festgelegten Zeitpunkten die Messwerte aufbewahren. Daher die Idee die Messwerte in eine eigenen Datenpunkt zu schreiben, welcher fest zum Objekt gehört. Wenn ich den Datenpunkt archiviere und später auswerten möchte, muss ich immer prüfen mit welchen Objekt der Datenpunkt zum jeweiligen Zeitpunkt verknüpft/zuständig war falls ich es direkt im Datenpunkt des Sensors archiviere.
zu 2. c) Wie du weiter unten beschreibst, kann ich über den blauen Kringel (Zahnrad?!) eines Datenpunktes die Einstellungen für archivierende Adapter setzen. Meine Frage dazu war, ob ich diese Einstellungen/die Aktivierung per Blockly-Lösung automatisieren kann.
zu 3. a) Ich wollte die Logik möglichst mit einer Lösung abdecken und nicht wild gemischt Blockly, Java- , Python - und Bash-Scripte nutzen.
zu 3. b) Ich kann in Blockly einen Datenpunkt-Typ auslesen, einen neuen Datenpunkt erstellen und mit den Wert eines anderen Datenpunktes füllen; also einen Datenpunkt kopieren. Falls nun mit einem zusätzlichen Adapter (influx, sql, usw.) eine Archivierung läuft, kann ich mit Blockly diese ebenfalls auf einen neuen Datenpunkt übertragen?
zu 4.) Siehe 2. b. Es geht mir um den logischen Aufbau meiner Objekte. Die Struktur dieser Objekte (Datenpunkte, Status, usw.) soll über Skripte angelegt werden. Dann möchte ich ganze Objekte archivieren.
Mache ich das über einen Datenpunkt "Status" innerhalb eines Objekt-Ordners oder sollte ich die Daten nur in der SQL behalten? Dann kommt mir die Frage, kann ich mit Blockly Datenpunkte löschen ohne die SQL-Datenbank zu beeinflussen? Wenn ich den Datenpunkt manuell lösche, werden die Datenbankeinträge auch entfernt.zu 5.) In meinem Bsp. wie beschrieben aktuell "rpi2.0" und "i2c.0". Aber unabhängig vom Adapter landen die Werte in einem Datenpunkt. Also kann doch dies meine Schnittstelle für alle Arten von Sensoren sein?
Meine Frage ist, wie machen ich der Logik begreiflich, dass der SensorX für Objekt_X in Verwendung ist.
Einen Datenpunkt erstellen mit "in use: true/false" und einen mit "assigned: objekt_x"?Im Grunde ist die Frage immer wieder, kann ich mit Blockly über die normalen Datenpunkte hinaus andere Adaptern ansteuern? Da sich dies sicher von Lösung zu Lösung unterscheidet war meine Frage ob im Falle der Archivierung wie von mir beschrieben SQL taugt?
Wie beschrieben möchte ich die Auswertung vorerst außerhalb durchführen. Selbstverständlich würde ich dabei auf die vorhandene SQL bzw. deren Backups zurückgreifen.
Ich hoffe ich konnte einiges verständlicher beschreibene.
Gruß
reinz - ja
-
@arteck
Danke für deine Antwort. Ich wollte bevor ich mich tiefer einarbeite und Zeit investiere nur abklären, ob sich die genannten Lösungen prinzipiell eignen.zu 1.) Wieso?
zu 2. a) Wird er doch nur, wenn ich einen entsprechenden Adapter verwende? In deinem Bsp. influx, in meinem SQL. Was ist der Vorteil von influx?
zu 2. b) Ich möchte den Datenpunkt nicht manuell archivieren. Jedoch nur zu festgelegten Zeitpunkten die Messwerte aufbewahren. Daher die Idee die Messwerte in eine eigenen Datenpunkt zu schreiben, welcher fest zum Objekt gehört. Wenn ich den Datenpunkt archiviere und später auswerten möchte, muss ich immer prüfen mit welchen Objekt der Datenpunkt zum jeweiligen Zeitpunkt verknüpft/zuständig war falls ich es direkt im Datenpunkt des Sensors archiviere.
zu 2. c) Wie du weiter unten beschreibst, kann ich über den blauen Kringel (Zahnrad?!) eines Datenpunktes die Einstellungen für archivierende Adapter setzen. Meine Frage dazu war, ob ich diese Einstellungen/die Aktivierung per Blockly-Lösung automatisieren kann.
zu 3. a) Ich wollte die Logik möglichst mit einer Lösung abdecken und nicht wild gemischt Blockly, Java- , Python - und Bash-Scripte nutzen.
zu 3. b) Ich kann in Blockly einen Datenpunkt-Typ auslesen, einen neuen Datenpunkt erstellen und mit den Wert eines anderen Datenpunktes füllen; also einen Datenpunkt kopieren. Falls nun mit einem zusätzlichen Adapter (influx, sql, usw.) eine Archivierung läuft, kann ich mit Blockly diese ebenfalls auf einen neuen Datenpunkt übertragen?
zu 4.) Siehe 2. b. Es geht mir um den logischen Aufbau meiner Objekte. Die Struktur dieser Objekte (Datenpunkte, Status, usw.) soll über Skripte angelegt werden. Dann möchte ich ganze Objekte archivieren.
Mache ich das über einen Datenpunkt "Status" innerhalb eines Objekt-Ordners oder sollte ich die Daten nur in der SQL behalten? Dann kommt mir die Frage, kann ich mit Blockly Datenpunkte löschen ohne die SQL-Datenbank zu beeinflussen? Wenn ich den Datenpunkt manuell lösche, werden die Datenbankeinträge auch entfernt.zu 5.) In meinem Bsp. wie beschrieben aktuell "rpi2.0" und "i2c.0". Aber unabhängig vom Adapter landen die Werte in einem Datenpunkt. Also kann doch dies meine Schnittstelle für alle Arten von Sensoren sein?
Meine Frage ist, wie machen ich der Logik begreiflich, dass der SensorX für Objekt_X in Verwendung ist.
Einen Datenpunkt erstellen mit "in use: true/false" und einen mit "assigned: objekt_x"?Im Grunde ist die Frage immer wieder, kann ich mit Blockly über die normalen Datenpunkte hinaus andere Adaptern ansteuern? Da sich dies sicher von Lösung zu Lösung unterscheidet war meine Frage ob im Falle der Archivierung wie von mir beschrieben SQL taugt?
Wie beschrieben möchte ich die Auswertung vorerst außerhalb durchführen. Selbstverständlich würde ich dabei auf die vorhandene SQL bzw. deren Backups zurückgreifen.
Ich hoffe ich konnte einiges verständlicher beschreibene.
Gruß
reinz@re1nz sagte in Fragen zu Projektaufbau, Datenpunkten und Archiv:
Ich hoffe ich konnte einiges verständlicher beschreibene.
ich kann dir nur empfehlen es auszuprobieren.
Je länger deine theoretische Planung, die auf bisherige Kenntnisse anderer Systeme beruht, wird, desto größer wird die Gefahr, dass es zu Verständnisproblemenen aufgrund der unterschiedlichen Funktionalität und Terminologie kommt.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
433
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge