

influxdb 3.0.0 verfügbar - eine Zusammenfassung
-
@diginix Hm ... ok muss ich in der UI noch anpassen. an sich nicht. Bin aber ehrlich: Ich habs es nicht selbst ausprobiert. Code technisch sollte es aber tun
@apollon77 Dauert noch ein paar Monate bis die 2 Jahre bei den ältesten Werten erreicht sind. Dann sehe ich ob Einstellung 5 Jahre greift.
In Adapter v2.6.3 hatte ich bereits die Standard Entprellzeit auf 1000 ms gesetzt. Nach dem Update auf v3 steht dort aber eine 0. Hätte der alte Wert nicht übernommen werden sollen?
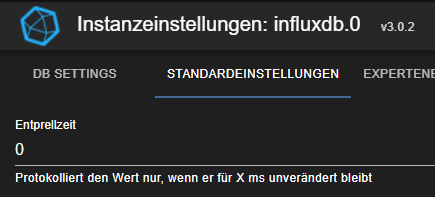
Und die damalige Entprellzeit pro Objekt ist nun neu die Blockzeit. Das ist so richtig?
..:: So long! Tom ::..
NUC7i3 (Ubuntu Proxmox VM) | Echo Dots 2+3. Gen | Xiaomi Sensoren | Mi Robot 1S | Yeelight | Sonoff | Shelly | H801 RGB | Gosund SP1 | NodeMCU+ESP32 | Kostal Plenticore PV+BYD | openWB
-
@apollon77 Dauert noch ein paar Monate bis die 2 Jahre bei den ältesten Werten erreicht sind. Dann sehe ich ob Einstellung 5 Jahre greift.
In Adapter v2.6.3 hatte ich bereits die Standard Entprellzeit auf 1000 ms gesetzt. Nach dem Update auf v3 steht dort aber eine 0. Hätte der alte Wert nicht übernommen werden sollen?
Und die damalige Entprellzeit pro Objekt ist nun neu die Blockzeit. Das ist so richtig?
-
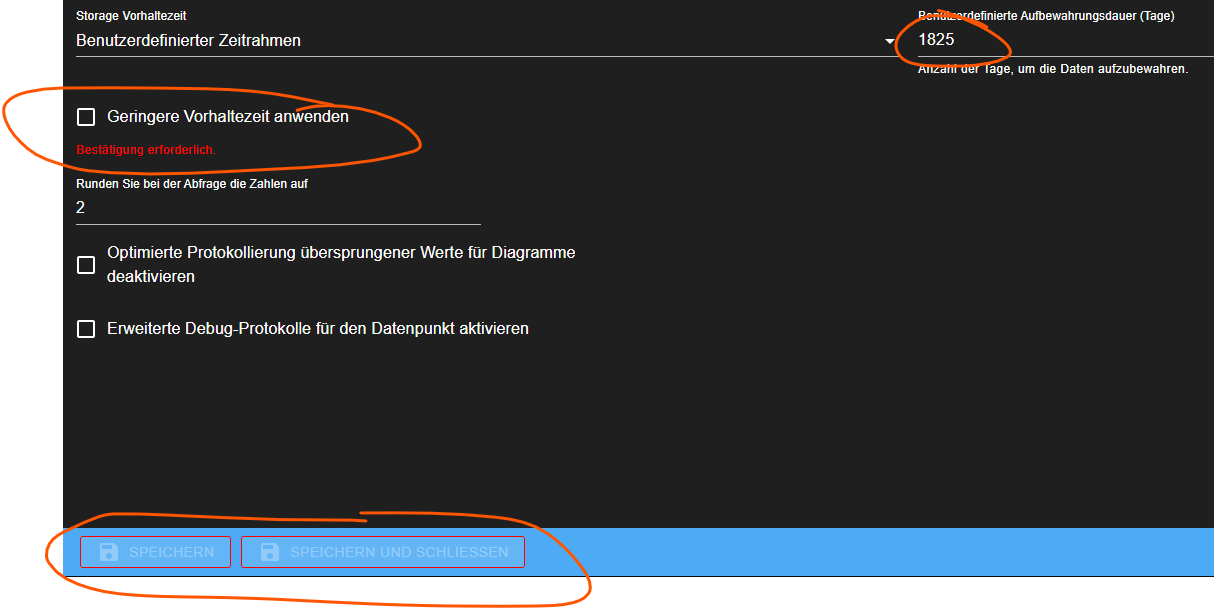
@apollon77 Wenn ich benutzerdefinierte Vorhaltezeit nutzen will und zuvor 2 Jahre eingestellt war und ich nun auf >2 Jahre gehe, muss ich trotzdem den Haken "geringere Vorhaltezeit anwenden" setzen. Das verunsichert mich.

Ich möchte ungern Daten verlieren.
@diginix Auf GitHub sollte die UI für alle Fälle korrigiert sein
Beitrag hat geholfen? Votet rechts unten im Beitrag :-) https://paypal.me/Apollon77 / https://github.com/sponsors/Apollon77
- Debug-Log für Instanz einschalten? Admin -> Instanzen -> Expertenmodus -> Instanz aufklappen - Loglevel ändern
- Logfiles auf Platte /opt/iobroker/log/… nutzen, Admin schneidet Zeilen ab
-
@apollon77
Habe admin 5.4.9
was react ui habe auf neue Ansicht aber in weiss
Loginfluxdb.0
2022-05-16 18:21:37.976 debug Send: 1 of: 2 in: 16msinfluxdb.0
2022-05-16 18:21:37.961 debug Query to execute: SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time <= '2022-05-16T15:52:00.000Z' ORDER BY time DESC LIMIT 1;SELECT * from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time > '2022-05-16T15:52:00.000Z' AND time < '2022-05-16T16:22:00.000Z' ORDER BY time DESC LIMIT 500;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time >= '2022-05-16T16:22:00.000Z' LIMIT 1influxdb.0
2022-05-16 18:21:37.960 debug Incoming message getHistory from system.adapter.admin.0influxdb.0
2022-05-16 18:21:35.743 debug Send: 10 of: 11 in: 30msinfluxdb.0
2022-05-16 18:21:35.732 debug Send: 10 of: 11 in: 28msinfluxdb.0
2022-05-16 18:21:35.718 debug Query to execute: SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time <= '2022-05-15T16:00:00.000Z' ORDER BY time DESC LIMIT 1;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time > '2022-05-15T16:00:00.000Z' AND time < '2022-05-16T16:21:35.206Z' ORDER BY time ASC;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time >= '2022-05-16T16:21:35.206Z' LIMIT 1influxdb.0
2022-05-16 18:21:35.712 debug Incoming message getHistory from system.adapter.admin.0influxdb.0
2022-05-16 18:21:35.705 debug Query to execute: SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time <= '2022-05-15T16:00:00.000Z' ORDER BY time DESC LIMIT 1;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time > '2022-05-15T16:00:00.000Z' AND time < '2022-05-16T16:21:35.185Z' ORDER BY time ASC;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time >= '2022-05-16T16:21:35.185Z' LIMIT 1influxdb.0
2022-05-16 18:21:35.703 debug Incoming message getHistory from system.adapter.admin.0influxdb.0
2022-05-16 18:21:02.029 debug Send: 0 of: 1 in: 24msinfluxdb.0
2022-05-16 18:21:02.007 debug Query to execute: SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time <= '2022-05-16T15:52:00.000Z' ORDER BY time DESC LIMIT 1;SELECT * from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time > '2022-05-16T15:52:00.000Z' AND time < '2022-05-16T16:22:00.000Z' ORDER BY time DESC LIMIT 500;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time >= '2022-05-16T16:22:00.000Z' LIMIT 1influxdb.0
2022-05-16 18:21:02.004 debug Incoming message getHistory from system.adapter.admin.0influxdb.0
2022-05-16 18:21:00.412 debug Send: 9 of: 10 in: 25msinfluxdb.0
2022-05-16 18:21:00.388 debug Query to execute: SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time <= '2022-05-15T16:00:00.000Z' ORDER BY time DESC LIMIT 1;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time > '2022-05-15T16:00:00.000Z' AND time < '2022-05-16T16:20:59.802Z' ORDER BY time ASC;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time >= '2022-05-16T16:20:59.802Z' LIMIT 1influxdb.0
2022-05-16 18:21:00.386 debug Incoming message getHistory from system.adapter.admin.0influxdb.0
2022-05-16 18:21:00.253 debug Send: 9 of: 10 in: 35msinfluxdb.0
2022-05-16 18:21:00.224 debug Query to execute: SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time <= '2022-05-15T16:00:00.000Z' ORDER BY time DESC LIMIT 1;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time > '2022-05-15T16:00:00.000Z' AND time < '2022-05-16T16:20:59.335Z' ORDER BY time ASC;SELECT value from "hm-rpc.0.MEQ0045799.2.STATE" WHERE time >= '2022-05-16T16:20:59.335Z' LIMIT 1influxdb.0
2022-05-16 18:21:00.209 debug Incoming message getHistory from system.adapter.admin.0@stephan61 GitHub Versio sollte es behoben haben. Falls Du testen willst nach GitHub install bitte manuell Adapter neu starten
-
@apollon77 sagte in influxdb 3.0.0 verfügbar - eine Zusammenfassung:
@diginix Auf GitHub sollte die UI für alle Fälle korrigiert sein
Bisher sehe ich die Checkbox wenn ich die Instanzeinstellungen öffne und auch wenn ich dann zB 2000 Tage statt 1825 eintrage, bleibt die Checkbox und ich kann ohne nicht speichern.
..:: So long! Tom ::..
NUC7i3 (Ubuntu Proxmox VM) | Echo Dots 2+3. Gen | Xiaomi Sensoren | Mi Robot 1S | Yeelight | Sonoff | Shelly | H801 RGB | Gosund SP1 | NodeMCU+ESP32 | Kostal Plenticore PV+BYD | openWB
-
@apollon77 sagte in influxdb 3.0.0 verfügbar - eine Zusammenfassung:
@diginix Auf GitHub sollte die UI für alle Fälle korrigiert sein
Bisher sehe ich die Checkbox wenn ich die Instanzeinstellungen öffne und auch wenn ich dann zB 2000 Tage statt 1825 eintrage, bleibt die Checkbox und ich kann ohne nicht speichern.
@diginix Mist ... einen Fall hab ich natürlich vergessen :-)
Jetzt aber hoffentlich
Beitrag hat geholfen? Votet rechts unten im Beitrag :-) https://paypal.me/Apollon77 / https://github.com/sponsors/Apollon77
- Debug-Log für Instanz einschalten? Admin -> Instanzen -> Expertenmodus -> Instanz aufklappen - Loglevel ändern
- Logfiles auf Platte /opt/iobroker/log/… nutzen, Admin schneidet Zeilen ab
-
@apollon77 Passt nun.
-
@stephan61 GitHub Versio sollte es behoben haben. Falls Du testen willst nach GitHub install bitte manuell Adapter neu starten
@apollon77
mit der github version werden die Werte wieder angezeigt . DankeGruß Stephan
-
Hallo,
eine Verständnisfrage. Die Aufbewahrungszeit, liese die sich auch pro Datenpunkt einstellen oder geht das bei InfluxDB nur generell, also Adapterweit? Der Hintergrund der Frage ist der, dass ich Datenpunkte habe, wo ich alle Infos ohne Löschung aufzeichne und andere, wo nur ein paar Wochen reichen würden.
-
Hallo,
eine Verständnisfrage. Die Aufbewahrungszeit, liese die sich auch pro Datenpunkt einstellen oder geht das bei InfluxDB nur generell, also Adapterweit? Der Hintergrund der Frage ist der, dass ich Datenpunkte habe, wo ich alle Infos ohne Löschung aufzeichne und andere, wo nur ein paar Wochen reichen würden.
@palm_maniac Geht nur pro DB.
..:: So long! Tom ::..
NUC7i3 (Ubuntu Proxmox VM) | Echo Dots 2+3. Gen | Xiaomi Sensoren | Mi Robot 1S | Yeelight | Sonoff | Shelly | H801 RGB | Gosund SP1 | NodeMCU+ESP32 | Kostal Plenticore PV+BYD | openWB
-
@palm_maniac Geht nur pro DB.
-
@diginix Ok, danke. Schade.
@palm_maniac Bist jetzt gefühlt der 5. der das fragt. Legt halt ein GitHub Ossue als Feature Request an ... kann man halt nur manuell machen. Muss mal lesen ob InfluxDB sowas mag oder überhaupt erlaubt
-
Hallo,
bei mir häufen sich in der letzten Zeit diese Fehler:
influxdb.0 2022-05-18 10:16:55.037 warn Error in query "import "influxdata/influxdb/schema" schema.tagKeys(bucket: "iobroker")": RequestTimedOutError: Request timed outDie treten jeden Morgen auf, gefolgt von mehreren Einträgen pro Datenpunkt im Log, was dazu führt dass es mehrere Gigabyte an Größe zulegt. Helfen tut hier nur ein Neustart des InfluxDB Service oder des LXC-Containers, in dem nur Influx läuft. Das Problem habe ich seit einiger Zeit und weiß langsam nicht mehr wo ich suchen soll. Vielleicht hat hier jemand eine Idee.
Im LXC ist Ubuntu 21.11 als Grundsystem installiert mit InfluxDB V2.2.
Ich frage auch deshalb hier, weil sich das Problem gefühlt mit meinen Tests mit der Adapterversion 3.0 eingestellt hat. Leider scheint es aber wohl nur ein Gefühl zu sein, denn der Fehler tritt jetzt auch mit der V2.6.3 auf, da aber bei weitem nicht so oft.
-
Hallo,
bei mir häufen sich in der letzten Zeit diese Fehler:
influxdb.0 2022-05-18 10:16:55.037 warn Error in query "import "influxdata/influxdb/schema" schema.tagKeys(bucket: "iobroker")": RequestTimedOutError: Request timed outDie treten jeden Morgen auf, gefolgt von mehreren Einträgen pro Datenpunkt im Log, was dazu führt dass es mehrere Gigabyte an Größe zulegt. Helfen tut hier nur ein Neustart des InfluxDB Service oder des LXC-Containers, in dem nur Influx läuft. Das Problem habe ich seit einiger Zeit und weiß langsam nicht mehr wo ich suchen soll. Vielleicht hat hier jemand eine Idee.
Im LXC ist Ubuntu 21.11 als Grundsystem installiert mit InfluxDB V2.2.
Ich frage auch deshalb hier, weil sich das Problem gefühlt mit meinen Tests mit der Adapterversion 3.0 eingestellt hat. Leider scheint es aber wohl nur ein Gefühl zu sein, denn der Fehler tritt jetzt auch mit der V2.6.3 auf, da aber bei weitem nicht so oft.
@palm_maniac Request "timeout" deutet an sich darauf hin das die InfluxDB selbst irgendwas hat bzw die Query länger dauert als der aktuelle Timeout. Den Request Timeout kannst Du hochsetzen in der Konfig ... vllt mal erhöhen?
Auch die Frage ist wo die Meldung herkommt schema.tagKeys gibts in den queries nicht ... machst Du custom Queries?
Beitrag hat geholfen? Votet rechts unten im Beitrag :-) https://paypal.me/Apollon77 / https://github.com/sponsors/Apollon77
- Debug-Log für Instanz einschalten? Admin -> Instanzen -> Expertenmodus -> Instanz aufklappen - Loglevel ändern
- Logfiles auf Platte /opt/iobroker/log/… nutzen, Admin schneidet Zeilen ab
-
@palm_maniac Request "timeout" deutet an sich darauf hin das die InfluxDB selbst irgendwas hat bzw die Query länger dauert als der aktuelle Timeout. Den Request Timeout kannst Du hochsetzen in der Konfig ... vllt mal erhöhen?
Auch die Frage ist wo die Meldung herkommt schema.tagKeys gibts in den queries nicht ... machst Du custom Queries?
@apollon77 Ich habe vor einiger Zeit nach Anleitung von V1.8 auf V2 gewechselt und die Datenbanken konvertiert. es sind also keine reinen frischen V2 Datenbanken. Vielleicht liegt es daran? Aber das hat bis vor kurzem nie Probleme bereitet.
-
@apollon77 Ich habe vor einiger Zeit nach Anleitung von V1.8 auf V2 gewechselt und die Datenbanken konvertiert. es sind also keine reinen frischen V2 Datenbanken. Vielleicht liegt es daran? Aber das hat bis vor kurzem nie Probleme bereitet.
@palm_maniac Keine Ahnung. ich bin selbst noch auf InfluxDB 1.8 und scheue mich vor den mega GB der migration :-)))
Beitrag hat geholfen? Votet rechts unten im Beitrag :-) https://paypal.me/Apollon77 / https://github.com/sponsors/Apollon77
- Debug-Log für Instanz einschalten? Admin -> Instanzen -> Expertenmodus -> Instanz aufklappen - Loglevel ändern
- Logfiles auf Platte /opt/iobroker/log/… nutzen, Admin schneidet Zeilen ab
-
@palm_maniac Keine Ahnung. ich bin selbst noch auf InfluxDB 1.8 und scheue mich vor den mega GB der migration :-)))
@apollon77 dito :D
-
@palm_maniac Keine Ahnung. ich bin selbst noch auf InfluxDB 1.8 und scheue mich vor den mega GB der migration :-)))
@apollon77 Wie entwickelst du dann den Adapter für influxDB v2? Testsystem mit Dummy Daten?
Hab bisher gedacht ich wäre allein mit v1.8 und sollte es mal angehen. Aber wenn das nicht einfach nur ein Update Kommando ist sondern mit mehr Aufwand verbunden ist, dann sitze ich das noch eine Weile aus.
Was hätte man mit v2 für Vorteile und gibt es auch Nachteile?
..:: So long! Tom ::..
NUC7i3 (Ubuntu Proxmox VM) | Echo Dots 2+3. Gen | Xiaomi Sensoren | Mi Robot 1S | Yeelight | Sonoff | Shelly | H801 RGB | Gosund SP1 | NodeMCU+ESP32 | Kostal Plenticore PV+BYD | openWB
-
@apollon77 Wie entwickelst du dann den Adapter für influxDB v2? Testsystem mit Dummy Daten?
Hab bisher gedacht ich wäre allein mit v1.8 und sollte es mal angehen. Aber wenn das nicht einfach nur ein Update Kommando ist sondern mit mehr Aufwand verbunden ist, dann sitze ich das noch eine Weile aus.
Was hätte man mit v2 für Vorteile und gibt es auch Nachteile?
@diginix sagte in influxdb 3.0.0 verfügbar - eine Zusammenfassung:
@apollon77 Wie entwickelst du dann den Adapter für influxDB v2? Testsystem mit Dummy Daten?
@diginix Die 2.0 Implementierung hat primär @Excodibur gebaut und der hatte da dann installiert. Ich hab auch irgendwo für sondertests ne mini influxdb in nem container laufen ... Ansonst habe ich einige Stunden gebastelt um bei den GitHub Actions wo alle Tests bei GitHub ausgeführt werden sowohl eine InfluxDB 1 wie auch eine InfluxDB 2 zu installieren und dann mit testdaten zu füttern und damit ie Tests laufen zu lassen ... https://github.com/ioBroker/ioBroker.influxdb/actions/runs/2337929675
Damit geht das meiste recht gut.
Das immer ein problem ist sind "Massendaten tests" weil die nahezu unmöglich sind zu stellen es sei denn man hat wirklich ein größ0eres System was Daten einliefert.
Hab bisher gedacht ich wäre allein mit v1.8 und sollte es mal angehen. Aber wenn das nicht einfach nur ein Update Kommando ist sondern mit mehr Aufwand verbunden ist, dann sitze ich das noch eine Weile aus.
Upgrade ist quasi ein Datenexport aus der 1.x und Import in die 2.x weil die Strukturen inkompatibel sind. In irgend einem Thread hier im Forum gabs das Thema schonmal auch mit den Befehlen und so.
Wenn ich es mal mache ist meine Idee:
- Adapter umstellen auf Influxdb 2 und damit gehen alle neuen Daten da rein
- Dann entweder die alten Daten Monatsweise oder so exportieren und dann die Exports Files durch die gegend schieben und einzeln importieren ODER irgendwie ein großes Dir per nfs von meiner NAS mounten und alles exportieren ... Ich glaube wir waren mal bei export faktor 10 oder größer oder sowas ... ich habe 41GB Roh-Daten angesammelt gg So arg will ich die VM nicht aufblasen
Und ich brauch noch ne Lösung für collectd weil die InfluxDB 2 das nicht mehr von hause aus kann sondern nur über umwege
Und um das alles rauszufinden fehlt mir gerade Zeit und Muse :-)
Was hätte man mit v2 für Vorteile und gibt es auch Nachteile?
Im zweifel: 1.x ist EOL denke ich und kriegt keine Updates mehr .... 2.x ist halt aktuell und bekommt Updates und neue Features udn hat ne neue Abfragesprache mit mehr möglichkeiten
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden433
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge