

Datenpunkt in LOG oder CSV File schreiben
-
Hallo,
wie kann ich um eine bestimmte Uhrzeit den Wert von zwei oder drei Datenpunkten automatisiert in ein Log-/oder CSV-File schreiben.
Dieses wird benötigt für eine Excel-Tabelle, wo das File dann entsprechend verarbeitet wird.
Gibt es dazu eine Möglichkeit (ohne den Weg des händigen Exports über History).
DANKE !!!!!@manfredh-1 Du kannst das mit Deiner Logikmaschine machen. Da gibts sicher schon Blocklies die jemand geschrieben hat.
Oder Du nimmst einen Node-Red Flow mit einer file Node.Habe einfach mal einen meiner Shellies genommen - der meldet immer kumuliert W/min Werte:

Der Flow ist mit der file Node super easy:

Die Überschrift muss halt schon vorhanden sein, ansonsten ist es ja kein Problem das im Excel in die 2. Zeile zu importieren.
Das ganze erzeugt bei jedem Triggern der Datenpunkte eine neue Zeile:
Datum & Uhrzeit;Wert 06.11.2021 17:04:14;82934 06.11.2021 17:05:13;82935 06.11.2021 17:06:06;82936 06.11.2021 17:06:43;82936 06.11.2021 17:07:07;82937 06.11.2021 17:08:13;82938 06.11.2021 17:09:03;82939 06.11.2021 17:10:13;82940 06.11.2021 17:11:07;82942 -
@manfredh-1 Du kannst das mit Deiner Logikmaschine machen. Da gibts sicher schon Blocklies die jemand geschrieben hat.
Oder Du nimmst einen Node-Red Flow mit einer file Node.Habe einfach mal einen meiner Shellies genommen - der meldet immer kumuliert W/min Werte:
Der Flow ist mit der file Node super easy:
Die Überschrift muss halt schon vorhanden sein, ansonsten ist es ja kein Problem das im Excel in die 2. Zeile zu importieren.
Das ganze erzeugt bei jedem Triggern der Datenpunkte eine neue Zeile:
Datum & Uhrzeit;Wert 06.11.2021 17:04:14;82934 06.11.2021 17:05:13;82935 06.11.2021 17:06:06;82936 06.11.2021 17:06:43;82936 06.11.2021 17:07:07;82937 06.11.2021 17:08:13;82938 06.11.2021 17:09:03;82939 06.11.2021 17:10:13;82940 06.11.2021 17:11:07;82942@mickym Hallo Dankeschön. Hab das jetzt mal ausprobiert und es funktioniert. zumindest bekomm ich einen Wert aus meinen Datenpunkten richtig in das CSV.
Wenn ich aber zwei oder drei Felder in das CSV exportieren will, wie muss ich da vorgehen.Sorry, für die vielleicht dämliche Fragestellung, aber ich bin mit iobroker noch ziemlich am Anfang und mit node-red habe ich bisher noch gar nichts gemacht.
DANKE.
-
@mickym Hallo Dankeschön. Hab das jetzt mal ausprobiert und es funktioniert. zumindest bekomm ich einen Wert aus meinen Datenpunkten richtig in das CSV.
Wenn ich aber zwei oder drei Felder in das CSV exportieren will, wie muss ich da vorgehen.Sorry, für die vielleicht dämliche Fragestellung, aber ich bin mit iobroker noch ziemlich am Anfang und mit node-red habe ich bisher noch gar nichts gemacht.
DANKE.
@manfredh-1 Na das ist keine dumme Frage - wahrscheinlich gibt es auch 1000 andere Wege, viele nutzen halt Blockly im iobroker Umfeld als Logikmaschine und ich halt NodeRed. Deshalb muss man sich als Anfänger nur mal mit der Frage auseinandersetzen, welche Logikmaschine man einsetzen will.
Und solche fertige Nodes - wie das Schreiben von Dateien bieten halt die anderen Logikmaschine nicht immer. Also setz Dich ruhig mit all den Fragen auseinander und Du wirst hier sicher Hilfe finden.
So nun zu Deiner Frage:
Wenn ich aber zwei oder drei Felder in das CSV exportieren will, wie muss ich da vorgehen.
Nun Datenpunkte kannst Du einfach soviele iobroker In Nodes vorne dran hängen wie Du willst. Wenn Du noch andere Infos in Deinem CSV haben möchtest, dann müsstest Du halt sagen was und dann können wir schauen, ob und wie man das realisieren könnte und ob das Sinn macht. Was zum Beispiel nicht geht sind die Aufzählungen (Raum oder Funktion) da rein zu schreiben, da diese kein Bestandteil des state-Objektes sind
das geht also nicht:

Sinn macht noch den Pfad des Datenpunktes mit aufzunehmen, damit man weiß woher der Wert kommt.
Hab das mal hinzugefügt:
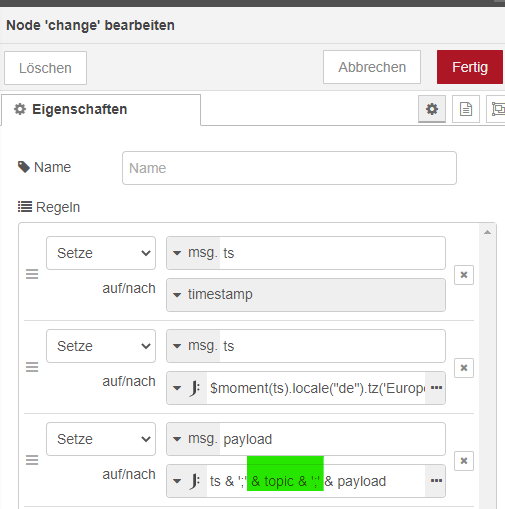
cat Werte.csv Datum & Uhrzeit;Datenpunkt;Wert 06.11.2021 19:05:59;mqtt/1/shellies/shellyplug-s-xxxxxx/relay/0/energy;83058 06.11.2021 19:06:21;mqtt/1/shellies/shellyplug-s-xxxxxx/relay/0/energy;83059und hier die Change Node mit dieser hier ersetzen:
Die Änderung ist, dass ich das Topic des Datenpunktes mit in die CSV schreibe.
Jeder Flow bzw. jedes Script, das ich hier poste implementiert jeder auf eigene Gefahr. Flows und Scripts können Fehler aufweisen und weder der Seitenbetreiber noch ich persönlich können hierfür haftbar gemacht werden. Das gleiche gilt für Empfehlungen aller Art.
-
@manfredh-1 Na das ist keine dumme Frage - wahrscheinlich gibt es auch 1000 andere Wege, viele nutzen halt Blockly im iobroker Umfeld als Logikmaschine und ich halt NodeRed. Deshalb muss man sich als Anfänger nur mal mit der Frage auseinandersetzen, welche Logikmaschine man einsetzen will.
Und solche fertige Nodes - wie das Schreiben von Dateien bieten halt die anderen Logikmaschine nicht immer. Also setz Dich ruhig mit all den Fragen auseinander und Du wirst hier sicher Hilfe finden.
So nun zu Deiner Frage:
Wenn ich aber zwei oder drei Felder in das CSV exportieren will, wie muss ich da vorgehen.
Nun Datenpunkte kannst Du einfach soviele iobroker In Nodes vorne dran hängen wie Du willst. Wenn Du noch andere Infos in Deinem CSV haben möchtest, dann müsstest Du halt sagen was und dann können wir schauen, ob und wie man das realisieren könnte und ob das Sinn macht. Was zum Beispiel nicht geht sind die Aufzählungen (Raum oder Funktion) da rein zu schreiben, da diese kein Bestandteil des state-Objektes sind
das geht also nicht:
Sinn macht noch den Pfad des Datenpunktes mit aufzunehmen, damit man weiß woher der Wert kommt.
Hab das mal hinzugefügt:
cat Werte.csv Datum & Uhrzeit;Datenpunkt;Wert 06.11.2021 19:05:59;mqtt/1/shellies/shellyplug-s-xxxxxx/relay/0/energy;83058 06.11.2021 19:06:21;mqtt/1/shellies/shellyplug-s-xxxxxx/relay/0/energy;83059und hier die Change Node mit dieser hier ersetzen:
Die Änderung ist, dass ich das Topic des Datenpunktes mit in die CSV schreibe.
@mickym sagte in Datenpunkt in LOG oder CSV File schreiben:
Nun Datenpunkte kannst Du einfach soviele iobroker In Nodes vorne dran hängen wie Du willst.
Die Frage wäre nur in welcher Form das .csv diese "mehreren" Informationen (=Spalten) verarbeiten soll.
@ManfredH-1
Immer zur (exakt) selben Zeit als Y-Achse und dann die Daten von verschiedenen Datenpunkten dahinter?
Anders ergibt ein Excel-Sheet für mich keinen Sinn.Nur die Datenpunkte werden sehr wahrscheinlich nie den exakt selben Timestamp haben, da der auf Millisekunden basiert.
Dann müsste man auch noch den (gemeinsamen) Timestamp manuell erzeugen -
@manfredh-1 Na das ist keine dumme Frage - wahrscheinlich gibt es auch 1000 andere Wege, viele nutzen halt Blockly im iobroker Umfeld als Logikmaschine und ich halt NodeRed. Deshalb muss man sich als Anfänger nur mal mit der Frage auseinandersetzen, welche Logikmaschine man einsetzen will.
Und solche fertige Nodes - wie das Schreiben von Dateien bieten halt die anderen Logikmaschine nicht immer. Also setz Dich ruhig mit all den Fragen auseinander und Du wirst hier sicher Hilfe finden.
So nun zu Deiner Frage:
Wenn ich aber zwei oder drei Felder in das CSV exportieren will, wie muss ich da vorgehen.
Nun Datenpunkte kannst Du einfach soviele iobroker In Nodes vorne dran hängen wie Du willst. Wenn Du noch andere Infos in Deinem CSV haben möchtest, dann müsstest Du halt sagen was und dann können wir schauen, ob und wie man das realisieren könnte und ob das Sinn macht. Was zum Beispiel nicht geht sind die Aufzählungen (Raum oder Funktion) da rein zu schreiben, da diese kein Bestandteil des state-Objektes sind
das geht also nicht:
Sinn macht noch den Pfad des Datenpunktes mit aufzunehmen, damit man weiß woher der Wert kommt.
Hab das mal hinzugefügt:
cat Werte.csv Datum & Uhrzeit;Datenpunkt;Wert 06.11.2021 19:05:59;mqtt/1/shellies/shellyplug-s-xxxxxx/relay/0/energy;83058 06.11.2021 19:06:21;mqtt/1/shellies/shellyplug-s-xxxxxx/relay/0/energy;83059und hier die Change Node mit dieser hier ersetzen:
Die Änderung ist, dass ich das Topic des Datenpunktes mit in die CSV schreibe.
-
Der Timestamp ist für mich in diesem FAll nicht so wichtig.
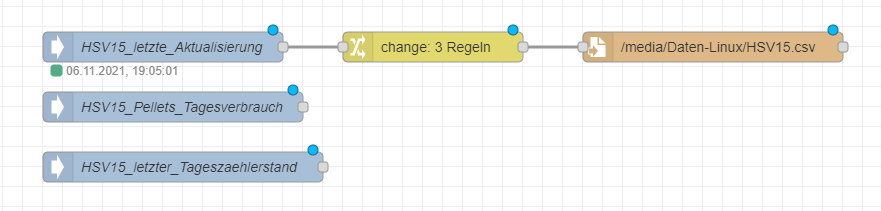
Ich bräuchte für den Anfang einfach diese 3 Datenpunkte (HSV15 ....) jeden in einer Spalte im CSV und das ganze sollte eine Minute vor Mitternacht weggeschrieben werden.
@manfredh-1 Wie gesagt nimm mal die veränderte Change Node und das Topic ist mit dabei.
Jetzt gibt es 2 Möglichkeiten - entweder Du machst im Excel Pivot Tabellen oder Du machst in die Change Nodes entsprechende Semicolons für die zusätzlichen Spalten.
Die letzte Aktualisierung ist aber Käse weil der Timestamp ja durch die Change NOde gesetzt ist.
Für die 1 Variante kannst alle in die modifizierte Change Node laufen lassen,
ansonsten für Spalte 2 brauchst halt für jede Spalte eine andere Change Node.Die 2. Variante erzeugt dann so eine csv
cat Werte.csv Datum & Uhrzeit;Datenpunkt;Aktualisierung;Tagesverbrauch;Tageszähler 06.11.2021 19:24:51;HSV_15_letzte_Aktualisierung;06.11.2021. 19:05:01 06.11.2021 19:24:53;HSV_15_Pellets_Tagesverbrauch;;23 06.11.2021 19:24:54;HSV_15_Pellets_Tageszählerstand;;;522 06.11.2021 19:25:00;HSV_15_letzte_Aktualisierung;06.11.2021. 19:05:01Ich finde das mit den zusätzlichen Spalten pro Datenpunkt eigentlich unschön

Wenn man sicher stellen kann, dass die Datenpunkte einmal in der richtigen Reihenfolge getriggert werden, kann man auch ein Objekt erstellen, dass wäre dann die 3. Möglichkeit:
Dann muss man aber darauf achten, dass die Datenpunkte in der richtigen Reihenfolge einmal aktualisiert werden

In diesem Fall werden immer alle 3 Datenpunkte mit dem letzten Wert geschrieben:
cat Werte.csv Datum & Uhrzeit;Aktualisierung;Tagesverbrauch;Tageszähler 06.11.2021 19:52:02;06.11.2021. 19:05:01;35;525 06.11.2021 19:54:02;06.11.2021. 19:05:01;35;525
Meines Erachtens solltest Du aber die einfachste Methode (1. Methode) einfach Datum, Topic, Wert nehmen und mit Pivot Tabellen arbeiten und nach Topic gruppieren - aber da bin ich nicht der Spezialist - das können andere sicher besser.
Aber ich denke ich habs hinbekommen:
Präferierte Lösung:
Wenn Du nut einfach Timestamp, Topic und Wert nimmst, dann bekommst den Linken Teil der Tabelle und kannst daraus über das Pivot das leicht gruppieren.
-
@manfredh-1 Wie gesagt nimm mal die veränderte Change Node und das Topic ist mit dabei.
Jetzt gibt es 2 Möglichkeiten - entweder Du machst im Excel Pivot Tabellen oder Du machst in die Change Nodes entsprechende Semicolons für die zusätzlichen Spalten.
Die letzte Aktualisierung ist aber Käse weil der Timestamp ja durch die Change NOde gesetzt ist.
Für die 1 Variante kannst alle in die modifizierte Change Node laufen lassen,
ansonsten für Spalte 2 brauchst halt für jede Spalte eine andere Change Node.Die 2. Variante erzeugt dann so eine csv
cat Werte.csv Datum & Uhrzeit;Datenpunkt;Aktualisierung;Tagesverbrauch;Tageszähler 06.11.2021 19:24:51;HSV_15_letzte_Aktualisierung;06.11.2021. 19:05:01 06.11.2021 19:24:53;HSV_15_Pellets_Tagesverbrauch;;23 06.11.2021 19:24:54;HSV_15_Pellets_Tageszählerstand;;;522 06.11.2021 19:25:00;HSV_15_letzte_Aktualisierung;06.11.2021. 19:05:01Ich finde das mit den zusätzlichen Spalten pro Datenpunkt eigentlich unschön
Wenn man sicher stellen kann, dass die Datenpunkte einmal in der richtigen Reihenfolge getriggert werden, kann man auch ein Objekt erstellen, dass wäre dann die 3. Möglichkeit:
Dann muss man aber darauf achten, dass die Datenpunkte in der richtigen Reihenfolge einmal aktualisiert werden
In diesem Fall werden immer alle 3 Datenpunkte mit dem letzten Wert geschrieben:
cat Werte.csv Datum & Uhrzeit;Aktualisierung;Tagesverbrauch;Tageszähler 06.11.2021 19:52:02;06.11.2021. 19:05:01;35;525 06.11.2021 19:54:02;06.11.2021. 19:05:01;35;525Meines Erachtens solltest Du aber die einfachste Methode (1. Methode) einfach Datum, Topic, Wert nehmen und mit Pivot Tabellen arbeiten und nach Topic gruppieren - aber da bin ich nicht der Spezialist - das können andere sicher besser.
Aber ich denke ich habs hinbekommen:
Präferierte Lösung:
Wenn Du nut einfach Timestamp, Topic und Wert nimmst, dann bekommst den Linken Teil der Tabelle und kannst daraus über das Pivot das leicht gruppieren. -
@mickym Super vielen Dank für Deine Mühe. Werde mich jetzt mal damit genauer beschäftigen. Und eventuell nochmals nachfragen wenn ich nicht weiterkommen sollte.
@manfredh-1 Wenn Du übrigens Tabstopps haben willst dann änderst Du die JSONATA Zeile in der Change Node wie folgt:
ts & '\t' & topic & '\t' & payload -
Hallo,
wie kann ich um eine bestimmte Uhrzeit den Wert von zwei oder drei Datenpunkten automatisiert in ein Log-/oder CSV-File schreiben.
Dieses wird benötigt für eine Excel-Tabelle, wo das File dann entsprechend verarbeitet wird.
Gibt es dazu eine Möglichkeit (ohne den Weg des händigen Exports über History).
DANKE !!!!!@manfredh-1
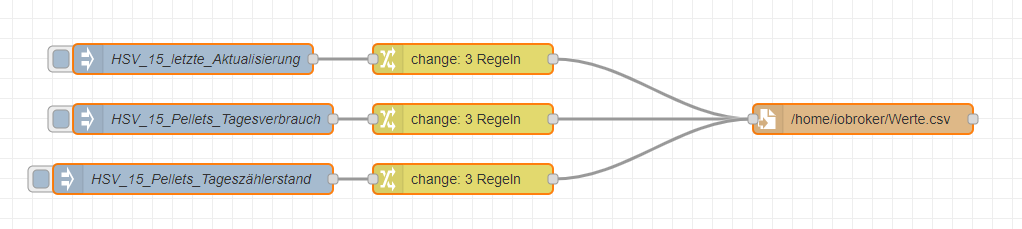
So ich habe nun mal ein Flow geschrieben mit dem man aus den Datenpunkten eine CSV Datei schreiben kann die entsprechend den Datenpunkten - einen Datensatz schreiben.
Sofern ein Satz immer zu einem Zeitpunkt geschrieben werden, kann man die JOIN Node entsprechend konfigurieren, dass immer erst der Satz geschrieben wird, sobald alle Datenpunkte aktualisiert sind. Ist das nicht möglich und soll ein Satz geschrieben werden, sobald ein Datenpunkt aktualisiert wurde muss man eben die Option, dass nach einer bestimmten Anzahl an Aktualisierungen ein Objekt verschickt wird.
Das wichtigste ist, dass hier die CSV Node zum Einsatz kommt, die einem Einiges an Arbeit abnimmt. Die File Node zum Schreiben einer Datei ist aus dem Standardset.
Diese hat eine Eigenart - die man auf jeden Fall beachten muss - insbesondere wenn man auf gemountete Verzeichnisse schreibt (am besten unter /home/iobroker - einhängen und in der fstab definieren). Ich halte es jedoch für besser lokal zu schreiben und nur bei Bedarf zu kopieren, da man sonst halt den Flow wesentlich komplexer zu machen, falls entfernte Ressourcen nicht mehr zur Verfügung stehen. Die Eigenart ist, dass wenn man den Pfad der Datei in die file Node selbst schreibt - bleibt die Datei immer offen. Wenn die Datei nach dem Schreiben einer payload immer geschlossen werden soll, dann muss man die Datei in msg.filename speichern und keine Datei in der file Node definieren.
Um zu Überprüfen, ob die Datei neu erstellt wird oder bereits existiert nutze ich die Nodes - die einige Funktionen zur Dateibehandlung im Allgemeinen zur Verfügung stellt - also auch später zum Kopieren von Dateien:
https://flows.nodered.org/node/node-red-contrib-fs-ops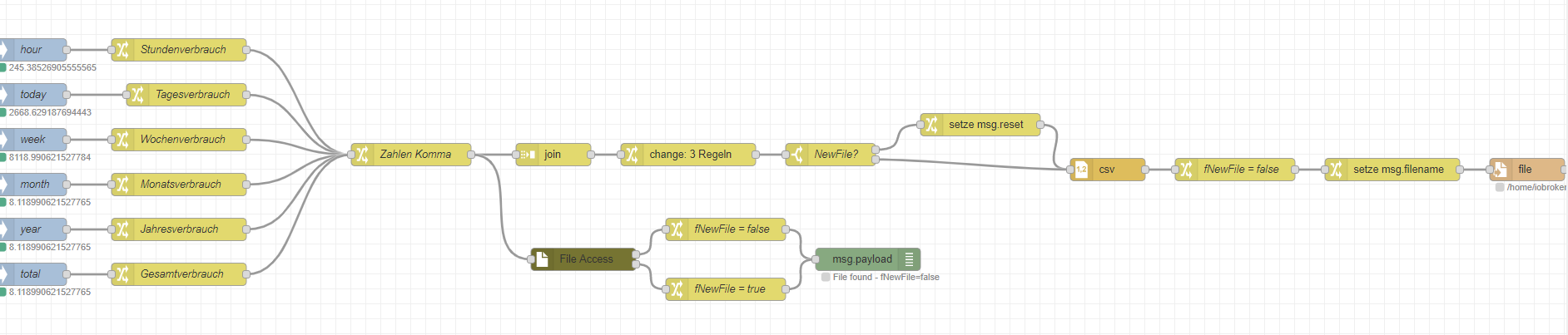
Mit der CSV Node hat man nun die Möglichkeit über das Eigenschaften der Objekte und der Spaltendefinition sowohl die Reihenfolge, als auch Subset definieren, die geschrieben werden können.
Ich überlege mir - eventuell einen eigenen Thread noch zu eröffnen, um ggf. den Flow noch detailierter zu erläutern. Aber klar beantworte ich gerne auch hier weitere Fragen.
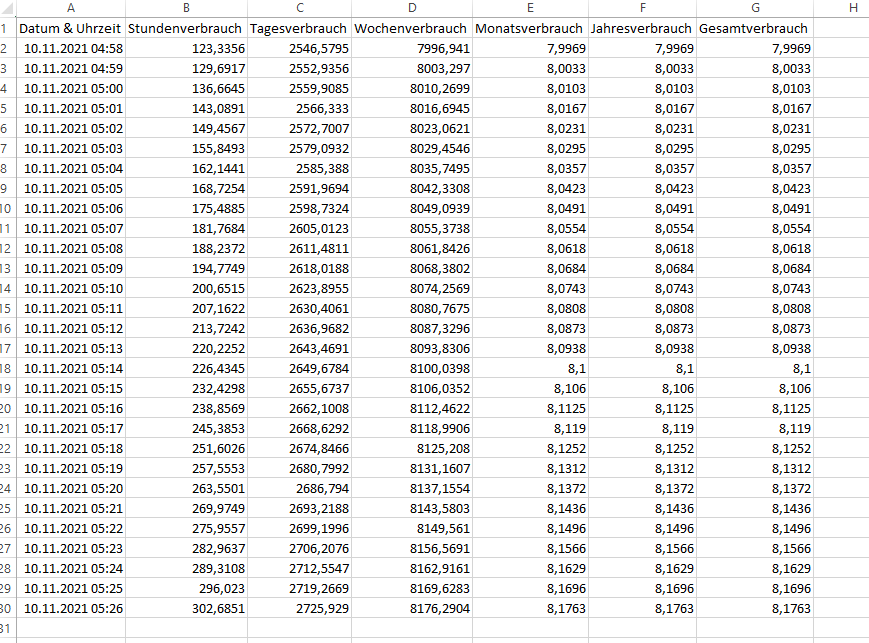
Zu guter Letzt auch die CSV Datei - um selbst den Import sowie die Datenaktualisierung im Excel zu testen:
Jeder Flow bzw. jedes Script, das ich hier poste implementiert jeder auf eigene Gefahr. Flows und Scripts können Fehler aufweisen und weder der Seitenbetreiber noch ich persönlich können hierfür haftbar gemacht werden. Das gleiche gilt für Empfehlungen aller Art.
-
@manfredh-1
So ich habe nun mal ein Flow geschrieben mit dem man aus den Datenpunkten eine CSV Datei schreiben kann die entsprechend den Datenpunkten - einen Datensatz schreiben.
Sofern ein Satz immer zu einem Zeitpunkt geschrieben werden, kann man die JOIN Node entsprechend konfigurieren, dass immer erst der Satz geschrieben wird, sobald alle Datenpunkte aktualisiert sind. Ist das nicht möglich und soll ein Satz geschrieben werden, sobald ein Datenpunkt aktualisiert wurde muss man eben die Option, dass nach einer bestimmten Anzahl an Aktualisierungen ein Objekt verschickt wird.
Das wichtigste ist, dass hier die CSV Node zum Einsatz kommt, die einem Einiges an Arbeit abnimmt. Die File Node zum Schreiben einer Datei ist aus dem Standardset.
Diese hat eine Eigenart - die man auf jeden Fall beachten muss - insbesondere wenn man auf gemountete Verzeichnisse schreibt (am besten unter /home/iobroker - einhängen und in der fstab definieren). Ich halte es jedoch für besser lokal zu schreiben und nur bei Bedarf zu kopieren, da man sonst halt den Flow wesentlich komplexer zu machen, falls entfernte Ressourcen nicht mehr zur Verfügung stehen. Die Eigenart ist, dass wenn man den Pfad der Datei in die file Node selbst schreibt - bleibt die Datei immer offen. Wenn die Datei nach dem Schreiben einer payload immer geschlossen werden soll, dann muss man die Datei in msg.filename speichern und keine Datei in der file Node definieren.
Um zu Überprüfen, ob die Datei neu erstellt wird oder bereits existiert nutze ich die Nodes - die einige Funktionen zur Dateibehandlung im Allgemeinen zur Verfügung stellt - also auch später zum Kopieren von Dateien:
https://flows.nodered.org/node/node-red-contrib-fs-opsMit der CSV Node hat man nun die Möglichkeit über das Eigenschaften der Objekte und der Spaltendefinition sowohl die Reihenfolge, als auch Subset definieren, die geschrieben werden können.
Ich überlege mir - eventuell einen eigenen Thread noch zu eröffnen, um ggf. den Flow noch detailierter zu erläutern. Aber klar beantworte ich gerne auch hier weitere Fragen.
Zu guter Letzt auch die CSV Datei - um selbst den Import sowie die Datenaktualisierung im Excel zu testen:
So das ganze funktioniert zuverlässig - ich habe es nun mal einen halben Tag laufen lassen:
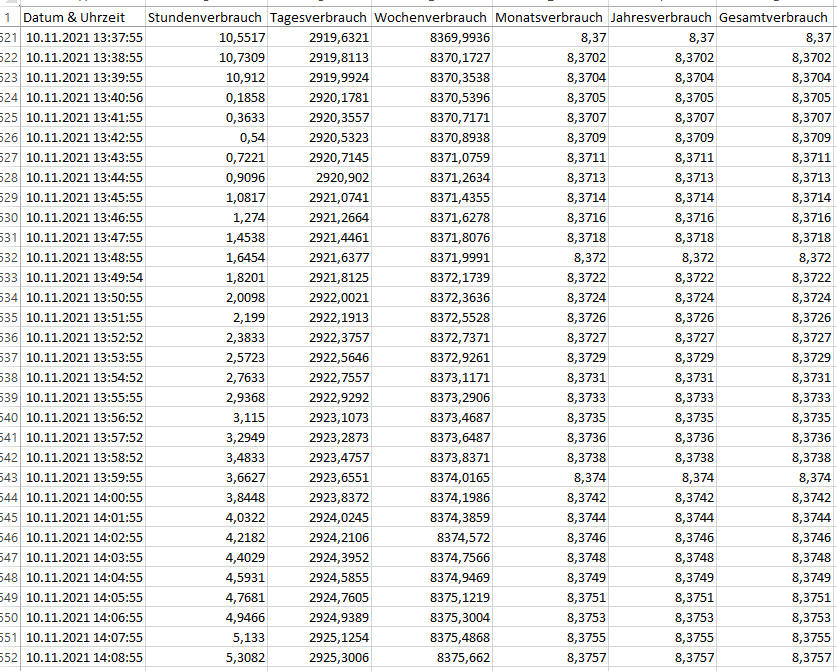
Wie gesagt - um Fehler beim Schreiben auf andere Devices zu vermeiden würde ich es nicht direkt machen, sondern das kopieren. Wenn man unter dem iobroker Homeverzeichnis mounted.
Man kann durchaus auf gemounted devices schreiben - aber wenn die Systeme halt dann mal wegbrechen - neu gebootet werden - dann muss die Behandlung wesentlich komplexer verlaufen
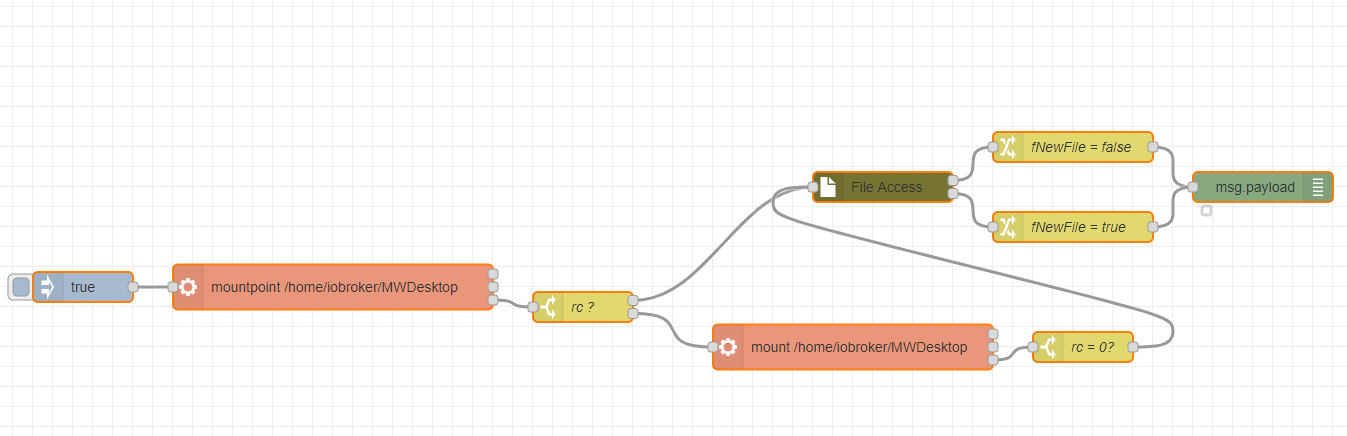 das kann mich sich halt mit einem perodischen Copy sparen.
das kann mich sich halt mit einem perodischen Copy sparen. -
@manfredh-1
So ich habe nun mal ein Flow geschrieben mit dem man aus den Datenpunkten eine CSV Datei schreiben kann die entsprechend den Datenpunkten - einen Datensatz schreiben.
Sofern ein Satz immer zu einem Zeitpunkt geschrieben werden, kann man die JOIN Node entsprechend konfigurieren, dass immer erst der Satz geschrieben wird, sobald alle Datenpunkte aktualisiert sind. Ist das nicht möglich und soll ein Satz geschrieben werden, sobald ein Datenpunkt aktualisiert wurde muss man eben die Option, dass nach einer bestimmten Anzahl an Aktualisierungen ein Objekt verschickt wird.
Das wichtigste ist, dass hier die CSV Node zum Einsatz kommt, die einem Einiges an Arbeit abnimmt. Die File Node zum Schreiben einer Datei ist aus dem Standardset.
Diese hat eine Eigenart - die man auf jeden Fall beachten muss - insbesondere wenn man auf gemountete Verzeichnisse schreibt (am besten unter /home/iobroker - einhängen und in der fstab definieren). Ich halte es jedoch für besser lokal zu schreiben und nur bei Bedarf zu kopieren, da man sonst halt den Flow wesentlich komplexer zu machen, falls entfernte Ressourcen nicht mehr zur Verfügung stehen. Die Eigenart ist, dass wenn man den Pfad der Datei in die file Node selbst schreibt - bleibt die Datei immer offen. Wenn die Datei nach dem Schreiben einer payload immer geschlossen werden soll, dann muss man die Datei in msg.filename speichern und keine Datei in der file Node definieren.
Um zu Überprüfen, ob die Datei neu erstellt wird oder bereits existiert nutze ich die Nodes - die einige Funktionen zur Dateibehandlung im Allgemeinen zur Verfügung stellt - also auch später zum Kopieren von Dateien:
https://flows.nodered.org/node/node-red-contrib-fs-opsMit der CSV Node hat man nun die Möglichkeit über das Eigenschaften der Objekte und der Spaltendefinition sowohl die Reihenfolge, als auch Subset definieren, die geschrieben werden können.
Ich überlege mir - eventuell einen eigenen Thread noch zu eröffnen, um ggf. den Flow noch detailierter zu erläutern. Aber klar beantworte ich gerne auch hier weitere Fragen.
Zu guter Letzt auch die CSV Datei - um selbst den Import sowie die Datenaktualisierung im Excel zu testen:
@mickym sagte in Datenpunkt in LOG oder CSV File schreiben:
Ich überlege mir - eventuell einen eigenen Thread noch zu eröffnen, um ggf. den Flow noch detailierter zu erläutern.
Gute Idee. Bei mir kommt als Ergebnis File not found - fNewFile=true. Naja gut einfach mal Copy und Paste klappt selten bis nie.
Was möchte ich machen.
Ich hole ein wenig aus. Bisher habe ich als Datenbank mysql phpMyAdmin auf meiner NAS genutzt. Lief soweit völlig ohne Probleme und ich dachte auch die Daten wären in der Datenbank gut aufgehoben. Weit gefehlt. Im Laufe des Jahres gab es ein Update und schon konnte man sich an der Datenbank nicht mehr anmelden. Nachdem ich dies dann geschnallt hatte und die Verwendung befindliche Nodes und PW angepasst waren lief alles wieder. Hat mich eine Ecke an Zeit gekostet. Da waren einige Handgriffe notwendig, bis hin zum Neustart von Node Red. Nun habe ich am Freitag ein für die NAS angebotenes Firmwareupdate zum Schließen von Sicherheitslücken aufgespielt. Jetzt kann ich mich an der Datenbank nicht mal mehr anmelden und die Nodes schreiben natürlich auch nichts mehr in die Datenbank. was für ein sinnloser Unfug. Es geht hier um Wettermessdaten und Wasserverbrauchswerte, dafür brauche ich doch keine gesicherte Datenbank, an die man irgenwann auch selber nicht mehr rankommt. Die Wetterdatenaufzeichnungen der letzten drei Jahre sind vermutlich weg. Aber damit könnte ich noch leben.
Für die Zukunft möchte ich eine ganz einfache Datenbank aufbauen, auf die ich zu jedem Zeitpunkt Zugriff habe. Klar der Wunsch wäre die Speicherung auf die NAS gewesen, aber scheint aber etwas kompliziert zu sein. Mir würde auch eine tägliche Wertespeicherung um 24:00 Uhr auf dem RasPi reichen. Bisher hatte ich alle 10 Minuten Werte in die DB geschrieben, Evtl. noch eine monatlichen Sicherung (Kopie) auf der NAS. Ein Zeitstempel im Klartext wäre sehr hilfreich. Für meine Regenmengendarstellung bräuchte ich noch Zugriff auf den letzten Regenmengenwert. Den Wert hatte ich bisher immer aus der Datenbank ausgelesen- Diesen könnte ich mir allerdings auch im Flow noch festhalten.Irgendwie hoffte ich kurz dein Flow könnte die Lösung sein. Jetzt bin ich mir nicht mehr so sicher. Ich mache mich mal an eine eigene Lösung.
Gruß Garf
-
@mickym sagte in Datenpunkt in LOG oder CSV File schreiben:
Ich überlege mir - eventuell einen eigenen Thread noch zu eröffnen, um ggf. den Flow noch detailierter zu erläutern.
Gute Idee. Bei mir kommt als Ergebnis File not found - fNewFile=true. Naja gut einfach mal Copy und Paste klappt selten bis nie.
Was möchte ich machen.
Ich hole ein wenig aus. Bisher habe ich als Datenbank mysql phpMyAdmin auf meiner NAS genutzt. Lief soweit völlig ohne Probleme und ich dachte auch die Daten wären in der Datenbank gut aufgehoben. Weit gefehlt. Im Laufe des Jahres gab es ein Update und schon konnte man sich an der Datenbank nicht mehr anmelden. Nachdem ich dies dann geschnallt hatte und die Verwendung befindliche Nodes und PW angepasst waren lief alles wieder. Hat mich eine Ecke an Zeit gekostet. Da waren einige Handgriffe notwendig, bis hin zum Neustart von Node Red. Nun habe ich am Freitag ein für die NAS angebotenes Firmwareupdate zum Schließen von Sicherheitslücken aufgespielt. Jetzt kann ich mich an der Datenbank nicht mal mehr anmelden und die Nodes schreiben natürlich auch nichts mehr in die Datenbank. was für ein sinnloser Unfug. Es geht hier um Wettermessdaten und Wasserverbrauchswerte, dafür brauche ich doch keine gesicherte Datenbank, an die man irgenwann auch selber nicht mehr rankommt. Die Wetterdatenaufzeichnungen der letzten drei Jahre sind vermutlich weg. Aber damit könnte ich noch leben.
Für die Zukunft möchte ich eine ganz einfache Datenbank aufbauen, auf die ich zu jedem Zeitpunkt Zugriff habe. Klar der Wunsch wäre die Speicherung auf die NAS gewesen, aber scheint aber etwas kompliziert zu sein. Mir würde auch eine tägliche Wertespeicherung um 24:00 Uhr auf dem RasPi reichen. Bisher hatte ich alle 10 Minuten Werte in die DB geschrieben, Evtl. noch eine monatlichen Sicherung (Kopie) auf der NAS. Ein Zeitstempel im Klartext wäre sehr hilfreich. Für meine Regenmengendarstellung bräuchte ich noch Zugriff auf den letzten Regenmengenwert. Den Wert hatte ich bisher immer aus der Datenbank ausgelesen- Diesen könnte ich mir allerdings auch im Flow noch festhalten.Irgendwie hoffte ich kurz dein Flow könnte die Lösung sein. Jetzt bin ich mir nicht mehr so sicher. Ich mache mich mal an eine eigene Lösung.
Gruß Garf
@garf sagte in Datenpunkt in LOG oder CSV File schreiben:
@mickym sagte in Datenpunkt in LOG oder CSV File schreiben:
Ich überlege mir - eventuell einen eigenen Thread noch zu eröffnen, um ggf. den Flow noch detailierter zu erläutern.
Gute Idee. Bei mir kommt als Ergebnis File not found - fNewFile=true. Naja gut einfach mal Copy und Paste klappt selten bis nie.
Was möchte ich machen.
Ich hole ein wenig aus. Bisher habe ich als Datenbank mysql phpMyAdmin auf meiner NAS genutzt. Lief soweit völlig ohne Probleme und ich dachte auch die Daten wären in der Datenbank gut aufgehoben. Weit gefehlt. Im Laufe des Jahres gab es ein Update und schon konnte man sich an der Datenbank nicht mehr anmelden. Nachdem ich dies dann geschnallt hatte und die Verwendung befindliche Nodes und PW angepasst waren lief alles wieder. Hat mich eine Ecke an Zeit gekostet. Da waren einige Handgriffe notwendig, bis hin zum Neustart von Node Red. Nun habe ich am Freitag ein für die NAS angebotenes Firmwareupdate zum Schließen von Sicherheitslücken aufgespielt. Jetzt kann ich mich an der Datenbank nicht mal mehr anmelden und die Nodes schreiben natürlich auch nichts mehr in die Datenbank. was für ein sinnloser Unfug. Es geht hier um Wettermessdaten und Wasserverbrauchswerte, dafür brauche ich doch keine gesicherte Datenbank, an die man irgenwann auch selber nicht mehr rankommt. Die Wetterdatenaufzeichnungen der letzten drei Jahre sind vermutlich weg. Aber damit könnte ich noch leben.
Für die Zukunft möchte ich eine ganz einfache Datenbank aufbauen, auf die ich zu jedem Zeitpunkt Zugriff habe. Klar der Wunsch wäre die Speicherung auf die NAS gewesen, aber scheint aber etwas kompliziert zu sein. Mir würde auch eine tägliche Wertespeicherung um 24:00 Uhr auf dem RasPi reichen. Bisher hatte ich alle 10 Minuten Werte in die DB geschrieben, Evtl. noch eine monatlichen Sicherung (Kopie) auf der NAS. Ein Zeitstempel im Klartext wäre sehr hilfreich. Für meine Regenmengendarstellung bräuchte ich noch Zugriff auf den letzten Regenmengenwert. Den Wert hatte ich bisher immer aus der Datenbank ausgelesen- Diesen könnte ich mir allerdings auch im Flow noch festhalten.Irgendwie hoffte ich kurz dein Flow könnte die Lösung sein. Jetzt bin ich mir nicht mehr so sicher. Ich mache mich mal an eine eigene Lösung.
Gruß Garf
Na ich verstehe nicht, warum der Flow es nicht sein kann? Für die Überprüfung der Existenz einer Datei muss man halt die angegebenen Nodes noch installieren. Erst kann man es mit einer lokalen Datei untersuchen. Mit der Abprüfung ob die Datei existiert oder nicht wird ja nur unterschieden, ob eine Überschrift in die 1. Zeile geschrieben werden muss. Das es am Anfang mit einer File Not Found Nachricht losgeht ist doch normal. Ansonsten muss man halt untersuchen wo das Problem liegt.
Schließe halte Datenpunkte - iobroker In Nodes zu Beginn des Flows an - und behalte mal als Datei unter dem iobroker Homeverzeichnis wie in der Change Node angegeben bei. Wie gesagt DU kannst nicht einfach irgendwo hinschreiben, da alles unter der iobroker Kennung läuft. Ansonsten kann man unter dem iobroker Home Verzeichnis ein externes Vz. mounten - hat aber wie gesagt ein Problem, wenn das NAS nicht verfügbar ist, dann muss man das Ganze halt mitüberprüfen. Natürlich kannst Du gerne Deine Lösung nehmen. Aber wie gesagt file not found ist ganz normal und wird erst beim Schreiben des nächsten Datensatzes ja geändert.
-
@garf sagte in Datenpunkt in LOG oder CSV File schreiben:
@mickym sagte in Datenpunkt in LOG oder CSV File schreiben:
Ich überlege mir - eventuell einen eigenen Thread noch zu eröffnen, um ggf. den Flow noch detailierter zu erläutern.
Gute Idee. Bei mir kommt als Ergebnis File not found - fNewFile=true. Naja gut einfach mal Copy und Paste klappt selten bis nie.
Was möchte ich machen.
Ich hole ein wenig aus. Bisher habe ich als Datenbank mysql phpMyAdmin auf meiner NAS genutzt. Lief soweit völlig ohne Probleme und ich dachte auch die Daten wären in der Datenbank gut aufgehoben. Weit gefehlt. Im Laufe des Jahres gab es ein Update und schon konnte man sich an der Datenbank nicht mehr anmelden. Nachdem ich dies dann geschnallt hatte und die Verwendung befindliche Nodes und PW angepasst waren lief alles wieder. Hat mich eine Ecke an Zeit gekostet. Da waren einige Handgriffe notwendig, bis hin zum Neustart von Node Red. Nun habe ich am Freitag ein für die NAS angebotenes Firmwareupdate zum Schließen von Sicherheitslücken aufgespielt. Jetzt kann ich mich an der Datenbank nicht mal mehr anmelden und die Nodes schreiben natürlich auch nichts mehr in die Datenbank. was für ein sinnloser Unfug. Es geht hier um Wettermessdaten und Wasserverbrauchswerte, dafür brauche ich doch keine gesicherte Datenbank, an die man irgenwann auch selber nicht mehr rankommt. Die Wetterdatenaufzeichnungen der letzten drei Jahre sind vermutlich weg. Aber damit könnte ich noch leben.
Für die Zukunft möchte ich eine ganz einfache Datenbank aufbauen, auf die ich zu jedem Zeitpunkt Zugriff habe. Klar der Wunsch wäre die Speicherung auf die NAS gewesen, aber scheint aber etwas kompliziert zu sein. Mir würde auch eine tägliche Wertespeicherung um 24:00 Uhr auf dem RasPi reichen. Bisher hatte ich alle 10 Minuten Werte in die DB geschrieben, Evtl. noch eine monatlichen Sicherung (Kopie) auf der NAS. Ein Zeitstempel im Klartext wäre sehr hilfreich. Für meine Regenmengendarstellung bräuchte ich noch Zugriff auf den letzten Regenmengenwert. Den Wert hatte ich bisher immer aus der Datenbank ausgelesen- Diesen könnte ich mir allerdings auch im Flow noch festhalten.Irgendwie hoffte ich kurz dein Flow könnte die Lösung sein. Jetzt bin ich mir nicht mehr so sicher. Ich mache mich mal an eine eigene Lösung.
Gruß Garf
Na ich verstehe nicht, warum der Flow es nicht sein kann? Für die Überprüfung der Existenz einer Datei muss man halt die angegebenen Nodes noch installieren. Erst kann man es mit einer lokalen Datei untersuchen. Mit der Abprüfung ob die Datei existiert oder nicht wird ja nur unterschieden, ob eine Überschrift in die 1. Zeile geschrieben werden muss. Das es am Anfang mit einer File Not Found Nachricht losgeht ist doch normal. Ansonsten muss man halt untersuchen wo das Problem liegt.
Schließe halte Datenpunkte - iobroker In Nodes zu Beginn des Flows an - und behalte mal als Datei unter dem iobroker Homeverzeichnis wie in der Change Node angegeben bei. Wie gesagt DU kannst nicht einfach irgendwo hinschreiben, da alles unter der iobroker Kennung läuft. Ansonsten kann man unter dem iobroker Home Verzeichnis ein externes Vz. mounten - hat aber wie gesagt ein Problem, wenn das NAS nicht verfügbar ist, dann muss man das Ganze halt mitüberprüfen. Natürlich kannst Du gerne Deine Lösung nehmen. Aber wie gesagt file not found ist ganz normal und wird erst beim Schreiben des nächsten Datensatzes ja geändert.
@mickym sagte in Datenpunkt in LOG oder CSV File schreiben:
Na ich verstehe nicht, warum der Flow es nicht sein kann?
Da sind wir schon Zwei. Ich robbe mich gerade so an das Thema ran und verstehe in kleinen Schritten was Du da mit den Nodes machst. iobroker läuft bei mir nicht. Ich habe mich für einen anderen Weg entschieden. Meine Daten bekäme ich über den MQTT-Broker und den MQTT Nodes.
Ich muss mal schauen inwieweit ich den Flow auch für nutzbar bekomme. Die ersten Eigenversuche mit dem Erstellen der csv-Datei zeigen deutlich welche Probleme Du mit dem Flow gelöst hast. Sieht super aus und kann direkt in Excel weiter verarbeitet werden.
Ich schau mal wie weit ich kommen werde.
Danke schon einmal für deine tolle Arbeit.
-
@mickym sagte in Datenpunkt in LOG oder CSV File schreiben:
Na ich verstehe nicht, warum der Flow es nicht sein kann?
Da sind wir schon Zwei. Ich robbe mich gerade so an das Thema ran und verstehe in kleinen Schritten was Du da mit den Nodes machst. iobroker läuft bei mir nicht. Ich habe mich für einen anderen Weg entschieden. Meine Daten bekäme ich über den MQTT-Broker und den MQTT Nodes.
Ich muss mal schauen inwieweit ich den Flow auch für nutzbar bekomme. Die ersten Eigenversuche mit dem Erstellen der csv-Datei zeigen deutlich welche Probleme Du mit dem Flow gelöst hast. Sieht super aus und kann direkt in Excel weiter verarbeitet werden.
Ich schau mal wie weit ich kommen werde.
Danke schon einmal für deine tolle Arbeit.
@garf sagte in Datenpunkt in LOG oder CSV File schreiben:
Da sind wir schon Zwei. Ich robbe mich gerade so an das Thema ran und verstehe in kleinen Schritten was Du da mit den Nodes machst. iobroker läuft bei mir nicht. Ich habe mich für einen anderen Weg entschieden. Meine Daten bekäme ich über den MQTT-Broker und den MQTT Nodes.
Nun dann entweder die aus den MQTT kommenden Strings in Zahlen umwandeln:
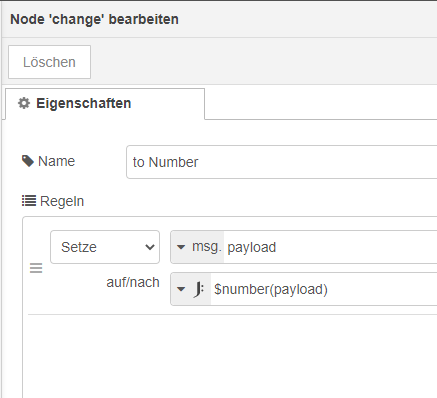
Ansonsten musst halt Strings manipulieren.
Die topics der Change Nodes musst Du den Spaltenüberschriften anpassen und die Reihenfolge legst Du über msg.columns fest.Und wie gesagt die Eigenart beachten:
Die Eigenart ist, dass wenn man den Pfad der Datei in die file Node selbst schreibt - bleibt die Datei immer offen. Wenn die Datei nach dem Schreiben einer payload immer geschlossen werden soll, dann muss man die Datei in msg.filename speichern und keine Datei in der file Node definieren.
-
@garf sagte in Datenpunkt in LOG oder CSV File schreiben:
Da sind wir schon Zwei. Ich robbe mich gerade so an das Thema ran und verstehe in kleinen Schritten was Du da mit den Nodes machst. iobroker läuft bei mir nicht. Ich habe mich für einen anderen Weg entschieden. Meine Daten bekäme ich über den MQTT-Broker und den MQTT Nodes.
Nun dann entweder die aus den MQTT kommenden Strings in Zahlen umwandeln:
Ansonsten musst halt Strings manipulieren.
Die topics der Change Nodes musst Du den Spaltenüberschriften anpassen und die Reihenfolge legst Du über msg.columns fest.Und wie gesagt die Eigenart beachten:
Die Eigenart ist, dass wenn man den Pfad der Datei in die file Node selbst schreibt - bleibt die Datei immer offen. Wenn die Datei nach dem Schreiben einer payload immer geschlossen werden soll, dann muss man die Datei in msg.filename speichern und keine Datei in der file Node definieren.
-
Soweit bin ich noch nicht. Die Fehlermeldung bleibt, auch wenn sechs Werte eingegangen sind. Simuliere die sechs Werte mit inject-Nodes. Die csv-Datei sieht noch nicht wie gewünscht aus. Wo habe ich da noch einen Fehler?
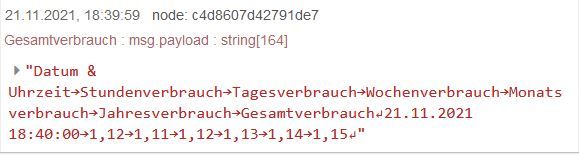 Payload
Payload csv-Datei
csv-Datei -
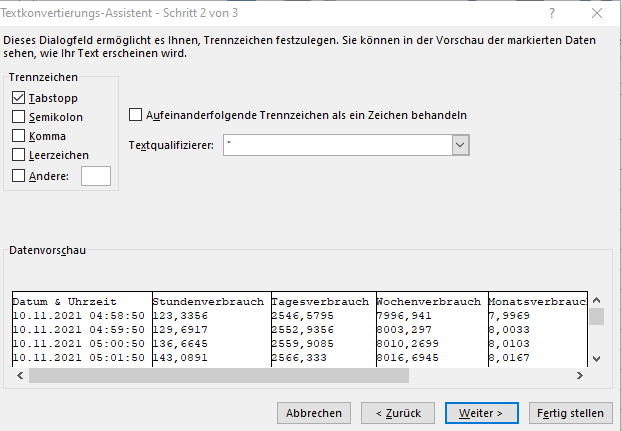
@garf Also Du musst im Excel das einmal richtig importieren - in diesem Fall ist es ein Tab:
Also im Excel Daten ==> aus Text dann macht sich der Assitent auf und dann Tab als Trennzeichen auswählen:

-
Ich dachte es mir schon. CSV Dateien sind im Prinzip ja nur Textdateien. Ich wandel mal um, mal sehen wie es dann aussieht.
@garf sagte in Datenpunkt in LOG oder CSV File schreiben:
Ich dachte es mir schon. CSV Dateien sind im Prinzip ja nur Textdateien. Ich wandel mal um, mal sehen wie es dann aussieht.
Mach so wie ich gerade beschrieben habe.
Wenn diese Datei dann wächst brauchst im Excel dann unter Daten nur noch auf aktualisieren gehen.
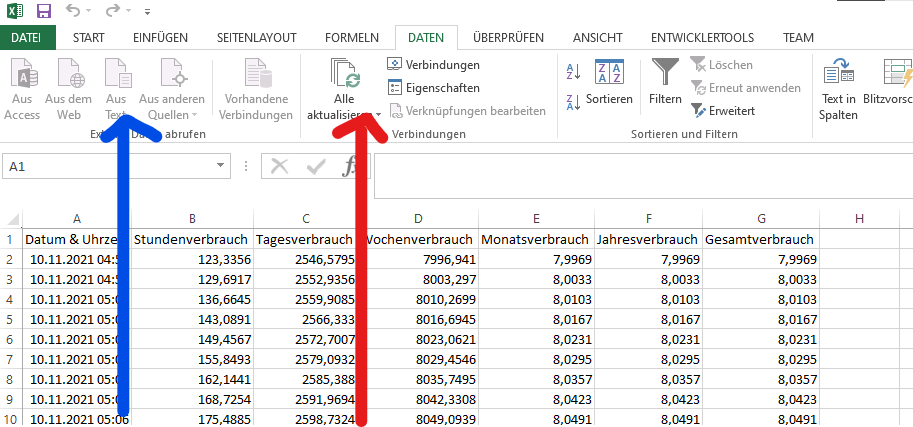
und auch nicht wieder neu importieren.
Also 1. blauer Pfeil, Tab als Trennzeichen wählen, 2. wenn Datei wächst nur noch aktualisieren roter Pfeil.
-
@garf sagte in Datenpunkt in LOG oder CSV File schreiben:
Ich dachte es mir schon. CSV Dateien sind im Prinzip ja nur Textdateien. Ich wandel mal um, mal sehen wie es dann aussieht.
Mach so wie ich gerade beschrieben habe.
Wenn diese Datei dann wächst brauchst im Excel dann unter Daten nur noch auf aktualisieren gehen.
und auch nicht wieder neu importieren.
Also 1. blauer Pfeil, Tab als Trennzeichen wählen, 2. wenn Datei wächst nur noch aktualisieren roter Pfeil.
Alles klar. Die Datei war noch geöffnet und mit Text in Spalte kommt dann folgendes Ergebnis heraus:

Ergebnis sieht mehr als brauchbar aus. Werde gleich den von dir beschriebenen Weg probieren. Insgesamt kann es sich schon mal sehen lassen.
-
Alles klar. Die Datei war noch geöffnet und mit Text in Spalte kommt dann folgendes Ergebnis heraus:
Ergebnis sieht mehr als brauchbar aus. Werde gleich den von dir beschriebenen Weg probieren. Insgesamt kann es sich schon mal sehen lassen.
@garf sagte in Datenpunkt in LOG oder CSV File schreiben:
Alles klar. Die Datei war noch geöffnet und mit Text in Spalte kommt dann folgendes Ergebnis heraus:
Ergebnis sieht mehr als brauchbar aus. Werde gleich den von dir beschriebenen Weg probieren. Insgesamt kann es sich schon mal sehen lassen.
Dann hast Du wahrscheinlich wie ich gesagt habe - den Dateipfad fest in die file Node geschrieben. Ich habe nicht umsonst den fetten Text hier reingeschrieben:
https://forum.iobroker.net/topic/49120/datenpunkt-in-log-oder-csv-file-schreiben/8?_=1637518991766
wie gesagt Dateinamen nicht in die File Node schreiben - dann wird die Datei auch nach jedem Datensatz geschlossen.
Bin in der nächsten Zeit nur sporadisch an Board.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
302
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge