

[Umfrage] Hochverfügbarer ioBroker auf RPIs
-
Ich würde neben dem "Master" auch einmal einen Blick auf den Rest des Systems werfen.
Da gibt es meines Erachtens ebenfalls eine Menge an "Single Points of Failures (SPoF)". Der Server ist da nur einer.
Wenn man die anderen SPoF außer Acht lässt, hat man unter Umständen nicht wirklich etwas gewonnen.
Außer den Konzepten der Architektur könnte es auch sinnvoll sein, Ausfallwahrscheinlichkeiten zu bedenken und zunächst vor allem die Punkte mit (relativ) hoher Ausfallwahrscheinlichkeit zu "stärken".
Dann wäre zu überlegen, was wirklich redundant sein muss und was redundant sein könnte (zusäätzlicher Komfort).
Je geringer die notwendige Redundanz ist, desto einfacher dürfte das Konzept werden.
-
Reicht es, wenn gewisse Grundfuktionen weiter laufen? Welche wären das?
-
Muss Bedienung weiter möglich sein?
-
Muss reine Visualisierung redundant sein?
-
Mit welchen Ausfällen kann ich über eine gewisse Zeit leben?
In der Anlagenautomatisierung versucht man Inseln zu schaffen, die über eine übergeordnete Instanz gesteuert werden (im Sinn von Vorgaben). Diese Inseln sollten möglichst völlig autark weiterlaufen können (natürlich ohne Änderung / Bedienung über die übergeordnete Instanz).
Das gibt einem die Möglichkeit einzelne wichtige Inseln betriebssicherer zu machen (z.B. durch Redundanz), ohne gleich alles redundant zu machen.
Im Redundanzkonzept sollte auch das (bzw. die) Kommunikationsnetz(e) betrachtet werden. Wie stabil sind diese? Welche Fehler können auftreten? Welche SPoF gibt es hier? Welche Auswirkung haben Fehler in den Netzen?
Dann noch die Aktoren und Sensoren: Wie sicher und stabil sind dies? Diese Frage muss auch Messungen und Aktionen umfassen. Es macht wenig Sinn, hier dann unzuverlässige Geräte zu nutzen, wenn hohe Verfügbarkeit gefordert ist.
In der Automatisierung habe ich Systeme realisiert, die neben der Redundanz der Steuerung auch redundante Ansteuerungen (I/O), redundante Netze und Redundanz bei Aktoren und Sensoren beinhaltet haben. Das sind dann echt komplexe Projekte. Und Firmen investieren für so etwas sehr viel Geld, falls dies benötigt wird.
Ich möchte damit den Gedanken von Stabilostick nicht kaputt machen.
Er ist auf jeden Fall ein erster Ansatz für das Thema "Hochverfügbarkeit". Es ist aber wichtig, dass die Grenzen dieser Lösungen auch verstanden werden. Sonst ist mit viel Frust zu rechnen.
-
-
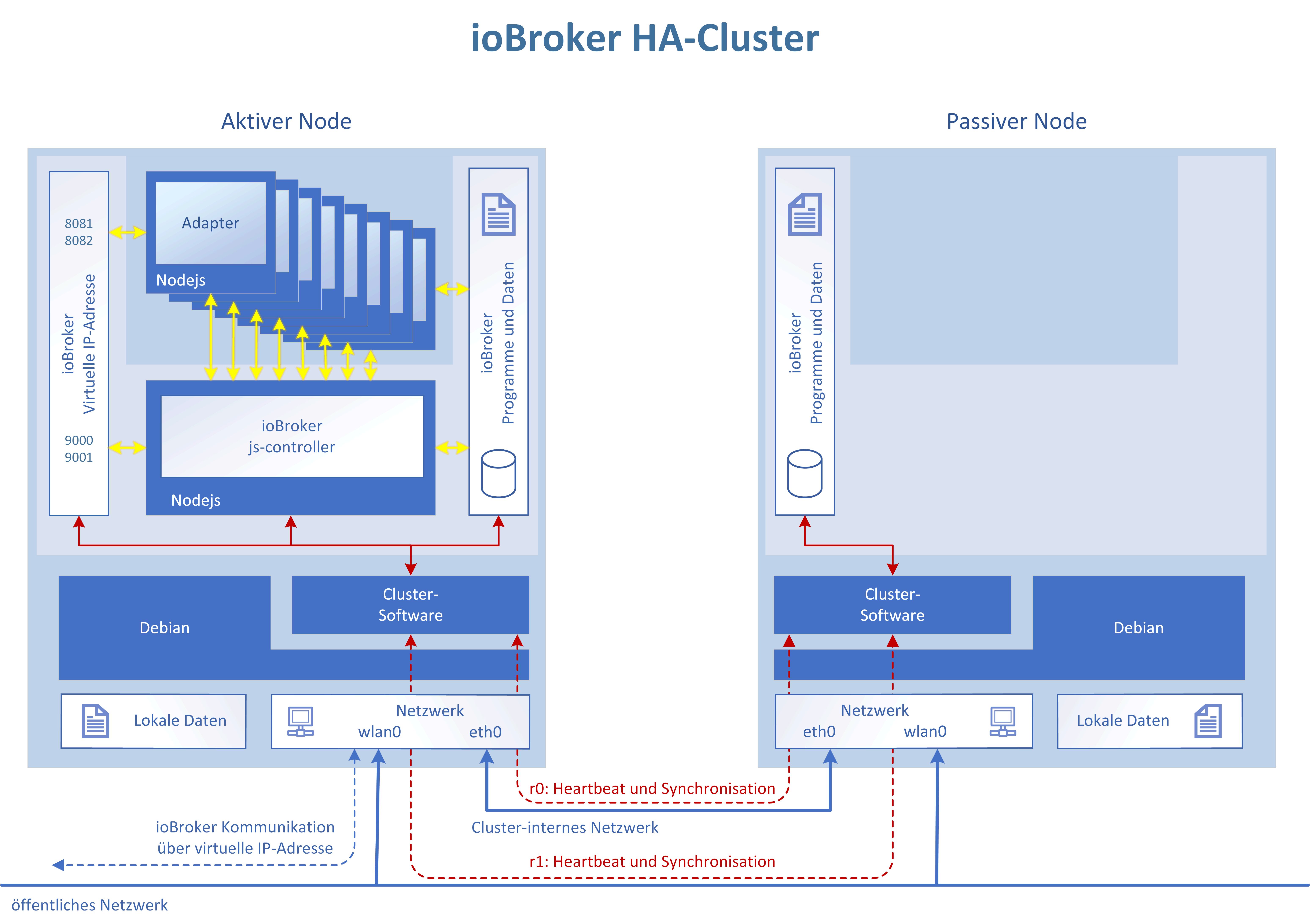
Hochverfügbarkeit für Arme: Identisches inaktives Standby System, welches durch ein externes System aktiviert werden kann. `
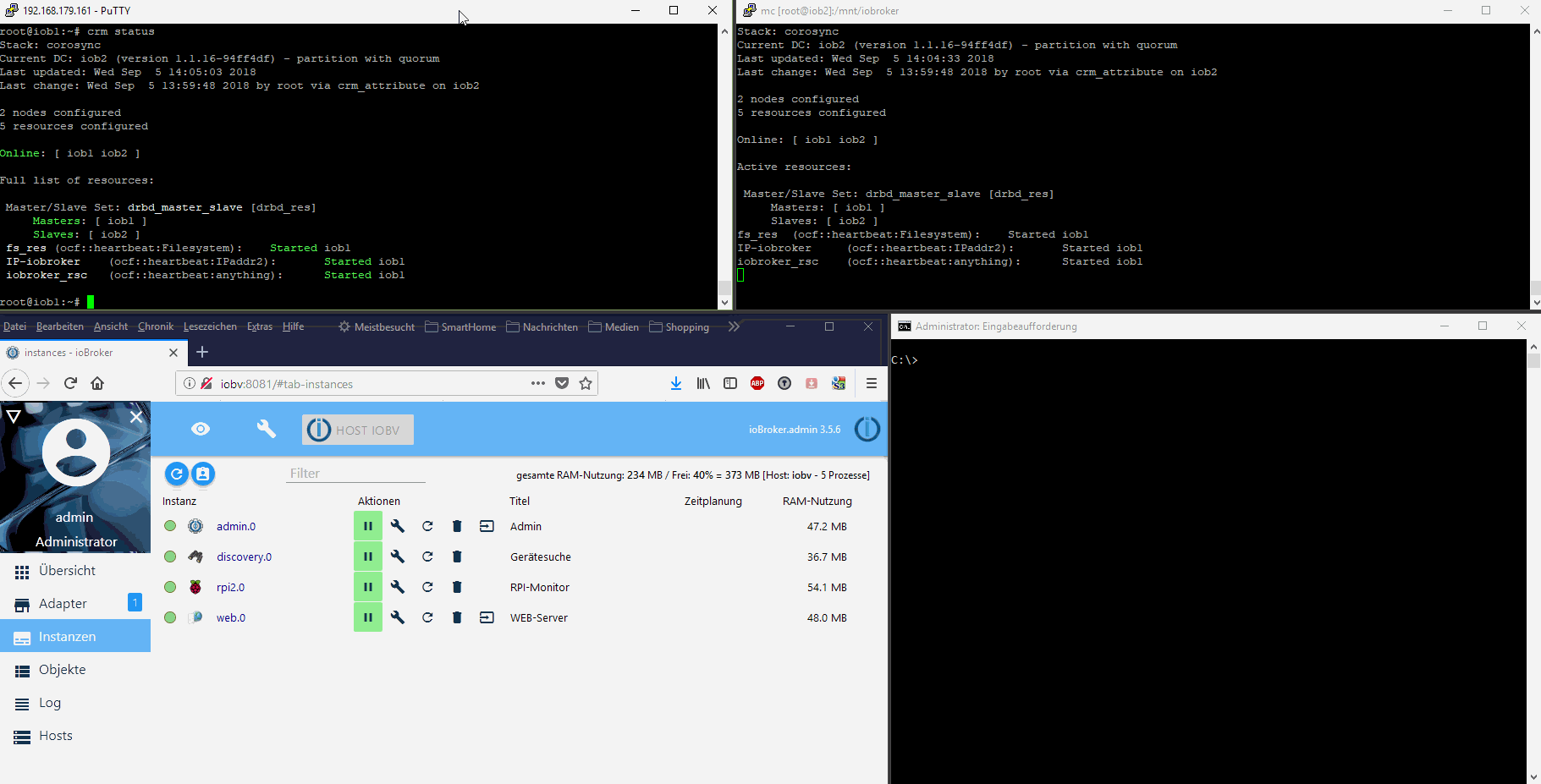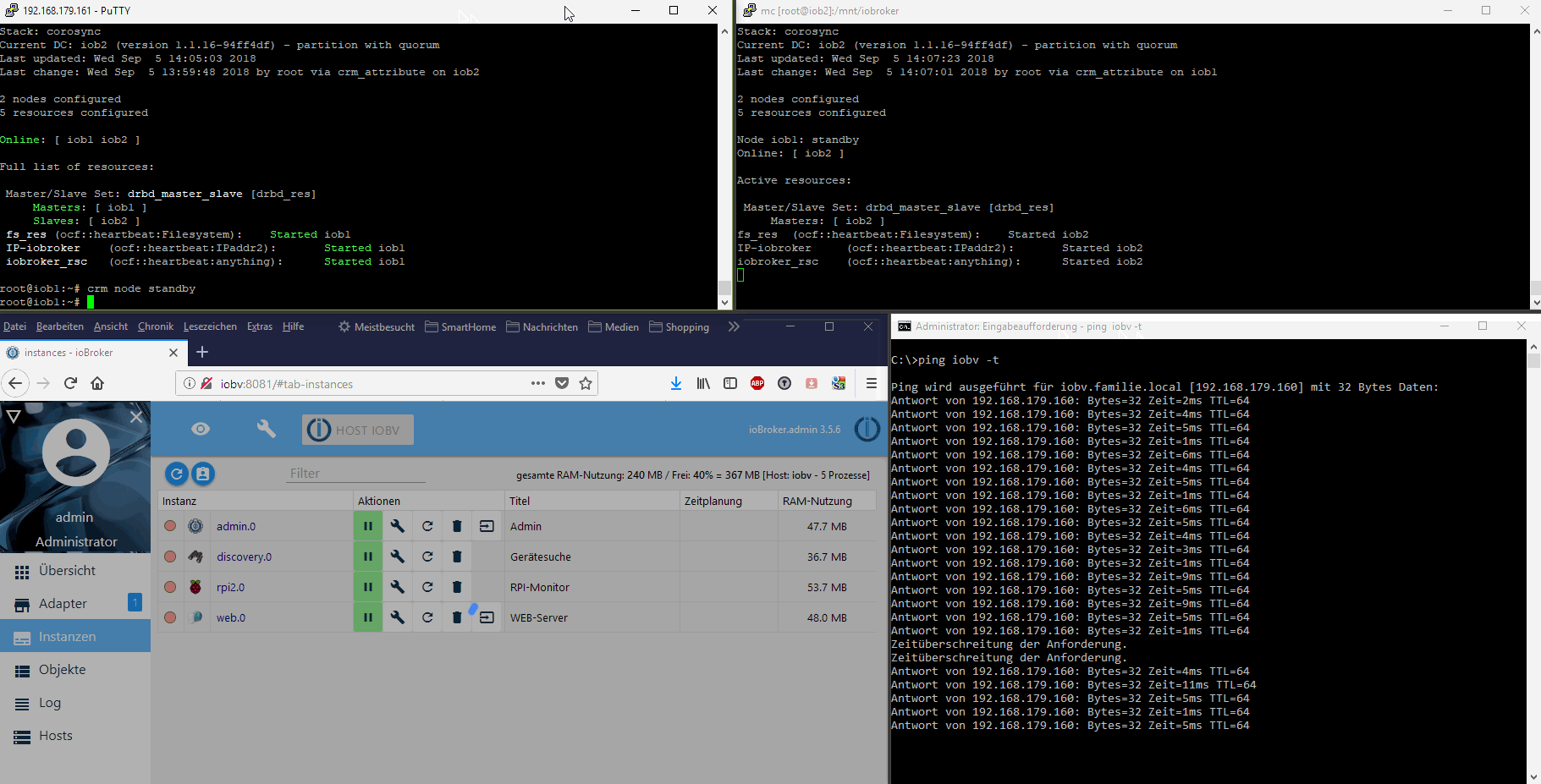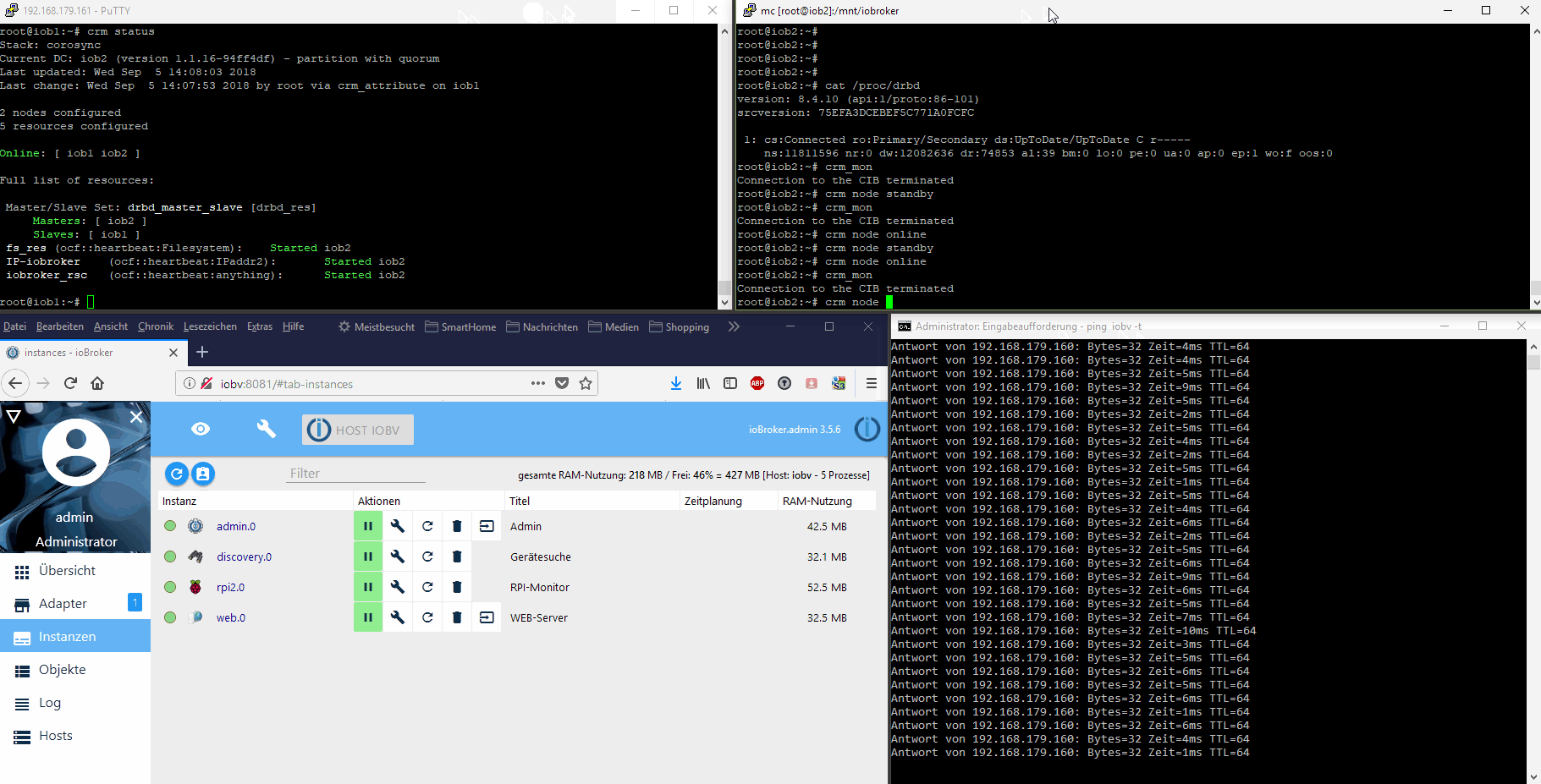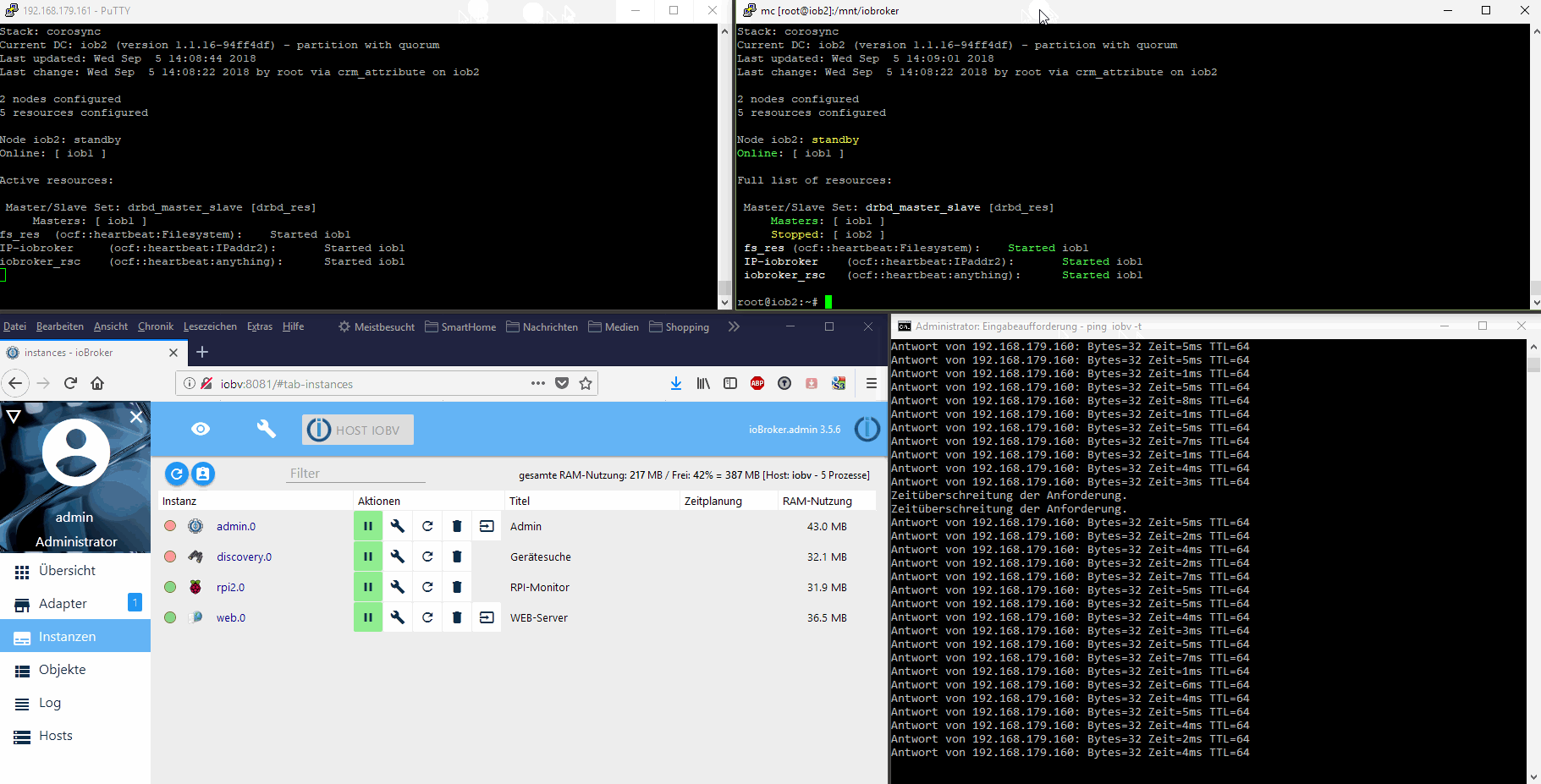
Wie sorgst Du dafür, dass die Daten auf beiden Systemen gleich sind? Das hier ist ein Shared Nothing, Aktiv-Passive-Cluster mit einem Filesystem auf einen Distributed Block Device.
Hier erfolgt die Aktivierung nicht manuell, sondern vollautomatisch. Und ALLE ioBroker-Daten und Adapter sind auf allen Nodes immer zu 100% identisch. Das ist kein HA für Arme. Aber trotzdem günstig (vgl. die HW die Du bei Deiner HA für Arme-Lösung auch vorhalten darfst und nicht die Sicherheit hast). :D
Bei echter HA brauchst du mind. 3 Systeme, sonst kannst du in ein Split-Brain reinlaufen. Idealerweise kombiniert mit STONITH Mechanismus. `
Das hier ist echte HA. Nur - es geht in diesem Fall auch mit zwei Nodes. Und die beiden schaltbaren Steckdosen sind für das erzwungene Ausschalten (Stonith = Shoot The Other Node In The Head) des fehlerbehafteten Knotens - genau wie Du schreibst.
Deswegen aber auch die Bitte um Mithilfe. `
Hi,
Die Lösung ist für Arme, weil eben der ganze Automatismus fehlt und man einiges manuell machen muss. Weniger Komfort, weniger Sicherheit, aber halt auch weniger Komplexität und weniger Wissen beim Anwender nötig.
Bei nur zwei Nodes kann es dir beim Ausfall des Netzwerks passieren, dass beide denken, dass der andere tot ist und ihn mit dem STONITH Device abschießen. Mit einem dritten Node hast du einen Mehrheitsentscheid für das Abschießen. Und wenn das Netzwerk ausfallen sollte. gibt es keine Mehrheit und daher wird der aktive Node nicht abgeschossen, aber es übernimmt auch keiner der anderen beiden Nodes. Es läuft dann also erstmal weiter. Schön wär für sowas natürlich ein HA Switch Stack mit redundanter Anbindung zu jeden Node, aber dann wird es für den Privathaushalt schon etwas sehr teuer.
Beim Filesystem wäre GlusterFS vielleicht noch eine Option, es hat ein paar Vorteile, nicht auf Block Ebene, sondern auf File Ebene zu arbeiten. (Aber klar auch Nachteile)
Viele Grüße
Alex
-
Hallo Karl_999,
wie Du selbst schreibst, teilt man das Problem HA in der Regel in viele kleine Teillösungen auf, die über definierte Schnittstellen, klar geregelte Verfügbarkeiten, Service Level Agreements und Leuten mit Wissen und Praxis zusammengehalten werden. Eine Abteilung stellt das SAN bereit, die andere das Netzwerk und die Dritte die Serverhardware. Und dazu gibt es noch Zuständige für Backup/Restore, Betrieb und Monitoring.
Wir müssen es hier einfacher halten. Ich bin zuhause - bezogen auf die Backendtechnik - alleine. Meine Frau mag nichts von Technik wissen, freut sich aber über die Automatismen, an die sie sich inzwischen gewöhnt hat. Und mir graut vor dem Moment, an dem ich nicht mehr bin und etwas nicht geht. Dann bleibt wohl nur der Rückbau.
Bislang haben wir bis auf das automatische Starten von "hängengebliebenen" Adaptern im ioBroker fast nichts. Etwas Monitoring und ein Autostart-Script. Aus- und Einschalten. Keine Watchdog für die Hardware, keine redundante Datenhaltung, kein automatisches Failover, keine … nichts. Mir ist nicht bekannt, ob wir uns da von anderen Lösungen wie openHAB oder FHEM unterscheiden.
Dazu kommt, dass man aufgrund der (positiven) Vielseitigkeit von ioBroker so gut wie keine einheitlichen Standardverfahren für alle möglichen Funk-, Wired, CCU, Homee, .... , Heizungsanlagen und Smartmetern global aus den Ärmeln schütteln kann. Jedes ioBroker-System ist in seiner Gesamtheit individuell.
Ja, man muss sich Gedanken machen, was einem wichtig (und ggf. auch teuer) ist. Aber es gibt eine Komponente, die überall vorhanden ist.
Bei und mit dem ioBroker haben wir auf dem ersten Blick einen SPoF. Er ist das zentrale Logik- und Kommunikationsmodul. Natürlich zusammen mit seiner Infrastrukturanbindung. Er muss mindestens HA sein, damit man sich dann Gedanken machen kann, welche Schnittstellen/Sensoren/Aktoren auch bei einem Stromausfall noch laufen müssen. Dafür muss ich dann ggf. auch Geld in die Hand nehmen, um diese über USV an das Stromnetz anzuschließen. Oder gleich welche mit Batterie nehmen. Oder enOcean. Oder...
Einer HA-Lösung für die ioBroker-Software selbst kann man standardisieren. In dem man wie hier z.B. sagt, wir unterstützen zuerst einmal genau die folgenden Infrasturkurkomponenten. Und genau die Softwareversion. Sonst keine. Und eine gute Dokumentation bereitstellt.
Wie sähe es denn bei Dir aus? Was sagen Dir Deine Erfahrungen mit HA über Deine Hausautomatisationslösung und ioBroker?
-
Hallo Alexander,
auch Dir ein herzliches Danke für Deine kritischen Anmerkungen.
> Die Lösung ist für Arme, weil eben der ganze Automatismus fehltWas fehlt bei meinem Lösungsansatz? Was muss man wann manuell machen? Ich bitte um Beispiele. Hast Du Dir mein Video oben angesehen? Oder meinst Du Deinen Vorschlag, einfach ein Standby-System nebenhin zu stellen. Dann greift aber Punkt 3 aus meiner Liste oben. Keine HA. Nicht mal für Arme.
> Bei nur zwei Nodes kann es dir beim Ausfall des Netzwerks passieren, dass beide denken, dass der andere tot istIch kenne das Thema. Hier letztendlich (hoffentlich) nicht. Die Netzwerkkommunikation ist redundant ausgelegt und die Clusterkommunikation wird über zwei unabhängige Wege geprüft (Public/Private-Network). Eine der beiden Kommunikationenwege geht nicht über einen Switch.
-
Hi,
> Die Lösung ist für Arme, weil eben der ganze Automatismus fehltWas fehlt bei meinem Lösungsansatz? Was muss man wann manuell machen? `
Sorry, mißverstädlich von mir geschrieben. Ich meinte nicht deinen Ansatz, sondern das, was ich bei meinem ersten Post schon so bezeichnet hatte. Und ja, da greift dein Punkt drei, die Frage ist nur, reicht das nicht für viele schon aus? Ich für mich sehe es ausreichend aus, aber bei mir funktionieren auch alle wichtigen Dinge, wenn das Smarthome abgestürzt ist, nur bei weitem nicht so komfortabel. Aber das sollte man bewusst entscheiden und ich finde deine Gedanken/Bemühungen in die Richtung echtes HA sehr toll.
> Bei nur zwei Nodes kann es dir beim Ausfall des Netzwerks passieren, dass beide denken, dass der andere tot istIch kenne das Thema. Hier letztendlich (hoffentlich) nicht. Die Netzwerkkommunikation ist redundant ausgelegt und die Clusterkommunikation wird über zwei unabhängige Wege geprüft (Public/Private-Network). Eine der beiden Kommunikationenwege geht nicht über einen Switch. `
Einfaches, aber leider realisttisches Problemszenario beim Pi: Kurze Undervoltage, USB wird deaktiviert, LAN (welches ja intern an USB hängt) und WLAN sind auf einen Schlag kurz weg. –> Gesamtsystem über Stonith aus.
Viele Grüße
Alex
-
Hihi, zweiter hat kein Undervoltage, erkennt den ersten nicht mehr, schaltet den ersten deshalb hart aus und übernimmt automatisch die Rolle als Master. Die Daten hat er ja alle.
Erster hat keine Chance zum Schalten. Schließlich ist seine Kommunikation tod oder er ist zu langsam.
-
Habe nur kurz drübergeflogen. Eine Erhöhung der Verfügbarkeit auf RPI ist ziemlich relevant für mich, im Optimalfall sollte hierbei aber kein zweiter Host nötig sein.
Wichtige Themen sind IMO:
-
USV (diese sollte aber keinen negativen Einfluss auf das Startverhalten haben)
-
Erhöhung der SD-Lebensdauer (z.B. durch boot-only SD + Daten-SSD)
-
Watchdog-Integration (wenn ioBroker oder bestimmte Adapter längere Zeit nicht reagieren, bzw die CPU auf 100% festhängt, Host neustarten)
-
… [?]
Bezüglich Integration von Funk-Platinen hatte ich mir in anderem Kontext schonmal Gedanken gemacht. Über eine reine Spinnerei kam das aber noch nicht hinaus:
-
Erstellen eines oder mehrerer Fake-Serialports auf dem Host (in Software)
-
Diese Software packt die Daten dieser Fake-Serialports in ein eigenes Protokoll und schreibt sie in den GPIO
-
An den eigentlichen Serialport (GPIO) sind mehrere Mikrocontroller angeschlossen (in Reihe geschaltet), die beim Empfang von Daten prüfen, ob das Paket für sie ist (-> verarbeiten, sonst weiterschicken).
-
Jeder Mikrocontroller sendet die für ihn bestimmten Daten an seinen eigenen Serialport, an den die Funk-Platinen angeschlossen sind.
-
Per Funk empfangene Daten werden wieder in das Protokoll gepackt und an den Host adressiert. Dort friemelt die Software die Pakete wieder auseinander und leitet sie an den entsprechenden Listener weiter.
-
Die Mikrocontorller können einfach aufgebaut sein, z.B. DFRobot Beetle (8$) oder vergleichbare Arduinos.
-
-
Wie sähe es denn bei Dir aus? Was sagen Dir Deine Erfahrungen mit HA über Deine Hausautomatisationslösung und ioBroker? `
Ich selbst bin kein Fan davon, auf einem PI eine hochverfügbare Lösung laufen zu lassen.Ich habe eine dreistufige Lösung im Einsatz, die momentan für mich ausreichend ist. Gesteuert werden momentan ausschließlich die Heizkörper in der Wohnung. Mit ioBroker habe ich zum einen komfortable Bedienmöglichkeiten. Darüber hinaus stellt ioBroker noch eine Visualiserung von vielen anderen Informationen an zentraler Stelle zur Verfügung
Stufe 1 (ioBroker)
Als vernetzte Steuerungs- und Bedienungsebene kommt ioBroker zum Einsatz. Hier laufen alle Programme zur Steuerung der Heizkörper, insbesondere mit Verknüpfungen zu z.B. Außentemperatur.
Stufe 2 (Backup Aktoren / Notprogramm)
Bei einem Ausfall von ioBroker steht noch die nächste Ebene zur Verfügung.
Hier kommt eine CCU2 zum Einsatz. Momentan habe ich hier kein Fallback-Konzept erarbeitet. Auf der CCU sind Programme zur Steuerung der Temperatur hinterlegt, allerdings deaktiviert. Damit kann sehr schnell wieder eine (etwas einfachere) Steuerung aktiviert werden.
Zugleich dient die CCU2 auch als Datenspeicher für die unterlagerten Thermostate (Einstellungen)
Stufe 3 (Aktoren / Sensoren)
Dann habe ich alle Heizkörper mit HM-Komponenten ausgestattet. Zusammen mit dem darauf gespeicherten Programm habe ich meine minimale Fall-Backstufe.
Bei einem Ausfall der CCU kann jeder Heizkörper weiterhin völlig autark weiterarbeiten. eine Bedienung vor Ort ist direkt am Aktor möglich. Die Daten sind in der CCU gespeichert, so dass z.B. eine leere Batterie keine Schwierigkeiten bereitet (außer der dadurch bedingten fehlenden Heizkörpersteuerung). Dies ist der Grund warum ich meinen alten Rondostat-Steuerungen nachweine. Dort lässt sich der Kopf abnehmen und dann steht sogar noch eine absolute Handebene zur Bedienung (keine Regelung mehr, aber immerhin Steller).
Welche Ausfälle hatte ich schon:
- Ausfall ioBroker
Jemand brauchte eine Steckdose und hat das Netzteil für den PI gezogen. Gemerkt habe ich es dann nach zwei Tagen, weil die Wohnung etwas kühler war als üblich. Die Thermostate haben hier autark weitergearbeitet, nur das Tagprogramm über ioBroker lief nicht mehr.
Probleme nach der Aktualisierung von Adapter. Das treibt bei mir auch nicht den Adrenalinpegel sehr hoch. Und die Unterstützung hier im Forum / bei den Entwicklern ist so gut, dass die meistens nach ein bis zwei Tagen erledigt ist. Passiert nicht, wenn ich abwesend bin.
Natürlich den klassischen Ausfall durch defekte SD-Karten. Das zeigt sich meistens nach einem Reboot.
Der Verlust der Visualisierung und Bedienung war/ist unkritisch, da sehr selten genutzt wird.
- Regelmäßige Störungen der Funkverbindung der HM-Komponenten
Das ist ja leider ein bekanntes Problem aufgrund der nicht ganz optimal angepassten Antennen aller HM-Komponenten. Dadurch geht der eine oder andere Stellbefehl verloren. Ich löse das dadurch, dass ich diese zyklisch in größeren Abständen (1/4 Stunde) sende. Das ist nicht optimal, aber es funktioniert wunderbar.
Mir ist klar, dass andere natürlich andere Funktionen als sehr wichtig ansehen und sich dafür gerne eine höhere Sicherheit der Verfügbarkeit wünschen.
-
Bei und mit dem ioBroker haben wir auf dem ersten Blick einen SPoF. Er ist das zentrale Logik- und Kommunikationsmodul. `
Ich denke, hier sollte man unterscheiden, was ioBroker macht.1. Es gibt unkritische Dinge wie z.B. reine Visualisierung (z.B. Wetterbericht, Staumeldungen, Terminkalender)
2. Dann gibt es unkritische Steuerungen und Bedienung. Hier würde ich z.B. schöne Fernbedienungen, intelligente Lichtsteuerungen, Heizung mit Verknüpfung anderer Daten mit einordnen.
3. Und dann gibt es noch Basissteuerungen (z.B. Steuerung der Heizung, aber nur die Minimalfunktionen)
Wirklich kritisch sind nur die in 3. vorhandenen Funktionen. Der Rest ist Komfort. Was man in welcher Ebene sieht, muss jeder für sich selbst entscheiden.
Ich habe es selbst (noch) nicht gemacht, aber hier müsste man bereits die ersten Trennungen machen und entsprechende Module einsetzen. Nein, nicht nur die Adapter, sondern auf eigener Hardware.
Natürlich muss man diese dann wieder verbinden, aber das ist kein großes Problem.
Das hat dann den Vorteil, dass die einzelnen Module wesentlich kleiner und übersichtlicher werden und man gezielt Sicherungen einbauen kann.
Dann sollte man sich auch noch einmal kurz Gedanken über die Lebensdauer der eingesetzten Lösung machen:
- Welche Ersatzteile bekomme ich in 1, 2, 5 oder 10 Jahren noch, wenn Teile defekt sind?
Das ist in meinen Augen ein sehr hohes Risiko, da all die IT-Teile eine sehr kurze Verfügbarkeit haben. Und eine Anpassung mit neuen Komponenten oftmals sehr aufwendig wird.
Das ist dann die Domäne großer Hersteller in der Anlagenautomatisierung, die nach Abkündigung (das gibt es dort) bis zu 10 Jahre danach Ersatz liefern können.
-
Dann sollte man sich auch noch einmal kurz Gedanken über die Lebensdauer der eingesetzten Lösung machen:
- Welche Ersatzteile bekomme ich in 1, 2, 5 oder 10 Jahren noch, wenn Teile defekt sind?
Das ist in meinen Augen ein sehr hohes Risiko, da all die IT-Teile eine sehr kurze Verfügbarkeit haben. Und eine Anpassung mit neuen Komponenten oftmals sehr aufwendig wird.
Das ist dann die Domäne großer Hersteller in der Anlagenautomatisierung, die nach Abkündigung (das gibt es dort) bis zu 10 Jahre danach Ersatz liefern können. `
Dann sind wir wieder bei der Lösung die in den ioBroker integriert ist und unabhängig von der Hardware arbeitet.
Leider finde ich es erschreckend das bisher lediglich 20 Stimmen an der Abstimmung teilgenommen haben. Gehen hier wirklich alle "volles Risiko" ohne sich über Ausfälle Gedanken zu machen?
-
Mir wurde gesagt, Feedback von 5% aller Leser zu erhalten, wäre ein außerordentlich gutes Ergebnis. [emoji26]
Es ist korrekt, man kann den ioBroker und seine Adapter auch wieder in Verfügbarkeitsklassen aufteilen.
Das habe ich aber vorerst nicht vor. Ich wollte den im ioBroker integrierten Restartmechanismus der Adapter nutzen und direkt den Nodejs-Prozess, der den js-Controller mit seinen beiden Datenbanken bereitstellt, überwachen. Wenn der stirbt oder die Überwachungsprozesse fehlschlagen, dann ist ein Kriterium für einen Neustartversuch, bzw. wenn der fehlschlägt ein Kriterium für ein vollständiges Failover auf den Standby-Node gegeben.
Ein Failover ist dabei immer mit einem kurzfristigen Verbindungsverlust verbunden. Die in-Memory-Datenbanken von ioBroker werden ca. alle 30s auf den Datenträger gespeichert. Die Daten und ioBroker-Programmdateien sind auf beiden Cluster-Nodes immer gleich. Man verliert bei einem Fehler also Daten von max. 30s+Startzeit des ioBrokers+Adapter. Das sind letztendlich 1-2 Minuten. Danach läuft ioBroker weiter, als sei außer einem Restart nichts geschehen. Siehe Video oben im ersten Post.
-
Die in-Memory-Datenbanken von ioBroker werden ca. alle 30s auf den Datenträger gespeichert. `
Das trifft normal für die Zustände (states) bei Verwendung der Datei states.json zu (habe ich bei mir auf 10 Minuten erhöht). Redis speichert bei typischer Ereignisfrequenz alle 5 Minuten in eine Datei. Die statischen Objekte werden normalerweise viel seltener in objects.json gespeichert. -
Danke für den Hinweis. Ich werde mir die Konfigurationsoptionen und den Quelltext anschauen.
Redis ist erst einmal außen vor. Das hat eigene Hochverfügbarkeitsoptionen.
-
Ich habe im ersten Artikel eine Übersichtsbild der angedachten Lösung angefügt. DIe Umfage läuft noch kurze Zeit. Wer noch nicht abgestimmt hat, ist eingeladen das noch schnell nachzuholen. ;)
Ich würde mich freuen, wenn diejenigen, die direkt mitmachen wollen, mir eine kurze PN zukommen lassen würden.
Erstes Ziel wird es ein, die HW-Auswahl "festzuklopfen" und eine für alle nachvollziehbare Dokumentation zur Einrichtung einer Filesystemspiegelung (RAID 1 over LAN :D ) zu erstellen.
-
Ich hatte mir früher auch mal Gedanken gemacht, unter anderem war da der Gedanke, eine IObroker Instanz auf einem Webserver zu hosten und per Internet Verbindung zu synchronisieren, als Callback Leitung dann per Handynetz.
Da dann eine laufende, angreifbare Instanz außerhalb der Wohnung liegt, kommt das nicht in Frage.
Dann geht es weiter, theoretisch müßten alle Module z.B. Zwave doppelt vorhanden sein, aber Komponenten lassen sich nur an ein Gateway anbinden.
Für mich war also eines klar, alles wirklich alles, was wichtig ist, muß von Hand bedienbar sein, so das die Frau auch ohne mich klar kommt.
IOBroker läuft jetzt virtualisiert, mit regelmäßigen Snapshots und Backups auf NAS und Webcloud (verschlüsselt).
Fällt das System aus, bekomme ich es in kürzester Zeit wieder Online, liege ich im Krankenhaus, habe ich andere Sorgen als Kompfort.
Was aber nicht heißt, das ich an einem dauerhaft verfügbaren System kein Interesse hätte, wenn ich helfen kann, würde ich dies natürlich tun. Aber wie gesagt, ich sehe die Probleme nicht bei IOBroker an sich, sondern an den Modulen der Hersteller.
-
Wie verhält sich das mit den Modulen? Kann man das durch einfaches umstecken zwischen den Raspberries lösen? Z.B. alles über das Netzwerk geht automatisch, USB-Sticks aber manuell umstecken? Alternativen dazu? USB Device Server und dann per LAN? SPoF…
-
Bei einem USB Device Server hat man wieder eine Komponente die ausfallen kann. Backups ziehe ich zur Zeit von Hand. Wenn die Hardware ausfallen würde, neue kaufen, Proxmox drauf, Sticks einstecken, Container einspielen fertig.
Für meinen Teil habe ich festgestellt, es geht leider nicht ohne Handeingriff bei einem Ausfall der Hardware. Und genau da fängt dann der Punkt Frau an, nicht weil sie es nicht kann, sondern weil es sie nervt.
Für mich bedeutet höchste Verfügbarkeit mitlerweile nur noch, wie minimiere ich die Ausfallzeit.
To do Liste für mich:
-
Abgleich der SQL Historie mit einer SQL Datenbank auf meinem Webbspace
-
Spiegelung der Container anlegen, so das bei einem Software defekt der entsprechende Container über eine VPN Verbindung gestoppt und der Backup Container gestartet werden kann.
Was ich noch suche ist ein Script für den Webspace, das den Status des Systems abfragt und bei Ausfall, also z.B. Strom weg, Hardware Ausfall, einen Error wirft und dies per Pushover an mich weiterleitet.
-
-
So,
ich bin vor Tagen schon auf dieses Thema gestoßen und will nun auch mal mein Senf dazu abgeben. Ich würde von einer HOCHVERFÜGBARKEIT per Definition davon absehen. Das ist mit geringen, finanziellen Mitteln nicht machbar. "Ein System gilt als hochverfügbar, wenn eine Anwendung auch im Fehlerfall weiterhin verfügbar ist und ohne unmittelbaren menschlichen Eingriff weiter genutzt werden kann."
Eine Hochverfügbarkeit im Sinne der 'Verfügbarkeitsklassen' wären wir hier bei der VK5, VK6 oder VK7. Wozu das ganze? Das ganze hat eine Wahnsinnige Anforderung an alle Komponenten sowie dokumentierte und festgelegte Handlungen. Ich würde mir als Ziel maximal VK2 setzen (3,5 Tage Ausfallzeit im Jahr).
Hochverfügbarkeit erreicht man nicht über:
-
Festlegung auf einer Hardware (leider wird das 'schwierig' bei INTEL / ARM Mischumgebung)
-
Knausern bei USB / Serial / GPIO Geräten oder Spezialhardware. Sprich, das zWave Netwerk bräuchte auf jeden Fall zwei Sticks. Geht das - keine Ahnung. GPIO wird schon haariger.
-
Festlegung auf spezielle Produkte die eine Koexistenz von irgendwie geartete Netzwerke benötigt (Zigbee, zWave etc.) => Also Sensoren usw selber bauen die über WLAN und LAN arbeiten - denn das ist Hochverfügbar
-
Einfachen Hausmitteln ohne viel Zeit zu investieren.
Hochverfügbarkeit nur mal so im Anfang
=> Also geht es los: du brauchst 2 versch. Räume in unterschiedlichen Brandabschnitten
=> In jeden Raum müssen zwei versch. Stromkreise sein, Einspeisung von außen über zwei Wege.
=> Jeder Raum muss vollständig versorgt sein, USV, Switch, Patchfelder und Monitoring wie Rauchmelder, CO / Wassermelder bei Kellerebene
=> Wenn Cloud /Internet wichtig: dann untersch. Anbindung, sowohl vom Anbieter als auch von der Physik: (DSL über Kabel, DSL über LTE), der Hochverfügbarkeit wegen muss in jeden Raum einmal LTE und einmal DSL sein.
=> WLAN, Accesspoints aufgeteilt auf beide Serverräume. Sprich, mindestens 2, sonst 4, sonst 6
=> Dienste dürfen nicht hardwarebezogen sein, also müssen diese virtuell laufen -> Virtualisierungsschicht einplanen
=> Virtualisierung ist auch ein Stichwort: Netzwerk, Storage usw. müssen virtuell laufen
=> Storage fehlt auch, also 2x Ausfallsicheres SAN (NAS) inkl. Spiegelung untereinander, zum ablegen der virtuellen Maschine…
=> Backups nach dem Generationsprinzip: ab und zu können BUGs auch erst Wochen später auftreten.
=> Da fehlt noch einiges, müsste aber jetzt in mich gehen....
ALSO in Summe: Lieber ein vernünftigen Wideranlaufplan ausarbeiten - möglichst mit allen Aspekten und ein 'Cold-Standby'-System fahren.
-
-
Was für ein Aufriss.
Ich hab es auch "ausfallsicher" und es hat nichts gekostet.
Bei mir liegt der Ordner /opt/iobroker auf einem RAID Netzwerk-Share und wird von dort gestartet. Wenn Raspberry1 3 mal binnen 30 Sekunden nicht auf einen Ping reagiert, wird der zweite Raspberry gestartet und greift auf das gleiche Netzwerkshare zu.
Das ist zwar nicht "hochverfügbar" reicht mir aber aus. Einem Privatanwender wird kaum auffallen, dass der Raspberry 2 minuten weg war. Es sei denn, man löst genau in dem Moment ein Kommando aus. Aber da reicht mir simple Wahrscheinlichkeitsrechnung.
-
1. Raspberry 2 hat eine andere ip-Adresse als raspberry 1, oder? Was machst Du, wenn die Schalter ihre Infos beim ioBroker abliefern?
2. Wie verhindert Du, dass beide Raspberries gleichzeitig laufen (Ein kurzzeitiger Netzwerkausfal kann durchaus passieren?)
3. Zentraler Point of Failure: Netzwerk Share.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden417
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge