

Test paperless-ngx Adapter
-
Aktuelle Test Version 0.0.2 Veröffentlichungsdatum 02.08.2024 Github Link https://github.com/BenAhrdt/ioBroker.paperless-ngx.git Bitte, wer mag Testen.
Aktuell in Version 0.0.2 verfügbar.
Anwahl, ob die Ergebnisse der Abfragen von- documents
- tags
in Ordnern dargestellt werden.
Ja, nutze ich auch zum Digitalisieren meiner Dokumente, aber was macht dieser Adapter zu meinem Nutzen?
Ich sehe es (noch) nicht.
Proxmox und HA - dank KI/AI endlich "blocklyfrei"
-
Ja, nutze ich auch zum Digitalisieren meiner Dokumente, aber was macht dieser Adapter zu meinem Nutzen?
Ich sehe es (noch) nicht.
@meister-mopper Die Idee war nicht von mir, sondern kommt aus diesem Issue:
https://github.com/ioBroker/AdapterRequests/issues/862 -
Ich sehe die Notwendigkeit eines solchen Adapters (noch immer) nicht.
Paperless-ngx ist sehr gut zu bedienen. Was sollte dieser Adapter besser/übersichtlicher machen?
Proxmox und HA - dank KI/AI endlich "blocklyfrei"
-
@meister-mopper Les Dir bitte die Anfrage durch.
Du musst den Adapter ja nicht verwenden. -
@n3ucr0n
Und auch der Rest ;-)Wie würde es euch denn besser gefallen?
A) so wie es aktuell ist, dass die Tags im Unterordner „Tags“ nach Name sortiert sind?B) wenn die Tags in ihrem Unterordner nach ihrer ID sortiert sind?
Ich frage deshalb, da die Dokumente einen Eintrag für ihre Tags haben. Dort werden allerdings die id‘s der Tags angegeben, nicht die Namen.
Wie wäre zusätzlich der Vorschlag, das bei abgewählten Dingen wie dokumente / Tags.
Trotzdem deren basics gefüllt werden… also bei Dokumenten und Tags der datenpunkt „count“ und zumindest zu sehen, wieviele Dokumente vorhanden sind. (Wenngleich man auch nicht deren Details sehen möchte) -
@n3ucr0n die Version 0.0.4 geht gleich online.
Darin kann man unter anderem entscheiden, welche Daten von den einzelnen Optionen abgeholt bzw. angelegt werden.
(ohne, Basisparameter, Ausführlich)
Es sollte dann auch bei Dir kein Problem sein, dass viele Dokumente vorhanden sind, denn es wird in den Basisparametern nur der "count" angelegt.Ps. Die Tags habe ich weiterhin in der ausführliche Variante drin, dass sie mit ihrem Namen angelegt werden.
In der Basisariante, wird auch hier nur der count der Tags angezeigt. -
@n3ucr0n die Version 0.0.4 geht gleich online.
Darin kann man unter anderem entscheiden, welche Daten von den einzelnen Optionen abgeholt bzw. angelegt werden.
(ohne, Basisparameter, Ausführlich)
Es sollte dann auch bei Dir kein Problem sein, dass viele Dokumente vorhanden sind, denn es wird in den Basisparametern nur der "count" angelegt.Ps. Die Tags habe ich weiterhin in der ausführliche Variante drin, dass sie mit ihrem Namen angelegt werden.
In der Basisariante, wird auch hier nur der count der Tags angezeigt. -
@meister-mopper ich gebe dir absolut recht, dass Paperless für sich genommen ausreichend ist.
Der Usecase für die ioBroker Integration ist bei mir an einer Stelle am interessantesten:
Ich habe in Paperless automatische Importe von Dokumenten laufen. Aktuell überprüfe ich den entsprechend gesetzten Inbox Tag in Paperless manuell.
Mittels der Integration in den ioBroker kann ich mir auf meiner Visualisierung beispielsweise anzeigen lassen, ob bzw. Wie viele neue Dokumente vorhanden sind. Auch Benachrichtigungen via WhatsApp Mail Alexa etc. Über den Eingang neuer Dokumente sind realisierbar.
Das empfinde ich als sehr hilfreich und freue mich sehr über die begonnene Entwicklungsarbeit. :-)
-
@ben1983 hört sich super an. Habe es heute leider nicht mehr an den PC geschafft aber schaue mir mit Freude morgen die neue Version an! Danke 😊
@n3ucr0n OK. Ich bin daran erweiterungen rausnzu suchen, welche noch interessant sein könnten.
Wäre was für dich schön, wenn es priorisiert behandelt wird?
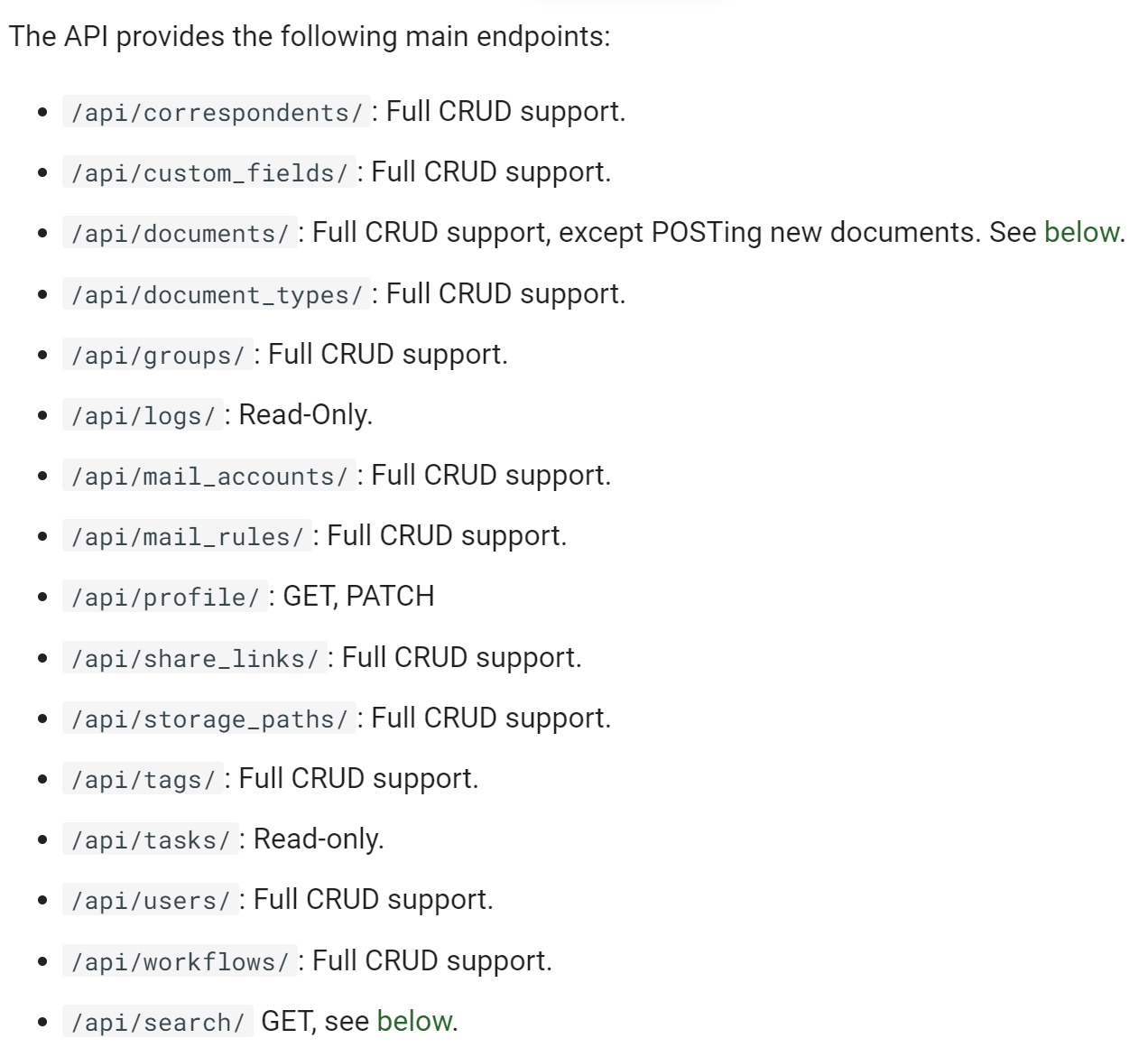
Ps. man kann jetzt auch Suchen.
In den EIntrag search kann man unter query entwas eintragen und danach werden einem in dem result Ordner des search ordners die Ergebnisse / das Ergebnis angezeigt.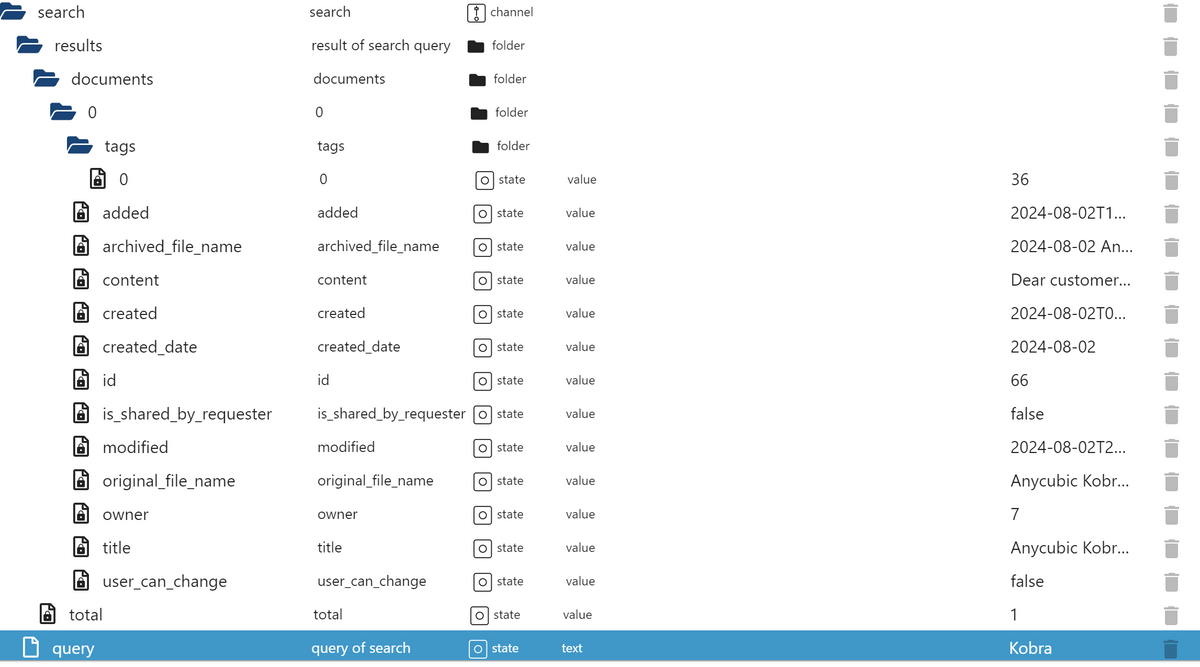
-
@n3ucr0n was hältst Du hiervon:
Ordnerstruktur:
Bsp. Für Tags:
0.tags.basic
0.tags.detailed
0.tags.retainedDas eben für alle angewandt.
Es gibt in den meisten Ordnern einen Basic Bereich. Hier liegt sowas drin wie bsp. CountDann gibt es den Detailed Bereich. Hier liegen bspw. Detaillierte Angaben zu den Tags drin.
Zu guter letzt der remaining Part.
Hier liegen alle restlichen Daten drin, die noch gesendet wurden. -
@n3ucr0n was hältst Du hiervon:
Ordnerstruktur:
Bsp. Für Tags:
0.tags.basic
0.tags.detailed
0.tags.retainedDas eben für alle angewandt.
Es gibt in den meisten Ordnern einen Basic Bereich. Hier liegt sowas drin wie bsp. CountDann gibt es den Detailed Bereich. Hier liegen bspw. Detaillierte Angaben zu den Tags drin.
Zu guter letzt der remaining Part.
Hier liegen alle restlichen Daten drin, die noch gesendet wurden.@ben1983 Diese Aufteilung hört sich für mich sinnvoll an.
Und wäre auch eine klar nachzuvollziehen, wenn über die Einstellungen entsprechende Synchronisierungen ausgewählt werden. (Sync Basic, Sync Detailed, Sync Retained).
Zum Thema der API könnte ich mir vorstellen, dass USER und LOGS noch interessant wäre.
Über User könnte ich dann sicherlich Rückschlüsse ziehen, welche User ID zu einem User gehört, was wiederum bei der Steuerung von Benachrichtigungen interessant wäre, und bei den LOGS wäre es spannend zu sehen was raus kommt. Ggf. kann man darüber mittels ioBroker auf Fehler in Paperless reagieren.Ich habe jetzt gestern und heute den Adapter mal versucht laufen zu lassen.
Leider funktioniert es bei mir noch nicht wirklich, mit jedoch spannendem Verhalten.Hier erstmal die Grundeinstellungen des Adapters:
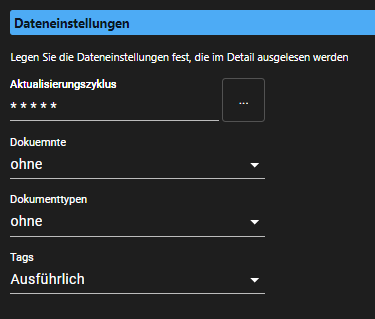
Der Adapter wird grün und fängt an die Daten zu holen.
Kurz darauf sieht mein Objektbaum so aus: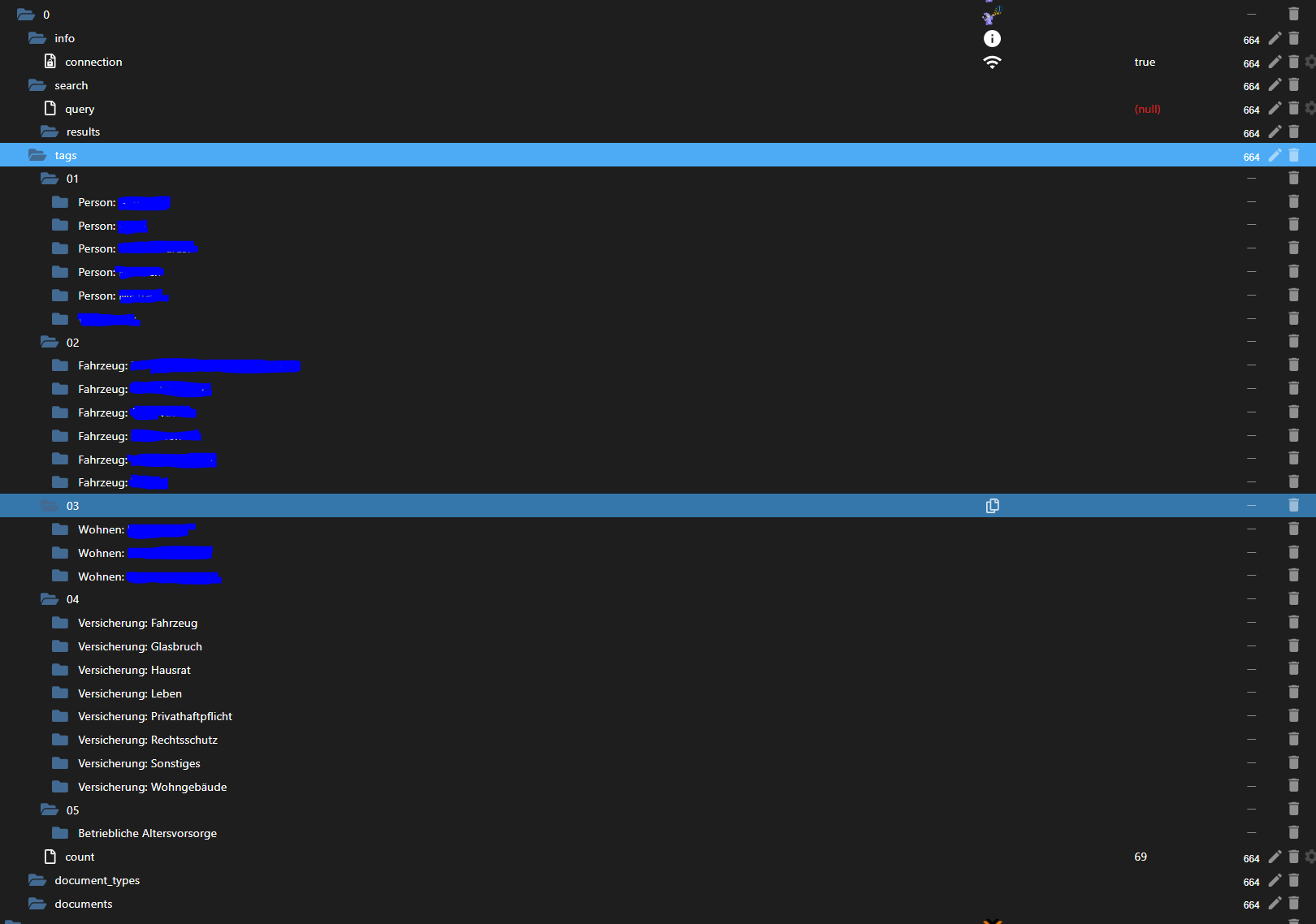
Das geht schon in die richtige Richtung, leider sind dies bei weitem nicht alle Tags die ich in Paperless habe. Der Count zeigt ja auch die 69 Tags :-)
Warum er an dieser Stelle aufhört die Tags zu holen, vermag ich nicht zu sagen.
Auffällig ist, dass er die Tags genau so weit holt, wie sie in Paperless auf "Seite 1" der Tags angezeigt werden. Das kann aber natürlich auch nur ein Zufall sein.Die Aufteilung und die Unterordner 01, 02, etc. dürfte von Dir nicht so geplant gewesen sein und ist ein für mich nachvollziehbares Ergebnis aus meiner speziellen Art in Paperless die Tags zu benennen. Ich habe auf diese Weise meine Tags in Paperless versehen, damit ich eine Möglichkeit habe die Tags zu sortieren (und thematisch ähnliche Tags zusammengehörig stehen habe). Für mich ist dies aber fast eher ein Feature und kein Problem :-)
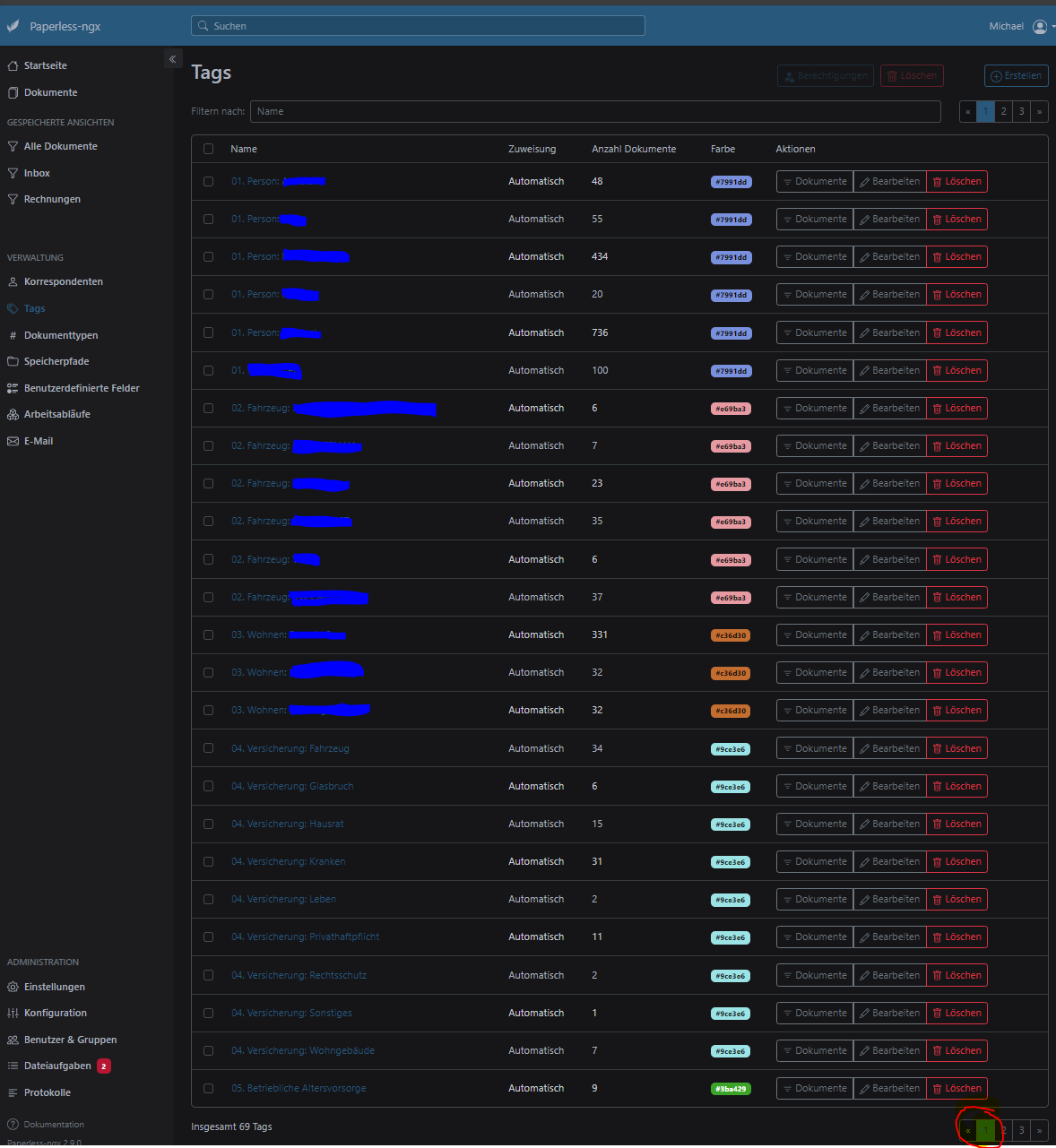
Kurz darauf verschwinden allerdings die Tags jedoch alle bis auf einen wieder:
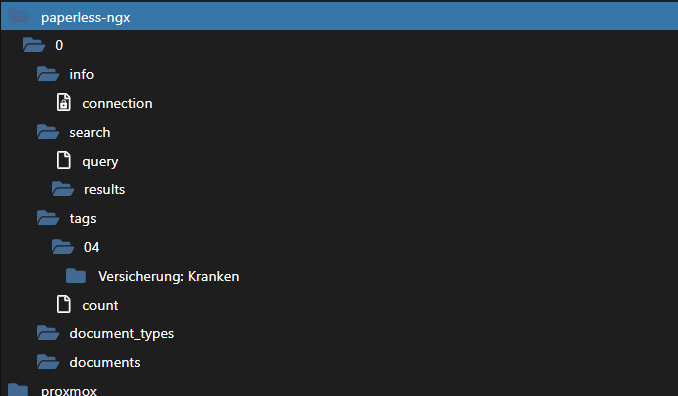
Das ist natürlich doof.
Ich teste grade, ob das mit dem Aktualisierungsintervall zu tun haben könnte.Installiert ist natürlich 0.0.5
Soweit der aktuelle Stand :-)
-
@ben1983 Diese Aufteilung hört sich für mich sinnvoll an.
Und wäre auch eine klar nachzuvollziehen, wenn über die Einstellungen entsprechende Synchronisierungen ausgewählt werden. (Sync Basic, Sync Detailed, Sync Retained).
Zum Thema der API könnte ich mir vorstellen, dass USER und LOGS noch interessant wäre.
Über User könnte ich dann sicherlich Rückschlüsse ziehen, welche User ID zu einem User gehört, was wiederum bei der Steuerung von Benachrichtigungen interessant wäre, und bei den LOGS wäre es spannend zu sehen was raus kommt. Ggf. kann man darüber mittels ioBroker auf Fehler in Paperless reagieren.Ich habe jetzt gestern und heute den Adapter mal versucht laufen zu lassen.
Leider funktioniert es bei mir noch nicht wirklich, mit jedoch spannendem Verhalten.Hier erstmal die Grundeinstellungen des Adapters:
Der Adapter wird grün und fängt an die Daten zu holen.
Kurz darauf sieht mein Objektbaum so aus:Das geht schon in die richtige Richtung, leider sind dies bei weitem nicht alle Tags die ich in Paperless habe. Der Count zeigt ja auch die 69 Tags :-)
Warum er an dieser Stelle aufhört die Tags zu holen, vermag ich nicht zu sagen.
Auffällig ist, dass er die Tags genau so weit holt, wie sie in Paperless auf "Seite 1" der Tags angezeigt werden. Das kann aber natürlich auch nur ein Zufall sein.Die Aufteilung und die Unterordner 01, 02, etc. dürfte von Dir nicht so geplant gewesen sein und ist ein für mich nachvollziehbares Ergebnis aus meiner speziellen Art in Paperless die Tags zu benennen. Ich habe auf diese Weise meine Tags in Paperless versehen, damit ich eine Möglichkeit habe die Tags zu sortieren (und thematisch ähnliche Tags zusammengehörig stehen habe). Für mich ist dies aber fast eher ein Feature und kein Problem :-)
Kurz darauf verschwinden allerdings die Tags jedoch alle bis auf einen wieder:
Das ist natürlich doof.
Ich teste grade, ob das mit dem Aktualisierungsintervall zu tun haben könnte.Installiert ist natürlich 0.0.5
Soweit der aktuelle Stand :-)
@n3ucr0n Hallo,
das schaue ich mir die Tage, wenn ich dazu komme einmal an.
Mal sehen, ob es mit der Anzahl wirklich nur ein Zufall ist.Edit: Habe gerade gemerkt, dass der wirklich über die API nur die ersten liefert.
Müsste ich dann noch anpassen. -
@n3ucr0n Hallo,
das schaue ich mir die Tage, wenn ich dazu komme einmal an.
Mal sehen, ob es mit der Anzahl wirklich nur ein Zufall ist.Edit: Habe gerade gemerkt, dass der wirklich über die API nur die ersten liefert.
Müsste ich dann noch anpassen. -
@ben1983 Super! Ich freue mich auf die neu Version, sag einfach bescheid wenn Du Zeit gefunden hast. Dann teste ich es gerne :-)
@n3ucr0n So. Da ich in den nächsten Wochen wenig / keine Zeit haben werde (Urlaub ;-) )
Habe ich gerade nochmal die 0.06 online gestellt.Hier wird:
a) das Suchen ermöcht
b) das Auflisten aller Tags / Dokumente etc. in den detailed Ordner durchgeführt
(vorher wurde nur die erste Seite [erste Daten] der API geschrieben)
c) eine Aufteilung in basic und detailed vorgenommen, je nach Auswahl, werden dann entsprechende Daten zugewiesen.Die Struktur der Daten, musste ich allerdings anpassen, da es bei den Test zu Fehlern, bzw. Warnungen kam, wenn ich bspw. ein Ordnername so darstellen wollte, wie ein Dokument Betitelt ist. Hier kann es dazu kommen, dass nicht erlaubte Zeichen im Dokumententitel vorkommen. Also musste ich auf die "Arraystruktur" zurückgreifen und habe es numerisch durchnummerieren lassen.
Bspw.
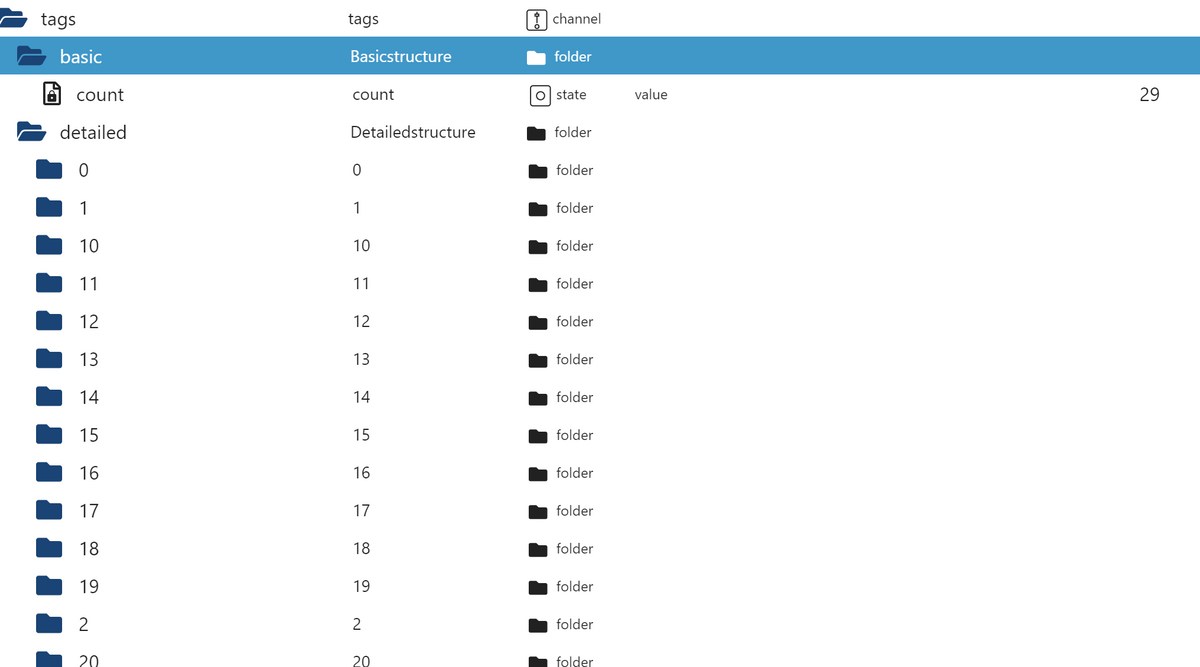
Gerne kann getestet werden.
Am Besten vor installieren der neuen 0.0.6 einmal den Adapter stoppen und das Instanz Verzeichnis löschen. -
@n3ucr0n So. Da ich in den nächsten Wochen wenig / keine Zeit haben werde (Urlaub ;-) )
Habe ich gerade nochmal die 0.06 online gestellt.Hier wird:
a) das Suchen ermöcht
b) das Auflisten aller Tags / Dokumente etc. in den detailed Ordner durchgeführt
(vorher wurde nur die erste Seite [erste Daten] der API geschrieben)
c) eine Aufteilung in basic und detailed vorgenommen, je nach Auswahl, werden dann entsprechende Daten zugewiesen.Die Struktur der Daten, musste ich allerdings anpassen, da es bei den Test zu Fehlern, bzw. Warnungen kam, wenn ich bspw. ein Ordnername so darstellen wollte, wie ein Dokument Betitelt ist. Hier kann es dazu kommen, dass nicht erlaubte Zeichen im Dokumententitel vorkommen. Also musste ich auf die "Arraystruktur" zurückgreifen und habe es numerisch durchnummerieren lassen.
Bspw.
Gerne kann getestet werden.
Am Besten vor installieren der neuen 0.0.6 einmal den Adapter stoppen und das Instanz Verzeichnis löschen.@ben1983 Ja dann genieß den Urlaub in vollen Zügen :-)
Habe die Version grade ausprobiert und es scheint alles erstmal richtig angezeigt zu werden.
Es werden alle Tags aufgelistet und scheinen vom Count her auch zu stimmen.Morgen werde ich mal Tests bezüglich
- Dokumente hinzufügen
- Dokumente löschen
- Tags ändern
- Tags umbenenen
- Tags Löschen
- etc.
durchführen. Ich berichte dann :-)
Das Einzige was mir jetzt schon aufgefallen ist, ist das die Tags bzw. die Ordner der Tags aktuell nur mit der ID dargestellt werden. Da wäre natürlich der Tag-Name sehr schön. Das würde auch vermeiden, dass nach der 19 erstmal die 2 vor der 20 kommt. Aber das sind ja nur Schönheitsfehler :-)
EDIT: Habe grade nochmal mit Verstand Deinen Post gelesen und gesehen, dass es einen guten Grund für die numerische Darstellung gibt. Wenn das erstmal so der klügste Weg ist, dann passt das natürlich super :-)
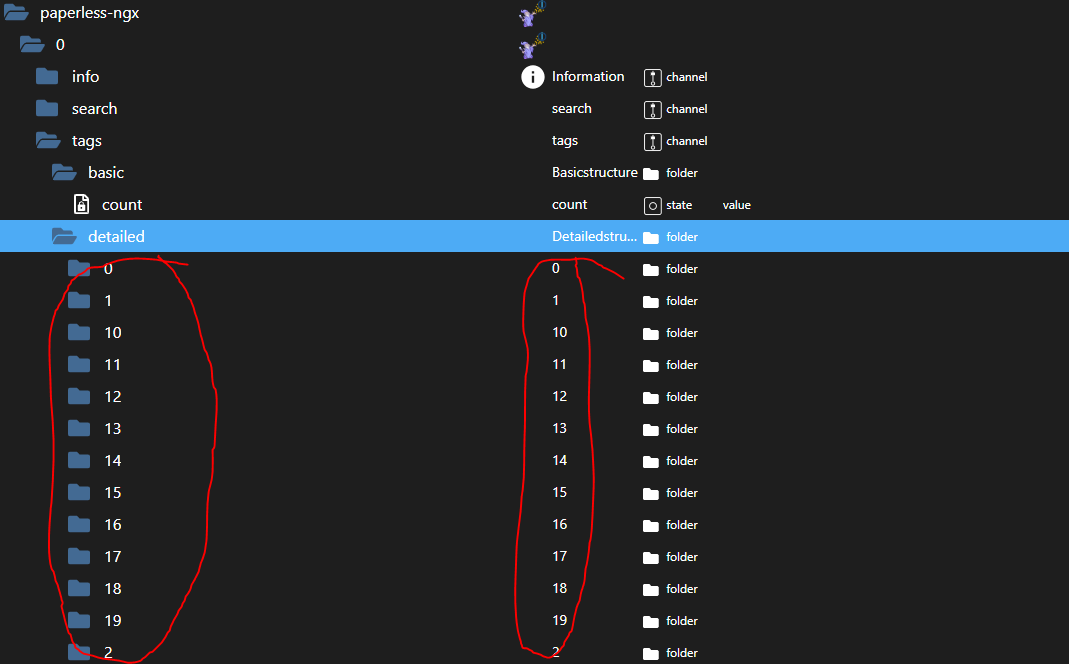
Ansonsten schonmal DANKE für die bisherige Entwicklung! :-)
-
@ben1983 Ja dann genieß den Urlaub in vollen Zügen :-)
Habe die Version grade ausprobiert und es scheint alles erstmal richtig angezeigt zu werden.
Es werden alle Tags aufgelistet und scheinen vom Count her auch zu stimmen.Morgen werde ich mal Tests bezüglich
- Dokumente hinzufügen
- Dokumente löschen
- Tags ändern
- Tags umbenenen
- Tags Löschen
- etc.
durchführen. Ich berichte dann :-)
Das Einzige was mir jetzt schon aufgefallen ist, ist das die Tags bzw. die Ordner der Tags aktuell nur mit der ID dargestellt werden. Da wäre natürlich der Tag-Name sehr schön. Das würde auch vermeiden, dass nach der 19 erstmal die 2 vor der 20 kommt. Aber das sind ja nur Schönheitsfehler :-)
EDIT: Habe grade nochmal mit Verstand Deinen Post gelesen und gesehen, dass es einen guten Grund für die numerische Darstellung gibt. Wenn das erstmal so der klügste Weg ist, dann passt das natürlich super :-)
Ansonsten schonmal DANKE für die bisherige Entwicklung! :-)
@n3ucr0n ja leider ist dass mit den Namen nicht so einfach möglich.
Denn, wie gesagt könnte ja der Name ein in iobroker ungültiges Zeichen erhalten.
Man könnte das natürlich mittels einer Funktion in einen gültigen String ändern, aber dann würde auch der Tag / Ordner wieder nicht ganz so heißen, wie der originalname des Tags. Aus diesem Grund habe ich mich für das numerische entschieden
Man könnte noch überlegen, ob man mit führenden „00“ arbeitet, aber die Nummerierung haben eh nichts mit den Tag IDS zu tun, sondern sind die Reihenfolge, wie sie übertragen wurden.
Hier wäre noch zu überlegen, ob man nach ids benamt. Aber schau mal durch und gib mal Bescheid, was du so dazu meinst.
So wie aktuell ist es halt am einfachsten, aber das muss ja nicht so bleiben.Schau dir auch mal an, wie es dargestellt wird, wie die Auflistung innerhalb eines Dokuments angezeigt wird, welchen Tag das Dokument enthält.
Dort stehen glaube Auktion einzelne States:Documents.5.tags.0 —- wert: 28
Oder so.
Hier wäre eine Option, dass stattdessen:
Documents.5.tags —— wert: array[28,25,2]Bspw. Wäre das sinnvoll, oder anderen Vorschlag. Oder so wie es ist, ok?
-
@ben1983 Ja dann genieß den Urlaub in vollen Zügen :-)
Habe die Version grade ausprobiert und es scheint alles erstmal richtig angezeigt zu werden.
Es werden alle Tags aufgelistet und scheinen vom Count her auch zu stimmen.Morgen werde ich mal Tests bezüglich
- Dokumente hinzufügen
- Dokumente löschen
- Tags ändern
- Tags umbenenen
- Tags Löschen
- etc.
durchführen. Ich berichte dann :-)
Das Einzige was mir jetzt schon aufgefallen ist, ist das die Tags bzw. die Ordner der Tags aktuell nur mit der ID dargestellt werden. Da wäre natürlich der Tag-Name sehr schön. Das würde auch vermeiden, dass nach der 19 erstmal die 2 vor der 20 kommt. Aber das sind ja nur Schönheitsfehler :-)
EDIT: Habe grade nochmal mit Verstand Deinen Post gelesen und gesehen, dass es einen guten Grund für die numerische Darstellung gibt. Wenn das erstmal so der klügste Weg ist, dann passt das natürlich super :-)
Ansonsten schonmal DANKE für die bisherige Entwicklung! :-)
-
@ben1983 Ja dann genieß den Urlaub in vollen Zügen :-)
Habe die Version grade ausprobiert und es scheint alles erstmal richtig angezeigt zu werden.
Es werden alle Tags aufgelistet und scheinen vom Count her auch zu stimmen.Morgen werde ich mal Tests bezüglich
- Dokumente hinzufügen
- Dokumente löschen
- Tags ändern
- Tags umbenenen
- Tags Löschen
- etc.
durchführen. Ich berichte dann :-)
Das Einzige was mir jetzt schon aufgefallen ist, ist das die Tags bzw. die Ordner der Tags aktuell nur mit der ID dargestellt werden. Da wäre natürlich der Tag-Name sehr schön. Das würde auch vermeiden, dass nach der 19 erstmal die 2 vor der 20 kommt. Aber das sind ja nur Schönheitsfehler :-)
EDIT: Habe grade nochmal mit Verstand Deinen Post gelesen und gesehen, dass es einen guten Grund für die numerische Darstellung gibt. Wenn das erstmal so der klügste Weg ist, dann passt das natürlich super :-)
Ansonsten schonmal DANKE für die bisherige Entwicklung! :-)
@n3ucr0n So. jetzt aber vorerst die letzte Änderung:
Habe das Erzeugen nochmal intern etwas verändert.
Nun werden ach ding wie Tags, in der Dokumentenauflistung als Array ausgegeben.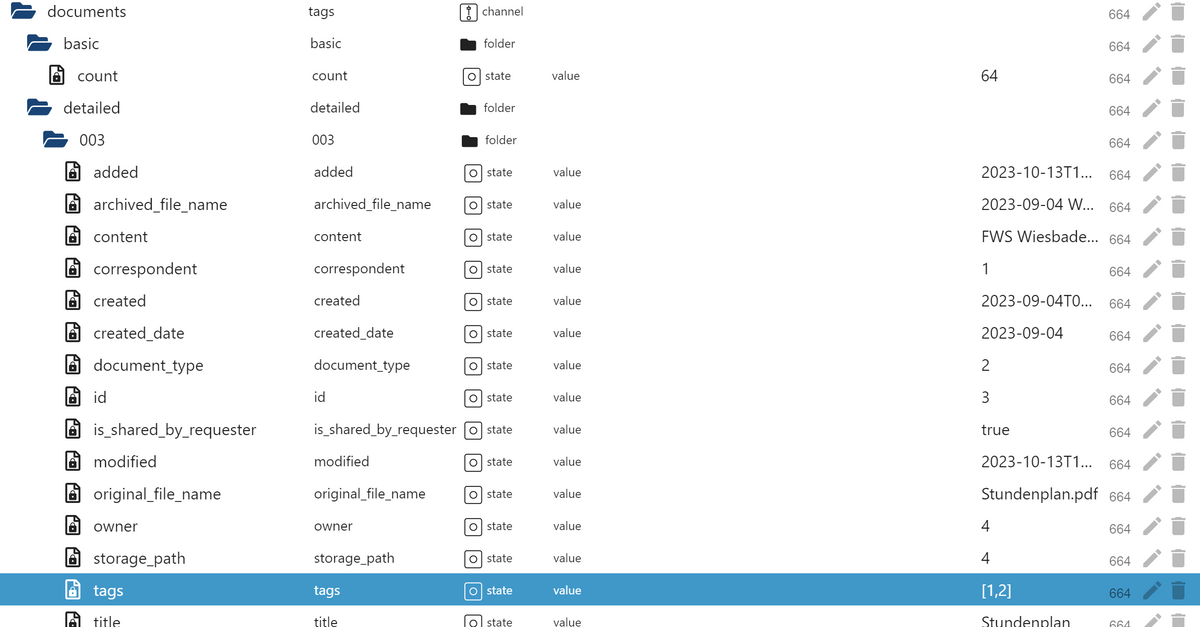
Zusätzlich gibt´s noch etwas "kosmetik" in Form von icons

V0.0.8
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
306
Online33.0k
Benutzer83.3k
Themen1.3m
Beiträge