

Showcase: SSD und HDD Gesundheitszustand überwachen
-
Ich lese auf dem PVE-Hypervisor Linux per bash script im cron job S.M.A.R.T Parameter der System SSD und einer 4TB USB-HDD ein und schreibe per SimpleAPI einige mir interessant vorkommende Parameter nach "userdata". Alle 4 Stunden zur 11. Minute der Stunde werden die Werte aktualisert.
S.M.A.R.T Ausgabe meiner USB-HDD
Interessant fand ich da Seek_Error_Rate und Raw_Read_Error_Rate
Die entsprechenden Zeilen sehen so aus ...
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE ... 1 Raw_Read_Error_Rate 0x000f 081 063 006 Pre-fail Always - 242543912 ... 7 Seek_Error_Rate 0x000f 087 060 030 Pre-fail Always - 475250992Interessant ist "VALUE", da der Wert "normalisiert ist, gilt, je höher, desto besser Maximum ist 100. Gibt den aktuellen Wert wieder.
"WORST" ist da schlechteste jemals gemessene Wert.
"THRESH" ist der Schwellwert, bei dem ein Defekt sehr nahe ist.Bei der SSD habe ich erstmal weniger Parameter angedacht, da fehlt womöglich noch etwas.
An einigen Stellen differieren die Parameter, sodass die angedachte allgemeine Einlese-Funktion nicht möglich ist - schon für diese beiden Platten habe ich individuelle Funktionen bauen müssen...Hier die komplette Ausgabe der SSD
Neben der "Raw_Read_Error_Rate" habe ich nur "VALUE" aus...
Percent_Lifetime_Remain 0x0030 092 092 001 Old_age Offline - 8.... extrahiert
Das Bash-Script wird auf dem PVE-System selber ausgeführt
Erst wird eine Textdatei mit dem Output von Smartctrl erzeugt, dann wird diese passend in der entsprechenden Funktion zerlegt
# Intenso USB hdd smartctl -a -d sat /dev/sdb >Testdata.txt write_userdata_hdd "Proxmox_N3000.HDD_Intenso1." # system SSD smartctl -a /dev/sda >Testdata.txt write_userdata_ssd "Proxmox_N3000.System_SSD."Hier der ganze Code:
#!/usr/bin/bash # to make script ready for cron PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin SimpleApiUrl="http://192.168.2.201:8087/set/0_userdata.0." echo "test_hdd_data.sh drive health check started" > /root/scripte/Proxmox_Skripte/last_run.log # parameter §1 is subpath (no leading dot but a trailing dot function write_userdata_hdd() { # normalized read error rate # use simple api to write to iobroker # example: http://192.168.1.:8087/set/javascript.0.test?value=1 # ReadErrorRate and ReadErrorRateWorst should be ABOVE ReadErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"NormalizedReadErrorRate?value="$(awk '/Raw_Read_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateWorst?value="$(awk '/Raw_Read_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateLimit?value="$(awk '/Raw_Read_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); # SeekErrorRate and SeekErrorRateWorst should be ABOVE SeekErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"SeekErrorRate?value="$(awk '/Seek_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"SeekErrorRateWorst?value="$(awk '/Seek_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"SeekErrorRateLimit?value="$(awk '/Seek_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"LastSmartResult?value="$2 } function write_userdata_ssd() { # normalized read error rate # use simple api to write to iobroker # example: http://192.168.1.:8087/set/javascript.0.test?value=1 # ReadErrorRate and ReadErrorRateWorst should be ABOVE ReadErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"NormalizedReadErrorRate?value="$(awk '/Raw_Read_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateWorst?value="$(awk '/Raw_Read_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateLimit?value="$(awk '/Raw_Read_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); # SeekErrorRate and SeekErrorRateWorst should be ABOVE SeekErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"PercentLifetimeRemain?value="$(awk '/Percent_Lifetime_Remain/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"LastSmartResult?value="$2 } # write smartctl of hdds of interest to file and analyze results # for test purpose comment out smartctl invocations and invoke write_userdata_... functions with off script got Testdata.txt # even possible on different linux machine # Intenso USB hdd smartctl -a -d sat /dev/sdb >/root/scripte/Proxmox_Skripte/Testdata.txt result=$? echo " test_hdd_data.sh drive health check data of usb hdd retrieved result="$result >> /root/scripte/Proxmox_Skripte/last_run.log write_userdata_hdd "Proxmox_N3000.HDD_Intenso1." $result # system SSD smartctl -a /dev/sda >/root/scripte/Proxmox_Skripte/Testdata.txt result=$? echo " test_hdd_data.sh drive health check data of system ssd retrieved result="$result >> /root/scripte/Proxmox_Skripte/last_run.log write_userdata_ssd "Proxmox_N3000.System_SSD." $result echo " test_hdd_data.sh drive health check finished" >> /root/scripte/Proxmox_Skripte/last_run.logHier die Datenpunkte, die ich manuell in Userdata erzeugt habe:
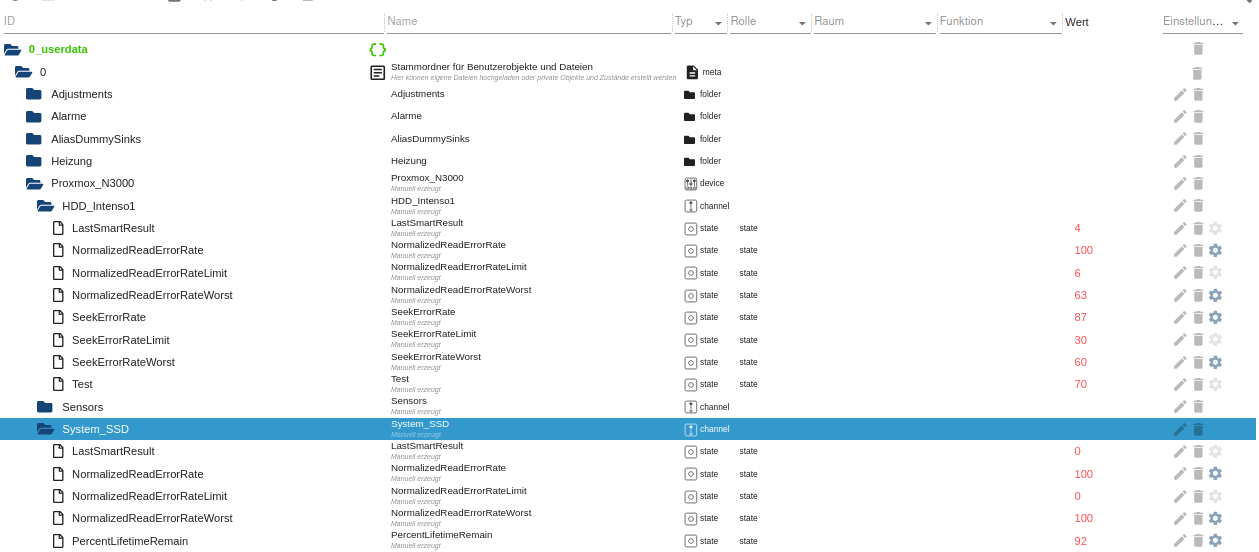
Und das der Eintrag in die root crontab (da man für smartmontools eh sudo braucht... habe aber zumindest die sh Datei readonly gemacht)11 */4 * * * bash /root/skripte/check_usb_hdd.sh 2>&1 /dev/nullIntel(R) Celeron(R) CPU N3000 @1.04GHz 8G RAM 480G SSD * Virtualization : unprivileged lxc container on Proxmox * 6 GByte RAM für den iobroker Container * Remote-Access über Wireguard meiner Fritzbox
-
Ich lese auf dem PVE-Hypervisor Linux per bash script im cron job S.M.A.R.T Parameter der System SSD und einer 4TB USB-HDD ein und schreibe per SimpleAPI einige mir interessant vorkommende Parameter nach "userdata". Alle 4 Stunden zur 11. Minute der Stunde werden die Werte aktualisert.
S.M.A.R.T Ausgabe meiner USB-HDD
Interessant fand ich da Seek_Error_Rate und Raw_Read_Error_Rate
Die entsprechenden Zeilen sehen so aus ...
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE ... 1 Raw_Read_Error_Rate 0x000f 081 063 006 Pre-fail Always - 242543912 ... 7 Seek_Error_Rate 0x000f 087 060 030 Pre-fail Always - 475250992Interessant ist "VALUE", da der Wert "normalisiert ist, gilt, je höher, desto besser Maximum ist 100. Gibt den aktuellen Wert wieder.
"WORST" ist da schlechteste jemals gemessene Wert.
"THRESH" ist der Schwellwert, bei dem ein Defekt sehr nahe ist.Bei der SSD habe ich erstmal weniger Parameter angedacht, da fehlt womöglich noch etwas.
An einigen Stellen differieren die Parameter, sodass die angedachte allgemeine Einlese-Funktion nicht möglich ist - schon für diese beiden Platten habe ich individuelle Funktionen bauen müssen...Hier die komplette Ausgabe der SSD
Neben der "Raw_Read_Error_Rate" habe ich nur "VALUE" aus...
Percent_Lifetime_Remain 0x0030 092 092 001 Old_age Offline - 8.... extrahiert
Das Bash-Script wird auf dem PVE-System selber ausgeführt
Erst wird eine Textdatei mit dem Output von Smartctrl erzeugt, dann wird diese passend in der entsprechenden Funktion zerlegt
# Intenso USB hdd smartctl -a -d sat /dev/sdb >Testdata.txt write_userdata_hdd "Proxmox_N3000.HDD_Intenso1." # system SSD smartctl -a /dev/sda >Testdata.txt write_userdata_ssd "Proxmox_N3000.System_SSD."Hier der ganze Code:
#!/usr/bin/bash # to make script ready for cron PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin SimpleApiUrl="http://192.168.2.201:8087/set/0_userdata.0." echo "test_hdd_data.sh drive health check started" > /root/scripte/Proxmox_Skripte/last_run.log # parameter §1 is subpath (no leading dot but a trailing dot function write_userdata_hdd() { # normalized read error rate # use simple api to write to iobroker # example: http://192.168.1.:8087/set/javascript.0.test?value=1 # ReadErrorRate and ReadErrorRateWorst should be ABOVE ReadErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"NormalizedReadErrorRate?value="$(awk '/Raw_Read_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateWorst?value="$(awk '/Raw_Read_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateLimit?value="$(awk '/Raw_Read_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); # SeekErrorRate and SeekErrorRateWorst should be ABOVE SeekErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"SeekErrorRate?value="$(awk '/Seek_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"SeekErrorRateWorst?value="$(awk '/Seek_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"SeekErrorRateLimit?value="$(awk '/Seek_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"LastSmartResult?value="$2 } function write_userdata_ssd() { # normalized read error rate # use simple api to write to iobroker # example: http://192.168.1.:8087/set/javascript.0.test?value=1 # ReadErrorRate and ReadErrorRateWorst should be ABOVE ReadErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"NormalizedReadErrorRate?value="$(awk '/Raw_Read_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateWorst?value="$(awk '/Raw_Read_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateLimit?value="$(awk '/Raw_Read_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); # SeekErrorRate and SeekErrorRateWorst should be ABOVE SeekErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"PercentLifetimeRemain?value="$(awk '/Percent_Lifetime_Remain/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"LastSmartResult?value="$2 } # write smartctl of hdds of interest to file and analyze results # for test purpose comment out smartctl invocations and invoke write_userdata_... functions with off script got Testdata.txt # even possible on different linux machine # Intenso USB hdd smartctl -a -d sat /dev/sdb >/root/scripte/Proxmox_Skripte/Testdata.txt result=$? echo " test_hdd_data.sh drive health check data of usb hdd retrieved result="$result >> /root/scripte/Proxmox_Skripte/last_run.log write_userdata_hdd "Proxmox_N3000.HDD_Intenso1." $result # system SSD smartctl -a /dev/sda >/root/scripte/Proxmox_Skripte/Testdata.txt result=$? echo " test_hdd_data.sh drive health check data of system ssd retrieved result="$result >> /root/scripte/Proxmox_Skripte/last_run.log write_userdata_ssd "Proxmox_N3000.System_SSD." $result echo " test_hdd_data.sh drive health check finished" >> /root/scripte/Proxmox_Skripte/last_run.logHier die Datenpunkte, die ich manuell in Userdata erzeugt habe:
Und das der Eintrag in die root crontab (da man für smartmontools eh sudo braucht... habe aber zumindest die sh Datei readonly gemacht)11 */4 * * * bash /root/skripte/check_usb_hdd.sh 2>&1 /dev/nullHier noch die erste Grafana Auswertung der Messwerte als "Fieberkurven" vielleicht mache ich mir daraus auch noch Gauge-Views, aber da verliert man den Blick auf den "Trend"
Bei der SSD stehen die Thresholds für Alarm alle auf Null, also habe ich mir da auch nichts eingezeichnet, bei der HDD gibt es für Read-Errors eine Threshold von 6, für Seek-Errors einen von 30 - den habe ich da als roten dünnen Hintergrund dahintergeklemmt
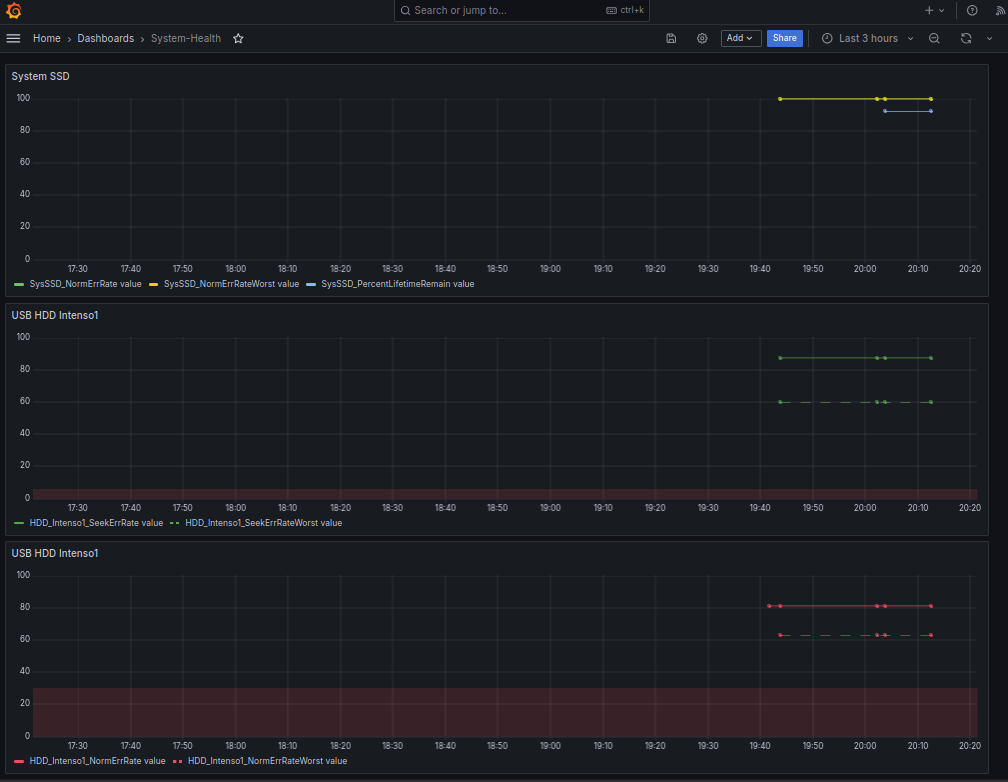
Um da nicht vier Stunden auf Messwerte zu warten (wenn Cron mal wieder gefeuert hat), habe ich zwischendurch das Script einige Male von Hand gestartet
-
Ich lese auf dem PVE-Hypervisor Linux per bash script im cron job S.M.A.R.T Parameter der System SSD und einer 4TB USB-HDD ein und schreibe per SimpleAPI einige mir interessant vorkommende Parameter nach "userdata". Alle 4 Stunden zur 11. Minute der Stunde werden die Werte aktualisert.
S.M.A.R.T Ausgabe meiner USB-HDD
Interessant fand ich da Seek_Error_Rate und Raw_Read_Error_Rate
Die entsprechenden Zeilen sehen so aus ...
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE ... 1 Raw_Read_Error_Rate 0x000f 081 063 006 Pre-fail Always - 242543912 ... 7 Seek_Error_Rate 0x000f 087 060 030 Pre-fail Always - 475250992Interessant ist "VALUE", da der Wert "normalisiert ist, gilt, je höher, desto besser Maximum ist 100. Gibt den aktuellen Wert wieder.
"WORST" ist da schlechteste jemals gemessene Wert.
"THRESH" ist der Schwellwert, bei dem ein Defekt sehr nahe ist.Bei der SSD habe ich erstmal weniger Parameter angedacht, da fehlt womöglich noch etwas.
An einigen Stellen differieren die Parameter, sodass die angedachte allgemeine Einlese-Funktion nicht möglich ist - schon für diese beiden Platten habe ich individuelle Funktionen bauen müssen...Hier die komplette Ausgabe der SSD
Neben der "Raw_Read_Error_Rate" habe ich nur "VALUE" aus...
Percent_Lifetime_Remain 0x0030 092 092 001 Old_age Offline - 8.... extrahiert
Das Bash-Script wird auf dem PVE-System selber ausgeführt
Erst wird eine Textdatei mit dem Output von Smartctrl erzeugt, dann wird diese passend in der entsprechenden Funktion zerlegt
# Intenso USB hdd smartctl -a -d sat /dev/sdb >Testdata.txt write_userdata_hdd "Proxmox_N3000.HDD_Intenso1." # system SSD smartctl -a /dev/sda >Testdata.txt write_userdata_ssd "Proxmox_N3000.System_SSD."Hier der ganze Code:
#!/usr/bin/bash # to make script ready for cron PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin SimpleApiUrl="http://192.168.2.201:8087/set/0_userdata.0." echo "test_hdd_data.sh drive health check started" > /root/scripte/Proxmox_Skripte/last_run.log # parameter §1 is subpath (no leading dot but a trailing dot function write_userdata_hdd() { # normalized read error rate # use simple api to write to iobroker # example: http://192.168.1.:8087/set/javascript.0.test?value=1 # ReadErrorRate and ReadErrorRateWorst should be ABOVE ReadErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"NormalizedReadErrorRate?value="$(awk '/Raw_Read_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateWorst?value="$(awk '/Raw_Read_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateLimit?value="$(awk '/Raw_Read_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); # SeekErrorRate and SeekErrorRateWorst should be ABOVE SeekErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"SeekErrorRate?value="$(awk '/Seek_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"SeekErrorRateWorst?value="$(awk '/Seek_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"SeekErrorRateLimit?value="$(awk '/Seek_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"LastSmartResult?value="$2 } function write_userdata_ssd() { # normalized read error rate # use simple api to write to iobroker # example: http://192.168.1.:8087/set/javascript.0.test?value=1 # ReadErrorRate and ReadErrorRateWorst should be ABOVE ReadErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"NormalizedReadErrorRate?value="$(awk '/Raw_Read_Error_Rate/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateWorst?value="$(awk '/Raw_Read_Error_Rate/{print $5}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"NormalizedReadErrorRateLimit?value="$(awk '/Raw_Read_Error_Rate/{print $6}' /root/scripte/Proxmox_Skripte/Testdata.txt); # SeekErrorRate and SeekErrorRateWorst should be ABOVE SeekErrorRateLimit # decreasing distance to limit is an indicator for hdd getting worse curl $SimpleApiUrl$1"PercentLifetimeRemain?value="$(awk '/Percent_Lifetime_Remain/{print $4}' /root/scripte/Proxmox_Skripte/Testdata.txt); curl $SimpleApiUrl$1"LastSmartResult?value="$2 } # write smartctl of hdds of interest to file and analyze results # for test purpose comment out smartctl invocations and invoke write_userdata_... functions with off script got Testdata.txt # even possible on different linux machine # Intenso USB hdd smartctl -a -d sat /dev/sdb >/root/scripte/Proxmox_Skripte/Testdata.txt result=$? echo " test_hdd_data.sh drive health check data of usb hdd retrieved result="$result >> /root/scripte/Proxmox_Skripte/last_run.log write_userdata_hdd "Proxmox_N3000.HDD_Intenso1." $result # system SSD smartctl -a /dev/sda >/root/scripte/Proxmox_Skripte/Testdata.txt result=$? echo " test_hdd_data.sh drive health check data of system ssd retrieved result="$result >> /root/scripte/Proxmox_Skripte/last_run.log write_userdata_ssd "Proxmox_N3000.System_SSD." $result echo " test_hdd_data.sh drive health check finished" >> /root/scripte/Proxmox_Skripte/last_run.logHier die Datenpunkte, die ich manuell in Userdata erzeugt habe:
Und das der Eintrag in die root crontab (da man für smartmontools eh sudo braucht... habe aber zumindest die sh Datei readonly gemacht)11 */4 * * * bash /root/skripte/check_usb_hdd.sh 2>&1 /dev/nullChatGPT sag mir, dass diese Parameter wichtig sind
Dein SSD-Status zeigt, dass die SMART-Gesundheitsprüfung bestanden wurde. Hier sind die wichtigsten Punkte:
- Gesundheitszustand: „PASSED“ (keine Probleme erkannt).
- Betriebsstunden: 14.036 Stunden.
- Restleben: 92 % (das bedeutet, dass die SSD noch eine gute Lebensdauer hat).
- Reallocated Blocks: 0 (keine fehlerhaften Blöcke).
- Temperatur: 32 °C (normal).
Insgesamt sieht es so aus, als ob deine SSD gut funktioniert. Du solltest regelmäßig Backups machen und die SMART-Werte im Auge behalten.
-
ChatGPT sag mir, dass diese Parameter wichtig sind
Dein SSD-Status zeigt, dass die SMART-Gesundheitsprüfung bestanden wurde. Hier sind die wichtigsten Punkte:
- Gesundheitszustand: „PASSED“ (keine Probleme erkannt).
- Betriebsstunden: 14.036 Stunden.
- Restleben: 92 % (das bedeutet, dass die SSD noch eine gute Lebensdauer hat).
- Reallocated Blocks: 0 (keine fehlerhaften Blöcke).
- Temperatur: 32 °C (normal).
Insgesamt sieht es so aus, als ob deine SSD gut funktioniert. Du solltest regelmäßig Backups machen und die SMART-Werte im Auge behalten.
@oliverio Hatte noch Probleme, dass das Script zwar aus der Console gestartet gelaufen ist, aber aus dem cron nicht funktioniert hat ...
Nach Internetrecherche kriegt die Shell anscheinend nicht alle ENV-Einträge der normalen Umgebung
Mit "env" kann man sich das anschauen
Crontab-Eintrag, um zu schauen, wie das Env im cron aussieht:
* * * * * env >mist.envmist.env
HOME=/root LOGNAME=root PATH=/usr/bin:/bin LANG=en_US.UTF-8 SHELL=/bin/sh PWD=/rootenv aus der konsole
SHELL=/bin/bash PWD=/root LOGNAME=root XDG_SESSION_TYPE=tty MOTD_SHOWN=pam HOME=/root LANG=en_US.UTF-8 XDG_SESSION_CLASS=user TERM=xterm-256color USER=root SHLVL=1 XDG_SESSION_ID=19428 XDG_RUNTIME_DIR=/run/user/0 HUSHLOGIN=FALSE PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/0/bus MAIL=/var/mail/root _=/usr/bin/env OLDPWD=/root/scripte/Proxmox_Skriptehabe mir den PATH aus der Konsole in das Bash Script an den Anfang kopiert und jetzt läuft das Script auch aus dem cron
Neueste Version, mit Auswertung des Rückgabewertes habe ich im obersten Beitrag abgelegt, das alte Listing ersetzt
Intel(R) Celeron(R) CPU N3000 @1.04GHz 8G RAM 480G SSD * Virtualization : unprivileged lxc container on Proxmox * 6 GByte RAM für den iobroker Container * Remote-Access über Wireguard meiner Fritzbox
-
@oliverio Hatte noch Probleme, dass das Script zwar aus der Console gestartet gelaufen ist, aber aus dem cron nicht funktioniert hat ...
Nach Internetrecherche kriegt die Shell anscheinend nicht alle ENV-Einträge der normalen Umgebung
Mit "env" kann man sich das anschauen
Crontab-Eintrag, um zu schauen, wie das Env im cron aussieht:
* * * * * env >mist.envmist.env
HOME=/root LOGNAME=root PATH=/usr/bin:/bin LANG=en_US.UTF-8 SHELL=/bin/sh PWD=/rootenv aus der konsole
SHELL=/bin/bash PWD=/root LOGNAME=root XDG_SESSION_TYPE=tty MOTD_SHOWN=pam HOME=/root LANG=en_US.UTF-8 XDG_SESSION_CLASS=user TERM=xterm-256color USER=root SHLVL=1 XDG_SESSION_ID=19428 XDG_RUNTIME_DIR=/run/user/0 HUSHLOGIN=FALSE PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/0/bus MAIL=/var/mail/root _=/usr/bin/env OLDPWD=/root/scripte/Proxmox_Skriptehabe mir den PATH aus der Konsole in das Bash Script an den Anfang kopiert und jetzt läuft das Script auch aus dem cron
Neueste Version, mit Auswertung des Rückgabewertes habe ich im obersten Beitrag abgelegt, das alte Listing ersetzt
Interessanterweise gibt es bei der USB-HDD einen Returncode !=0
Bei der SSD kommt immer eine 0 (alles O.K.) als "result" zurück, bei der HDD eine 4... also Bit 2 gesetzt ...
ich vermute, aufgrund der folgenden Fehlermeldung mit anschließender Warnung
... === START OF READ SMART DATA SECTION === SMART Status command failed: scsi error unsupported scsi opcode SMART overall-health self-assessment test result: PASSED Warning: This result is based on an Attribute check. ....smartctl -a /dev/sda >/root/scripte/Proxmox_Skripte/Testdata.txt result=$?Das bedeutet laut untenstehendem ...
Return Values
The return values of smartctl are defined by a bitmask. If all is well with the disk, the return value (exit status) of smartctl is 0 (all bits turned off). If a problem occurs, or an error, potential error, or fault is detected, then a non-zero status is returned. In this case, the eight different bits in the return value have the following meanings for ATA disks; some of these values may also be returned for SCSI disks.
Bit 0:
Command line did not parse.
Bit 1:
Device open failed, device did not return an IDENTIFY DEVICE structure, or device is in a low-power mode (see '-n' option above).
Bit 2:
Some SMART or other ATA command to the disk failed, or there was a checksum error in a SMART data structure (see '-b' option above).
Bit 3:
SMART status check returned "DISK FAILING".
Bit 4:
We found prefail Attributes <= threshold.
Bit 5:
SMART status check returned "DISK OK" but we found that some (usage or prefail) Attributes have been <= threshold at some time in the past.
Bit 6:
The device error log contains records of errors.
Bit 7:
The device self-test log contains records of errors. [ATA only] Failed self-tests outdated by a newer successful extended self-test are ignored.
To test within the shell for whether or not the different bits are turned on or off, you can use the following type of construction (this is bash syntax):smartstat=$(($? & 8))
This looks at only at bit 3 of the exit status $? (since 8=2^3). The shell variable $smartstat will be nonzero if SMART status check returned "disk failing" and zero otherwise.
This bash script prints all status bits:
status=$?
for ((i=0; i<8; i++)); do
echo "Bit $i: $((status & 2**i && 1))"
done
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
224
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge