

Test Adapter influxdb 2.0
-
@apollon77 ich habe Grafana am laufen und möchte in Grafana nun die Settings für InfluxDB setzen. Influxdb wurde in ioBroker auch erfolgreich installiert. Nach Eingabe der Daten kommt immer dieser Fehler:
InfluxDB Error: database name required
Wie kann ich diesen beheben?
Kannst Du mir weiterhelfen?
@turbosasch Ja welchen DB namen haste denn in Grafana gesetzt?
-
@turbosasch Ja welchen DB namen haste denn in Grafana gesetzt?
Hallo zusammen,
ich habe gestern den Adpter von 1.x auf 2.6.3 upgedatet. Seither bekomme ich keine Verbindung mehr zur Influx Datenbank. Jetzt habe ich eine zweite Instanz istalliert. Die diese läuft mit den selben einstellungen problemlos. Woran könnte das liegen?
-
Hallo zusammen,
ich habe gestern den Adpter von 1.x auf 2.6.3 upgedatet. Seither bekomme ich keine Verbindung mehr zur Influx Datenbank. Jetzt habe ich eine zweite Instanz istalliert. Die diese läuft mit den selben einstellungen problemlos. Woran könnte das liegen?
@banis Ohne Logs oder mehr Details müsste ich jetzt die Glaskugel rausholen. Kann es sein das Du das Passwort neu eingeben musst? So wie es im Changelog steht und wie es Admin auch als eine von Zwei Messages beim Update via Admin angezeigt hat? ;-)
-
@banis Ohne Logs oder mehr Details müsste ich jetzt die Glaskugel rausholen. Kann es sein das Du das Passwort neu eingeben musst? So wie es im Changelog steht und wie es Admin auch als eine von Zwei Messages beim Update via Admin angezeigt hat? ;-)
-
@apollon77 wow in dem Fall hast du doch ne Glaskugel:-) Musste tatsächlich das Passwort neue eingeben. Sorry für die überflüssige Frage, aber bei so vielen Versionssprüngen hab ich den Changelog nur flüchtig überflogen.
-
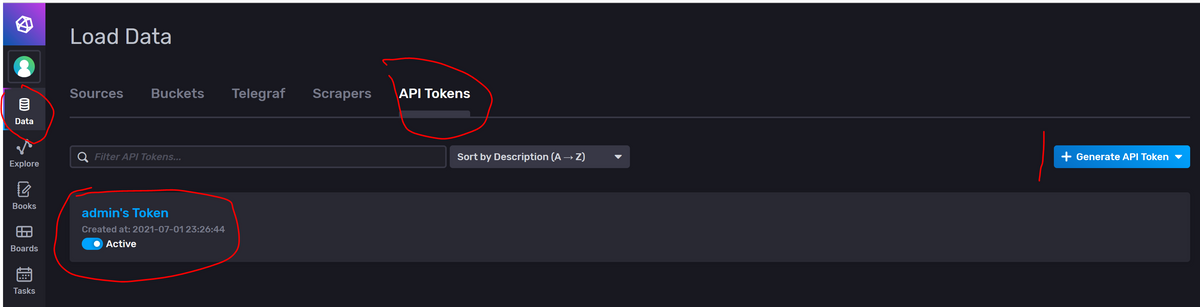
@humidor Hier. Über den Button "Generate API Token" kannst du einen Token generieren:
@feuersturm ich greife den Punkt hier nochmals als Hinweis auf, da er mich wirklich einige Stunden gekostet hat.
Ich hatte an den letzten Tagen bereits mehrfach neue Tokens generiert, bekam dennoch aber immer wieder 'http authorization failures' so das ich mich in meiner verzweifelten Suche dann eben hier auch nochmals durch den gesamten Fred gehangelt hatte.
Als ich den Post hier lass dachte ich mir, ok, 'last try' sonst ein entsprechender Hilferuf-Post hier.Weil ich irgendwo mal weiter oben etwas über Sonderzeichen gelesen hatte, (ich hatte meine vorherigen Tokens iobroker@influx genannt), habe ich nun einen ganz simplen Namen genommen.
Damit ging es dann sofort. Ich schreibe das hier mal für andere 'Verzweifelte' auf, da mir, sollte es daran gelegen haben, dieser Zusammenhang überhaupt nicht klar war, da der Name des Tokens ja auch nicht in den Adapter eingetragen wird sondern die Organisation.
Die deutlich mehr Wissenden hier können das ja gerne auch nochmals verifizieren :-)
Achso, evtl. noch, da ich in Sachen Installation (im Proxmox Container) auch erst einmal eine kleine Odysee hinter mich gebracht hatte, Mit dem Tutorial hier (YT: https://www.youtube.com/watch?v=Jx7OeFlPr-8), bzw. denn hinterlegten Befehlen, hatte es dann endlich geklappt. Alle anderen Tutorials führten an irgendeiner Stelle immer wieder 'vor den Poller' wo ich als Linux Noob, trotz viel Recherche zu den einzelnen Problemchen. jeweils nicht mehr weiter kam.
Evtl. gibt's da ja noch etwas besseres, aber Eddy scheint das immer wieder nachgepflegt zu haben.Pedder
All @Proxmox/Trixie auf HP Elitedesk 800 G4; Zigbee: ZigStar (LAN), ~110Devices
Unifi, Motioneye/3Reolinks, PiHole, Bosch CS7800i via BBQKees/EMS-ESP, Fronius/BYD 11kWp via Modbus
Under construction: Smart-WoMo auf Raspi4 -
@feuersturm ich greife den Punkt hier nochmals als Hinweis auf, da er mich wirklich einige Stunden gekostet hat.
Ich hatte an den letzten Tagen bereits mehrfach neue Tokens generiert, bekam dennoch aber immer wieder 'http authorization failures' so das ich mich in meiner verzweifelten Suche dann eben hier auch nochmals durch den gesamten Fred gehangelt hatte.
Als ich den Post hier lass dachte ich mir, ok, 'last try' sonst ein entsprechender Hilferuf-Post hier.Weil ich irgendwo mal weiter oben etwas über Sonderzeichen gelesen hatte, (ich hatte meine vorherigen Tokens iobroker@influx genannt), habe ich nun einen ganz simplen Namen genommen.
Damit ging es dann sofort. Ich schreibe das hier mal für andere 'Verzweifelte' auf, da mir, sollte es daran gelegen haben, dieser Zusammenhang überhaupt nicht klar war, da der Name des Tokens ja auch nicht in den Adapter eingetragen wird sondern die Organisation.
Die deutlich mehr Wissenden hier können das ja gerne auch nochmals verifizieren :-)
Achso, evtl. noch, da ich in Sachen Installation (im Proxmox Container) auch erst einmal eine kleine Odysee hinter mich gebracht hatte, Mit dem Tutorial hier (YT: https://www.youtube.com/watch?v=Jx7OeFlPr-8), bzw. denn hinterlegten Befehlen, hatte es dann endlich geklappt. Alle anderen Tutorials führten an irgendeiner Stelle immer wieder 'vor den Poller' wo ich als Linux Noob, trotz viel Recherche zu den einzelnen Problemchen. jeweils nicht mehr weiter kam.
Evtl. gibt's da ja noch etwas besseres, aber Eddy scheint das immer wieder nachgepflegt zu haben.@pedder007 Wenn Ihr da Infos habt die man in de Readme vom Adapter schreiben sollte oder zb wisst welche Sonderzeichen ggf probleme machen dann bitte issue beim Adapter anlegen bzw gern Änderungen für die Readme vorschlagen
Beitrag hat geholfen? Votet rechts unten im Beitrag :-) https://paypal.me/Apollon77 / https://github.com/sponsors/Apollon77
- Debug-Log für Instanz einschalten? Admin -> Instanzen -> Expertenmodus -> Instanz aufklappen - Loglevel ändern
- Logfiles auf Platte /opt/iobroker/log/… nutzen, Admin schneidet Zeilen ab
-
@pedder007 Wenn Ihr da Infos habt die man in de Readme vom Adapter schreiben sollte oder zb wisst welche Sonderzeichen ggf probleme machen dann bitte issue beim Adapter anlegen bzw gern Änderungen für die Readme vorschlagen
@apollon77 Hi, habe ich gerade mal gemacht.
Da fällt mir noch ein (hier Off-Topic) was machen wir mit dem Tuya Wassermelder, den wir vor ~2 Wochen im ZigBee Adapter manuell nachgepflegt hatten?
Ich habe mittlerweile den zweiten auch noch angelernt und es gibt keine Probleme mehr mit dem Abruf des nicht-vorhandenen %-Batterie-Levels. Leider habe allerdings zwischenzeitlich keine halbwegs leere CR2032 mehr hier gehabt (die Holde hatte gerade alle entsorgt), sodass ich den nun vorhandenen true/false Batterie 'low' Status auch nicht mehr prüfen konnte.Pedder
All @Proxmox/Trixie auf HP Elitedesk 800 G4; Zigbee: ZigStar (LAN), ~110Devices
Unifi, Motioneye/3Reolinks, PiHole, Bosch CS7800i via BBQKees/EMS-ESP, Fronius/BYD 11kWp via Modbus
Under construction: Smart-WoMo auf Raspi4 -
@apollon77 Hi, habe ich gerade mal gemacht.
Da fällt mir noch ein (hier Off-Topic) was machen wir mit dem Tuya Wassermelder, den wir vor ~2 Wochen im ZigBee Adapter manuell nachgepflegt hatten?
Ich habe mittlerweile den zweiten auch noch angelernt und es gibt keine Probleme mehr mit dem Abruf des nicht-vorhandenen %-Batterie-Levels. Leider habe allerdings zwischenzeitlich keine halbwegs leere CR2032 mehr hier gehabt (die Holde hatte gerade alle entsorgt), sodass ich den nun vorhandenen true/false Batterie 'low' Status auch nicht mehr prüfen konnte.@pedder007 Hm ...
1.) Offtopic blöd, schiebs bitte in den richtigen Thread
2.) Was hab ich mit zigbee zu tun? ;-)Beitrag hat geholfen? Votet rechts unten im Beitrag :-) https://paypal.me/Apollon77 / https://github.com/sponsors/Apollon77
- Debug-Log für Instanz einschalten? Admin -> Instanzen -> Expertenmodus -> Instanz aufklappen - Loglevel ändern
- Logfiles auf Platte /opt/iobroker/log/… nutzen, Admin schneidet Zeilen ab
-
Hallo zusammen,
ich habe ja bereits vor längerer Zeit meine Daten erfolgreich auf v2 umgezogen. Nun bin ich über das Feature Tags gestolpert, mit dem q, ack und from als Tag und nicht als Field gespeichert werden können (Zwischenfrage: Was ist eigentlich q?). Nachteil ist wohl, dass man bestehende Measurements nicht einfach auf Tags umstellen kann.
https://stackoverflow.com/questions/68994445/influxdb-how-to-convert-field-to-tag-in-influxdb-v2-0
Mit flux kann man wohl Daten eines Measurements in ein neues schreiben und dabei fields in tags umwandeln. Meine Idee wäre nun, alle Measuremments in ein neues bucket zu schreiben, dabei die fields q, ack und from in Tags umzuwandeln und dann den influxDB Adapter auf das neue bucket umzustellen?Was meint ihr? Hat das vielleicht schon jemand versucht?
@sputnik24 said in Test Adapter influxdb 2.0:
Hallo zusammen,
ich habe ja bereits vor längerer Zeit meine Daten erfolgreich auf v2 umgezogen. Nun bin ich über das Feature Tags gestolpert, mit dem q, ack und from als Tag und nicht als Field gespeichert werden können (Zwischenfrage: Was ist eigentlich q?). Nachteil ist wohl, dass man bestehende Measurements nicht einfach auf Tags umstellen kann.
https://stackoverflow.com/questions/68994445/influxdb-how-to-convert-field-to-tag-in-influxdb-v2-0
Mit flux kann man wohl Daten eines Measurements in ein neues schreiben und dabei fields in tags umwandeln. Meine Idee wäre nun, alle Measuremments in ein neues bucket zu schreiben, dabei die fields q, ack und from in Tags umzuwandeln und dann den influxDB Adapter auf das neue bucket umzustellen?Was meint ihr? Hat das vielleicht schon jemand versucht?
Hallo zusammen,
gibt es zu den "Konvertierung" von influx 1.x measurments zu influx 2.x mesurements mit tags schon Neuigkeiten?
@apollon77
Weiter habe ich einmal eine Verständnisfrage zu den Tags. Ich schreiibe ja per ioBroker die Daatenpunkte in die db. Ist es mit den Tags möglich, zu einem measurment - z.B. "Netzbezug" als Tags die beiden Werte "Power" und "Consuption" zu schreiben? Oder sind es nur die Tags q, ack und from?Danke und Gruß
-
@sputnik24 said in Test Adapter influxdb 2.0:
Hallo zusammen,
ich habe ja bereits vor längerer Zeit meine Daten erfolgreich auf v2 umgezogen. Nun bin ich über das Feature Tags gestolpert, mit dem q, ack und from als Tag und nicht als Field gespeichert werden können (Zwischenfrage: Was ist eigentlich q?). Nachteil ist wohl, dass man bestehende Measurements nicht einfach auf Tags umstellen kann.
https://stackoverflow.com/questions/68994445/influxdb-how-to-convert-field-to-tag-in-influxdb-v2-0
Mit flux kann man wohl Daten eines Measurements in ein neues schreiben und dabei fields in tags umwandeln. Meine Idee wäre nun, alle Measuremments in ein neues bucket zu schreiben, dabei die fields q, ack und from in Tags umzuwandeln und dann den influxDB Adapter auf das neue bucket umzustellen?Was meint ihr? Hat das vielleicht schon jemand versucht?
Hallo zusammen,
gibt es zu den "Konvertierung" von influx 1.x measurments zu influx 2.x mesurements mit tags schon Neuigkeiten?
@apollon77
Weiter habe ich einmal eine Verständnisfrage zu den Tags. Ich schreiibe ja per ioBroker die Daatenpunkte in die db. Ist es mit den Tags möglich, zu einem measurment - z.B. "Netzbezug" als Tags die beiden Werte "Power" und "Consuption" zu schreiben? Oder sind es nur die Tags q, ack und from?Danke und Gruß
@schtallone Aktuell nur die genannten Tags ... Es gibt noch https://github.com/ioBroker/ioBroker.influxdb/pull/278, was aber aus Zeitgründen noch in keiner Version drin ist. Kommt noch, dann gehen ggf auch Custom tags
-
@pedder007 Hm ...
1.) Offtopic blöd, schiebs bitte in den richtigen Thread
2.) Was hab ich mit zigbee zu tun? ;-)@apollon77 said in Test Adapter influxdb 2.0:
1.) Offtopic blöd, schiebs bitte in den richtigen Thread
2.) Was hab ich mit zigbee zu tun?Du hast sowas von Recht

Das Off-Topic ist Zustande gekommen, weil ich Dich mit Asgothian verwechselt habe, sorry! -
Hallo zusammen,
irgendwie bekomme ich keine Zugriffsrechte auf meine InfluxDB.
Habe Adapter installiert, Server und Organisation eingeben. Einen Custom Token in der InfluxDB generiert, der lese und schreibrechte für den iobroker Bucket hat.
Nun bekomme ich aber den Fehler:
Error: No organizations exists or the token do not have proper permissions. Please check the token (see Readme for Tipps)!Habe schon mit verschiedenen Token probiert. Immer der gleiche Fehler
Jemand ne Idee? -
Hallo zusammen,
irgendwie bekomme ich keine Zugriffsrechte auf meine InfluxDB.
Habe Adapter installiert, Server und Organisation eingeben. Einen Custom Token in der InfluxDB generiert, der lese und schreibrechte für den iobroker Bucket hat.
Nun bekomme ich aber den Fehler:
Error: No organizations exists or the token do not have proper permissions. Please check the token (see Readme for Tipps)!Habe schon mit verschiedenen Token probiert. Immer der gleiche Fehler
Jemand ne Idee?@michisa86888 readme vom adapter lesen? Nimm erstmal den Admin Token. Mehr Details da
-
Hallo zusammen,
irgendwie bekomme ich keine Zugriffsrechte auf meine InfluxDB.
Habe Adapter installiert, Server und Organisation eingeben. Einen Custom Token in der InfluxDB generiert, der lese und schreibrechte für den iobroker Bucket hat.
Nun bekomme ich aber den Fehler:
Error: No organizations exists or the token do not have proper permissions. Please check the token (see Readme for Tipps)!Habe schon mit verschiedenen Token probiert. Immer der gleiche Fehler
Jemand ne Idee?@michisa86888 sagte in Test Adapter influxdb 2.0:
Habe schon mit verschiedenen Token probiert. Immer der gleiche Fehler
Jemand ne Idee?Du benötigst, wenn du nicht den admin Token nimmst, mindestens einen „All Access Token“. Read/Write reicht nicht aus.
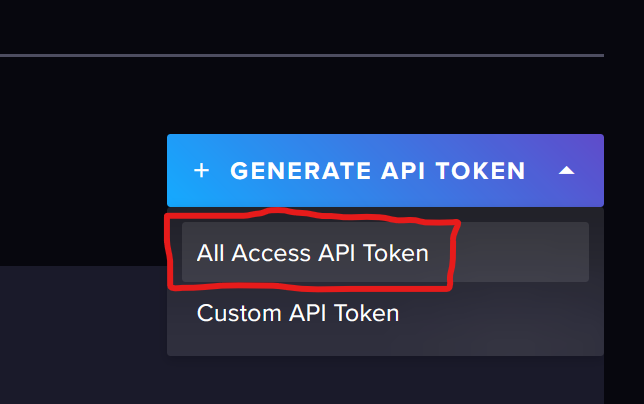
Dieser All Access Token funktioniert dann für ALLE Buckets dieser Organization.
-
@michisa86888 sagte in Test Adapter influxdb 2.0:
Habe schon mit verschiedenen Token probiert. Immer der gleiche Fehler
Jemand ne Idee?Du benötigst, wenn du nicht den admin Token nimmst, mindestens einen „All Access Token“. Read/Write reicht nicht aus.
Dieser All Access Token funktioniert dann für ALLE Buckets dieser Organization.
@marc-berg
Okay, habe ich gestern Abend probiert einen zu generieren. Da kam irgendeine Fehlermeldung. Bin aber erst wieder Montag zuhause.
Das mit dem Admin token habe ich irgendwo gelesen. Nur finde bzw. habe ich den admin token nicht? Kann ich den irgendwo in Influx bzw. über Konsole abfragen? -
@marc-berg
Okay, habe ich gestern Abend probiert einen zu generieren. Da kam irgendeine Fehlermeldung. Bin aber erst wieder Montag zuhause.
Das mit dem Admin token habe ich irgendwo gelesen. Nur finde bzw. habe ich den admin token nicht? Kann ich den irgendwo in Influx bzw. über Konsole abfragen?@michisa86888 sagte in Test Adapter influxdb 2.0:
@marc-berg
Okay, habe ich gestern Abend probiert einen zu generieren. Da kam irgendeine Fehlermeldung. Bin aber erst wieder Montag zuhause.
Das mit dem Admin token habe ich irgendwo gelesen. Nur finde bzw. habe ich den admin token nicht? Kann ich den irgendwo in Influx bzw. über Konsole abfragen?influx auth list --jsonEs sollte der erste sein. Du kannst ihn daran erkennen, dass in den Permissions kein "orgs" enthalten ist. Mit diesem Token hast du Rechte auf alle Organizations und muss auch benutzt werden, um ein Backup/Restore zu machen.
-
@sputnik24 said in Test Adapter influxdb 2.0:
Hallo zusammen,
ich habe ja bereits vor längerer Zeit meine Daten erfolgreich auf v2 umgezogen. Nun bin ich über das Feature Tags gestolpert, mit dem q, ack und from als Tag und nicht als Field gespeichert werden können (Zwischenfrage: Was ist eigentlich q?). Nachteil ist wohl, dass man bestehende Measurements nicht einfach auf Tags umstellen kann.
https://stackoverflow.com/questions/68994445/influxdb-how-to-convert-field-to-tag-in-influxdb-v2-0
Mit flux kann man wohl Daten eines Measurements in ein neues schreiben und dabei fields in tags umwandeln. Meine Idee wäre nun, alle Measuremments in ein neues bucket zu schreiben, dabei die fields q, ack und from in Tags umzuwandeln und dann den influxDB Adapter auf das neue bucket umzustellen?Was meint ihr? Hat das vielleicht schon jemand versucht?
Hallo zusammen,
gibt es zu den "Konvertierung" von influx 1.x measurments zu influx 2.x mesurements mit tags schon Neuigkeiten?
@apollon77
Weiter habe ich einmal eine Verständnisfrage zu den Tags. Ich schreiibe ja per ioBroker die Daatenpunkte in die db. Ist es mit den Tags möglich, zu einem measurment - z.B. "Netzbezug" als Tags die beiden Werte "Power" und "Consuption" zu schreiben? Oder sind es nur die Tags q, ack und from?Danke und Gruß
Auch wenn der Thread schon etwas älter ist...
Ich stand vor ein paar Wochen vor dem selben Problem beim Umstieg von InfluxDB 1.8.x auf 2.7.Wollte meine 1,6GB Datenbank des IOBrokers nicht einfach wegschmeißen, wollte mir aber auch noch keine Gedanken über ein Downsampling machen. Und irgendwie kam es mir immer komisch vor, dass der IOBroker Influx-Adapter die "Meta-Infos" als Fields speicherte und nicht als Tags. In der Doku der Influx stand auch, dass sowas besser in Tags aufgehoben sei wegen Geschwindigkeit, Speicherplatz, ...
Also mußte ein kleines Bash-Script her, dass die alten Daten in eine neue DB kopiert und dabei die 3 Fields ack, q und from in Tags umwandelt/schreibt. Parallel lief die neue DB schon und wurde parallel auch fleißig vom IOBroker weiter befüllt.
Ich bin nun wahrlich kein Programmierer und dementsprechend ist das Script bestimmt auch für Profis zum Haare raufen, aber es tut was es soll...
Zum Script:
- Es ist nicht wirklich parametrierbar gemacht, d.h. der alte und der neue DB-name stehen des öfteren in den einzelnen Zeilen. Bei mir waren es alt: iobroker/global und neu: iobroker2/global. Wer es anders benötigt muß es anpassen...
- Man braucht die Influx-cli und sie muß konfiguriert sein (so dass man nicht immer Token und Org mit angeben muß)
- Das Script arbeitet immer einzelne Batches ab, deren Größe ist oben im Script anpassbar. Solange die Daten relativ kontinuierlich in der DB sind gibt es kein Problem, ich hatte einige Measurements, in denen ich 15 Minuten-Werte meiner alten Wetterstation hatte und dann seit 1,5 Jahren mit einer neuen Wetterstation alle X Sekunden einen Wert. Da mußte ich dann die Batch-Größe stark runterschrauben...
- Vor dem Abarbeiten jedes neuen Batches prüft das Script, ob noch genug Arbeitsspeicher vorhanden ist (700MB war bei mir ein guter Wert und der steht in der "while" Schleife in Zeile 60). Wenn nicht wartet es 10 Sekunden und testet dann erneut, bis irgendwann wieder genug vorhanden ist...
- Wenn man das Script mal abbricht, fängt es wieder von vorne mit dem ersten verfügbaren Measurement an. In den Fällen habe ich dann vor dem Neustart des Scripts die übertragenen Daten geprüft und die schon abgearbeiteten Measurements aus der alten DB gelöscht
- Wenn einem Datenpunkt der alten DB mal eins der 3 Fields/Tags fehlt wird für q=0 gesetzt, für ack=false und für from=manual (ich hatte einige Werte mal manuell "nachgetragen" ohne die Fields auch zu schreiben...)
Nach dem Umkopieren war die DB dann nicht mehr 1,6GB groß sondern nur noch 600MB. Beim Arbeitsspeicher hat es leider nichts gebracht, der ist seit dem Umstieg von 1.8 auf 2.7 von ca. 1GB auf ca. 1,5GB für die Influx gestiegen...
Hier das Script:
IOBroker_copy_dbGruß
Hefo -
Auch wenn der Thread schon etwas älter ist...
Ich stand vor ein paar Wochen vor dem selben Problem beim Umstieg von InfluxDB 1.8.x auf 2.7.Wollte meine 1,6GB Datenbank des IOBrokers nicht einfach wegschmeißen, wollte mir aber auch noch keine Gedanken über ein Downsampling machen. Und irgendwie kam es mir immer komisch vor, dass der IOBroker Influx-Adapter die "Meta-Infos" als Fields speicherte und nicht als Tags. In der Doku der Influx stand auch, dass sowas besser in Tags aufgehoben sei wegen Geschwindigkeit, Speicherplatz, ...
Also mußte ein kleines Bash-Script her, dass die alten Daten in eine neue DB kopiert und dabei die 3 Fields ack, q und from in Tags umwandelt/schreibt. Parallel lief die neue DB schon und wurde parallel auch fleißig vom IOBroker weiter befüllt.
Ich bin nun wahrlich kein Programmierer und dementsprechend ist das Script bestimmt auch für Profis zum Haare raufen, aber es tut was es soll...
Zum Script:
- Es ist nicht wirklich parametrierbar gemacht, d.h. der alte und der neue DB-name stehen des öfteren in den einzelnen Zeilen. Bei mir waren es alt: iobroker/global und neu: iobroker2/global. Wer es anders benötigt muß es anpassen...
- Man braucht die Influx-cli und sie muß konfiguriert sein (so dass man nicht immer Token und Org mit angeben muß)
- Das Script arbeitet immer einzelne Batches ab, deren Größe ist oben im Script anpassbar. Solange die Daten relativ kontinuierlich in der DB sind gibt es kein Problem, ich hatte einige Measurements, in denen ich 15 Minuten-Werte meiner alten Wetterstation hatte und dann seit 1,5 Jahren mit einer neuen Wetterstation alle X Sekunden einen Wert. Da mußte ich dann die Batch-Größe stark runterschrauben...
- Vor dem Abarbeiten jedes neuen Batches prüft das Script, ob noch genug Arbeitsspeicher vorhanden ist (700MB war bei mir ein guter Wert und der steht in der "while" Schleife in Zeile 60). Wenn nicht wartet es 10 Sekunden und testet dann erneut, bis irgendwann wieder genug vorhanden ist...
- Wenn man das Script mal abbricht, fängt es wieder von vorne mit dem ersten verfügbaren Measurement an. In den Fällen habe ich dann vor dem Neustart des Scripts die übertragenen Daten geprüft und die schon abgearbeiteten Measurements aus der alten DB gelöscht
- Wenn einem Datenpunkt der alten DB mal eins der 3 Fields/Tags fehlt wird für q=0 gesetzt, für ack=false und für from=manual (ich hatte einige Werte mal manuell "nachgetragen" ohne die Fields auch zu schreiben...)
Nach dem Umkopieren war die DB dann nicht mehr 1,6GB groß sondern nur noch 600MB. Beim Arbeitsspeicher hat es leider nichts gebracht, der ist seit dem Umstieg von 1.8 auf 2.7 von ca. 1GB auf ca. 1,5GB für die Influx gestiegen...
Hier das Script:
IOBroker_copy_dbGruß
Hefo -
@hefo hey, super! Das ist cool. Wie hast Du den InfluxDB Adater denn für InfluxDB 2 eingestellt das das mit den tags so passt? (So noch vllt als ergänzung zu oben)
@apollon77 Einziger Unterschied zu einer Konfiguration des Influx Adapters für eine InfluxDB 2 mit Fields war eigentlich nur der Haken auf der Experten-Seite der Adapter-Config:
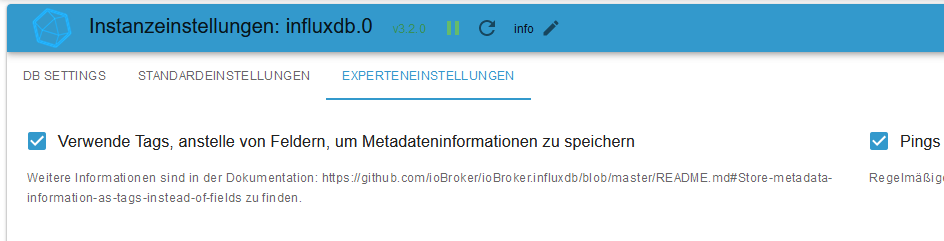
Man muß / sollte nur etwas auf die Reihenfolge achten, um ein Mischmasch von Fields und Tags in einer DB zu vermeiden.
Bzw. wollte ich es nicht drauf ankommen lassen herauszufinden, ob der Adapter beim Setzen des Hakens meckert, wenn schon Daten ohne Tags in der DB sind. Das gilt wahrscheinlich vor allem für Nutzer, die schon auf V2.x umgestiegen sind, aber bei den Fields geblieben sind.Vor setzen des Hakens bei "Verwende Tags..." sollte man die Influx auf 2.x (2.7 in meinem Fall) migriert haben. Dabei werden alle Datenbanken mit migriert. Bei mir gab es etwas Probleme durch den komischen Aufbau/Inhalt des Debian-Pakets von Influx, so dass im ersten Versuch alles in meinem User-home landete, beim zweiten Mal dann in /var/lib/influx/.influx...
 Das konnte ich dann aber ganz am Ende noch auf Dateisystem-Ebene hin- und herschieben...
Das konnte ich dann aber ganz am Ende noch auf Dateisystem-Ebene hin- und herschieben...Wenn man dann auf 2.x ist, einen Token für den IOBroker angelegt hat und der IOBroker wieder/weiter in seine DB schreibt, legt man eine neue DB an (in meinem Fall die iobroker2/global). Dem IOBroker-User dann auch Zugriff auf die neue DB gewähren!
Dann Influx-Adapter stoppen, auf der "DB Settings"-Seite des Adapters die neue DB angeben und auf der "Experteneinstellungen" Seite den Haken setzen.
Dann den Adapter wieder starten.
Mehr habe ich in Hinsicht "Konfiguration" nicht gemacht.Dass ich das "/global" mitschleppe hängt eigendlich nur daran, dass ich meine ganzen Grafana-Dashboards nicht über den Haufen schmeißen wollte, bzw. mir den Anpassungsaufwand ersparen wollte. Ein neues / geändertes DBRP-Mapping in der Influx hätte es wohl auch getan, so fand ich es aber übersichtlicher...
Für diejenigen, die schon mehr als eine Datenbank des Influx-Adapters haben, z.B. weil sie beim Umstieg von 1.8 auf 2.x eine Neue angelegt haben: Auch hier kann man das Script nehmen, dann muß man es halt zwei Mal anwenden. Einmal um die 1.8er Daten umzuscheffeln, einmal um die 2.x umzuscheffeln.
Wichtig in dem Zusammenhang: Das Script geht davon aus, dass keine Tags in der DB vorhanden sind. Was es macht, falls doch welche drin sind? Keine Ahnung, ich habe es nicht ausprobiert. Im besten Fall meckert es nicht und schreibt nur, da es keine passenden Fields findet, in alle Tags die "Manuellen" Werte (s.o.) rein. Die "richtigen" Tags würden dann überschrieben.Gruß
Hefo
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
224
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge