

Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet
-
Hallo.
Ich muss mal den alten Thread hoch holen.
Ich habe genau das gleiche Problem.
Ich lasse jeden Tag um 23:59 Uhr einen Wert in die InfluxDB schreiben.
Influx ordnet diesen Wert aber dem Folgetag zu.
Das liegt nun an InfluxDB und deren UTC Einstellung?
Wo und wie verändere ich das?Gruß
Andreas -
Hallo.
Ich muss mal den alten Thread hoch holen.
Ich habe genau das gleiche Problem.
Ich lasse jeden Tag um 23:59 Uhr einen Wert in die InfluxDB schreiben.
Influx ordnet diesen Wert aber dem Folgetag zu.
Das liegt nun an InfluxDB und deren UTC Einstellung?
Wo und wie verändere ich das?Gruß
Andreas@andreask sagte in Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet:
Das liegt nun an InfluxDB und deren UTC Einstellung?
Wo und wie verändere ich das?Moin,
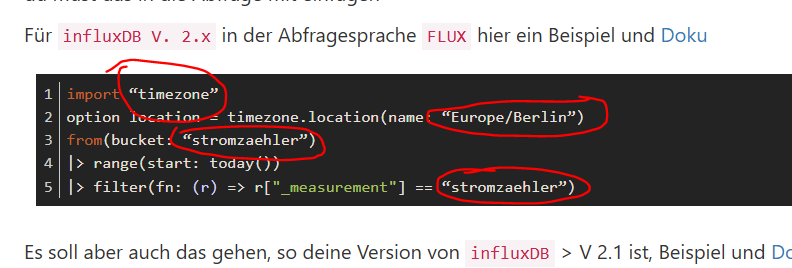
du must das in die Abfrage mit einfügen
Für
influxDB V. 2.xin der AbfragespracheFLUXhier ein Beispiel und Dokuimport “timezone” option location = timezone.location(name: “Europe/Berlin”) from(bucket: “stromzaehler”) |> range(start: today()) |> filter(fn: (r) => r["_measurement"] == “stromzaehler”)Es soll aber auch das gehen, so deine Version von
influxDB> V 2.1 ist, Beispiel und Dokuoption location = loadLocation(name:"Europe/Berlin") from(bucket: “stromzaehler”) |> range(start: today()) |> filter(fn: (r) => r["_measurement"] == “stromzaehler”)VG
Bernd -
@andreask sagte in Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet:
Das liegt nun an InfluxDB und deren UTC Einstellung?
Wo und wie verändere ich das?Moin,
du must das in die Abfrage mit einfügen
Für
influxDB V. 2.xin der AbfragespracheFLUXhier ein Beispiel und Dokuimport “timezone” option location = timezone.location(name: “Europe/Berlin”) from(bucket: “stromzaehler”) |> range(start: today()) |> filter(fn: (r) => r["_measurement"] == “stromzaehler”)Es soll aber auch das gehen, so deine Version von
influxDB> V 2.1 ist, Beispiel und Dokuoption location = loadLocation(name:"Europe/Berlin") from(bucket: “stromzaehler”) |> range(start: today()) |> filter(fn: (r) => r["_measurement"] == “stromzaehler”)VG
Bernd -
@dp20eic
Sorry, wenn ich fragen muss. Bin neu in dem Thema!
In die Query von Grafana?
Ich habe die InfluxDB v2.6.1 am Laufen@andreask sagte in Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet:
@dp20eic
Sorry, wenn ich fragen muss. Bin neu in dem Thema!
In die Query von Grafana?
Ich habe die InfluxDB v2.6.1 am LaufenMoin,
ja,, in Grafana im Panel/Daschborad welches du anpassen musst. Die Abfragesprache ist haltinfluxDB - Flux, wenn dein Grafana gegen eineinfluxDB V 2.xgebunden ist und Du dort mitFLUXabfragst.VG
BerndEdit, Bild gelöscht, da es mehr verwirrt als hilft.
-
Hallo.
Aktuell sieht meine Query so ausimport “timezone” option location = timezone.location(name: “Europe/Berlin”) from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "Täglicher Stromverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false) |> yield(name: "mean")Nun bekomme aber folgende Fehlermeldung
invalid: compilation failed: error @1:8-1:11: expected STRING, got ILLEGAL (“) at 1:8 error @1:8-1:11: invalid string literal error @1:19-1:22: invalid statement: ” error @3:37-3:59: invalid expression @3:59-3:62: ” error @3:46-3:52: invalid expression @3:43-3:46: “Als Datenquelle habe ich IngfluxDB mit Query Language "Flux" eingerichtet
-
Hallo.
Aktuell sieht meine Query so ausimport “timezone” option location = timezone.location(name: “Europe/Berlin”) from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "Täglicher Stromverbrauch") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false) |> yield(name: "mean")Nun bekomme aber folgende Fehlermeldung
invalid: compilation failed: error @1:8-1:11: expected STRING, got ILLEGAL (“) at 1:8 error @1:8-1:11: invalid string literal error @1:19-1:22: invalid statement: ” error @3:37-3:59: invalid expression @3:59-3:62: ” error @3:46-3:52: invalid expression @3:43-3:46: “Als Datenquelle habe ich IngfluxDB mit Query Language "Flux" eingerichtet
-
@andreask sagte in Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet:
import “timezone”
“Europe/Berlin”)die Anführungszeichen " sind falsch , liegt an deiner Tastatur !!!
Steht auch in der Meldung :
got ILLEGAL (“)
Warst schneller :)
Neh, kann auch an dem Kopierten von mir liegen :(
Wollte Ihm auch gerade die Fehlermeldungen mal erklären, für die Zukunft ;)
VG
Bernd -
Warst schneller :)
Neh, kann auch an dem Kopierten von mir liegen :(
Wollte Ihm auch gerade die Fehlermeldungen mal erklären, für die Zukunft ;)
VG
Bernd@dp20eic sagte in Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet:
Neh, kann auch an dem Kopierten von mir liegen
Ahh ... gar nicht oben gesehn :)
-
@dp20eic sagte in Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet:
Neh, kann auch an dem Kopierten von mir liegen
Ahh ... gar nicht oben gesehn :)
@glasfaser sagte in Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet:
Ahh ... gar nicht oben gesehn
Deswegen, wer kopiert, verliert :)
VG
Bernd -
Na toll

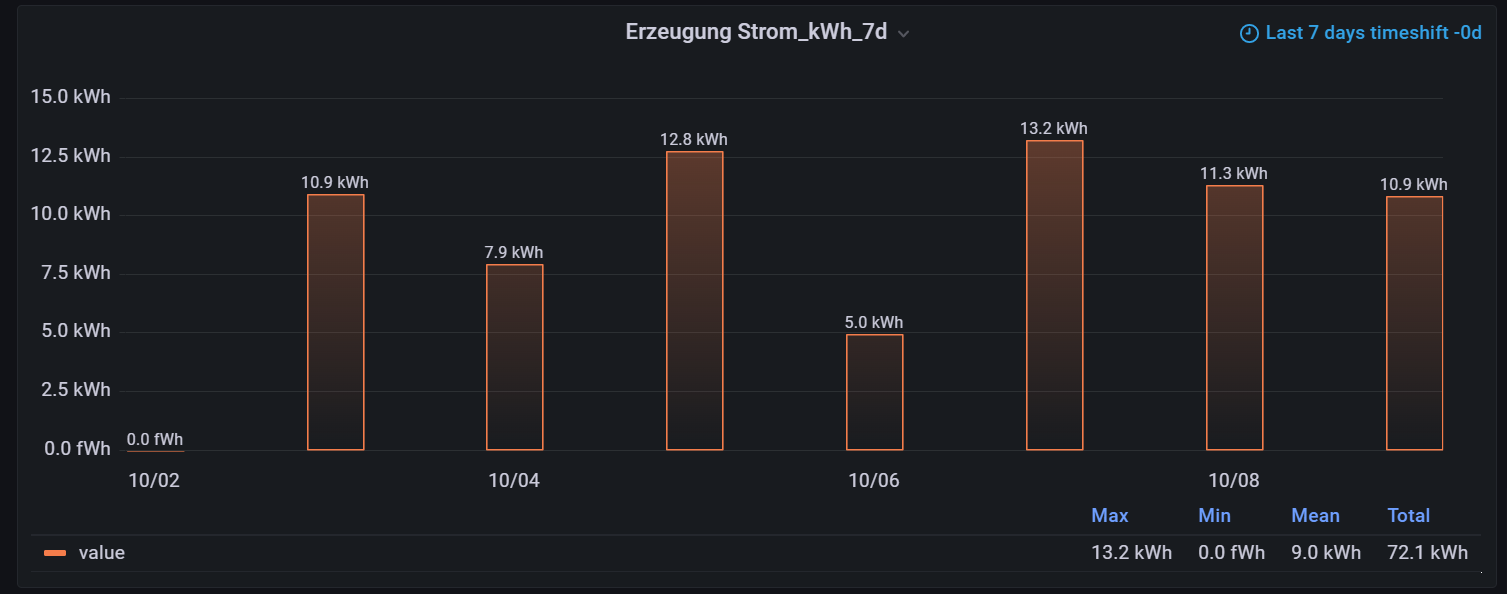
Nun habe ich es richtig hinzugefügt. Aber trotzdem wird der Wert, welcher laut iobroker am 29.01. um 23:59 Uhr (unter letzter Änderung) ins Objekt geschrieben wurde, immer noch im Balken des 30.01. angezeigt.
Was ist hier immer noch falsch? -
@andreask sagte in Grafana - InfluxDB 2 - Tageswert wird Folgetag zugeordnet:
Na toll
Nun habe ich es richtig hinzugefügt. Aber trotzdem wird der Wert, welcher laut iobroker am 29.01. um 23:59 Uhr (unter letzter Änderung) ins Objekt geschrieben wurde, immer noch im Balken des 30.01. angezeigt.
Was ist hier immer noch falsch?Mit Deiner Abfrage stellst Du nicht sicher, dass ein "aggregateWindow" auch exakt um 00:00 Uhr startet. Es könnte je nach Ausführungsstart auch um 23:50 Uhr starten und bis 00:05 Uhr gehen. Durch die Dynamik in der Abfrage (v.timeRangestart ...) ist das eher zufällig.
Ich habe das so gelöst, wobei ich je nach Abfragezeitraum noch fixe aggregateWindows berechne. Beachte dabei den Teil "date.truncate"!
Meine Abfrage bezieht sich auf einen Zählerstand, deshalb "difference", das müsstest Du für Dich anpassen.import "date" import "timezone" option location = timezone.location(name: "Europe/Berlin") v_duration = duration(v:uint(v: v.timeRangeStop) - uint(v: v.timeRangeStart)) v_every = if int(v:v_duration) <= int(v:2d) then 1h else if int(v:v_duration) <= int(v:7d) then 6h else if int(v:v_duration) <= int(v:30d) then 24h else 1w from(bucket: "iobroker") |> range(start:date.truncate(t:v.timeRangeStart, unit:v_every), stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "mqtt.0.power.Elektro.ZaehlerStandE") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every: v_every,fn:sum,timeSrc: "_start",createEmpty:false)Kann sein, dass es irgendwie auch einfacher geht. Eine bessere Lösung habe ich aber bisher nicht gefunden.
Edit: timeSrc: "_start" nicht vergessen! (letzte Zeile)
-
Na toll
Nun habe ich es richtig hinzugefügt. Aber trotzdem wird der Wert, welcher laut iobroker am 29.01. um 23:59 Uhr (unter letzter Änderung) ins Objekt geschrieben wurde, immer noch im Balken des 30.01. angezeigt.
Was ist hier immer noch falsch?Bin mir nicht sicher, ob das passt, habe keine passenden Daten.
|> range(start: today()) |> aggregateWindow(every: 1h, fn: mean, createEmpty: false)VG
Bernd -
Hier ist meine Lösung zu einem ähnlichen Problem. Sourceanalytix schreibt den Tagesverbrauch immer 00:01 am nächsten Tag. Ich hab also in Grafana ein Shift eingebaut. Unique brauche ich, weil SA bei Neustart des Adapters den Wert erneut schreibt.
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "multimedia-power-consumed") |> filter(fn: (r) => r["_field"] == "value") |> timeShift(duration: -24h) |> aggregateWindow(every: v.windowPeriod, fn: unique, createEmpty: false) |> unique() |> fill(column: "value", usePrevious: true)
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
278
Online32.9k
Benutzer83.2k
Themen1.3m
Beiträge