

Gelegentliche Verbindungsabbrüche (zigbee, telegram, wled)
-
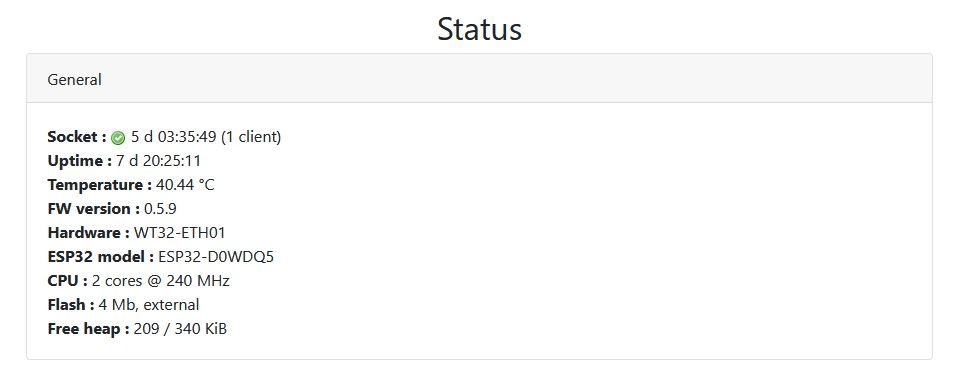
ich will mich nicht zu früh freun, aber es sieht aus als wäre es weg.
https://forum.proxmox.com/threads/e1000-driver-hang.58284/page-8
apt install -y ethtool ethtool -K eth0 gso off gro off tso off tx off rx off rxvlan off txvlan off sg offdas ist aber nach einem reboot wieder weg deswegen muss man es fest in die network interfaces eintragen.
@saeft_2003 Und was ist das genau für ein Fehler. Das ich das auch verstehe. :)
-
@saeft_2003 Und was ist das genau für ein Fehler. Das ich das auch verstehe. :)
Wohl irgendwie ein Treiberfehler im Kernel. Aber wirklich Ahnung hab ich davon nicht Hauptsache es geht…
-
Wohl irgendwie ein Treiberfehler im Kernel. Aber wirklich Ahnung hab ich davon nicht Hauptsache es geht…
@saeft_2003 Ok :)
-
@saeft_2003 Ok :)
Da es den Fehler schon sehr lange gibt verstehe ich bloß nicht warum der nicht mit einem Update behoben wird?!
Bei mir läuft es jetzt schon 2 Tage fehlerfrei, sonst kam es am Tag manchmal sogar mehrfach. Sollte bei mir also behoben sein…
-
@saeft_2003 Bei mir war es mehrmals am Tag gekommen. Und das ganze erst früh 10:45 was irgendwie komisch ist. Ich habe jetzt mal das ganze direkt in meinen Router gesteckt und über 1gb Verbindung verbunden. Anstatt 100mbits vielleicht war das schon das Problem.
Das ganze läuft jetzt 20h ohne Abbrüche aber ich möchte es nicht so laut sagen :) -
@saeft_2003 Bei mir war es mehrmals am Tag gekommen. Und das ganze erst früh 10:45 was irgendwie komisch ist. Ich habe jetzt mal das ganze direkt in meinen Router gesteckt und über 1gb Verbindung verbunden. Anstatt 100mbits vielleicht war das schon das Problem.
Das ganze läuft jetzt 20h ohne Abbrüche aber ich möchte es nicht so laut sagen :) -
Ich habe noch einmal Fragen zu diesen Thema seit paar Tagen kommt bei mir folgende Fehler. Hat das mit der Konfiguration des Netzwerk Adapter zutun in Proxmox?
an 21 19:17:59 pve pvestatd[1028]: auth key pair too old, rotating.. Jan 21 19:59:51 pve kernel: e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang: TDH <a> TDT <90> next_to_use <90> next_to_clean <9> buffer_info[next_to_clean]: time_stamp <10fac799d> next_to_watch <a> jiffies <10fac7b18> next_to_watch.status <0> MAC Status <40080083> PHY Status <796d> PHY 1000BASE-T Status <7800> PHY Extended Status <3000> PCI Status <10> Jan 21 19:59:53 pve kernel: e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang: TDH <a> TDT <90> next_to_use <90> next_to_clean <9> buffer_info[next_to_clean]: time_stamp <10fac799d> next_to_watch <a> jiffies <10fac7d08> next_to_watch.status <0> MAC Status <40080083> PHY Status <796d> PHY 1000BASE-T Status <7800> PHY Extended Status <3000> PCI Status <10> Jan 21 19:59:55 pve kernel: e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang: TDH <a> TDT <90> next_to_use <90> next_to_clean <9> buffer_info[next_to_clean]: time_stamp <10fac799d> next_to_watch <a> jiffies <10fac7f00> next_to_watch.status <0> MAC Status <40080083> PHY Status <796d> PHY 1000BASE-T Status <7800> PHY Extended Status <3000> PCI Status <10> Jan 21 19:59:57 pve kernel: e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang: TDH <a> TDT <90> next_to_use <90> next_to_clean <9> buffer_info[next_to_clean]: time_stamp <10fac799d> next_to_watch <a> jiffies <10fac80f0> next_to_watch.status <0> MAC Status <40080083> PHY Status <796d> PHY 1000BASE-T Status <7800> PHY Extended Status <3000> PCI Status <10> Jan 21 19:59:58 pve kernel: e1000e 0000:00:1f.6 eno1: Reset adapter unexpectedly Jan 21 19:59:58 pve kernel: vmbr0: port 1(eno1) entered disabled state Jan 21 20:00:02 pve kernel: e1000e 0000:00:1f.6 eno1: NIC Link is Up 1000 Mbps Full Duplex, Flow Control: Rx/Tx Jan 21 20:00:02 pve kernel: vmbr0: port 1(eno1) entered blocking state Jan 21 20:00:02 pve kernel: vmbr0: port 1(eno1) entered forwarding state -
oder liegt es an einem Update. Ich habe vor ein paar Tagen. In der Übersicht etwas gelöscht. Ich weiß nicht ob es damit zutun hat.

-
oder liegt es an einem Update. Ich habe vor ein paar Tagen. In der Übersicht etwas gelöscht. Ich weiß nicht ob es damit zutun hat.
sieht nach dem gleichen Fehler wie bei mir aus. Mach einfach den workaround dann ists wieder gut...
-
sieht nach dem gleichen Fehler wie bei mir aus. Mach einfach den workaround dann ists wieder gut...
@saeft_2003 Welchen meinst du? Und danach klappt es wohl wieder?
Wir haben zwar einen neuen Anbieter (Telekom) wo die Verbindung nicht stabil ist aber daran soll es ja nicht liegen. -
@saeft_2003 Welchen meinst du? Und danach klappt es wohl wieder?
Wir haben zwar einen neuen Anbieter (Telekom) wo die Verbindung nicht stabil ist aber daran soll es ja nicht liegen.hatte ich dir doch schon geschrieben. Bei mir ist der fehler seit dem 5.12.21 nicht mehr aufgetreten...
-
hatte ich dir doch schon geschrieben. Bei mir ist der fehler seit dem 5.12.21 nicht mehr aufgetreten...
@saeft_2003 Ja das stimmt das komische der Fehler ist erst seit den 15.01 da. Und davor war eine Zeitlang ruhe.
-
@saeft_2003 Ja das stimmt das komische der Fehler ist erst seit den 15.01 da. Und davor war eine Zeitlang ruhe.
Dann gib das doch einfach mal in der Konsole ein, dann wirste sehen obs weg ist oder nicht...
-
Dann gib das doch einfach mal in der Konsole ein, dann wirste sehen obs weg ist oder nicht...
@saeft_2003 Ja okay probiere ich. Ich habe auch mal Updates installiert und neugestartet. Aber die beiden Adapter sind erstmal richtig eingestellt? Weil im eno1 nichts drinnen steht?
-
ich will mich nicht zu früh freun, aber es sieht aus als wäre es weg.
https://forum.proxmox.com/threads/e1000-driver-hang.58284/page-8
apt install -y ethtool ethtool -K eth0 gso off gro off tso off tx off rx off rxvlan off txvlan off sg offdas ist aber nach einem reboot wieder weg deswegen muss man es fest in die network interfaces eintragen.
@saeft_2003 Funktioniert es bei dir eigentlich jetzt richtig?
-
@saeft_2003 Funktioniert es bei dir eigentlich jetzt richtig?
Ich hab doch erst vor 40min geschrieben das der Fehler bei mir seitdem nicht mehr aufgetreten ist…
-
Ich hab doch erst vor 40min geschrieben das der Fehler bei mir seitdem nicht mehr aufgetreten ist…
@saeft_2003 Habe ich überlesen. :)
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren Anmelden503
Online32.9k
Benutzer83.0k
Themen1.3m
Beiträge