

Daten Seriell von Paradigma Solaranlage lesen
-
@glitzi Mit binären Daten kannst du mit Buffern sehr schön arbeiten, da sie dir das lästige Rechnen und so abnehmen - dazu musst du aber aus text alle Leerzeichen entfernen.
Und die erste 0 scheint auch überzählig, wie kommst du denn an die Daten? Greifst du nicht direkt auf die Schnittstelle zu? Mir scheint es, als wäre der delimiter-parser für deine Zwecke super geeignet:const SerialPort = require('serialport') const Delimiter = require('@serialport/parser-delimiter') const port = new SerialPort('/dev/tty-usbserial1') const parser = port.pipe(new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { // Wird für jeden Abschnitt der Nutzdaten aufgerufen, d.h. beim ersten Aufruf wäre es ein Buffer mit Inhalt // 0902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085 // High und low byte tauschen (wirklich nötig??) chunk = chunk.swap16(); // Auf Daten zugreifen (die 4 bytes Startsequenz sind hier nicht enthalten) let val = chunk[1] * 256 + chunk[0] / 10; // Das /10 kommt mir spanisch vor, alternativ kannst du auch direkt mehrbytige // Zahlen aus dem Buffer lesen val = chunk.readUInt16BE(0) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen val = chunk.readUInt16LE(0) // liest eine 2-byte-Zahl ab Position 0 und tauscht Bytes });Wenn du die Daten nicht direkt vom Serialport bekommst, kannst du trotzdem den Parser nutzen:
const Delimiter = require('@serialport/parser-delimiter') const Passthrough = require('stream').PassThrough; const myStream = new Passthrough(); const parser = myStream.pipe(new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { // wie vorher }); // Bei jedem Dateneingang: myStream.push(hexDatenOhneLeerzeichen, "hex");Denk aber dran,
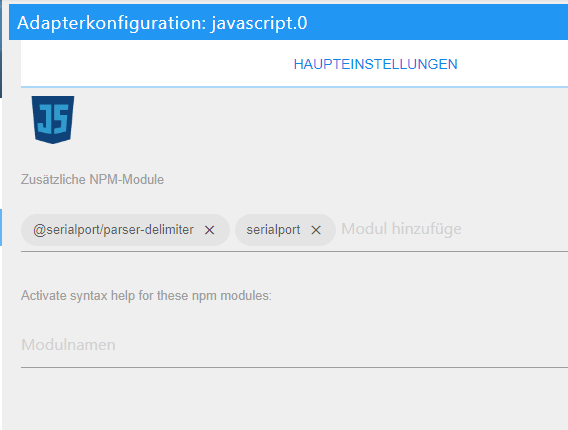
@serialport/parser-delimiterund ggf.serialportin den Adaptereinstellungen als zusätzliche Module zu laden.Das sieht super aus, obwohl ich das erstmal verdauen muss ;-)
die /10 kommen wegen der Kommastellen, nach Umrechnung 520 > auf 52,0
Die Daten werden nach dem Wechsel von OpenHAB auf IOBroker direkt von Serial Port kommen. In der Übergangsphase muss ich erstmal alle Daten, Schnittstellen, Influx, VIS usw. vorbereiten.
Daher noch eine Frage:
Wo könnte ich den Test-Datensatz z.B. "0000000 fc 3e 24 01 09 02 87 02 43 01 49 00 00 00 56 01 00 00 00 00 00 00 usw." einfügen?const myStream = new Passthrough(HIER?);
MfG
-
Das sieht super aus, obwohl ich das erstmal verdauen muss ;-)
die /10 kommen wegen der Kommastellen, nach Umrechnung 520 > auf 52,0
Die Daten werden nach dem Wechsel von OpenHAB auf IOBroker direkt von Serial Port kommen. In der Übergangsphase muss ich erstmal alle Daten, Schnittstellen, Influx, VIS usw. vorbereiten.
Daher noch eine Frage:
Wo könnte ich den Test-Datensatz z.B. "0000000 fc 3e 24 01 09 02 87 02 43 01 49 00 00 00 56 01 00 00 00 00 00 00 usw." einfügen?const myStream = new Passthrough(HIER?);
MfG
@glitzi sagte in Daten Seriell von Paradigma Solaranlage lesen:
die /10 kommen wegen der Kommastellen, nach Umrechnung 520 > auf 52,0
Dann musst du aber erst addieren und dann teilen, nicht nur das eine Byte. Also
chunk.readUInt16LE(0) / 10@glitzi sagte in Daten Seriell von Paradigma Solaranlage lesen:
Wo könnte ich den Test-Datensatz z.B. "0000000 fc 3e 24 01 09 02 87 02 43 01 49 00 00 00 56 01 00 00 00 00 00 00 usw." einfügen?
Vor Zeile 12:
const hexDatenOhneLeerzeichen = "fc3e240109...";Führende Nullen am besten weglassen, sonst wird versucht, daraus was zu lesen. Und wie gesagt ohne Leerzeichen
-
@glitzi sagte in Daten Seriell von Paradigma Solaranlage lesen:
die /10 kommen wegen der Kommastellen, nach Umrechnung 520 > auf 52,0
Dann musst du aber erst addieren und dann teilen, nicht nur das eine Byte. Also
chunk.readUInt16LE(0) / 10@glitzi sagte in Daten Seriell von Paradigma Solaranlage lesen:
Wo könnte ich den Test-Datensatz z.B. "0000000 fc 3e 24 01 09 02 87 02 43 01 49 00 00 00 56 01 00 00 00 00 00 00 usw." einfügen?
Vor Zeile 12:
const hexDatenOhneLeerzeichen = "fc3e240109...";Führende Nullen am besten weglassen, sonst wird versucht, daraus was zu lesen. Und wie gesagt ohne Leerzeichen
jetzt kämpfe ich noch mit folgender Fehlermeldung:
const Delimiter = require('@serialport/parser-delimiter') const Passthrough = require('stream').PassThrough; createState('Paradigma_Kollektor'); const myStream = new Passthrough(); const parser = myStream.pipe(new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { val = chunk.readUInt16BE(0) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Kollektor', text, true); }); // Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; myStream.push(hexDatenOhneLeerzeichen, "hex");19:08:50.225 error javascript.0 (11358) script.js.Paradigma_Test: Error: Cannot find module '/opt/iobroker/node_modules/iobroker.javascript/lib/../../stream' 19:08:50.227 error javascript.0 (11358) at script.js.Paradigma_Test:2:21 19:08:50.233 error javascript.0 (11358) script.js.Paradigma_Test: script.js.Paradigma_Test:2 19:08:50.234 error javascript.0 (11358) at script.js.Paradigma_Test:2:38Die Module habe ich eingebunden.
-
jetzt kämpfe ich noch mit folgender Fehlermeldung:
const Delimiter = require('@serialport/parser-delimiter') const Passthrough = require('stream').PassThrough; createState('Paradigma_Kollektor'); const myStream = new Passthrough(); const parser = myStream.pipe(new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { val = chunk.readUInt16BE(0) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Kollektor', text, true); }); // Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; myStream.push(hexDatenOhneLeerzeichen, "hex");19:08:50.225 error javascript.0 (11358) script.js.Paradigma_Test: Error: Cannot find module '/opt/iobroker/node_modules/iobroker.javascript/lib/../../stream' 19:08:50.227 error javascript.0 (11358) at script.js.Paradigma_Test:2:21 19:08:50.233 error javascript.0 (11358) script.js.Paradigma_Test: script.js.Paradigma_Test:2 19:08:50.234 error javascript.0 (11358) at script.js.Paradigma_Test:2:38Die Module habe ich eingebunden.
@glitzi Komisch, "stream" ist ein eingebautes Modul von Node.js - das müsste er finden (aber nicht da wo es gesucht wird).
Alternativ (ungetestet) lass mal Zeilen 2 und 5 weg, ändere 6 zu
const parser = new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") });und ersetze
myStreamin Zeile 15 durchparser -
@glitzi Komisch, "stream" ist ein eingebautes Modul von Node.js - das müsste er finden (aber nicht da wo es gesucht wird).
Alternativ (ungetestet) lass mal Zeilen 2 und 5 weg, ändere 6 zu
const parser = new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") });und ersetze
myStreamin Zeile 15 durchparser@AlCalzone
Einfach KLASSE es funktioniert...Noch eine Frage:
Ist es egal wenn folgende Zeilen erst am Ende stehen?
// Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; myStream.push(hexDatenOhneLeerzeichen, "hex"); -
@AlCalzone
Einfach KLASSE es funktioniert...Noch eine Frage:
Ist es egal wenn folgende Zeilen erst am Ende stehen?
// Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; myStream.push(hexDatenOhneLeerzeichen, "hex"); -
@AlCalzone
Einfach KLASSE es funktioniert...Noch eine Frage:
Ist es egal wenn folgende Zeilen erst am Ende stehen?
// Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; myStream.push(hexDatenOhneLeerzeichen, "hex");Wenn ich Testweise einige Zeichen vor das fc3... einfüge sollte das Skript ja trotzdem erst bei fc3 etc Anfangen.
Leider macht er das nicht?
const parser = new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") }); parser.on('data', chunk => { val = chunk.readUInt16LE(4) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Kollektor', val /10, true);@AlCalzone
Einfach KLASSE es funktioniert...Noch eine Frage:
Ist es egal wenn folgende Zeilen erst am Ende stehen?
// Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; Parser.push(hexDatenOhneLeerzeichen, "hex"); -
Wenn ich Testweise einige Zeichen vor das fc3... einfüge sollte das Skript ja trotzdem erst bei fc3 etc Anfangen.
Leider macht er das nicht?
const parser = new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") }); parser.on('data', chunk => { val = chunk.readUInt16LE(4) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Kollektor', val /10, true);@AlCalzone
Einfach KLASSE es funktioniert...Noch eine Frage:
Ist es egal wenn folgende Zeilen erst am Ende stehen?
// Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; Parser.push(hexDatenOhneLeerzeichen, "hex");@glitzi sagte in Daten Seriell von Paradigma Solaranlage lesen:
Wenn ich Testweise einige Zeichen vor das fc3... einfüge sollte das Skript ja trotzdem erst bei fc3 etc Anfangen.
Leider macht er das nicht?Nein, der teilt die eingehenden Daten an
fc3e2401auf. D.h. alles was vorher kommt, wird auch an die verarbeitende Methode gegeben.
Du könntest z.B. bevor du die Daten auswertest prüfen, ob die erhaltene Datenmenge dem entspricht, was zu erwarten ist, z.B.:if (chunk.length < 10) return;(ich weiß nicht wie viele Bytes Nutzdaten üblicherweise kommen, ggf. muss die Schwelle kleiner oder größer gewählt werden.)
-
@glitzi sagte in Daten Seriell von Paradigma Solaranlage lesen:
Wenn ich Testweise einige Zeichen vor das fc3... einfüge sollte das Skript ja trotzdem erst bei fc3 etc Anfangen.
Leider macht er das nicht?Nein, der teilt die eingehenden Daten an
fc3e2401auf. D.h. alles was vorher kommt, wird auch an die verarbeitende Methode gegeben.
Du könntest z.B. bevor du die Daten auswertest prüfen, ob die erhaltene Datenmenge dem entspricht, was zu erwarten ist, z.B.:if (chunk.length < 10) return;(ich weiß nicht wie viele Bytes Nutzdaten üblicherweise kommen, ggf. muss die Schwelle kleiner oder größer gewählt werden.)
@AlCalzone
Da kommen auch noch sehr viele andere (und unbekannte) Daten über die Schnittstelle rein, daher benötige ich x Byte nach dem fc3e2401 und nur diese sollen dann verarbeitet werden.Eventuell versteh ich das auch falsch?
aktuell nutze ich ja nur einen Test Datensatz, später kommt das ja von der Seriellen Schnittstelle -
@AlCalzone
Da kommen auch noch sehr viele andere (und unbekannte) Daten über die Schnittstelle rein, daher benötige ich x Byte nach dem fc3e2401 und nur diese sollen dann verarbeitet werden.Eventuell versteh ich das auch falsch?
aktuell nutze ich ja nur einen Test Datensatz, später kommt das ja von der Seriellen Schnittstelle@glitzi Hmm, scheint so als würde der Parser genau anders herum arbeiten als du das brauchst. Er wartet immer bis die Byte-Folge kommt und gibt alles davor aus.
Ich hab so einen ähnlichen Anwendungsfall in meinem Adapter, ich bau dir mal ne Alternative. -
@glitzi schau mal hier. Ab Zeile 56 steht wie du es nutzen kannst. Zeile 63 bitte mit deiner bestehenden Auswertung ersetzen, ich hab das nur zum Testen mal geloggt. Außerdem war noch ein kleiner Fehler drin (letzte Zeile). Die Daten müssen per
writein den Parser geschrieben werden, nicht perpush.const { Transform } = require("stream"); class PreambleParser extends Transform { /** * @param {Buffer} preamble * @param {number} payloadLength */ constructor(preamble, payloadLength) { super(); this.receiveBuffer = Buffer.allocUnsafe(0); this.preamble = preamble; this.payloadLength = payloadLength; } _transform(chunk, encoding, callback) { this.receiveBuffer = Buffer.concat([this.receiveBuffer, chunk]); while (this.receiveBuffer.length >= this.preamble.length) { // Check if the buffer starts with the preamble const preambleIndex = this.receiveBuffer.indexOf(this.preamble); if (preambleIndex === -1) { // not found, wait for the next chunk break; } // Skip bytes before the preamble this.receiveBuffer = skipBytes(this.receiveBuffer, preambleIndex); // Check if we still have enough data if ( this.receiveBuffer.length >= this.preamble.length + this.payloadLength ) { // Yes, emit it this.push( this.receiveBuffer.slice( this.preamble.length, this.preamble.length + this.payloadLength, ), ); // And skip the bytes this.receiveBuffer = skipBytes( this.receiveBuffer, this.preamble.length + this.payloadLength, ); } } callback(); } } /** Skips the first n bytes of a buffer and returns the rest */ function skipBytes(buf, n) { return Buffer.from(buf.slice(n)); } // --- const parser = new PreambleParser( Buffer.from("fc3e2401", "hex"), // Start der Datenpakete 10, // Wie viele Bytes nach dem Start ausgewertet werden ); parser.on("data", (chunk) => { console.log(chunk.toString("hex")); }); // Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "00112233fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; parser.write(hexDatenOhneLeerzeichen, "hex");Eine Testausgabe auf der Konsole zeigt die gewünschten 10 Bytes nach den Anfangs-Bytes.:
$ node preambleParser.js 09028702430149000000 0902870243014a000000 -
@glitzi schau mal hier. Ab Zeile 56 steht wie du es nutzen kannst. Zeile 63 bitte mit deiner bestehenden Auswertung ersetzen, ich hab das nur zum Testen mal geloggt. Außerdem war noch ein kleiner Fehler drin (letzte Zeile). Die Daten müssen per
writein den Parser geschrieben werden, nicht perpush.const { Transform } = require("stream"); class PreambleParser extends Transform { /** * @param {Buffer} preamble * @param {number} payloadLength */ constructor(preamble, payloadLength) { super(); this.receiveBuffer = Buffer.allocUnsafe(0); this.preamble = preamble; this.payloadLength = payloadLength; } _transform(chunk, encoding, callback) { this.receiveBuffer = Buffer.concat([this.receiveBuffer, chunk]); while (this.receiveBuffer.length >= this.preamble.length) { // Check if the buffer starts with the preamble const preambleIndex = this.receiveBuffer.indexOf(this.preamble); if (preambleIndex === -1) { // not found, wait for the next chunk break; } // Skip bytes before the preamble this.receiveBuffer = skipBytes(this.receiveBuffer, preambleIndex); // Check if we still have enough data if ( this.receiveBuffer.length >= this.preamble.length + this.payloadLength ) { // Yes, emit it this.push( this.receiveBuffer.slice( this.preamble.length, this.preamble.length + this.payloadLength, ), ); // And skip the bytes this.receiveBuffer = skipBytes( this.receiveBuffer, this.preamble.length + this.payloadLength, ); } } callback(); } } /** Skips the first n bytes of a buffer and returns the rest */ function skipBytes(buf, n) { return Buffer.from(buf.slice(n)); } // --- const parser = new PreambleParser( Buffer.from("fc3e2401", "hex"), // Start der Datenpakete 10, // Wie viele Bytes nach dem Start ausgewertet werden ); parser.on("data", (chunk) => { console.log(chunk.toString("hex")); }); // Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "00112233fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; parser.write(hexDatenOhneLeerzeichen, "hex");Eine Testausgabe auf der Konsole zeigt die gewünschten 10 Bytes nach den Anfangs-Bytes.:
$ node preambleParser.js 09028702430149000000 0902870243014a000000Ich bin Stolz auf mich ;-)
so geht es
const parser = new Ready({ delimiter: Buffer.from("fc3e2401", "hex") });und
parser.write(hexDatenOhneLeerzeichen, "hex");Nächste Woche benötige ich dann dieses Skript und muß das Empfangene dann in die obere Zeile bringen?
const SerialPort = require('serialport') const Delimiter = require('@serialport/parser-delimiter') const port = new SerialPort('/dev/tty-usbserial1') const parser = port.pipe(new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { chunk = chunk.swap16(); });Der Vollständigkeit nochmal das ganze...
const Delimiter = require('@serialport/parser-delimiter') const Ready = require('@serialport/parser-ready') createState('Paradigma_Kollektor'); createState('Paradigma_Speichertemperatur'); createState('Paradigma_Solarvorlauf'); createState('Paradigma_Aussentemperatur'); createState('Paradigma_Solarrücklauf'); createState('Paradigma_Durchfluss'); createState('Paradigma_PWMPumpe'); createState('Paradigma_Tagesleistung'); createState('Paradigma_Gesamtleistung'); createState('Paradigma_Status'); createState('Paradigma_StatusText'); createState('Paradigma_Fehlercode'); createState('Paradigma_FehlercodeText'); //const parser = new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") }); //const parser = new PreambleParser(Buffer.from("fc3e2401", "hex"), 10, ); const parser = new Ready({ delimiter: Buffer.from("fc3e2401", "hex") }); parser.on('data', chunk => { console.log(chunk.toString("hex")); val = chunk.readUInt16LE(0) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Kollektor', val /10, true); val = chunk.readUInt16LE(2) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Speichertemperatur', val /10, true); val = chunk.readUInt16LE(4) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Solarvorlauf', val /10, true); val = chunk.readInt16LE(6) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Aussentemperatur', val /10, true); val = chunk.readUInt16LE(10) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Solarrücklauf', val /10, true); val = chunk.readUInt16LE(12) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Durchfluss', val /10, true); val = chunk.readUInt8(14) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_PWMPumpe', val /10, true); val = chunk.readUInt16LE(29) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Tagesleistung', val , true); val = chunk.readUInt16LE(32) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Gesamtleistung', val /10, true); val = chunk.readUInt8(17) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Status', val, true); switch(val) { case 0: setState('Paradigma_StatusText', 'Warten auf Sonne', true); break; case 1: setState('Paradigma_StatusText', 'Frostschutz', true); break; case 2: setState('Paradigma_StatusText', 'Anschieben', true); break; case 3: setState('Paradigma_StatusText', 'Einschaltverzögerung', true); break; case 4: setState('Paradigma_StatusText', 'erwärmt Speicher', true); break; case 5: setState('Paradigma_StatusText', 'Speicher voll', true); break; case 6: setState('Paradigma_StatusText', 'Kollektor überhitzt', true); break; case 7: setState('Paradigma_StatusText', 'Hand, Test oder Aus', true); break; case 8: setState('Paradigma_StatusText', 'Messung', true); break; default: setState('Paradigma_StatusText', val, true); } val = chunk.readUInt8(18) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Fehlercode', val /10, true); switch(val) { case 0: setState('Paradigma_FehlercodeText', 'OK', true); break; case 1: setState('Paradigma_FehlercodeText', 'Kein Volumenstrom', true); break; case 2: setState('Paradigma_FehlercodeText', 'Luft in der Anlage', true); break; case 4: setState('Paradigma_FehlercodeText', 'Vor- u. Rücklauf vertauscht', true); break; case 5: setState('Paradigma_FehlercodeText', 'Zonenventil defekt', true); break; case 6: setState('Paradigma_FehlercodeText', 'Falsche Uhrzeit', true); break; case 7: setState('Paradigma_FehlercodeText', 'Druckabfall in der Anlage', true); break; case 9: setState('Paradigma_FehlercodeText', 'Falsche Hydraulik', true); break; case 10: setState('Paradigma_FehlercodeText', 'Rohrisolierung', true); break; case 11: setState('Paradigma_FehlercodeText', 'Stromversorgung n. konstant', true); break; case 12: setState('Paradigma_FehlercodeText', 'OLV defekt', true); break; case 13: setState('Paradigma_FehlercodeText', 'Zu wenig Volumenstrom', true); break; case 14: setState('Paradigma_FehlercodeText', 'Speicher unterkühlt durch Frostschutz', true); break; case 20: setState('Paradigma_FehlercodeText', 'Fühler Außentemperatur falsch montiert', true); break; case 21: setState('Paradigma_FehlercodeText', 'Ausfall Kollektorfühler', true); break; case 22: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Solarrücklauf', true); break; case 23: setState('Paradigma_FehlercodeText', 'Störung Kollektrofühler', true); break; case 24: setState('Paradigma_FehlercodeText', 'Frostschutz', true); break; case 25: setState('Paradigma_FehlercodeText', 'Fühler TSA u. TAM vertauscht', true); break; case 26: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Solarvorlauf', true); break; case 27: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Außentemperatur', true); break; case 34: setState('Paradigma_FehlercodeText', 'Überhitzung Speicher 1', true); break; case 35: setState('Paradigma_FehlercodeText', 'Überhitzung Speicher 2', true); break; case 49: setState('Paradigma_FehlercodeText', 'Solarstation unterkühlt', true); break; case 50: setState('Paradigma_FehlercodeText', 'Kollektor eingefroren', true); break; default: setState('Paradigma_FehlercodeText', val, true); } }); // Bei jedem Dateneingang: //const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; const hexDatenOhneLeerzeichen = "fc3e240163007002d300f8ff000072010000000000010001100015141b0b1439000000000039440000000000000000000000630000000000000000000000000001fc3e240163007002d300f9ff0000"; //parser.push(hexDatenOhneLeerzeichen, "hex"); parser.write(hexDatenOhneLeerzeichen, "hex"); -
Ich bin Stolz auf mich ;-)
so geht es
const parser = new Ready({ delimiter: Buffer.from("fc3e2401", "hex") });und
parser.write(hexDatenOhneLeerzeichen, "hex");Nächste Woche benötige ich dann dieses Skript und muß das Empfangene dann in die obere Zeile bringen?
const SerialPort = require('serialport') const Delimiter = require('@serialport/parser-delimiter') const port = new SerialPort('/dev/tty-usbserial1') const parser = port.pipe(new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { chunk = chunk.swap16(); });Der Vollständigkeit nochmal das ganze...
const Delimiter = require('@serialport/parser-delimiter') const Ready = require('@serialport/parser-ready') createState('Paradigma_Kollektor'); createState('Paradigma_Speichertemperatur'); createState('Paradigma_Solarvorlauf'); createState('Paradigma_Aussentemperatur'); createState('Paradigma_Solarrücklauf'); createState('Paradigma_Durchfluss'); createState('Paradigma_PWMPumpe'); createState('Paradigma_Tagesleistung'); createState('Paradigma_Gesamtleistung'); createState('Paradigma_Status'); createState('Paradigma_StatusText'); createState('Paradigma_Fehlercode'); createState('Paradigma_FehlercodeText'); //const parser = new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") }); //const parser = new PreambleParser(Buffer.from("fc3e2401", "hex"), 10, ); const parser = new Ready({ delimiter: Buffer.from("fc3e2401", "hex") }); parser.on('data', chunk => { console.log(chunk.toString("hex")); val = chunk.readUInt16LE(0) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Kollektor', val /10, true); val = chunk.readUInt16LE(2) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Speichertemperatur', val /10, true); val = chunk.readUInt16LE(4) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Solarvorlauf', val /10, true); val = chunk.readInt16LE(6) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Aussentemperatur', val /10, true); val = chunk.readUInt16LE(10) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Solarrücklauf', val /10, true); val = chunk.readUInt16LE(12) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Durchfluss', val /10, true); val = chunk.readUInt8(14) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_PWMPumpe', val /10, true); val = chunk.readUInt16LE(29) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Tagesleistung', val , true); val = chunk.readUInt16LE(32) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Gesamtleistung', val /10, true); val = chunk.readUInt8(17) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Status', val, true); switch(val) { case 0: setState('Paradigma_StatusText', 'Warten auf Sonne', true); break; case 1: setState('Paradigma_StatusText', 'Frostschutz', true); break; case 2: setState('Paradigma_StatusText', 'Anschieben', true); break; case 3: setState('Paradigma_StatusText', 'Einschaltverzögerung', true); break; case 4: setState('Paradigma_StatusText', 'erwärmt Speicher', true); break; case 5: setState('Paradigma_StatusText', 'Speicher voll', true); break; case 6: setState('Paradigma_StatusText', 'Kollektor überhitzt', true); break; case 7: setState('Paradigma_StatusText', 'Hand, Test oder Aus', true); break; case 8: setState('Paradigma_StatusText', 'Messung', true); break; default: setState('Paradigma_StatusText', val, true); } val = chunk.readUInt8(18) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Fehlercode', val /10, true); switch(val) { case 0: setState('Paradigma_FehlercodeText', 'OK', true); break; case 1: setState('Paradigma_FehlercodeText', 'Kein Volumenstrom', true); break; case 2: setState('Paradigma_FehlercodeText', 'Luft in der Anlage', true); break; case 4: setState('Paradigma_FehlercodeText', 'Vor- u. Rücklauf vertauscht', true); break; case 5: setState('Paradigma_FehlercodeText', 'Zonenventil defekt', true); break; case 6: setState('Paradigma_FehlercodeText', 'Falsche Uhrzeit', true); break; case 7: setState('Paradigma_FehlercodeText', 'Druckabfall in der Anlage', true); break; case 9: setState('Paradigma_FehlercodeText', 'Falsche Hydraulik', true); break; case 10: setState('Paradigma_FehlercodeText', 'Rohrisolierung', true); break; case 11: setState('Paradigma_FehlercodeText', 'Stromversorgung n. konstant', true); break; case 12: setState('Paradigma_FehlercodeText', 'OLV defekt', true); break; case 13: setState('Paradigma_FehlercodeText', 'Zu wenig Volumenstrom', true); break; case 14: setState('Paradigma_FehlercodeText', 'Speicher unterkühlt durch Frostschutz', true); break; case 20: setState('Paradigma_FehlercodeText', 'Fühler Außentemperatur falsch montiert', true); break; case 21: setState('Paradigma_FehlercodeText', 'Ausfall Kollektorfühler', true); break; case 22: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Solarrücklauf', true); break; case 23: setState('Paradigma_FehlercodeText', 'Störung Kollektrofühler', true); break; case 24: setState('Paradigma_FehlercodeText', 'Frostschutz', true); break; case 25: setState('Paradigma_FehlercodeText', 'Fühler TSA u. TAM vertauscht', true); break; case 26: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Solarvorlauf', true); break; case 27: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Außentemperatur', true); break; case 34: setState('Paradigma_FehlercodeText', 'Überhitzung Speicher 1', true); break; case 35: setState('Paradigma_FehlercodeText', 'Überhitzung Speicher 2', true); break; case 49: setState('Paradigma_FehlercodeText', 'Solarstation unterkühlt', true); break; case 50: setState('Paradigma_FehlercodeText', 'Kollektor eingefroren', true); break; default: setState('Paradigma_FehlercodeText', val, true); } }); // Bei jedem Dateneingang: //const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; const hexDatenOhneLeerzeichen = "fc3e240163007002d300f8ff000072010000000000010001100015141b0b1439000000000039440000000000000000000000630000000000000000000000000001fc3e240163007002d300f9ff0000"; //parser.push(hexDatenOhneLeerzeichen, "hex"); parser.write(hexDatenOhneLeerzeichen, "hex");@glitzi Ich fürchte mit dem Ready-Parser wird es auch nicht hinhauen. Wenn du da mal das Beispiel liest:
all data after READY is received
d.h. du bekommst nur einmal sämtliche Daten, die nach dem allerersten
fc3e2401kommen. Allerdings enthält schon dein Beispielcode zwei "Datenpakete". Mit meinemPreambleParserbekommst du die angegebene Anzahl an Bytes nach jedemfc3e2401- nach deinem Code zu urteilen brauchst du 34 Bytes. -
@glitzi Ich fürchte mit dem Ready-Parser wird es auch nicht hinhauen. Wenn du da mal das Beispiel liest:
all data after READY is received
d.h. du bekommst nur einmal sämtliche Daten, die nach dem allerersten
fc3e2401kommen. Allerdings enthält schon dein Beispielcode zwei "Datenpakete". Mit meinemPreambleParserbekommst du die angegebene Anzahl an Bytes nach jedemfc3e2401- nach deinem Code zu urteilen brauchst du 34 Bytes.Kann das nicht funktionieren wenn ich alle x Sekunden die Daten von der Schnittstelle in einen Datenpunkt schreibe und den Parser damit neu triggere?
Dann sollte ja auch das überlange Telegramm nicht stören.
Dazu wäre noch interessant wie ich das vorher von der Schnittstelle in einen Datenpunkt bekomme?
-
Kann das nicht funktionieren wenn ich alle x Sekunden die Daten von der Schnittstelle in einen Datenpunkt schreibe und den Parser damit neu triggere?
Dann sollte ja auch das überlange Telegramm nicht stören.
Dazu wäre noch interessant wie ich das vorher von der Schnittstelle in einen Datenpunkt bekomme?
@glitzi sagte in Daten Seriell von Paradigma Solaranlage lesen:
Kann das nicht funktionieren wenn ich alle x Sekunden die Daten von der Schnittstelle in einen Datenpunkt schreibe und den Parser damit neu triggere?
Wenn es dich nicht stört, dass du dann einen Teil der Daten ignorierst.
Ich bin mir nicht sicher, wie die Daten vom Serialport kommen. Musst du ein Paket schicken, damit Daten zurück kommen? Oder sendet die Solaranlage permanent/regelmäßig?
Falls letzteres wäre es IMO besser, beim Skriptstart die Schnittstelle zu öffnen, einmal einen geeigneten Parser aufsetzen und dann nur noch aufs data-Event zu lauschen. Dann brauchst du auch keinen Umweg über Datenpunkte, wenn dich nachher eh nur die Nutzdaten interessieren.
-
Ich bin Stolz auf mich ;-)
so geht es
const parser = new Ready({ delimiter: Buffer.from("fc3e2401", "hex") });und
parser.write(hexDatenOhneLeerzeichen, "hex");Nächste Woche benötige ich dann dieses Skript und muß das Empfangene dann in die obere Zeile bringen?
const SerialPort = require('serialport') const Delimiter = require('@serialport/parser-delimiter') const port = new SerialPort('/dev/tty-usbserial1') const parser = port.pipe(new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { chunk = chunk.swap16(); });Der Vollständigkeit nochmal das ganze...
const Delimiter = require('@serialport/parser-delimiter') const Ready = require('@serialport/parser-ready') createState('Paradigma_Kollektor'); createState('Paradigma_Speichertemperatur'); createState('Paradigma_Solarvorlauf'); createState('Paradigma_Aussentemperatur'); createState('Paradigma_Solarrücklauf'); createState('Paradigma_Durchfluss'); createState('Paradigma_PWMPumpe'); createState('Paradigma_Tagesleistung'); createState('Paradigma_Gesamtleistung'); createState('Paradigma_Status'); createState('Paradigma_StatusText'); createState('Paradigma_Fehlercode'); createState('Paradigma_FehlercodeText'); //const parser = new Delimiter({ delimiter: Buffer.from("fc3e2401", "hex") }); //const parser = new PreambleParser(Buffer.from("fc3e2401", "hex"), 10, ); const parser = new Ready({ delimiter: Buffer.from("fc3e2401", "hex") }); parser.on('data', chunk => { console.log(chunk.toString("hex")); val = chunk.readUInt16LE(0) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Kollektor', val /10, true); val = chunk.readUInt16LE(2) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Speichertemperatur', val /10, true); val = chunk.readUInt16LE(4) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Solarvorlauf', val /10, true); val = chunk.readInt16LE(6) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Aussentemperatur', val /10, true); val = chunk.readUInt16LE(10) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Solarrücklauf', val /10, true); val = chunk.readUInt16LE(12) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Durchfluss', val /10, true); val = chunk.readUInt8(14) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_PWMPumpe', val /10, true); val = chunk.readUInt16LE(29) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Tagesleistung', val , true); val = chunk.readUInt16LE(32) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Gesamtleistung', val /10, true); val = chunk.readUInt8(17) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Status', val, true); switch(val) { case 0: setState('Paradigma_StatusText', 'Warten auf Sonne', true); break; case 1: setState('Paradigma_StatusText', 'Frostschutz', true); break; case 2: setState('Paradigma_StatusText', 'Anschieben', true); break; case 3: setState('Paradigma_StatusText', 'Einschaltverzögerung', true); break; case 4: setState('Paradigma_StatusText', 'erwärmt Speicher', true); break; case 5: setState('Paradigma_StatusText', 'Speicher voll', true); break; case 6: setState('Paradigma_StatusText', 'Kollektor überhitzt', true); break; case 7: setState('Paradigma_StatusText', 'Hand, Test oder Aus', true); break; case 8: setState('Paradigma_StatusText', 'Messung', true); break; default: setState('Paradigma_StatusText', val, true); } val = chunk.readUInt8(18) // liest eine 2-byte-Zahl ab Position 0 ohne Bytes zu tauschen setState('Paradigma_Fehlercode', val /10, true); switch(val) { case 0: setState('Paradigma_FehlercodeText', 'OK', true); break; case 1: setState('Paradigma_FehlercodeText', 'Kein Volumenstrom', true); break; case 2: setState('Paradigma_FehlercodeText', 'Luft in der Anlage', true); break; case 4: setState('Paradigma_FehlercodeText', 'Vor- u. Rücklauf vertauscht', true); break; case 5: setState('Paradigma_FehlercodeText', 'Zonenventil defekt', true); break; case 6: setState('Paradigma_FehlercodeText', 'Falsche Uhrzeit', true); break; case 7: setState('Paradigma_FehlercodeText', 'Druckabfall in der Anlage', true); break; case 9: setState('Paradigma_FehlercodeText', 'Falsche Hydraulik', true); break; case 10: setState('Paradigma_FehlercodeText', 'Rohrisolierung', true); break; case 11: setState('Paradigma_FehlercodeText', 'Stromversorgung n. konstant', true); break; case 12: setState('Paradigma_FehlercodeText', 'OLV defekt', true); break; case 13: setState('Paradigma_FehlercodeText', 'Zu wenig Volumenstrom', true); break; case 14: setState('Paradigma_FehlercodeText', 'Speicher unterkühlt durch Frostschutz', true); break; case 20: setState('Paradigma_FehlercodeText', 'Fühler Außentemperatur falsch montiert', true); break; case 21: setState('Paradigma_FehlercodeText', 'Ausfall Kollektorfühler', true); break; case 22: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Solarrücklauf', true); break; case 23: setState('Paradigma_FehlercodeText', 'Störung Kollektrofühler', true); break; case 24: setState('Paradigma_FehlercodeText', 'Frostschutz', true); break; case 25: setState('Paradigma_FehlercodeText', 'Fühler TSA u. TAM vertauscht', true); break; case 26: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Solarvorlauf', true); break; case 27: setState('Paradigma_FehlercodeText', 'Ausfall Fühler Außentemperatur', true); break; case 34: setState('Paradigma_FehlercodeText', 'Überhitzung Speicher 1', true); break; case 35: setState('Paradigma_FehlercodeText', 'Überhitzung Speicher 2', true); break; case 49: setState('Paradigma_FehlercodeText', 'Solarstation unterkühlt', true); break; case 50: setState('Paradigma_FehlercodeText', 'Kollektor eingefroren', true); break; default: setState('Paradigma_FehlercodeText', val, true); } }); // Bei jedem Dateneingang: //const hexDatenOhneLeerzeichen = "fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; const hexDatenOhneLeerzeichen = "fc3e240163007002d300f8ff000072010000000000010001100015141b0b1439000000000039440000000000000000000000630000000000000000000000000001fc3e240163007002d300f9ff0000"; //parser.push(hexDatenOhneLeerzeichen, "hex"); parser.write(hexDatenOhneLeerzeichen, "hex");Also dann so?
const SerialPort = require('serialport') const Delimiter = require('@serialport/parser-delimiter') const port = new SerialPort('/dev/tty-usbserial1') const parser = port.pipe(new Ready({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { chunk = chunk.swap16(); });und das weglassen?
const hexDatenOhneLeerzeichen = "fc3e240163007002d300f8ff000072010000000000010001100015141b0b1439000000000039440000000000000000000000630000000000000000000000000001fc3e240163007002d300f9ff0000"; parser.write(hexDatenOhneLeerzeichen, "hex"); -
Also dann so?
const SerialPort = require('serialport') const Delimiter = require('@serialport/parser-delimiter') const port = new SerialPort('/dev/tty-usbserial1') const parser = port.pipe(new Ready({ delimiter: Buffer.from("fc3e2401", "hex") })) parser.on('data', chunk => { chunk = chunk.swap16(); });und das weglassen?
const hexDatenOhneLeerzeichen = "fc3e240163007002d300f8ff000072010000000000010001100015141b0b1439000000000039440000000000000000000000630000000000000000000000000001fc3e240163007002d300f9ff0000"; parser.write(hexDatenOhneLeerzeichen, "hex");@glitzi Wie oben schon geschrieben... mit dem Ready-Parser bekommst du nur ein einziges Mal ein Datenpaket.
@AlCalzone sagte in Daten Seriell von Paradigma Solaranlage lesen:
Mit meinem PreambleParser bekommst du die angegebene Anzahl an Bytes nach jedem fc3e2401 - nach deinem Code zu urteilen brauchst du 34 Bytes.
-
@glitzi Wie oben schon geschrieben... mit dem Ready-Parser bekommst du nur ein einziges Mal ein Datenpaket.
@AlCalzone sagte in Daten Seriell von Paradigma Solaranlage lesen:
Mit meinem PreambleParser bekommst du die angegebene Anzahl an Bytes nach jedem fc3e2401 - nach deinem Code zu urteilen brauchst du 34 Bytes.
-
Auch wenn ich das jede 30s Triggere?
-
@glitzi schau mal hier. Ab Zeile 56 steht wie du es nutzen kannst. Zeile 63 bitte mit deiner bestehenden Auswertung ersetzen, ich hab das nur zum Testen mal geloggt. Außerdem war noch ein kleiner Fehler drin (letzte Zeile). Die Daten müssen per
writein den Parser geschrieben werden, nicht perpush.const { Transform } = require("stream"); class PreambleParser extends Transform { /** * @param {Buffer} preamble * @param {number} payloadLength */ constructor(preamble, payloadLength) { super(); this.receiveBuffer = Buffer.allocUnsafe(0); this.preamble = preamble; this.payloadLength = payloadLength; } _transform(chunk, encoding, callback) { this.receiveBuffer = Buffer.concat([this.receiveBuffer, chunk]); while (this.receiveBuffer.length >= this.preamble.length) { // Check if the buffer starts with the preamble const preambleIndex = this.receiveBuffer.indexOf(this.preamble); if (preambleIndex === -1) { // not found, wait for the next chunk break; } // Skip bytes before the preamble this.receiveBuffer = skipBytes(this.receiveBuffer, preambleIndex); // Check if we still have enough data if ( this.receiveBuffer.length >= this.preamble.length + this.payloadLength ) { // Yes, emit it this.push( this.receiveBuffer.slice( this.preamble.length, this.preamble.length + this.payloadLength, ), ); // And skip the bytes this.receiveBuffer = skipBytes( this.receiveBuffer, this.preamble.length + this.payloadLength, ); } } callback(); } } /** Skips the first n bytes of a buffer and returns the rest */ function skipBytes(buf, n) { return Buffer.from(buf.slice(n)); } // --- const parser = new PreambleParser( Buffer.from("fc3e2401", "hex"), // Start der Datenpakete 10, // Wie viele Bytes nach dem Start ausgewertet werden ); parser.on("data", (chunk) => { console.log(chunk.toString("hex")); }); // Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "00112233fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; parser.write(hexDatenOhneLeerzeichen, "hex");Eine Testausgabe auf der Konsole zeigt die gewünschten 10 Bytes nach den Anfangs-Bytes.:
$ node preambleParser.js 09028702430149000000 0902870243014a000000@AlCalzone sagte in Daten Seriell von Paradigma Solaranlage lesen:
Habe nichts gegen Deinen Vorschlag ;-)
muss ich den Teil vor der Zeile 68 auch übernehmen? und wo kommt der Part mit der Schnittstelle hin und wie wir das dann alle 30s getriggert?
@glitzi schau mal hier. Ab Zeile 56 steht wie du es nutzen kannst. Zeile 63 bitte mit deiner bestehenden Auswertung ersetzen, ich hab das nur zum Testen mal geloggt. Außerdem war noch ein kleiner Fehler drin (letzte Zeile). Die Daten müssen per
writein den Parser geschrieben werden, nicht perpush.const { Transform } = require("stream"); class PreambleParser extends Transform { /** * @param {Buffer} preamble * @param {number} payloadLength */ constructor(preamble, payloadLength) { super(); this.receiveBuffer = Buffer.allocUnsafe(0); this.preamble = preamble; this.payloadLength = payloadLength; } _transform(chunk, encoding, callback) { this.receiveBuffer = Buffer.concat([this.receiveBuffer, chunk]); while (this.receiveBuffer.length >= this.preamble.length) { // Check if the buffer starts with the preamble const preambleIndex = this.receiveBuffer.indexOf(this.preamble); if (preambleIndex === -1) { // not found, wait for the next chunk break; } // Skip bytes before the preamble this.receiveBuffer = skipBytes(this.receiveBuffer, preambleIndex); // Check if we still have enough data if ( this.receiveBuffer.length >= this.preamble.length + this.payloadLength ) { // Yes, emit it this.push( this.receiveBuffer.slice( this.preamble.length, this.preamble.length + this.payloadLength, ), ); // And skip the bytes this.receiveBuffer = skipBytes( this.receiveBuffer, this.preamble.length + this.payloadLength, ); } } callback(); } } /** Skips the first n bytes of a buffer and returns the rest */ function skipBytes(buf, n) { return Buffer.from(buf.slice(n)); } // --- const parser = new PreambleParser( Buffer.from("fc3e2401", "hex"), // Start der Datenpakete 10, // Wie viele Bytes nach dem Start ausgewertet werden ); parser.on("data", (chunk) => { console.log(chunk.toString("hex")); }); // Bei jedem Dateneingang: const hexDatenOhneLeerzeichen = "00112233fc3e24010902870243014900000056010000000000000000000010100c0b1405000000000005440000000000000000000000090200000000000000000000000085fc3e24010902870243014a00000057010000"; parser.write(hexDatenOhneLeerzeichen, "hex");Eine Testausgabe auf der Konsole zeigt die gewünschten 10 Bytes nach den Anfangs-Bytes.:
$ node preambleParser.js 09028702430149000000 0902870243014a000000Und Hier gibt es noch Probleme:
19| const { Transform } = require('stream');18:37:15.725 error javascript.0 (1126) script.js.Paradigma.TEST: Error: Cannot find module 'emitter' 18:37:15.727 error javascript.0 (1126) at script.js.Paradigma.TEST:19:23 18:37:15.730 error javascript.0 (1126) script.js.Paradigma.TEST: script.js.Paradigma.TEST:19 18:37:15.731 error javascript.0 (1126) at script.js.Paradigma.TEST:19:9
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
425
Online33.0k
Benutzer83.4k
Themen1.3m
Beiträge