

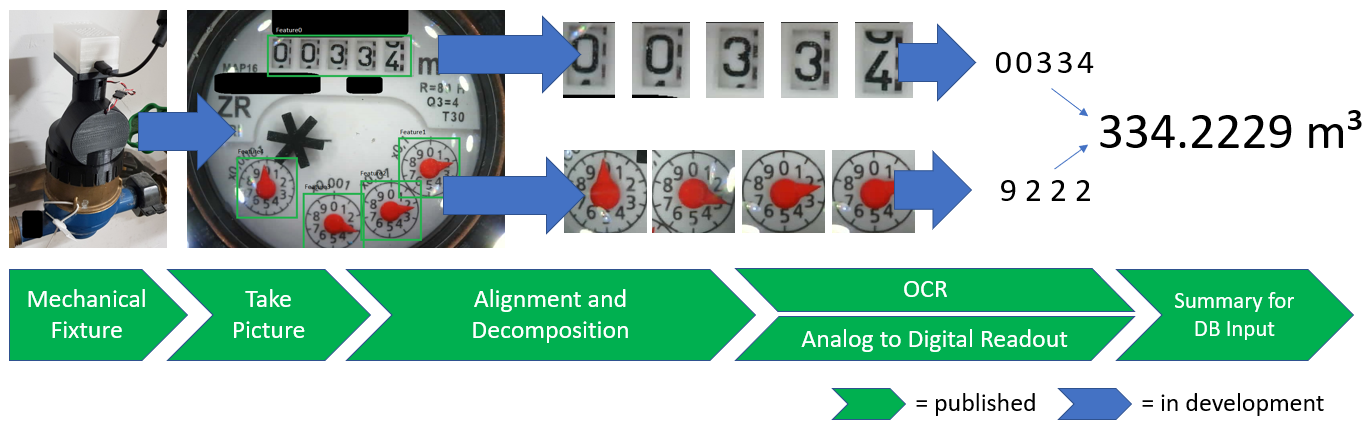
Wasserzähler - Selfmade
-
Hi, wie meinst du denn mit hochrechnen des M3 Wertes?
Wie rechnest du denn hoch?
Man könnte natürlich entweder nur die digitalen Ziffern auswerten, dann fehlen einem aber genauere Zwischenwerte.
Oder man zählt den den kleinsten analogen Zähler hoch, da müsste man dann aber sehr viele Bilder machen und sehr genau hochrechnen, bzw. braucht ein hohes Abtastintervall, damit das funktioniert.
Wie hast du es denn gelöst? -
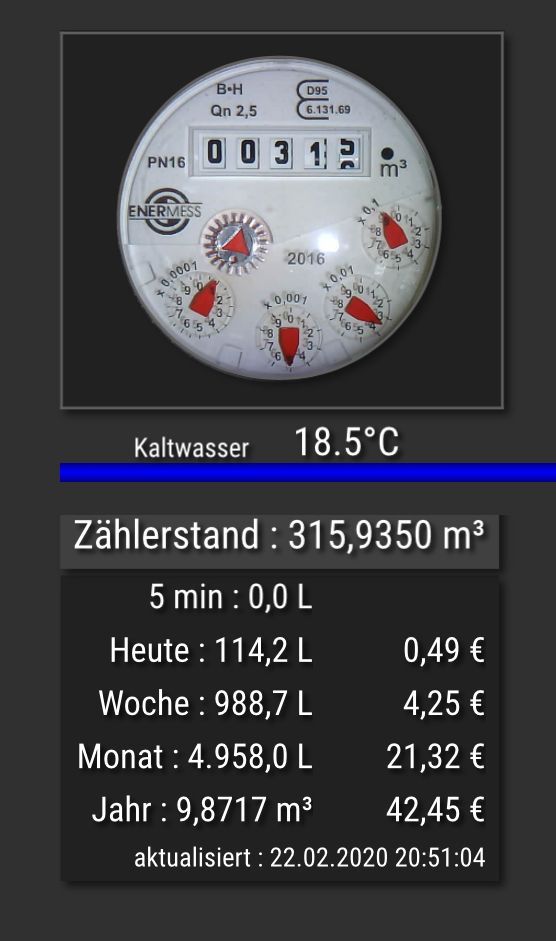
Weil bei mir gerade wieder die m3 Zahl sich zwischen 2 Werten bewegt, habe ich nachgeschaut, was erkannt wird.

192.168.178.86:1905/wasserzaehler.html?usePrevalue gibt aus

Richtig wäre 315,9350
Nur zur Info
Auswertung unter Docker mit aktuellem rolling auf Synology.
PS.: mit meiner Berechnung (Blockly hier im Thread) mit hochrechnen des m3 Wertes funktioniert das seit 2 Monaten ohne Fehler
Hallo @Knallochse,
das Problem kenne ich und es liegt daran, dass bevor "NAN" kam, er die verschobene 5 als 9 erkannt hat und dann diesen Wert in "PreValue" gespeichert hat. Das tritt eigentlich nur beim Überang von 5 auf 6 auf und ich habe vor kurzem mein CNN nochmals besser trainiert. Aber es läuft noch nicht lange genug, um sicher zu sein, dass es hilft. -
Hi, wie meinst du denn mit hochrechnen des M3 Wertes?
Wie rechnest du denn hoch?
Man könnte natürlich entweder nur die digitalen Ziffern auswerten, dann fehlen einem aber genauere Zwischenwerte.
Oder man zählt den den kleinsten analogen Zähler hoch, da müsste man dann aber sehr viele Bilder machen und sehr genau hochrechnen, bzw. braucht ein hohes Abtastintervall, damit das funktioniert.
Wie hast du es denn gelöst?@Atifan Meine Lösung (Blockly) hatte ich hier beschrieben
https://forum.iobroker.net/post/340650Und @sissiwup hatte hier
https://forum.iobroker.net/post/360651
auch ein JavaScript veröffentlicht .
Dieses Script hatte ich bisher nicht getestet. -
@Atifan Meine Lösung (Blockly) hatte ich hier beschrieben
https://forum.iobroker.net/post/340650Und @sissiwup hatte hier
https://forum.iobroker.net/post/360651
auch ein JavaScript veröffentlicht .
Dieses Script hatte ich bisher nicht getestet.@Knallochse sagte in Wasserzähler - Selfmade:
@Atifan Meine Lösung (Blockly) hatte ich hier beschrieben
https://forum.iobroker.net/post/340650Und @sissiwup hatte hier
https://forum.iobroker.net/post/360651
auch ein JavaScript veröffentlicht .
Dieses Script hatte ich bisher nicht getestet.Wenn ich darüber nachdenke, dürfte das eigentlich nicht passieren, denn einen solchen Sprung sollte der Parameter
MaxRateValue(typsicherweise 0.1) verhindern. Ich schaue bei Gelegenheit nochmal in den Quellcode. -
Hallo @Knallochse,
das Problem kenne ich und es liegt daran, dass bevor "NAN" kam, er die verschobene 5 als 9 erkannt hat und dann diesen Wert in "PreValue" gespeichert hat. Das tritt eigentlich nur beim Überang von 5 auf 6 auf und ich habe vor kurzem mein CNN nochmals besser trainiert. Aber es läuft noch nicht lange genug, um sicher zu sein, dass es hilft.@jomjol Guten Morgen.
Ich habe gerade nochmal in meine config.ini geschaut.
Ich hatte den ConsistencyCheck auf FALSE.
Ich hatte damals das Problem, dass (selbst bei nur Wasserzaehler.html / ohne ?usePrevalue) manchmal der alte Zählerwert bei der Ausgabe an erster Stelle stand. (also auch da - ohne "?usePrevalue" die Prüfung stattfand).
Mittlerweile ist aber mein Zählerstand auf 6 gewandert (wird auch als 6 erkannt), so dass ich leider gerade nicht prüfen kann, was mit ConsistencyCheck = TRUE erkannt wird.
Also muss der Fehler nicht in deinem Code liegen.Meine Beobachtungen der Ausgabewerte hatte ergeben, dass ich mich nur auf die Erkennung der Analogzeiger verlassen kann. Deshalb mein Blockly, welches den String nach Digital (5 Stellen) und Analog (4 Stellen) zerlegt. Dann wird bei Aktualisierung des Zählerwertes (Parser - 5min) der neue Analogwert von vorhergehenden subtrahiert und wenn das Ergebnis größer 0,5 (500 Liter) ist, wird Digital/M³ um 1 erhöht.
@sissiwup hat ja was ähnliches in sein Javascript eingebaut. Könnte man sich ja auch genauer anschauen.Wenn man die ausgegebenen Werte protokolliert und auswertet, muss man sich auf deren Richtigkeit verlassen können.
Schon ein falscher Wert (falsche m³ Zahl / 1000 Liter) verfälscht die Auswertung gewaltig.Ich werde heute mal einen 2. Docker einrichten, damit ich die Daten vergleichen kann.
Ich bin nach wie vor von deinem Projekt begeistert, und danke Dir vielmals, dass du es mit uns teilst.

-
@jomjol Guten Morgen.
Ich habe gerade nochmal in meine config.ini geschaut.
Ich hatte den ConsistencyCheck auf FALSE.
Ich hatte damals das Problem, dass (selbst bei nur Wasserzaehler.html / ohne ?usePrevalue) manchmal der alte Zählerwert bei der Ausgabe an erster Stelle stand. (also auch da - ohne "?usePrevalue" die Prüfung stattfand).
Mittlerweile ist aber mein Zählerstand auf 6 gewandert (wird auch als 6 erkannt), so dass ich leider gerade nicht prüfen kann, was mit ConsistencyCheck = TRUE erkannt wird.
Also muss der Fehler nicht in deinem Code liegen.Meine Beobachtungen der Ausgabewerte hatte ergeben, dass ich mich nur auf die Erkennung der Analogzeiger verlassen kann. Deshalb mein Blockly, welches den String nach Digital (5 Stellen) und Analog (4 Stellen) zerlegt. Dann wird bei Aktualisierung des Zählerwertes (Parser - 5min) der neue Analogwert von vorhergehenden subtrahiert und wenn das Ergebnis größer 0,5 (500 Liter) ist, wird Digital/M³ um 1 erhöht.
@sissiwup hat ja was ähnliches in sein Javascript eingebaut. Könnte man sich ja auch genauer anschauen.Wenn man die ausgegebenen Werte protokolliert und auswertet, muss man sich auf deren Richtigkeit verlassen können.
Schon ein falscher Wert (falsche m³ Zahl / 1000 Liter) verfälscht die Auswertung gewaltig.Ich werde heute mal einen 2. Docker einrichten, damit ich die Daten vergleichen kann.
Ich bin nach wie vor von deinem Projekt begeistert, und danke Dir vielmals, dass du es mit uns teilst.
@Knallochse Guten Morgen,
danke für den Input - Code ist okay, aber ich hatte folgendes Phänomen: falsche erkannte letzte Ziffer (3 --> 9), das wurde mit RateTooHigh auch korrekt gemeldet. Die richtige Ziffer kam erst 150 Liter weiter (wieder zurück zur 3). Aber dann wurde sie auch nicht mehr gemeldet, da jetzt wieder RateTooHigh aufgrund der 150 Liter! Offensichtlich dauert es bei meiner Wasseruhr ca. 150 Liter bis die letzte Ziffer wieder korrekt im Bild ist.
Ich habe jetzt erstmal den MaxRateValue auf 0.2 gesetzt (auch in den Default Settings - v5.5.2)
Habe auch schonmal überlegt, ob ich deinen Algo zur Berechnung der Ziffern implementieren soll. Dann wird es halt für Aussenstehende echt schwierig, das zu verstehen und einzustellen. Andererseits wenn nur richtige Werte komme ist es auch egal, was im Inneren läuft.@all: Was ist eure Meinung?
P.S.: versuche gerade Tensorflow 2.1 für die Synology zu kompilieren. Hatte auch schon geklappt aber nur mit Python 3.6, brauche aber Python 3.7. Mal sehen, vielleicht klappt es ja irgendwann demnächst (Run dauert immer etwas, da 10h+ kompiliert wird - gutes Argument für einen neuen Rechner - versuche es gerade meiner Frau schmackhaft zu machen
 )
)Gruß,
jomjol -
@Knallochse Guten Morgen,
danke für den Input - Code ist okay, aber ich hatte folgendes Phänomen: falsche erkannte letzte Ziffer (3 --> 9), das wurde mit RateTooHigh auch korrekt gemeldet. Die richtige Ziffer kam erst 150 Liter weiter (wieder zurück zur 3). Aber dann wurde sie auch nicht mehr gemeldet, da jetzt wieder RateTooHigh aufgrund der 150 Liter! Offensichtlich dauert es bei meiner Wasseruhr ca. 150 Liter bis die letzte Ziffer wieder korrekt im Bild ist.
Ich habe jetzt erstmal den MaxRateValue auf 0.2 gesetzt (auch in den Default Settings - v5.5.2)
Habe auch schonmal überlegt, ob ich deinen Algo zur Berechnung der Ziffern implementieren soll. Dann wird es halt für Aussenstehende echt schwierig, das zu verstehen und einzustellen. Andererseits wenn nur richtige Werte komme ist es auch egal, was im Inneren läuft.@all: Was ist eure Meinung?
P.S.: versuche gerade Tensorflow 2.1 für die Synology zu kompilieren. Hatte auch schon geklappt aber nur mit Python 3.6, brauche aber Python 3.7. Mal sehen, vielleicht klappt es ja irgendwann demnächst (Run dauert immer etwas, da 10h+ kompiliert wird - gutes Argument für einen neuen Rechner - versuche es gerade meiner Frau schmackhaft zu machen
)Gruß,
jomjol@jomjol Ich habe auch nochmal intensiv überlegt.
Sollte bei meiner Methode die ESP-Cam mal über einen längeren Zeitraum nicht erreichbar sein (ist noch nicht vorgekommen) , dann würde aber meine Auswertung auch durcheinander kommen, da die Erkennung Digitalzahlen nicht mehr berücksichtigt werden.Ich habe auch schon einen 2. Docker am laufen, mit dem ConsistencyCheck und MaxRateValue auf 0.2. Ich zeichne die Daten der zwei Container mit dem SQL-Adapter auf und werde vergleichen.
Vielleicht schaust du dir auch nochmal das Script von @sissiwup an, was der mit den Daten anstellt. (Ich versteh den Javascript-Code leider nicht - habe keine Programmierkenntnisse)
https://forum.iobroker.net/post/360651Vielleicht meldet sich @sissiwup selbst nochmal zu dem Thema.
-
@jomjol Ich habe auch nochmal intensiv überlegt.
Sollte bei meiner Methode die ESP-Cam mal über einen längeren Zeitraum nicht erreichbar sein (ist noch nicht vorgekommen) , dann würde aber meine Auswertung auch durcheinander kommen, da die Erkennung Digitalzahlen nicht mehr berücksichtigt werden.Ich habe auch schon einen 2. Docker am laufen, mit dem ConsistencyCheck und MaxRateValue auf 0.2. Ich zeichne die Daten der zwei Container mit dem SQL-Adapter auf und werde vergleichen.
Vielleicht schaust du dir auch nochmal das Script von @sissiwup an, was der mit den Daten anstellt. (Ich versteh den Javascript-Code leider nicht - habe keine Programmierkenntnisse)
https://forum.iobroker.net/post/360651Vielleicht meldet sich @sissiwup selbst nochmal zu dem Thema.
@Knallochse er macht es ähnlich. Wenn die letzte Ziffer nicht stimmt, wird sie errechnet.
Ist ein Grundsatzproblem: du kannst die Ziffern errechnen, dann bist du unabhängig von Erkennungsfehlern ABER: wenn du dich verzählst/verrechnest, steht dein Wert total im Wald und du merkst es nicht.Das läßt sich nie ganz lösen. Es kann nur durch eine zweite Logik-Ebene verbessert werden. Erstmal umwandeln und auf Konsistentz prüfen. Ist dort ein Problem, den Wert errechnen (gibt es mehrer Optionen).
Und in einer zweiten Ebene mitnotieren, dass es jetzt gerade errechnet wurde und wenn das zu oft / zu lange der Fall ist, dann Meldung an den Nutzer. -
@Knallochse er macht es ähnlich. Wenn die letzte Ziffer nicht stimmt, wird sie errechnet.
Ist ein Grundsatzproblem: du kannst die Ziffern errechnen, dann bist du unabhängig von Erkennungsfehlern ABER: wenn du dich verzählst/verrechnest, steht dein Wert total im Wald und du merkst es nicht.Das läßt sich nie ganz lösen. Es kann nur durch eine zweite Logik-Ebene verbessert werden. Erstmal umwandeln und auf Konsistentz prüfen. Ist dort ein Problem, den Wert errechnen (gibt es mehrer Optionen).
Und in einer zweiten Ebene mitnotieren, dass es jetzt gerade errechnet wurde und wenn das zu oft / zu lange der Fall ist, dann Meldung an den Nutzer.@jomjol stimme dir in jedem Punkt zu. Vielleicht kannst du ja einen Adapter Programmierer dazu bewegen, einen IoBroker Adapter zu erstellen. (dann würde auch der Weg über Parser entfallen) .
Wenn der Adapter einen Datenpunkt "Fehler" mit True/False steuert, dann könnte man darauf reagieren mit z.Bsp. Message per Telegramm; VIS Ausgabe etc.
Mit der Meldung müsste man dann wieder manuell (SetpreValue) nachjustieren. -
Ich habe um die Fehlerquote zu verringern und genauere Werte zu erhalten die config angepasst.
alt -> MaxRateValue=0.1
neu-> MaxRateValue=0.011m³=1000L
0,1m³=100L
0,01m³=10L
0,001m³=1L
0,0001m³=100mLDas ganze muss natürlich auch auf die Abtastrate passen.
Bei mir ist diese 60 Sekunden.
Werde testen ob es ausreicht.
Man könnte die MaxRateValue natürlich auch noch erhöhen auf z.B. 0.02 was dann 20L/min entsprechen.PS: Es gibt aber ein Problem, dass mir gerade eingefallen ist. Wenn der Wasserzähler Server mal offline ist und in dieser Zeit mehr als 10-20L Wasser verbraucht werden, geht der Zähler der Uhr ja höher und der Bildvergleichsserver spuckt dann zukünftig nur noch Fehler raus, weil der Abstand zu groß ist. Dann müsste man den Docker Container manuell stoppen den aktuellen Wert in die prevalue.ini schreiben und dann den Container wieder starten.
-
Ich habe um die Fehlerquote zu verringern und genauere Werte zu erhalten die config angepasst.
alt -> MaxRateValue=0.1
neu-> MaxRateValue=0.011m³=1000L
0,1m³=100L
0,01m³=10L
0,001m³=1L
0,0001m³=100mLDas ganze muss natürlich auch auf die Abtastrate passen.
Bei mir ist diese 60 Sekunden.
Werde testen ob es ausreicht.
Man könnte die MaxRateValue natürlich auch noch erhöhen auf z.B. 0.02 was dann 20L/min entsprechen.PS: Es gibt aber ein Problem, dass mir gerade eingefallen ist. Wenn der Wasserzähler Server mal offline ist und in dieser Zeit mehr als 10-20L Wasser verbraucht werden, geht der Zähler der Uhr ja höher und der Bildvergleichsserver spuckt dann zukünftig nur noch Fehler raus, weil der Abstand zu groß ist. Dann müsste man den Docker Container manuell stoppen den aktuellen Wert in die prevalue.ini schreiben und dann den Container wieder starten.
@Atifan den Wert kannst du mit
IPServer:Port/setPreValue.html?value=
mitgeben. Ohne stoppen oder Starten des Servers -
Ich habe um die Fehlerquote zu verringern und genauere Werte zu erhalten die config angepasst.
alt -> MaxRateValue=0.1
neu-> MaxRateValue=0.011m³=1000L
0,1m³=100L
0,01m³=10L
0,001m³=1L
0,0001m³=100mLDas ganze muss natürlich auch auf die Abtastrate passen.
Bei mir ist diese 60 Sekunden.
Werde testen ob es ausreicht.
Man könnte die MaxRateValue natürlich auch noch erhöhen auf z.B. 0.02 was dann 20L/min entsprechen.PS: Es gibt aber ein Problem, dass mir gerade eingefallen ist. Wenn der Wasserzähler Server mal offline ist und in dieser Zeit mehr als 10-20L Wasser verbraucht werden, geht der Zähler der Uhr ja höher und der Bildvergleichsserver spuckt dann zukünftig nur noch Fehler raus, weil der Abstand zu groß ist. Dann müsste man den Docker Container manuell stoppen den aktuellen Wert in die prevalue.ini schreiben und dann den Container wieder starten.
@Atifan Hi Atfian, Dein MaxRateValue=0.01 wird nicht funktionieren, da bei einem Wechsel von einer zur anderen Ziffer bei mir circa 130 Liter "vergehen". Ich habe mit MaxRateValue=0.15 gute Erfahrungen gemacht. Weiter oben im Thread gibt es von mir auch eine Berechnung wieviel Liter maximal pro Sekunde über eine Wasseruhr laufen können. Die multiplizierst Du dann mit Deiner Abtastrate, aber wie schon von @jomjol und @Knallochse geschrieben, wäre eine zweite Auswertelogikschicht sicher das optimale Auswerteverfahren.
@jomjol Auf Deine Frage weiter oben, es sollte niemanden stören wie der Wert zustande kommt, da die gesamte SW eh in einem Docker läuft und damit eh nicht mehr editierbar / lesbar ist.
-
@Knallochse er macht es ähnlich. Wenn die letzte Ziffer nicht stimmt, wird sie errechnet.
Ist ein Grundsatzproblem: du kannst die Ziffern errechnen, dann bist du unabhängig von Erkennungsfehlern ABER: wenn du dich verzählst/verrechnest, steht dein Wert total im Wald und du merkst es nicht.Das läßt sich nie ganz lösen. Es kann nur durch eine zweite Logik-Ebene verbessert werden. Erstmal umwandeln und auf Konsistentz prüfen. Ist dort ein Problem, den Wert errechnen (gibt es mehrer Optionen).
Und in einer zweiten Ebene mitnotieren, dass es jetzt gerade errechnet wurde und wenn das zu oft / zu lange der Fall ist, dann Meldung an den Nutzer.@jomjol
Hallo,ich probiere hier mit den neuronalen Netzen für die Erkennung der digitalen Ziffern rum.
Leider ist das Ergebnis immer noch nicht so toll, wie man sich das wünschen könnte.Ich habe den Ansatz probiert, ein std. Netz zu nehmen und es zu trainieren, dass geht, aber dass ist vermutlich zu gross für einen Raspi.
Vlt. aber eine interessante alternative, die nicht so dramatische Änderungen nach sich zieht:
Von OpenCV gibt es tesseract. Das kann OCR mit LSTM und klassisch.
Ich habe recht gute Ergebnisse erzielt (erstmal ohne Integration in den Server) mit
tesseract ziffer5_2020-02-20_16-10-04.jpg stdout --dpi 70 --oem 2 --psm 10
wobei das jpg eine Ziffer darstellt. Selbst bei NAN Werten ist es nicht schlecht.
Was aber gut funktioniert ist die Unterscheidung von 3 9 6 und 5.tesseract nutze ich in Version 4.0.0
tesseract kann man auch sehr gut per wrapper direkt aus python nutzen.
-
Meint ihr die ESP32 CAM macht es auf dauer mit, wenn sie jede Minute ein Bild macht und die LED an geht?
Das sind pro Tag 60 x 24 = 1440 Bilder bzw. Auslösungen und im Jahr 525600 Auslösungen.
Ich denke das ist etwas zu hohe Abtastrate oder hat jemand Langzeiterfahrung und macht die CAM bzw. die LED das mit?
In welchen Intervallen tastet ihr denn so ab? -
@Atifan Ich taste mit 30 Sekunden-Intervallen ab, da ich damit auch in meinem Haus eine Art "Leckerkennung" betreibe (habe viele alte Kupferrohre). Ich habe mir einen zweiten ESP32CAM hergerichtet, welchen ich dann bei Versagen des in Betrieb befindlichen austauschen kann. Bei circa 10 Euro für einen ESP32CAM ist das auch kein hoher finanzieller Verlust. Mein ESP32CAM läuft nun seit circa 5 Monaten ohne Probleme durch.
-
Hi, ich habe das Problem, dass der Parser anscheinend nach paar Stunden nicht mehr weitermacht und den Datenpunkt nicht mehr aktualisiert.
Ich muss dann einfach die Instanz parser.0 stoppen und neustarten, dann funktioniert es wieder.
Hat jemand das gleiche Problem?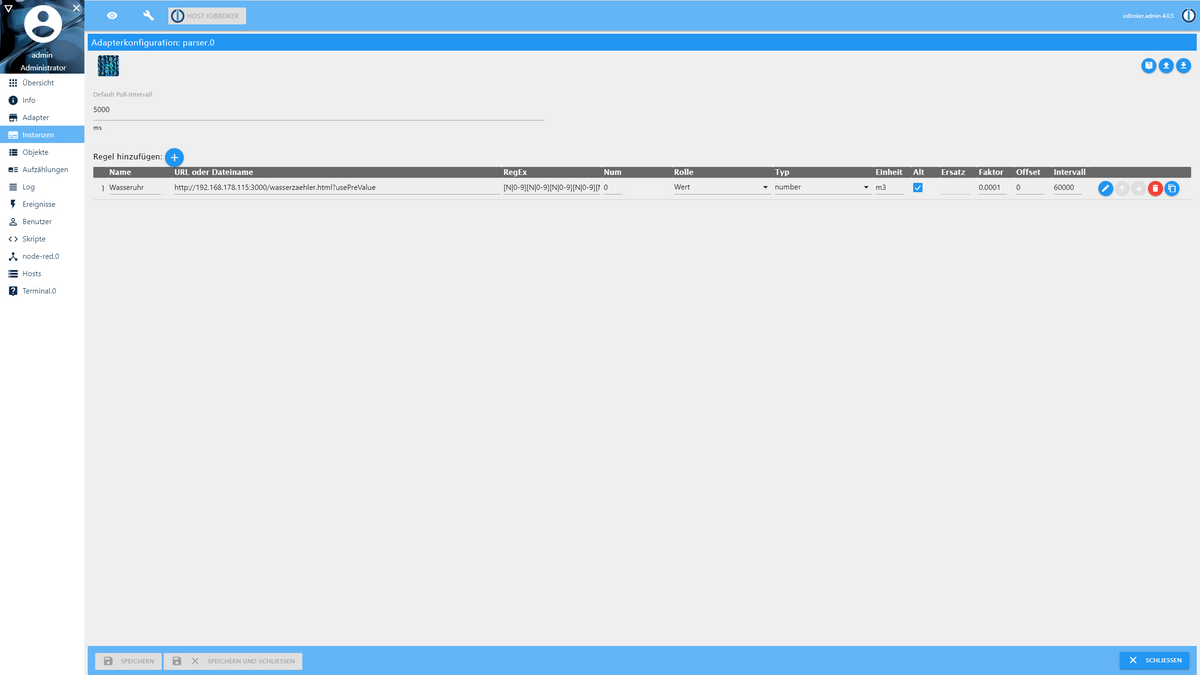
-
@Knallochse Guten Morgen,
danke für den Input - Code ist okay, aber ich hatte folgendes Phänomen: falsche erkannte letzte Ziffer (3 --> 9), das wurde mit RateTooHigh auch korrekt gemeldet. Die richtige Ziffer kam erst 150 Liter weiter (wieder zurück zur 3). Aber dann wurde sie auch nicht mehr gemeldet, da jetzt wieder RateTooHigh aufgrund der 150 Liter! Offensichtlich dauert es bei meiner Wasseruhr ca. 150 Liter bis die letzte Ziffer wieder korrekt im Bild ist.
Ich habe jetzt erstmal den MaxRateValue auf 0.2 gesetzt (auch in den Default Settings - v5.5.2)
Habe auch schonmal überlegt, ob ich deinen Algo zur Berechnung der Ziffern implementieren soll. Dann wird es halt für Aussenstehende echt schwierig, das zu verstehen und einzustellen. Andererseits wenn nur richtige Werte komme ist es auch egal, was im Inneren läuft.@all: Was ist eure Meinung?
P.S.: versuche gerade Tensorflow 2.1 für die Synology zu kompilieren. Hatte auch schon geklappt aber nur mit Python 3.6, brauche aber Python 3.7. Mal sehen, vielleicht klappt es ja irgendwann demnächst (Run dauert immer etwas, da 10h+ kompiliert wird - gutes Argument für einen neuen Rechner - versuche es gerade meiner Frau schmackhaft zu machen
)Gruß,
jomjol@jomjol
Hallo,tesseract hat es bei meinen Tests nicht so sehr gebracht.
Habe aber die Bildoptimierung in den normalen Zweig eingebaut. Damit sind bei mir die Ergebnisse besser.
Natürlich sollte man das Modell dann auch auf solch optimierten Bildern trainieren.Habs als Pullrequest eingestellt.
MfG
Sissi
–-----------------------------------------
1 CCU3 1 CCU2-Gateway 1 LanGateway 1 Pi-Gateway 1 I7 für ioBroker/MySQL
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
276
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge