

InfluxDB2 aufeinmal sehr hohe CPU Auslastung
-
Hallo zusammen,
ich habe auf meinen Raspi 5 mit 8gb RAM seit ca 7 Monate ein Grafana Dashboard laufen.
Dazu einige Adapter welche die Daten in meine InfluxDB2 schaufeln.
Vorgestern sprang aufeinmal die Temperatur die sonst immer bei 50°C war sprunghaft auf 85°C dauerhaft.
Top zeigt auch tatsächlich eine CPU Auslastung von teils über 100% für den Dienst influxdb.
Tasks: 163 total, 1 running, 162 sleeping, 0 stopped, 0 zombie %Cpu(s): 53.3 us, 3.4 sy, 0.0 ni, 41.3 id, 1.4 wa, 0.0 hi, 0.5 si, 0.0 st MiB Mem : 8052.3 total, 3135.4 free, 1612.4 used, 3408.3 buff/cache MiB Swap: 512.0 total, 512.0 free, 0.0 used. 6440.0 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 755 influxdb 20 0 19.0g 960880 733728 S 112.0 11.7 31:17.00 influxd 17792 iobroker 20 0 5281216 129984 46080 S 57.8 1.6 0:02.31 io.tibberlink.0 17582 iobroker 20 0 5363744 401664 40448 S 22.3 4.9 0:12.79 iobroker.js-con 17642 iobroker 20 0 5241360 81568 40960 S 16.9 1.0 0:02.80 io.influxdb.0 17717 iobroker 20 0 5031344 134480 40448 S 8.3 1.6 0:02.65 io.mqtt.0 17760 iobroker 20 0 5010800 107984 40448 S 5.3 1.3 0:01.62 io.sonoff.0 17681 iobroker 20 0 4970448 74432 39936 S 4.0 0.9 0:01.22 io.rpi2.0 17777 iobroker 20 0 5075504 103120 40448 S 1.3 1.3 0:01.78 io.modbus.0 15658 root 20 0 60480 8192 3584 S 0.7 0.1 0:08.93 rtl_433 17600 iobroker 20 0 5382144 218368 46592 S 0.7 2.6 0:05.69 io.admin.0 17 root 20 0 0 0 0 I 0.3 0.0 0:00.63 rcu_preempt 819 grafana 20 0 1722144 271856 156160 S 0.3 3.3 1:04.06 grafana 16424 root 20 0 0 0 0 I 0.3 0.0 0:00.27 kworker/2:1-events 17378 root 20 0 20352 10224 7680 S 0.3 0.1 0:00.11 sshd 1 root 20 0 169808 11680 8192 S 0.0 0.1 0:02.76 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.00 pool_workqueue_release 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-rcu_g 5 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-rcu_p 6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-slub_ 7 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-netns 9 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-events_highpri 11 root 20 0 0 0 0 I 0.0 0.0 0:00.00 kworker/u8:0-netns 12 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-mm_pe 13 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_kthread 14 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_rude_kthread 15 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_trace_kthread 16 root 20 0 0 0 0 S 0.0 0.0 0:00.13 ksoftirqd/0 18 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 19 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0 20 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/1 21 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/1 root@raspberrypi:~# vcgencmd measure_temp temp=71.9'CHat jemand einen Tip was hier passiert sein kann?
Danke und Gruß
-
Hallo zusammen,
ich habe auf meinen Raspi 5 mit 8gb RAM seit ca 7 Monate ein Grafana Dashboard laufen.
Dazu einige Adapter welche die Daten in meine InfluxDB2 schaufeln.
Vorgestern sprang aufeinmal die Temperatur die sonst immer bei 50°C war sprunghaft auf 85°C dauerhaft.
Top zeigt auch tatsächlich eine CPU Auslastung von teils über 100% für den Dienst influxdb.
Tasks: 163 total, 1 running, 162 sleeping, 0 stopped, 0 zombie %Cpu(s): 53.3 us, 3.4 sy, 0.0 ni, 41.3 id, 1.4 wa, 0.0 hi, 0.5 si, 0.0 st MiB Mem : 8052.3 total, 3135.4 free, 1612.4 used, 3408.3 buff/cache MiB Swap: 512.0 total, 512.0 free, 0.0 used. 6440.0 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 755 influxdb 20 0 19.0g 960880 733728 S 112.0 11.7 31:17.00 influxd 17792 iobroker 20 0 5281216 129984 46080 S 57.8 1.6 0:02.31 io.tibberlink.0 17582 iobroker 20 0 5363744 401664 40448 S 22.3 4.9 0:12.79 iobroker.js-con 17642 iobroker 20 0 5241360 81568 40960 S 16.9 1.0 0:02.80 io.influxdb.0 17717 iobroker 20 0 5031344 134480 40448 S 8.3 1.6 0:02.65 io.mqtt.0 17760 iobroker 20 0 5010800 107984 40448 S 5.3 1.3 0:01.62 io.sonoff.0 17681 iobroker 20 0 4970448 74432 39936 S 4.0 0.9 0:01.22 io.rpi2.0 17777 iobroker 20 0 5075504 103120 40448 S 1.3 1.3 0:01.78 io.modbus.0 15658 root 20 0 60480 8192 3584 S 0.7 0.1 0:08.93 rtl_433 17600 iobroker 20 0 5382144 218368 46592 S 0.7 2.6 0:05.69 io.admin.0 17 root 20 0 0 0 0 I 0.3 0.0 0:00.63 rcu_preempt 819 grafana 20 0 1722144 271856 156160 S 0.3 3.3 1:04.06 grafana 16424 root 20 0 0 0 0 I 0.3 0.0 0:00.27 kworker/2:1-events 17378 root 20 0 20352 10224 7680 S 0.3 0.1 0:00.11 sshd 1 root 20 0 169808 11680 8192 S 0.0 0.1 0:02.76 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.00 pool_workqueue_release 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-rcu_g 5 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-rcu_p 6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-slub_ 7 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-netns 9 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-events_highpri 11 root 20 0 0 0 0 I 0.0 0.0 0:00.00 kworker/u8:0-netns 12 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-mm_pe 13 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_kthread 14 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_rude_kthread 15 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_trace_kthread 16 root 20 0 0 0 0 S 0.0 0.0 0:00.13 ksoftirqd/0 18 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 19 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0 20 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/1 21 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/1 root@raspberrypi:~# vcgencmd measure_temp temp=71.9'CHat jemand einen Tip was hier passiert sein kann?
Danke und Gruß
Schau dir das log der Influx mal an.
Hatte ich auch. Influx db war zu groß (oder defekt ?) und konnte nicht geöffnet werden. Dadurch hat sie dauernd gestartet und das System dicht gemacht.
Als weizteres indic kannst du die pid des influx prozesses anschaun. Wenn die wechselt startet das Ding ziemlich sicher andauernd neu
Entwicklung u Betreuung: envertech-pv, hoymiles-ms, ns-client, pid, snmp Adapter;
Support Repositoryverwaltung.Wer 'nen Kaffee spendieren will: https://paypal.me
-
Hallo zusammen,
ich habe auf meinen Raspi 5 mit 8gb RAM seit ca 7 Monate ein Grafana Dashboard laufen.
Dazu einige Adapter welche die Daten in meine InfluxDB2 schaufeln.
Vorgestern sprang aufeinmal die Temperatur die sonst immer bei 50°C war sprunghaft auf 85°C dauerhaft.
Top zeigt auch tatsächlich eine CPU Auslastung von teils über 100% für den Dienst influxdb.
Tasks: 163 total, 1 running, 162 sleeping, 0 stopped, 0 zombie %Cpu(s): 53.3 us, 3.4 sy, 0.0 ni, 41.3 id, 1.4 wa, 0.0 hi, 0.5 si, 0.0 st MiB Mem : 8052.3 total, 3135.4 free, 1612.4 used, 3408.3 buff/cache MiB Swap: 512.0 total, 512.0 free, 0.0 used. 6440.0 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 755 influxdb 20 0 19.0g 960880 733728 S 112.0 11.7 31:17.00 influxd 17792 iobroker 20 0 5281216 129984 46080 S 57.8 1.6 0:02.31 io.tibberlink.0 17582 iobroker 20 0 5363744 401664 40448 S 22.3 4.9 0:12.79 iobroker.js-con 17642 iobroker 20 0 5241360 81568 40960 S 16.9 1.0 0:02.80 io.influxdb.0 17717 iobroker 20 0 5031344 134480 40448 S 8.3 1.6 0:02.65 io.mqtt.0 17760 iobroker 20 0 5010800 107984 40448 S 5.3 1.3 0:01.62 io.sonoff.0 17681 iobroker 20 0 4970448 74432 39936 S 4.0 0.9 0:01.22 io.rpi2.0 17777 iobroker 20 0 5075504 103120 40448 S 1.3 1.3 0:01.78 io.modbus.0 15658 root 20 0 60480 8192 3584 S 0.7 0.1 0:08.93 rtl_433 17600 iobroker 20 0 5382144 218368 46592 S 0.7 2.6 0:05.69 io.admin.0 17 root 20 0 0 0 0 I 0.3 0.0 0:00.63 rcu_preempt 819 grafana 20 0 1722144 271856 156160 S 0.3 3.3 1:04.06 grafana 16424 root 20 0 0 0 0 I 0.3 0.0 0:00.27 kworker/2:1-events 17378 root 20 0 20352 10224 7680 S 0.3 0.1 0:00.11 sshd 1 root 20 0 169808 11680 8192 S 0.0 0.1 0:02.76 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.00 pool_workqueue_release 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-rcu_g 5 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-rcu_p 6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-slub_ 7 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-netns 9 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-events_highpri 11 root 20 0 0 0 0 I 0.0 0.0 0:00.00 kworker/u8:0-netns 12 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/R-mm_pe 13 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_kthread 14 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_rude_kthread 15 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_trace_kthread 16 root 20 0 0 0 0 S 0.0 0.0 0:00.13 ksoftirqd/0 18 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 19 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0 20 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/1 21 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/1 root@raspberrypi:~# vcgencmd measure_temp temp=71.9'CHat jemand einen Tip was hier passiert sein kann?
Danke und Gruß
@kirk1701 sagte in InfluxDB2 aufeinmal sehr hohe CPU Auslastung:
root@raspberrypi
Damit kann alles passiert sein...
Verdammte AXT, HAMPELT DOCH NICHT IMMER ALS SCHEISS ROOT ÜBER DIE KISTEN...
In Logs schauen und prüfen was da passiert...
-
Schau dir das log der Influx mal an.
Hatte ich auch. Influx db war zu groß (oder defekt ?) und konnte nicht geöffnet werden. Dadurch hat sie dauernd gestartet und das System dicht gemacht.
Als weizteres indic kannst du die pid des influx prozesses anschaun. Wenn die wechselt startet das Ding ziemlich sicher andauernd neu
@mcm1957 ,
danke für deinen Tip.
Wie kann denn eine Datenbank zu groß werden? In der Tat läuft das Dashboard jetzt schon einige Monate und es werden alle 10sek Werte geschrieben.
Kann man bei InfluxDB2 eventuell die Datenbank "auto" prüfen lassen?
Wie groß darf denn eine InfluxDB2 werden bevor es Probleme gibt? Ich schaue heute Abend mal ob man mit den Log etwas (oder ich) anfangen kann.
Das Problem trat plötzlich und unerwartet auf siehe Temperaturverlauf.
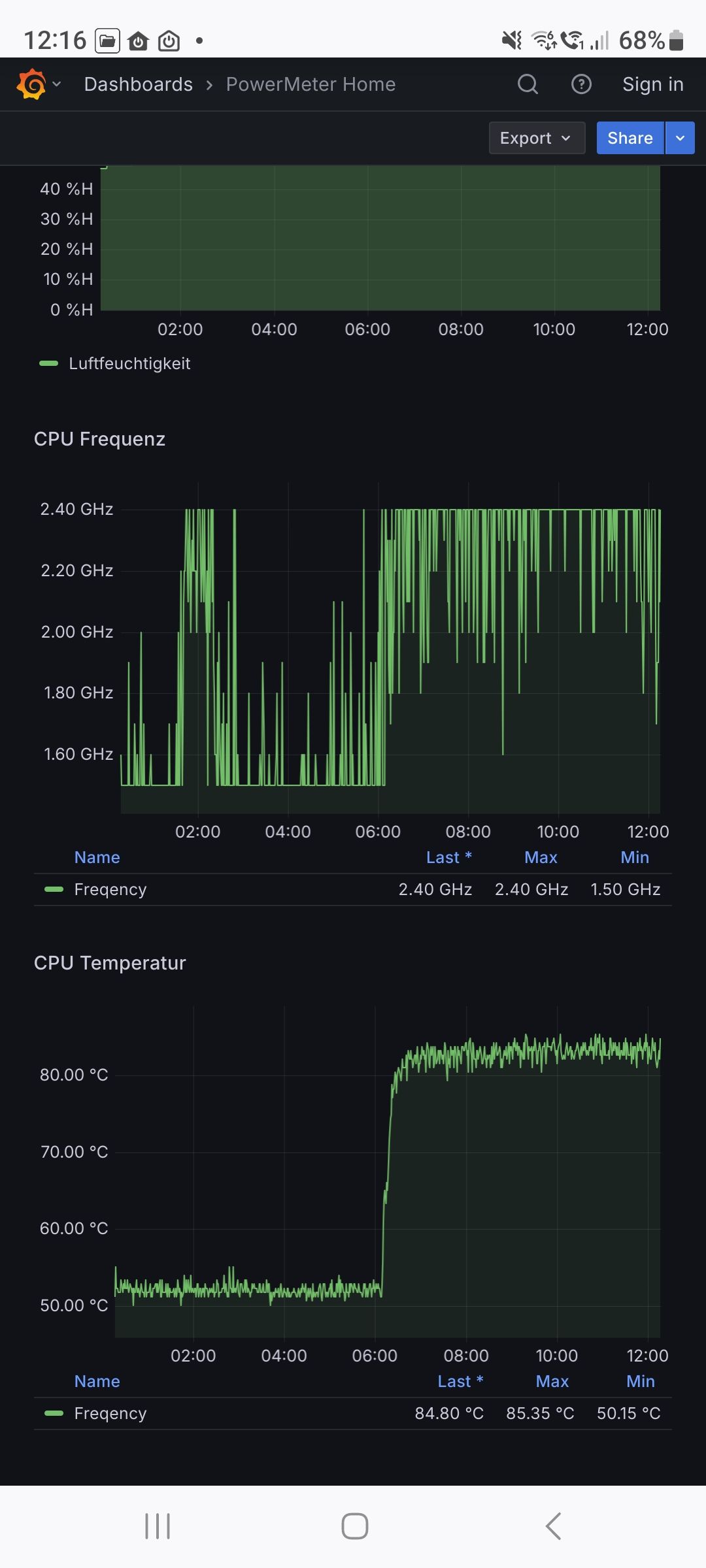
Danke und Gruß
-
@mcm1957 ,
danke für deinen Tip.
Wie kann denn eine Datenbank zu groß werden? In der Tat läuft das Dashboard jetzt schon einige Monate und es werden alle 10sek Werte geschrieben.
Kann man bei InfluxDB2 eventuell die Datenbank "auto" prüfen lassen?
Wie groß darf denn eine InfluxDB2 werden bevor es Probleme gibt? Ich schaue heute Abend mal ob man mit den Log etwas (oder ich) anfangen kann.
Das Problem trat plötzlich und unerwartet auf siehe Temperaturverlauf.
Danke und Gruß
@kirk1701
Bei mir hat sie beim Start gemeldet fass das Memory ausgeht u ist gecrashed. Kam zu restart loop u hoher cpu last bei ewigen restarts.Habs nicht weiter analysiert. Wenn der db server bei dir nicht crashed ist was anderes.
Entwicklung u Betreuung: envertech-pv, hoymiles-ms, ns-client, pid, snmp Adapter;
Support Repositoryverwaltung.Wer 'nen Kaffee spendieren will: https://paypal.me
-
@kirk1701
Bei mir hat sie beim Start gemeldet fass das Memory ausgeht u ist gecrashed. Kam zu restart loop u hoher cpu last bei ewigen restarts.Habs nicht weiter analysiert. Wenn der db server bei dir nicht crashed ist was anderes.
Tja, so wie es aussieht hat es die Partiton nach 7 Monaten voll geschrieben....
Filesystem 1K-blocks Used Available Use% Mounted on udev 4089360 0 4089360 0% /dev tmpfs 825680 7360 818320 1% /run /dev/nvme0n1p2 50347112 11500156 36750884 24% / tmpfs 4128352 0 4128352 0% /dev/shm tmpfs 5120 48 5072 1% /run/lock /dev/nvme0n1p1 522230 57458 464772 12% /boot/firmware /dev/nvme0n1p5 19849964 18467376 342204 99% /media/datenbank /dev/nvme0n1p6 906993596 4537336 856310272 1% /media/netzlaufwerk /dev/sda3 239241612 10205832 216810300 5% /media/backup tmpfs 825664 0 825664 0% /run/user/0Ich zieh die mal größer und werde berichten.
Gruß
Nachtrag... die 20Gb waren einfach voll

Filesystem 1K-blocks Used Available Use% Mounted on udev 4089360 0 4089360 0% /dev tmpfs 825680 7376 818304 1% /run /dev/nvme0n1p2 50347112 11501104 36749936 24% / tmpfs 4128352 0 4128352 0% /dev/shm tmpfs 5120 48 5072 1% /run/lock /dev/nvme0n1p1 522230 57458 464772 12% /boot/firmware /dev/nvme0n1p5 125945132 18173248 101341420 16% /media/datenbank /dev/nvme0n1p6 805195880 4537336 759683756 1% /media/netzlaufwerk /dev/sda3 239241612 10205832 216810300 5% /media/backup tmpfs 825664 0 825664 0% /run/user/0Nun läuft wieder alles :-)
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
428
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge