

[gelöst]Speicherbelegung influxdb2 (nach Containerisierung?)
-
Moin,
ich weiß, dass ich vermutlich an anderen Stellen mit influx-Problemen "richtiger" wäre, aber ich habe mit dieser Community einfach super Erfahrungen :-) Wer also nicht weiterlesen möchte, den möchte ich nicht aufhalten.
Hard- & Software:
Ich habe einen Pi4 mit 8GB RAM.
Es läuft noch bullseye, da ich über bookworm gelesen habe, dass es mit ioBroker im Docker wohl noch irgendwo Probleme gab. Aber das ist hier nicht das Thema.Container werden über Portainer verwaltet. ioBroker & Influx2. Configuration kann ich im Zweifel nachreichen.
Backups mache ich via BackItUp in die Cloud, und zwar von ioBroker, Node-Red und InfluxDB.Das Problem:
Nach der erfolgreichen Containerisierung lief anfangs alles perfekt, ich habe Influx auch neu aufgesetzt, deswegen fing ich wieder bei 0 an - die Daten sind glücklicherweise nicht super wichtig für mich. Nun war ich leider für 3 Wochen nicht zu Hause und der Cloud-Speicherplatz quillt auf einmal über. Der Grund: Die Backups von Influx2.Jetzt muss ich kurz ausholen:
In Influx speichere ich von ~15 Temperatursensoren alle fünf Minuten die Werte. Vorhaltezeit war auf zwei Jahre gesetzt, was für mich angesichts der Datenmenge völlig ok gewesen ist. Nach Adam Ries sind das 4.320 Datenpunkte pro Tag und 30.240 pro Woche. In zwei Jahren sind das rund 3 Mio. Datenpunkte, bevor die Vorhaltezeit abläuft. Also nichts, mit dem man Speicherplatz vollmüllen würde. So dachte ich...Bisherige Analyse:
Vor der Containerisierung lief die gleiche Software, aber eben "roh", auf dem Pi. Zu der Zeit wuchsen die Influx-Sicherungen ca. um 100kb pro Woche. In meinen Augen ein gesunder Wert, um den ich mir nie Gedanken gemacht habe.Und jetzt traf mich der Schlag, als ich den Grund der Speicherplatzwarnung gefunden hatte. Die Influx-Sicherung wuchs alle zwei Tage im viele mb an, siehe Screenshot.
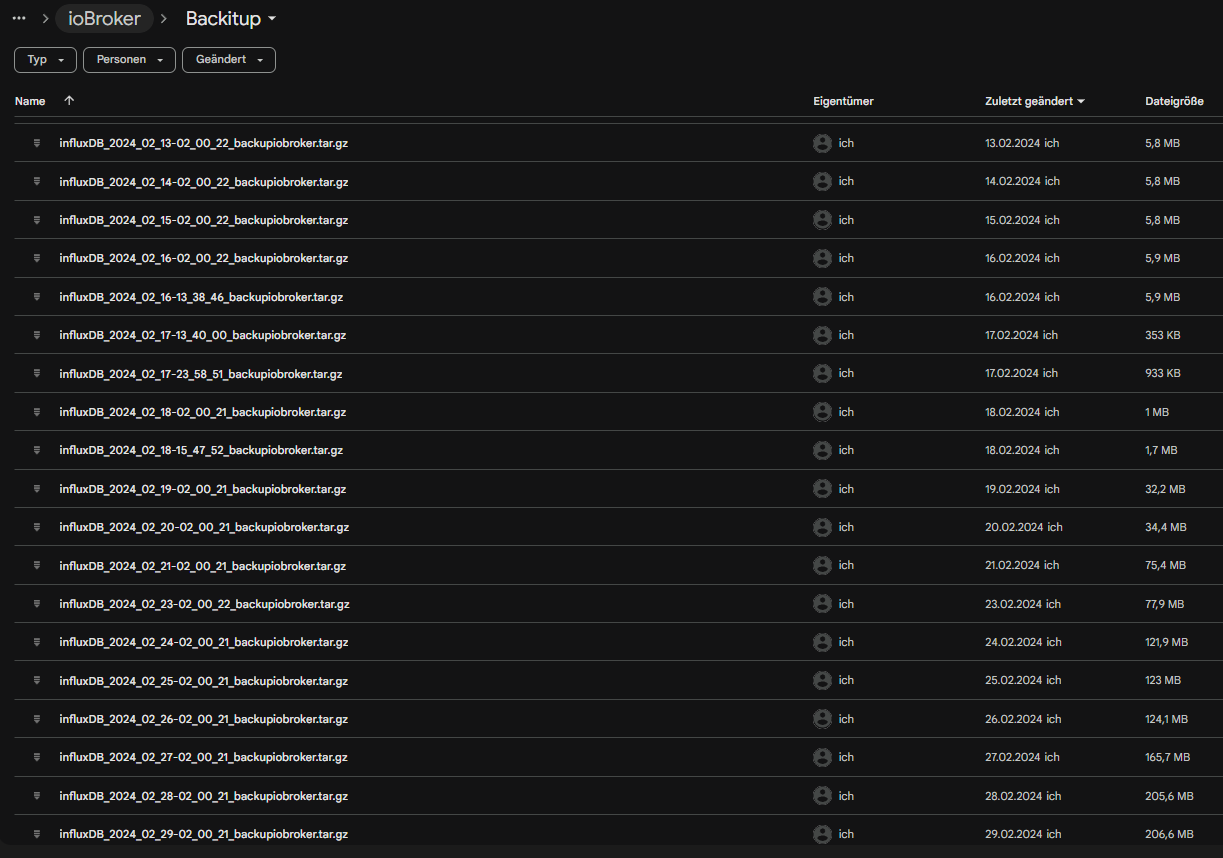
Am 17.2. habe ich ioBroker und Influx in Container verschoben. Davor war alles super. Die ersten 2-3 Tage nach der Containerisierung habe ich zwar auch geschaut, aber da war es noch nicht so auffällig. Während meiner Abwesenheit wurden die Backups dann allerdings bis 1gb groß.
Nachdem ich vorgestern wieder zu Hause war, war meine erste Reißleine die Vorhaltezeit. Ich habe ohne groß nachzudenken die Vorhaltezeit auf zwei Wochen gesetzt. Jetzt sind die Backups wieder bei rund 770mb. Auffällig war, dass so ein großer Speicherplatz-Sprung nur alle zwei Tage auftritt. Die anderen Tage waren die Sprünge nicht so groß, aber immer noch beachtlich für die relativ geringe Menge der Daten.Ab jetzt wurde die Analyse sehr zäh. Ich verstehe weder, wie genau Influx funktioniert (anders als relationale Datenbanken, wenn ich das richtig gelesen habe), noch weiß ich, was genau in der Datenbank steht und soviel Speicherplatz belegt. Ich habe auch keine Ahnung, ob es Logs sind, oder ob da was komprimiert oder entrümpelt werden kann.
Ich konnte nur herausfinden, dass es riesige .tsm-Dateien gibt, die sich in den Ordnern befinden. Hier mal ein Screenshot von der Influx-Ordner-Speicherplatzbelegung:
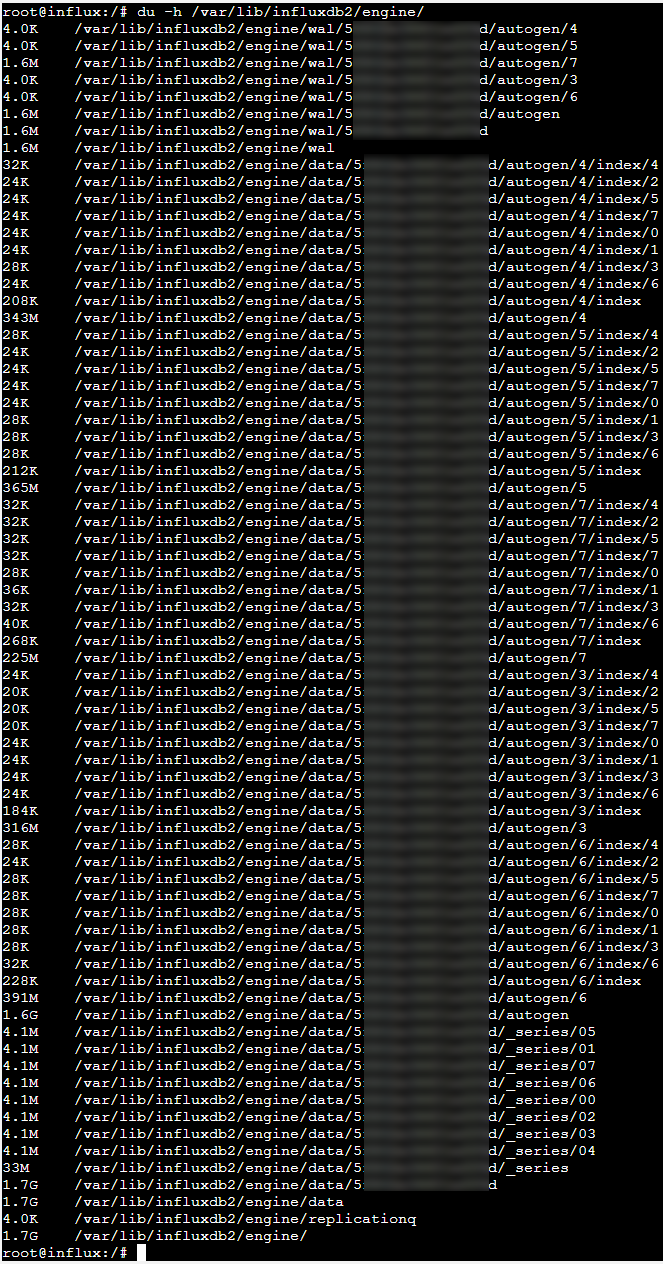
An dieser Stelle schon einmal vielen Dank für's Lesen!
Jetzt kommt die alles entscheidende Frage: Hat jemand eine Idee, was hier im Argen liegen könnte?
Wenn ich die Datenmenge vor der Containerisierung anschaue, dann kann ich mir das überhaupt nicht erklären. Liegt's gar am Container? Ich habe gestern einmal die Container neu heruntergeladen, aber noch keine auswertbaren Daten, die ich hier jetzt nennen könnte. Ich habe nach meinen Änderungen drei Backups im Abstand von 4h gemacht. Jedes Mal wuchs die Sicherung um 100kb. Das erscheint gegenüber vorher besser zu sein, aber immer noch wesentlich mehr als vor der Containerisierung. Und vor allem sind da immer noch über 700mb, deren Vorhandensein ich nicht verstehe.
Ich bin für jeden Hinweis dankbar.
VG
Tobias -
Moin,
ich weiß, dass ich vermutlich an anderen Stellen mit influx-Problemen "richtiger" wäre, aber ich habe mit dieser Community einfach super Erfahrungen :-) Wer also nicht weiterlesen möchte, den möchte ich nicht aufhalten.
Hard- & Software:
Ich habe einen Pi4 mit 8GB RAM.
Es läuft noch bullseye, da ich über bookworm gelesen habe, dass es mit ioBroker im Docker wohl noch irgendwo Probleme gab. Aber das ist hier nicht das Thema.Container werden über Portainer verwaltet. ioBroker & Influx2. Configuration kann ich im Zweifel nachreichen.
Backups mache ich via BackItUp in die Cloud, und zwar von ioBroker, Node-Red und InfluxDB.Das Problem:
Nach der erfolgreichen Containerisierung lief anfangs alles perfekt, ich habe Influx auch neu aufgesetzt, deswegen fing ich wieder bei 0 an - die Daten sind glücklicherweise nicht super wichtig für mich. Nun war ich leider für 3 Wochen nicht zu Hause und der Cloud-Speicherplatz quillt auf einmal über. Der Grund: Die Backups von Influx2.Jetzt muss ich kurz ausholen:
In Influx speichere ich von ~15 Temperatursensoren alle fünf Minuten die Werte. Vorhaltezeit war auf zwei Jahre gesetzt, was für mich angesichts der Datenmenge völlig ok gewesen ist. Nach Adam Ries sind das 4.320 Datenpunkte pro Tag und 30.240 pro Woche. In zwei Jahren sind das rund 3 Mio. Datenpunkte, bevor die Vorhaltezeit abläuft. Also nichts, mit dem man Speicherplatz vollmüllen würde. So dachte ich...Bisherige Analyse:
Vor der Containerisierung lief die gleiche Software, aber eben "roh", auf dem Pi. Zu der Zeit wuchsen die Influx-Sicherungen ca. um 100kb pro Woche. In meinen Augen ein gesunder Wert, um den ich mir nie Gedanken gemacht habe.Und jetzt traf mich der Schlag, als ich den Grund der Speicherplatzwarnung gefunden hatte. Die Influx-Sicherung wuchs alle zwei Tage im viele mb an, siehe Screenshot.
Am 17.2. habe ich ioBroker und Influx in Container verschoben. Davor war alles super. Die ersten 2-3 Tage nach der Containerisierung habe ich zwar auch geschaut, aber da war es noch nicht so auffällig. Während meiner Abwesenheit wurden die Backups dann allerdings bis 1gb groß.
Nachdem ich vorgestern wieder zu Hause war, war meine erste Reißleine die Vorhaltezeit. Ich habe ohne groß nachzudenken die Vorhaltezeit auf zwei Wochen gesetzt. Jetzt sind die Backups wieder bei rund 770mb. Auffällig war, dass so ein großer Speicherplatz-Sprung nur alle zwei Tage auftritt. Die anderen Tage waren die Sprünge nicht so groß, aber immer noch beachtlich für die relativ geringe Menge der Daten.Ab jetzt wurde die Analyse sehr zäh. Ich verstehe weder, wie genau Influx funktioniert (anders als relationale Datenbanken, wenn ich das richtig gelesen habe), noch weiß ich, was genau in der Datenbank steht und soviel Speicherplatz belegt. Ich habe auch keine Ahnung, ob es Logs sind, oder ob da was komprimiert oder entrümpelt werden kann.
Ich konnte nur herausfinden, dass es riesige .tsm-Dateien gibt, die sich in den Ordnern befinden. Hier mal ein Screenshot von der Influx-Ordner-Speicherplatzbelegung:
An dieser Stelle schon einmal vielen Dank für's Lesen!
Jetzt kommt die alles entscheidende Frage: Hat jemand eine Idee, was hier im Argen liegen könnte?
Wenn ich die Datenmenge vor der Containerisierung anschaue, dann kann ich mir das überhaupt nicht erklären. Liegt's gar am Container? Ich habe gestern einmal die Container neu heruntergeladen, aber noch keine auswertbaren Daten, die ich hier jetzt nennen könnte. Ich habe nach meinen Änderungen drei Backups im Abstand von 4h gemacht. Jedes Mal wuchs die Sicherung um 100kb. Das erscheint gegenüber vorher besser zu sein, aber immer noch wesentlich mehr als vor der Containerisierung. Und vor allem sind da immer noch über 700mb, deren Vorhandensein ich nicht verstehe.
Ich bin für jeden Hinweis dankbar.
VG
TobiasDu kannst grob prüfen, woher die Menge an Daten kommt, wenn du diese Abfrage in den Data Explorer wirfst (ggf. den Bucketnamen anpassen):
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})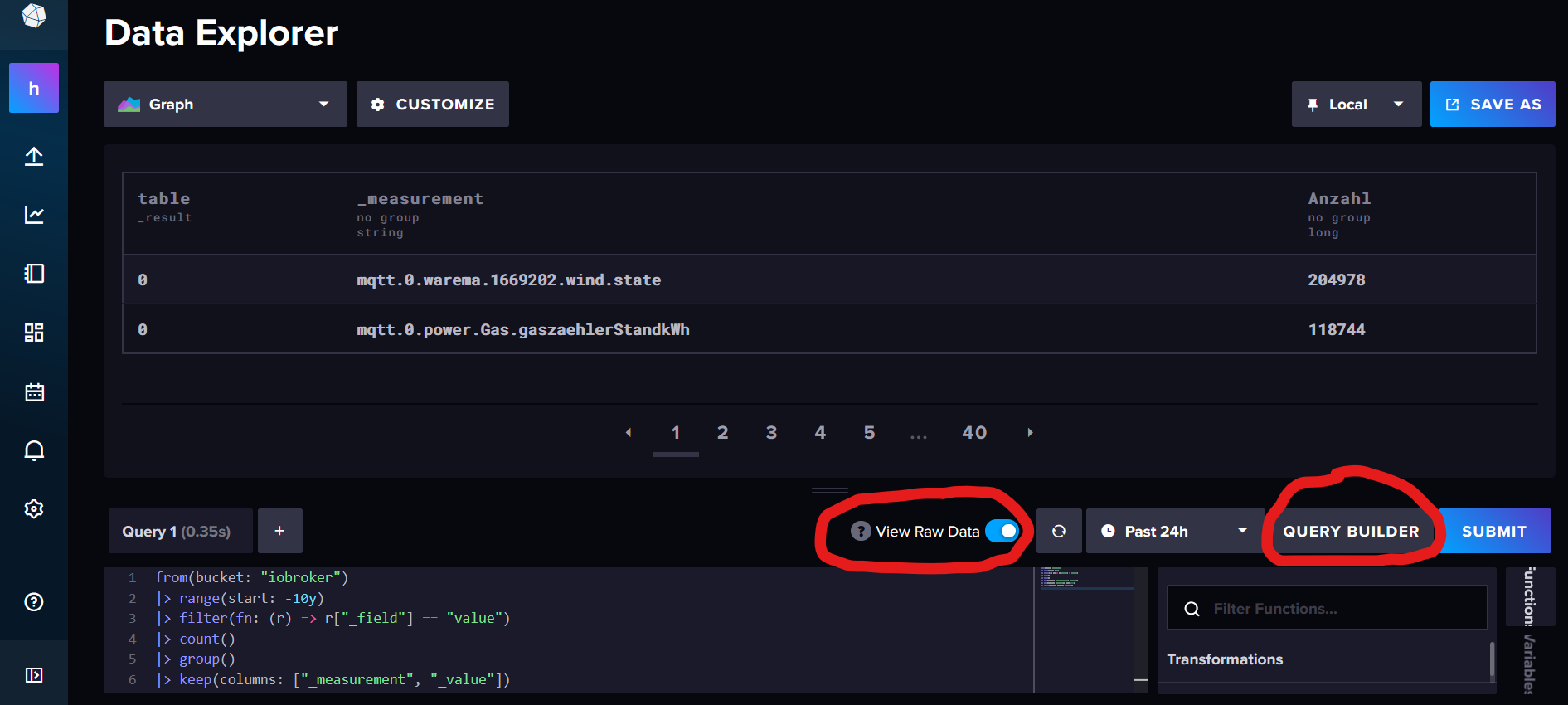
-
Du kannst grob prüfen, woher die Menge an Daten kommt, wenn du diese Abfrage in den Data Explorer wirfst (ggf. den Bucketnamen anpassen):
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})@marc-berg said in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})Hey, danke dir, Marc.
Wenn ich das ausführe, kommt das dabei raus:
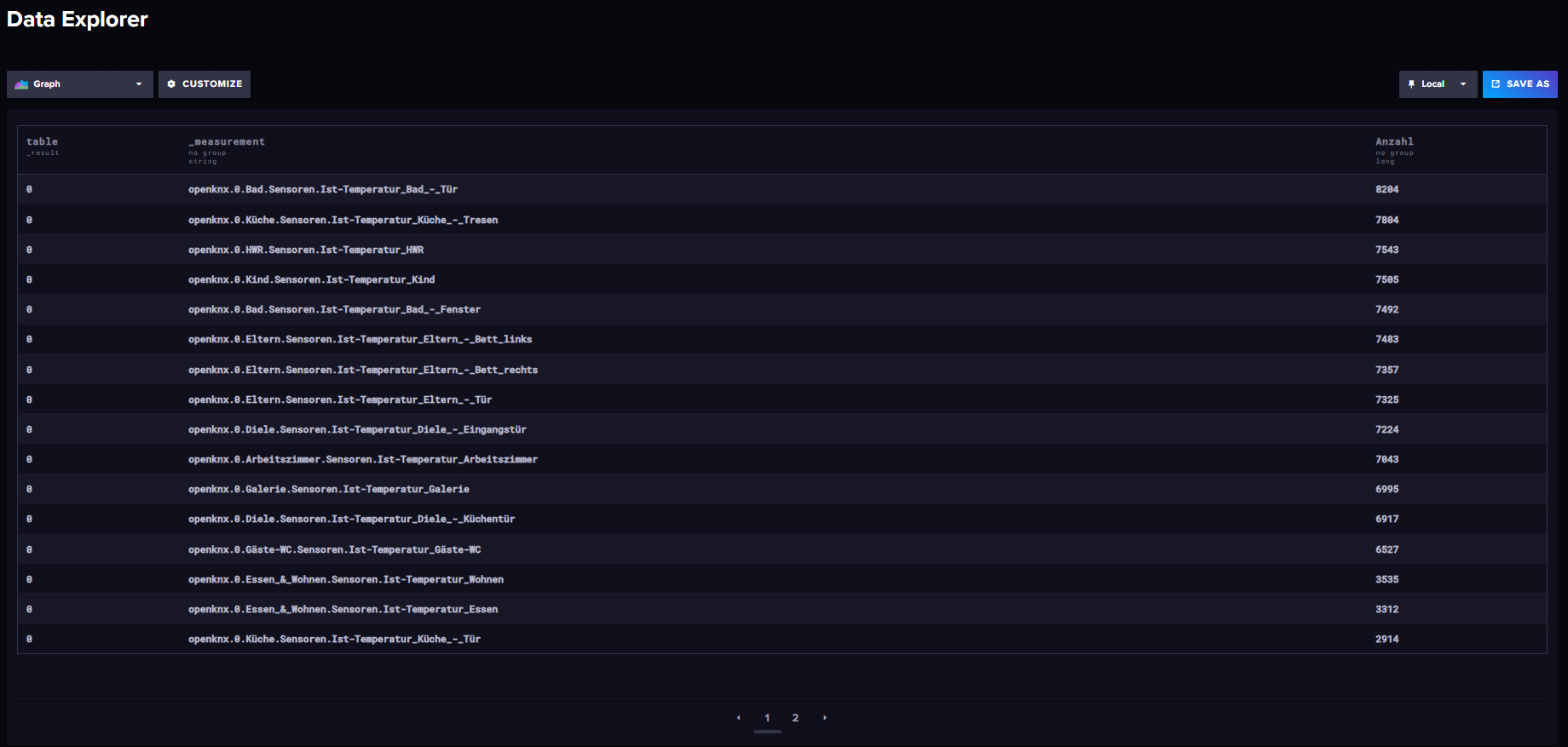
Sieht jetzt nicht nach über 700mb (gepackt!) aus....
-
@marc-berg said in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})Hey, danke dir, Marc.
Wenn ich das ausführe, kommt das dabei raus:
Sieht jetzt nicht nach über 700mb (gepackt!) aus....
@sleepwalker sagte in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
Sieht jetzt nicht nach über 700mb (gepackt!) aus....
Nein, wirklich nicht. Und weitere Buckets gibt es nicht?
EDIT: um gaaanz sicher zu gehen, dass nicht außer ioBroker noch andere Quellen mit untypischen Zeiten/Inhalten in die DB schreiben, kannst du nochmal diese angepasste Abfrage benutzen:
from(bucket: "iobroker") |> range(start: 0,stop: 100y) |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"}) -
@sleepwalker sagte in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
Sieht jetzt nicht nach über 700mb (gepackt!) aus....
Nein, wirklich nicht. Und weitere Buckets gibt es nicht?
EDIT: um gaaanz sicher zu gehen, dass nicht außer ioBroker noch andere Quellen mit untypischen Zeiten/Inhalten in die DB schreiben, kannst du nochmal diese angepasste Abfrage benutzen:
from(bucket: "iobroker") |> range(start: 0,stop: 100y) |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})@marc-berg said in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
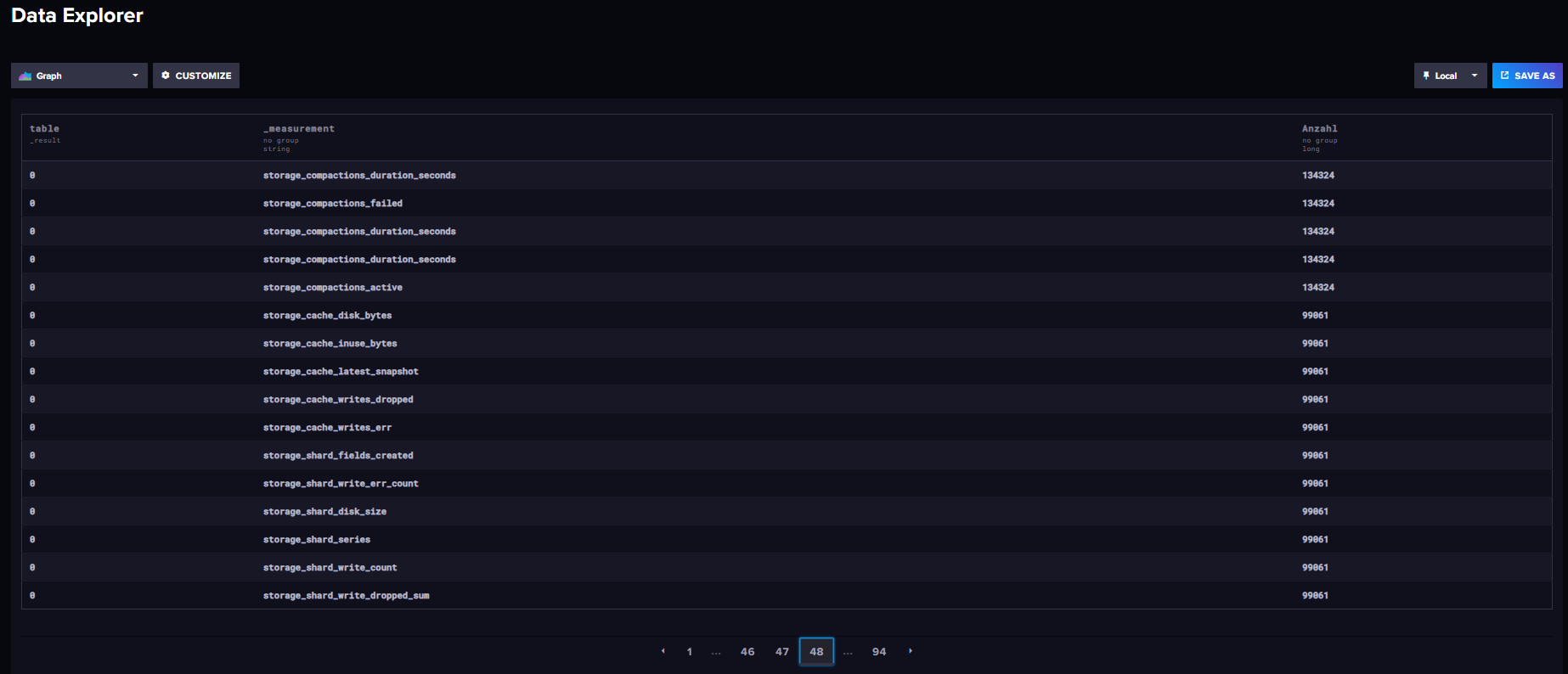
from(bucket: "iobroker") |> range(start: 0,stop: 100y) |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})Das sieht schon verdächtiger aus. Ab Seite 48 wird es erst 5-stellig. Habe aber nicht alles einzeln nachgeschaut, sind auch andere influx-Sachen dabei.
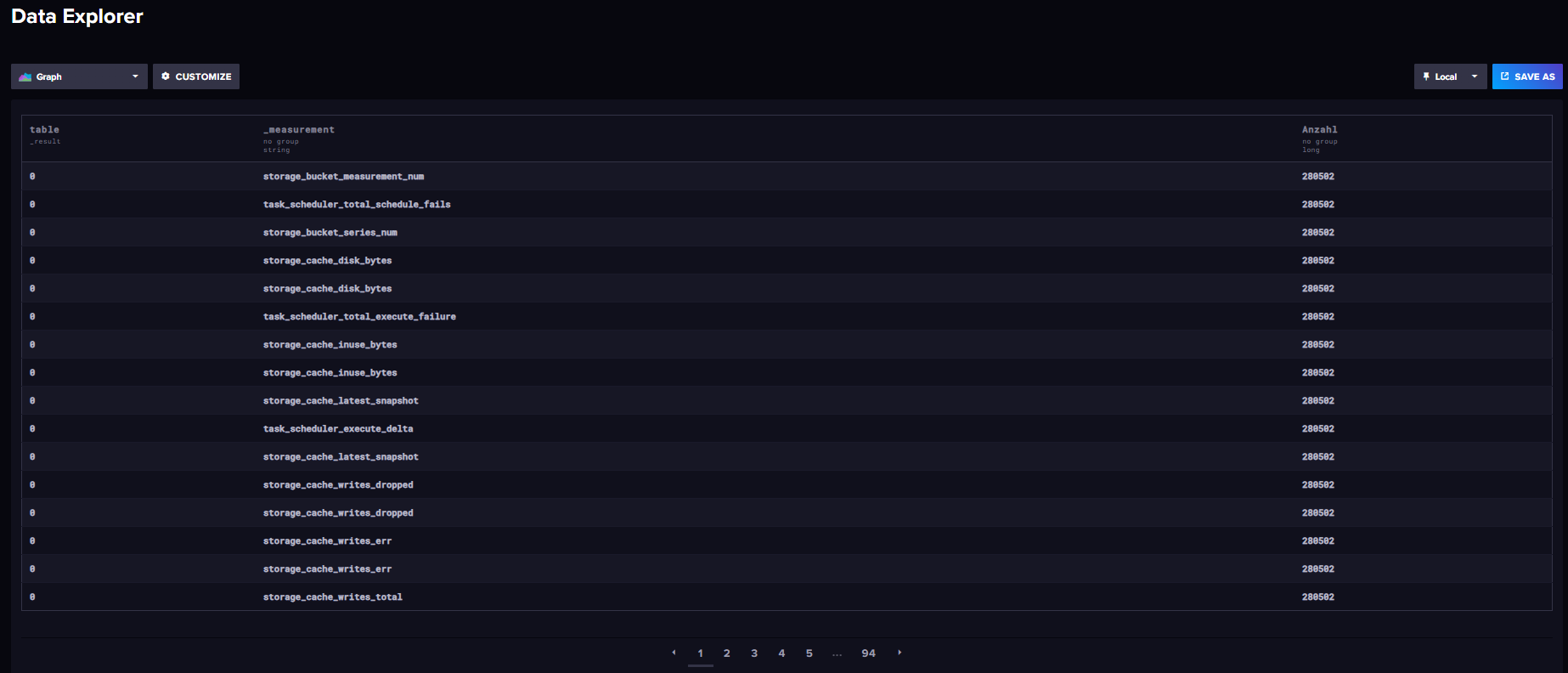
Auch failed Einträge...
PS: Nein, ich habe nur iobroker als Bucket angelegt.
-
@marc-berg said in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
from(bucket: "iobroker") |> range(start: 0,stop: 100y) |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})Das sieht schon verdächtiger aus. Ab Seite 48 wird es erst 5-stellig. Habe aber nicht alles einzeln nachgeschaut, sind auch andere influx-Sachen dabei.
Auch failed Einträge...
PS: Nein, ich habe nur iobroker als Bucket angelegt.
@sleepwalker
Jo, dann hast du wohl einen Scraper aktiviert, der dir die Monitoring-Daten ins Bucket schreibt
-
@sleepwalker
Jo, dann hast du wohl einen Scraper aktiviert, der dir die Monitoring-Daten ins Bucket schreibt@marc-berg
Ja, da ist irgendwas. Aber was und wofür genau ist das, und kann das weg?

-
@marc-berg
Ja, da ist irgendwas. Aber was und wofür genau ist das, und kann das weg?
@sleepwalker sagte in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
Aber was und wofür genau ist das, und kann das weg?
Das legt sich nicht von selbst an, und ja, das kann weg. Damit verschwinden aber die schon geschriebenen Daten nicht. Wenn die restlichen Daten nicht so wichtig sind, das ganze Bucket löschen und neu anlegen (lassen).
-
@sleepwalker sagte in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
Aber was und wofür genau ist das, und kann das weg?
Das legt sich nicht von selbst an, und ja, das kann weg. Damit verschwinden aber die schon geschriebenen Daten nicht. Wenn die restlichen Daten nicht so wichtig sind, das ganze Bucket löschen und neu anlegen (lassen).
@marc-berg Cool, danke dir. Ich weiß nicht, woher der/die/das Scraper kam. Wenn die sich nicht selbst erstellen, war ich es wohl aus Versehen. Kann mich jedenfalls nicht mehr dran erinnern.
Ich erstelle den Bucket neu, danke nochmal!
PS: Dankeschöns nachgetragen!
-
@sleepwalker sagte in Speicherplatzbelegung influxdb2 (nach Containerisierung?):
Aber was und wofür genau ist das, und kann das weg?
Das legt sich nicht von selbst an, und ja, das kann weg. Damit verschwinden aber die schon geschriebenen Daten nicht. Wenn die restlichen Daten nicht so wichtig sind, das ganze Bucket löschen und neu anlegen (lassen).
@marc-berg
Moin, als kurzer Nachtrag: Jetzt läuft alles wieder ohne Probleme. Herzlichen Dank nochmal.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
251
Online33.0k
Benutzer83.5k
Themen1.3m
Beiträge