

influxdb2 - Downsampling per Tasks
-
@marc-berg sagte in influxdb2 - Downsampling per Tasks:
ergibt leider gar keinen Sinn.
das ist vielleicht mein Verständnisproblem !
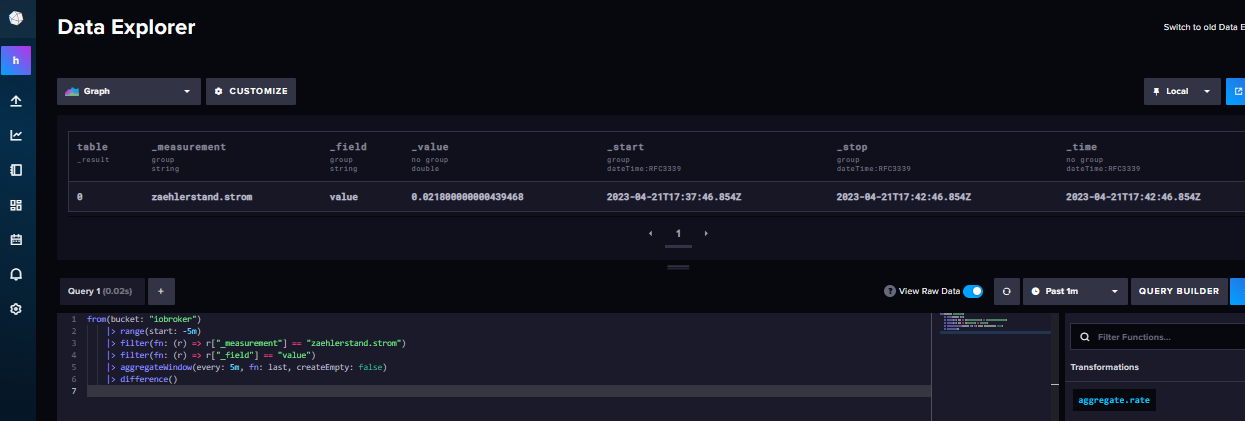
Wenn ich diese Abfrage ausführe ergibt das ein zumindest ein Ergebnis. Ob richtig sei mal dahingestellt :-)
@agrippinenser
Dann ist mir irgendwie unklar, was du erreichen willst. Willst du die Zählerstände im Ergebnis haben oder die Verbräuche?NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
@agrippinenser sagte in influxdb2 - Downsampling per Tasks:
aber ich finde im Bucket test5m keinen Eintrag.
.. noch zur Ergänzung > so versuche ich zu finden!
from(bucket: "test5m") |> range(start: 1970-01-01T00:00:00Z, stop: now()) |> filter(fn: (r) => r["_measurement"] == "zaehlerstand.strom") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false) |> yield(name: "last")Moin,
vielleicht als Denkanstoß,
import "timezone" option task = {name: "Downsampling Vb_Stromzaehler", cron: "15 0 * * *"} option location = timezone.location(name: "Europe/Berlin") data = from(bucket: "iobroker_strom") |> range(start: -2mo, stop: now()) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh") |> filter(fn: (r) => r["_field"] == "value") // Spalten "_start", "_stop", "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_time") // In Wh ohne Komma |> toInt() |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "iobroker_strom")VG
Bernd -
@agrippinenser
Dann ist mir irgendwie unklar, was du erreichen willst. Willst du die Zählerstände im Ergebnis haben oder die Verbräuche?@marc-berg sagte in influxdb2 - Downsampling per Tasks:
dann ist mir irgendwie unklar, was du erreichen willst.
hätte ich auch vorher sagen sollen. Ich wollte downsampling üben.
Zu Testzwecken werden alle paar Sekunden Zählerstände des Stromzählers in Bucket "zaehlerstand.strom" geschrieben.
Nun sollte das Range zwischen(Anfang und Ende) der letzten 5 Minuten ermittelt werden und ins Bucket "test5m" wegeschieben werden.Grüße vom Rhein @Colonia Claudia Ara Agrippinensium
-
@agrippinenser
Dann ist mir irgendwie unklar, was du erreichen willst. Willst du die Zählerstände im Ergebnis haben oder die Verbräuche?vielleicht noch .. es geht mir weniger um das richte Ergebnis sodern das überhaupt etwas geschrieben wird.
@marc-berg sagte in influxdb2 - Downsampling per Tasks:
ergibt leider gar keinen Sinn.
könntest du eine Abfrage zum errechnen der Differenz zwischen min und max innerhalb des Zeitraumes vorschlagen?
-
@marc-berg sagte in influxdb2 - Downsampling per Tasks:
dann ist mir irgendwie unklar, was du erreichen willst.
hätte ich auch vorher sagen sollen. Ich wollte downsampling üben.
Zu Testzwecken werden alle paar Sekunden Zählerstände des Stromzählers in Bucket "zaehlerstand.strom" geschrieben.
Nun sollte das Range zwischen(Anfang und Ende) der letzten 5 Minuten ermittelt werden und ins Bucket "test5m" wegeschieben werden.@agrippinenser sagte in influxdb2 - Downsampling per Tasks:
Nun sollte das Range zwischen(Anfang und Ende) der letzten 5 Minuten ermittelt werden und ins Bucket "test5m" wegeschieben werden.
okay, das ginge z.B. so:
from(bucket: "iobroker") |> range(start:-5m) |> filter(fn: (r) => r["_measurement"] == "zaehlerstand.strom") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every:5m,fn:sum,createEmpty:false)Damit ermitteltst du im ersten Schritt alle Differenzen zwischen allen Einzelwerten im Zeitraum und bildest danach die Summe aller Differenzen. Damit ist eigentlich dein Ziel erreicht, trotzdem würde ich es so nicht machen, da dir ggf. die Differenzen zwischen den Zeitfenstern verloren gehen können.
Stattdessen würde ich nicht die Verbräuche "downsamplen", sondern z.B. den jeweils letzten Zählerstand des Tages wegschreiben. Aus diesen Tageswerten kannst du dann dynamisch Verbräuche errechnen. Das(?) Ziel, Speicherplatz zu sparen ist aber erreicht. Das Beispiel von Bernd macht glaube ich, genau das.
NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
@marc-berg @dp20eic
Vielen Dank euch ... dass muss ich erst mal verarbeiten ..
-
@marc-berg @dp20eic
Vielen Dank euch ... dass muss ich erst mal verarbeiten ..
@agrippinenser ich hab da auch noch ein Beispiel, wie ich von den Tagestemperaturen Min und Max pro Tag in ein anderes Bucket schreibe.
import "timezone" option location = timezone.location(name: "Europe/Berlin") option task = {name: "Downsampling Temperatur_Ost", cron: "10 0 * * *"} data = from(bucket: "ioBroker") // Für Cron: "10 0 * * *" = 0:10 Uhr |> range(start: date.truncate(t: -2d, unit: 1d), stop: today()) |> filter(fn: (r) => r["_measurement"] == "Ost_Temperatur") |> filter(fn: (r) => r["from"] == "system.adapter.hm-rpc.0") // Spalten "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) min_temp = data |> aggregateWindow(every: 1d, fn: min, createEmpty: false, timeSrc: "_start") |> set(key: "_field", value: "min") max_temp = data |> aggregateWindow(every: 1d, fn: max, createEmpty: false, timeSrc: "_start") |> set(key: "_field", value: "max") data union(tables: [min_temp, max_temp]) |> set(key: "_measurement", value: "Ost_Balkon") |> to(bucket: "Temperaturen", org: "RBE")Anzeigen aus dem anderen Bucket mit:
import "timezone" // import wegen der Berechnung um 02:00:00 option location = timezone.location(name: "Europe/Berlin") from(bucket: "Temperaturen") |> range(start: -1y, stop: now()) |> filter(fn: (r) => r["_measurement"] == "Ost_Balkon") |> filter(fn: (r) => r["_field"] == "max" or r["_field"] == "min") |> yield(name: "Ost")Viel Spaß beim durchforsten.
DS720|Nuc8i3BEH|Proxmox|RaspberryMatic|ioBroker|influxDB2|Grafana
-
@agrippinenser sagte in influxdb2 - Downsampling per Tasks:
Nun sollte das Range zwischen(Anfang und Ende) der letzten 5 Minuten ermittelt werden und ins Bucket "test5m" wegeschieben werden.
okay, das ginge z.B. so:
from(bucket: "iobroker") |> range(start:-5m) |> filter(fn: (r) => r["_measurement"] == "zaehlerstand.strom") |> filter(fn: (r) => r["_field"] == "value") |> difference() |> aggregateWindow(every:5m,fn:sum,createEmpty:false)Damit ermitteltst du im ersten Schritt alle Differenzen zwischen allen Einzelwerten im Zeitraum und bildest danach die Summe aller Differenzen. Damit ist eigentlich dein Ziel erreicht, trotzdem würde ich es so nicht machen, da dir ggf. die Differenzen zwischen den Zeitfenstern verloren gehen können.
Stattdessen würde ich nicht die Verbräuche "downsamplen", sondern z.B. den jeweils letzten Zählerstand des Tages wegschreiben. Aus diesen Tageswerten kannst du dann dynamisch Verbräuche errechnen. Das(?) Ziel, Speicherplatz zu sparen ist aber erreicht. Das Beispiel von Bernd macht glaube ich, genau das.
@marc-berg sagte in influxdb2 - Downsampling per Tasks:
Stattdessen würde ich nicht die Verbräuche "downsamplen", sondern z.B. den jeweils letzten Zählerstand des Tages wegschreiben.
Dank eurer Hilfe bin ich einen riesen Schritt weiter gekommen. Daten werden richtig aggregiert per Task geschrieben und ich finde sie auch wieder.

Den letzten Zählerstand niederschreiben macht Sinn! Das bringt mich allerdings zu grundlegender selbstkritischer Idee:
"Warum protokolliere ich den Zählerstand vor Tageswechsel nicht mittels Skript in einen Datenpunkt und mache stattdessen solche Umwege?".. wo wir gerade dabei sind, habe dieses gestern im Netz gefunden, weis leider nicht mehr wo.
Hier wird min / max / range ausgegeben. Vielleicht kann es jemand brauchen.from(bucket: "iobroker") // |> range(start: 1970-01-01T00:00:00Z, stop: now()) // |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> range(start:-24d) |> filter(fn: (r) => r["_measurement"] == "zaehlerstand.strom") |> filter(fn: (r) => r["_field"] == "value") |> reduce(fn: (r, accumulator) => ({ min: if r._value < accumulator.min then r._value else accumulator.min, max: if r._value > accumulator.max then r._value else accumulator.max }), identity: {min: 10000000000.0, max: -10000000000.0}) |> map(fn: (r) => ({ r with range: (r.max - r.min)*1.0 })) |> yield(name: "Range/[kWh]")vielen Dank !
LG -
@agrippinenser ich hab da auch noch ein Beispiel, wie ich von den Tagestemperaturen Min und Max pro Tag in ein anderes Bucket schreibe.
import "timezone" option location = timezone.location(name: "Europe/Berlin") option task = {name: "Downsampling Temperatur_Ost", cron: "10 0 * * *"} data = from(bucket: "ioBroker") // Für Cron: "10 0 * * *" = 0:10 Uhr |> range(start: date.truncate(t: -2d, unit: 1d), stop: today()) |> filter(fn: (r) => r["_measurement"] == "Ost_Temperatur") |> filter(fn: (r) => r["from"] == "system.adapter.hm-rpc.0") // Spalten "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) min_temp = data |> aggregateWindow(every: 1d, fn: min, createEmpty: false, timeSrc: "_start") |> set(key: "_field", value: "min") max_temp = data |> aggregateWindow(every: 1d, fn: max, createEmpty: false, timeSrc: "_start") |> set(key: "_field", value: "max") data union(tables: [min_temp, max_temp]) |> set(key: "_measurement", value: "Ost_Balkon") |> to(bucket: "Temperaturen", org: "RBE")Anzeigen aus dem anderen Bucket mit:
import "timezone" // import wegen der Berechnung um 02:00:00 option location = timezone.location(name: "Europe/Berlin") from(bucket: "Temperaturen") |> range(start: -1y, stop: now()) |> filter(fn: (r) => r["_measurement"] == "Ost_Balkon") |> filter(fn: (r) => r["_field"] == "max" or r["_field"] == "min") |> yield(name: "Ost")Viel Spaß beim durchforsten.
vielen Dank dafür. Ich nutze das nun etwas abgeändert für abfragen von min max Aktienkurse.
ich muss zugeben das ich den Umstieg von V1.8 auf 2.x unterschätz habe. Aber so langsam geht's voran

import "date" import "timezone" option location = timezone.location(name: "Europe/Berlin") data = from(bucket: "iobroker") |> range(start: date.truncate(t: -1d, unit: 1d), stop: today()) |> filter(fn: (r) => r["_measurement"] == "Aktien_WKN_XXXXXX") |> filter(fn: (r) => r["_field"] == "value") |> drop(columns: ["ack", "q", "from"]) minkurs = data |> aggregateWindow(every: 1d, fn: min, createEmpty: false, timeSrc: "_start") |> set(key: "_field", value: "min") maxkurs = data |> aggregateWindow(every: 1d, fn: max, createEmpty: false, timeSrc: "_start") |> set(key: "_field", value: "max") data union(tables: [minkurs, maxkurs]) |> set(key: "_measurement", value: "min_max_Kurse") |> to(bucket: "Tageskurse", org: "home") -
vielen Dank dafür. Ich nutze das nun etwas abgeändert für abfragen von min max Aktienkurse.
ich muss zugeben das ich den Umstieg von V1.8 auf 2.x unterschätz habe. Aber so langsam geht's voran
import "date" import "timezone" option location = timezone.location(name: "Europe/Berlin") data = from(bucket: "iobroker") |> range(start: date.truncate(t: -1d, unit: 1d), stop: today()) |> filter(fn: (r) => r["_measurement"] == "Aktien_WKN_XXXXXX") |> filter(fn: (r) => r["_field"] == "value") |> drop(columns: ["ack", "q", "from"]) minkurs = data |> aggregateWindow(every: 1d, fn: min, createEmpty: false, timeSrc: "_start") |> set(key: "_field", value: "min") maxkurs = data |> aggregateWindow(every: 1d, fn: max, createEmpty: false, timeSrc: "_start") |> set(key: "_field", value: "max") data union(tables: [minkurs, maxkurs]) |> set(key: "_measurement", value: "min_max_Kurse") |> to(bucket: "Tageskurse", org: "home")@agrippinenser
@SpacerX
kann mir mal bitte jemand erklären warum ich keinen task speichern kann der button ist ausgegraut.Danke
-
@agrippinenser
@SpacerX
kann mir mal bitte jemand erklären warum ich keinen task speichern kann der button ist ausgegraut.Danke
@babl sagte in influxdb2 - Downsampling per Tasks:
@agrippinenser
@SpacerX
kann mir mal bitte jemand erklären warum ich keinen task speichern kann der button ist ausgegraut.Danke
Moin,
kannst Du zeigen, was Du gemacht hast, denn meine Glaskugel ist zur Politur.
VG
Bernd -
@babl sagte in influxdb2 - Downsampling per Tasks:
@agrippinenser
@SpacerX
kann mir mal bitte jemand erklären warum ich keinen task speichern kann der button ist ausgegraut.Danke
Moin,
kannst Du zeigen, was Du gemacht hast, denn meine Glaskugel ist zur Politur.
VG
Bernd@dp20eic ich habe das task script von oben genommen, habe es in einen task eingegeben und nach meinen datenpunkten angepasst und dann wollte ich das speichern um es zu testen, wenn ich auf den button save klicke ändert sich der mauszeiger in ein durchfahrtsverbot und das wars.
Habe es jetzt aber anders gelöst, im data explorer die datenpunkte ausgewählt die ich aggregieren will und dann save as "task" angeklickt, hier wird der task gespeichert, so nun bin ich mal am testen daß ich hier vernünftige lösungen hinbekomme um auch die datenbank nicht zu groß werden zu lassen und doch vernünftig daten auf längere sicht zu haben.
-
@agrippinenser
@SpacerX
kann mir mal bitte jemand erklären warum ich keinen task speichern kann der button ist ausgegraut.Danke
@babl sagte in influxdb2 - Downsampling per Tasks:
kann mir mal bitte jemand erklären warum ich keinen task speichern kann der button ist ausgegraut.
"Save" wird nur aktiv, wenn mindestens "Name" und "Every/Cron" ausgefüllt wurde.
NUC10I3+Ubuntu+Docker+ioBroker+influxDB2+Node Red+EMQX+Grafana
Pi-hole, Traefik, Checkmk, Conbee II+Zigbee2MQTT, ESPSomfy-RTS, LoRaWAN
Benutzt das Voting im Beitrag, wenn er euch geholfen hat.
-
@babl sagte in influxdb2 - Downsampling per Tasks:
kann mir mal bitte jemand erklären warum ich keinen task speichern kann der button ist ausgegraut.
"Save" wird nur aktiv, wenn mindestens "Name" und "Every/Cron" ausgefüllt wurde.
@marc-berg hei!
..und falls es ein CRON Job werden soll dann konfiguriere ich dort UTC, also für 23:59 Uhr
59 21 * * *
Zumindest habe ich das nach gefühlt 73 Versuchen für mich festgestellt.
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
598
Online32.9k
Benutzer83.2k
Themen1.3m
Beiträge