Verfügbarkeit von Sensoren über Node Red überwachen
-
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
Das alleine funktioniert aber nicht, sondern ich muss diesen Payload erst splitten und dann wieder joinen. -> Warum? Was für einen Unterschied macht es den Kontext zu übergeben vs. Kontext splitten dann wieder joinen und dann übergeben?
Nun das ist einfach die Methode einzelne Objekte zu verändern - in der klassischen Programmierung würdest Du es über eine Schleife machen, die auch jedes einzelne Objekt anfasst. Du kannst auch function Nodes schreiben indem Du über Objekte oder Arrays iterierst. Das Ausplitten und joinen ist also dafür nötig, um letztlich ein Array von Objekten zu erzeugen, dass die table Node benötigt.
Um das zu verhindern wäre meine Idee nach dem Abspeichern ein JOIN zu machen und eine Sekunde zu warten. Dann geht es (hoffentlich) nur 1 mal weiter statt 18 mal.
Bei Arrays bleibt Dir sowieso nur die Zeit übrig - ich es ehrlich gesagt in Deinem Fall so machen würde, dass ich im Prinzip diese ganze Zeitstempel nach der letzten JOIN Node des ursprünglichen Flows einbauen würde. Da dann bereits die Anzahl der Elemente im Array unverändert bleibt, würde ich das Array aufsplitten und automatisch wieder zusammensetzen lassen. Dann würde ich nur für jede einzelne Nachricht die Zeitdifferenz berechnen lassen und in das Objekt mit aufzunehmen. Im Prinzip also von dem zentralen Flow Abschied nehmen. Über das initiale Einlesen hast Du ja alle Timestamps in Deiner Flow variable. Ich würde also einen anderen Ansatz nehmen.
-
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
Mal was ganz anderes:
Ich spiele grade mit den Link in/out/call Nodes rum.
Wofür ist denn die Link Call Node gut? Die hat leider keinerlei Eintrag im HandbuchJa die wäre für Dich geeignet. Ist - wie eine Art Unterprogramm aufzurufen. Wie gesagt fang mal an mit der ersten Initialisierung in Deinem Flow Kontext die Zeitstempel der Geräte mit den Topics als Objekteigenschaften zu sammeln . Die Zeitdifferenzen berechnest Du dann nach einem split hinter der letzten JOIN Node für jedes einzelne Objekt.
Bei der CALL Node musst Du nur unbedingt darauf achten, dass die auf jeden Fall wieder zu aufrufenden Node zurück kehrt.
Du machst also eine Call Node hinter die split Node und kannst dann über eine Link-In Node die Zeitdifferenzen berechnen .- die link-out Node musst dann so konfigurieren, dass diese wieder an die aufrufende Node zurückkehrt.
Hier wieder das Video von meinem amerikansichen NodeRed Guru: https://www.youtube.com/watch?v=qryeuduhsoo
-
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
Das alleine funktioniert aber nicht, sondern ich muss diesen Payload erst splitten und dann wieder joinen. -> Warum? Was für einen Unterschied macht es den Kontext zu übergeben vs. Kontext splitten dann wieder joinen und dann übergeben?
Nun das ist einfach die Methode einzelne Objekte zu verändern - in der klassischen Programmierung würdest Du es über eine Schleife machen, die auch jedes einzelne Objekt anfasst. Du kannst auch function Nodes schreiben indem Du über Objekte oder Arrays iterierst. Das Ausplitten und joinen ist also dafür nötig, um letztlich ein Array von Objekten zu erzeugen, dass die table Node benötigt.
Wow, ich schäme mich gerade echt überhaupt die Frage gestellt zu haben.
In der Node ist doch klar ersichtlich dass er ein Array erstellt und nicht wieder einen einzigen Payload... I'm sorry
Die Function Node baut die Tabelle dann für jeden Eintrag im Array, also jede Zeile.
Ganz ehrlich, dass mir jetzt erst klar wird bzw ich realisiere wie das was ich da mache funktioniert (oder wieder?) bringt mich grade echt so ein bisschen an den Rand der Verzweiflung...
Wirklich, ganz herzlichen Dank dass du dich trotzdem mit mir außeinandersetzt!Um das zu verhindern wäre meine Idee nach dem Abspeichern ein JOIN zu machen und eine Sekunde zu warten. Dann geht es (hoffentlich) nur 1 mal weiter statt 18 mal.
Bei Arrays bleibt Dir sowieso nur die Zeit übrig - ich es ehrlich gesagt in Deinem Fall so machen würde, dass ich im Prinzip diese ganze Zeitstempel nach der letzten JOIN Node des ursprünglichen Flows einbauen würde. Da dann bereits die Anzahl der Elemente im Array unverändert bleibt, würde ich das Array aufsplitten und automatisch wieder zusammensetzen lassen. Dann würde ich nur für jede einzelne Nachricht die Zeitdifferenz berechnen lassen und in das Objekt mit aufzunehmen. Im Prinzip also von dem zentralen Flow Abschied nehmen. Über das initiale Einlesen hast Du ja alle Timestamps in Deiner Flow variable. Ich würde also einen anderen Ansatz nehmen.
Guter Ansatz, ich werde das versuchen so umzusetzen wenn ich das mit den Link Nodes verstanden und umgesetzt habe um aufzuräumen
")
-
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
Mal was ganz anderes:
Ich spiele grade mit den Link in/out/call Nodes rum.
Wofür ist denn die Link Call Node gut? Die hat leider keinerlei Eintrag im HandbuchJa die wäre für Dich geeignet. Ist - wie eine Art Unterprogramm aufzurufen. Wie gesagt fang mal an mit der ersten Initialisierung in Deinem Flow Kontext die Zeitstempel der Geräte mit den Topics als Objekteigenschaften zu sammeln . Die Zeitdifferenzen berechnest Du dann nach einem split hinter der letzten JOIN Node für jedes einzelne Objekt.
Bei der CALL Node musst Du nur unbedingt darauf achten, dass die auf jeden Fall wieder zu aufrufenden Node zurück kehrt.
Du machst also eine Call Node hinter die split Node und kannst dann über eine Link-In Node die Zeitdifferenzen berechnen .- die link-out Node musst dann so konfigurieren, dass diese wieder an die aufrufende Node zurückkehrt.
Hier wieder das Video von meinem amerikansichen NodeRed Guru: https://www.youtube.com/watch?v=qryeuduhsoo
Danke dir für den Link und den Input!
Die Funktion der Nodes ist absolut selbsterklärend, keine Ahnung warum ich mit "return to calling node" nicht gecheckt habe dass damit literally die "Link Call" Node gemeint ist.
Entweder ich bin wirklich so stupide, oder ich sollte aufhören mich erst nach Mitternacht mit NR zu beschäftigen..ich geh mich gleich vergraben^^ -
Ich habe noch rundimentäre Teile unserer Nodes gefunden - aber ich werde Deinen Flow nicht mehr importieren - da ich auch den Zigbee Adapter nicht mehr verwende.
Also wie gesagt, wenn Du bei der Initialisierung die Timestamps in einem Flow Objekt gespeichert hast, dann kannst Du eine link call Node verwenden, aber eigentlich rentiert es sich nicht weil wahrscheinlich eine einfache Change Node ausreichnen würde:
-
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
Mal was ganz anderes:
Ich spiele grade mit den Link in/out/call Nodes rum.
Wofür ist denn die Link Call Node gut? Die hat leider keinerlei Eintrag im HandbuchJa die wäre für Dich geeignet. Ist - wie eine Art Unterprogramm aufzurufen. Wie gesagt fang mal an mit der ersten Initialisierung in Deinem Flow Kontext die Zeitstempel der Geräte mit den Topics als Objekteigenschaften zu sammeln . Die Zeitdifferenzen berechnest Du dann nach einem split hinter der letzten JOIN Node für jedes einzelne Objekt.
Bei der CALL Node musst Du nur unbedingt darauf achten, dass die auf jeden Fall wieder zu aufrufenden Node zurück kehrt.
Du machst also eine Call Node hinter die split Node und kannst dann über eine Link-In Node die Zeitdifferenzen berechnen .- die link-out Node musst dann so konfigurieren, dass diese wieder an die aufrufende Node zurückkehrt.
Hier wieder das Video von meinem amerikansichen NodeRed Guru: https://www.youtube.com/watch?v=qryeuduhsoo
Danke dir für den Link und den Input!
Die Funktion der Nodes ist absolut selbsterklärend, keine Ahnung warum ich mit "return to calling node" nicht gecheckt habe dass damit literally die "Link Call" Node gemeint ist.
Entweder ich bin wirklich so stupide, oder ich sollte aufhören mich erst nach Mitternacht mit NR zu beschäftigen..ich geh mich gleich vergraben^^Na so hart wäre ich jetzt an Deiner Stelle auch nicht mit Dir selbst. Ich habe mir das auch erst nochmal mit dem Video klar gemacht, falls es Dich beruhigt. Auch wenn es im Nachhinein logisch ist, hat man halt trotzdem erst mal ein Brett vor dem Kopf.
Ich glaube Du kommst mit einer Change Node evtl. aus.
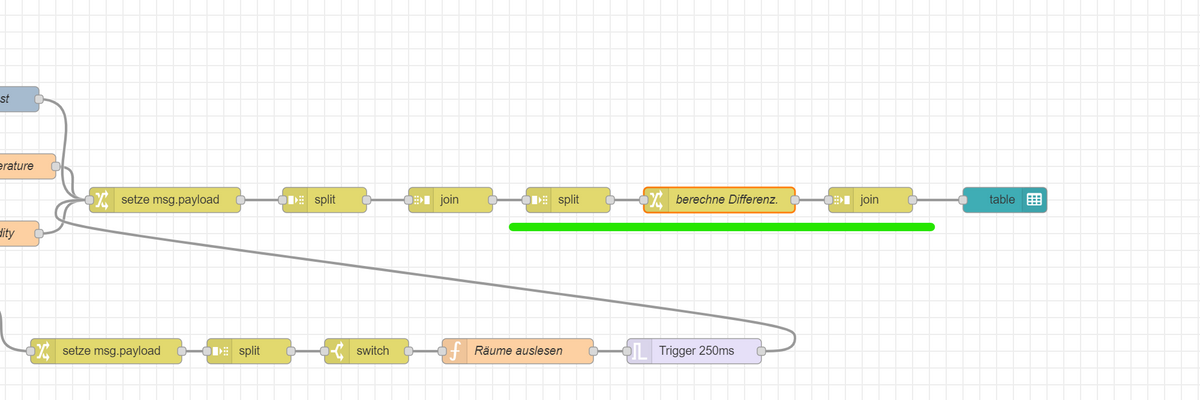
Und in diesem Fall kannst du die JOIN Node das Array auch wieder automatisch zusammensetzen lassen.
Kannst Du denn aus den Arrays noch das ursprünlgiche topic ermitteln oder ist das enthalten, sonst müsstest Du es ggf aufnehmen.
Wie ich gerade sehe - wurde das ja alles in flow.sensors gespeichert - also da müsste halt das topic enthalten sein.
Die berechne Differenz Change Node würde dann ausreichen - Du musst halt das topic in den Array Objekten mitschleifen, auch wenn es nicht in der Tabelle angezeigt würde und dann halt einer weiteren Eigenschaft zuordnen.
Dann kannst Du es mittels Change Node einfach so aus der Kontextvariablen auslesen:
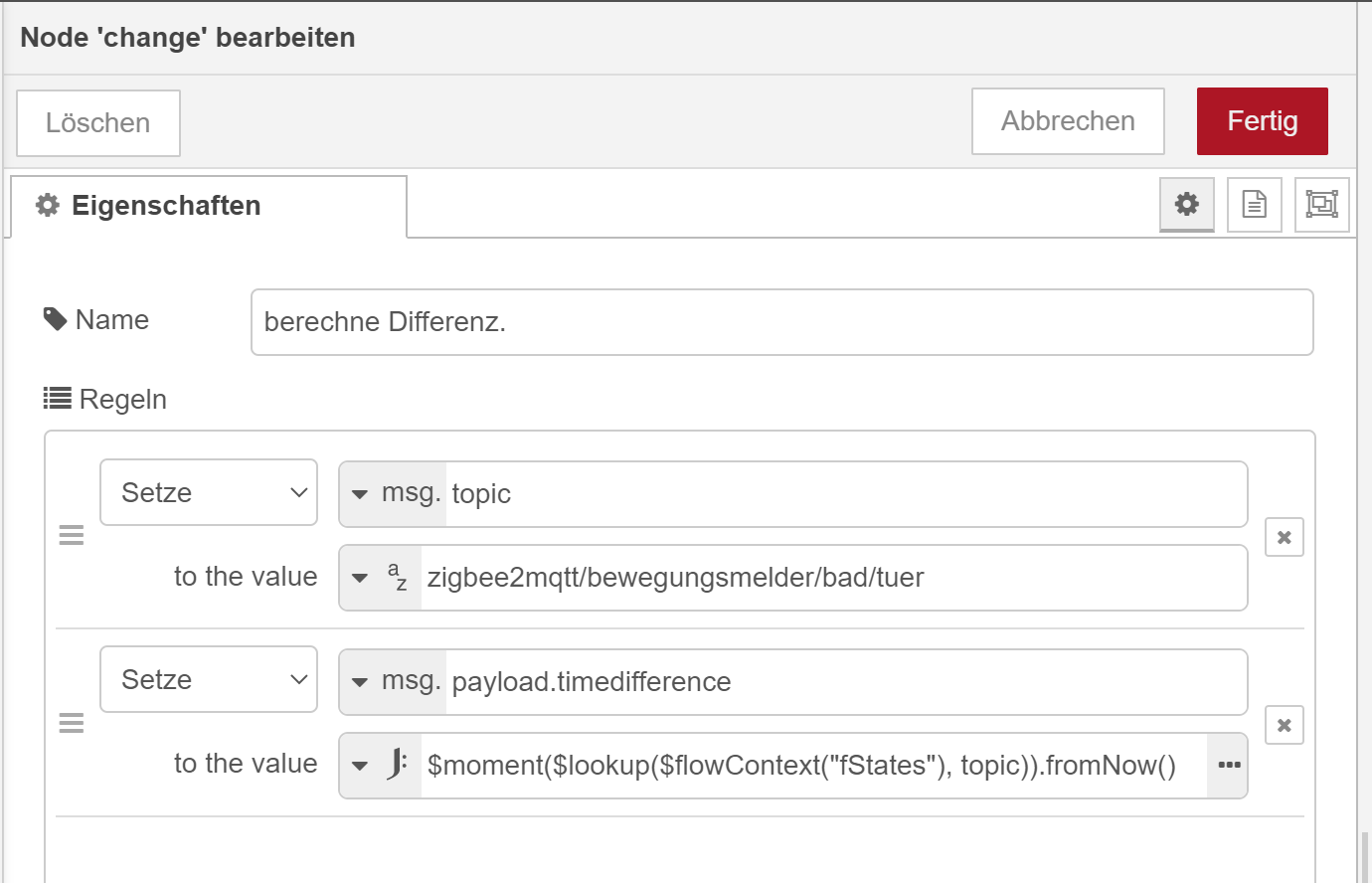
-
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
Mal was ganz anderes:
Ich spiele grade mit den Link in/out/call Nodes rum.
Wofür ist denn die Link Call Node gut? Die hat leider keinerlei Eintrag im HandbuchJa die wäre für Dich geeignet. Ist - wie eine Art Unterprogramm aufzurufen. Wie gesagt fang mal an mit der ersten Initialisierung in Deinem Flow Kontext die Zeitstempel der Geräte mit den Topics als Objekteigenschaften zu sammeln . Die Zeitdifferenzen berechnest Du dann nach einem split hinter der letzten JOIN Node für jedes einzelne Objekt.
Bei der CALL Node musst Du nur unbedingt darauf achten, dass die auf jeden Fall wieder zu aufrufenden Node zurück kehrt.
Du machst also eine Call Node hinter die split Node und kannst dann über eine Link-In Node die Zeitdifferenzen berechnen .- die link-out Node musst dann so konfigurieren, dass diese wieder an die aufrufende Node zurückkehrt.
Hier wieder das Video von meinem amerikansichen NodeRed Guru: https://www.youtube.com/watch?v=qryeuduhsoo
Danke dir für den Link und den Input!
Die Funktion der Nodes ist absolut selbsterklärend, keine Ahnung warum ich mit "return to calling node" nicht gecheckt habe dass damit literally die "Link Call" Node gemeint ist.
Entweder ich bin wirklich so stupide, oder ich sollte aufhören mich erst nach Mitternacht mit NR zu beschäftigen..ich geh mich gleich vergraben^^Na so hart wäre ich jetzt an Deiner Stelle auch nicht mit Dir selbst. Ich habe mir das auch erst nochmal mit dem Video klar gemacht, falls es Dich beruhigt. Auch wenn es im Nachhinein logisch ist, hat man halt trotzdem erst mal ein Brett vor dem Kopf.
Ich glaube Du kommst mit einer Change Node evtl. aus.
Und in diesem Fall kannst du die JOIN Node das Array auch wieder automatisch zusammensetzen lassen.
Kannst Du denn aus den Arrays noch das ursprünlgiche topic ermitteln oder ist das enthalten, sonst müsstest Du es ggf aufnehmen.
Wie ich gerade sehe - wurde das ja alles in flow.sensors gespeichert - also da müsste halt das topic enthalten sein.
Die berechne Differenz Change Node würde dann ausreichen - Du musst halt das topic in den Array Objekten mitschleifen, auch wenn es nicht in der Tabelle angezeigt würde und dann halt einer weiteren Eigenschaft zuordnen.
Dann kannst Du es mittels Change Node einfach so aus der Kontextvariablen auslesen:
Merci!
Das mit der Change Node hatte ich anfangs probiert, aber wenn ich versuche über die Change Node einen neuen Payload zu "erstellen" (also zb. msg.payload.timedifference) hat der bei mir gemeckert dass das nicht existiert. Aber vermutlich habe ich da dann was anderes falsch gemacht.
Ich mach mal eben das mit den Call Nodes fertig und versuche das mit der Change Node dann nochmal anders zu machen -
@schmetterfliege Das muss nicht existieren - Du musst nur schauen, dass die payload bereits ein Objekt ist - wenn es ein skalarer Wert ist, meckert er, dass die payload kein Objekt ist.
-
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege Das muss nicht existieren - Du musst nur schauen, dass die payload bereits ein Objekt ist - wenn es ein skalarer Wert ist, meckert er, dass die payload kein Objekt ist.
Was ist denn ein "skalarer Wert"?

-
@schmetterfliege Ein Sting, eine Zahl oder ein Boolean - also alles was nicht in irgendwelchen Klammern steht.
")

-
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege Ein Sting, eine Zahl oder ein Boolean - also alles was nicht in irgendwelchen Klammern steht.
Verstehe ich irgendwie trotzdem nicht^^
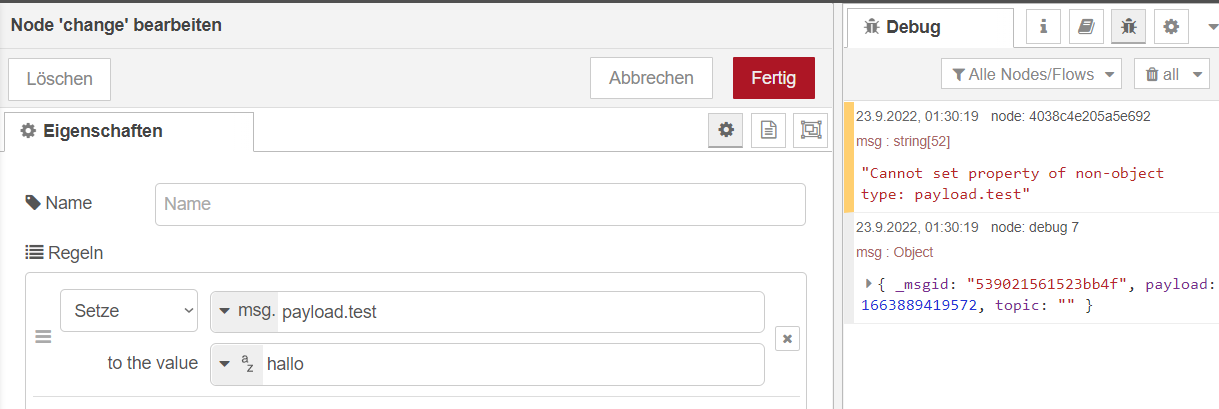
Ich trigger einfach nur die Change Node um "payload.test" zu erstellen und den Text auszugeben. Der meckert dann aber dass das ein non-object ist.
Wie mache ich das denn zum Object? -
@schmetterfliege Ja weil die payload kein Objekt ist. Wenn gar nichts drin ist oder war - sagt er Dir er kann kein Wert für ein skalaren Wert oder in node red Sprache auf einen non-Object Type setzen. Wenn Du aber vorher die payload auf ein leeres Objekt setzt - dann funktioniert das.
So würde es gehen.
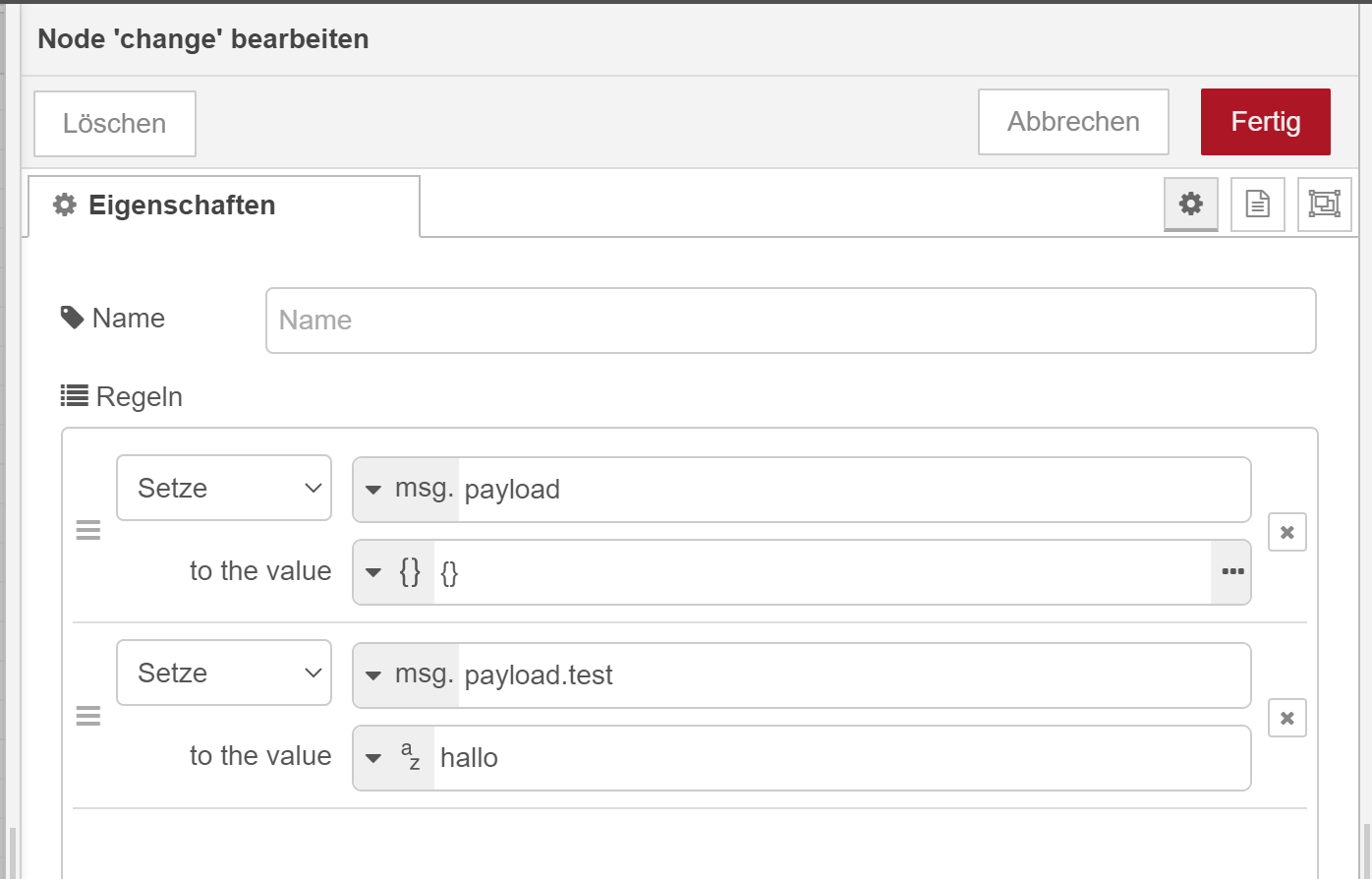
-
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege Ja weil die payload kein Objekt ist. Wenn gar nichts drin ist oder war - sagt er Dir er kann kein Wert für ein skalaren Wert oder in node red Sprache auf einen non-Object Type setzen. Wenn Du aber vorher die payload auf ein leeres Objekt setzt - dann funktioniert das.
So würde es gehen.
aaaah, jetzt gerafft. Danke!
Ich arbeite sowohl mit dem Payload als Objekt, als auch als non-object, indem ich einfach zb. msg.temperature, msg.timestamp usw nutze.
Gibts irgendein Grund weshalb es besser wäre alles in ein Payload Objekt zu packen, statt wie ich einzelne...keine Ahnung wie man das nennt?... zu machen? -
@schmetterfliege Man kann auch die payload direkt also Objekt mit der Eigenschaft test zu definieren:
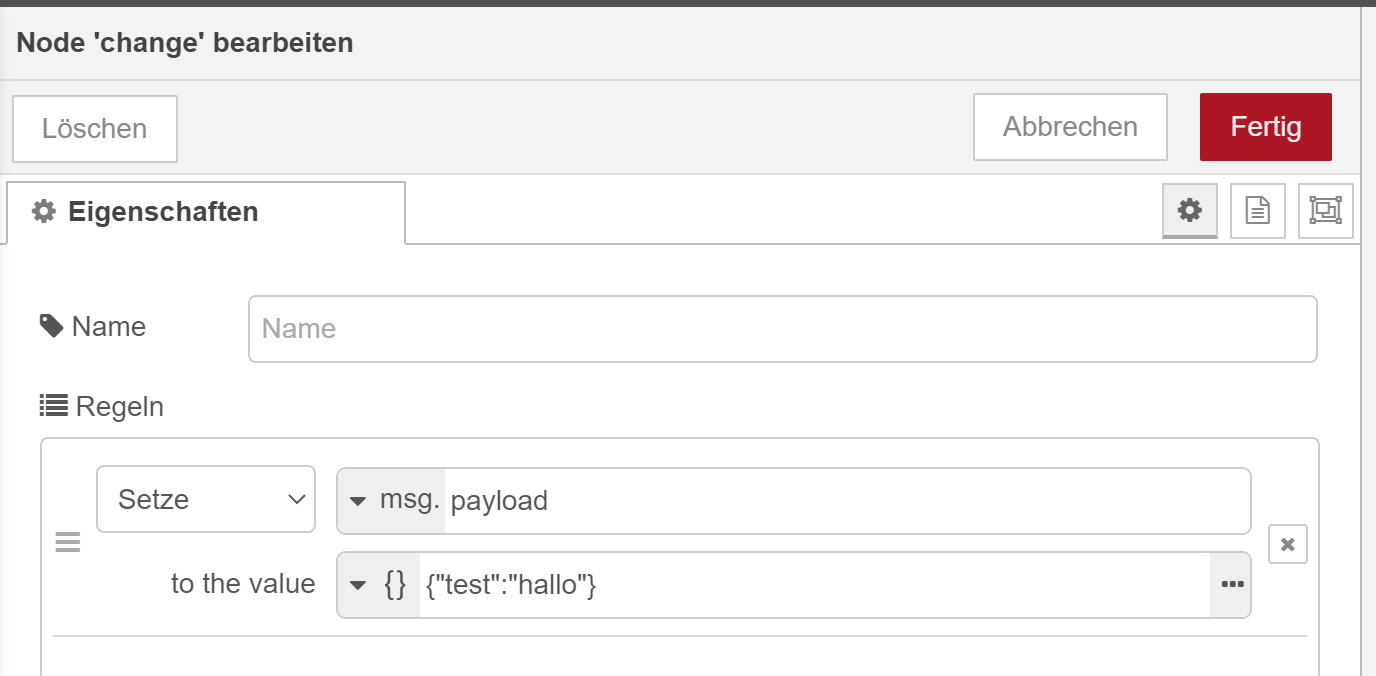
Gibts irgendein Grund weshalb es besser wäre alles in ein Payload Objekt zu packen, statt wie ich einzelne...keine Ahnung wie man das nennt?... zu machen?
Kann man nicht allgemein sagen.
msg.temperature, msg.timestamp sind ja auch nur Eigenschaften des Objektes msg. - Wenn Du Dir mal das komplette Nachrichtenobjekt anschaust. Die msg.payload ist genauso eine Eigenschaft, wie msg.topic oder msg.temperature - alles Eigenschaften des msg Objektes. Jede Eigenschaft eines Objektes kann wiederum ein Objekt sein usw.Manche Nodes zum Beispiel die iobroker- get Node kann zum Beispiel die Werte nicht Eigenschaften einer payload zuweisen. Andere Nodes oder transport zu anderen Systemen gehen nur über eine payload bzw. über einen JSON String. Man bildet also ein payload als Objekt - die eine JSON Node dann in einen String verwandelt und so kannst Du dann ein ganzes Objekt zum Beispiel in einen iobroker Datenpunkt schreiben.
Wenn Du den visuellen Editor eines Objektes benutzt, dann kannst Du ja sehen, dass Du sowohl skalare wie auch nicht skalare Datentypen den Eigenschaften eines Objektes zuweisen kannst.
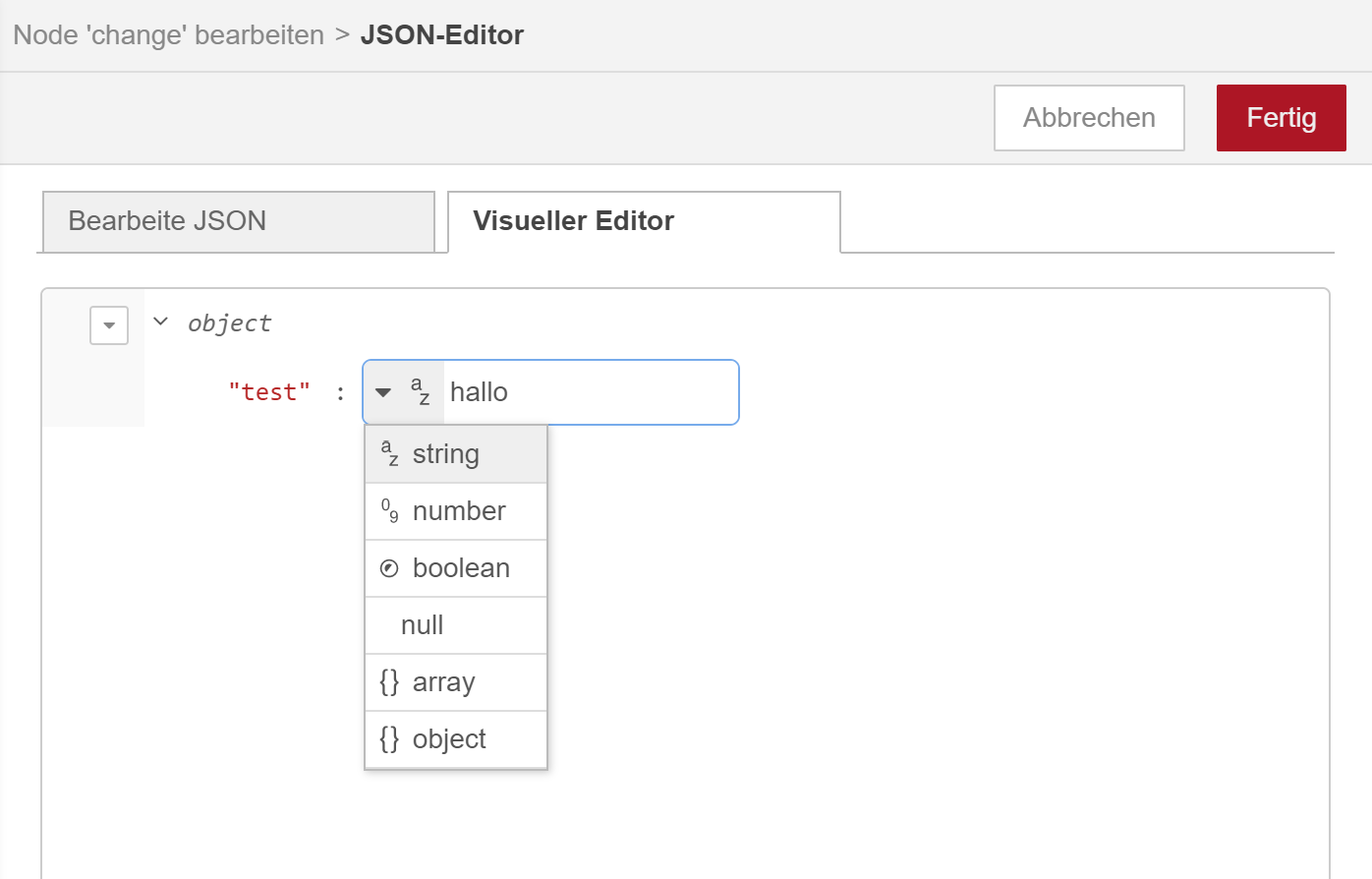
-
Ich bin gerade etwas überfordert mit den Link Nodes...
I know, du möchtest eigentlich nicht meinen Flow komplett analysieren. Also falls dir das zu doof ist - kein Thema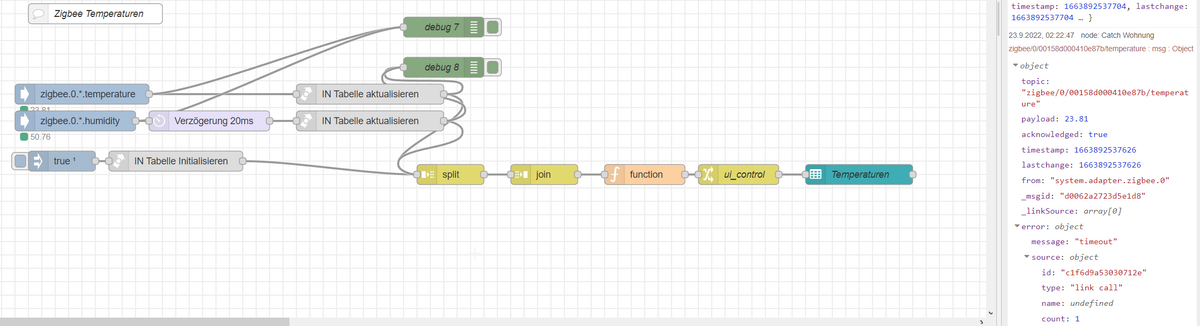
Long Story short:
die beiden IOB IN Nodes triggern den gleichen Flow. Beide triggern "gleichzeitig" weil die Sensoren immer beide Werte gleichzeitig liefern.
Eine der beiden Call Nodes landet aber immer im Timeout.
In dem Flow in den das ganze rein geht habe ich eine Trigger Node die 500ms wartet.
Ist das das Problem?
Die Werte kommen zwar gleichzeitig, werden aber nacheinander abgearbeitet - logisch.
Wert1 triggert den Flow und damit den 500ms Trigger.
Wert2 möchte den Flow auch triggern, geht aber nicht weil dieser noch beschäftigt ist (500ms Trigger) und wird deshalb verworfen.
-> Call Node landet im Timeout weil sie niemals eine Rückmeldung bekommt.
Ist meine Vermutung richtig?Ich hab bisher nur mit Subflows gearbeitet, und da hat ja jeder "run" seine eigene Instanz - ich kann einen Subflow also gleichzeitig mehrfach triggern. Gilt das für das im Bild oben nicht?
-
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
die beiden IOB IN Nodes triggern den gleichen Flow. Beide triggern "gleichzeitig" weil die Sensoren immer beide Werte gleichzeitig liefern.
Eine der beiden Call Nodes landet aber immer im Timeout.Dann machs halt nicht - langt doch wenn Du in einen Zweig - ich seh auch keinen Wert das überhaupt aus dem Flow rauszunehmen. Wenn der timeout kommt, dann liegt es nur daran, dass Du nicht alles zurück gibst. Da braucht es keine Verzögerung.
Schau Dir mal den Flow - an - der läuft auch parallel ab:
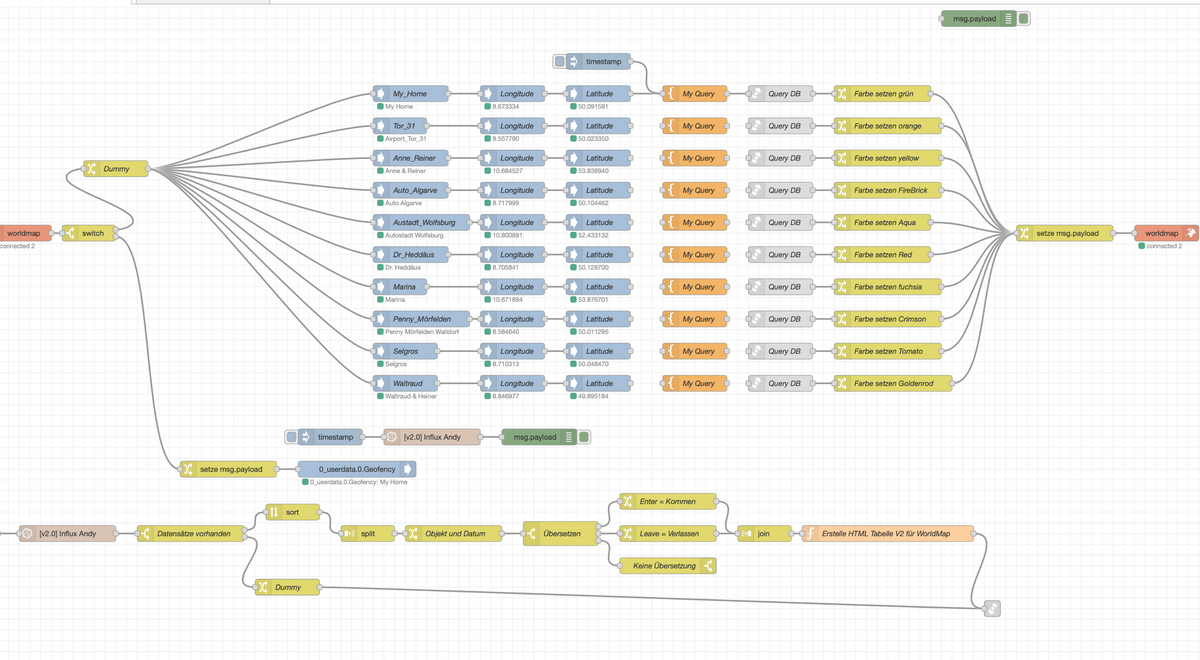
Wie gesagt ich bin der Meinung ist - dass Du keine call Nodes brauchst und Timeout gibts nur, wenn der Flow das ursprüngliche Nachrichtenobjekt nicht wieder zurück gibt. Es geht - aber momentan hast Du doch andere Sorgen, als Dich hier um call Nodes zu kümmern. Im prinzip musst Du doch nur den Zeitstempel speichern und die topic mit ins Objekt aufnehmen.
-
@schmetterfliege Ausserdem am Anfang müssen die timestamps parallel zum Hauptflow machen - da diese nicht Bestandteil der Tabellenobjekte sein müssen.
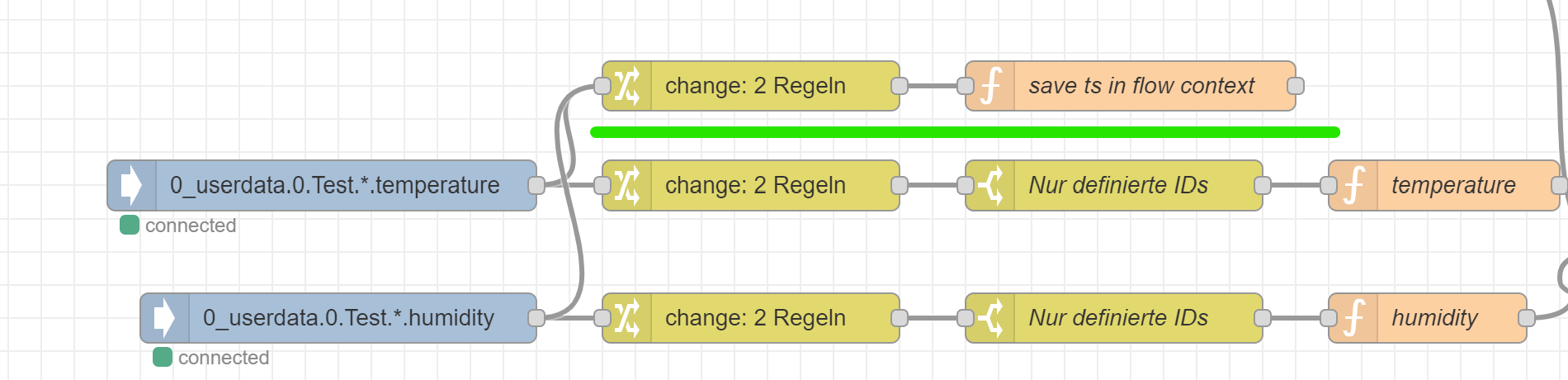
Bei der Erstinitialisierung mit den Räumen kann ich im Moment nicht mmehr nachvollziehen, wie wir die Initialisierung gemacht haben.
-
@schmetterfliege Damit Du siehst das es kein Timing Problem an sich mit den call Nodes gibt - hier ein kleines Beispiel:
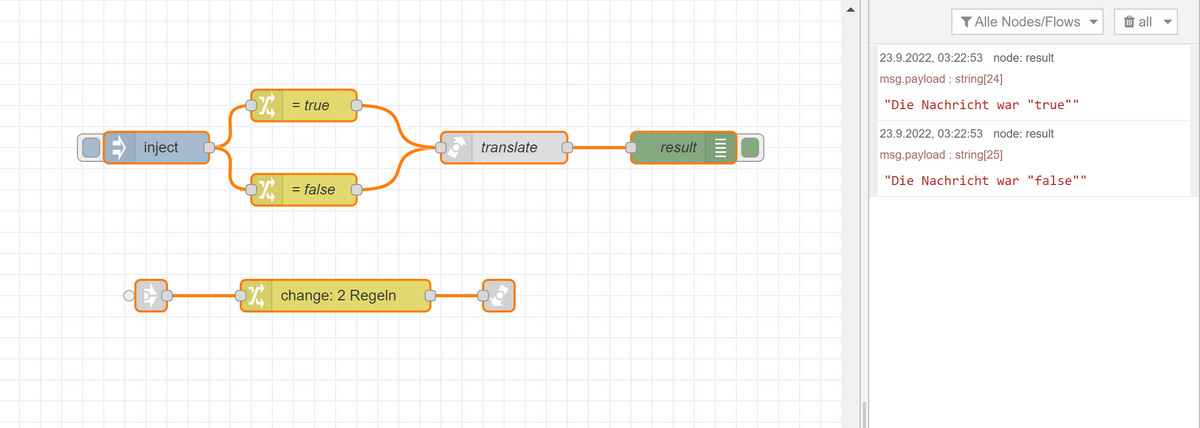
Auch das geht ohne Probleme
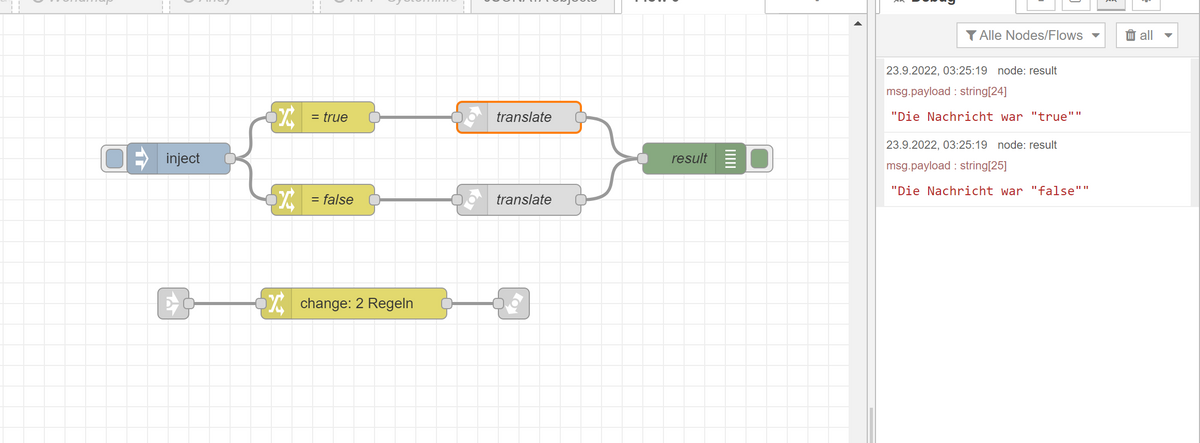
Wie gesagt - Du musst halt aufpassen das Du die Originalnachricht behälst - wenn Du es nur in einer Flowvariablen speicherst ohne zurückzugeben, dann hast du das Problem. Bei der call Nodes gibst Identifikationsmerkmale die prüfen, ob die Originalnachricht wieder zurückgegeben wird - ansonsten gibts den timeout.
-
@mickym said in Verfügbarkeit von Sensoren über Node Red überwachen:
@schmetterfliege sagte in Verfügbarkeit von Sensoren über Node Red überwachen:
die beiden IOB IN Nodes triggern den gleichen Flow. Beide triggern "gleichzeitig" weil die Sensoren immer beide Werte gleichzeitig liefern.
Eine der beiden Call Nodes landet aber immer im Timeout.Dann machs halt nicht - langt doch wenn Du in einen Zweig - ich seh auch keinen Wert das überhaupt aus dem Flow rauszunehmen. Wenn der timeout kommt, dann liegt es nur daran, dass Du nicht alles zurück gibst. Da braucht es keine Verzögerung.
Schau Dir mal den Flow - an - der läuft auch parallel ab:
Wie gesagt ich bin der Meinung ist - dass Du keine call Nodes brauchst und Timeout gibts nur, wenn der Flow das ursprüngliche Nachrichtenobjekt nicht wieder zurück gibt. Es geht - aber momentan hast Du doch andere Sorgen, als Dich hier um call Nodes zu kümmern. Im prinzip musst Du doch nur den Zeitstempel speichern und die topic mit ins Objekt aufnehmen.
Ich glaube ich bin gerade an einem ganz anderen Punkt als du^^
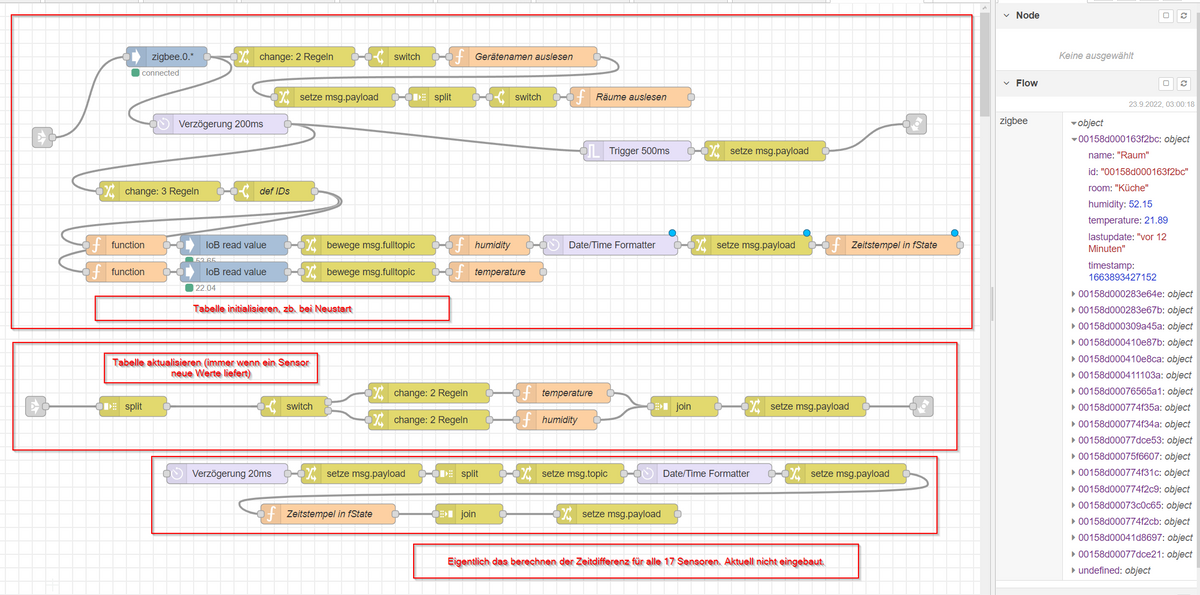
Ich habe alles was mit den Flowvariablen zu tun hat in einen gesonderten Flow gepackt, weil entweder alles oder gar nichts - ich beziehe mich ja permanent auf die Kontextdaten. Dementsprechend muss alles in einem Flow passieren.
Das Initialisieren funktioniert Problemlos. Die Berechnung der Zeitdiff mache ich dort auch.
Zuerst werden alle Zigbee-Adapter Daten aus IOB geholt, gecheckt ob "Multisensor" im Gerätename ist und der Name sowie der Raum abgespeichert.
Nach 200ms werden dann die Daten für die einzelnen Sensoren (haben ja vorher die Topics rausgesucht) aus IOB geholt und für jedes Gerät abgespeichert.
Die Zeitdiff mache ich dann da wo die Humidity gesetzt wird für jedes Gerät einzeln.
Nach der Initialisierung hat jedes Gerät alle Daten abgespeichert, die ich möchte.
Das funktioniert wie gesagt problemlos.Das Problem ist das Aktualisieren der Tabelle.
Weil da ja dann nur für 1 Gerät ein Update kommt, ich die Zeitdifferenz aber für alle Sensoren neu berechnen möchte.
Also muss ich mir aus den Kontextvariablen alle Timestamps holen und für jedes Gerät die Differenz neu berechnen.
Variablen in Payload packen -> Splitten -> für jeden Payload die Topic anpassen -> Zeit formatieren weil fromNow() nicht mit Unix timestamps klappt -> Differenz abspeichern.
Und weil es 17 Sensoren sind muss ich da irgendwas einbauen das verhindert dass es 17 Rückmeldungen gibt.
Und das pausiert den Flow, auch wenn es nur ganz kurz ist.
Wenn der Teil im unteren roten Kasten nicht in Verwendung ist bekomme ich keinen Timeout.
Also muss da ja irgendwas dafür sorgen dass es keine zweite Rückmeldung gibt... -
@schmetterfliege Wie gesagt - das hat damit nichts zu tun und nein Du musst die nicht in die payload packen. Mach mal den unteren Teil wie er vorher war. Also schmeiss mal das weg was Du im letzten Kästchen eingefügt hast. Meines Erachtens wurde da vorher nur das zigbee Objekt geladen und in ein Array von Objekten überführt . Mach das nochmal.
So war das bei mir:
Was Du mit den letzten beiden Nodes machst (function und ui_control ) - weiß ich gerade nicht - aber das sollte nochmal der Ausgangspunkt werden:
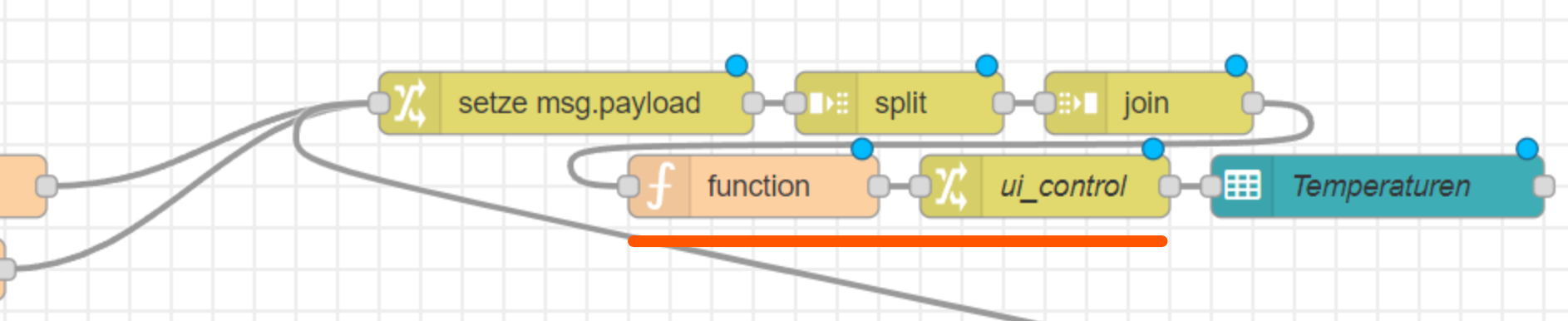
Dann würde ich in der fState variable das Datum nach id speichern und nicht nach topic - also 1.Kästchen.
Das Zeitstempel aktualisieren ist das was ich gesagt haben - da langt ein Teil um die fState Variable mit der entspechenden ID zu aktualisieren.
