

Test Adapter ioBroker.n8n

-
Hi, vielleicht könnt Ihr mir helfen, ich habe leider weiterhin Probleme bei der Installation.
Ich habe den Adapter heute nach einigen Vorsuchen in der letzten Zeit wieder deinstalliert und (über das GUI) neu installiert. Wir hier weiter oben bereits beschrieben lauft es ungewöhnlich schnell durch und danach kommen bald Fehlermeldungen.
Unter Hosts bekomme ich die Meldung "Restart loop detected"
und mehrfach: "Exception-Code: ENOENT: ENOENT: no such file or directory, open '/opt/iobroker/iobroker-data/n8n-engine/node_modules/n8n-editor-ui/dist/index.html'"Auf der Commandline schaut das dann so aus:
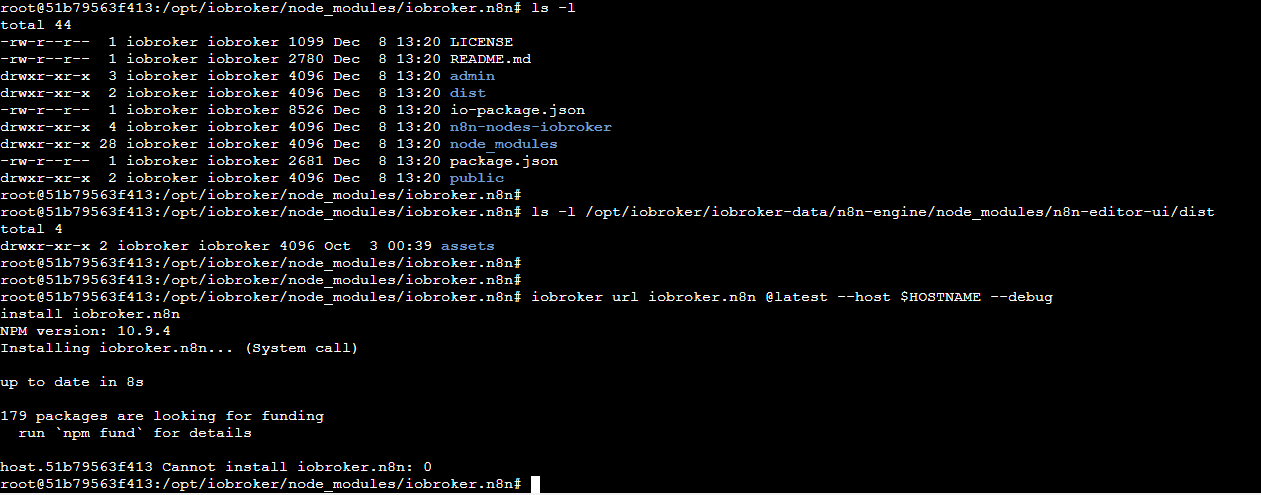
Das Verzeichnis /opt/iobroker/iobroker-data/n8n-engine/node_modules/n8n-editor-ui/dist ist also vom Oktober, wo ich das wohl zum ersten Mal (auch über das GUI) versucht habe, und der versuchten Installation über "iobroker url iobroker.n8n @latest --host $HOSTNAME --debug" komme ich scheinbar auch nicht weiter.
index.html fehlt also tatsächlich, was sonst noch dort sein sollte, weiß ich auch nicht.Ich muss noch dazusagen, dass ich den aktuellsten IOBroker mit https unter Docker mit einer "macvlan" IP-Adresse fahre (was wiederum bedeuten sollte, dass ich das Port 5678 in dem Fall nicht gesondert behandeln muss).
Hat jemand von Euch einen Tipp?
Danke und liebe Grüße!
Falls sich mal jemand mit der selben Frage hier her verirrt: Die Lösung war dann recht einfach - nach der Deinstallation vom n8n-Adapter mussten noch zusätzlich auf der Commandline nach n8n-Resten gesucht und diese einfach gelöscht werden. Danach hat eine Neu-Installation problemlos funktioniert.
-
Hallo in die Runde,
Eine Frage, vielleicht fällt Euch was dazu ein:
Ich habe den Aufbau des (sehr tollen!) Videos (Danke!!) nachgestellt und es funktioniert teilweise gut!
Aber bei bestimmten Geräten bekomme ich immer Müll als Antwort.
In dieser Grafik sieht man beim Befehl "Schalte die Lampe in der Küche ein" die (fast richtige) Antwort "Esstischlampe" mit der (entsprechenden) Shelly-ID
Meldung in Telegram: Esstisch auf true gesetzt...
Die Frage nach der Fernsehlampe findet diese zwar, erfindet aber eine ID "hm-rpc.1.0023A95A88E2A2.1.STATE" - sagt das jemandem was - ich finde diese ID nicht in den JSON Daten in IOBroker-Read.
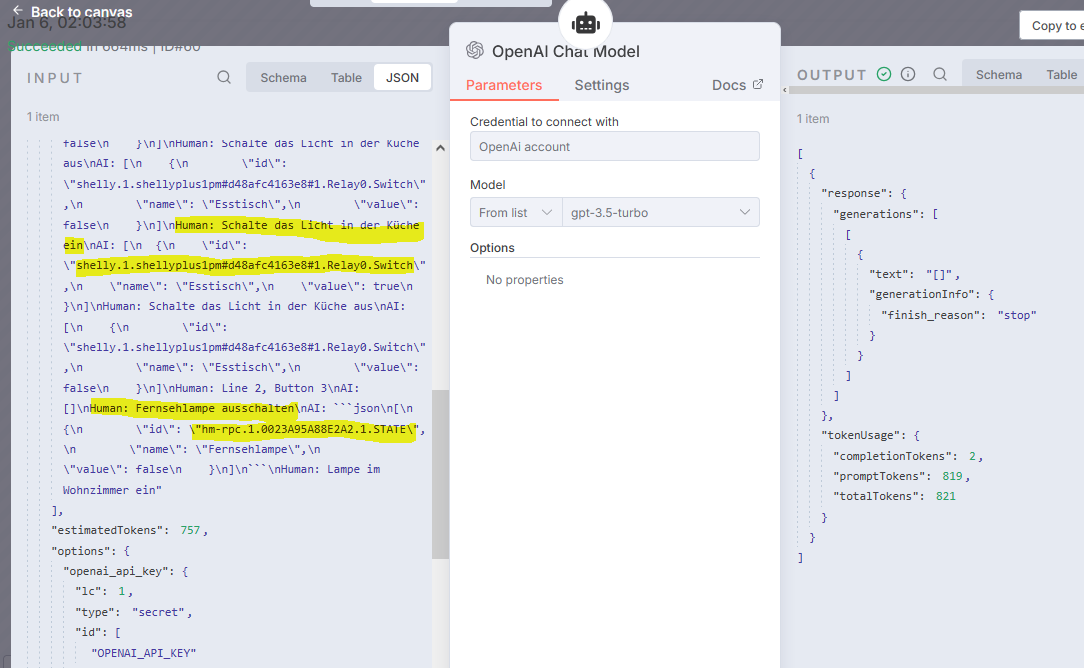
Auch die Bitte die "Esstischlampe" oder "Esstisch" einzuschalten liedert eine solche hm-rpc-ID und es funktioniert nicht, es geht nur mit "Lampe in der Küche"
Während ich diese Nachricht schreibe, hat sich mit dem gleichen Befehl "Schalte die Lampe in der Küche ein" eine andere Lampe (eigentlich nun wirklich die richtige) eingeschalten - es heißt ja, man bekommt bei KI immer wieder mal was anderes :)
In Telegram: shelly-dimmer-kueche auf true gesetzt...
-
Hallo in die Runde,
Eine Frage, vielleicht fällt Euch was dazu ein:
Ich habe den Aufbau des (sehr tollen!) Videos (Danke!!) nachgestellt und es funktioniert teilweise gut!
Aber bei bestimmten Geräten bekomme ich immer Müll als Antwort.
In dieser Grafik sieht man beim Befehl "Schalte die Lampe in der Küche ein" die (fast richtige) Antwort "Esstischlampe" mit der (entsprechenden) Shelly-ID
Meldung in Telegram: Esstisch auf true gesetzt...
Die Frage nach der Fernsehlampe findet diese zwar, erfindet aber eine ID "hm-rpc.1.0023A95A88E2A2.1.STATE" - sagt das jemandem was - ich finde diese ID nicht in den JSON Daten in IOBroker-Read.
Auch die Bitte die "Esstischlampe" oder "Esstisch" einzuschalten liedert eine solche hm-rpc-ID und es funktioniert nicht, es geht nur mit "Lampe in der Küche"
Während ich diese Nachricht schreibe, hat sich mit dem gleichen Befehl "Schalte die Lampe in der Küche ein" eine andere Lampe (eigentlich nun wirklich die richtige) eingeschalten - es heißt ja, man bekommt bei KI immer wieder mal was anderes :)
In Telegram: shelly-dimmer-kueche auf true gesetzt...
Wenn die KI solche ID erfindet, dann hat sie zu wenig Input.
Hast du denn ihr genügend Informationen gegeben, dass sie deine menschlichen Anweisungen auf irgendwelche Geräte mappen kann?
Eventuell musst du auch den Prompt noch verbessern, so dass die ki dort auch nachschaut -
Hallo Oliver,
Ich habe eine Testprogramm gebaut, dass mit dem selben Systemprompt arbeitet und auch das orignal JSON aus dem n8n "IOBroker-Reader Devices" übernommen.
Damit komme ich zu folgenden Ergebnissen:Frage: Esstischlampe einschalten 6.1.2026, 01:56:07
Antwort:[ { "id": "shelly.1.shellyplus1pm#d48afc4163e8#1.Relay0.Switch", "name": "Esstisch", "value": true } ]Tokens: 8927/574 · Kosten: 0.0038 $ · Session: a9763548-0100-4360-b892-e110096daf20 · OpenAI/gpt-5-nanoFrage: Wohnzimmerlampe 50% 6.1.2026, 14:41:23
Antwort:[ { "id": "shelly.0.SHDM-2#C8C9A325A9BB#1.lights.brightness", "name": "Wohnzimmerlampe", "value": 50 } ]Tokens: 8997/1024 · Kosten: 0.0040 $ · Session: a9763548-0100-4360-b892-e110096daf20 · OpenAI/gpt-5-nanoFrage: Fernsehlampe ein, rot, 30% 6.1.2026, 14:42:28
Antwort:[ { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.Switch", "name": "Fernsehlampe", "value": true }, { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.brightness", "name": "Fernsehlampe", "value": 30 }, { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.hue", "name": "Fernsehlampe", "value": 0 }, { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.saturation", "name": "Fernsehlampe", "value": 100 } ]Tokens: 9073/1421 · Kosten: 0.0042 $ · Session: a9763548-0100-4360-b892-e110096daf20 · OpenAI/gpt-5-miniFrage: Fernsehlampe ein, weiß, 100% 6.1.2026, 14:43:57
Antwort:[ { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.Switch", "name": "Fernsehlampe", "value": true }, { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.white", "name": "Fernsehlampe", "value": 100 } ]Tokens: 9141/104 · Kosten: 0.0000 $ · Session: a9763548-0100-4360-b892-e110096daf20 · OpenAI-older/gpt-3.5-turboSchaut für mich alles perfekt aus. Wie Du siehst, habe ich auch die Modelle durchgewechselt, wobei gpt-3.5-turbo eigentlich am Ende eh am Besten abgeschnitten hat.
gpt-5-nano sollte wesentlich "billiger" sein, war aber auch um 2-3 Sekunden langsamer und daher für diesen Einsatzzweck nicht wirklich brauchbar.Ich habe alle Modelle natürlich auch wechselweise in n8n/IObroker versucht!
Leider bleibt dort bisher als einziger Zufallstreffer "Schalte die Lampe in der Küche ein" erfolgreich, bei allen anderen Versuchen kommen immer wieder diese RFC-IDs daher, aber vor allem sehe ich auch, dass nicht nur die IDs falsch sind sondern auch die Geräte entsprechend "falsch" gefunden werden.
A. hat jemand eine Idee woher diese RPC-IDs kommen könnten (kommt das irgendwo im IOBroker vor?)
B. wie kann ich sicherstellen, dass n8n-GPT auch wirklich mit der "richtigen" JSON arbeitet (obwohl ich die Daten für meine Tests ja eh aus dem Adapter kopiert hab und sie für mich richtig erscheinen!)[offtopic:] Eine für mich wichtige Erkenntniss bei meinen Versuchen:
Zuerst habe ich versucht, einfach alles in einen Prompt zu stecken. Den Systemprompt, die Frage und das JSON.Bei gpt-3.5-turbo kommt es dann in meinem Testprogramm zu einem Fehler:
OpenAI HTTP 400: { "error": { "message": "This model's maximum context length is 16385 tokens. However, your messages resulted in 20559 tokens. Please reduce the length of the messages.", "type": "invalid_request_error", "param": "message...Mit gpt-5-nano ging das dann...
Frage: Schalte das Licht in der Küche ein
Antwort:
[ { "id": "shelly.1.shellydimmerg3#e4b063ec4c10#1.Light0.Switch", "name": "shelly-dimmer-kueche", "value": true } ]Tokens: 20982/1283 · Kosten: 0.0089 $ · Session: 9f7027df-8649-4a90-a4ac-26f03a017bc4 · OpenAI/gpt-5-nanoErst als ich mein Programm so umgebaut habe, dass ich gesondert System-Prompt und Roles schicken kann, wie es wohl auch der n8n-Adapter macht, hat es überhaupt mit gpt-3.5-turbo geklappt.
Wie man oben sieht, schaut es mit den Tokens ganz anders aus, wenn man den System-Prompt wirklich als solchen schickt und das JSON als Datei und dann separat die Frage...
-
Hallo Oliver,
Ich habe eine Testprogramm gebaut, dass mit dem selben Systemprompt arbeitet und auch das orignal JSON aus dem n8n "IOBroker-Reader Devices" übernommen.
Damit komme ich zu folgenden Ergebnissen:Frage: Esstischlampe einschalten 6.1.2026, 01:56:07
Antwort:[ { "id": "shelly.1.shellyplus1pm#d48afc4163e8#1.Relay0.Switch", "name": "Esstisch", "value": true } ]Tokens: 8927/574 · Kosten: 0.0038 $ · Session: a9763548-0100-4360-b892-e110096daf20 · OpenAI/gpt-5-nanoFrage: Wohnzimmerlampe 50% 6.1.2026, 14:41:23
Antwort:[ { "id": "shelly.0.SHDM-2#C8C9A325A9BB#1.lights.brightness", "name": "Wohnzimmerlampe", "value": 50 } ]Tokens: 8997/1024 · Kosten: 0.0040 $ · Session: a9763548-0100-4360-b892-e110096daf20 · OpenAI/gpt-5-nanoFrage: Fernsehlampe ein, rot, 30% 6.1.2026, 14:42:28
Antwort:[ { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.Switch", "name": "Fernsehlampe", "value": true }, { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.brightness", "name": "Fernsehlampe", "value": 30 }, { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.hue", "name": "Fernsehlampe", "value": 0 }, { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.saturation", "name": "Fernsehlampe", "value": 100 } ]Tokens: 9073/1421 · Kosten: 0.0042 $ · Session: a9763548-0100-4360-b892-e110096daf20 · OpenAI/gpt-5-miniFrage: Fernsehlampe ein, weiß, 100% 6.1.2026, 14:43:57
Antwort:[ { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.Switch", "name": "Fernsehlampe", "value": true }, { "id": "shelly.0.SHCB-1#3494546B298D#1.lights.white", "name": "Fernsehlampe", "value": 100 } ]Tokens: 9141/104 · Kosten: 0.0000 $ · Session: a9763548-0100-4360-b892-e110096daf20 · OpenAI-older/gpt-3.5-turboSchaut für mich alles perfekt aus. Wie Du siehst, habe ich auch die Modelle durchgewechselt, wobei gpt-3.5-turbo eigentlich am Ende eh am Besten abgeschnitten hat.
gpt-5-nano sollte wesentlich "billiger" sein, war aber auch um 2-3 Sekunden langsamer und daher für diesen Einsatzzweck nicht wirklich brauchbar.Ich habe alle Modelle natürlich auch wechselweise in n8n/IObroker versucht!
Leider bleibt dort bisher als einziger Zufallstreffer "Schalte die Lampe in der Küche ein" erfolgreich, bei allen anderen Versuchen kommen immer wieder diese RFC-IDs daher, aber vor allem sehe ich auch, dass nicht nur die IDs falsch sind sondern auch die Geräte entsprechend "falsch" gefunden werden.
A. hat jemand eine Idee woher diese RPC-IDs kommen könnten (kommt das irgendwo im IOBroker vor?)
B. wie kann ich sicherstellen, dass n8n-GPT auch wirklich mit der "richtigen" JSON arbeitet (obwohl ich die Daten für meine Tests ja eh aus dem Adapter kopiert hab und sie für mich richtig erscheinen!)[offtopic:] Eine für mich wichtige Erkenntniss bei meinen Versuchen:
Zuerst habe ich versucht, einfach alles in einen Prompt zu stecken. Den Systemprompt, die Frage und das JSON.Bei gpt-3.5-turbo kommt es dann in meinem Testprogramm zu einem Fehler:
OpenAI HTTP 400: { "error": { "message": "This model's maximum context length is 16385 tokens. However, your messages resulted in 20559 tokens. Please reduce the length of the messages.", "type": "invalid_request_error", "param": "message...Mit gpt-5-nano ging das dann...
Frage: Schalte das Licht in der Küche ein
Antwort:
[ { "id": "shelly.1.shellydimmerg3#e4b063ec4c10#1.Light0.Switch", "name": "shelly-dimmer-kueche", "value": true } ]Tokens: 20982/1283 · Kosten: 0.0089 $ · Session: 9f7027df-8649-4a90-a4ac-26f03a017bc4 · OpenAI/gpt-5-nanoErst als ich mein Programm so umgebaut habe, dass ich gesondert System-Prompt und Roles schicken kann, wie es wohl auch der n8n-Adapter macht, hat es überhaupt mit gpt-3.5-turbo geklappt.
Wie man oben sieht, schaut es mit den Tokens ganz anders aus, wenn man den System-Prompt wirklich als solchen schickt und das JSON als Datei und dann separat die Frage...
sag mir mal noch wo ich
mit dem selben Systemprompt arbeitet und auch das orignal JSON aus dem n8n "IOBroker-Reader Devices"
finde?
Das ist evtl auch eines deiner Probleme
This model's maximum context length is 16385 tokens
Die Modelle haben alle ein unterschiedlich großes Kontextfenster.
16K ist relativ klein. hängt aber davon ab, wieviel Datenpunkte und Details du da reinpackst.
Um ein Gefühl dafür zu bekommen kann man den link ausprobieren
https://platform.openai.com/tokenizer
Der tokenizer ist aber für jedes Modell (auch bei unterschiedlichen Anbietern) anders.Hier kannst du mal schauen welche Modelle mit größeren Kontextfenster existieren und die Kostentechnisch nicht so teuer ist (openai gehört mehr zu den teueren Anbietern)
https://explodingtopics.com/blog/list-of-llms?utm_source=chatgpt.comAcuh kann man ggfs über andere Provider, die einheitlichen API Zugriff für mehrere Modelle anbieten ggfs auch Kostenvorteile erhalten.
Falls die Kontextfenster nix sagt:
Das ist der Größe des Gehirns, das einem LLM in einem Durchgang als ERinnerungsvermögen zur Verfügung steht. Alles was da nicht reinpasst, weiß die KI nicht. Wenn man im laufe eines Chatverlaufs die Grenze überschreitet fällt irgend etwas älteres heraus. Mittlerweile gibt es so Komprimierungs Strategien bei dem älteres "Wissen" komprimiert wird, so das das wichtigste erhalten bleibt, aber das ist aktuell erst am werden.
die nano modelle von openai haben zwar ein größeres Kontextfenster (1Million), allerdings ist die parametergröße eher Klein (geschätzt 7 Milliarden. das normale 5.2 Modell hat geschätzt 2-5Billionen und ist eine Größe für die Gesamtintelligenz.
Per N8N ist mehr oder weniger wirklich jedes Modell anbindbar.Eine weitere Alternative wäre noch, die iobroker Daten in eine vektoren Datenbank "hineinzutrainieren" (ist kein echtes Training). Dazu würde deine Anfrage zu einer Vorauswahl auf Basis der Vekotendaten führen, welche dann letztendlich zu Anfrage bei einem LLM führt. Bein so volatilen Daten wie die Datenpunkte und deren Inhalte bei iobroker habe ich noch keine Tests gemacht.
-
Der Systemprompt ist:
You are a Smart Home assistant for ioBroker. Always use tool to get the structure of rooms and devicses in rooms. Based on the user input below, extract all commands and return them as a JSON array of objects: ```json [ { "id": "stateId", // Take ID from the JSON structure "name": "Device name", // Take the name from the provided JSON structure "value": commandValue // take the value from command context } ] * One object per device/action. * If the input is unclear, return an empty array `[]`. * **Return only valid JSON. No explanation.** **Critical: use only IDs from by tool provided schema!**Das ist der originale Wert aus dem Video von @bluefox - wie ich oben gezeigt habe, funktioniert er mit meinem eigenen (Test)Tool perfekt, es werden alle Geräte richitg erkannt. (wohlbemerkt nicht in n8n, nur im Tool)
Das JSON findest Du im IO-Broker Reader:
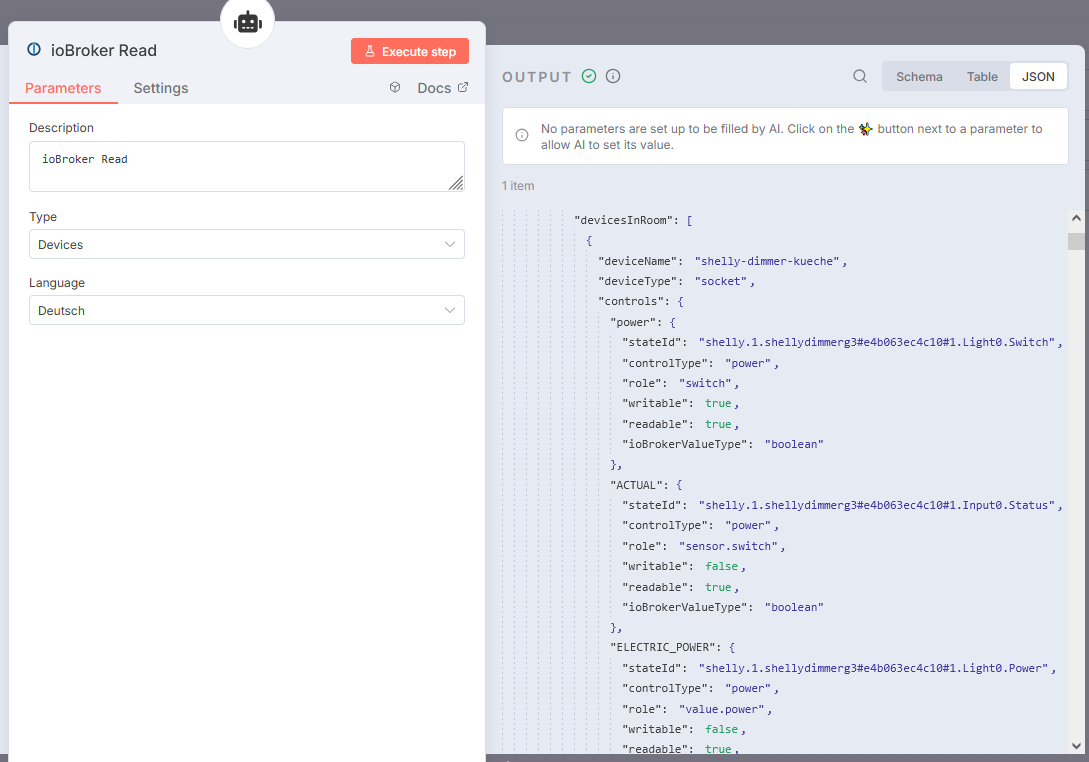
Das JSON hat 19KB und 2474 Zeilen. Im Tokenizer werden ähnlich wie in meinem Test-Tool dafür 20,370 Tokens berechnet. (Sollte es von Belang sein, kann ich die Datei hochladen oder schicken, aber es ist wohl eine "normale bis kleine" IObroker-Config...)
Schickt man den Systemprompt gemeinsam mit dem JSON (als Datei) und der anschließenden Frage, dann kommt man ja nach Modell auf 8000-9000 Tokens, also alles im grünen Bereich.
Was das Kontextfenster betrifft, habe ich oben doch recht genaue Überlegungen gepostet. Wie auch die Überlegungen und Tests zu anderen Modellen. gpt-5-nano würde rund 10% von gpt3.5-turbo kosten und hat auch alle Anfragen sauber gelöst (dann sind die Parameter doch egal) aber es braucht halt für den Schaltvorgang ca. 3-4 Sekunden... (wäre für meinen Boiler OK, für meine Lampen eher nix) - wie gesagt bleibe ich momentan einfach beim Beispiel von bluefox und versuche das sauber hinzubekommen.
Generell werden wir an dieser Stelle wohl in Zukunft alle so was wie TOON verwenden um günstiger und schneller zu werden oder länger im Kontextfenster zu bleiben. https://github.com/toon-format/toon
Für meine ersten Versuche hier wird nun aber wohl auch das aktuelle Setup von bluefox mit JSON reichen.Danke für den Hinweis zu anderen Providern, aber Du musst doch bei jedem einen Basis-Account von ca. 20€/Monat kaufen um überhaupt auf die API-Funktion zu kommen. Ich hab aktuell welche von OpenAI und Perplexity mit denen ich meine Tests ausführe. Für die APIs habe ich bisher gerade mal 5€ gezahlt, aber für die Möglichkeit sie zu haben, schon einige hundert...
Ich habe gestern übrigens auch noch mit lokalel Modellen experimentiert (LLAMA) , aber bei diesen muss man dann wohl doch den Prompt noch entsprechend anpassen, da habe ich bisher noch keine perfekten Ergebnisse bekommen. (Ist aber momentan nicht relevant, weil meine LLAMA-Modelle und IOBroker sich nicht im gleichen Netz befinden, das kann ich wirklich nur für Prompt-Tests verwenden und Euch dann ggf. Bescheid geben...)
Aus meiner Sicht sind alle KI-technischen Fragen beantwortet - mein n8n-Setup liefert dennoch falsche Ergebnisse. Es müssen aus meiner Sicht also zur Laufzeit falsche Daten reinfließen.
Kann mir jemand helfen, herauszufinden, warum bei meinem Setup anscheinend am Ende dann doch ein anderes JSON bei GPT landet als hier im Screenshot sichtbar ist und hat jemand Hinweise, woher die IDs wie "hm-rpc.1.0023A95A88E2A2.1.STATE" kommen könnten. Diese sind nicht in meinem (mir bekannten) JSON enthalten, müssen aber irgendwo herkommen. (könnte auch reine Haluzination sein - aber warum??)
-
@fritzthecat
Ich habe ebenfalls bereits mit dem im Video beschriebenen Workflow "gespielt".
Allerdings habe ich es auch nicht geschafft einen verlässlich Funktionierenden "Assistenten" aufzusetzen.
Aufgrund der relativ Großen Datenbank von ioBroker und den unterschiedlichsten Datenpunkten welche bin ich am Ende immer in ein Token runout gelaufen.
auch die Rooms und Devices reader konnten da nicht wirklich Abhilfe schaffen.
Nachdem ich es dann mit Vektor Datenbank, Lokalen Llama Modellen, usw. probiert habe, hab ich es dann beiseite gelegt und mich anderen Workflows gewidmet.Was du tun könntest wenn es sich bei deinen Geräten nur um Shellys handelt.
Erwähne die Shellys und den Datenpunktpfad (shelly.0) explizit im System Prompt. Zusätzlich Erwähnst du, dass Andere Datenpunktformate welche zb. mit hm-rpc.1 oder zigbee.0 usw. anfangen nicht verwendet werden sollen.
Wenn du unterschiedliche Geräte verwendest dann im Prompt auch ganz klar sagen welche Geräte für was verwendet werden:
Lichter = Shellys = shelly.0
Heizung = HomaticIP = hm-rpc.1
usw.
Ich vermute der "hm-rpc.1" kommt daher, das die für die Analyse hergezogenen Daten einst mit vielen Homematic Geräten "gefüttert" wurden. Und die Modelle nun immer wieder auf diese Datenpunkt Struktur zurückfallen.Es gibt bereits einen ShowCase Beitrag von mir: https://forum.iobroker.net/topic/82726/n8n-iobroker-workflows-showcase
Eventuell findest du da etwas für dich brauchbares.Aktuell teste ich eine Workflow um den ioBroker Log fortlaufend zu analysieren, mich zu benachrichtigen wenn etwas wirklich relevant ist und entsprechende Fehlerbehebungen anzubieten und auszuführen (SSH)
-
Der Systemprompt ist:
You are a Smart Home assistant for ioBroker. Always use tool to get the structure of rooms and devicses in rooms. Based on the user input below, extract all commands and return them as a JSON array of objects: ```json [ { "id": "stateId", // Take ID from the JSON structure "name": "Device name", // Take the name from the provided JSON structure "value": commandValue // take the value from command context } ] * One object per device/action. * If the input is unclear, return an empty array `[]`. * **Return only valid JSON. No explanation.** **Critical: use only IDs from by tool provided schema!**Das ist der originale Wert aus dem Video von @bluefox - wie ich oben gezeigt habe, funktioniert er mit meinem eigenen (Test)Tool perfekt, es werden alle Geräte richitg erkannt. (wohlbemerkt nicht in n8n, nur im Tool)
Das JSON findest Du im IO-Broker Reader:
Das JSON hat 19KB und 2474 Zeilen. Im Tokenizer werden ähnlich wie in meinem Test-Tool dafür 20,370 Tokens berechnet. (Sollte es von Belang sein, kann ich die Datei hochladen oder schicken, aber es ist wohl eine "normale bis kleine" IObroker-Config...)
Schickt man den Systemprompt gemeinsam mit dem JSON (als Datei) und der anschließenden Frage, dann kommt man ja nach Modell auf 8000-9000 Tokens, also alles im grünen Bereich.
Was das Kontextfenster betrifft, habe ich oben doch recht genaue Überlegungen gepostet. Wie auch die Überlegungen und Tests zu anderen Modellen. gpt-5-nano würde rund 10% von gpt3.5-turbo kosten und hat auch alle Anfragen sauber gelöst (dann sind die Parameter doch egal) aber es braucht halt für den Schaltvorgang ca. 3-4 Sekunden... (wäre für meinen Boiler OK, für meine Lampen eher nix) - wie gesagt bleibe ich momentan einfach beim Beispiel von bluefox und versuche das sauber hinzubekommen.
Generell werden wir an dieser Stelle wohl in Zukunft alle so was wie TOON verwenden um günstiger und schneller zu werden oder länger im Kontextfenster zu bleiben. https://github.com/toon-format/toon
Für meine ersten Versuche hier wird nun aber wohl auch das aktuelle Setup von bluefox mit JSON reichen.Danke für den Hinweis zu anderen Providern, aber Du musst doch bei jedem einen Basis-Account von ca. 20€/Monat kaufen um überhaupt auf die API-Funktion zu kommen. Ich hab aktuell welche von OpenAI und Perplexity mit denen ich meine Tests ausführe. Für die APIs habe ich bisher gerade mal 5€ gezahlt, aber für die Möglichkeit sie zu haben, schon einige hundert...
Ich habe gestern übrigens auch noch mit lokalel Modellen experimentiert (LLAMA) , aber bei diesen muss man dann wohl doch den Prompt noch entsprechend anpassen, da habe ich bisher noch keine perfekten Ergebnisse bekommen. (Ist aber momentan nicht relevant, weil meine LLAMA-Modelle und IOBroker sich nicht im gleichen Netz befinden, das kann ich wirklich nur für Prompt-Tests verwenden und Euch dann ggf. Bescheid geben...)
Aus meiner Sicht sind alle KI-technischen Fragen beantwortet - mein n8n-Setup liefert dennoch falsche Ergebnisse. Es müssen aus meiner Sicht also zur Laufzeit falsche Daten reinfließen.
Kann mir jemand helfen, herauszufinden, warum bei meinem Setup anscheinend am Ende dann doch ein anderes JSON bei GPT landet als hier im Screenshot sichtbar ist und hat jemand Hinweise, woher die IDs wie "hm-rpc.1.0023A95A88E2A2.1.STATE" kommen könnten. Diese sind nicht in meinem (mir bekannten) JSON enthalten, müssen aber irgendwo herkommen. (könnte auch reine Haluzination sein - aber warum??)
@FritzTheCat sagte in Test Adapter ioBroker.n8n:
mein n8n-Setup liefert dennoch falsche Ergebnisse. Es müssen aus meiner Sicht also zur Laufzeit falsche Daten reinfließen.
aber das kann man in n8n doch ganz gut verifizieren. du hast ja immer an jedem step die input und output sicht. wo ist dann der unterschied?
welche node nimmst du für gpt nano? eine openai node oder eine der LangChain Nodes?
-
@fritzthecat
Ich habe ebenfalls bereits mit dem im Video beschriebenen Workflow "gespielt".
Allerdings habe ich es auch nicht geschafft einen verlässlich Funktionierenden "Assistenten" aufzusetzen.
Aufgrund der relativ Großen Datenbank von ioBroker und den unterschiedlichsten Datenpunkten welche bin ich am Ende immer in ein Token runout gelaufen.
auch die Rooms und Devices reader konnten da nicht wirklich Abhilfe schaffen.
Nachdem ich es dann mit Vektor Datenbank, Lokalen Llama Modellen, usw. probiert habe, hab ich es dann beiseite gelegt und mich anderen Workflows gewidmet.Was du tun könntest wenn es sich bei deinen Geräten nur um Shellys handelt.
Erwähne die Shellys und den Datenpunktpfad (shelly.0) explizit im System Prompt. Zusätzlich Erwähnst du, dass Andere Datenpunktformate welche zb. mit hm-rpc.1 oder zigbee.0 usw. anfangen nicht verwendet werden sollen.
Wenn du unterschiedliche Geräte verwendest dann im Prompt auch ganz klar sagen welche Geräte für was verwendet werden:
Lichter = Shellys = shelly.0
Heizung = HomaticIP = hm-rpc.1
usw.
Ich vermute der "hm-rpc.1" kommt daher, das die für die Analyse hergezogenen Daten einst mit vielen Homematic Geräten "gefüttert" wurden. Und die Modelle nun immer wieder auf diese Datenpunkt Struktur zurückfallen.Es gibt bereits einen ShowCase Beitrag von mir: https://forum.iobroker.net/topic/82726/n8n-iobroker-workflows-showcase
Eventuell findest du da etwas für dich brauchbares.Aktuell teste ich eine Workflow um den ioBroker Log fortlaufend zu analysieren, mich zu benachrichtigen wenn etwas wirklich relevant ist und entsprechende Fehlerbehebungen anzubieten und auszuführen (SSH)
Danke für diese Infos! Vor allem die Überlegung zu "hm-rpc.1..." klingt einleuchtend. Ich hatte ja auch schon vermutet, dass es sich hier um Halluzination handeln könnte, das hat mich ganz verrückt gemacht.
Das seltsamste: ohne jede Änderung habe ich es nun vor meiner Antwort an dich nochmal getestet und bekomme nun plötzlich viel bessere Ergebnisse als zuvor (Uhrzeitabhängige Antworten der API?)
Dafür wurde trotz nun richtig gefundener Shellys plötzlich nicht mehr geschalten. Weil nun bei "Value" statt true/false "ein" und "aus" von GPT geliefert wird.
Aber auch bei mir bleibt es vorerst ein Spielprojekt und hat eigentlich noch noch keinen realen Wert, denn ich kann ja ohnehin bereits alles mit IPhone und Siri schalten was sich steuern lässt. Ich werden dennoch bei Gelegenheit Verbesserungsversuche machen und die Erkenntnisse hier posten! Es ist ein tolles Projekt um mit n8n zu spielen!
Die Erweiterung im Knoten "Parsing" die nun auch mit plötzlichem Auftreten von "Ein" "Aus" fertig wird, schaut dann so aus:
let text = $input.first().json.output; if (typeof text === 'string') { text = text.replaceAll('```', ''); text = text.replace(/^json/, ''); text = JSON.parse(text); } return text.map(it => { let v = it.value; if (typeof v === 'string') { const norm = v.trim().toLowerCase(); if (norm === 'ein') v = true; else if (norm === 'aus') v = false; } return { json: { ...it, value: v } }; }); -
@FritzTheCat sagte in Test Adapter ioBroker.n8n:
mein n8n-Setup liefert dennoch falsche Ergebnisse. Es müssen aus meiner Sicht also zur Laufzeit falsche Daten reinfließen.
aber das kann man in n8n doch ganz gut verifizieren. du hast ja immer an jedem step die input und output sicht. wo ist dann der unterschied?
welche node nimmst du für gpt nano? eine openai node oder eine der LangChain Nodes?
@OliverIO im ersten Beitrag siehst Du im Screenshot "OpenAI Chat Model" und bei Model "gpt-3.5-turbo"
an dieser Stelle, habe ich (immer korrespondierend zu meinen Versuchen in meinem eigenen Tool) verschiedene Modelle ausgewählt und die Ergebnisse verglichen.
Wähle ich hier etwa "gpt-5-nano", dann dauert der Schaltvorgang ca. 3-4 Sekunden. Jedenfalls deutlich länger als bei den "teureren" Varianten. Die Qualität der Ergebnisse war aber immer gleich/ähnlich. -
Nach der Installation kannst du n8n mit Port 5678 direkt öffnen. IObroker bindet das nur per IFrame ein. Ich nehme an, das ist was du suchst?
-
 H Homoran verschob dieses Thema von Tester am
H Homoran verschob dieses Thema von Tester am
-
H Homoran verschob dieses Thema von ...nicht in offiziellem Repo am
Hey! Du scheinst an dieser Unterhaltung interessiert zu sein, hast aber noch kein Konto.
Hast du es satt, bei jedem Besuch durch die gleichen Beiträge zu scrollen? Wenn du dich für ein Konto anmeldest, kommst du immer genau dorthin zurück, wo du zuvor warst, und kannst dich über neue Antworten benachrichtigen lassen (entweder per E-Mail oder Push-Benachrichtigung). Du kannst auch Lesezeichen speichern und Beiträge positiv bewerten, um anderen Community-Mitgliedern deine Wertschätzung zu zeigen.
Mit deinem Input könnte dieser Beitrag noch besser werden 💗
Registrieren AnmeldenSupport us
380
Online33.0k
Benutzer83.3k
Themen1.3m
Beiträge